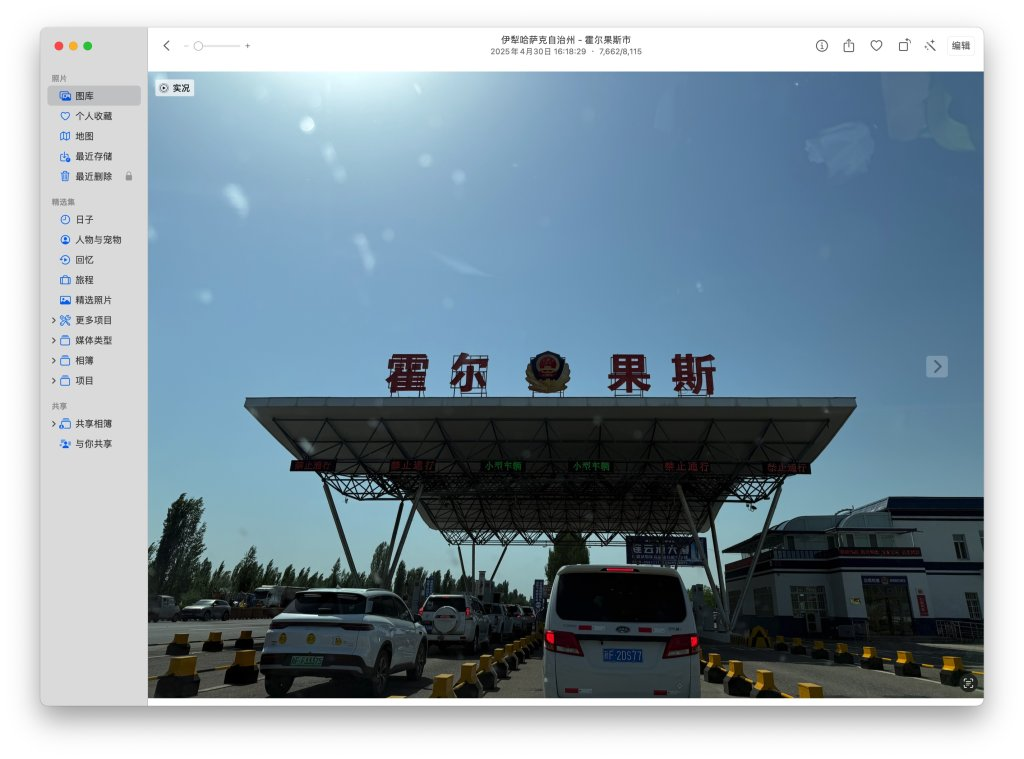
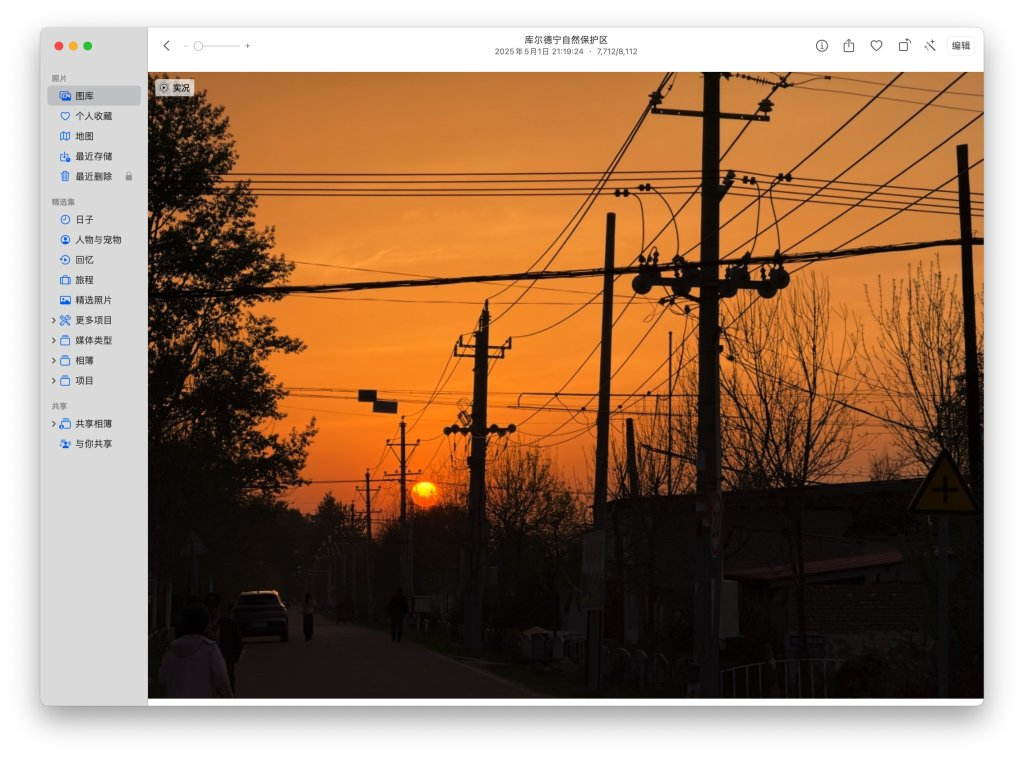
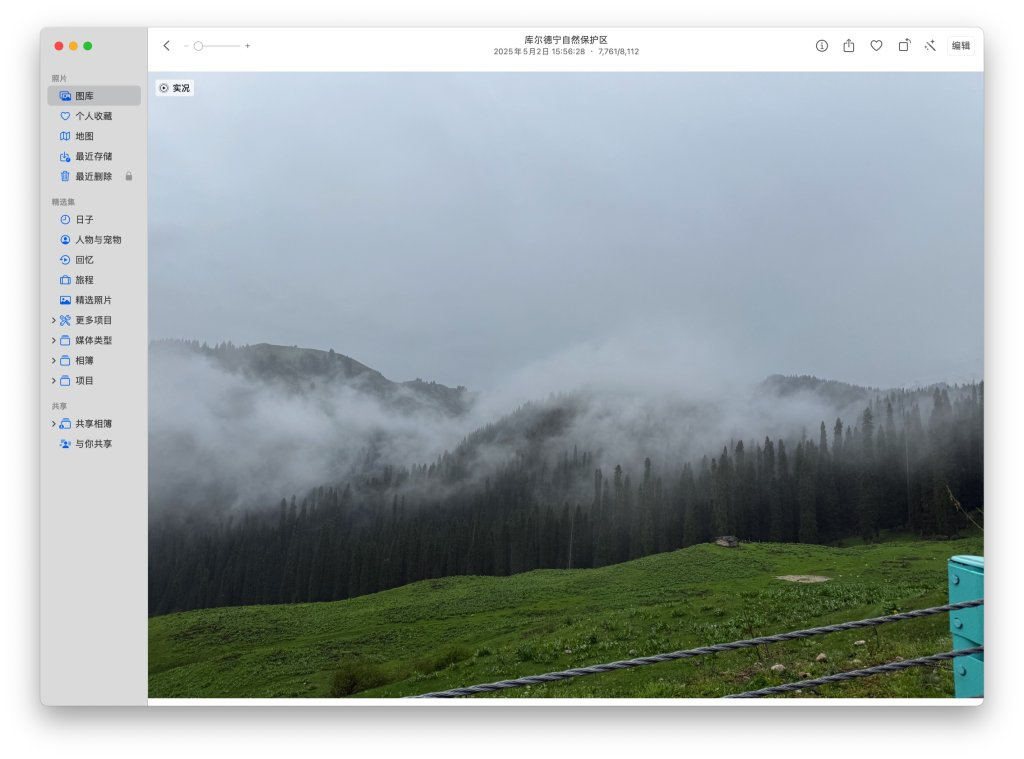
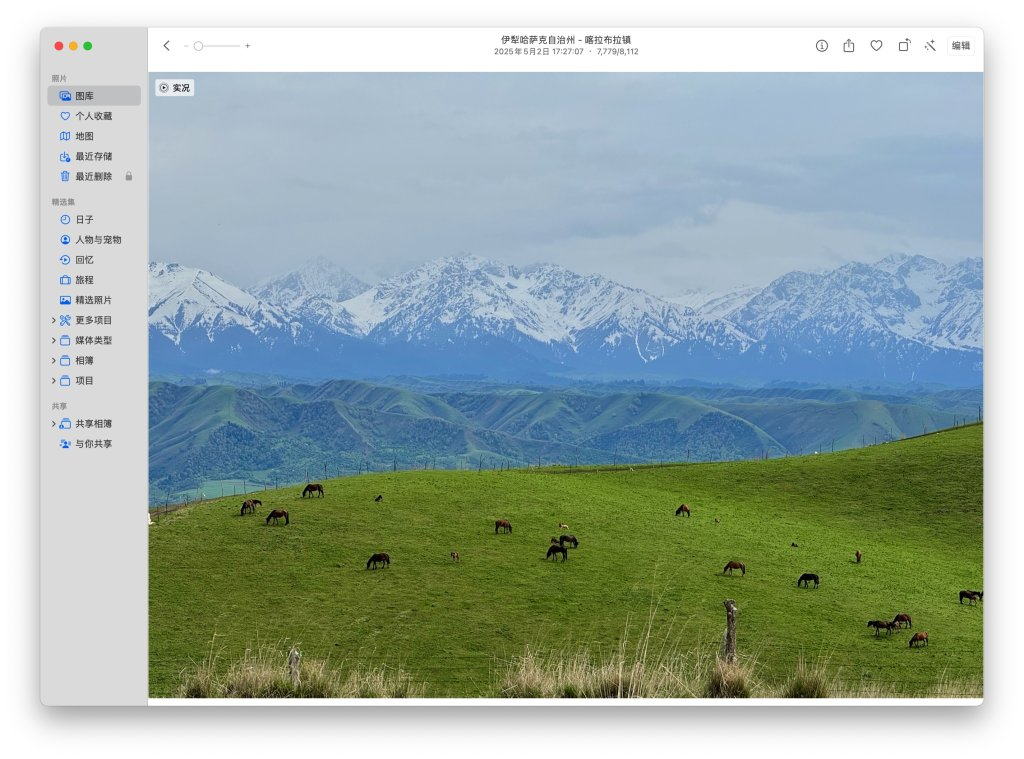
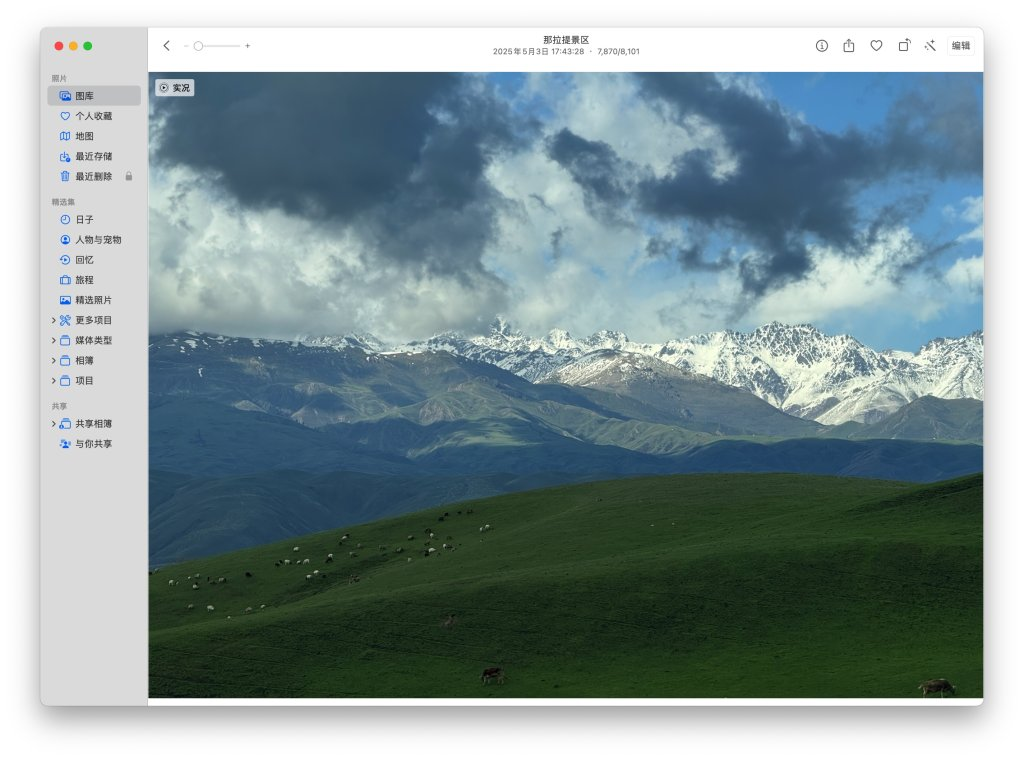
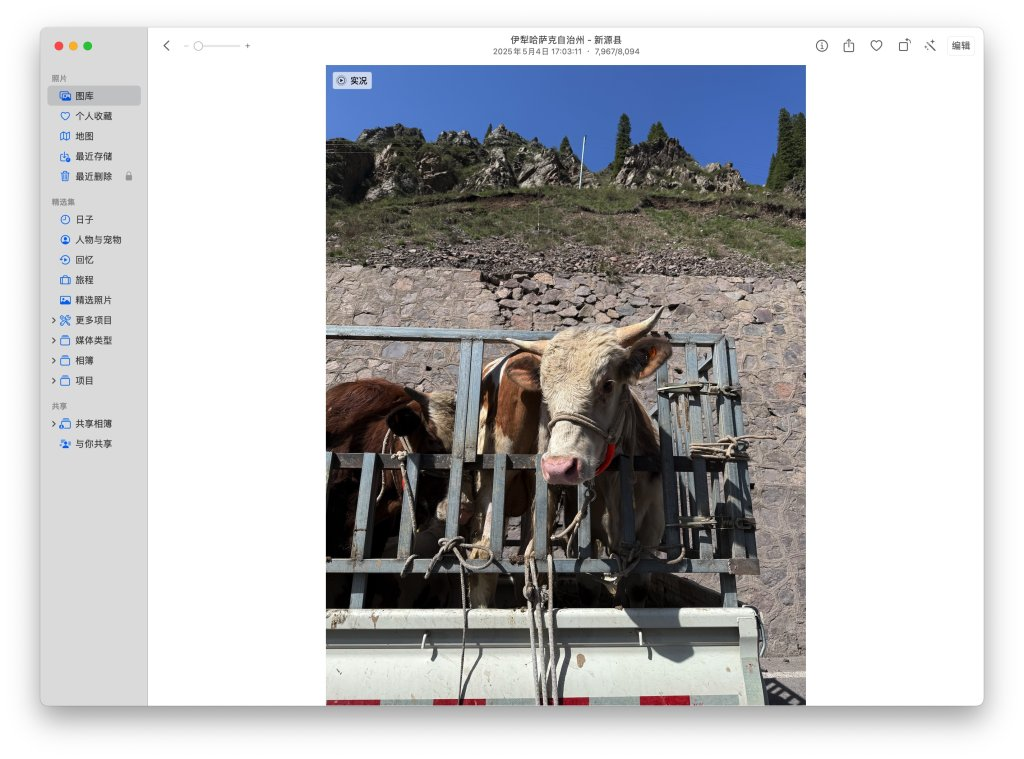
从巩乃斯前往和静县的路途中,会经过海拔3050米的艾肯达坂(也就是山口,垭口),这里的路况条件极差,一方面道路两侧的山上还有未消融的白雪覆盖,路面中则是坑坑洼洼的各种炮弹坑,我们驾驶的 SUV 虽然相对轿车有更好的通过性,但毕竟人生地不熟,看着旁边当地牌照本地人开的轿车飞来飞去,还有疯狂提速的卡车挂车,我们也只能按照安全的原则认真行驶,好歹路上蒋老师帮我盯着路况,一同的队友也给了充分的支持和信心,再加上全神贯注的驾驶,终于还是翻过了这一段艾肯达坂。
但好像也没有一个明确的算法和公式来衡量每个人在这里的 ROI 是否公平且合理,随着向上管理的风气和权责不一致的风气越来越严重,大家普遍也对老板们失去了信心,能够说服自己“受人之托忠人之事”也变成了我安慰自己为数不多的理由。当然这件事也并不能归因在某几个人或者某几个角色上吧,可能大家都有自己的难处和说服自己不去改变的理由?
可能是习惯性的敏感性格,我早在前两年就在说服自己尝试改变,尝试责任心别那么重,尝试在工作中不去那么主动,尝试在日常中少去发挥点自己的热心,但按照目前的结论来看,好像没成功,只是说服自己内心的感觉能够好受一点,为了避免找工作中出现太长的 GAP 我提前把自己的线上简历都修订更新了。
计算机的核心从 CPU 转向 GPU,上个时代依靠程序员写代码指挥 CPU 执行指令解决问题,构成了现在庞大的 IT 产业,程序员是中心。现在的时代逐渐转变,GPU 生产的 token 逐渐能解决越来越多的问题,能思考,能生成代码指挥 CPU 去执行解决问题,计算的核心一定会转向 GPU,世界对 GPU 的需求只会越来越高。
给 AI 分了四个阶段,Perception AI → Generative AI → Agentic AI → Physical AI,不是很认同,Agentic 和 Physical 都是 Generative AI 的延续,不过无所谓,可以看到 Agentic 这个概念实在是火爆。
Scaling Law 没有停止,Agentic AI 需要深度思考,深度思考有新的 Test-time Scaling Law,越多的 token 输出效果越好需,要多轮理解和工具调用对 token 的消耗更是指数级上涨。
Physical AI 要更好地理解现实世界,声音/视觉/触感,都会比纯文本思考对 token 消耗的诉求更高,像 2G 时代看文字新闻,3G 4G 图片,5G 视频一样。
多个 session 都在推广 NVidia 的 Video Search and Summarization Agent,串联从视频的获取→分割→VLM识别、CV物体识别和跟踪→数据处理存储和RAG召回→用户对话 整个流程,做到可以对视频提供实时分析和报警,也可以自然语言交互查询视频内容,边缘部署,适合用于监控,算是用 NVidia 技术栈做 AI 应用的一个标杆范例。
AIGC
关注了下视频 AIGC 相关的几个 Session
在好莱坞干了几十年的视觉效果的 Ed Ulbrich 开了个公司 Metaphysic,以前的电影特效制作成本巨大,对人的处理还很难跨过恐怖谷,而基于 AI 技术做特效,用完全不同的技术栈,效果好成本低,是一种颠覆。metaphysic 给娱乐行业提供人脸替换、数字人的服务,看起来是用的 GAN,在人物换脸技术上,GAN 还是更能做到稳定和实时,特别是实时这个点,基于 diffusion 很难做到。基于市场需求,利用已有的不同技术(甚至是上一代技术)深入解决问题,是有空间的。
但模型本身目前解决不了所有问题,还需要工程上的一些策略和串联做优化。例如 Tree of Thought 让任务不是以线性一步步执行的形式,而是生成解决问题的多个节点,多角度思考问题,形成树结构的任务,评估节点的价值,在里面寻找最优解。 Reflexion 会有 Evaluator 对各种反馈(工具调用结果/模型输出/用户指令)进行反思,梳理改进方向,也会把反思结果作为知识库经验,指导后续的任务。
熟悉我的朋友应该都知道,我在工作中时不时要参与到一些诸如客户支持,定价沟通,产品价值talking 的环节中,可能是这两年大家都把 AI 作为了“年度话题”的重要性,所以总会有一些客户想要进一步了解“产品如何在实际的业务流中快速集成 AI 的能力”,市面上也有各种各样吹嘘“自己的产品又一次集成了 AI”的 PR 文章,但本质上其实大都是在云市场集成 AI 之后快速实现了一个 chatbot,好像效果并没有那么好。
当然也有一些客户会来问一些在不同视角的问题,我听过的问题印象比较深的就是“产品集成了 AI 能力我是认可的,但是这个产品中我看不到 Deepseek 的露出,你们怎么处理”,“在产品中集成 LLM 其实各家都大差不差,但是差异性的效果我暂时还没有看到”,此外在一些类似的产品中我发现 C2C(Copy to china) 的思路目前可能还是奏效的,去 ProductHunt 或者类似的网站看看国外的“同行们”又搞出来了哪些 AI 相关的应用,然后看看哪一个最适合集成到自己的项目中,砍掉一些复杂功能再做一些本地化,好像给自己的产品也就搭上了 AI 这趟快车。
昨天和同事聊天的时候说到不同行业中的门槛其实还比较高,可能互联网行业的从业者大都掌握了无痛访问 Google 或者 Github 等网站的方式,但其实还有非常多的老百姓不太分得清其中的区别(事实上互联网从业者也不见得都掌握了这个能力),对于老百姓来说耳熟能详的张一鸣和王兴兴是那种“在某一个行业中实现了成功的例子”,但是对他们到底在做什么其实并不清楚,其实说到 AI,说到人工智能,这应该是一个伴随计算机有 N 多年历史的故事了。
但是 AI 到底是咋来的?好像前些年我们对 AI 的理解和认知还停留在 TensorFlow 和 Pytorch 这样的算法中,怎么一眨眼 AI 就已经飞入寻常百姓家了?
值得一提的是冯·诺伊曼从小就以过人的智力与记忆力而闻名。他在一生中发表了大约150篇论文,其中有60篇纯数学论文,20篇物理学以及60篇应用数学论文。他最后的作品是一个在医院未完成的手稿,后来以书名《计算机与人脑》(The Computer and the Brain)发布,表现了他生命最后时光的兴趣方向(但其实冯诺依曼不仅在计算机方向有建树,他也是博弈论之父)。
罗森布拉特,能否让计算机自己学习?
1958 年,弗兰克·罗森布拉特提出了一个让整个 AI 领域兴奋的想法——“感知机(Perceptron)”,它是一种最简单的神经网络,可以通过调整权重来学习模式,比如识别简单的形状。“创造具有人类特质的机器,一直是科幻小说里一个令人着迷的领域。但我们即将在现实中见证这种机器的诞生,这种机器不依赖人类的训练和控制,就能感知、识别和辨认出周边环境。”
然而,1969 年,闵斯基(Marvin Minsky)和派普特(Seymour Papert) 在《感知机(Perceptrons)》一书中证明,感知机无法解决像“异或”这样的基本问题,这让整个 AI 研究陷入了“AI 冬天”,神经网络被主流科学界抛弃。这本书抨击了罗森布拉特的工作,并本质上终结了感知机的命运。
1956 年,达特茅斯会议 上,一群科学家聚在一起,试图定义“人工智能” 这个领域。其中,闵斯基作为 MIT 人工智能实验室的创建者,是符号主义 AI 的坚定支持者。
他的梦想很宏大:“AI 应该像人一样思考,我们只要给它足够的逻辑规则,它就能成为真正的智能。” 他的研究主要基于符号逻辑,比如他开发了一种叫做 Lisp 机器 的计算机,专门用来运行 AI 代码。
与此同时,佩珀特则更加关注机器学习和儿童教育,他认为计算机应该像孩子一样学习,而不是依赖固有规则。他发明了一种编程语言——Logo,可以让孩子通过简单的指令控制“小乌龟”在屏幕上画图形。他们二位的 AI 研究,让 AI 在 1960 年代成为了学术界的明星,政府和企业纷纷投资,AI 似乎要迎来一个黄金时代!
但好景不长,感知机(Perceptron) 的失败让闵斯基和佩珀特觉得,神经网络完全没戏。他们在 1969 年合著了一本书——《Perceptrons》,直接指出了感知机的致命缺陷“感知机无法解决“异或(XOR)”问题——也就是说,它没办法学会“如果 A 和 B 相同,输出 0,否则输出 1” 这样的简单逻辑。”
他们的批评毁灭性地打击了神经网络研究,导致 1970 年代 AI 研究资金骤减,进入了第一次“AI 冬天”。
虽然闵斯基和佩珀特让神经网络陷入低谷,但他们的研究也推动了 AI 其他方向的发展。
闵斯基继续研究“心智架构”,提出了“框架理论”(Frame Theory)——AI 应该拥有类似人类的知识结构,而不是单纯的数据处理器。佩珀特专注于教育领域,创造了建构主义学习理论,他的 Logo 语言影响了后来的 Scratch 和 Python 在教育领域的应用。
直到 1980 年代,辛顿通过反向传播算法解决了感知机的问题,才让神经网络重新崛起。但讽刺的是,闵斯基并不认同深度学习,他仍然认为符号 AI 才是未来。
他提出了贝叶斯网络,用数学方式描述变量之间的因果联系,让 AI 具备更强的推理能力。后来,他又发展出因果推理和反事实思维,让 AI 不仅能预测,还能回答“如果情况不同,结果会怎样?”。这些理论如今影响着数据科学、医疗 AI、经济学,甚至推动下一代更智能的 AI 发展。
珀尔的因果推理思想,彻底改变了 AI 的研究方向。过去,AI 主要依赖深度学习,但神经网络的一个问题是它们只会发现模式,而不会理解因果。
比如传统 AI 可能发现:夏天卖冰淇淋的同时,游泳馆的溺水率也会上升。但因果 AI 知道:冰淇淋不会导致溺水,真正的原因是夏天气温升高。他的著作《为什么(The Book of Why)》深入探讨了因果推理的重要性,这为现代 AI 的解释能力奠定了基础。
杰弗里辛顿,如何训练深度神经网络?
1970 年代,神经网络研究遭遇寒冬。当时的主流 AI 研究者(如闵斯基和佩珀特)认为神经网络太简单,无法解决复杂问题。许多科学家纷纷放弃,但辛顿偏偏选择了这条“错误的道路”。
辛顿出生于英国,外祖父是著名数学家 George Boole(布尔代数的创始人),他从小就喜欢挑战权威。在攻读博士期间,他研究反向传播算法(Backpropagation),一种可以让神经网络自动调整权重的方法。尽管这个算法早已在 1970 年被提出,但几乎没人相信它真的能让 AI 学习。Hinton 和他的团队坚持优化反向传播,并在 1986 年成功证明它可以让多层神经网络高效学习复杂任务。
这种“对抗学习”的方式,突破了传统 AI 生成方法的局限,被命名为 GAN(Generative Adversarial Network)。
GAN 让 AI 从“分析数据”变成了“创造数据”,彻底改变了 AI 在艺术、设计、游戏、影视等行业的应用方式。可以说,他的研究让 AI 从理解世界进化到了创造世界,并成为 AI 生成内容(AIGC)浪潮的奠基者之一。
古德费洛不仅是GAN 之父,也是AI 伦理的重要倡导者,他的贡献将长期影响 AI 发展方向。
达里奥,AI 能否像人类一样写作和推理?
达里奥是 AI 研究领域的重要人物之一,曾在 OpenAI 领导多个关键项目,后创办 Anthropic,专注于 AI 安全与“AI 对齐”研究。他的工作推动了 AI 模型能力的飞跃,同时也让 AI 伦理问题进入公众视野。
达里奥最初是一名神经科学家,研究大脑与神经网络的相似性。他后来转向机器学习,加入 OpenAI,成为 AI 研究的核心人物之一。他在 OpenAI 期间的关键贡献包括:GPT-2 与 GPT-3 研究负责人:推动了现代大语言模型(LLM)的发展。AI 对齐研究的先驱:他提出 AI 需要“对齐人类价值观”,否则可能失控。
2021 年,达里奥离开 OpenAI,与几位前同事共同创立 Anthropic,专注于 AI 安全和“可控 AI”研究。Anthropic 的核心产品 Claude 系列(类似 ChatGPT)强调安全性,避免 AI 生成危险内容。他的研究强调:“AI 必须对人类有益,否则超级智能可能带来无法预测的后果。”
Anthropic 目前是 OpenAI 的主要竞争对手之一,并获得了 Google 近 30 亿美元的投资。
当然,说到达里奥我们其实也需要提到 Tom B Brown 和 Alec Radford,他们一行三个人的研究共同塑造了现代 AI 发展路径。但我想他们从 OpenA I跳槽到 Anthropic 也许还是遇到了那个难以抉择的问题“是追求更强大的 AI,还是追求更安全的 AI”?
但如果我们回到 2025 年的当下,会发现 AI 的发展已经度过了“通用智能”的探索阶段,下一步可能还是要对准通用人工智能的方向进行进一步的细化和延伸。由于各类基于 Claude 3.7 的产品我们已经基本跳过了“AI 行不行”的疑惑,但到底“如何让他更安全,更有效”还是一个短期内我们看不到答案的问题。
前一段时间木遥的解读“vibe coding”在朋友圈和各种渠道刷屏,文章中那句“一方面它犹如神助,让你有一种第一次挥舞魔杖的幻觉。另一方面它写了新的忘了旧的,不断重构又原地打转,好像永远在解决问题但永远创造出更多新的问题,并且面对 bug 采取一种振振有词地姿态对你 gaslighting。你面对着层出不穷的工具甚至不知道自己该认真考虑哪个,心知肚明可能下个月就又有了新的「最佳实践」,养成任何肌肉记忆都是一种浪费,而所谓新的最佳实践只不过是用更快的速度产出更隐蔽的 bug 而已。”可能也是许多正在与 AI 结对编程朋友的真实感觉。
但我想,AI 带来的改变确实日新月异,我能看到身边的朋友能够逐渐完成“不相信 AI → 怀疑 AI → 全部用 AI → 不敢信任 AI → 再一次信任 AI”的无限循环之中。我在一些业余时间也尝试练手用 AI 帮我写了几个产品,相比原先的产品设计与研发过程中,会发现现在的 AI 可能每一次都会比前一段时间的使用更加流畅一些,但依然无法完全避免上下文遇到限制导致记忆力幻觉或者相关的问题,这种感觉好像就像是一种慢性毒药,一方面更爽了,另一方面又不是那么爽。在产品设计过程中各种刷屏的什么“用 AI 搞定原型图,搞定高保真效果图”的论据其实也能变相让我们感知到 AI 在具体业务中的应用其实还处在比较早期的阶段。
一方面我受益于使用 AI 能够极大程度加快我把脑海中的某些想法付诸于实践的过程,但另一方面好像也能明显感知到过拟合带来的某种不适感,在开启新项目的时候确实能够通过 AI 极大程度加快效率,但是否会因为过度信任 AI 而导致代码中潜藏了许多暂时没有精力与时间发现的 bug,又变成代码中一个潜藏的问题真的很难一两句话讲清楚。
如果对比我前端时间那篇《AI 取代人工进展走到哪一步了?》,当下的我结论还是那句“保持对前沿技术学习与了解,让自己不要落伍的概念是没问题的,用 AI 来输出一下自己无处安放的创造力或者做一些创新与变化的真实落地是很好的”,但 AI 改变世界的进度条到哪一步了?