很早之前就想做了,然后一直拖……一直拖……想起有这么个事,但天气不好……一直拖……一直拖……一直一直拖……
终于在了一个晴天多云的日子,找了个看起来还不错挺干净的景,背着一大包的设备,在同一时间段同一角度拍照片。
设备列表
根据设备购买年份排序
- Canon PowerShot A3300 IS
- Nokia C2-00
- Nintendo 3DS
- Sony Ericsson Xperia mini pro, SK17i
- 红米2
- VIVO Y51A
- Sony Xperia XZ1
- iPhone 8
都是古董。
本来手里能拍照的设备还有一个小米平板1和iPad4,但是反复检查了好几遍这俩机器,还检查了定期备份,都没发现当日的照片。可能是忘记拍摄了?
红米1虽然也能拍照,但是早就自杀无法开机了。
拍照效果
因为是无限远景,所以均未使用手动对焦。而且非触屏设备也没有手动对焦的功能。
所有图片均为原图,保留了EXIF信息但删除了所有GPS相关的meta。文件使用 Leanify 的 mozjpeg 进行无损压缩。
想要查看具体的EXIF信息,可以另存图片到本地,然后用EXIF工具查看。
图片是走 Cloudflare CDN 的,因为都是原图所以文件比较大,国内打开很慢很正常。
Canon PowerShot A3300 IS
1600万像素(4608 × 3456)。CCD。未使用光学变焦。

Nokia C2-00
30万像素(640 × 480)。
2007怀旧画质。
Nintendo 3DS
30万像素(640 × 480)。未使用3D效果。
2007怀旧画质 x2。老任个抠逼用这么低端的硬件也是传统艺能了。
Sony Ericsson Xperia mini pro, SK17i
500万像素(2592 × 1944)。使用 Free Xperia Project, CyanogenMod-7.2.0-mango 系统的相机应用。
不对比都发现不了,这手机拍照发黄?赶紧翻了下2013年时拍的照片,发现还真的偏黄,只是不严重,单拿出来发现不了。
红米2
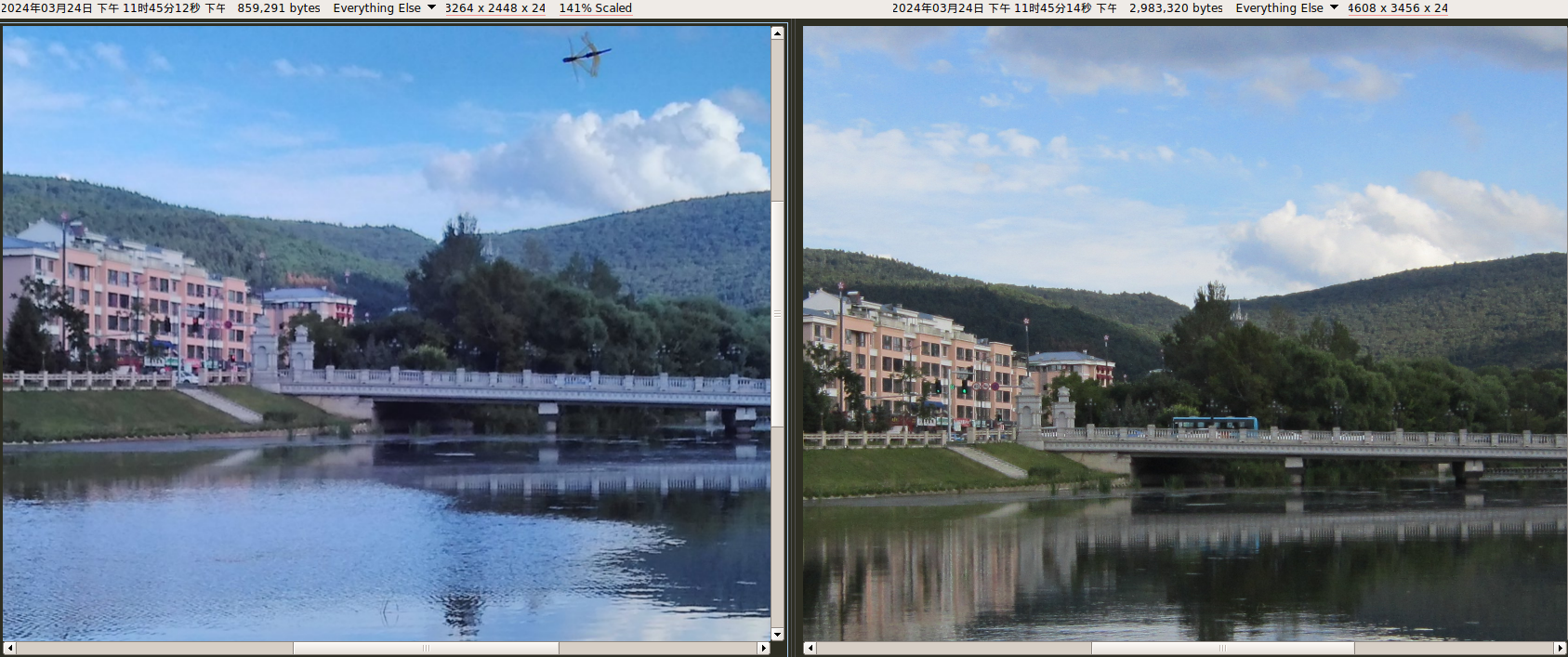
800万像素(3264 × 2448)。使用 LineageOS 15.1-20200223-NIGHTLY-wt88047 系统的相机应用。
拍第一张的时候自动光圈抽风,非常暗。
拍第二张的时候,这镜头前飞过来的这是个啥虫子???
反正这画质是够烂了,当年那么多人吹小米拍照(现在也很多人吹),也不知道有多少是水军。
VIVO Y51A
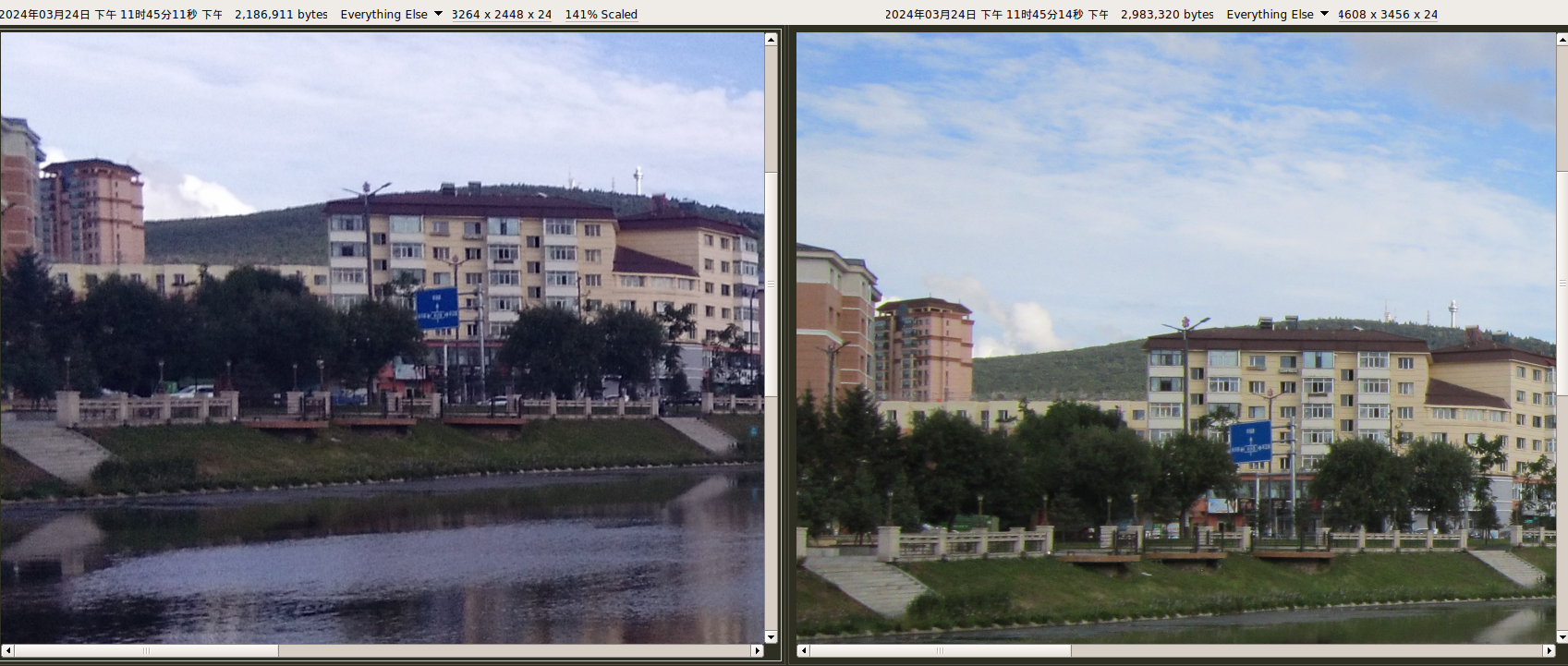
800万像素(3264 × 2448)。使用系统自带拍照应用。
如果说 SK17i 是发黄,那 Y51A 就是发蓝。
Sony Xperia XZ1
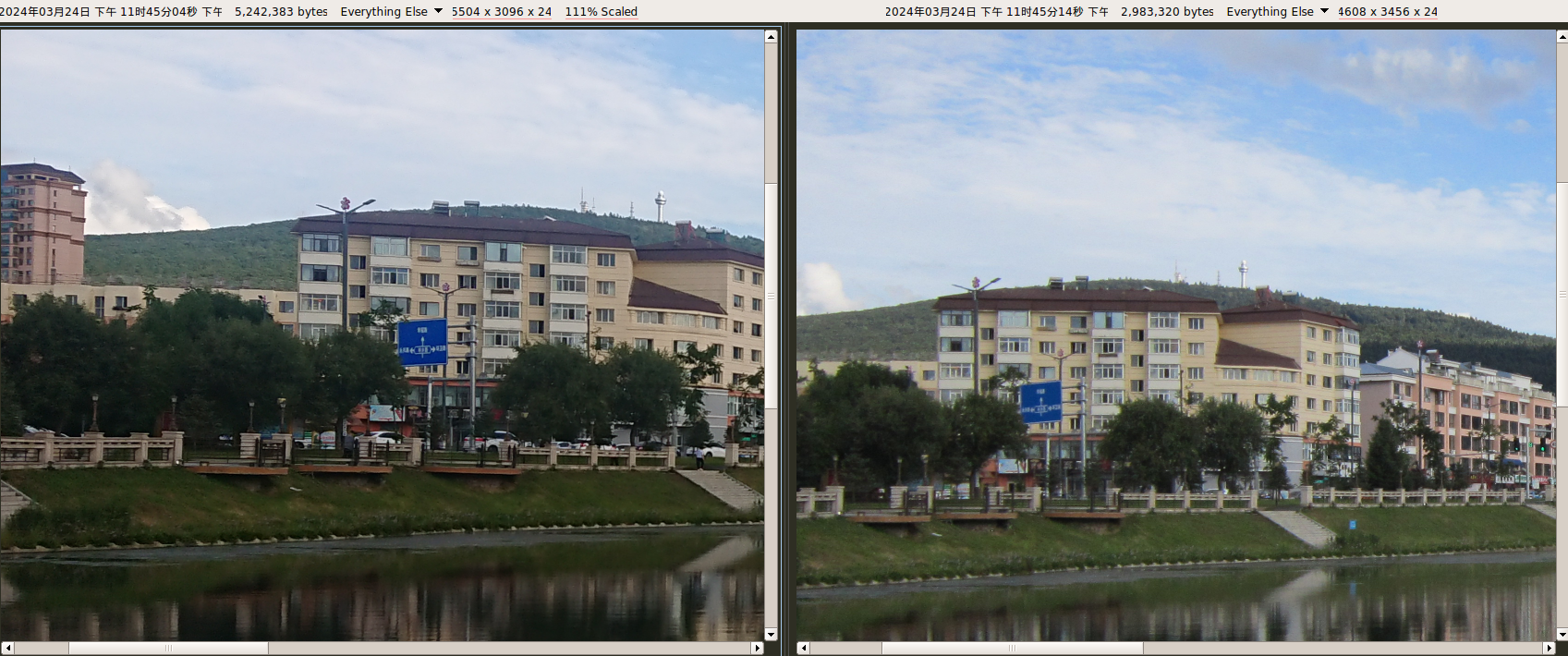
1700万像素(5504 × 3096)。使用系统自带拍照应用。自动模式,未开启 HDR。
像素比相机A3300还高,清晰度明显更占优势。但在手机镜头的硬件功能上差很多,相机永远是相机。
iPhone 8
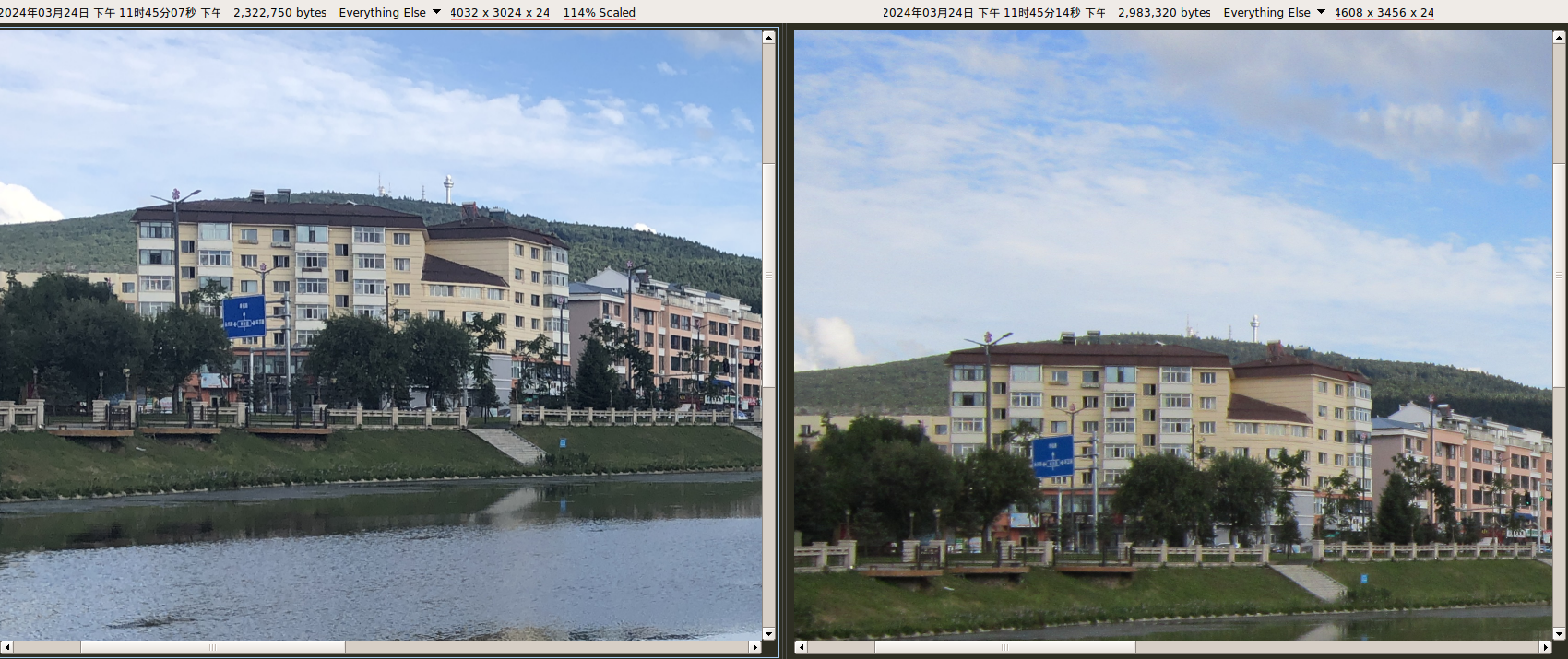
1200万像素(4032 × 3024)。使用系统自带拍照应用。自动模式,开启 HDR。使用JPG作为保存格式。(垃圾HEIF)
破玩意卖得贼拉贵,像素低,颜色微微发蓝(当然可能是太阳光照角度的问题。天气嘛,变幻莫测)。
对比
以佳能A3300为基准做对比。
使用 BCompare 进行对比。对像素较少的图片进行缩放,以高度未基准(这意味着XZ1这个有更高分辨率但图像高度低,要被放大后才能追上A3310)。
几个不是一个级别的硬件就不跟 A3300 比了,其实也就 3DS 和 C2-00 单拿出来比一下就好。
3DS VS C2-00
XZ1 VS A3300
红米2 VS A3300
Y51A VS A3300
SK17i VS A3300
iPhone8 VS A3300
总结
都是古董。
以 A3300 的战斗力仍然能坚挺。2011年的千元卡片机直到2017年才被高端手机追平(还得是无光学变焦的前提下)。
只不过现在有 HDR 这种东西存在,解决了高对比度高点光源的问题,拍照难度下降一大截,而且现在手机都是多镜头(个人认为屁用没有,我甚至怀疑各个APP是否有真的调用过多镜头)。
而且索尼的运营策略也太过奇葩,就如同applemiku说的:索尼的产品总是把本应能做的功能,硬是留到下一代产品当卖点,恶心人,明显拥有两个版本周期的巨大优势,硬是要拖到下一个版本,然后发布出来时仍是半成品,然后半个版本周期内友商就做出来完成品,两个版本周期的巨大优势 被硬搞成 半个周期的一般特性,手机照相APP的HDR功能就是,默认不开启,必须进入手动模式才开启,然后内核不支持RAW进而导致第三方应用无法支持硬件HDR,作为一个卖点是照相的拍照手机来讲,这一块做得实在太拉胯了。更别说索尼还搞了个基于相机+六轴感应实现的3D建模扫描,做到一半服务器也崩了,谷歌Drive接口也崩了,崩得一塌糊涂,结果三星下一个版本就做出来了更好的应用,并作为核心卖点进行宣传,行业内甚至都没人想得起这玩意其实是索尼先开始做的。
反正现在我拍照也不拍场照了,漫展什么的自从荷花遍地之后就不感兴趣了,跑展甚至看不到什么原创商品,以前认识的作者基本上全都退圈了(不然呢,快40多岁还跑展摆摊,那身体得多棒才跑得动)。
现在拍照基本上就是拍拍景。点光源特别亮的那种景,即使是现在有 HDR 的手机也没见谁拍出来(猜测是人的拍照技术问题)。拍人的话顶多就是给家里老人拍照片,人家要求必须要用短视频APP开美颜拍照然后自动配乐……就当哄老人乐子了,什么构图什么清晰度都不需要。
再说现在遍地魔怔人。前几天我说我有台 Xperia ,结果某个群里就嘲讽上「这么破旧的手机你也用」,我也没说我用的是啥型号,Xperia 1 V 是2023年5月发布的,还不满一年。这就有人跳起来嘲讽,这互联网上疯子是真多了。
当然我是想买新手机新相机的,但是没钱。
The post
一堆可拍照的古董设备的成像效果「多图」 first appeared on
石樱灯笼博客.