计算机的核心从 CPU 转向 GPU,上个时代依靠程序员写代码指挥 CPU 执行指令解决问题,构成了现在庞大的 IT 产业,程序员是中心。现在的时代逐渐转变,GPU 生产的 token 逐渐能解决越来越多的问题,能思考,能生成代码指挥 CPU 去执行解决问题,计算的核心一定会转向 GPU,世界对 GPU 的需求只会越来越高。
给 AI 分了四个阶段,Perception AI → Generative AI → Agentic AI → Physical AI,不是很认同,Agentic 和 Physical 都是 Generative AI 的延续,不过无所谓,可以看到 Agentic 这个概念实在是火爆。
Scaling Law 没有停止,Agentic AI 需要深度思考,深度思考有新的 Test-time Scaling Law,越多的 token 输出效果越好需,要多轮理解和工具调用对 token 的消耗更是指数级上涨。
Physical AI 要更好地理解现实世界,声音/视觉/触感,都会比纯文本思考对 token 消耗的诉求更高,像 2G 时代看文字新闻,3G 4G 图片,5G 视频一样。
多个 session 都在推广 NVidia 的 Video Search and Summarization Agent,串联从视频的获取→分割→VLM识别、CV物体识别和跟踪→数据处理存储和RAG召回→用户对话 整个流程,做到可以对视频提供实时分析和报警,也可以自然语言交互查询视频内容,边缘部署,适合用于监控,算是用 NVidia 技术栈做 AI 应用的一个标杆范例。
AIGC
关注了下视频 AIGC 相关的几个 Session
在好莱坞干了几十年的视觉效果的 Ed Ulbrich 开了个公司 Metaphysic,以前的电影特效制作成本巨大,对人的处理还很难跨过恐怖谷,而基于 AI 技术做特效,用完全不同的技术栈,效果好成本低,是一种颠覆。metaphysic 给娱乐行业提供人脸替换、数字人的服务,看起来是用的 GAN,在人物换脸技术上,GAN 还是更能做到稳定和实时,特别是实时这个点,基于 diffusion 很难做到。基于市场需求,利用已有的不同技术(甚至是上一代技术)深入解决问题,是有空间的。
但模型本身目前解决不了所有问题,还需要工程上的一些策略和串联做优化。例如 Tree of Thought 让任务不是以线性一步步执行的形式,而是生成解决问题的多个节点,多角度思考问题,形成树结构的任务,评估节点的价值,在里面寻找最优解。 Reflexion 会有 Evaluator 对各种反馈(工具调用结果/模型输出/用户指令)进行反思,梳理改进方向,也会把反思结果作为知识库经验,指导后续的任务。
熟悉我的朋友应该都知道,我在工作中时不时要参与到一些诸如客户支持,定价沟通,产品价值talking 的环节中,可能是这两年大家都把 AI 作为了“年度话题”的重要性,所以总会有一些客户想要进一步了解“产品如何在实际的业务流中快速集成 AI 的能力”,市面上也有各种各样吹嘘“自己的产品又一次集成了 AI”的 PR 文章,但本质上其实大都是在云市场集成 AI 之后快速实现了一个 chatbot,好像效果并没有那么好。
当然也有一些客户会来问一些在不同视角的问题,我听过的问题印象比较深的就是“产品集成了 AI 能力我是认可的,但是这个产品中我看不到 Deepseek 的露出,你们怎么处理”,“在产品中集成 LLM 其实各家都大差不差,但是差异性的效果我暂时还没有看到”,此外在一些类似的产品中我发现 C2C(Copy to china) 的思路目前可能还是奏效的,去 ProductHunt 或者类似的网站看看国外的“同行们”又搞出来了哪些 AI 相关的应用,然后看看哪一个最适合集成到自己的项目中,砍掉一些复杂功能再做一些本地化,好像给自己的产品也就搭上了 AI 这趟快车。
昨天和同事聊天的时候说到不同行业中的门槛其实还比较高,可能互联网行业的从业者大都掌握了无痛访问 Google 或者 Github 等网站的方式,但其实还有非常多的老百姓不太分得清其中的区别(事实上互联网从业者也不见得都掌握了这个能力),对于老百姓来说耳熟能详的张一鸣和王兴兴是那种“在某一个行业中实现了成功的例子”,但是对他们到底在做什么其实并不清楚,其实说到 AI,说到人工智能,这应该是一个伴随计算机有 N 多年历史的故事了。
但是 AI 到底是咋来的?好像前些年我们对 AI 的理解和认知还停留在 TensorFlow 和 Pytorch 这样的算法中,怎么一眨眼 AI 就已经飞入寻常百姓家了?
值得一提的是冯·诺伊曼从小就以过人的智力与记忆力而闻名。他在一生中发表了大约150篇论文,其中有60篇纯数学论文,20篇物理学以及60篇应用数学论文。他最后的作品是一个在医院未完成的手稿,后来以书名《计算机与人脑》(The Computer and the Brain)发布,表现了他生命最后时光的兴趣方向(但其实冯诺依曼不仅在计算机方向有建树,他也是博弈论之父)。
罗森布拉特,能否让计算机自己学习?
1958 年,弗兰克·罗森布拉特提出了一个让整个 AI 领域兴奋的想法——“感知机(Perceptron)”,它是一种最简单的神经网络,可以通过调整权重来学习模式,比如识别简单的形状。“创造具有人类特质的机器,一直是科幻小说里一个令人着迷的领域。但我们即将在现实中见证这种机器的诞生,这种机器不依赖人类的训练和控制,就能感知、识别和辨认出周边环境。”
然而,1969 年,闵斯基(Marvin Minsky)和派普特(Seymour Papert) 在《感知机(Perceptrons)》一书中证明,感知机无法解决像“异或”这样的基本问题,这让整个 AI 研究陷入了“AI 冬天”,神经网络被主流科学界抛弃。这本书抨击了罗森布拉特的工作,并本质上终结了感知机的命运。
1956 年,达特茅斯会议 上,一群科学家聚在一起,试图定义“人工智能” 这个领域。其中,闵斯基作为 MIT 人工智能实验室的创建者,是符号主义 AI 的坚定支持者。
他的梦想很宏大:“AI 应该像人一样思考,我们只要给它足够的逻辑规则,它就能成为真正的智能。” 他的研究主要基于符号逻辑,比如他开发了一种叫做 Lisp 机器 的计算机,专门用来运行 AI 代码。
与此同时,佩珀特则更加关注机器学习和儿童教育,他认为计算机应该像孩子一样学习,而不是依赖固有规则。他发明了一种编程语言——Logo,可以让孩子通过简单的指令控制“小乌龟”在屏幕上画图形。他们二位的 AI 研究,让 AI 在 1960 年代成为了学术界的明星,政府和企业纷纷投资,AI 似乎要迎来一个黄金时代!
但好景不长,感知机(Perceptron) 的失败让闵斯基和佩珀特觉得,神经网络完全没戏。他们在 1969 年合著了一本书——《Perceptrons》,直接指出了感知机的致命缺陷“感知机无法解决“异或(XOR)”问题——也就是说,它没办法学会“如果 A 和 B 相同,输出 0,否则输出 1” 这样的简单逻辑。”
他们的批评毁灭性地打击了神经网络研究,导致 1970 年代 AI 研究资金骤减,进入了第一次“AI 冬天”。
虽然闵斯基和佩珀特让神经网络陷入低谷,但他们的研究也推动了 AI 其他方向的发展。
闵斯基继续研究“心智架构”,提出了“框架理论”(Frame Theory)——AI 应该拥有类似人类的知识结构,而不是单纯的数据处理器。佩珀特专注于教育领域,创造了建构主义学习理论,他的 Logo 语言影响了后来的 Scratch 和 Python 在教育领域的应用。
直到 1980 年代,辛顿通过反向传播算法解决了感知机的问题,才让神经网络重新崛起。但讽刺的是,闵斯基并不认同深度学习,他仍然认为符号 AI 才是未来。
他提出了贝叶斯网络,用数学方式描述变量之间的因果联系,让 AI 具备更强的推理能力。后来,他又发展出因果推理和反事实思维,让 AI 不仅能预测,还能回答“如果情况不同,结果会怎样?”。这些理论如今影响着数据科学、医疗 AI、经济学,甚至推动下一代更智能的 AI 发展。
珀尔的因果推理思想,彻底改变了 AI 的研究方向。过去,AI 主要依赖深度学习,但神经网络的一个问题是它们只会发现模式,而不会理解因果。
比如传统 AI 可能发现:夏天卖冰淇淋的同时,游泳馆的溺水率也会上升。但因果 AI 知道:冰淇淋不会导致溺水,真正的原因是夏天气温升高。他的著作《为什么(The Book of Why)》深入探讨了因果推理的重要性,这为现代 AI 的解释能力奠定了基础。
杰弗里辛顿,如何训练深度神经网络?
1970 年代,神经网络研究遭遇寒冬。当时的主流 AI 研究者(如闵斯基和佩珀特)认为神经网络太简单,无法解决复杂问题。许多科学家纷纷放弃,但辛顿偏偏选择了这条“错误的道路”。
辛顿出生于英国,外祖父是著名数学家 George Boole(布尔代数的创始人),他从小就喜欢挑战权威。在攻读博士期间,他研究反向传播算法(Backpropagation),一种可以让神经网络自动调整权重的方法。尽管这个算法早已在 1970 年被提出,但几乎没人相信它真的能让 AI 学习。Hinton 和他的团队坚持优化反向传播,并在 1986 年成功证明它可以让多层神经网络高效学习复杂任务。
这种“对抗学习”的方式,突破了传统 AI 生成方法的局限,被命名为 GAN(Generative Adversarial Network)。
GAN 让 AI 从“分析数据”变成了“创造数据”,彻底改变了 AI 在艺术、设计、游戏、影视等行业的应用方式。可以说,他的研究让 AI 从理解世界进化到了创造世界,并成为 AI 生成内容(AIGC)浪潮的奠基者之一。
古德费洛不仅是GAN 之父,也是AI 伦理的重要倡导者,他的贡献将长期影响 AI 发展方向。
达里奥,AI 能否像人类一样写作和推理?
达里奥是 AI 研究领域的重要人物之一,曾在 OpenAI 领导多个关键项目,后创办 Anthropic,专注于 AI 安全与“AI 对齐”研究。他的工作推动了 AI 模型能力的飞跃,同时也让 AI 伦理问题进入公众视野。
达里奥最初是一名神经科学家,研究大脑与神经网络的相似性。他后来转向机器学习,加入 OpenAI,成为 AI 研究的核心人物之一。他在 OpenAI 期间的关键贡献包括:GPT-2 与 GPT-3 研究负责人:推动了现代大语言模型(LLM)的发展。AI 对齐研究的先驱:他提出 AI 需要“对齐人类价值观”,否则可能失控。
2021 年,达里奥离开 OpenAI,与几位前同事共同创立 Anthropic,专注于 AI 安全和“可控 AI”研究。Anthropic 的核心产品 Claude 系列(类似 ChatGPT)强调安全性,避免 AI 生成危险内容。他的研究强调:“AI 必须对人类有益,否则超级智能可能带来无法预测的后果。”
Anthropic 目前是 OpenAI 的主要竞争对手之一,并获得了 Google 近 30 亿美元的投资。
当然,说到达里奥我们其实也需要提到 Tom B Brown 和 Alec Radford,他们一行三个人的研究共同塑造了现代 AI 发展路径。但我想他们从 OpenA I跳槽到 Anthropic 也许还是遇到了那个难以抉择的问题“是追求更强大的 AI,还是追求更安全的 AI”?
但如果我们回到 2025 年的当下,会发现 AI 的发展已经度过了“通用智能”的探索阶段,下一步可能还是要对准通用人工智能的方向进行进一步的细化和延伸。由于各类基于 Claude 3.7 的产品我们已经基本跳过了“AI 行不行”的疑惑,但到底“如何让他更安全,更有效”还是一个短期内我们看不到答案的问题。
前一段时间木遥的解读“vibe coding”在朋友圈和各种渠道刷屏,文章中那句“一方面它犹如神助,让你有一种第一次挥舞魔杖的幻觉。另一方面它写了新的忘了旧的,不断重构又原地打转,好像永远在解决问题但永远创造出更多新的问题,并且面对 bug 采取一种振振有词地姿态对你 gaslighting。你面对着层出不穷的工具甚至不知道自己该认真考虑哪个,心知肚明可能下个月就又有了新的「最佳实践」,养成任何肌肉记忆都是一种浪费,而所谓新的最佳实践只不过是用更快的速度产出更隐蔽的 bug 而已。”可能也是许多正在与 AI 结对编程朋友的真实感觉。
但我想,AI 带来的改变确实日新月异,我能看到身边的朋友能够逐渐完成“不相信 AI → 怀疑 AI → 全部用 AI → 不敢信任 AI → 再一次信任 AI”的无限循环之中。我在一些业余时间也尝试练手用 AI 帮我写了几个产品,相比原先的产品设计与研发过程中,会发现现在的 AI 可能每一次都会比前一段时间的使用更加流畅一些,但依然无法完全避免上下文遇到限制导致记忆力幻觉或者相关的问题,这种感觉好像就像是一种慢性毒药,一方面更爽了,另一方面又不是那么爽。在产品设计过程中各种刷屏的什么“用 AI 搞定原型图,搞定高保真效果图”的论据其实也能变相让我们感知到 AI 在具体业务中的应用其实还处在比较早期的阶段。
一方面我受益于使用 AI 能够极大程度加快我把脑海中的某些想法付诸于实践的过程,但另一方面好像也能明显感知到过拟合带来的某种不适感,在开启新项目的时候确实能够通过 AI 极大程度加快效率,但是否会因为过度信任 AI 而导致代码中潜藏了许多暂时没有精力与时间发现的 bug,又变成代码中一个潜藏的问题真的很难一两句话讲清楚。
如果对比我前端时间那篇《AI 取代人工进展走到哪一步了?》,当下的我结论还是那句“保持对前沿技术学习与了解,让自己不要落伍的概念是没问题的,用 AI 来输出一下自己无处安放的创造力或者做一些创新与变化的真实落地是很好的”,但 AI 改变世界的进度条到哪一步了?
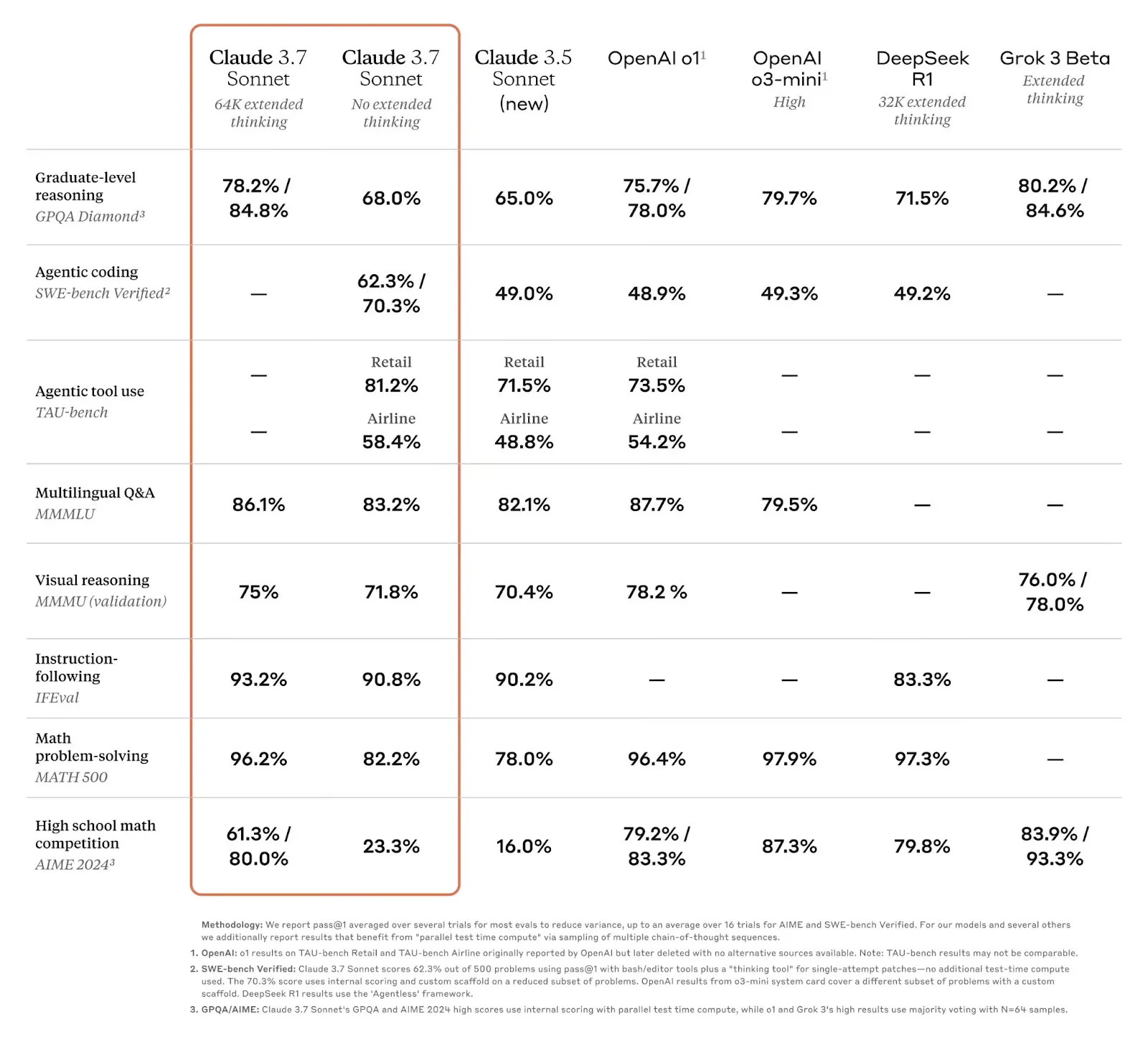
Claude 3.7 Sonnet 在万众期待中推出了,为什么期待,因为从 Claude 3.5 Sonnet 发布后,一直是AI Coding Agent 领域最好的模型,综合效果没有对手,后面陆续推出的 o1/o3/DeepSeek 都没能撼动,更让人期待 Claude 3.7 Sonnet 在 AI Coding 领域能不能有进一步提升。
Claude 3.7 放出来的 Benchmark 里,有两个是跟 AI Coding Agent 表现强相关的:
SWE-bench Verified: Claude 3.7 Sonnet scores 62.3% out of 500 problems using pass@1 with bash/editor tools plus a "thinking tool" for single-attempt patches — no additional test-time compute used. 70.3% score uses internal scoring and custom scaffold on a reduced subset of problems. Scaffold Deepseek R1 results use the "Agentless" framework. OpenAI results from o3-mini system card cover a different subset of problems with a custom compute.
Claude 没有具体说明怎么做检索代码的,官方blog附录里提到在运行环境上是用了极简的方案,只提供了命令和编辑文件的能力,看起来是只把代码仓库目录扔给 LLM,让它自行去做文件搜索。另外有提到 Deepseek 的跑分是基于 Agentless 框架跑的,Agentless 专门介绍说明了如何跑 SWE-Bench,以及具体是怎么做代码检索的。见 Agentless/README_swebench.md。
{
"annotator": 0,
"user_id": "omar_rossi_1241",
"instruction": "Your user id is omar_rossi_1241. For your upcoming trip from New York to Chicago, you want to change the passenger to yourself, upgrade it to economy class, and have 3 checked bags. You prefer gift card payment. Your birthday is in your user profile so you do not prefer to provide it. You are reactive to the agent and will not say anything that is not asked.",
"actions": [
{
"name": "update_reservation_flights",
"arguments": {
"reservation_id": "FQ8APE",
"cabin": "economy",
"flights": [
{
"flight_number": "HAT056",
"date": "2024-05-25",
},
{
"flight_number": "HAT138",
"date": "2024-05-25",
},
],
"payment_id": "gift_card_8190333",
},
},
{
"name": "update_reservation_passengers",
"arguments": {
"reservation_id": "FQ8APE",
"passengers": [
{
"first_name": "Omar",
"last_name": "Rossi",
"dob": "1970-06-06",
}
],
},
},
{
"name": "update_reservation_baggages",
"arguments": {
"reservation_id": "FQ8APE",
"total_baggages": 3,
"nonfree_baggages": 0,
"payment_id": "gift_card_8190333",
},
},
],
},
转化后这个case实际跟大模型交互的过程:
{"traj": [
{
"role": "system",
"content": "# Airline Agent Policy\n\nThe current time is 2024-05-15 15:00:00 EST.\n\nAs an airline agent, you can help users book, modify, or cancel flight reservations.\n\n- Before taking any actions that update the booking database (booking, modifying flights, editing baggage, upgrading cabin class, or updating passenger information), you must list the action details and obtain explicit user confirmation (yes) to proceed.\n\n- You should not provide any information, knowledge, or procedures not provided by the user or available tools, or give subjective recommendations or comments.\n\n- You should only make one tool call at a time, and if you make a tool call, you should not respond to the user simultaneously. If you respond to the user, you should not make a tool call at the same time.\n\n- You should deny user requests that are against this policy.\n\n- You should transfer the user to a human agent if and only if the request cannot be handled within the scope of your actions.\n\n## Domain Basic\n\n- Each user has a profile containing user id, email, addresses, date of birth, payment methods, reservation numbers, and membership tier.\n\n- Each reservation has an reservation id, user id, trip type (one way, round trip), flights, passengers, payment methods, created time, baggages, and travel insurance information.\n\n- Each flight has a flight number, an origin, destination, scheduled departure and arrival time (local time), and for each date:\n - If the status is "available", the flight has not taken off, available seats and prices are listed.\n - If the status is "delayed" or "on time", the flight has not taken off, cannot be booked.\n - If the status is "flying", the flight has taken off but not landed, cannot be booked.\n\n## Book flight\n\n- The agent must first obtain the user id, then ask for the trip type, origin, destination.\n\n- Passengers: Each reservation can have at most five passengers. The agent needs to collect the first name, last name, and date of birth for each passenger. All passengers must fly the same flights in the same cabin.\n\n- Payment: each reservation can use at most one travel certificate, at most one credit card, and at most three gift cards. The remaining amount of a travel certificate is not refundable. All payment methods must already be in user profile for safety reasons.\n\n- Checked bag allowance: If the booking user is a regular member, 0 free checked bag for each basic economy passenger, 1 free checked bag for each economy passenger, and 2 free checked bags for each business passenger. If the booking user is a silver member, 1 free checked bag for each basic economy passenger, 2 free checked bag for each economy passenger, and 3 free checked bags for each business passenger. If the booking user is a gold member, 2 free checked bag for each basic economy passenger, 3 free checked bag for each economy passenger, and 3 free checked bags for each business passenger. Each extra baggage is 50 dollars.\n\n- Travel insurance: the agent should ask if the user wants to buy the travel insurance, which is 30 dollars per passenger and enables full refund if the user needs to cancel the flight given health or weather reasons.\n\n## Modify flight\n\n- The agent must first obtain the user id and the reservation id.\n\n- Change flights: Basic economy flights cannot be modified. Other reservations can be modified without changing the origin, destination, and trip type. Some flight segments can be kept, but their prices will not be updated based on the current price. The API does not check these for the agent, so the agent must make sure the rules apply before calling the API!\n\n- Change cabin: all reservations, including basic economy, can change cabin without changing the flights. Cabin changes require the user to pay for the difference between their current cabin and the new cabin class. Cabin class must be the same across all the flights in the same reservation; changing cabin for just one flight segment is not possible.\n\n- Change baggage and insurance: The user can add but not remove checked bags. The user cannot add insurance after initial booking.\n\n- Change passengers: The user can modify passengers but cannot modify the number of passengers. This is something that even a human agent cannot assist with.\n\n- Payment: If the flights are changed, the user needs to provide one gift card or credit card for payment or refund method. The agent should ask for the payment or refund method instead.\n\n## Cancel flight\n\n- The agent must first obtain the user id, the reservation id, and the reason for cancellation (change of plan, airline cancelled flight, or other reasons)\n\n- All reservations can be cancelled within 24 hours of booking, or if the airline cancelled the flight. Otherwise, basic economy or economy flights can be cancelled only if travel insurance is bought and the condition is met, and business flights can always be cancelled. The rules are strict regardless of the membership status. The API does not check these for the agent, so the agent must make sure the rules apply before calling the API!\n\n- The agent can only cancel the whole trip that is not flown. If any of the segments are already used, the agent cannot help and transfer is needed.\n\n- The refund will go to original payment methods in 5 to 7 business days.\n\n## Refund\n\n- If the user is silver/gold member or has travel insurance or flies business, and complains about cancelled flights in a reservation, the agent can offer a certificate as a gesture after confirming the facts, with the amount being $100 times the number of passengers.\n\n- If the user is silver/gold member or has travel insurance or flies business, and complains about delayed flights in a reservation and wants to change or cancel the reservation, the agent can offer a certificate as a gesture after confirming the facts and changing or cancelling the reservation, with the amount being $50 times the number of passengers.\n\n- Do not proactively offer these unless the user complains about the situation and explicitly asks for some compensation. Do not compensate if the user is regular member and has no travel insurance and flies (basic) economy.\n"
},
{
"role": "user",
"content": "Hi! I'd like to make a few changes to my trip from New York to Chicago. Can you help me with that?"
},
{
"role": "assistant",
"content": "Of course! I can help you modify your trip. Could you please provide your user ID and the reservation ID for the trip you want to change?",
},
{
"role": "user",
"content": "Sure! My user ID is omar_rossi_1241. But I'm not sure about the reservation ID at the moment."
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"user_id":"omar_rossi_1241"}",
"name": "get_user_details"
},
"id": "call_FXi5dyufwOlkHksVgNwVhhVB",
"type": "function"
}
]
},
{
"role": "assistant",
"content": "I found your reservations. Could you please confirm which reservation ID you'd like to modify for your trip from New York to Chicago? Here are your reservation IDs:\n\n- UM3OG5\n- 5RJ7UH\n- FQ8APE\n- QKRY03\n\nLet me know which one you'd like to modify!",
},
{
"role": "user",
"content": "I'm not entirely certain, but I believe it might be the first one, UM3OG5."
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"reservation_id":"UM3OG5"}",
"name": "get_reservation_details"
},
"id": "call_FApEDaUHdL2hx8FNbu5UCMb8",
"type": "function"
}
]
},
{
"role": "assistant",
"content": "The reservation ID "UM3OG5" is for a round trip from Seattle (SEA) to Dallas/Fort Worth (DFW), not from New York to Chicago. \n\nCould you please check if any of the other reservation IDs match your trip from New York to Chicago? Here are the remaining reservation IDs:\n\n- 5RJ7UH\n- FQ8APE\n- QKRY03\n\nLet me know which one you'd like to modify!",
},
{
"role": "user",
"content": "In that case, I think it might be FQ8APE. Can you check that for me?"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"reservation_id":"FQ8APE"}",
"name": "get_reservation_details"
},
"id": "call_W507pQxieFVdAxvqONuYWvN2",
"type": "function"
}
]
},
{
"content": "The reservation ID "FQ8APE" is for a one-way trip from Newark (EWR) to Chicago (ORD) with a stop in Houston (IAH). Since this reservation is in basic economy, please note that the flights cannot be modified. However, I can assist with other changes like cabin upgrades or baggage additions.\n\nPlease let me know what specific changes you would like to make to this reservation!",
"role": "assistant"
},
{
"role": "user",
"content": "Great! I'd like to add three checked bags, change the passenger to myself, and upgrade to economy class, please."
},
{
"role": "assistant",
"content": "Here are the changes you want to make to your reservation:\n\n1. **Add three checked bags**: \n - Since you are a gold member and upgrading to economy class, you will have 3 free checked bags, so no additional charges for the bags.\n\n2. **Change the passenger to yourself**:\n - Current passenger: Ivan Garcia\n - New passenger: Omar Rossi (DOB: 1970-06-06)\n\n3. **Upgrade to economy class**:\n - Upgrade from basic economy to economy class.\n\nPlease confirm if you would like to proceed with these changes.",
},
{
"role": "user",
"content": "Yes, I'd like to proceed with those changes. And please use a gift card for any payment needed."
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"reservation_id": "FQ8APE", "passengers": [{"first_name": "Omar", "last_name": "Rossi", "dob": "1970-06-06"}]}",
"name": "update_reservation_passengers"
},
"id": "call_jK7xz4ERk3csc9jBfroPobGs",
"type": "function"
}
]
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"reservation_id":"FQ8APE","cabin":"economy","flights":[{"origin":"EWR","destination":"IAH","flight_number":"HAT056","date":"2024-05-25"},{"origin":"IAH","destination":"ORD","flight_number":"HAT138","date":"2024-05-25"}],"payment_id":"gift_card_8190333"}",
"name": "update_reservation_flights"
},
"id": "call_zeyT5c2EYzRvfY42X7YOKOng",
"type": "function"
}
]
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"function": {
"arguments": "{"reservation_id":"FQ8APE","total_baggages":3,"nonfree_baggages":0,"payment_id":"gift_card_8190333"}",
"name": "update_reservation_baggages"
},
"id": "call_PA1XaKLPX8egjewaxIArCkRc",
"type": "function"
}
]
},
{
"role": "assistant",
"content": "Your reservation has been successfully updated with the following changes:\n\n1. **Passenger Change**: The passenger is now Omar Rossi.\n2. **Cabin Upgrade**: Upgraded to economy class.\n3. **Checked Baggage**: Added three checked bags, all free due to your gold membership.\n\nThe payment for the cabin upgrade was processed using your gift card. If you have any more questions or need further assistance, feel free to ask!",
},
{
"role": "user",
"content": "Thank you for helping with the changes! That's all for now. ###STOP###"
}
],
}
但坦白来说今年在产品设计上的新尝试也挺多的,使用 AI 做了很多奇怪的东西(甚至自己一个人就用 40 块搞了一个网站出来),做了很多面向电视大屏,手机和各种移动设备的产品出来,但这些东西终归是属于小打小闹,我也不好意思平常写在博客和大家分享,等我觉得搞的差不多或者真的挺有意思再和大家分享吧。
说到 AI 不可避免还是要聊聊 AI 对产业的冲突,其实之前我也在博客里写过一些对 AI 的分析,截止目前我依然觉得“AI 工具还是适合那些有一定经验的开发者,不管是快速搭出原型,还是学习一个新的技术和工具。以后 AI 肯定会更智能更聪明,但做出一款好的产品还是要靠设计者的同理心与感知世界的能力。也别想的用 AI 来彻底降本增效了,AI 应该用来加速试错和优化迭代,而不是直接取代已有的软件设计与开发方式”。
大家都在研究怎么用 AI 打造一些趁手的工具,但有时间的话也可以抬头想想一些“飘在风中的问题”,比如“我们这种碳基大模型的下一步发展方向在何处?”,“产品设计师应该专注于创造工具,还是尝试和工具互相影响?”……
PPO 用 Reward Model 计算大模型完整输出的奖励分数(r),过程中会跟原始模型的输出做对比(KL),避免偏离太远。大模型每步 token 输出,都会经过 Value Model 判定输出对后续奖励的期望值(v),经过 GAE 函数计算每步动作的好坏程度,更新我们在训练的大模型 Policy Model 参数。
GRPO 去掉了 Value Model,对每个输入(q)输出多个结果o1 o2 o3 …,奖励模型判断这些结果的好坏,从中选出最好的,更新模型参数。对算法和公式更详细的介绍,推荐这两个讲解:(1),(2)
2. Aha moment:训练过程中模型学会了停下来重新评估前面的思考,而且使用拟人的口气进行了反思。强化学习过程中人类没有输入任何类似的反思引导,模型能自主进行这种反思,十分有趣。我理解为,在预训练的模型里,模型已经有这样的反思意识潜力,在训练的某次输出过程中偶然出现,而出现后的结果对复杂推理有帮助,强化学习的机制会持续鼓励这样的输出。
训练的结果,在推理相关的 benchmark上,基本达到 o1 的水平:
R1-Zero 有非常有趣的发现,即不做监督学习,仅对预训练模型进行强化学习这条路是 OK 的,最终的模型有媲美o1的推理能力,但当前这种方式训练出的 R1-Zero 实际对外使用会有些问题,主要是对人不友好,比如输出的内容中英文混杂,猜测是奖励模型并没有做这种人类阅读友好的奖励判定,模型没理由能做好这块。
R1
为了做出一个推理能力强,输出对人类友好,综合能力 OK 的模型,DeepSeek 另外训练了R1模型。
You are OpenHands agent, a helpful AI assistant that can interact with a computer to solve tasks.
<IMPORTANT>
//
* If user provides a path, you should NOT assume it's relative to the current working directory. Instead, you should explore the file system to find the file before working on it.
* When configuring git credentials, use "openhands" as the user.name and "openhands@all-hands.dev" as the user.email by default, unless explicitly instructed otherwise.
* The assistant MUST NOT include comments in the code unless they are necessary to describe non-obvious behavior.
RuntimeInfo(available_hosts={'http://localhost:54090': 54090, 'http://localhost:55602': 55602})
</IMPORTANT>
<RUNTIME_INFORMATION>
The user has access to the following hosts for accessing a web application,
each of which has a corresponding port:
* http://localhost:54090 (port 54090)
* http://localhost:55602 (port 55602)
When starting a web server, use the corresponding ports. You should also
set any options to allow iframes and CORS requests.
</RUNTIME_INFORMATION>
You have access to the following functions:
---- BEGIN FUNCTION #1: execute_bash ----
Description: Execute a bash command in the terminal.
* Long running commands: For commands that may run indefinitely, it should be run in the background and the output should be redirected to a file, e.g. command = `python3 app.py > server.log 2>&1 &`.
* Interactive: If a bash command returns exit code `-1`, this means the process is not yet finished. The assistant must then send a second call to terminal with an empty `command` (which will retrieve any additional logs), or it can send additional text (set `command` to the text) to STDIN of the running process, or it can send command like `C-c` (Ctrl+C) to interrupt the process.
Parameters:
(1) command (string, required): The bash command to execute. Can be empty string to view additional logs when previous exit code is `-1`. Can be `C-c` (Ctrl+C) to interrupt the currently running process.
---- END FUNCTION #1 ----
---- BEGIN FUNCTION #2: finish ----
Description: Finish the interaction when the task is complete OR if the assistant cannot proceed further with the task.
No parameters are required for this function.
---- END FUNCTION #2 ----
---- BEGIN FUNCTION #3: web_read ----
Description: Read (convert to markdown) content from a webpage. You should prefer using the `web_read` tool over the `browser` tool, but do use the `browser` tool if you need to interact with a webpage (e.g., click a button, fill out a form, etc.).
You may use the `web_read` tool to read content from a webpage, and even search the webpage content using a Google search query (e.g., url=`https://www.google.com/search?q=YOUR_QUERY`).
Parameters:
(1) url (string, required): The URL of the webpage to read. You can also use a Google search query here (e.g., `https://www.google.com/search?q=YOUR_QUERY`).
---- END FUNCTION #3 ----
---- BEGIN FUNCTION #4: browser ----
Description: Interact with the browser using Python code. Use it ONLY when you need to interact with a webpage.
See the description of "code" parameter for more details.
Multiple actions can be provided at once, but will be executed sequentially without any feedback from the page.
More than 2-3 actions usually leads to failure or unexpected behavior. Example:
fill('a12', 'example with "quotes"')
click('a51')
click('48', button='middle', modifiers=['Shift'])
Parameters:
(1) code (string, required): The Python code that interacts with the browser.
The following 15 functions are available. Nothing else is supported.
goto(url: str)
Description: Navigate to a url.
Examples:
goto('http://www.example.com')
go_back()
Description: Navigate to the previous page in history.
Examples:
go_back()
go_forward()
Description: Navigate to the next page in history.
Examples:
go_forward()
noop(wait_ms: float = 1000)
Description: Do nothing, and optionally wait for the given time (in milliseconds).
You can use this to get the current page content and/or wait for the page to load.
Examples:
noop()
noop(500)
scroll(delta_x: float, delta_y: float)
Description: Scroll horizontally and vertically. Amounts in pixels, positive for right or down scrolling, negative for left or up scrolling. Dispatches a wheel event.
Examples:
scroll(0, 200)
scroll(-50.2, -100.5)
fill(bid: str, value: str)
Description: Fill out a form field. It focuses the element and triggers an input event with the entered text. It works for <input>, <textarea> and [contenteditable] elements.
Examples:
fill('237', 'example value')
fill('45', 'multi-line
example')
fill('a12', 'example with "quotes"')
select_option(bid: str, options: str | list[str])
Description: Select one or multiple options in a <select> element. You can specify option value or label to select. Multiple options can be selected.
Examples:
select_option('a48', 'blue')
select_option('c48', ['red', 'green', 'blue'])
click(bid: str, button: Literal['left', 'middle', 'right'] = 'left', modifiers: list[typing.Literal['Alt', 'Control', 'ControlOrMeta', 'Meta', 'Shift']] = [])
Description: Click an element.
Examples:
click('a51')
click('b22', button='right')
click('48', button='middle', modifiers=['Shift'])
dblclick(bid: str, button: Literal['left', 'middle', 'right'] = 'left', modifiers: list[typing.Literal['Alt', 'Control', 'ControlOrMeta', 'Meta', 'Shift']] = [])
Description: Double click an element.
Examples:
dblclick('12')
dblclick('ca42', button='right')
dblclick('178', button='middle', modifiers=['Shift'])
hover(bid: str)
Description: Hover over an element.
Examples:
hover('b8')
press(bid: str, key_comb: str)
Description: Focus the matching element and press a combination of keys. It accepts the logical key names that are emitted in the keyboardEvent.key property of the keyboard events: Backquote, Minus, Equal, Backslash, Backspace, Tab, Delete, Escape, ArrowDown, End, Enter, Home, Insert, PageDown, PageUp, ArrowRight, ArrowUp, F1 - F12, Digit0 - Digit9, KeyA - KeyZ, etc. You can alternatively specify a single character you'd like to produce such as "a" or "#". Following modification shortcuts are also supported: Shift, Control, Alt, Meta, ShiftLeft, ControlOrMeta. ControlOrMeta resolves to Control on Windows and Linux and to Meta on macOS.
Examples:
press('88', 'Backspace')
press('a26', 'ControlOrMeta+a')
press('a61', 'Meta+Shift+t')
focus(bid: str)
Description: Focus the matching element.
Examples:
focus('b455')
clear(bid: str)
Description: Clear the input field.
Examples:
clear('996')
drag_and_drop(from_bid: str, to_bid: str)
Description: Perform a drag & drop. Hover the element that will be dragged. Press left mouse button. Move mouse to the element that will receive the drop. Release left mouse button.
Examples:
drag_and_drop('56', '498')
upload_file(bid: str, file: str | list[str])
Description: Click an element and wait for a "filechooser" event, then select one or multiple input files for upload. Relative file paths are resolved relative to the current working directory. An empty list clears the selected files.
Examples:
upload_file('572', '/home/user/my_receipt.pdf')
upload_file('63', ['/home/bob/Documents/image.jpg', '/home/bob/Documents/file.zip'])
---- END FUNCTION #4 ----
---- BEGIN FUNCTION #5: execute_ipython_cell ----
Description: Run a cell of Python code in an IPython environment.
* The assistant should define variables and import packages before using them.
* The variable defined in the IPython environment will not be available outside the IPython environment (e.g., in terminal).
Parameters:
(1) code (string, required): The Python code to execute. Supports magic commands like %pip.
---- END FUNCTION #5 ----
---- BEGIN FUNCTION #6: str_replace_editor ----
Description: Custom editing tool for viewing, creating and editing files
* State is persistent across command calls and discussions with the user
* If `path` is a file, `view` displays the result of applying `cat -n`. If `path` is a directory, `view` lists non-hidden files and directories up to 2 levels deep
* The `create` command cannot be used if the specified `path` already exists as a file
* If a `command` generates a long output, it will be truncated and marked with `<response clipped>`
* The `undo_edit` command will revert the last edit made to the file at `path`
Notes for using the `str_replace` command:
* The `old_str` parameter should match EXACTLY one or more consecutive lines from the original file. Be mindful of whitespaces!
* If the `old_str` parameter is not unique in the file, the replacement will not be performed. Make sure to include enough context in `old_str` to make it unique
* The `new_str` parameter should contain the edited lines that should replace the `old_str`
Parameters:
(1) command (string, required): The commands to run. Allowed options are: `view`, `create`, `str_replace`, `insert`, `undo_edit`.
Allowed values: [`view`, `create`, `str_replace`, `insert`, `undo_edit`]
(2) path (string, required): Absolute path to file or directory, e.g. `/workspace/file.py` or `/workspace`.
(3) file_text (string, optional): Required parameter of `create` command, with the content of the file to be created.
(4) old_str (string, optional): Required parameter of `str_replace` command containing the string in `path` to replace.
(5) new_str (string, optional): Optional parameter of `str_replace` command containing the new string (if not given, no string will be added). Required parameter of `insert` command containing the string to insert.
(6) insert_line (integer, optional): Required parameter of `insert` command. The `new_str` will be inserted AFTER the line `insert_line` of `path`.
(7) view_range (array, optional): Optional parameter of `view` command when `path` points to a file. If none is given, the full file is shown. If provided, the file will be shown in the indicated line number range, e.g. [11, 12] will show lines 11 and 12. Indexing at 1 to start. Setting `[start_line, -1]` shows all lines from `start_line` to the end of the file.
---- END FUNCTION #6 ----
If you choose to call a function ONLY reply in the following format with NO suffix:
<function=example_function_name>
<parameter=example_parameter_1>value_1</parameter>
<parameter=example_parameter_2>
This is the value for the second parameter
that can span
multiple lines
</parameter>
</function>
<IMPORTANT>
Reminder:
- Function calls MUST follow the specified format, start with <function= and end with </function>
- Required parameters MUST be specified
- Only call one function at a time
- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after.
- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls
----------
Here's a running example of how to perform a task with the provided tools.
--------------------- START OF EXAMPLE ---------------------
USER: Create a list of numbers from 1 to 10, and display them in a web page at port 5000.
ASSISTANT: Sure! Let me first check the current directory:
<function=execute_bash>
<parameter=command>
pwd && ls
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
/workspace
openhands@runtime:~/workspace$
ASSISTANT: There is no `app.py` file in the current directory. Let me create a Python file `app.py`:
<function=str_replace_editor>
<parameter=command>create</parameter>
<parameter=path>/workspace/app.py</parameter>
<parameter=file_text>
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
numbers = list(range(1, 11))
return str(numbers)
if __name__ == '__main__':
app.run(port=5000)
</parameter>
</function>
USER: EXECUTION RESULT of [str_replace_editor]:
File created successfully at: /workspace/app.py
ASSISTANT: I have created a Python file `app.py` that will display a list of numbers from 1 to 10 when you run it. Let me run the Python file for you:
<function=execute_bash>
<parameter=command>
python3 app.py > server.log 2>&1 &
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
[1] 121
[1]+ Exit 1 python3 app.py > server.log 2>&1
ASSISTANT: Looks like the server is running with PID 121 then crashed. Let me check the server log:
<function=execute_bash>
<parameter=command>
cat server.log
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
Traceback (most recent call last):
File "/workspace/app.py", line 2, in <module>
from flask import Flask
ModuleNotFoundError: No module named 'flask'
ASSISTANT: Looks like the server crashed because the `flask` module is not installed. Let me install the `flask` module for you:
<function=execute_bash>
<parameter=command>
pip3 install flask
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
Defaulting to user installation because normal site-packages is not writeable
Collecting flask
Using cached flask-3.0.3-py3-none-any.whl (101 kB)
Collecting blinker>=1.6.2
Using cached blinker-1.7.0-py3-none-any.whl (13 kB)
Collecting Werkzeug>=3.0.0
Using cached werkzeug-3.0.2-py3-none-any.whl (226 kB)
Collecting click>=8.1.3
Using cached click-8.1.7-py3-none-any.whl (97 kB)
Collecting itsdangerous>=2.1.2
Using cached itsdangerous-2.2.0-py3-none-any.whl (16 kB)
Requirement already satisfied: Jinja2>=3.1.2 in /home/openhands/.local/lib/python3.10/site-packages (from flask) (3.1.3)
Requirement already satisfied: MarkupSafe>=2.0 in /home/openhands/.local/lib/python3.10/site-packages (from Jinja2>=3.1.2->flask) (2.1.5)
Installing collected packages: Werkzeug, itsdangerous, click, blinker, flask
Successfully installed Werkzeug-3.0.2 blinker-1.7.0 click-8.1.7 flask-3.0.3 itsdangerous-2.2.0
ASSISTANT: The `flask` module is installed successfully. Let me run the Python file again:
<function=execute_bash>
<parameter=command>
python3 app.py > server.log 2>&1 &
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
[1] 124
ASSISTANT:
Let me check the server log again:
<function=execute_bash>
<parameter=command>
cat server.log
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
* Serving Flask app 'app'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:5000
Press CTRL+C to quit
ASSISTANT:
The server is running on port 5000 with PID 124. You can access the list of numbers by visiting http://127.0.0.1:5000. If you have any further questions, feel free to ask!
USER: Now kill the server, make it display the numbers in a table format.
ASSISTANT:
Sure! Let me stop the server first:
<function=execute_bash>
<parameter=command>
kill 124
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
[1]+ Terminated python3 app.py > server.log 2>&1
ASSISTANT:
Now let me display the numbers in a table format:
<function=str_replace_editor>
<parameter=command>str_replace</parameter>
<parameter=path>/workspace/app.py</parameter>
<parameter=old_str>return str(numbers)</parameter>
<parameter=new_str>return '<table>' + ''.join([f'<tr><td>{i}</td></tr>' for i in numbers]) + '</table>'</parameter>
</function>
USER: EXECUTION RESULT of [str_replace_editor]:
The file /workspace/app.py has been edited. Here's the result of running `cat -n` on a snippet of /workspace/app.py:
3
4 @app.route('/')
5 def index():
6 numbers = list(range(1, 11))
7 return '<table>' + ''.join([f'<tr><td>{i}</td></tr>' for i in numbers]) + '</table>'
8
9 if __name__ == '__main__':
10 app.run(port=5000)
Review the changes and make sure they are as expected. Edit the file again if necessary.
ASSISTANT:
Running the updated file:
<function=execute_bash>
<parameter=command>
<parameter=command>
python3 app.py > server.log 2>&1 &
</parameter>
</function>
USER: EXECUTION RESULT of [execute_bash]:
[1] 126
ASSISTANT:
The server is running on port 5000 with PID 126. You can access the list of numbers in a table format by visiting http://127.0.0.1:5000. Let me know if you have any further requests!
<function=finish>
</function>
--------------------- END OF EXAMPLE ---------------------
Do NOT assume the environment is the same as in the example above.
附:任务 Prompt示例
以下是真实执行一个任务时,循环添加输入 LLM 的 Prompt case:
--------------------- NEW TASK DESCRIPTION ---------------------
创建一个可以调用deepseek模型的程序,并运行测试确保可用
--------------------- END OF NEW TASK DESCRIPTION ---------------------
PLEASE follow the format strictly! PLEASE EMIT ONE AND ONLY ONE FUNCTION CALL PER MESSAGE.
----------
Let me start by checking the current directory and listing its contents:
<function=execute_bash>
<parameter=command>pwd && ls</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
/workspace
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 0]
----------
I see we are in the `/workspace` directory. Let's create a Python file that can call the DeepSeek model. First, I'll create a new file called `deepseek_app.py`:
<function=str_replace_editor>
<parameter=command>create</parameter>
<parameter=path>/workspace/deepseek_app.py</parameter>
<parameter=file_text>
from deepseek import DeepSeekModel
def call_deepseek_model(input_text):
model = DeepSeekModel()
response = model.generate(input_text)
return response
if __name__ == "__main__":
test_input = "Hello, DeepSeek!"
result = call_deepseek_model(test_input)
print("Model Response:", result)
</parameter>
</function>
----------
EXECUTION RESULT of [str_replace_editor]:
File created successfully at: /workspace/deepseek_app.py
----------
Now, let's check if the `deepseek` module is installed. If not, we'll need to install it:
<function=execute_bash>
<parameter=command>pip3 show deepseek</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
WARNING: Package(s) not found: deepseek
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 1]
----------
The `deepseek` module is not installed. Let me install it using pip:
<function=execute_bash>
<parameter=command>pip3 install deepseek</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Collecting deepseek
Downloading deepseek-1.0.0-py3-none-any.whl.metadata (3.9 kB)
Requirement already satisfied: requests in /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages (from deepseek) (2.32.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages (from requests->deepseek) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages (from requests->deepseek) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages (from requests->deepseek) (2.3.0)
Requirement already satisfied: certifi>=2017.4.17 in /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages (from requests->deepseek) (2024.12.14)
Downloading deepseek-1.0.0-py3-none-any.whl (4.5 kB)
Installing collected packages: deepseek
Successfully installed deepseek-1.0.0
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 0]
----------
The `deepseek` module is now installed. Let's run the `deepseek_app.py` program to test if it works:
<function=execute_bash>
<parameter=command>python3 deepseek_app.py</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Traceback (most recent call last):
File "/workspace/deepseek_app.py", line 1, in <module>
from deepseek import DeepSeekModel
ImportError: cannot import name 'DeepSeekModel' from 'deepseek' (/openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages/deepseek/__init__.py)
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 1]
----------
It seems the `DeepSeekModel` class is not available in the `deepseek` module. Let me check the documentation or available classes in the `deepseek` module:
<function=execute_bash>
<parameter=command>python3 -c "import deepseek; print(dir(deepseek))"</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
['DeepSeekAPI', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', 'api', 'const']
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 0]
----------
The `deepseek` module provides a `DeepSeekAPI` class instead of `DeepSeekModel`. Let me update the `deepseek_app.py` file to use the correct class:
<function=str_replace_editor>
<parameter=command>str_replace</parameter>
<parameter=path>/workspace/deepseek_app.py</parameter>
<parameter=old_str>
from deepseek import DeepSeekModel
def call_deepseek_model(input_text):
model = DeepSeekModel()
response = model.generate(input_text)
return response
</parameter>
<parameter=new_str>
from deepseek import DeepSeekAPI
def call_deepseek_model(input_text):
api = DeepSeekAPI()
response = api.generate(input_text)
return response
</parameter>
</function>
----------
EXECUTION RESULT of [str_replace_editor]:
The file /workspace/deepseek_app.py has been edited. Here's the result of running `cat -n` on a snippet of /workspace/deepseek_app.py:
1 from deepseek import DeepSeekAPI
2
3 def call_deepseek_model(input_text):
4 api = DeepSeekAPI()
5 response = api.generate(input_text)
6 return response
7
8 if __name__ == "__main__":
9 test_input = "Hello, DeepSeek!"
10 result = call_deepseek_model(test_input)
Review the changes and make sure they are as expected. Edit the file again if necessary.
----------
Now that the file is updated, let's run the program again to test if it works:
<function=execute_bash>
<parameter=command>python3 deepseek_app.py</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Traceback (most recent call last):
File "/workspace/deepseek_app.py", line 10, in <module>
result = call_deepseek_model(test_input)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/deepseek_app.py", line 4, in call_deepseek_model
api = DeepSeekAPI()
^^^^^^^^^^^^^
File "/openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages/deepseek/api.py", line 9, in __init__
raise ValueError("DEEPSEEK_API_KEY is missing")
ValueError: DEEPSEEK_API_KEY is missing
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 1]
----------
The program requires an API key to use the `DeepSeekAPI`. Let me update the program to include the API key as an environment variable. First, I'll modify the `deepseek_app.py` file:
<function=str_replace_editor>
<parameter=command>str_replace</parameter>
<parameter=path>/workspace/deepseek_app.py</parameter>
<parameter=old_str>
from deepseek import DeepSeekAPI
def call_deepseek_model(input_text):
api = DeepSeekAPI()
response = api.generate(input_text)
return response
</parameter>
<parameter=new_str>
import os
from deepseek import DeepSeekAPI
def call_deepseek_model(input_text):
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("Please set the DEEPSEEK_API_KEY environment variable.")
api = DeepSeekAPI(api_key=api_key)
response = api.generate(input_text)
return response
</parameter>
</function>
----------
EXECUTION RESULT of [str_replace_editor]:
The file /workspace/deepseek_app.py has been edited. Here's the result of running `cat -n` on a snippet of /workspace/deepseek_app.py:
1 import os
2 from deepseek import DeepSeekAPI
3
4 def call_deepseek_model(input_text):
5 api_key = os.getenv("DEEPSEEK_API_KEY")
6 if not api_key:
7 raise ValueError("Please set the DEEPSEEK_API_KEY environment variable.")
8 api = DeepSeekAPI(api_key=api_key)
9 response = api.generate(input_text)
10 return response
11
12 if __name__ == "__main__":
13 test_input = "Hello, DeepSeek!"
14 result = call_deepseek_model(test_input)
Review the changes and make sure they are as expected. Edit the file again if necessary.
----------
Now, let's set the `DEEPSEEK_API_KEY` environment variable and run the program again. Please provide the API key for DeepSeek, and I will set it up for you. If you don't have one, you may need to sign up for an API key from DeepSeek's official website.
<function=execute_bash>
<parameter=command>export DEEPSEEK_API_KEY=your_api_key_here && python3 deepseek_app.py</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Traceback (most recent call last):
File "/workspace/deepseek_app.py", line 14, in <module>
result = call_deepseek_model(test_input)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/deepseek_app.py", line 9, in call_deepseek_model
response = api.generate(input_text)
^^^^^^^^^^^^
AttributeError: 'DeepSeekAPI' object has no attribute 'generate'
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 1]
----------
It seems the `DeepSeekAPI` class does not have a `generate` method. Let me check the available methods in the `DeepSeekAPI` class:
<function=execute_bash>
<parameter=command>python3 -c "from deepseek import DeepSeekAPI; print(dir(DeepSeekAPI))"</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_post_request', 'chat_completion', 'completion_impl', 'fim_completion', 'get_models', 'user_balance']
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 0]
----------
The `DeepSeekAPI` class provides methods like `chat_completion`, `fim_completion`, and `get_models`. Let's update the `deepseek_app.py` file to use the `chat_completion` method instead of `generate`:
<function=str_replace_editor>
<parameter=command>str_replace</parameter>
<parameter=path>/workspace/deepseek_app.py</parameter>
<parameter=old_str>
api = DeepSeekAPI(api_key=api_key)
response = api.generate(input_text)
return response
</parameter>
<parameter=new_str>
api = DeepSeekAPI(api_key=api_key)
response = api.chat_completion(input_text)
return response
</parameter>
</function>
----------
EXECUTION RESULT of [str_replace_editor]:
The file /workspace/deepseek_app.py has been edited. Here's the result of running `cat -n` on a snippet of /workspace/deepseek_app.py:
4 def call_deepseek_model(input_text):
5 api_key = os.getenv("DEEPSEEK_API_KEY")
6 if not api_key:
7 raise ValueError("Please set the DEEPSEEK_API_KEY environment variable.")
8 api = DeepSeekAPI(api_key=api_key)
9 response = api.chat_completion(input_text)
10 return response
11
12 if __name__ == "__main__":
13 test_input = "Hello, DeepSeek!"
14 result = call_deepseek_model(test_input)
Review the changes and make sure they are as expected. Edit the file again if necessary.
----------
Now, let's run the program again with the updated method. Please provide the `DEEPSEEK_API_KEY` environment variable:
<function=execute_bash>
<parameter=command>export DEEPSEEK_API_KEY=your_api_key_here && python3 deepseek_app.py</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Traceback (most recent call last):
File "/workspace/deepseek_app.py", line 14, in <module>
result = call_deepseek_model(test_input)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/deepseek_app.py", line 9, in call_deepseek_model
response = api.chat_completion(input_text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages/deepseek/api.py", line 62, in chat_completion
response = self._post_request(API_CHAT_COM, payload, stream)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/openhands/poetry/openhands-ai-5O4_aCHf-py3.12/lib/python3.12/site-packages/deepseek/api.py", line 25, in _post_request
raise Exception(f"HTTP Error {response.status_code}: {response.text}")
Exception: HTTP Error 401: {"error":{"message":"Authentication Fails (no such user)","type":"authentication_error","param":null,"code":"invalid_request_error"}}
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 1]
----------
The error indicates that the provided API key is invalid or does not correspond to a valid user. To proceed, you will need to:
1. Obtain a valid API key from DeepSeek's official platform.
2. Ensure the API key is correctly set in the environment.
Once you have a valid API key, you can set it and run the program again. Let me know if you need further assistance!
----------
key: *** ///在这里输入了key,隐藏
----------
Thank you for providing the API key. Let's set the environment variable and run the program again:
<function=execute_bash>
<parameter=command>export DEEPSEEK_API_KEY=sk-4a727097b1ef4e61a3444ec96e1e0db0 && python3 deepseek_app.py</parameter>
</function>
----------
EXECUTION RESULT of [execute_bash]:
Model Response: Hello! How can I assist you today? 😊
[Python Interpreter: /openhands/poetry/openhands-ai-5O4_aCHf-py3.12/bin/python]
[Command finished with exit code 0]
纸质书的购买逐年下降,电子书比重已经达到70%以上。水墨屏阅读体验已经很好,多设备之间阅读进度实时同步,笔记整理效率更高,便携性更高。硬件我用过 KPW1 和 KPW3,更换到小米多看 Pro II 主要为了安装微信读书。而纸质书除了特别经典的,都是逐年在清理。(书架强烈建议买有柜门的,不然没几年书就发黄严重,灰尘还不好清理。)