小毛驴三四年骑了2000多公里,难得去一趟,莫名其妙突然电瓶不上电,充电是红灯,淘宝一搜一块电瓶要特么2399,这不抢钱。
略花了一些时间,处理方式很简单,图中的进水探头直接拆掉就行了,大概率是因为常年停地库湿度太大,探头上有腐蚀造成短路导致的。
需要注意的是电池和外壳底部是用胶封住的,在拉出电池的时候,要注意扶助电池,别一不小心直接砸地上了(别问我是咋知道的)

小毛驴三四年骑了2000多公里,难得去一趟,莫名其妙突然电瓶不上电,充电是红灯,淘宝一搜一块电瓶要特么2399,这不抢钱。
略花了一些时间,处理方式很简单,图中的进水探头直接拆掉就行了,大概率是因为常年停地库湿度太大,探头上有腐蚀造成短路导致的。
需要注意的是电池和外壳底部是用胶封住的,在拉出电池的时候,要注意扶助电池,别一不小心直接砸地上了(别问我是咋知道的)
去年冬天结束才发现小米的电暖器插头已经烧糊掉了,想着后面天气暖和一时半会也用不着了就一直拖着没修,今年入冬前本来想自己换一条电源线,动手的时候才发现手动没有合适的螺丝刀头就又开始搁置了,冷的时候开开空调也顶得住,最近一段时间苏州实在冷的一批,开空调也顶不住了又懒得自己弄,干脆试试找小米售后看看,毕竟买了好几年,也不知道小米还有没有售后配件,于是在网上的小米售后渠道提交了售后申请。
之所以说是是一次不错的售后体验,是因为售后申请单发出去当天,小米就安排了顺丰取件,隔天就有工作人员联系并说明了报价,确认维修后,第三天就用京东返修了回来,本来换个电源线只需要25元的物料费用,由于寄出去的售后没有原包装,顺丰弄坏了一个支撑脚(小米售后也电话确认是否要进行签收),只能额外自费更换了一副支撑脚,好在不贵,比换个新的电暖器要便宜得多。
掐指一算又是快一年没更新了,服务器也从国内搬出来懒得续费了,从最初关注博客的响应和性能到现在能访问就行,对于很多东西越来越懒得折腾,博客就这么不知不觉写了14年,当初热血的少年如今也终于进入了而立之年,感谢博客让很多回忆历历在目。
公司也快搞一周年了,虽然没有特别大的收入变化,但是感觉状态是越做越顺手,似乎在努力其实不过是稀里糊涂的糊口,有时候想想理应很焦虑可事实却焦虑不起来,只觉得尽人力听天命就行,很多事情不能说悲观但肯定不能算乐观,总之是希望越来越好吧。
感谢2024还在一起的朋友伙伴,也预祝各位朋友2024新春愉快!

稀里糊涂一年半没更新了,果断水一篇,中间好多次写一半嫌太麻烦还是删了,博客做了快13年了,时间过的实在太快了,surface pro4越来越卡,新的pro9买不起,日常卡的顶不住了,无奈搞台主机放到办公室用,12代的i3-12100性能还是相当顶的,为了用bitlocker加密,单独加了块TPM模块。
离职创业也差不多一个月了,工商、税务各类手续、收拾办公室、跑新客户,一大堆事,比预期的困难,离职前有个待遇翻番的offer,但不是特别感兴趣的岗位,仔细想想自己单身一个,还是搞个公司玩玩吧,毕竟人生玩的就是不能有遗憾,希望后面一切顺利:)
|
部件
|
产品
|
价格(¥)
|
|---|---|---|
|
主板
|
471.00
|
|
|
CPU
|
628.00
|
|
|
内存
|
258.00
|
|
|
机箱
|
105.00
|
|
|
散热器
|
39.00
|
|
|
电源
|
金河田 智能芯 480GTX
|
120.00
|
|
其他
|
66.00
|
|
|
总计:
|
1687.00
|


好久没更新,掐指一算也分手半年多了,差俩月7年没熬过去也是挺可惜的
原理是利用oxidized的hooks功能调用zabbix_sender推送数据给zabbix_server。
hooks:
node_success:
type: exec
events: [node_success]
cmd: '
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.datetime -o `date +%s`;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.status -o 0;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_EVENT -o $OX_EVENT;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_STATUS -o $OX_JOB_STATUS;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_TIME -o $OX_JOB_TIME;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_IP -o $OX_NODE_IP;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_MODEL -o $OX_NODE_MODEL;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_NAME -o $OX_NODE_NAME'
async: false
timeout: 120
node_fail:
type: exec
events: [node_fail]
cmd: '
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.datetime -o `date +%s`;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_EVENT -o $OX_EVENT;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_STATUS -o $OX_JOB_STATUS;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_TIME -o $OX_JOB_TIME;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_IP -o $OX_NODE_IP;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_MODEL -o $OX_NODE_MODEL;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_NAME -o $OX_NODE_NAME;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.status -o 1'
async: false
timeout: 120
post_store:
type: exec
events: [post_store]
cmd: '
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.datetime -o `date +%s`;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_EVENT -o $OX_EVENT;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_STATUS -o $OX_JOB_STATUS;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_JOB_TIME -o $OX_JOB_TIME;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_IP -o $OX_NODE_IP;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_MODEL -o $OX_NODE_MODEL;
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k OX_NODE_NAME -o ${OX_NODE_NAME};
/usr/local/zabbix/bin/zabbix_sender -z zabbix_server_ip -s zabbix_agentd(server_name) -k oxidized.status -o 2'
async: false
timeout: 120
5.2
2021-04-16T06:03:29Z
Templates
Template Application - Oxidized
Template Application - Oxidized
This template allows traps to be sent to Zabbix using Oxidized Hooks. See https://github.com/clontarfx/zabbix-template-oxidized for more information.
Templates
Oxidized Backup Status
Oxidized Information
-
Backup Time
TRAP
oxidized.datetime
0
unixtime
Oxidized Backup Status
-
Backup Status
TRAP
oxidized.status
0
Oxidized Backup Status
-
Event
TRAP
OX_EVENT
0
0
TEXT
Oxidized Information
-
Job Status
TRAP
OX_JOB_STATUS
0
0
TEXT
Oxidized Information
-
Job Runtime
TRAP
OX_JOB_TIME
0
FLOAT
s
Oxidized Information
-
Node IP
TRAP
OX_NODE_IP
0
0
TEXT
OOB_IP
Oxidized Information
-
Node Model
TRAP
OX_NODE_MODEL
0
0
TEXT
Oxidized Information
-
Node Name
TRAP
OX_NODE_NAME
0
0
TEXT
Oxidized Information
{$OXIDIZED_AGE_WARNING}
24h
{$OXIDIZED_RUNTIME_SLOW}
60
{Template Application - Oxidized:OX_NODE_NAME.last()}=0 or {Template Application - Oxidized:oxidized.status.last(#1)}=1
NONE
Oxidized {ITEM.VALUE} Configuration Backup Failed
WARNING
MULTIPLE
YES
{Template Application - Oxidized:OX_NODE_NAME.last()}=0 or {Template Application - Oxidized:oxidized.status.last(#1)}=2
NONE
Oxidized {ITEM.VALUE} Configuration Changed
INFO
Oxidized has reported that the backup for {HOST.NAME} ({HOST.IP}) has failed. The last failure reason was {{HOST.HOST}:OX_REASON.last()}.
MULTIPLE
YES
参考:
https://cloud.tencent.com/developer/article/1657025
https://github.com/clontarfx/zabbix-template-oxidized
https://github.com/ytti/oxidized/blob/master/docs/Hooks.md
https://www.opscaff.com/2018/04/23/oxidized-%E6%9C%80%E5%A5%BD%E7%94%A8%E7%9A%84%E7%BD%91%E7%BB%9C%E8%AE%BE%E5%A4%87%E5%A4%87%E4%BB%BD%E7%B3%BB%E7%BB%9F%E4%BA%8C/
Zabbix 默认会启用 housekeeping 功能用于清理 history/trend 等历史数据,当监控服务器数量增加,保留时间有要求的情况下,housekeeping 的清理策略就会造成 Zabbix Server 性能下降,比如查询历史监控数据等。Zabbix 官方的建议是直接在数据库按照时间唯独创建分区表并定时清理,好处自然就是减少 Zabbix Server 的负担提升 Zabbix 应用对于数据库读写性能。Zabbix 3.4 之后的版本增加了对 Elasticsearch 的支持。
数据库的优化有横向和纵向扩展,这里使用数据的分布式,而分表可以看做是分布式的一种。。
在zabbix_server.conf文件中,找到如下两个参数:
(1)HousekeepingFrequency=1 解释:多久删除一次数据库里面的过期数据(间隔时间),默认一小时
(2)MaxHousekeeperDelete=5000 解释:每次删除数据量的上线(最大删除量),默认5000
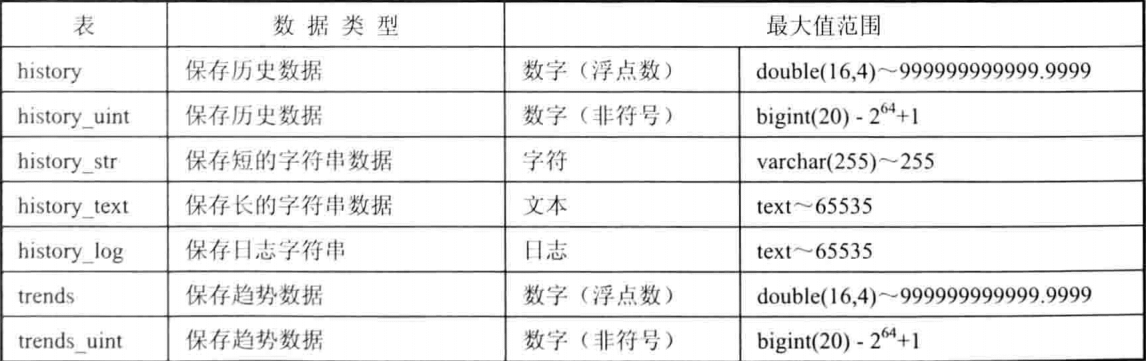
SELECT table_name AS "Tables",
round(((data_length + index_length) / 1024 / 1024), 2) "Size in MB"
FROM information_schema.TABLES
WHERE table_schema = 'zabbix'
ORDER BY (data_length + index_length) DESC;
+----------------------------+------------+
| Tables | Size in MB |
+----------------------------+------------+
| history_uint | 16452.17 |
| history | 3606.36 |
| history_str | 2435.03 |
| trends_uint | 722.48 |
| trends | 176.28 |
| history_text | 10.03 |
| alerts | 7.47 |
| items | 5.78 |
| triggers | 3.72 |
| events | 2.64 |
| images | 1.53 |
| items_applications | 0.70 |
| item_discovery | 0.58 |
| functions | 0.53 |
| event_recovery | 0.38 |
| item_preproc | 0.38 |
………………
通过以上可以看到,history_uint数据超过16G,随着数据越来越多,查询数据明显较慢,所以通过表分区的方式提升Zabbix操作MySQL的性能。
truncate table history;
optimize table history;
truncate table history_str;
optimize table history_str;
truncate table history_uint;
optimize table history_uint;
truncate table trends;
optimize table trends;
truncate table trends_uint;
optimize table trends_uint;
truncate table events;
optimize table events;
注意:这些命令会把zabbix所有的监控数据清空,只是清空监控数据,添加的主机,配置,拓扑图不会丢失。如果对监控数据比较看重的话注意备份数据库,truncate是删除了表,然后根据表结构重新建立。
vim partition.sql
DELIMITER $$
CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
PARTITIONNAME = The name of the partition to create
*/
/*
Verify that the partition does not already exist
*/
DECLARE RETROWS INT;
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK;
IF RETROWS = 0 THEN
/*
1. Print a message indicating that a partition was created.
2. Create the SQL to create the partition.
3. Execute the SQL from #2.
*/
SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd)
*/
DECLARE done INT DEFAULT FALSE;
DECLARE drop_part_name VARCHAR(16);
/*
Get a list of all the partitions that are older than the date
in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with
a "p", so use SUBSTRING TO get rid of that character.
*/
DECLARE myCursor CURSOR FOR
SELECT partition_name
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) CREATE_NEXT_INTERVALS THEN
LEAVE create_loop;
END IF;
SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600);
SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00');
IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN
CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP);
END IF;
SET @__interval=@__interval+1;
SET OLD_PARTITION_NAME = PARTITION_NAME;
END LOOP;
SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000');
CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE);
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11))
BEGIN
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE RETROWS INT(11);
DECLARE FUTURE_TIMESTAMP TIMESTAMP;
/*
* Check if any partitions exist for the given SCHEMANAME.TABLENAME.
*/
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL;
/*
* If partitions do not exist, go ahead and partition the table
*/
IF RETROWS = 1 THEN
/*
* Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values.
* We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition
* that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could
* end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000").
*/
SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00'));
SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00');
-- Create the partitioning query
SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)");
SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));");
-- Run the partitioning query
PREPARE STMT FROM @__PARTITION_SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE`partition_maintenance_all`(SCHEMA_NAME VARCHAR(32))
BEGIN
CALL partition_maintenance(SCHEMA_NAME, 'history', 90, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 90, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 90, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 90, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 90, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 730, 24, 14);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 730, 24, 14);
END$$
DELIMITER ;
mysql -uzabbix -pzabbix zabbix /tmp/partition.log
#第一次可以设置1分钟执行1次,然后查看日志文件是否允许正常
mysql> show create tables history_uint;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'tables history_uint' at line 1
mysql>
mysql> show create table history_uint;
+--------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| history_uint | CREATE TABLE `history_uint` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` bigint(20) unsigned NOT NULL DEFAULT '0',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_uint_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
/*!50100 PARTITION BY RANGE (`clock`)
(PARTITION p202104100000 VALUES LESS THAN (1618070400) ENGINE = InnoDB,
PARTITION p202104110000 VALUES LESS THAN (1618156800) ENGINE = InnoDB,
PARTITION p202104120000 VALUES LESS THAN (1618243200) ENGINE = InnoDB,
PARTITION p202104130000 VALUES LESS THAN (1618329600) ENGINE = InnoDB,
PARTITION p202104140000 VALUES LESS THAN (1618416000) ENGINE = InnoDB,
PARTITION p202104150000 VALUES LESS THAN (1618502400) ENGINE = InnoDB,
PARTITION p202104160000 VALUES LESS THAN (1618588800) ENGINE = InnoDB,
PARTITION p202104170000 VALUES LESS THAN (1618675200) ENGINE = InnoDB,
PARTITION p202104180000 VALUES LESS THAN (1618761600) ENGINE = InnoDB,
PARTITION p202104190000 VALUES LESS THAN (1618848000) ENGINE = InnoDB,
PARTITION p202104200000 VALUES LESS THAN (1618934400) ENGINE = InnoDB,
PARTITION p202104210000 VALUES LESS THAN (1619020800) ENGINE = InnoDB,
PARTITION p202104220000 VALUES LESS THAN (1619107200) ENGINE = InnoDB,
PARTITION p202104230000 VALUES LESS THAN (1619193600) ENGINE = InnoDB) */ |
+--------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
在web界面,管理—-一般—-设置—管家,取消历史、趋势标识的管家功能。
./configure --prefix=/usr/local/zabbix --enable-server --enable-agent --with-mysql=/usr/local/mysql/bin/mysql_config --enable-ipv6 --with-net-snmp --with-libcurl --with-openssl --with-libxml2
#编译参数新增--with-libxml2,为了监控VMware vSphere主机做准备
create database zabbix character set utf8 collate utf8_bin;
#创建数据库使用utf8_bin编码
#zabbix_server.conf的DBSocket参数需要填写
参考:
https://blog.csdn.net/qq_22656871/article/details/110237755
https://wsgzao.github.io/post/zabbix-mysql-partition/
https://www.cnblogs.com/yjt1993/p/10871574.html
实实在在不想用ubuntu server,为了后面配合zabbix做配置变更的告警出发,docker后期的配置zabbix会更麻烦,所以经过一天的折腾,oxidized成功部署在了centos7.9上,docker的部署方式在本文后半段,需要的话请往后面翻。
系统版本号:CentOS Linux release 7.9.2009 (Core)
yum update
#更新前,建议更换国内yum源,开局可以直接更新,正式放到生产后不建议使用update更新所有rpm包
#记得关闭selinux
yum install centos-release-scl
#安装centos-release-scl软件源
yum install rh-ruby23 rh-ruby23-ruby-devel
#安装ruby2.3版本,系统自带为2.0的ruby
scl enable rh-ruby23 bash
#这一步非常重要,开启ruby的环境变量,否则oxidized无法启动
yum install make cmake which sqlite-devel openssl-devel libssh2-devel ruby gcc ruby-devel libicu-devel gcc-c++
#安装相关的依赖
gem install oxidized
#安装主角
gem install oxidized-script oxidized-web
#安装web界面
ruby -v
[root@localhost ~]# ruby -v
ruby 2.3.8p459 (2018-10-18 revision 65136) [x86_64-linux]
#检查ruby版本是否正确,应大于2.3
which ruby
[root@localhost ~]# which ruby
/opt/rh/rh-ruby23/root/usr/bin/ruby
#检查ruby路径
vim /etc/profile.d/rh-ruby22.sh
#!/bin/bash
source /opt/rh/rh-ruby23/enable
export X_SCLS="`scl enable rh-ruby23 'echo $X_SCLS'`"
export PATH=$PATH:/opt/rh/rh-ruby23/root/usr/bin/ruby
#配置环境变量的自启动
ln -s /opt/rh/rh-ruby23/root/usr/local/bin/oxidized /usr/local/bin/oxidized
vim /lib/systemd/system/oxidized.service
# /lib/systemd/system/oxidized.service
[Unit]
Description=Oxidized - Network Device Configuration Backup Tool
After=network-online.target multi-user.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/oxidized
KillSignal=SIGKILL
User=root
[Install]
WantedBy=multi-user.target
#以上使用root用户运行oxidized,一定要确保已经做了/usr/local/bin/oxidized的ls链接
chmod +x /lib/systemd/system/oxidized.service
vi /etc/ld.so.conf
#增加 /opt/rh/rh-ruby23/root/usr/lib64
ldconfig
ldconfig -v
#检查有没有ruby的so库
chmod +x /lib/systemd/system/oxidized.service
#接着需要创建router.db和config配置文件,这些请参考以下docker的配置流程,完全一致
[root@localhost ~]# systemctl enable oxidized.service
Created symlink from /etc/systemd/system/multi-user.target.wants/oxidized.service to /usr/lib/systemd/system/oxidized.service.
[root@localhost ~]# systemctl start oxidized.service
[root@localhost ~]# systemctl status oxidized.service
● oxidized.service - Oxidized - Network Device Configuration Backup Tool
Loaded: loaded (/usr/lib/systemd/system/oxidized.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2021-03-24 18:59:37 CST; 2s ago
Main PID: 6767 (oxidized)
CGroup: /system.slice/oxidized.service
└─6767 puma 3.11.4 (tcp://0.0.0.0:8888) [/]
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: I, [2021-03-24T18:59:37.635254 #6767] INFO -- : Oxidized starting, running as pid 6767
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: I, [2021-03-24T18:59:37.635810 #6767] INFO -- : lib/oxidized/nodes.rb: Loading nodes
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: I, [2021-03-24T18:59:37.711327 #6767] INFO -- : lib/oxidized/nodes.rb: Loaded 1 nodes
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: Puma starting in single mode...
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: * Version 3.11.4 (ruby 2.3.8-p459), codename: Love Song
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: * Min threads: 0, max threads: 16
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: * Environment: development
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: * Listening on tcp://0.0.0.0:8888
Mar 24 18:59:37 localhost.localdomain oxidized[6767]: Use Ctrl-C to stop
Mar 24 18:59:39 localhost.localdomain oxidized[6767]: W, [2021-03-24T18:59:39.990844 #6767] WARN -- : /192.168.1.1 status no_connection, retry attempt 1
[root@localhost ~]#
firewall-cmd --zone=public --add-port=8585/tcp --permanent
systemctl reload firewalld.service
如果不配置router.db是无法启动oxidized服务的,NGINX、时间等其他问题,也都和docker部署配置一致,请往下参考即可,最后请记得关闭防火墙或放行oxidized的web端口:)
早就听说过oxidized的大名,一直没环境折腾,刚好新做一个项目,有一定规模的交换机,手动备份费时费力,自动备份也比较单一没办法做到配置版本回溯比对,于是想用oxidized来实现初步的运维自动化建设,在centos使用gem安装oxidized的时候各种问题,网上资料也很少,实在不想费劲折腾也不想用Ubuntu,就选择使用docker进行部署,系统使用centos7.9minimal版本。
更新系统软件包(yum update)、关闭SELINUX这种系统的基线设置本文不予阐述,请根据自己的业务需求初始化自己的业务环境。
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#先卸载干净系统可能存在的docker软件包
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io
sudo systemctl start docker
sudo systemctl enable docker
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json
oxidized镜像
docker pull oxidized/oxidized:latest
mkdir /etc/oxidized
docker run --name='oxidized' -itd -v /etc/oxidized:/root/.config/oxidized -p 127.0.0.1:8888:8888/tcp -t oxidized/oxidized
#挂载本地/data/oxidized目录到容器内的/root/.config/oxidized目录下,将容器的8888端口映射到127.0.0.1的8888端口
#可以使用iptables -t nat -nL对iptables的NAT规则进行检查
docker logs oxidized #查看oxidized容器的日志
cd /etc/oxidized
touch router.db
#暂时使用router.db作为数据源,编辑该文件,格式示例:192.168.1.1:ios:admin:admin:enablepass
config配置文件
---
username: username
password: password
model: junos
resolve_dns: true
interval: 3600
use_syslog: false
debug: false
threads: 30
timeout: 20
retries: 3
prompt: !ruby/regexp /^([\w.@-]+[#>]\s?)$/
rest: 0.0.0.0:8888
next_adds_job: false
vars:
auth_methods: ["none", "publickey", "password", "keyboard-interactive"]
groups: {}
models: {}
pid: "/root/.config/oxidized/pid"
crash:
directory: "/root/.config/oxidized/crashes"
hostnames: false
stats:
history_size: 10
input:
default: ssh, telnet
debug: false
ssh:
secure: false
ftp:
passive: true
utf8_encoded: true
output:
default: git
git:
user: Oxidized
email: o@example.com
repo: "/home/oxidized/.config/oxidized/oxidized.git"
source:
default: csv
csv:
file: "/root/.config/oxidized/router.db"
delimiter: !ruby/regexp /:/
map:
name: 0
model: 1
username : 2
password : 3
vars_map:
enable : 4
gpg: false
model_map:
juniper: junos
cisco: ios
#以上将开启oxidized的历史版本功能,其中map后面的1、2、3…等对应router.db中:分割的字段
output:
default: file
file:
directory: "/root/.config/oxidized/configs"
#如果希望将备份文件存放在目录中,请将output修改为以上,如果即希望保存文件也希望保存历史版本,可以对接gitlab,由于对gitlab不熟悉目前没有进一步的折腾
以上感谢“网络自动化与安全”群中的. Toby、Game两位大佬的技术支持!
oxidized时间的问题
为了oxidized的时间有意义,需要对时间进行校准确保时间的准确性
docker exec -it oxidized /bin/bash
mkdir -P /usr/share/zoneinfo/Asia
vi /var/lib/gems/2.5.0/gems/oxidized-web-0.13.1/lib/oxidized/web/public/scripts/oxidized.js
#找到timeZone字段,将上面一行注释掉,并删掉timeZone参数(//var timeZone = date.toString().match(/\(.*\)/)[0].match(/[A-Z]/g).join('');)
#以上js修改可以参考:https://cloud.tencent.com/developer/article/1657021
exit
#以上进入oxidized容器,并在容器中创建时区目录以及修改ui的js文件中时区参数,操作完成后退出容器bash
docker cp /usr/share/zoneinfo/Asia/ oxidized:/usr/share/zoneinfo/Asia
docker cp /etc/localtime oxidized:/etc/localtime
#复制系统的时区文件给oxidized容器
yum -y install ntpdate
ntpdate ntp1.aliyun.com
shutdown -r now
#重启系统后,再启动oxidized容器,时间将变得正常,别问我为啥要重启,我也不知道,但重启过时间确实就ok了
#2021.3.24更新:直接安装测试注释以上无效,但是hour变量直接+8倒是可以的,如下:
var convertTime = function() {
/* Convert UTC times to local browser times
* Requires that the times on the server are UTC
* Requires a class name of `time` to be set on element desired to be changed
* Requires that element have a text in the format of `YYYY-mm-dd HH:MM:SS`
* See ytti/oxidized-web #16
*/
$('.time').each(function() {
var content = $(this).text();
if(content === 'never' || content === 'unknown' || content === '') { return; }
var utcTime = content.split(' ');
var date = new Date(utcTime[0] + 'T' + utcTime[1] + 'Z');
var year = date.getFullYear();
var month = ("0"+(date.getMonth()+1)).slice(-2);
var day = ("0" + date.getDate()).slice(-2);
var hour = ("8" + date.getHours()).slice(-2);
var minute = ("0" + date.getMinutes()).slice(-2);
var second = ("0" + date.getSeconds()).slice(-2);
//var timeZone = date.toString().match(/\(.*\)/)[0].match(/[A-Z]/g).join('');
$(this).text(year + '-' + month + '-' + day + ' ' + hour + ':' + minute + ':' + second + ' ');
});
};
Nginx反代设置
oxidized本身不包含用户身份验证的模块,所以需要依靠nginx的认证模块,调用.htpasswd来进行用户身份认证,这非常重要,毕竟设备配置中可能会保存一些重要的信息!
因为仅仅需要用到nginx的反代功能,所以直接yum安装即可,比编译安装起来方便的多。
yum install epel-release
yum install -y nginx
#在nginx.conf中添加include /etc/nginx/vhost/*.conf; 这存粹个人习惯,你爱怎么用nginx都行,配置直接写在nginx.conf都可以
mkdir /etc/nginx/vhost/
vim /etc/nginx/vhost/oxidized.conf
server {
listen 8585;
server_name 172.16.11.227;
auth_basic "SDFYY SWCFG MANAGER UI WEB";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:8888/;
}
access_log /var/log/nginx/access_oxidized.log;
error_log /var/log/nginx/error_oxidized.log;
}
#在run容器的命令中,将oxidized容器的8888端口NAT给了127.0.0.1的8888端口,故只需要反代127.0.0.1的8888即可
[root@localhost ~]# iptables -t nat -nL
.....
MASQUERADE tcp -- 172.17.0.2 172.17.0.2 tcp dpt:8888
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
DNAT tcp -- 0.0.0.0/0 127.0.0.1 tcp dpt:8888 to:172.17.0.2:8888
.....
其中.htpasswd的生成方法有很多,最简单可以在https://tool.oschina.net/htpasswd直接在线生成,但是这样会增加你的密码被md5字典收录的风险:)
重要参考#1:https://www.shuzhiduo.com/A/pRdBqbwn5n/
重要参考#2:https://kknews.cc/code/on2nzpo.html
重要参考#4:https://www.opscaff.com/2018/04/18/oxidized-%E6%9C%80%E5%A5%BD%E7%94%A8%E7%9A%84%E7%BD%91%E7%BB%9C%E8%AE%BE%E5%A4%87%E5%A4%87%E4%BB%BD%E7%B3%BB%E7%BB%9F/
重要参考#5:https://zhuanlan.zhihu.com/p/351533336
重要参考#6:https://cloud.tencent.com/developer/article/1657021
年关已至,作为主力机的苏菲婆电池越来越不耐操,观察8代X1C良久,无奈缺米未入,同时深受幽灵触摸折磨,连带屏幕一起换掉,希望缝缝补补可以再战三年。

测试期间直接删除了composer服务器,导致link clone生成的replica-xxx命令的副本母机无法删除,需要先解除保护后才能从VCSA中。
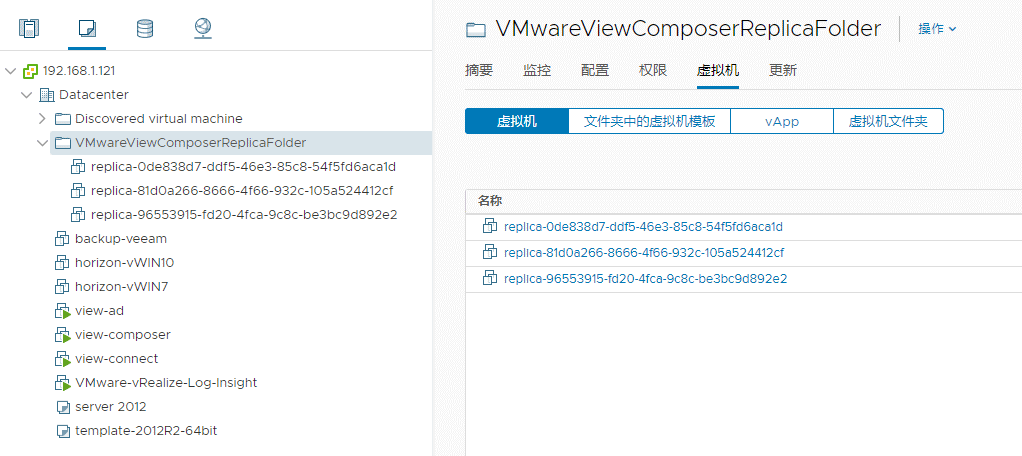
登录composer服务器,停用掉view composer服务,接着cmd先cd到C:\Program Files (x86)\VMware\VMware View Composer目录下,执行以下命令:
SviConfig -operation=UnprotectEntity -VcUrl=https://VC地址/sdk -DsnName=数据库名 -DbUsername=sa -DbPassword=SA密码 -VcUsername=Administrator@vsphere.local -VcPassword=VC密码 -InventoryPath="/Datacenter/vm/VMwareViewComposerReplicaFolder/replica-96553915-fd20-4fca-9c8c-be3bc9d892e2" -Recursive=true
执行过程中遇到了错误的话,请参考以下:
ExitStatus:
0 - operation ends successfully.
1 - The supplied DSN name can not be found.
2 - The supplied credentials are invalid.
3 - Unsupported driver for the provided database.
4 - Unexpected problem arisen.
9 - invalid URL.
10 - VC can not be accessed.
11 - entity is not found.
12 - unknown entity type.
13 - release failed.
15 - Other application is using required resources. Stop it and retry
the operation.
18 - Unable to connect to database server.
34 - invalid VC certificate.
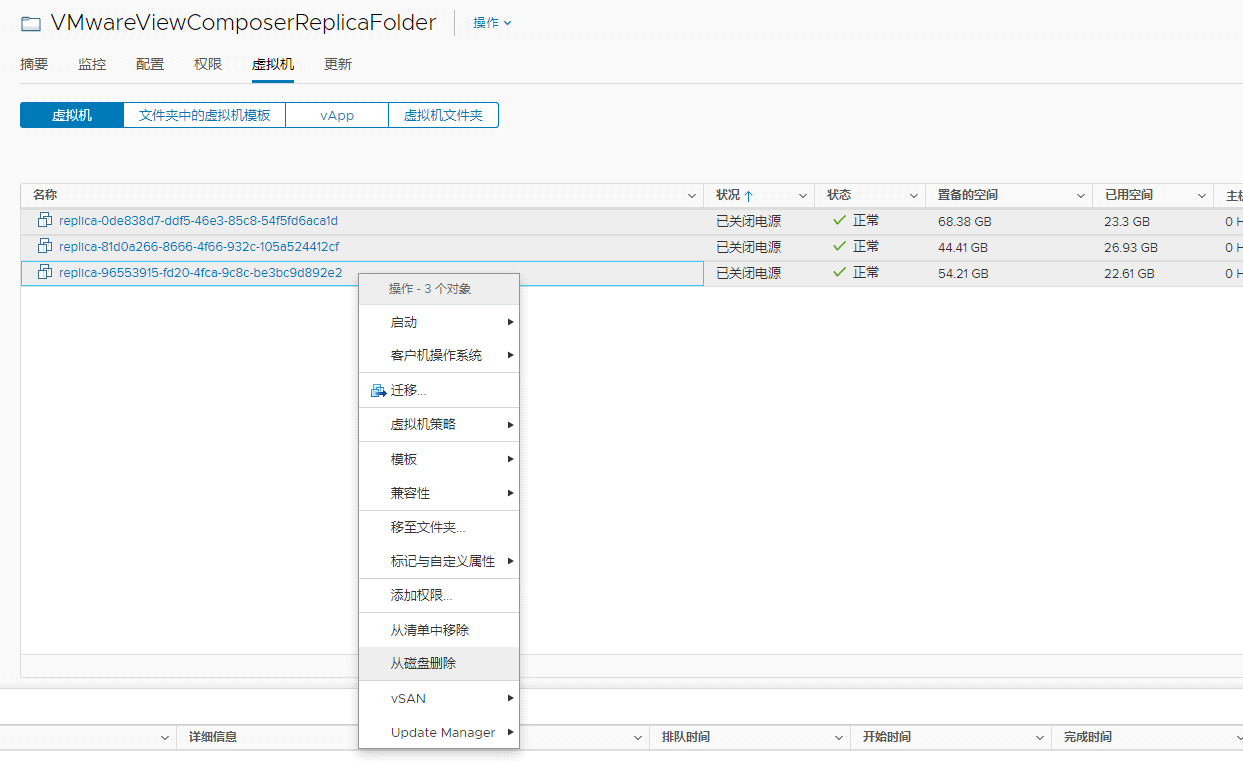
可算是能删掉了:
参考:
https://www.ntueees.tp.edu.tw/wordpress/?p=1686
https://kb.vmware.com/s/article/1008704?lang=zh_CN
https://kb.vmware.com/s/article/2009844?lang=zh_CN
http://blog.sina.com.cn/s/blog_83536791010111a4.html
https://blog.51cto.com/wangchunhai/1846285
https://blog.51cto.com/11388141/2295893
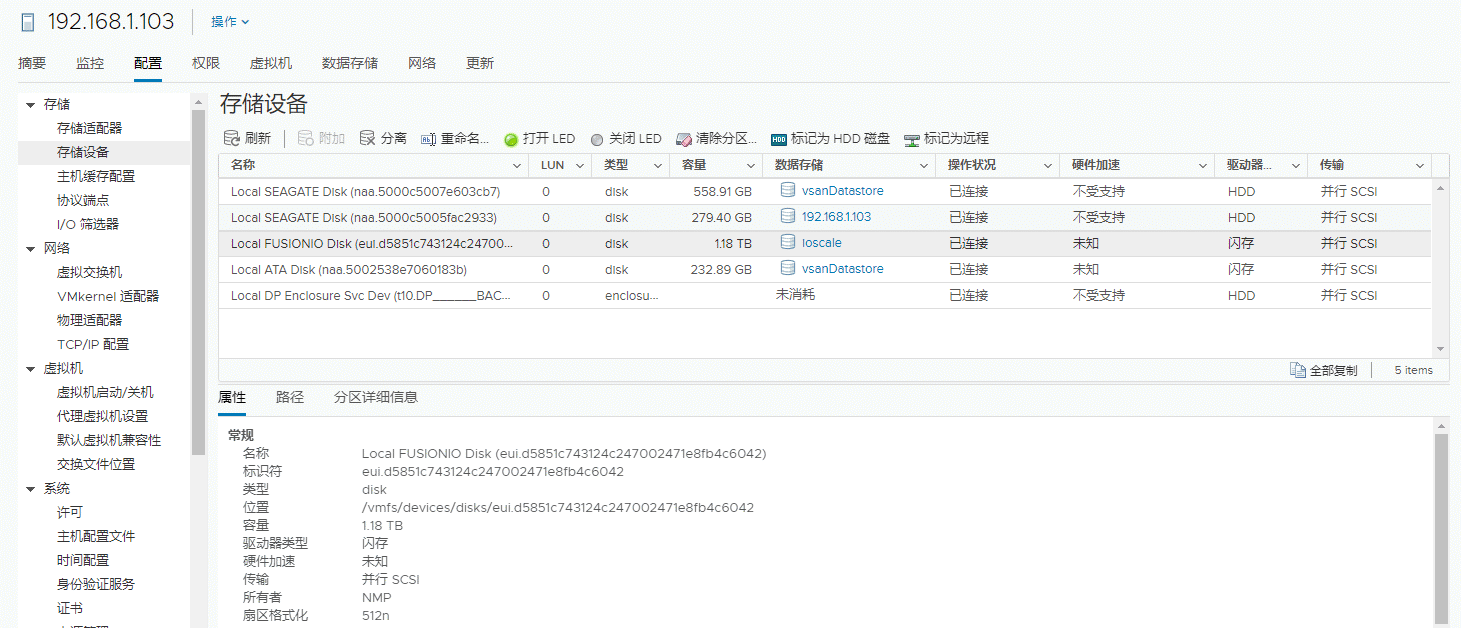
[root@localhost:~] esxcli software vib install -v /vmfs/volumes/192.168.1.103/ioscale/vib20/scsi-iomemory-vsl/SNDK_bootbank_scsi-iomemory-vsl_3.2.16.1731-1OEM.600.0.0.
2159203.vib
Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Reboot Required: true
VIBs Installed: SNDK_bootbank_scsi-iomemory-vsl_3.2.16.1731-1OEM.600.0.0.2159203
VIBs Removed:
VIBs Skipped:
[root@localhost:~]
现使用的fortigate防火墙软件版本有bug导致fortiview的流量分析经常报错,但因设备托管在机房不考虑到远程升级存在风险,所以还是考虑将防火墙日志通过syslog输出给日志平台进行分析处理。
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
因为现在只有1台fortigate防火墙的日志需要交给ELK处理,为方便测试学习,故将ELK组件安装在一台测试服务器上。
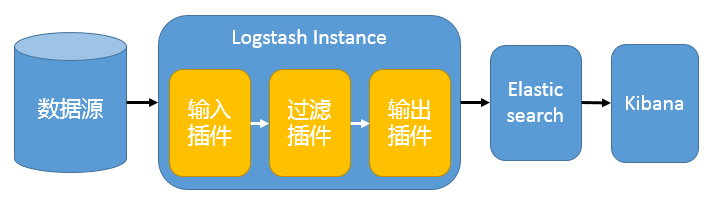
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
elasticsearch依赖Java开发环境支持,先安装JDK。
yum -y install java-1.8.0-openjdk
查看java安装情况
java -version
openjdk version "1.8.0_272"
OpenJDK Runtime Environment (build 1.8.0_272-b10)
OpenJDK 64-Bit Server VM (build 25.272-b10, mixed mode)
开始安装ElasticSearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.0.rpm
rpm -ivh elasticsearch-6.1.0.rpm #安装后自动创建elasticsearch用户及组
mkdir -p /home/es-data #es数据存放目录
mkdir -p /home/es-logs #es日志存放目录
chown -R elasticsearch:elasticsearch /home/es-data
chown -R elasticsearch:elasticsearch /home/es-logs
修改配置文件elasticsearch.yml
vim /etc/elasticsearch/elasticsearch.yml
修改如下内容:
#设置data存放的路径为/home/es-data
path.data: /home/es-data
#设置logs日志的路径为/home/es-logs
path.logs: /home/es-logs
#设置内存不使用交换分区
bootstrap.memory_lock: false
#配置了bootstrap.memory_lock为true时反而会引发9200不会被监听,原因不明
#设置允许所有ip可以连接该elasticsearch
network.host: 0.0.0.0
#开启监听的端口为9200
http.port: 9200
#增加新的参数,为了让elasticsearch-head插件可以访问es (5.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"
启动
systemctl start elasticsearch
查看状态
systemctl status elasticsearch
设置开机启动
systemctl enable elasticsearch
验证运行情况
[root@localhost ~]# curl -X GET http://localhost:9200
{
"name" : "ozNOtk_",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "KkWwJ4SeTu-e42sKa_nZwg",
"version" : {
"number" : "6.1.0",
"build_hash" : "c0c1ba0",
"build_date" : "2017-12-12T12:32:54.550Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
以上结果表示运行正常。
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.1.0.rpm
rpm -ivh logstash-6.1.0.rpm
mkdir -p /home/ls-data #创建ls数据存放目录
chown -R logstash:logstash /home/ls-data
mkdir -p /home/ls-logs #创建ls日志存放目录
chown -R logstash:logstash /home/ls-logs
创建测试配置文件
vim /etc/logstash/conf.d/syslog.conf #新增配置文件
input {
syslog {
type => "rsyslog"
port => "514"
}
}
output{
stdout{
codec => rubydebug
}
}
验证
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf #此时将设备syslog日志发送至ELK服务器,注意需要关闭系统防火墙或放行514端口
#正常情况下,会如下收到syslog日志
{
"@timestamp" => 2020-11-13T02:29:43.080Z,
"message" => "date=2020-11-13 time=10:29:43 devname=\"FG80D-OFFICE\" devid=\"FG080D3916000230\" logid=\"0000000013\" type=\"traffic\" subtype=\"forward\" level=\"notice\" vd=\"root\" eventtime=1605234583 srcip=192.168.1.5 srcname=\"Honor_Play-506a3bdd2b80af\" srcport=36584 srcintf=\"LAN\" srcintfrole=\"lan\" dstip=203.119.169.31 dstport=443 dstintf=port1 dstintfrole=\"undefined\" poluuid=\"55264c72-f728-51ea-f9c8-657401334c0c\" sessionid=2356948 proto=6 action=\"close\" policyid=1 policytype=\"policy\" service=\"HTTPS\" dstcountry=\"China\" srccountry=\"Reserved\" trandisp=\"snat\" transip=121.224.90.157 transport=36584 appid=47964 app=\"DingTalk\" appcat=\"Collaboration\" apprisk=\"elevated\" applist=\"default\" duration=782 sentbyte=5090 rcvdbyte=10772 sentpkt=48 rcvdpkt=39 utmaction=\"allow\" countapp=1 sentdelta=164 rcvddelta=84 devtype=\"Android Phone\" devcategory=\"Android Device\" osname=\"Android\" osversion=\"9\" mastersrcmac=\"00:be:3b:23:59:b6\" srcmac=\"00:be:3b:23:59:b6\" srcserver=0",
"priority" => 0,
"@version" => "1",
"type" => "rsyslog",
"severity" => 0,
"tags" => [
[0] "_grokparsefailure_sysloginput"
],
"facility" => 0,
"facility_label" => "kernel",
"host" => "121.224.90.157",
"severity_label" => "Emergency"
}
#如果收不到,请检查514端口占用情况
[root@localhost ~]# netstat -anp|grep 514
tcp6 0 0 :::514 :::* LISTEN 8623/java
udp 0 0 0.0.0.0:514 0.0.0.0:* 8623/java
创建配置正式配置文件
vim /etc/logstash/conf.d/syslog.conf #删除之前的所有配置内容
input {
syslog {
type => "syslog"
port => 514
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "syslog-%{+YYYY.MM.dd}" # 数据量不大的情况下索引数量不能配置太多,否则索引和分片过多会影响性能
}
}
#参考:https://jaminzhang.github.io/elk/Logstash-collect-syslog/
修改logstash的启动用户(因为syslog使用514端口,在linux中小于1000的端口需要以root身份运行才能开始侦听)
vim /etc/systemd/system/logstash.service
User=root
Group=root
#将user和group默认的logstash改为root
[root@localhost ~]# netstat -anp|grep 514
tcp6 0 0 :::514 :::* LISTEN 8745/java
udp 0 0 0.0.0.0:514 0.0.0.0:* 8745/java
#踩这个坑的时候,还找到个帖子说要修改/etc/logstash/startup.options,但实际看来只用修改以上logstash.service即可。
#参考1:https://my.oschina.net/u/4275236/blog/3354332
#参考2:https://www.123admin.com/logstash-do-not-bin-port-514/
配置文件测试
[root@localhost ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
Configuration OK
#关于WARNING: Could not find logstash.yml的解决方法
cd /usr/share/logstash
ln -s /etc/logstash ./config
[root@localhost logstash]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit
Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
Configuration OK
修改配置文件logstash.yml
vim /etc/logstash/logstash.yml
# 设置数据的存储路径为/home/ls-data
path.data: /home/ls-data
# 设置管道配置文件路径为/etc/logstash/conf.d
path.config: /etc/logstash/conf.d/*.conf
# 设置日志文件的存储路径为/home/ls-logs
path.logs: /home/ls-logs
启动
systemctl start logstash
查看状态
systemctl status logstash
设置开机启动
systemctl enable logstash
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.1.0-x86_64.rpm
rpm -ivh kibana-6.1.0-x86_64.rpm
rpm -ql kibana #默认安装目录/usr/share/kibana/
修改配置文件kibana.yml
vim /etc/kibana/kibana.yml
#kibana页面映射在5601端口
server.port: 5601
#允许所有ip访问5601端口
server.host: "0.0.0.0"
#elasticsearch所在的ip及监听的地址
elasticsearch.url: "http://localhost:9200"
启动
systemctl start kibana
查看状态
systemctl status kibana
设置开机启动
systemctl enable kibana
yum -y install epel-release
yum -y install nginx httpd-tools
cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak
vim /etc/nginx/nginx.conf
#将location配置部分,注释掉
#location / {
#}
创建kibana.conf
vim /etc/nginx/conf.d/kibana.conf
server {
listen 8000; #修改端口为8000
server_name kibana;
#auth_basic "Restricted Access";
#auth_basic_user_file /etc/nginx/kibana-user;
location / {
proxy_pass http://127.0.0.1:5601; #代理转发到kibana
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
重启nginx
systemctl restart nginx
到这一步,ELK基本配置完了,输入如下命令,启动服务
# 启动ELK和nginx
systemctl restart elasticsearch logstash kibana nginx
#查看ELK和nginx启动状态
systemctl status elasticsearch logstash kibana nginx
以上重点感谢参考:http://www.justdojava.com/2019/08/11/elk-install/
ElasticSearch Head现已有chrome插件版,安装比较方便,请参考:https://github.com/mobz/elasticsearch-head

太尼玛复杂了,我先慢慢研究
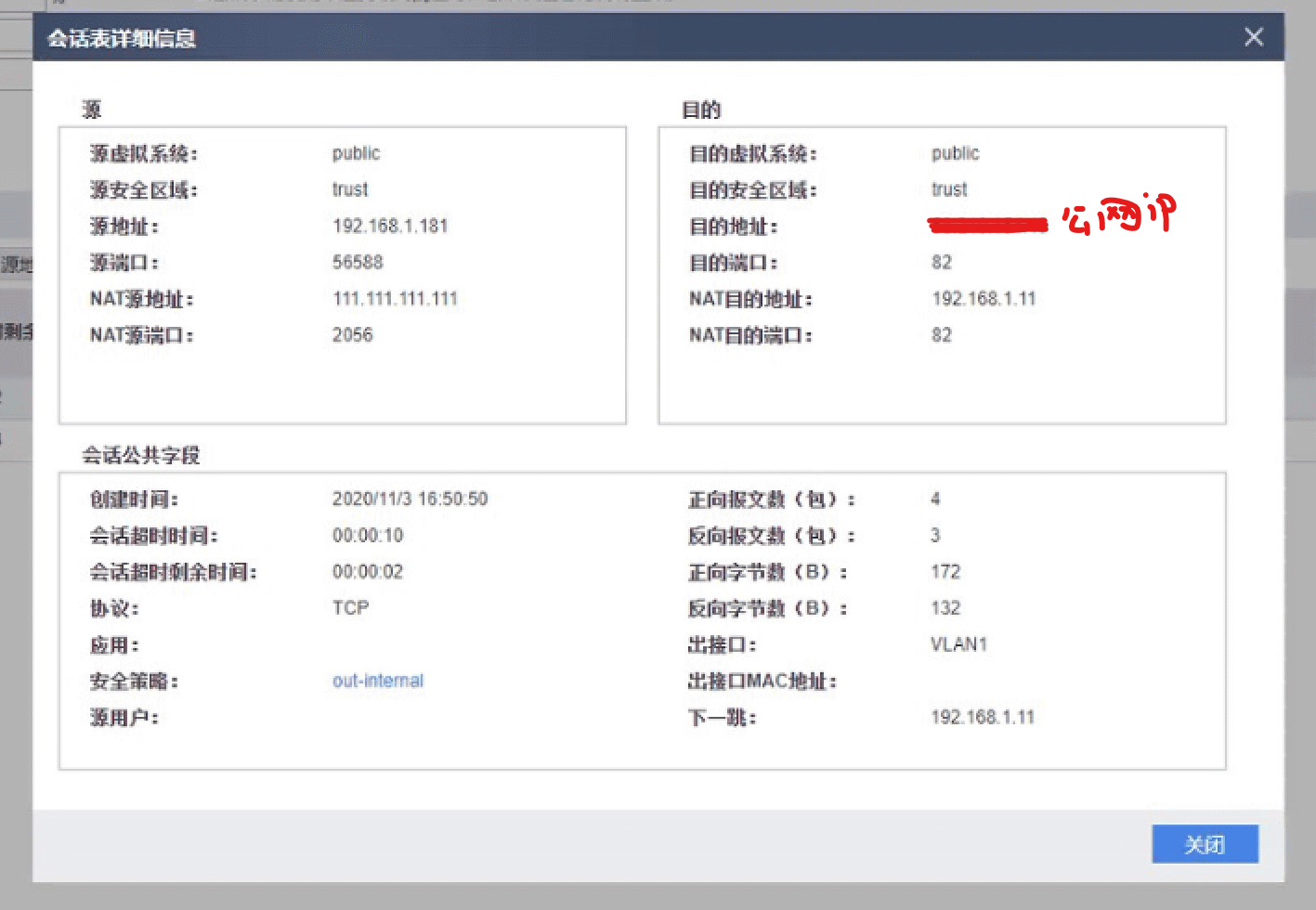
标题有点绕,问题就是在公网出接口上配置了内网某台服务器的端口映射,内网的普通用户通过内网地址访问正常,但无法通过公网IP进行正常访问,拓扑图如下:
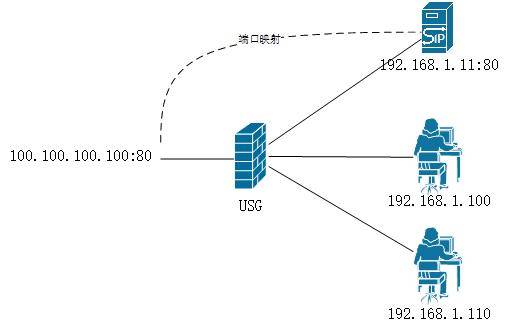
上图以出接口地址100.100.100.100:80映射为192.168.1.11:80为例,实际问题为192.168.1.100与192.168.1.110无法通过100.100.100.100:80进行访问,但通过互联网访问映射端口正常。
假设以192.168.1.100通过公网访问192.168.1.11:80的话,这里假设访问的源端口是10000,目标端口是80,主机发起web请求,那么访问目标就是100.100.100.100:80即数据包分析如下:
192.168.1.100:10000—>100.100.100.100:80
数据包最终会被路由到防火墙上,防火墙检查访问的目的地址,匹配到它的端口映射策略,将目标地址改为对192.168.1.11的访问,建立起一个针对目标ip地址转换的NAT会话表:
192.168.1.100:10000—>192.168.1.11:80
然后数据包到会被转发到192.168.1.11服务器上并会响应192.168.1.100主机的请求,将上述访问的源目ip地址及端口进行倒转,并将数据包交给它的网关处理,拓扑中即为USG防火墙:
192.168.1.11:80—>192.168.1.100:10000
网关发现目标ip地址是192.168.1.100,是在路由表中的内网直连地址,就会将数据包直接路由到主机上,主机接收到数据包,检查数据包的源ip和端口是192.168.1.11:80,发现其本身并没有这样一个http会话与之相匹配,就是说主机并没有主动发起对192.168.1.11:80的访问,实际发起的是对100.100.100.100:80的访问,那么主机就会丢弃这个数据包,导致内网用户通过域名或者公网ip地址访问自己的内网服务器不通的现象。
192.168.1.11:80—>192.168.1.100:10000
发生上述问题的原因,就是因为网关发现响应数据包的目的ip地址是内网一个可直接路由的地址,就会直接在内网进行路由转发。然而这并不是一个BUG,任何设备只要做了端口映射,都绕不开这个问题,因为TCP/IP协议栈就是这样工作的,有的设备在你做端口映射的时候,偷偷地把端口回流的问题也给你解决了。然而你也不要以为它们帮你做了端口回流,你就认为那些设备是好设备,感觉好高端,那你错了,我很少见企业级设备偷偷地帮你解决这个问题的(不是说没有,一般是应用层网络设备有这个),都是需要你主动去处理解决,这也体现了它们设备高度可定制性及专业性。
实际解决这个问题也很简单,即在192.168.1.100:10000访问192.168.1.11:80的时候,不走内网路由,再做一次回流的NAT映射即可。
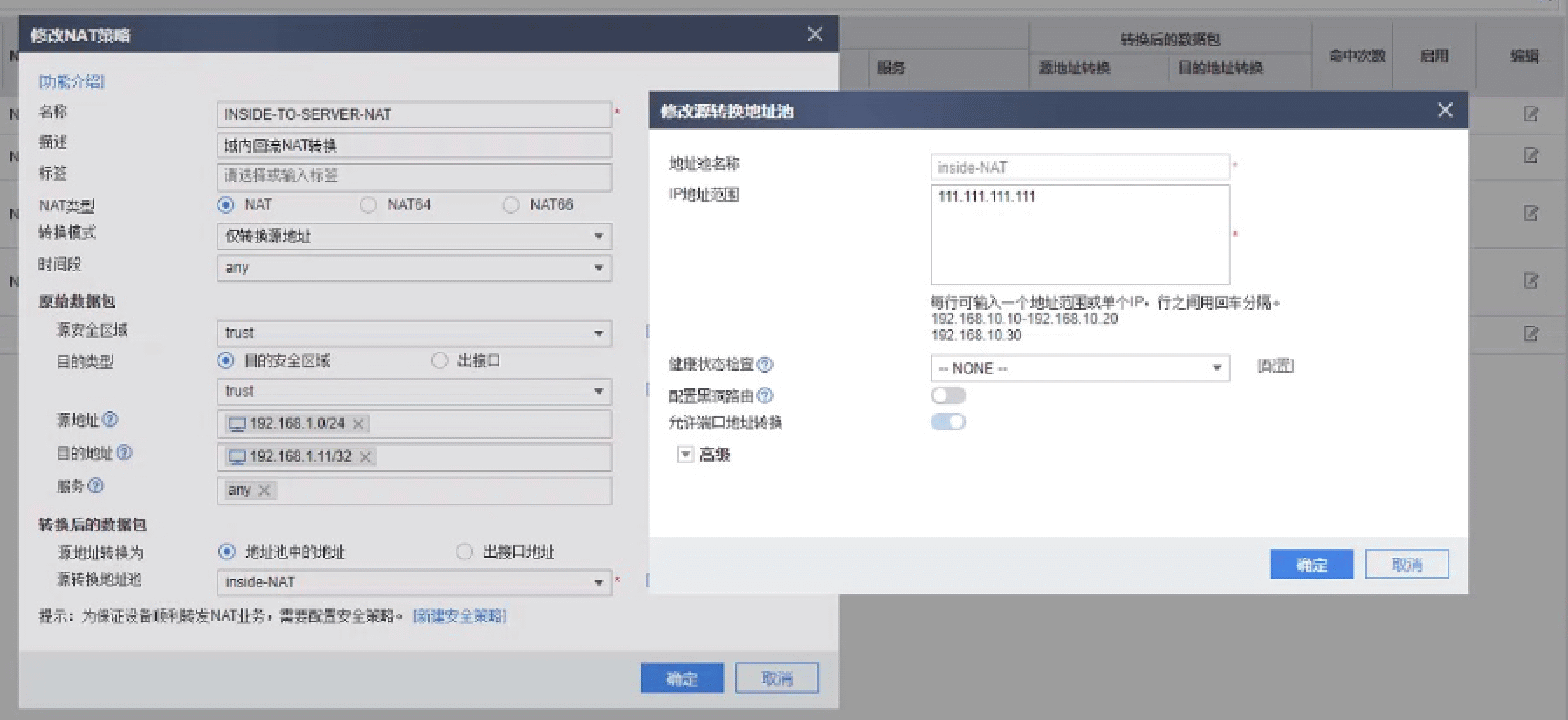
参考:
https://blog.51cto.com/11555417/2288036
http://www.360doc.com/content/18/0419/01/11935121_746788625.shtml
https://blog.csdn.net/weixin_30376509/article/details/97982837?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v28-1-97982837.nonecase&utm_term=%E9%98%B2%E7%81%AB%E5%A2%99%E5%81%9A%E5%9B%9E%E6%B5%81%E9%85%8D%E7%BD%AE&spm=1000.2123.3001.4430