我已经养成每天使用 AI 的习惯,甚至已经很少再使用 Google 搜索。遇到问题,第一反应是直接问 ChatGPT,不仅快,还能一步到位解决问题。
Vibe Coding:AI 驱动的编程方式
Vibe Coding 这个概念今年特别火,核心思想是“用氛围编码”。也就是说,程序员不再执着于每一行代码的细节,而是通过自然语言描述需求,让 AI 来实现代码的生成、重构与调试。
Andrej Karpathy (2025)
TLDR;Vibe 编码是一种新兴的软件构建实践,它用简单的语言描述你想要的内容 – 然后让 AI 处理代码和测试。
TLDR; Vibe coding is the emerging practice of building software by describing what you want in plain language – and letting AI handle the code and test.
只能怀疑是驱动问题了,毕竟 GTX1080 这个老显卡是诞生得比挖矿潮还早。但没有办法了,我之前把系统升级后(从 Linux Mint 20.3升级到 Linux Mint 22.1,基于Ubuntu20.04到Ubuntu24.04),驱动版本还是550,CUDA也只是从12.2升级到了12.4而已,而最新版本貌似是12.8。我也不清楚到底是 GTX1080 只能装这么高,还是有什么其他限制。Nvidia 官网倒是有一个 575版本,Linux Mint官方没说正式支持,我也不想试。毕竟即使跑 comfyui 的默认模型,显卡的噪音都超大,温度直达 70 度以上(风扇57%转速,再提高那噪音就真的难以忍受了),而仍然要等很久才能出一张图。
定制化配置:根据你的具体需求,对 Monitor Pro 进行定制化配置。例如,可以选择监控特定的资源,从而更有效地管理和优化资源使用。
This message is used to verify that this feed (feedId:42331815237783574) belongs to me (userId:55156152962822144). Join me in enjoying the next generation information browser https://follow.is.
真正的现代计算机要等到1945年ENIAC的诞生。约翰·毛克利和赫尔曼·戈德斯坦设计了ENIAC,意为“电子数值积分计算机”(Electronic Numerical Integrator and Computer),而后,他们又根据冯·诺依曼提出的设想设计了世界第一台冯·诺依曼结构计算机EDVAC。EDVAC是ENIAC的继承者,建立了现代计算机的标准:它采用了二进制,并且设计了存储程序,也就是说计算机指令将被存储在存储器中。这种设计思想也将软件与硬件分离,成为独立的存在。
当时微软公司刚刚成立,他们开发的BASIC编译程序被拷贝走了,并在“家酿计算机俱乐部”的黑客群体中流传。这一行为激怒了当时年仅二十岁的比尔·盖茨,1976年,他发表了一封名为《致电脑爱好者的一封信》(An Open Letter to Hobbyists)的公开信,他在信中痛斥自由拷贝软件的行为,说:“硬件必须付钱购买,但软件却被免费共享了。谁会在意为软件辛苦工作的人是否获得了合理报酬呢?”这封信在黑客群体掀起轩然大波,并且在以后的自由软件和开源软件社区中一直被当作反面案例来宣传。但必须承认的是,比尔·盖茨看到了软件的巨大商业价值,也正是他的这一先于时代的洞见,让他引领微软成为世界第一的软件提供商,而他本人也因此获得巨大商业回报成为世界首富。
Linux的诞生源于大学时代林纳斯·托瓦兹(Linus Torvalds)暑期的个人项目,他大学放假期间在家无聊,就写了Linux并发布到了互联网新闻组,没想到在黑客圈里广受欢迎,托瓦兹将它无偿开放出来,并广泛接纳社区开发者的代码提交。到了2005年,估计有近一万人给Linux贡献过代码,Linux也成了开源社区最大的项目。Linux项目代表了软件工程的另外一种模式,它没有企业项目那种自上而下的管理,通过互联网分布式协作来实现大型软件项目开发并管控质量。托瓦兹有句名言:“只要眼睛多,Bug容易捉。”(Given enough eyeballs, all bugs are shallow.)
七 万维网及敏捷软件开发
1990年,英国计算机科学家蒂姆·伯纳斯-李(Tim Berners-Lee)和他的工作伙伴罗伯特·卡里奥合作制定了一份计划书《万维网:一个超文本项目的计划书》(World Wide Web: Proposal for a Hyper Text Project),这个名叫万维网(World Wide Web, WWW)的系统将彻底改变计算机行业。互联网(Internet)可以追溯到上世纪六十年代的ARPANET,但一直到了万维网的出现才让它真正成为全球互联网。万维网可以理解为是互联网上的全球信息系统,很多人在概念里其实是将万维网与互联网等同了。在伯纳斯-李的设想中,万维网具备三项技术:全球唯一的统一资源标志符(Uniform Resource Locator, URL),超文本标记语言(HTML)和超文本传输协议(HTTP)。该年年底,伯纳斯-李在他的工作电脑上开发了第一个网页浏览器,实现了HTML解析和HTTP传输,值得一提的是,伯纳斯-李所使用的工作电脑正是乔布斯被赶出苹果后创办的新公司所生产的NeXT电脑。
万维网的疾速发展使得互联网软件开发呈井喷之态,大量的互联网企业需要快速开发并上线软件应用,并且要根据用户的反馈及时修改以应对需求变化。这种变化使得传统的瀑布开发模式无法满足企业需求,一种新的开发模式应运而生。2001年,十七位软件开发人员在美国犹他州雪鸟滑雪地组织了一场会面,他们中有很多是软件工程大师,包括写作《重构》的马丁·福勒(Martin Fowler)。会上,他们发表了“敏捷软件开发宣言”(Manifesto for agile software development),这其中主要是四句话:“个体和交互胜过流程和工具,可以工作的软件胜过详尽的文档,客户合作胜过合同谈判,响应变化胜过遵循计划。”敏捷软件开发鼓励快速响应变化、迭代开发与变更,它包含了一系列实践,如Scrum、极限编程等。
八 云计算与DevOps
2003年,在亚马逊工作的安迪·杰西(Andy Jassy)发现在亚马逊孵化新业务的过程中,工程师总要把大量时间投入在重复的基础设施构建工作上。他敏锐地察觉到了这一内部机会,并给亚马逊创始人兼CEO贝索斯写了一份商业计划书,在该计划书中构想了亚马逊AWS(Amazon Web Services)云的未来。安迪·杰西带着一个小团队开启了内部创业之旅,2006年发布了云服务S3和EC2。AWS在亚马逊内部的重要性越来越高,2023年利润占亚马逊整个利润的一半多。安迪·杰西一直担任AWS CEO职位,一直到2021年接替贝索斯成为亚马逊CEO. 虽然说云计算这个词在上世纪末就已出现,但AWS是真正将云计算商业化成功的第一个产品。AWS的成功也让众多互联网头部厂商看到机会,谷歌云、微软Azure云等紧追不舍。云计算成为了互联网软件乃至整个IT软件的底座。
云计算的本质是资源弹性,云服务厂商将一个个计算资源连接起来构成一个巨大的资源池,而软件用户只需要租用计算资源,根据业务需要弹性扩缩容。支撑资源弹性的是软件的架构弹性,这种架构模式就是微服务。微服务架构是将庞大的单体结构程序拆分成松耦合的独立组件,以API方式调用,这种架构解耦可以追溯到GoF的《设计模式》和Robert C. Martin的《敏捷软件开发》。另外,GitHub的出现让开源软件更容易流传,开源组件成为构筑现代软件的基本模块,开发软件像是搭积木一样,通过胶水语言将开源组件组装,便可以快速构建业务软件,这种开发模式极大地提升了开发效率。加上云平台提供的软件应用部署能力,从软件开发到部署发布及运维,可以快速在云平台上闭环。这种软件开发模式也被称为云化软件开发。
云化软件开发的工程实践是DevOps,它强调的是开发与运维之间的沟通协作以及更小粒度地发布和更频繁地变更,可以理解为是敏捷软件开发的延伸。Git、依赖包管理、docker、CI/CD等现代化开发工具成为DevOps工程实践的核心:Git的分布式开发方法和版本管理践行软件项目的“Everything as Code”的理念,如基础设施代码化(IaC)、配置代码化、流水线代码化等,团队各角色基于代码协作。诸如Ruby Bundler、Maven、NPM等语言依赖包管理工具使得组件化开发更简单,特别是对于开源组件的引用,一个Node.js工程项目,引用几百甚至上千个开源组件是非常常见的现象,因此网上也有关于NPM依赖黑洞的段子。而Docker、K8s等容器工具降低了微服务开发的门槛,结合CI/CD工具自动化部署,降低运维成本。小结一下,DevOps云化软件开发工程工具实践的几个关键词是代码化、组件化/开源、容器化、自动化,其本质是为了更频繁地变更(发布新特性和修复问题),缩短交付周期。
九 大模型时代的软件工程
前文提到,埃达·洛夫莱斯认为电脑不能思考,只会根据指令执行。一个世纪以后,图灵将她的主张写到自己的论文里,称为“洛夫莱斯夫人的异议”。这篇论文便是著名的人工智能奠基论文《计算机器与智能》(Computing Machinery and Intelligence),他在文中还提出了一个被后人称为“图灵测试”(Turing Test)的思想实验,在这个测试中,测试人与人和机器同时用文字交流,但他不知道背后谁是人或机器,如果在一段交流时间内无法通过交流内容来判断区分人和机器,那么就认为该机器通过了图灵测试,也就是说该机器具备与人类相当的智能。一个冷知识是:我们上网时经常被要求输入验证码的英文单词“Captcha”即是“完全自动通过图灵测试来区分计算机或人类”(Completely Automated Public Turing test to tell Computers and Humans Apart)的首字母缩写。图灵自己将此实验称为“模仿游戏”(The Imitation Game),关于他的传记和电影名称则取之于此。
历史上对人工智能的研究主要分成了两大阵营,一派推崇知识和推理逻辑,典型的如专家系统,被称为符号主义,也有称之为“GOFAI”(Good old fashioned artificial intelligence),这一派的发展如该词所言已经是old-fashioned了。还有一派通过模拟人类的大脑构建神经网络,将知识通过机器学习存储在大量的连接中,基于数据学习来发展人工智能,被称为连接主义,这一派的代表是神经网络系统。杰弗里·辛顿(Geoffrey Hinton)在神经网络领域潜心研究三十多年,开创了深度学习这一人工智能分支,而基于深度学习的大模型在近年来发展迅速,尤其在OpenAI的ChatGPT发布后成为全球最热门的技术。ChatGPT让人们看到了AGI(通用人工智能)的可能,它的AIGC能力可以帮助到人们将AI运用在实际的工作和生活中。关于神经网络和深度学习的历史和原理可以参见我的另外一篇文章《从神经网络到 Hugging Face》,这里我想就使用ChatGPT来辅助编码的案例实践来谈一谈我对大模型时代的软件工程的理解。
你可以通过运行Next.js应用来查看效果:在你的项目目录中,使用npm run dev(或者如果你使用Yarn的话,就是yarn dev),然后在浏览器中访问对应的页面(通常是http://localhost:3000/showText,取决于你的文件名和配置)。点击按钮后,你应该能在页面上看到指定的文本显示出来。
编辑器提示报错 “Property ‘forEach’ does not exist on type ‘string | string[]’.
Property ‘forEach’ does not exist on type ‘string’.”
让我惊讶的是ChatGPT非常自信的认为代码没有问题,而是给了我其他的debug思路:
这个错误表明TypeScript编译器不能确定textSegments变量在调用forEach方法时是一个数组。在你提供的上下文中,textSegments被明确声明为一个字符串数组(string[]),所以正常情况下不应该出现这个错误。错误信息“Property ‘forEach’ does not exist on type ‘string
string[]’. Property ‘forEach’ does not exist on type ‘string’.”暗示在某处textSegments可能被推断为string | string[]类型,即它可能是一个字符串或字符串数组。
另外报错: Argument of type ‘(prev: never[]) => string[]’ is not assignable to parameter of type ‘SetStateAction<never[]>’.
Type ‘(prev: never[]) => string[]’ is not assignable to type ‘(prevState: never[]) => never[]’.
Type ‘string[]’ is not assignable to type ‘never[]’.
Type ‘string’ is not assignable to type ‘never’.
在写作本文时,我正巧看到GitHub CEO Thomas Dohmke前不久在TED上发表的演讲,名为With AI, Anyone Can Be a Coder Now。他预测到2030年,GitHub上的软件开发者将从目前的1亿增加到超过10亿,也就是说全球超过10%的人都能够编写软件。因为在像GitHub Copilot这种大模型应用的帮助下,编写软件将变得像骑自行车一样容易。主持人问:既然AI这么强而且还在加速增强,那人类还需要参与软件开发其中吗?Thomas的回答是:这就是为什么我们给产品起名为“Copilot”(副驾驶员)的原因,因为还需要“Pilot”(驾驶员)。我们需要有创造力的Pilot决定做什么。
# Use a smaller base imageARG NODE_VERSION=node:20-alpine# Stage 1: Build dependenciesFROM $NODE_VERSION AS dependency-base# Create app directoryWORKDIR /app# Install pnpmRUN npm install -g pnpm# Copy the package filesCOPY package.json pnpm-lock.yaml ./# Install dependencies using pnpmRUN pnpm install --frozen-lockfile# Stage 2: Build the applicationFROM dependency-base AS production-base# Copy the source codeCOPY . .# Build the applicationRUN pnpm run build# Stage 3: Production imageFROM $NODE_VERSION AS production# Copy built assets from previous stageCOPY --from=production-base /app/.output /app/.output# Define environment variablesENV NUXT_HOST=0.0.0.0 \ NUXT_APP_VERSION=latest \ DATABASE_URL=file:./db.sqlite \ NODE_ENV=production# Set the working directoryWORKDIR /appEXPOSE 3000# Start the appCMD ["node", "/app/.output/server/index.mjs"]
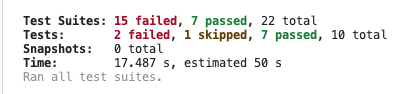
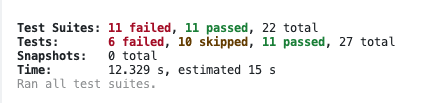
TestsuitefailedtorunJestencounteredanunexpectedtokenJestfailedtoparseafile.Thishappense.g.whenyourcodeoritsdependenciesusenon-standardJavaScriptsyntax,orwhenJestisnotconfiguredtosupportsuchsyntax.OutoftheboxJestsupportsBabel,whichwillbeusedtotransformyourfilesintovalidJSbasedonyourBabelconfiguration.Bydefault"node_modules"folderisignoredbytransformers.Here's what you can do: • If you are trying to use ECMAScript Modules, see https://jestjs.io/docs/ecmascript-modules for how to enable it. • If you are trying to use TypeScript, see https://jestjs.io/docs/getting-started#using-typescript • To have some of your "node_modules" files transformed, you can specify a custom "transformIgnorePatterns" in your config. • If you need a custom transformation specify a "transform" option in your config. • If you simply want to mock your non-JS modules (e.g. binary assets) you can stub them out with the "moduleNameMapper" config option.You'llfindmoredetailsandexamplesoftheseconfigoptionsinthedocs:https://jestjs.io/docs/configurationForinformationaboutcustomtransformations,see:https://jestjs.io/docs/code-transformation
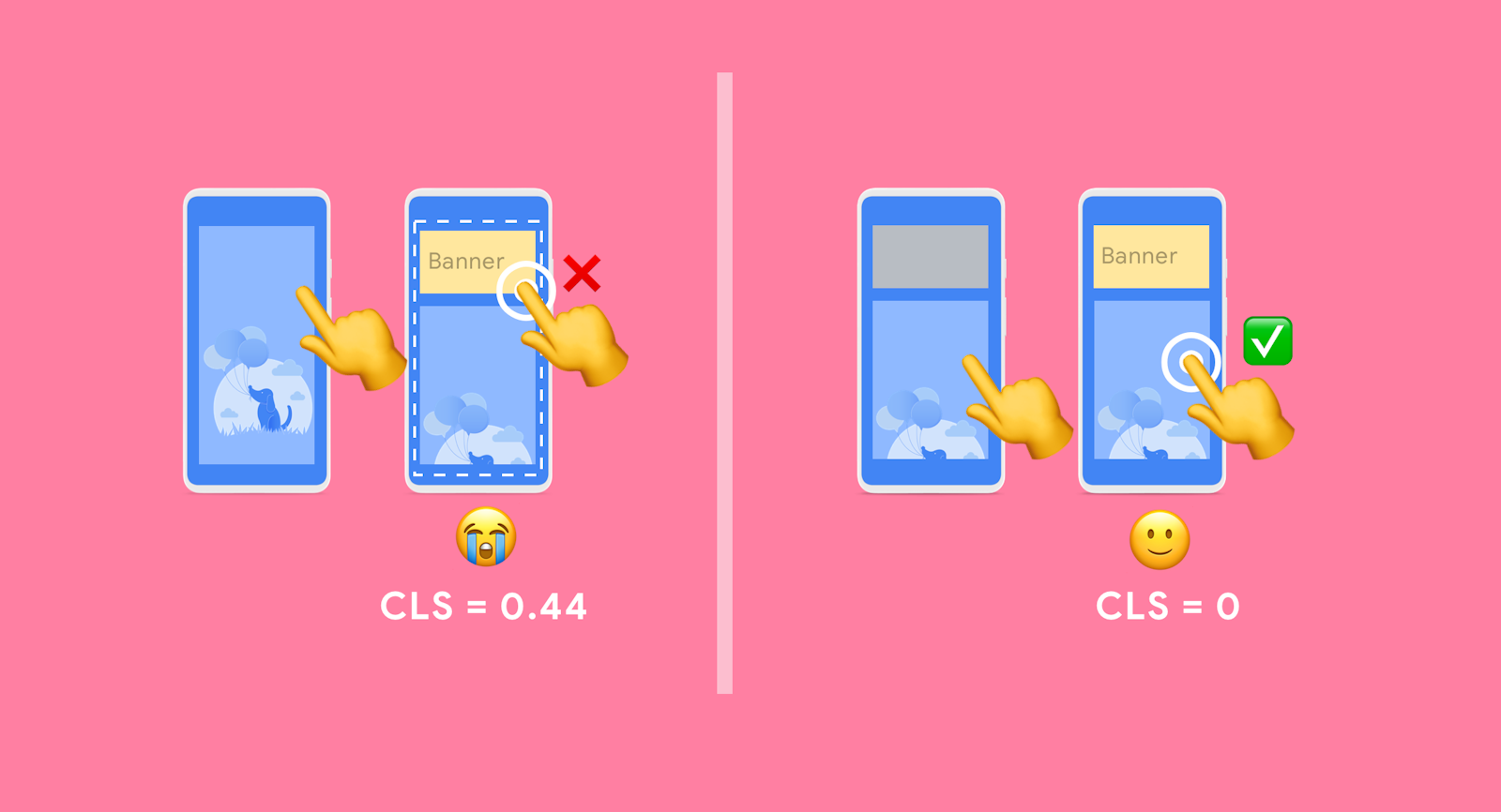
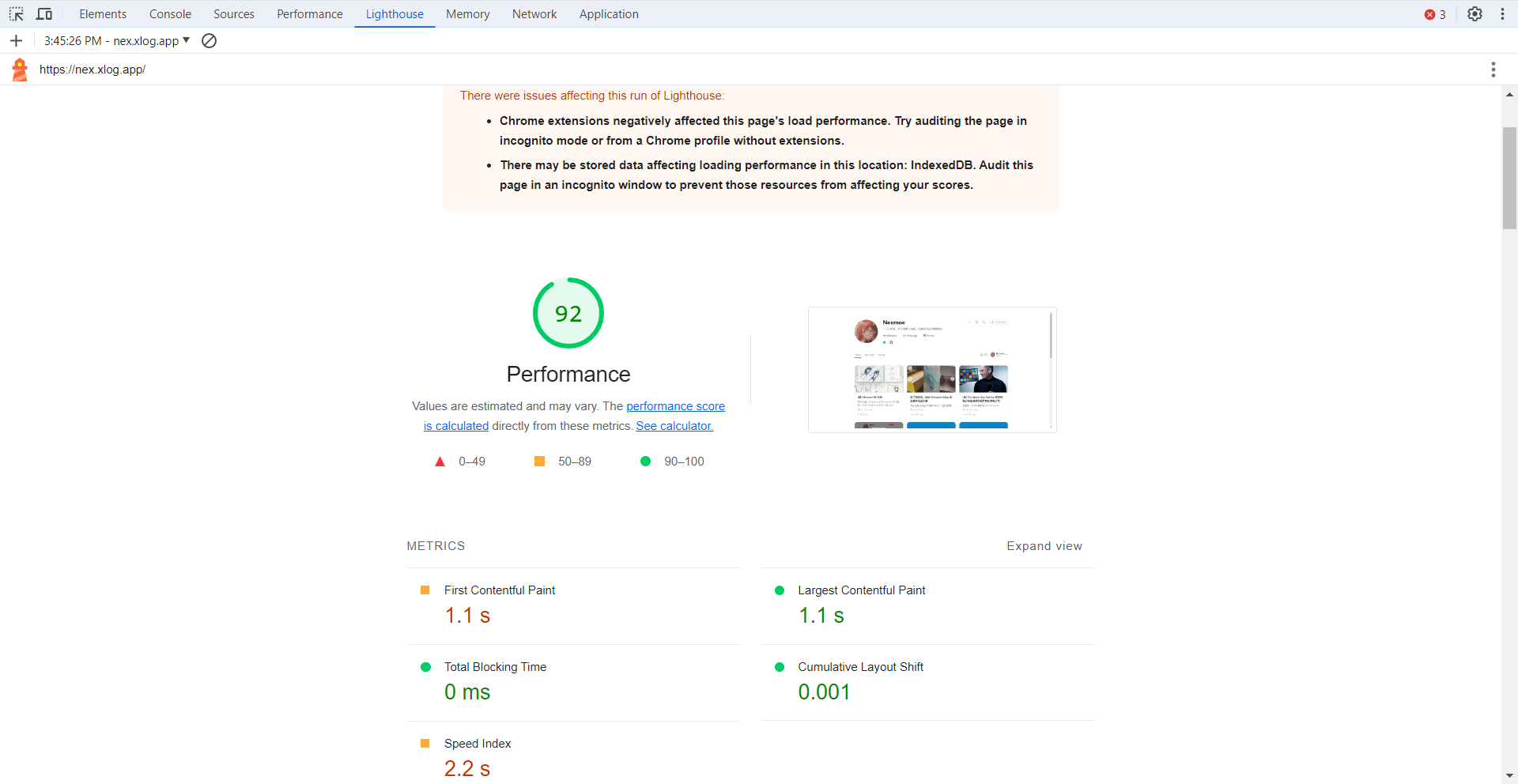
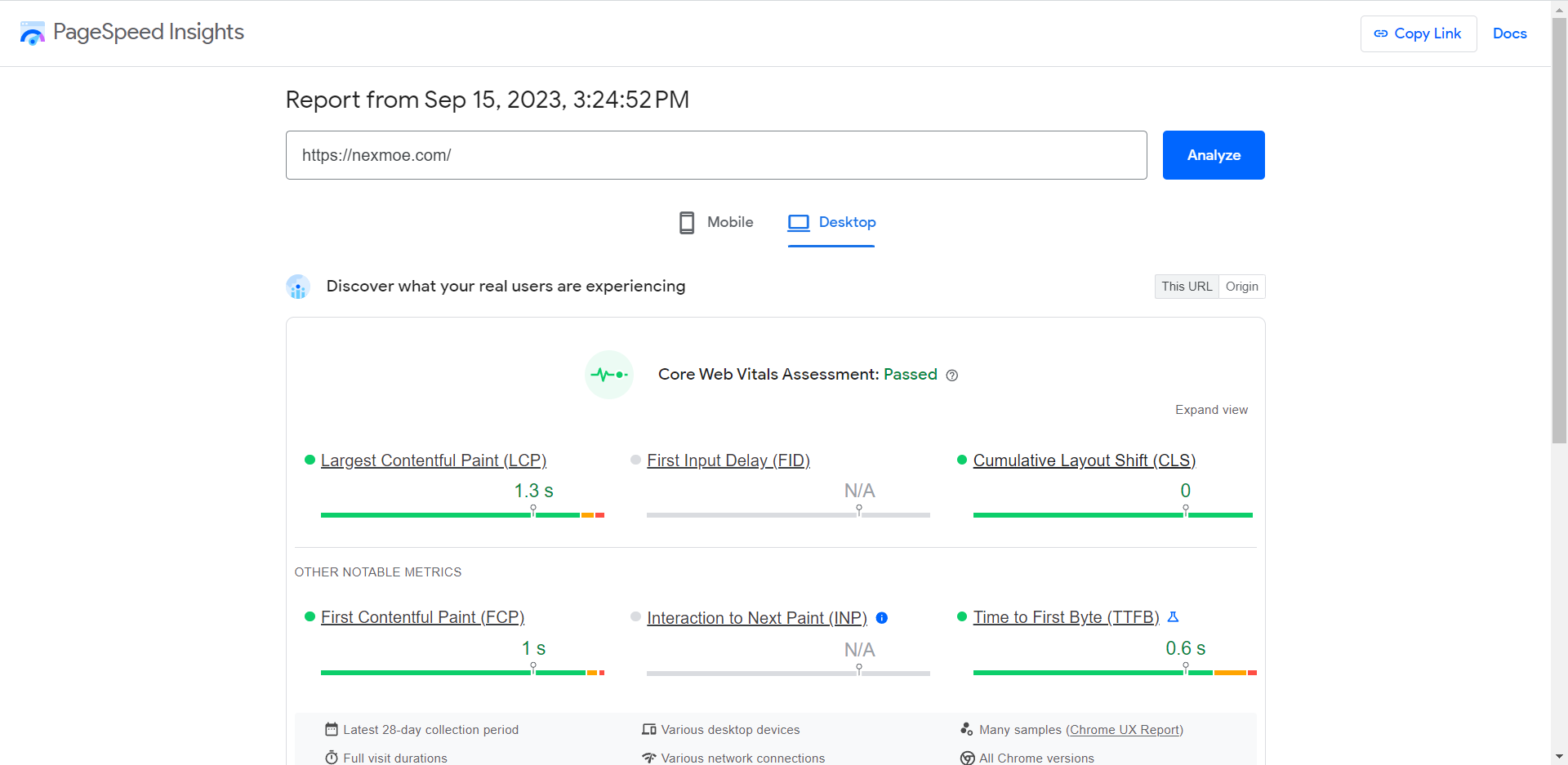
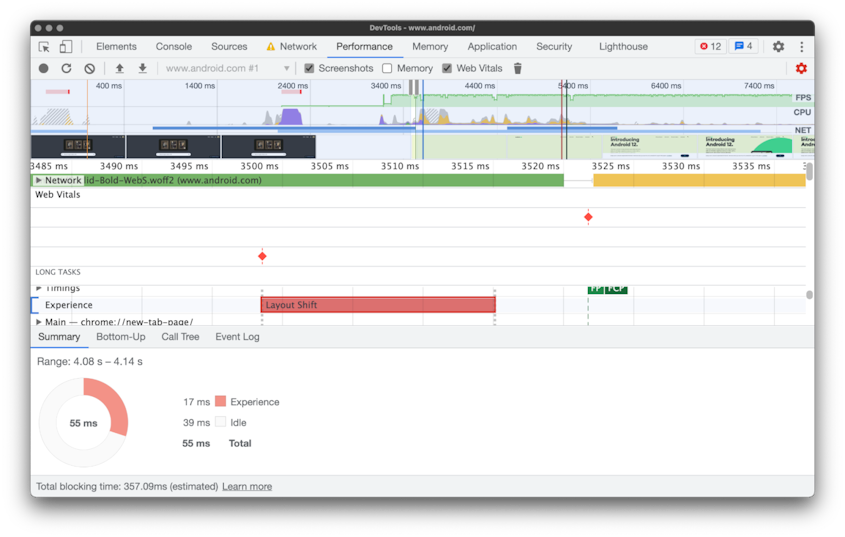
更详细的解释是:布局偏移指的是在网页上发生突然变化时,页面中的内容位置发生意外移动的现象。这种情况常常让人感到困扰,因为它会导致阅读中断或误操作。布局偏移通常是由于资源异步加载或动态添加到页面上的 DOM 元素导致的。可能的原因包括具有未知尺寸的图像或视频、字体与其备用字体渲染大小不同,或者第三方广告或小部件动态调整大小。
难受的是,网站在开发过程中的功能通常与用户体验有很大不同。个性化或第三方内容在开发中的行为通常与生产环境中不同,测试图像通常已经存在于开发者的浏览器缓存中,本地运行的 API 调用通常非常快,延迟几乎不可察觉。
 ChatGPT (OpenAI) 人工智能 (AI) 小技巧 程序员 程序设计 编程 资讯 软件工程")
 ChatGPT (OpenAI) 人工智能 (AI) 小技巧 程序员 程序设计 编程 资讯 软件工程")
 ChatGPT (OpenAI) 人工智能 (AI) 小技巧 程序员 程序设计 编程 资讯 软件工程")
 ChatGPT (OpenAI) 人工智能 (AI) 小技巧 程序员 程序设计 编程 资讯 软件工程")
 ChatGPT (OpenAI) 人工智能 (AI) 小技巧 程序员 程序设计 编程 资讯 软件工程")
















































































 Github 学习笔记 小技巧 程序设计 网站信息与统计 计算机 计算机")
























{kind=link}