浅谈苹果的命名困局:从Pro、Air说开去
西方语境中,13 不是一个好数字,背叛耶稣基督的犹大,据信是最后的晚餐餐桌上第 13 个就座的人。于是,西方人不喜欢数字 13 的传统一直延续到今天,很少有人宴客会邀请 13 个人,12 或 14 人都可以,13 不行。
不巧的是,9 月即将发布的新 iPhone,按照产品迭代,正好是 iPhone 13。苹果会考虑另一个名字来代替它吗?就像 iPhone X 那样?
具体选用哪个字母或数字,还要等到发布会才会揭晓。不过,回顾苹果产品线的命名史,其实可以窥见苹果虽然以简洁的市场文风著称,但有时仍会陷入不可解的命名困局。本文以 Mac、iPhone、iPad 三大产品线的命名演变史,来尝试还原苹果在开辟产品线及市场定位上的诸多困局与转变。
Mac:经典四象限命名,演变至今
之所以要先提 Mac(泛指苹果电脑产品线,下文同),是因为其 Pro 和 Air 命名影响了太多后来者。
后来者对苹果产品外观的模仿很容易让人理解,但为何连命名都要直接借鉴?原因无非两点,一是苹果自身的品牌跟进效应,二是这样的命名确实可以让消费者快速知晓产品线的特点与不同。
很明显, 无论是西文还是中文语境,Pro 让人联想到 Professional,主打专业与性能;Air 则让人联想到空气,主打轻薄便携。
这样精准、简洁的命名来源于乔布斯。
很长时间里,苹果都是作为一家电脑公司出现在人们视野,电脑产品线上根据「Apple」「Macintosh」延伸出多种多样的型号。
比如:
1990 年,乔布斯重回苹果,他将苹果的产品线缩减为简单的四象限,横轴两边分别为「消费者」「专业」,竖轴两边分别为「便携」「桌面」。消费类产品带有前缀「i」,而「Power」则保留给专业级产品使用。
这样的结果是:乔布斯的四象限命名法帮助苹果精简了产品命名上的诸多历史问题。
四象限的精妙之处在于,它可以明确每种产品的用途,让消费者一目了然。直到 2006 年,苹果都在沿用四象限命名法。
2006 年,苹果将电脑芯片从 Power 转向英特尔芯片阵营,这一年,除了 iMac 和 Mac mini 不变,其他所有的电脑名称都发生了变化。
面向消费者的 iBook 系列变成了 MacBook,面向专业消费者的 PowerBook 系列变成了 MacBook Pro,而面向专业消费者的 Power Mac 台式电脑系列变成了 Mac Pro。
乔布斯的四象限到此结束,Power 被 Pro 所取代,i 变成了 iOS 设备所专属(iPad、iPhone、iPod,除了 iMac),而在后面晚几年登场的 Watch、Pencil、TV,苹果重新沿用了 Apple 前缀,分别命名为 Apple Watch、Apple Pencil、Apple TV。(有意思的是,TV 最早代号是 iTV)
可以看出,乔布斯的第一次命名调整帮助苹果梳理了内部产品线,使之更为简洁,而第二次命名调整则是和公司整体战略相关。
iPhone:较为混乱,稍有秩序
Mac 作为生产力领域设备,同时模块化较强,无论是 CPU 强劲程度,显卡配置、屏幕尺寸都需要明确市场定位,从而可以让各种需求的消费者,能够快速找到适合自己的设备,这也是 Pro、Air 至今仍沿用的根本原因。
但是 iPhone 作为最为大众的消费类电子产品,大部分人关注的可能并不是性能,那苹果要如何做好市场定位及品宣,尽可能多地占据市场份额呢?
多品类出货无疑是最好的选择,但这也同样给 iPhone 带来了命名混乱。
其实,客观来说,从 2007 年的一代 iPhone 到现在的 iPhone 12,苹果起初定型于以每两年做一次数字迭代的方法命名新产品。(如一年 iPhone 5,下一年 iPhone 5S)
两年大迭代的频率持续到 iPhone 6 为止,也是在这一年(2014),各大手机厂商开始了大屏时代,这一年,新型号 iPhone 6 Plus 登场。
Plus 除了表示更大的屏幕之外,还有别于原版一些功能特性。如iPhone 7 Plus 相比 iPhone 7 ,多了一颗摄像头。
2015 年是让苹果开心的一年,这一年,iPhone 总销量达到历史巅峰 2.312 亿台,销售额达到 1550 亿美元。
或许是觉得「S」在人们眼里是小版本的修修补补,如何让抱着「下个版本见」的用户也加入换机浪潮,是苹果需要考虑的一大问题。于是,接下来,「S」不见了。
2016 年 iPhone 7 发布,2017 年 iPhone 8 发布,再也没有中间态「S」了。但是苹果手机的销量并没有因此而提升,反而持续下滑,2020 年营收下滑到 1377 亿美元。
2017 年 11 月,苹果在已经发布过 iPhone 8 的前提下,又发布了新机 iPhone X,直接跳过了 9 的命名。
而到了 2018 年,新机命名好像又回到了微更新「S」时代。
- iPhone XS
- iPhone XS Max
同时,Max 首次登场,这一年苹果手机销量逆势反弹到 1662 亿美元。
同年,苹果更新了 iPhone 5c 的继承品——iPhone XR,但 R 从何而来,我们目前找不到一个特别自洽的解释,只能说苹果希望表明它是「X」字辈,但又要和 XS 区分开。
这里值得注意的是,对于如 iPhone 5S 的「S」,iPhone XR的「R」,苹果习惯于将这样位置的字母,虽然大写,但是用更小的字体来展示,并外接边框,突出强调。
如:iPhone XS
还有更早之前的 iPhone 3GS:
到了 2019 年,苹果的新机命名又发生了变化,引入 Mac 经典命名 Pro,并将大屏旗舰从 Max 改名为 Pro Max。
- iPhone 11
- iPhone 11 Pro
- iPhone 11 Pro Max
新引入的 Pro 接棒原来的 Plus,而 Max 特指屏幕大一号。
2020 年,在 11 以往产品线的基础上,又添加了 iPhone 12 mini,作为大屏时代下的小屏补充。
- iPhone 12
- iPhone 12 Pro
- iPhone 12 Pro Max
- iPhone 12 mini
至此,iPhone 的产品线稳定下来。从命名上,可以看到,iPhone 的产品比 Mac 更为混乱,只能说少有秩序。
在苹果召开的 2021 秋季新品发布会上,我们看到同样的命名延续下来,也就不意外了。
- iPhone 13
- iPhone 13 Pro
- iPhone 13 Pro Max
- iPhone 13 mini
不过,发布会讲到iPhone 13 部分时,我们发现一个小细节——Pro 更加自成系列。
首先,iPhone 13 mini 和 iPhone 13 放在一起讲解。接着单独讲解人、单独过场动画的 Pro 系列登场。
苹果品宣 13 Pro 的点还是性能(A15 Bionic)、相机(前置深感、3摄等)、耐用性(外观、耐磨、耐腐蚀)、屏幕(Promotion、Oled、XDR),来包裹 Pro系列的核心关键词——专业性。
除了这些基本的参数讲解外,13 Pro 还引入电影导演的拍摄场景,来向用户传达:iPhone Pro 系列不是手机、是能干活的摄像机。
至此,苹果从 iPhone 11 推出 Pro 系列,经过三代演变,将乔布斯当时定下的消费者命名「i」,硬拉到「Pro」级别。使用的方法也非常简单,就是在硬件与生态领先后,为消费者打造出一种使用消费级产品,也能产出专业级内容的向往。
这种向往非常有鼓舞性:
尽管我不是大导演,只是一个普通人,但只要我做一件事,就有成为他们的可能,那就是购买 iPhone 13 Pro。
至此,iPhone的产品可以分为普通消费:
- iPhone 13 mini
- iPhone 13
以及专业级向往:
- iPhone 13 Pro
- iPhone 13 Pro Max
iPad:最为混乱,反正 Pro、Air 用起来没区别
如果说 iPhone 的命名演进看起来稍微有点混乱,那见识到 iPad 之后,或许你就释然了。
iPad 可以说是所有苹果设备中命名最为混乱的产品线,从 2010 年的 iPad 到 2011年 的 iPad 2 还规律可循。
2012 年,iPad 3 被命名为「全新 iPad」,作为首款配备 Retina 显示屏的iPad。这样的名字也着实敷衍,在产品角度,iPad 3 为了强上 Retina 屏,续航、重量、处理器、图形性能都差强人意,于是仅仅在存活 7 个月后,iPad 4 快速迭代了出来,三代随之停产。
iPad 4 名为「配备 Retina 显示屏的 iPad」,同时发布的还有第一代 iPad mini,当时,两台设备3天内共售出300万台,表现着实不凡。
2013年,iPad Air 发布,外观的改变促成了本次对 MacBook Air 的借名,iPad Air 仅厚 7.5毫米,重量从上代的 652g 速降至 469g,同时借鉴 iPad mini 的窄边框设计让 Air 更加名副其实,转年推出 iPad Air 2。
2015 年,最被苹果报以「生产力」期望的 iPad——iPad Pro 登场,2017年,iPad 基础版命名再次出现,不过这个时候,苹果的产品线终于已经稳定下来,入门款 iPad、轻薄款 iPad Air,性能版 iPad Pro,以及 iPad mini 同台竞技。
2017 年是一个分界线,这一年,iPad 的所有产品线后面都不再带有数字,如新推出的 iPad 改为 iPad(第 五 代),iPad Pro(第 二 代),这种只写产品线本名,将第几代弱化到详细说明中附属括号的表现方式,苹果沿用至今。
为什么 iPhone 命名会将产品名+第几代数字连写,而 iPad 不会,反而弱化到括号中?
或许是因为 iPhone 是以一年的更新频率规律更新,且随之附带的 Pro、Max 等也会随之相应规律更新。但 iPad 并不是这样,可能今年的 9 月更新 iPad Air,也可能转年的 3 月更新,也可能好几年都不更新。用户没办法通过数字快速知晓在售的这台 iPad 到底是哪年的新品,而且 Pro、Air、mini 的后缀数字也早已不在同一起跑线上了。这样一来,为何不直接去掉第几代,让消费者认为当下的这台就是最新款,无需对比历史机型。
于是,在 iPad 这一产品线上,苹果根据市场反馈,细分出 iPad 基础版、Air 轻薄版、Pro性能版、 mini 便携版。但在数字命名上,苹果选择了弱化第几代的方式进行呈现。
不过这样的产品线,到底是以满足不同用户的使用场景,还是只为了制造阶梯价格区间,收获更多利润,苹果或许陷入了一个两难境地。就以 Air 和 Pro 为例,iPad Air、Pro 之间的差别显然不如 MacBook Air、Pro 之间那样清晰。(MacBook Air 代表更轻的重量、MacBook Pro 代表更强的性能)
在 iPad 上所表现的的,11 寸(三代) iPad pro 重量为 466g,稍微比 iPad Air(四代)458g 重 8g 而已,但是厚度上,Pro 反而要比 Air 还要薄 0.2 毫米。实在体现不出来 iPad Air 的 Air 在哪里,再加上 iPad Pro 强硬件+弱软件的大马拉小车现状,也难以配得上 Pro 的称谓。
这样一来,iPad 的产品线定位更像一种价格阶梯,入门买 iPad,稍微预算高一些买 Air,想一步到位则买 Pro,尽管这三者,在目前移动办公、娱乐的使用差距上,真的很难拉开太大差距。
可以看出,乔布斯的四象限命名,已经在 iPad(亦可延展到苹果整体产品线)渐行渐远,无论是苹果刻意或无意为之,其产品线命名都在向营收导向而转型,苹果确实仍关心细分消费人群,只不过是从之前关心术业有专攻的不同需求人群,转为关心你口袋里的钞票是一张、五张、还是十张。在这里不禁要为 Mac 担心,美妙简洁且对消费者友好的四象限命名方式,还能维持多久?
定位困局,苹果求变成功了吗?
作为一家崇尚简洁的公司,可以看出,苹果相比其他厂商的命名已是十分克制,甚至对比其他厂商,苹果已然做的不错。
比如在 Lenovo 官网,可以看到,笔记本阵容分为 Thinkpad、ThinkBook、YOGA、LEGION 等五大产品线,仅在 Thinkpad 产品线下,就有将近 9 大系列,可以说是笔记本领域拥有最多 SKU 的厂商之一。
苹果的一个理念就是崇尚简洁,这种理念贯穿于其产品及对外宣传上,不过从产品命名上,却感觉苹果每次都很难考虑周全,有时做的好,有时做的一般。
在这里暂且举两个产品线消亡的例子,来一窥苹果更名背后的深层次原因。
12 寸 MacBook,难逃历史的车轮
第一个要提的产品是 MacBook(不带后缀)。2015 年,苹果发布 12 寸全新 MacBook,主打轻薄,去除了一切旧的物理接口,只留下 3.5mm 耳机插口与 Type-C 接口,移除风扇,厚度锐减到 1.31厘米,重量不到一公斤。然后于 2019 年 7 月从官网下架,空缺以新款 MacBook Air 代替。
苹果为什么要在已有 MacBook Air 的前提下,还推出 MacBook?并且为什么推出 4 年后反而砍掉?这还要回到当时的历史背景中去。
说回 MacBook Air,Air 产品线刚面世时,是绝对的高端产品线,价格甚至超过 Pro。但随后,Pro的产品形态也逐渐变得轻薄,Air 也就随之沦为 MacBook 系列中的低端型号,Air 于是不再走轻薄路线,但没让苹果想到的是,Air 的销量一直都非常不错。
于是,苹果认为,是时候重拾轻薄路线了,而在定位上,自然不会低端,因此,12 寸 MacBook 随之而来。
MacBook 不带后缀的产品线也非首次,早在 2007 年,苹果就有俗称「小白」的同名 MacBook 低端产品线,而 2015 年,苹果只是把这个产品线重拾了起来,并做了定位高端的品牌升级。
而更重要的一点是,苹果当时推出 12 寸 MacBook 契机也到了。
当年,intel 的超低功耗处理器走向成熟,这类 CPU 的明显特点是 TDP(热设计功耗)功耗仅 5-7W,且不带风扇,于是,苹果认为超低功耗 CPU 该崛起了,且非常适合极致轻薄设备。于是,苹果在机械结构、设计上做了很多努力,蝶式键盘的 MacBook 就与我们见面了。
而后其退出历史舞台,也有很多综合性因素,例如蝶式键盘口碑很糟,intel 不再强力,更重要的是 M1 的出现,让 Air 直接可以去掉风扇,变得更为轻薄。这就导致高端型号 12 寸 MacBook 并没有与低端型号 Air 拉开差距。存在感变得越来越低,从而退出历史舞台。
iMac Pro,并非 Mac Pro 竞对?
另一个消亡的产品线是 iMac Pro,不过提及它之前,不得不吐槽下 iMac 的命名,如果以当时乔布斯的意图,i 明显是赋予消费类电子产品的专属命名,如现在的 iPhone、iPad 等产品,像 iMac 这样强劲性能的产品,赋予 i 标签,或许只是一个权益之计。
2017年,苹果推出 iMac Pro,杂糅的命名(i、Pro并存)、强大的性能(浮点运算能力 24Teraflops)、不菲的售价(4万)。2021 年初,该款产品停售。
一种很流行的观点认为:iMac Pro 与 Mac Pro 是竞争关系,而大多数人用不上售价昂贵、性能溢出的 iMac Pro。
但这样的答案显然站不住脚。首先 iMac Pro 是一体机,定位更高,Pro 更像是四象限失效后,修饰 iMac 的形容词,定位于给需求更高的设计师使用。
而 Mac Pro 是工作站,定位于给像 使用 CAD 这样工业工程的专业级用户使用,而且设备可拆卸、可升级。
iMac Pro退出历史舞台的真正原因,还是因为 M1 的出现。苹果的野心是自己电脑全线配备 M1,但这真的很难。
苹果毕竟不是芯片公司,不可能为每一个产品线定制化芯片,所以我们看到 MacBook 全线+iMac 都用上了 M1。
但在 iMac Pro 工作站上,还能沿用 M1 吗?M1 再强,定位也只是低功耗处理器,TDP 顶天30 W,这和工作站的高性能还有一段距离, iMac Pro 需要的是 M1 X 这样的更强心脏,TDP 至少上百瓦才配得上工业级工作站的定位。
所以,在高性能芯片没出来时,iMac Pro 的定位着实尴尬,强上 M1也不是不行,只不过那就会和 iMac 的定位冲突了。
一种乐观的预测是: iMac Pro 只是暂时下架,等 M1 X 或是 M2 诞生,那就是它与消费级产品拉开性能差距,王者归来的时候。
我们可以发现,任何时刻,一个产品线的兴起和衰亡,与芯片更加息息相关,市场反馈则次之,要不就是出现了更强的芯片,可以让新产品线发挥垂直优势,要不就是合适的芯片还没有出现,只能先暂时别过。
内在革新 VS 外在创新
最后值得说道的还有 iPhone ,iPhone 作为目前苹果最为为大众所熟知的产品线,贡献的收入比例决定了苹果必须为该产品线分配更多的市场营销脑力与预算。
而一年一更新的苹果或许早已知道,电子产品的更新换代率和自己开新品发布会的频率总是对不上的,「凑活能用」的人们总比「永远用最新」的人要多。
如何让这一部分人乖乖掏钱,可以说是苹果最为头疼的问题,那就再开拓新的产品线吧,顺便赋予一个全新的名字,这样总比简单的数字迭代要看起来有购买欲望。
2014 年,面对大屏手机竞争,苹果开启全新型号 iphone 6 Plus 对抗安卓阵营,2015 年,小屏 SE 面世,这一年,iPhone 总销量达到历史巅峰 2.312 亿台,销售额达到 1550 亿美元。可是随后的 6 年里,苹果再也没有超过这个数字,无论是新型号 mini、Pro、Max 轮番登场,销量上,截止到 2020 年,iPhone 持续下降 14%,这是因为来自中国的竞争对手小米、华为等过于强劲了。
我们之所以无法在 Mac 市场上看到同样的命名突破,或许是因为 Mac 只占苹果 10%-20%的收入比例,同时对于专业人群,新的产品线,人们可能也并不那么感冒。
直到 2020 年,M1 芯片横空出世,告别 intel 之后,苹果为旗下 MacBook、iMac 注入更强劲的芯片,以真正实力再次获得消费者的认可,而不是市场营销层面的文字游戏。
这或许告诉我们一个道理,尽管(内在本质)革新要比创新(外在方法)难,但想办法开拓更多的产品线,并赋予一个新名词,不如打磨好已有的产品线,能获得的认可会更稳定。
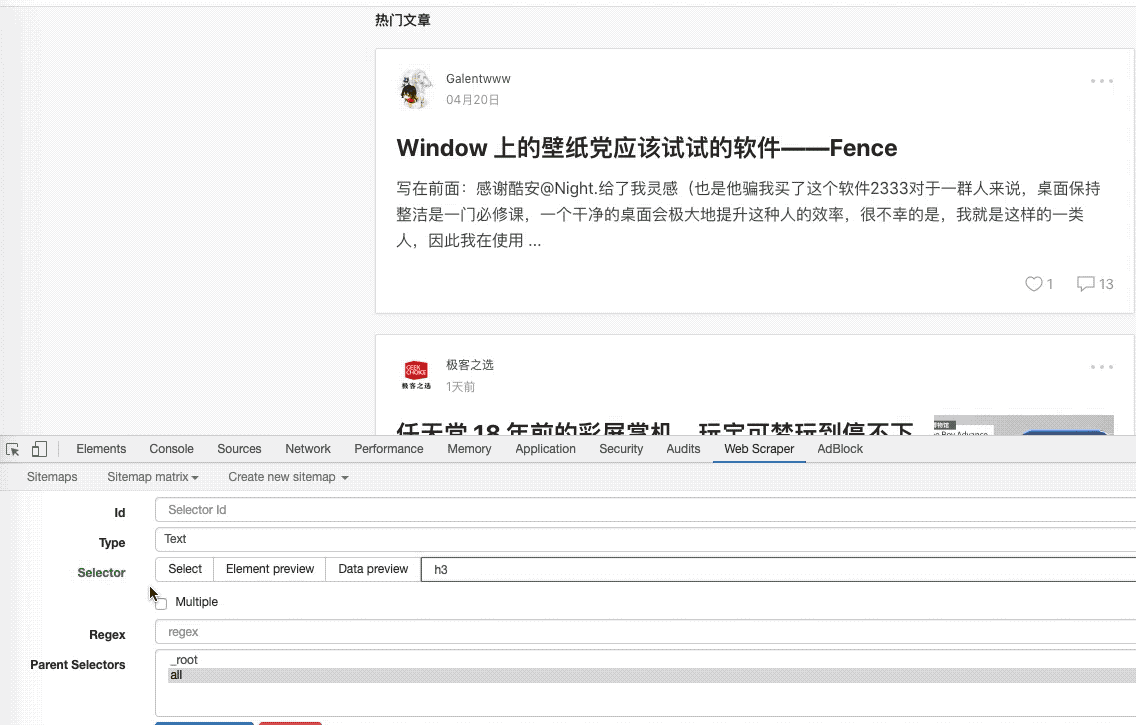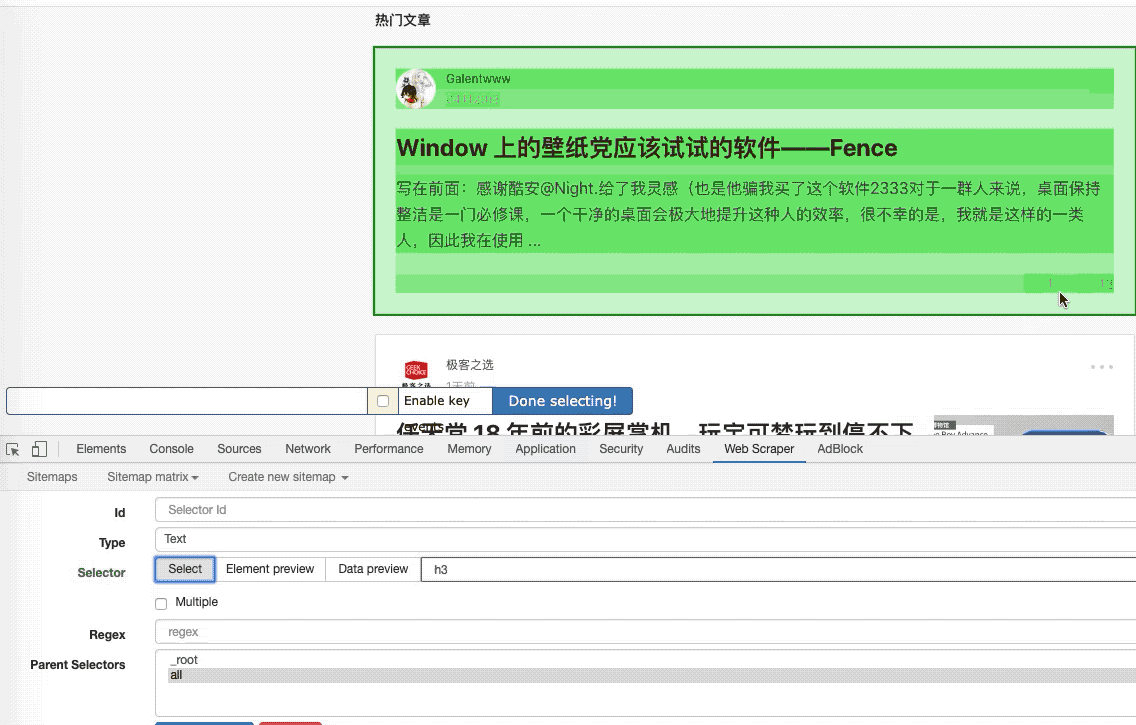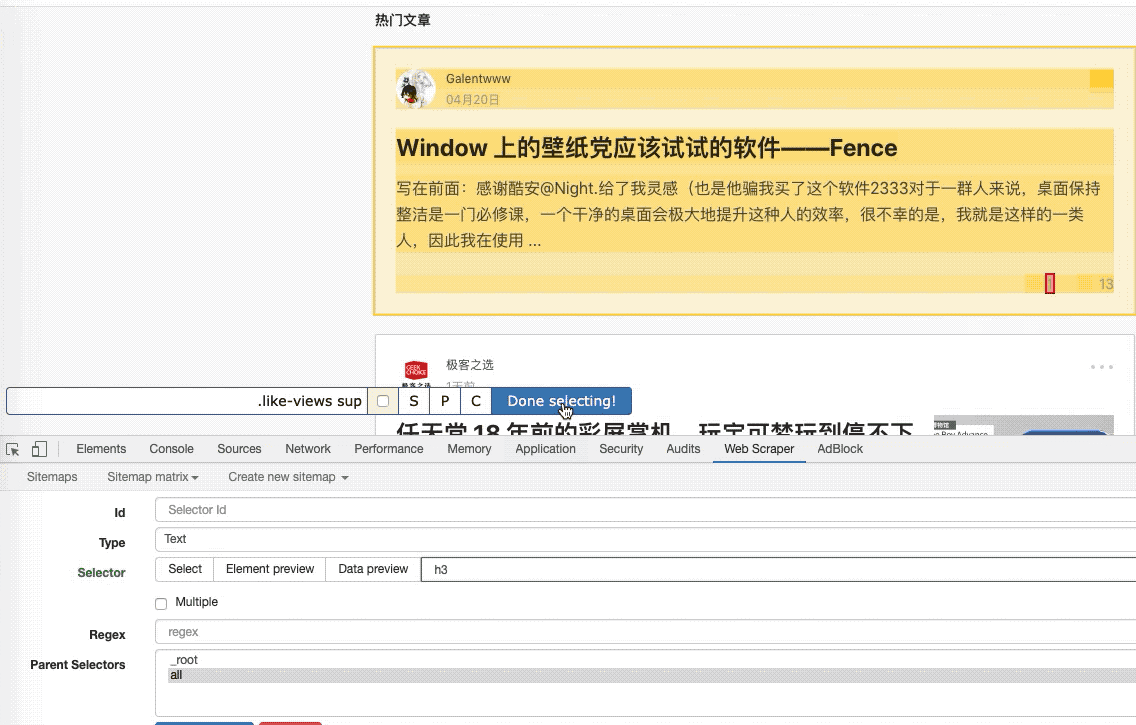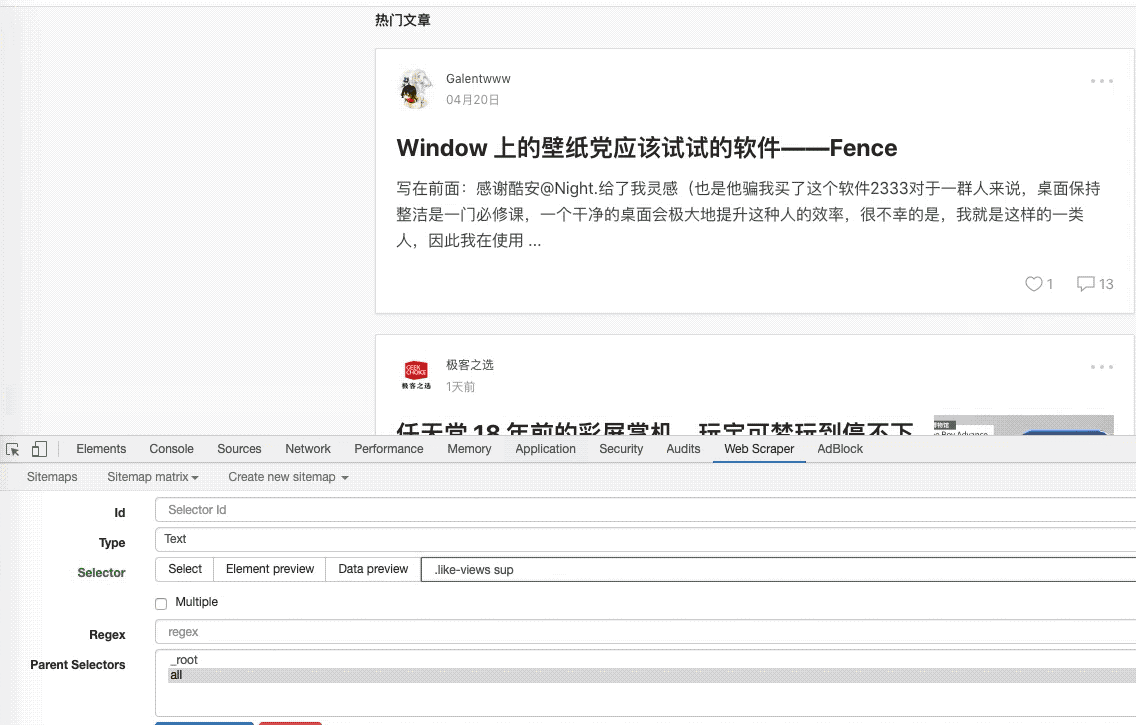
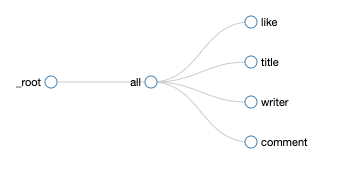
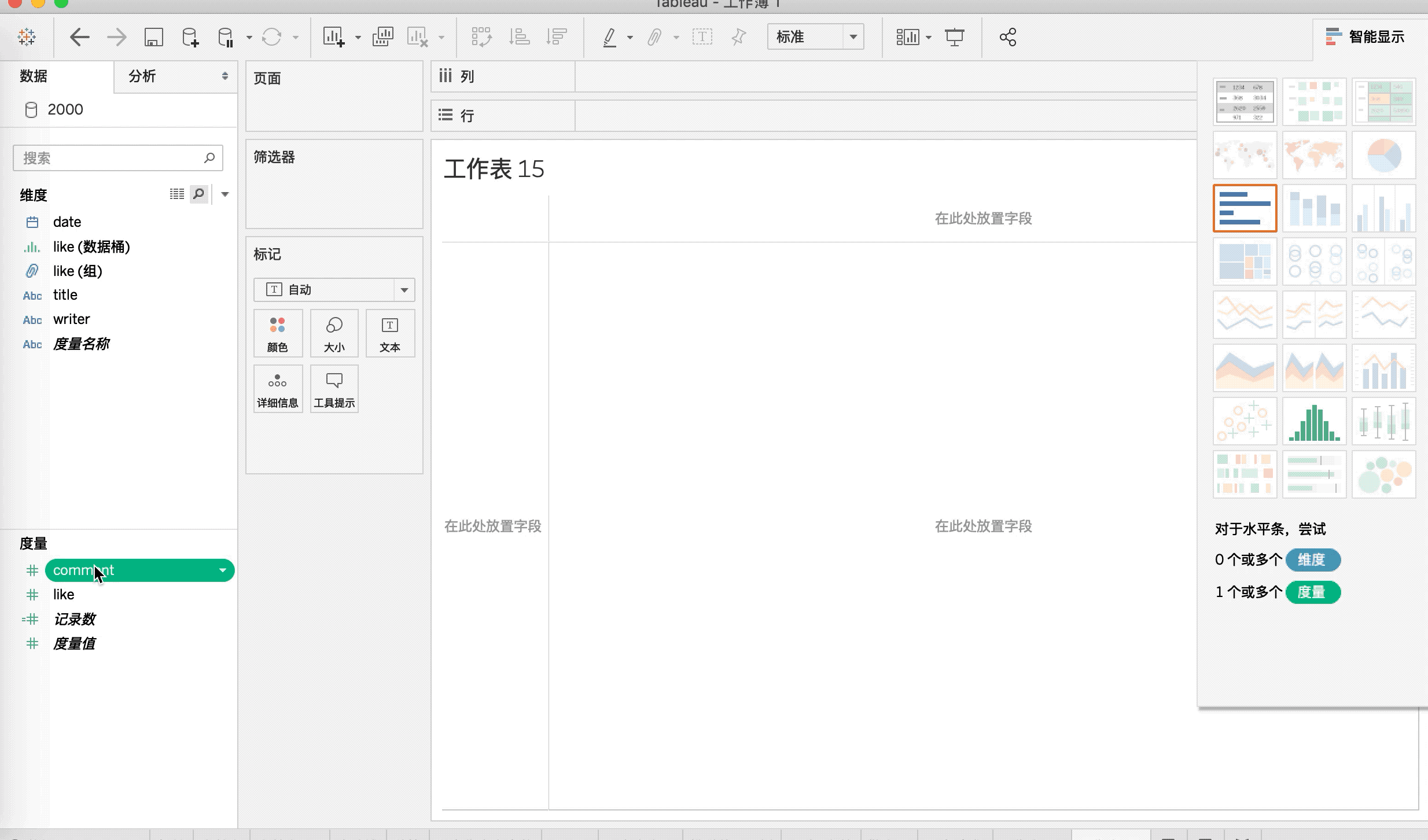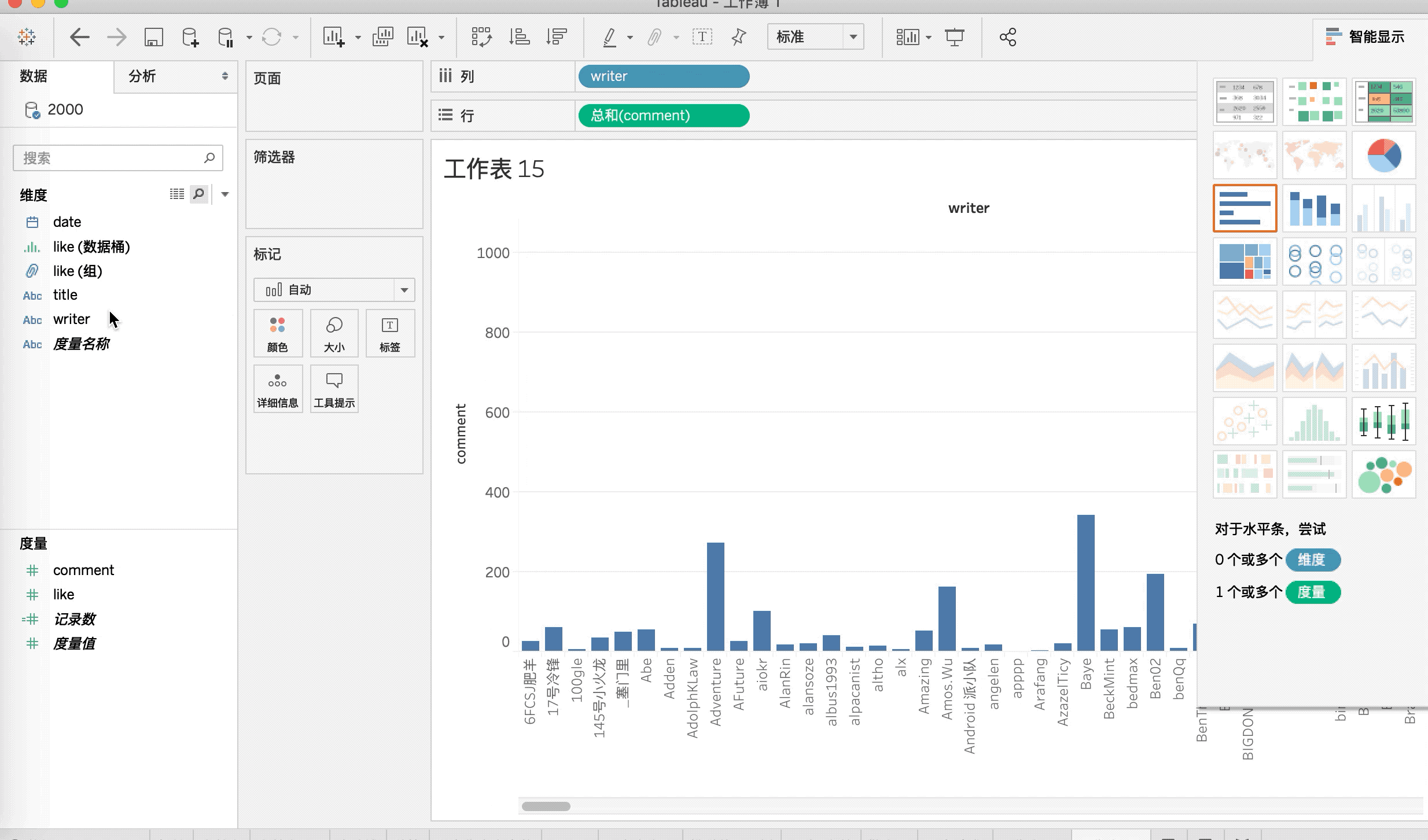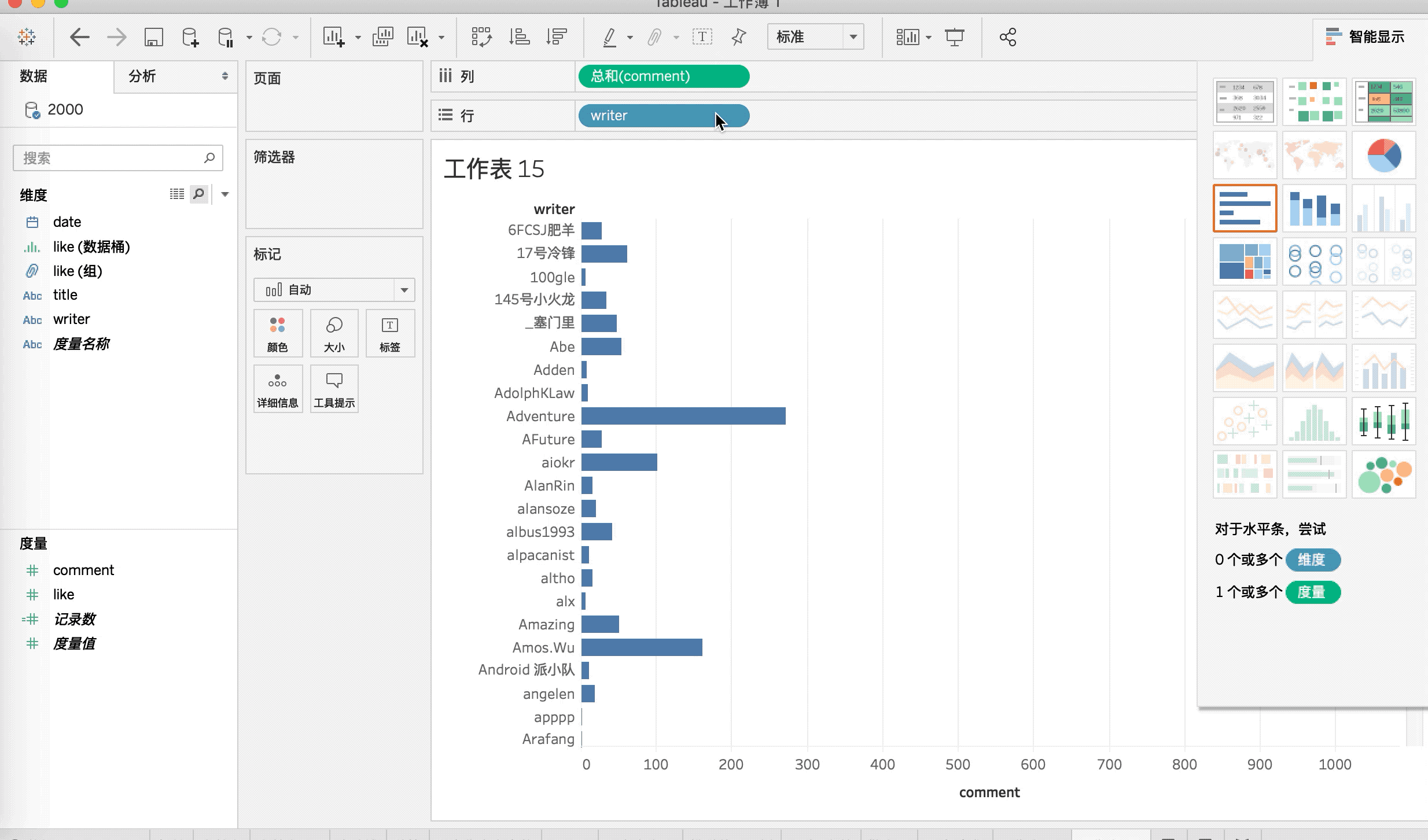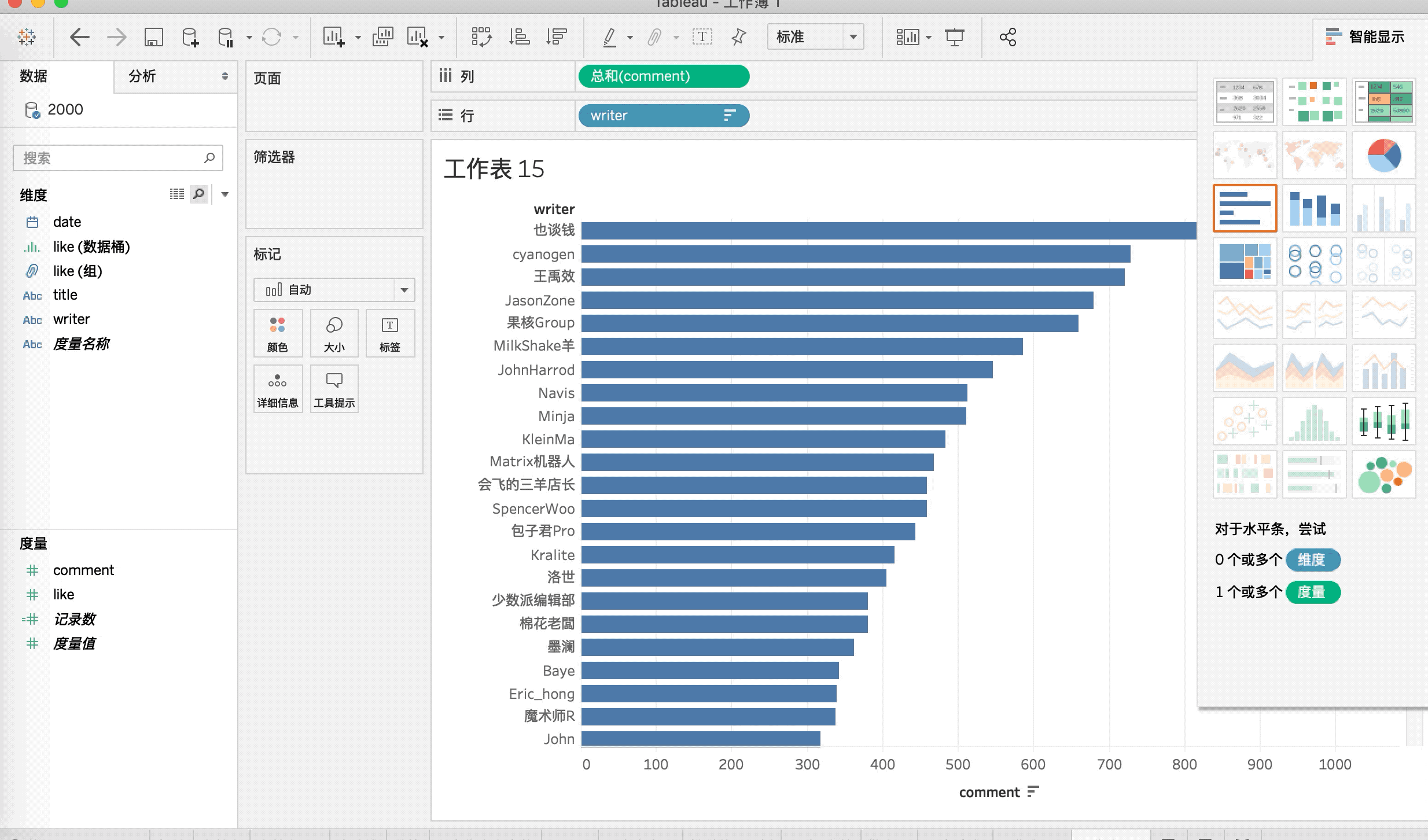
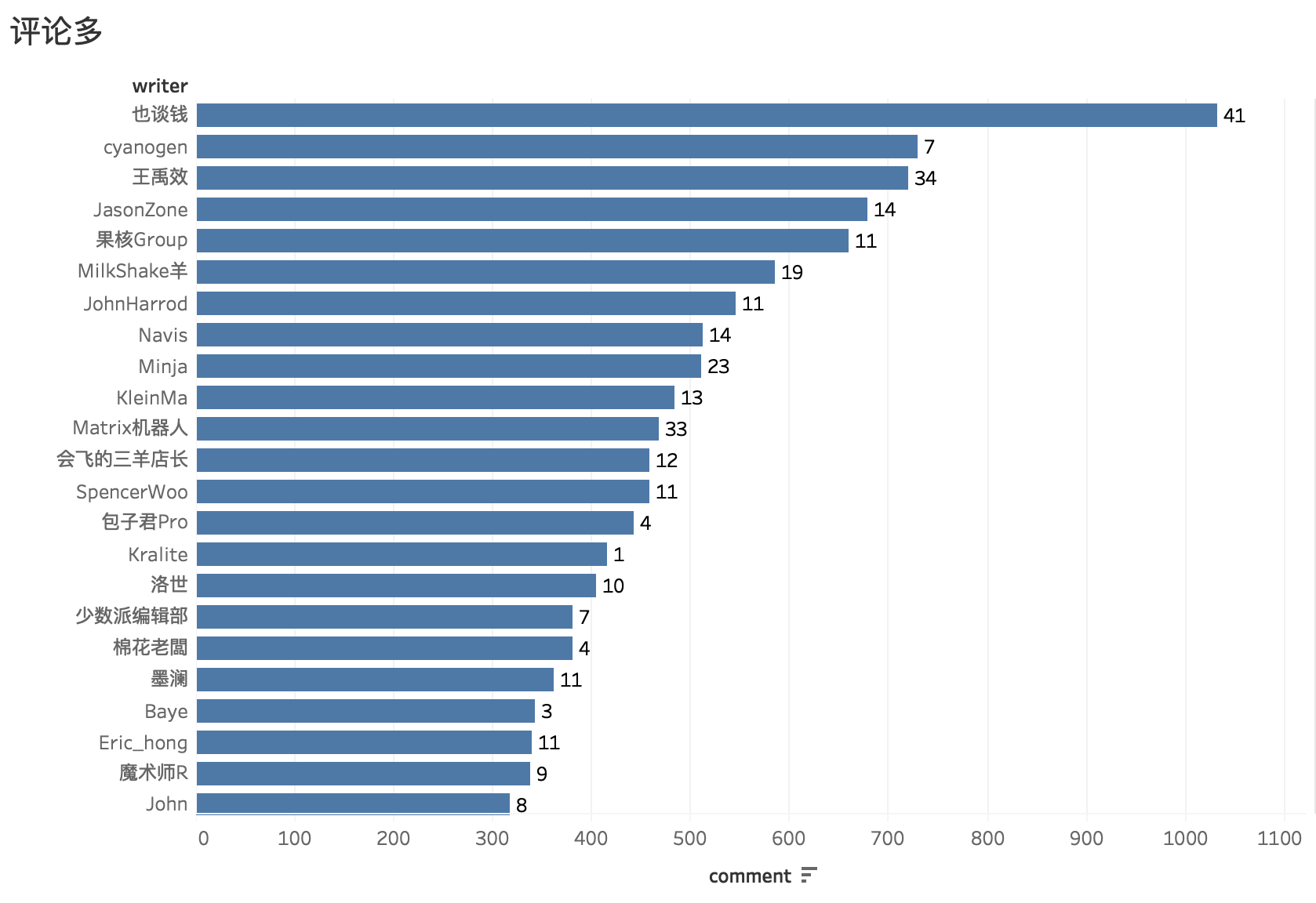
本文首发少数派,同步 WEB VIEW,感谢欧阳洋葱的内容支持。

























































{kind=link}