[已解决]”XX.app”想访问其他app的数据频繁弹窗提醒
在 macOS 中,许多应用在启动时会频繁弹出“XX.app 想访问其他App的数据”提示,非常影响使用体验。
在 macOS 中,许多应用在启动时会频繁弹出“XX.app 想访问其他App的数据”提示,非常影响使用体验。
Obsidian Web Clipper 是一个最初为 Obsidian 设计的网页剪藏工具,它允许用户快速保存网页内容到 Obsidian 笔记库中。
今天快下班的时候看到 @kepano 发布了新功能,不再限制导出路径,可以保存到电脑中。
所以,现在任何本地优先的笔记软件都能使用 Web Clipper 了。
不用 Obsidian 之后,一直眼馋 Web Clipper 的功能,可太开心了!
我平时储存的内容主要有以下几类:
.pdf 或 .html。Web Clipper 支持 Markdown 格式导出全文,但偶尔会有排版问题。个人更喜欢 .pdf 和 .html。
储存 .html 推荐使用 SingleFile,导出时能够保留双语翻译的结果。储存 .pdf 推荐使用 Just-One-Page-PDF。
Web Clipper 很适合收藏「链接」和「高亮内容」。
链接大多为工具性的,配合 AI 总结内容,方便日后检索。
首先,激活 Interpreter(解释器),绑定大模型 API,并选择自己喜欢的模型。
我试用了 Deepseek Chat 和 GPT-4o mini,GPT-4o mini 的速度要快一倍左右,推荐。
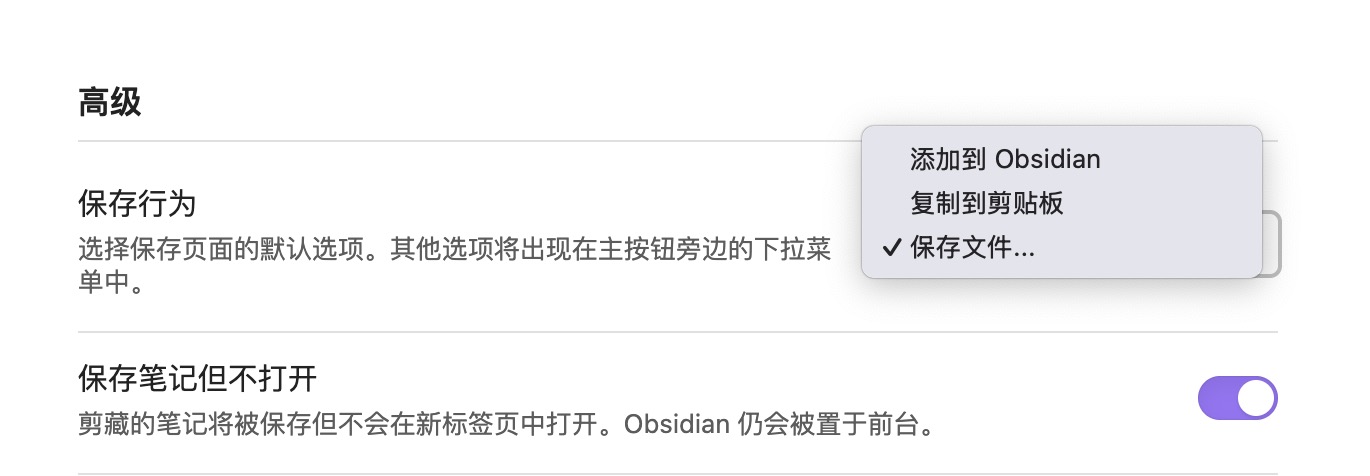
然后,在「常规设置-高级」,将保存行为改为「保存文件」。我还开启了「保存笔记但不打开」。
最后编辑模板,「文件名称」改为了 :
{{ date | date:YYYY-MM-DD}}-{{title}}
「笔记内容」部分的设置如下。一切为日后检索服务,添加了中英两种语言的总结。
### Summary
{{"a summary of the page"}}
{{"Three keywords"}}
{{"a summary of the page, translated to Chinese"}}
{{"a three bullet point summary, translated to Chinese"}}
### Highlights
{{highlights|map: item => item.text|join:"\n\n"}}
解释器上下文:
{{fullHtml}}
效果如下:

Markdown 文件会默认保存到浏览器默认的 download 文件夹。
我平时会使用 Hazel 配置规则,将 download 中的.md文件自动移动到 DEVONthink 的 Inbox 中。
虽然从 Obsidian 彻底转到了 DEVONthink,但我依旧认可和喜欢 kepano 的理念,也佩服他的很多决策,有舍才有得。
比起用功能绑住用户,Obsidian 更注重插件生态和社群活力,以此增强自己的不可替代性,也是我觉得比较可持续的发展路径。
前几天看到 拾月 开发了一个 RSS to Email 的服务,可以让读者订阅网站的 RSS feeds,0.002 元 / 封。
目前有 5 人民币的免费额度,对大部分博客来说,已经够用很久。
个人感觉这个服务很棒,不用花费额外精力配置,也不用再编辑一遍文本,都是自动化的,特别适合静态博客。
以此为契机,我搜了搜 WordPress 的插件商店,发现了 Newsletter 。
比起其他类似功能的插件,这个插件的优势是不需要注册,如果我保持 WordPress 版本不变,即使这个插件不更新维护,我依旧能使用。
设置很简单,如果 WordPress 配置过 SMTP 邮件转发,则可以直接下载使用该插件。
我目前使用的是免费版,效果请见链接 。可以展示近期的多篇博客,也可以每封邮件展示一篇博客全文。
试试用邮件订阅本博客吧!
Note: @JeffreyCalm 补充了一下非自建邮件服务(比如Gmail、Outlook)一天用 SMTP 发 200 封左右会被封停,自建的应该没有该限制。
自建邮箱则会有触达率的问题,目前大部分邮件服务商是白名单模式,新且小的 STMP 转发有可能被退信。

2023年的时候,《为了孩子的学习,入手华为MatePad 11》。当时主要是给闺女学习拼音用的,也花了一百多块钱买了洪恩的季度软件。但是现在学习之余却成了他们的娱乐工具。现在的平板上闺女安装了蛋仔派对儿子安装了王者,还有很多很多乱七八糟的小游戏。只要不是学习时间两个孩子都想着玩平板,这样下去真的不得了,必须要没收,没有商量的余地。
平板孩子不用了,也不能让它吃灰呀,正好这段时间需要看资料学习,而打印的东西又太多,所以计划直接在平板里看。年前自己从海鲜上淘了华为手写笔,硬件都准备好了,就是配备软件了,这两天测试了华为自带的笔记软件、云记、享做笔记和Notein四款。
对于这四款手写笔记软件,华为自带的笔记软件功能还是非常的少的,连word文档都不能导入,可以直接省略。对于云记、享做笔记和Notein这三款,想要使用全功能,都需要购买VIP。三款软件终身VIP价格也相差不大,都是五十来块钱,价格方面还是可以接受的。价格方面三者没有太大的区别,还是比较下功能及使用体验吧。
最终我还是花了52块钱买了个云记终身VIP。为什么选择云记呢,我感觉云记里有一个功能非常适合“记忆”,就是“记忆胶带”功能,可以把重点文字内容遮挡起来,点击之后再显示。另外选择云记的原因就是云备份不需要再单独购买,是包含在VIP里,而其他两款还需要再花10块钱一个月单独开通。云记云备份功能可以直接把数据同步到华为云盘,也可以把数据备份至百度网盘和OneDrive里。
软硬件都有了,就差自己努力的学习了!估计近三四个月时间,博客更新频率会降!以学习为重!
这两个月试了一些 AI 编程辅助工具,比如 Cursor、Windsurf、新版 Github Copilot、Cline 和 Roo Code等。
个人感受:
我平时仅会用代码完成数据分析项目,偶尔做个小插件。项目的代码量都不大,很少高频编程。
Roo Code 已经很够用。
【1】Roo Code 是基于 VS Code 的插件,额外安装 Copilot 后,只需在 API Provider 中选择 VS Code LM API,即可在 Roo Code 中调用 Copilot。如果你拥有 GitHub Student Developer Pack,那么这一套设置将是免费的。
注意:Reddit 的一个帖子 提到这样有账号被关闭的风险。该账号最终恢复了,但风险仍旧存在。
【2】Code、Architect 和 Ask 三个模式可以选择不同的模型,Architect 我选择的是 Deepseek R1,其他两个是 Claude 3.7 Sonnet。
【3】关闭 Roo Code 的 MCP Servers 服务,能减少很多引导词,节省日常使用的 Token。
【4】在 OpenRouter 中开启「Compress prompts and message chains to the context size」,能节省 Token。
【5】Gemini 系列目前不算热门,但性价比不错,效果也挺好。
** 本文基于 第三夏尔、Booooom 和 benji 的 Hugo 插件代码,修改为 WordPress 插件:DayuGuo/bear-style-like-button。
在 WordPress 的文章类型页面下方添加两个按钮:「点赞」和「支持」。
效果见本文下方,大家可以试试。
本插件可在 Github Releases 中 下载:DayuGuo/bear-style-like-button ,并在 WordPress 后台上传安装。
如有任何疑问可在评论区留言。
今天,我二娃搞了一个网页/网站,他通过 GitHub Pages 完成的,其实不难。几天前,他注册了一个 GitHub 账户(被戏称为全世界最大的“同志网站”——gayhub),取了个 ID,叫做 faceless15748。他说 faceless15 已经被人注册了。
他还自学了 HTML 和 Markdown,并且稍微懂一些 JavaScript 和 CSS。比我十岁时强多了。我十岁的时候,记得的只有在院子里玩泥巴。
我娃自己查文档、搜索,还会用 Copilot,他说以后想和我一样成为软件工程师。我竟然有点小小的感动。
在这个信息化的时代,技术的门槛越来越低。回想起我小时候,接触计算机和编程的机会并不多,学习的资源也十分有限。然而,今天的孩子们拥有无数的学习机会和工具,他们可以通过网络和开源项目实现几乎任何想法。

我儿子的第一个网站是架在Github上的静态网页。

第二个版本,加了个图片,家里的猫Pyro
GitHub Pages 是一个免费的静态网站托管服务,用户可以通过 GitHub 仓库将 HTML、CSS 和 JavaScript 文件上传,并托管成一个网站。这个服务特别适合个人、项目或组织展示,甚至可以直接用来做博客或者作品集。
如何轻松创建并托管你的 GitHub Pages 站点 (无服务器静态应用)
GitHub Pages 的最大优势之一就是无需服务器支持。所有的文件都会被托管在 GitHub 提供的全球 CDN(内容分发网络)上,加载速度非常快,且完全免费。更重要的是,GitHub Pages 完全支持自定义域名,允许你轻松地展示个人创作。
本文一共 550 个汉字, 你数一下对不对.
创建一个 GitHub Pages 站点是一个简单的过程,可以免费为你的个人、项目或组织创建网站/博客。按照此指南开始。
使用以下命令克隆仓库到本地机器:
git clone https://github.com/<username>/<repository-name>.git
创建一个 index.html 文件,包含你想要的内容。这里是一个例子:
<!DOCTYPE html> <title>我的 GitHub 页面</title> <h1>欢迎访问我的站点</h1> <p>这是我的第一个 GitHub Pages 站点。</p>
或者,你可以使用 README.md(Markdown)作为首页。
## 我的 Github 页面 ### 欢迎访问我的站点 THis is my first Github Pages site.
将你的更改提交并推送到 GitHub:
git add . git commit -m "Initial commit" git push origin main
 Github 学习笔记 小技巧 程序设计 网站信息与统计 计算机 计算机")
Github 上启用 Github Pages 的步骤
要添加主题,请转到 Pages 设置并选择“选择一个主题”。
你还可以上传额外的 HTML、CSS 和 JavaScript 文件以进行进一步的自定义。
GitHub Pages 作为无服务器静态应用运行,因为它们直接向用户提供预构建的静态 HTML、CSS 和 JavaScript 文件,而不依赖后端服务器或运行时动态内容生成。相反,这些文件托管在 GitHub 的全球内容分发网络(CDN)上,确保快速有效的交付。
优点:
缺点:
GitHub Pages 是一个令人赞叹的免费托管网站的工具。只需几步,你就可以为你的项目、作品集或个人使用创建一个站点。通过利用无服务器模型,你可以构建轻量、高效且维护最小的站点。
英文:How to Setup and Create GitHub Pages (Serverless Static Apps)
本文一共 587 个汉字, 你数一下对不对.
获取最新区块号(高度)是开发人员在去中心化系统中常见的任务。如果你正在使用 Sui 区块链,并希望通过 Node.js 和 JavaScript 获取最新的区块高度,以下是一个简单的实现方法。
Sui 是一个高性能、可扩展的区块链,以低延迟和创新架构而闻名。与 Sui 的交互需要利用其 API,这些 API 允许开发人员无缝查询区块链数据并与智能合约交互。首先,确保你已在计算机上设置了 Node.js 环境并安装了必要的依赖项。
了解 Sui 区块链:Sui区块链简介
首先,创建一个新的 Node.js 项目。你可以使用以下命令初始化项目:
mkdir sui-block-height cd sui-block-height npm init -y
接下来,安装 Axios 库,它通常用于在Node.js中发起 HTTP 请求。我们将用它从 Sui 区块链 API 获取数据:
npm install axios
现在,创建一个名为 getLatestBlock.js 的文件,并在你喜欢的代码编辑器中打开。在这个脚本中,我们将编写一个函数来获取最新的区块高度。Sui 区块链提供了一个 RPC 端点,允许你查询其状态。这个端点是获取区块数据的关键。
以下是代码:
const axios = require('axios');
// Sui RPC 端点 - 如果使用特定网络,请替换为实际端点
const SUI_RPC_URL = 'https://fullnode.sui.io/v1';
async function getLatestBlockHeight() {
try {
// 向 Sui RPC 端点发送 POST 请求
const response = await axios.post(SUI_RPC_URL, {
jsonrpc: '2.0',
id: 1,
method: 'sui_getLatestCheckpointSequenceNumber',
params: []
});
if (response.data && response.data.result !== undefined) {
console.log(`最新区块高度: ${response.data.result}`);
return response.data.result;
} else {
throw new Error('响应结构异常');
}
} catch (error) {
console.error('获取区块高度失败:', error.message);
throw error;
}
}
// 运行函数
getLatestBlockHeight().catch((err) => {
console.error('Failed to fetch the block height:', err);
});
在运行脚本之前,确保 Sui RPC 端点正确且可访问。示例中提供的 URL 指向 Sui 主网的全节点端点。如果你使用的是测试网或本地实例,请将 SUI_RPC_URL 变量替换为合适的端点。
运行脚本的命令:
node getLatestBlock.js
如果设置正确,你应该在控制台中看到打印的最新区块高度。此函数可以轻松集成到更大的应用程序中,或通过修改 RPC 方法和参数来适应其他区块链数据的获取需求。
实时交互区块链数据是构建去中心化应用程序的关键技能。借助 Sui 区块链强大的 API 和 Node.js 的简单性,你可以快速获取最新区块高度,并将此信息用于各种用途,例如监控网络、更新用户界面或触发应用程序中的特定操作。
随着 Sui 生态系统的发展,及时关注其文档和最佳实践可以确保你的集成高效且可靠。
英文:NodeJs/Javascript Function to Get the Latest Block Number (Height) on the Sui Blockchain
statistics.mode() 函数是 Python 中 statistics 模块的一部分,它返回数据集中出现次数最多的单个值(众数)。与 multimode() 不同,mode() 如果数据集包含多个众数(即多模态数据)或数据为空,则会引发错误。
以下是一些示例来说明 mode() 的行为:
statistics.mode(data)
data: 一个序列(例如 list、tuple),其中的元素是可散列的,用于确定众数。
from statistics import mode data = [1, 2, 2, 3, 4] result = mode(data) print(result) # 输出: 2
from statistics import mode data = ["apple", "banana", "apple", "cherry"] result = mode(data) print(result) # 输出: "apple"
如果有多个众数,mode() 会引发 StatisticsError。
from statistics import mode
data = [1, 1, 2, 2, 3]
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no unique mode; found 2 equally common values"
如果数据集中没有值重复,mode() 会引发 StatisticsError。
from statistics import mode
data = [1, 2, 3, 4, 5]
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no unique mode; found 5 equally common values"
如果数据集为空,mode() 会引发 StatisticsError。
from statistics import mode
data = []
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no mode for empty data"
在 Python 中,术语 multimode 通常指 statistics.multimode() 函数,这是 Python 3.8 中 statistics 模块的一部分。此函数用于找到数据集中出现次数最多的值(众数)。与 statistics.mode() 不同,后者仅返回单个众数(如果数据集是多模态的会引发错误),而 multimode() 可以处理包含多个众数的多模态数据集。
statistics.multimode(data)
data: 一个序列(例如 list、tuple),其中的元素是可散列的,用于查找众数。
返回输入数据中所有众数的列表。如果没有元素重复,则返回所有唯一值的列表,因为在这种情况下每个值都是众数。
from statistics import multimode data = [1, 2, 2, 3, 4] result = multimode(data) print(result) # 输出: [2]
from statistics import multimode data = [1, 1, 2, 2, 3] result = multimode(data) print(result) # 输出: [1, 2]
from statistics import multimode data = [1, 2, 3, 4, 5] result = multimode(data) print(result) # 输出: [1, 2, 3, 4, 5]
多模态支持:可以处理包含多个同频值的数据集。
优雅地处理唯一数据:如果没有重复值,则返回所有唯一值。
灵活的输入类型:适用于任何可散列对象的序列,包括字符串和元组。
data = ["apple", "banana", "apple", "cherry", "banana", "banana"] result = multimode(data) print(result) # 输出: ['banana']
如果数据集很大,计算众数可能会消耗大量计算资源,因为它需要统计所有元素的出现次数。
| 特性 | mode() | multimode() |
|---|---|---|
| 返回值 | 单个最频繁的值 | 所有最频繁值的列表 |
| 多模态数据行为 | 引发 StatisticsError |
返回所有众数 |
| 空数据集行为 | 引发 StatisticsError |
返回空列表 |
| 最佳用途 | 适用于期望唯一众数的单模态数据 | 适用于包含多个众数的多模态数据或任意数据 |
如果不确定数据是否包含多个众数或无重复值,multimode() 是更安全的选择。
英文:The mode vs multimode in Python
本文一共 702 个汉字, 你数一下对不对.
我一直是自己租用VPS服务器,然后搭建各种服务,比如博客就是Apache2+MySQL数据库。一般来说就是默认参数,没有去管,不过最近发现MySQL的性能参数都很保守,不能发挥整个服务器的性能。
然后我就网上搜索了一下,根据参数配置建议,用ChatGPT写了以下Python和BASH脚本。只需要在需要优化的服务器上,跑一下该脚本,然后就会显示参数配置,然后直接把参数添加到MySQL数据库配置参数文件上: /etc/mysql/mysql.conf.d/mysqld.cnf
然后运行: service mysql restart 重启MySQL服务器。
运行了几周,发现效果很好,博客反应速度也快了很多,这很大原因是根据了内存增加了MySQL缓存大小。
把下面的Python脚本存成 mysql_config.py 然后运行 python3 mysql_config.py
def get_total_ram():
with open('/proc/meminfo', 'r') as f:
for line in f:
if line.startswith("MemTotal:"):
total_ram_kb = int(line.split()[1])
return total_ram_kb * 1024 # 转换为字节(bytes)
return 0 # 如果未找到 MemTotal,则返回 0
def calculate_mysql_settings():
# 获取总内存(以字节为单位)
total_ram = get_total_ram()
# 根据总内存(以字节为单位)计算 MySQL 配置
innodb_buffer_pool_size = int(total_ram * 0.3) # 使用内存的 30%
key_buffer_size = min(total_ram * 20 // 100, 512 * 1024 * 1024) # 使用内存的 20%,最大限制为 512MB
sort_buffer_size = min(total_ram * 25 // 1000, 4 * 1024 * 1024) # 使用内存的 0.25%,最大限制为 4MB
read_rnd_buffer_size = min(total_ram * 625 // 100000, 512 * 1024) # 使用内存的 0.0625%,最大限制为 512KB
tmp_table_size = max_heap_table_size = min(total_ram * 5 // 100, 64 * 1024 * 1024) # 使用内存的 5%,最大限制为 64MB
join_buffer_size = min(total_ram * 2 // 1000, 4 * 1024 * 1024) # 使用内存的 0.2%,最大限制为 4MB
table_open_cache = min(400 + (total_ram // 64), 2000) # 根据内存动态计算,最大限制为 2000
thread_cache_size = min(total_ram * 15 // 1000, 100) # 使用内存的 1.5%,最大限制为 100
innodb_log_buffer_size = min(total_ram * 5 // 100, 16 * 1024 * 1024) # 使用内存的 5%,最大限制为 16MB
# 以字节为单位打印配置
print(f"MySQL 配置(基于总内存 {total_ram / (1024 * 1024):.2f} MB):")
print("将以下内容添加到 /etc/mysql/mysql.conf.d/mysqld.cnf 的末尾\n")
print(f"innodb_buffer_pool_size = {innodb_buffer_pool_size}")
print(f"key_buffer_size = {key_buffer_size}")
print(f"sort_buffer_size = {sort_buffer_size}")
print(f"read_rnd_buffer_size = {read_rnd_buffer_size}")
print(f"tmp_table_size = {tmp_table_size}")
print(f"max_heap_table_size = {max_heap_table_size}")
print(f"join_buffer_size = {join_buffer_size}")
print(f"table_open_cache = {table_open_cache}")
print(f"thread_cache_size = {thread_cache_size}")
print(f"innodb_log_buffer_size = {innodb_log_buffer_size}")
# 打印自定义设置
print("expire_logs_days = 3")
print("max_binlog_size = 100M")
if __name__ == "__main__":
calculate_mysql_settings()
会打印出类似以下的配置:
innodb_buffer_pool_size = 626468044 key_buffer_size = 417645363 sort_buffer_size = 4194304 read_rnd_buffer_size = 524288 tmp_table_size = 67108864 max_heap_table_size = 67108864 join_buffer_size = 4176453 table_open_cache = 2000 thread_cache_size = 100 innodb_log_buffer_size = 16777216 expire_logs_days = 3 max_binlog_size = 100M
添加到MySQL的配置文件:/etc/mysql/mysql.conf.d/mysqld.cnf 然后重启数据库即可:service mysql restart
以下是完成同样功能的BASH脚本。
#!/bin/bash
# 获取总内存大小(以字节为单位)
get_total_ram() {
# 从 /proc/meminfo 中提取总内存(以 kB 为单位)
total_ram_kb=$(awk '/^MemTotal:/ {print $2}' /proc/meminfo)
if [[ -z "$total_ram_kb" ]]; then
echo 0 # 如果未找到 MemTotal,则返回 0
else
echo $((total_ram_kb * 1024)) # 将 kB 转换为字节
fi
}
# 根据总内存大小计算 MySQL 配置
calculate_mysql_settings() {
# 获取总内存(以字节为单位)
total_ram=$(get_total_ram)
# 计算 MySQL 配置参数
innodb_buffer_pool_size=$((total_ram * 30 / 100)) # 使用内存的 30%
key_buffer_size=$(($((total_ram * 20 / 100)) < $((512 * 1024 * 1024)) ? $((total_ram * 20 / 100)) : $((512 * 1024 * 1024)))) # 使用内存的 20%,最大限制为 512MB
sort_buffer_size=$(($((total_ram * 25 / 1000)) < $((4 * 1024 * 1024)) ? $((total_ram * 25 / 1000)) : $((4 * 1024 * 1024)))) # 使用内存的 0.25%,最大限制为 4MB
read_rnd_buffer_size=$(($((total_ram * 625 / 100000)) < $((512 * 1024)) ? $((total_ram * 625 / 100000)) : $((512 * 1024)))) # 使用内存的 0.0625%,最大限制为 512KB
tmp_table_size=$((total_ram * 5 / 100 < 64 * 1024 * 1024 ? total_ram * 5 / 100 : 64 * 1024 * 1024)) # 使用内存的 5%,最大限制为 64MB
max_heap_table_size=$tmp_table_size # 临时表大小等于最大堆表大小
join_buffer_size=$(($((total_ram * 2 / 1000)) < $((4 * 1024 * 1024)) ? $((total_ram * 2 / 1000)) : $((4 * 1024 * 1024)))) # 使用内存的 0.2%,最大限制为 4MB
table_open_cache=$(($((400 + total_ram / 64)) < 2000 ? $((400 + total_ram / 64)) : 2000)) # 根据内存动态计算,最大限制为 2000
thread_cache_size=$(($((total_ram * 15 / 1000)) < 100 ? $((total_ram * 15 / 1000)) : 100)) # 使用内存的 1.5%,最大限制为 100
innodb_log_buffer_size=$(($((total_ram * 5 / 100)) < $((16 * 1024 * 1024)) ? $((total_ram * 5 / 100)) : $((16 * 1024 * 1024)))) # 使用内存的 5%,最大限制为 16MB
# 打印配置(以字节为单位)
echo "MySQL 配置(基于总内存 $((total_ram / (1024 * 1024))) MB):"
echo "将以下内容添加到 /etc/mysql/mysql.conf.d/mysqld.cnf 的末尾"
echo
echo "innodb_buffer_pool_size = $innodb_buffer_pool_size"
echo "key_buffer_size = $key_buffer_size"
echo "sort_buffer_size = $sort_buffer_size"
echo "read_rnd_buffer_size = $read_rnd_buffer_size"
echo "tmp_table_size = $tmp_table_size"
echo "max_heap_table_size = $max_heap_table_size"
echo "join_buffer_size = $join_buffer_size"
echo "table_open_cache = $table_open_cache"
echo "thread_cache_size = $thread_cache_size"
echo "innodb_log_buffer_size = $innodb_log_buffer_size"
echo
echo "expire_logs_days = 3" # 日志过期天数设置为 3 天
echo "max_binlog_size = 100M" # 最大二进制日志大小设置为 100M
}
# 主函数调用
calculate_mysql_settings
需要注意的是,我在脚本后面加入了一些我自定义的配置,根据需求自行修改即可。在配置文件里,后面定义的会覆盖前面的,这就是为什么要添加到文件尾的原因。
其中最关键的配置 innodb_buffer_pool_size 我设置为使用当前内存的30%,如果服务器只有数据库/博客这个功能,可以适当的提高比例,比如60%-80%。
英文:Python/Bash Script to Print the Optimized Parameters for MySQL Servers
{kind=link}