Android Systrace 流畅性实战 3 :卡顿分析过程中的一些疑问
不同的人对流畅性(卡顿掉帧)有不同的理解,对卡顿阈值也有不同的感知,所以有必要在开始这个系列文章之前,先把涉及到的内容说清楚,防止出现不同的理解,也方便大家带着问题去看这几篇问题,下面是一些基本的说明
- 对手机用户来说,卡顿包含了很多场景,比如在 滑动列表的时候掉帧、应用启动白屏过长、点击电源键亮屏慢、界面操作没有反应然后闪退、点击图标没有响应、窗口动画不连贯、滑动不跟手、重启手机进入桌面卡顿 等场景,这些场景跟我们开发人员所理解的卡顿还有点不一样,开发人员会更加细分去分析这些问题,这是开发人员和用户之间的一个认知差异,这一点在处理用户(或者测试人员)的问题反馈的时候尤其需要注意
- 对开发人员来说,上面的场景包括了 流畅度(滑动列表的时候掉帧、窗口动画不连贯、重启手机进入桌面卡顿)、响应速度(应用启动白屏过长、点击电源键亮屏慢、滑动不跟手)、稳定性(界面操作没有反应然后闪退、点击图标没有响应)这三个大的分类。之所以这么分类,是因为每一种分类都有不太一样的分析方法和步骤,快速分辨问题是属于哪一类很重要
- 在技术上来说,流畅度、响应速度、稳定性(ANR)这三类之所以用户感知都是卡顿,是因为这三类问题产生的原理是一致的,都是由于主线程的 Message 在执行任务的时候超时,根据不同的超时阈值来进行划分而已,所以要理解这些问题,需要对系统的一些基本的运行机制有一定的了解,本文会介绍一些基本的运行机制
- 流畅性这个系列主要是分析流畅度相关的问题,响应速度和稳定性会有专门的文章介绍,在理解了流畅性相关的内容之后,再去分析响应速度和稳定性问题会事半功倍
- 流畅性这个系列主要是讲如何使用 Systrace (Perfetto) 工具去分析,之所以 Systrace 为切入点,是因为影响流畅度的因素很多,有 App 自身的原因、也有系统的原因。而 Systrace(Perfetto) 工具可以从一个整机运行的角度来展示问题发生的过程,方便我们去初步定位问题
Systrace 系列文章如下
- Systrace 简介
- Systrace 基础知识 - Systrace 预备知识
- Systrace 基础知识 - Why 60 fps ?
- Systrace 基础知识 - SystemServer 解读
- Systrace 基础知识 - SurfaceFlinger 解读
- Systrace 基础知识 - Input 解读
- Systrace 基础知识 - Vsync 解读
- Systrace 基础知识 - Vsync-App :基于 Choreographer 的渲染机制详解
- Systrace 基础知识 - MainThread 和 RenderThread 解读
- Systrace 基础知识 - Binder 和锁竞争解读
- Systrace 基础知识 - Triple Buffer 解读
- Systrace 基础知识 - CPU Info 解读
- Systrace 流畅性实战 1 :了解卡顿原理
- Systrace 流畅性实战 2 :案例分析: MIUI 桌面滑动卡顿分析
- Systrace 流畅性实战 3 :卡顿分析过程中的一些疑问
- Systrace 响应速度实战 1 :了解响应速度原理
- Systrace 响应速度实战 2 :响应速度实战分析-以启动速度为例
- Systrace 响应速度实战 3 :响应速度延伸知识
- Systrace 线程 CPU 运行状态分析技巧 - Runnable 篇
- Systrace 线程 CPU 运行状态分析技巧 - Running 篇
- Systrace 线程 CPU 运行状态分析技巧 - Sleep 和 Uninterruptible Sleep 篇
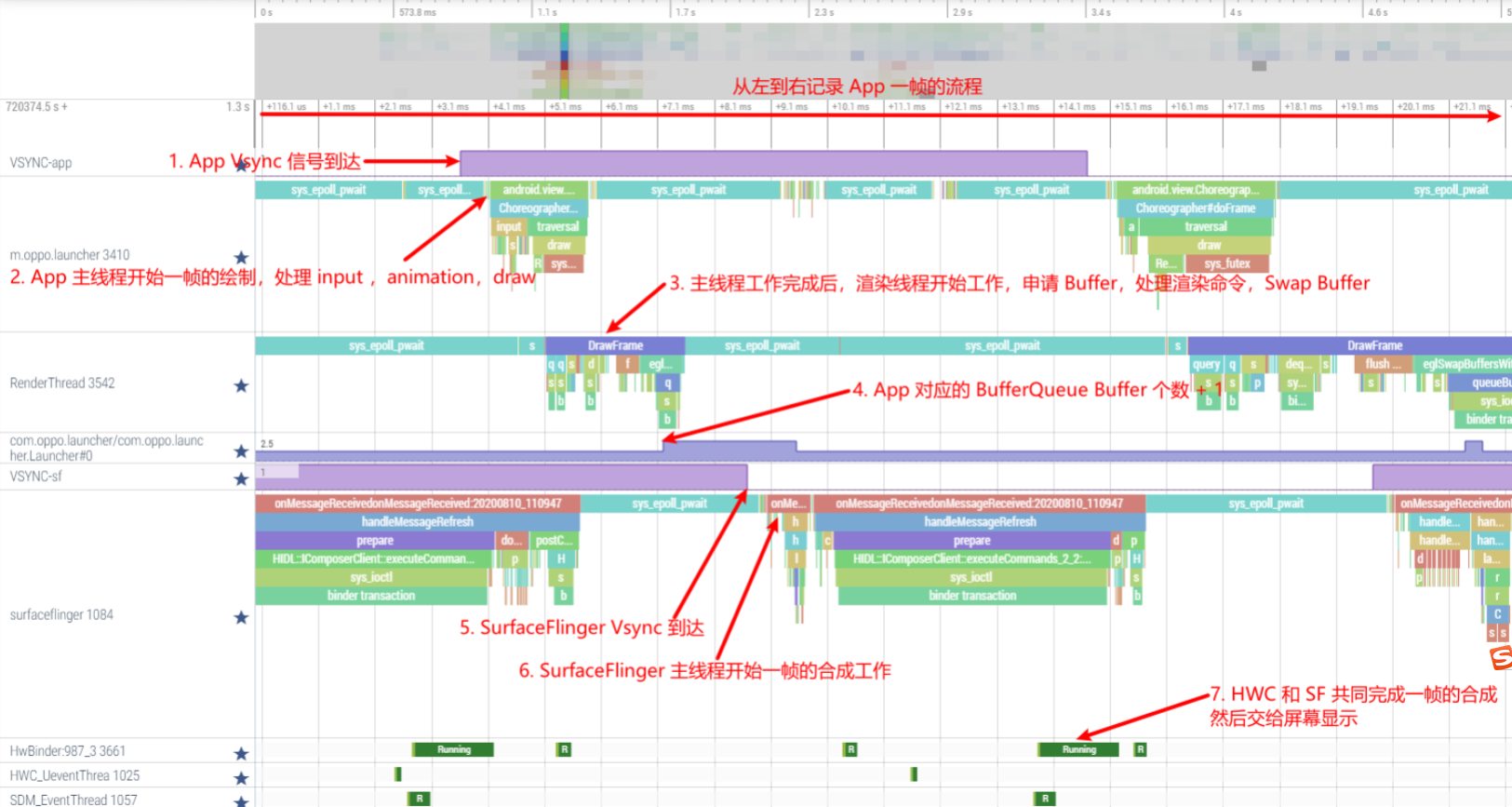
Systrace (Perfetto) 工具的基本使用如果还不是很熟悉,那么需要优先去补一下上面列出的 Systrace 基础知识系列,本文假设你已经熟悉 Systrace(Perfetto)的使用了
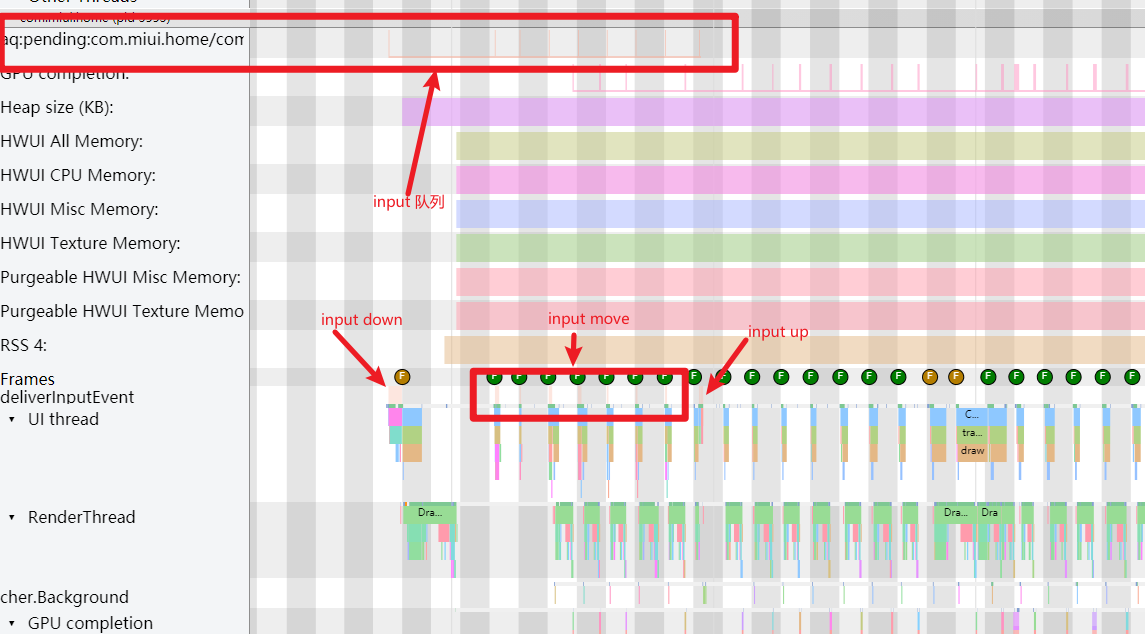
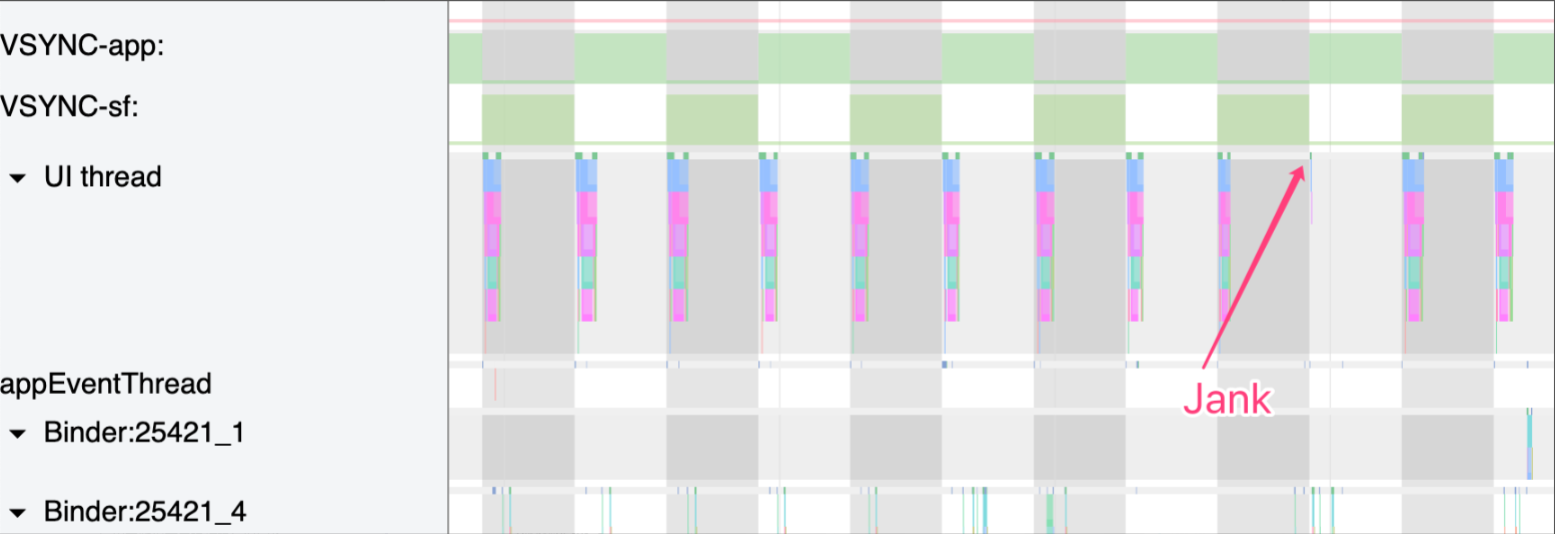
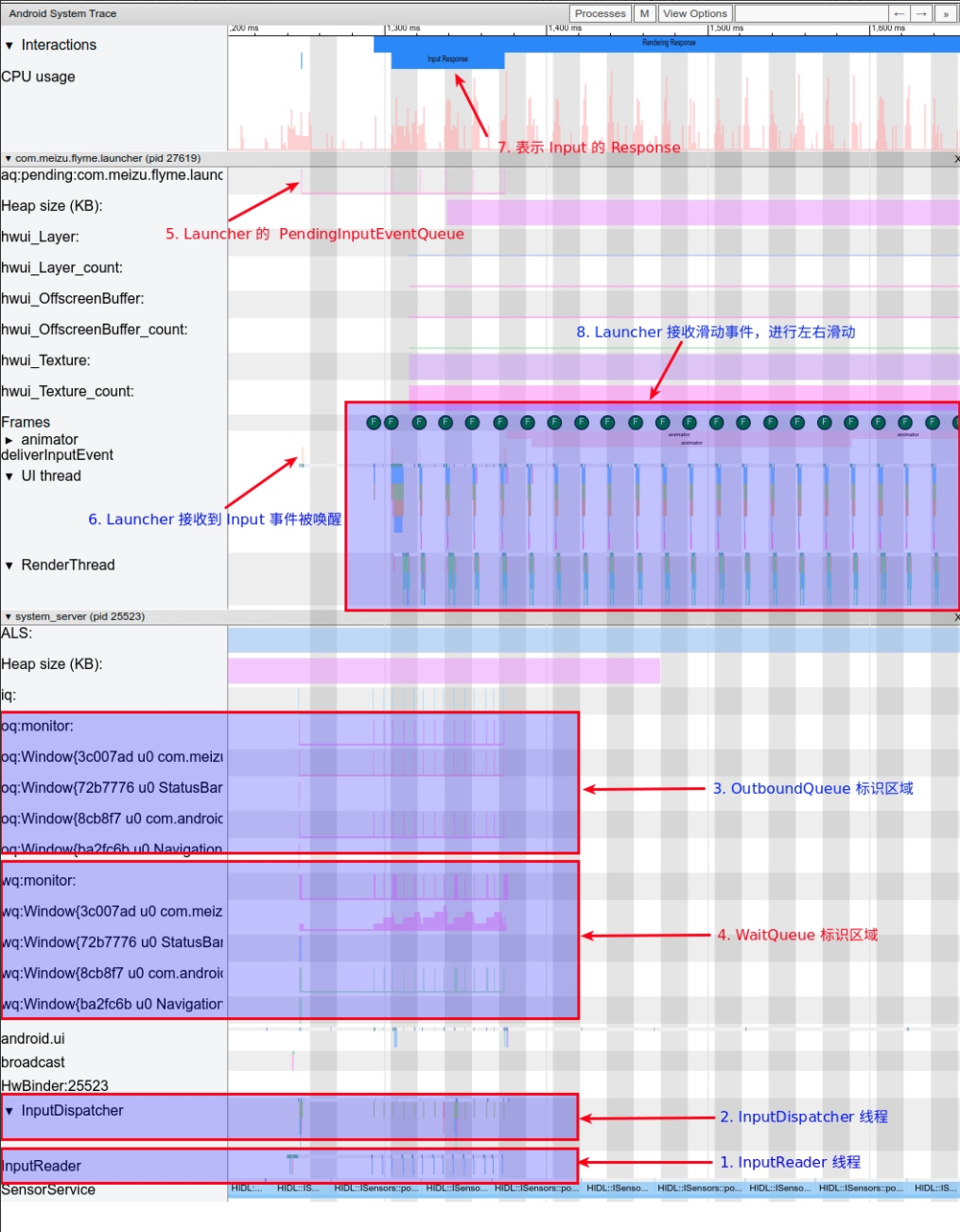
Systrace 的 Frame 颜色是什么意思?
这里的 Frame 标记指的是应用主线程上面那个圈,共有三个颜色,每一帧的耗时不同,则标识的颜色不同
点击这个小圆圈就可以看到这一帧所对应的主线程+渲染线程(会以高亮显示,其他的则变灰显示)
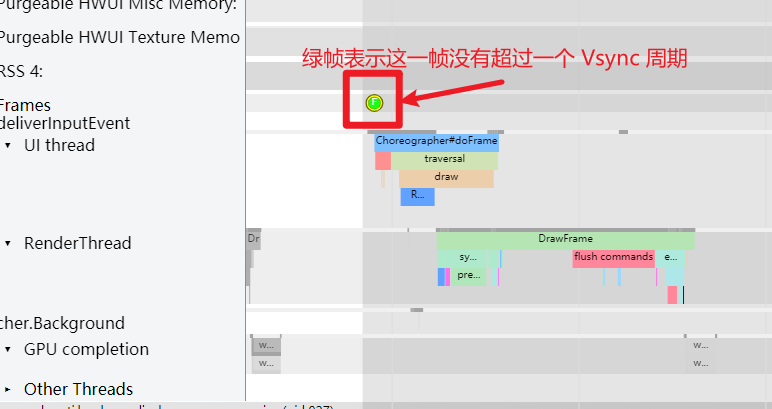
绿帧
绿帧是最常见的帧,表示这一帧在一个 Vsync 周期里面完成
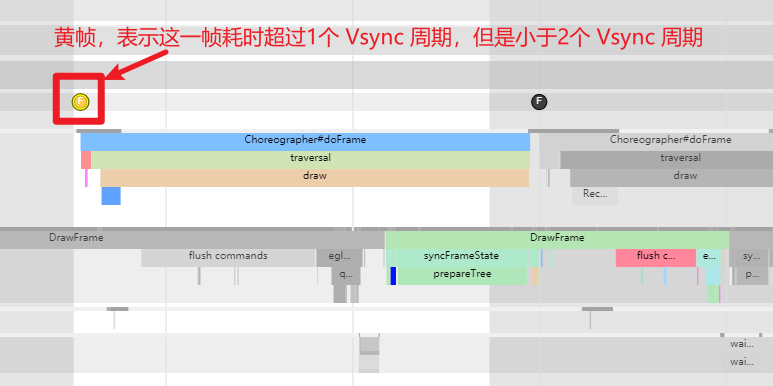
黄帧
黄帧表示这一帧耗时超过1个 Vsync 周期,但是小于 2 个 Vsync 周期。黄帧的出现表示这一帧可能存在性能问题,可能会导致卡顿情况出现
红帧
红帧表示这一帧耗时超过 2 个 Vsync 周期,红帧的出现表示这一帧可能存在性能问题,大概率会导致卡顿情况出现

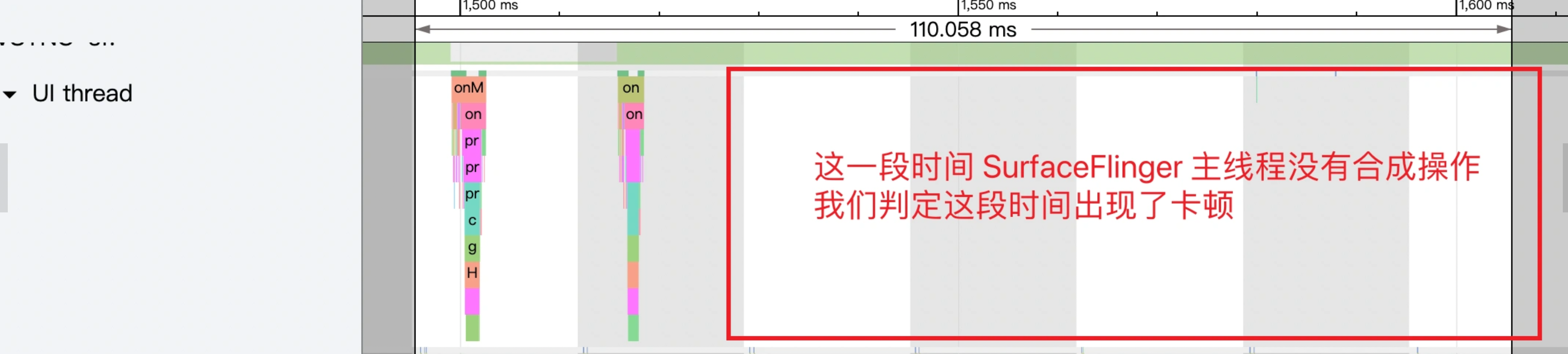
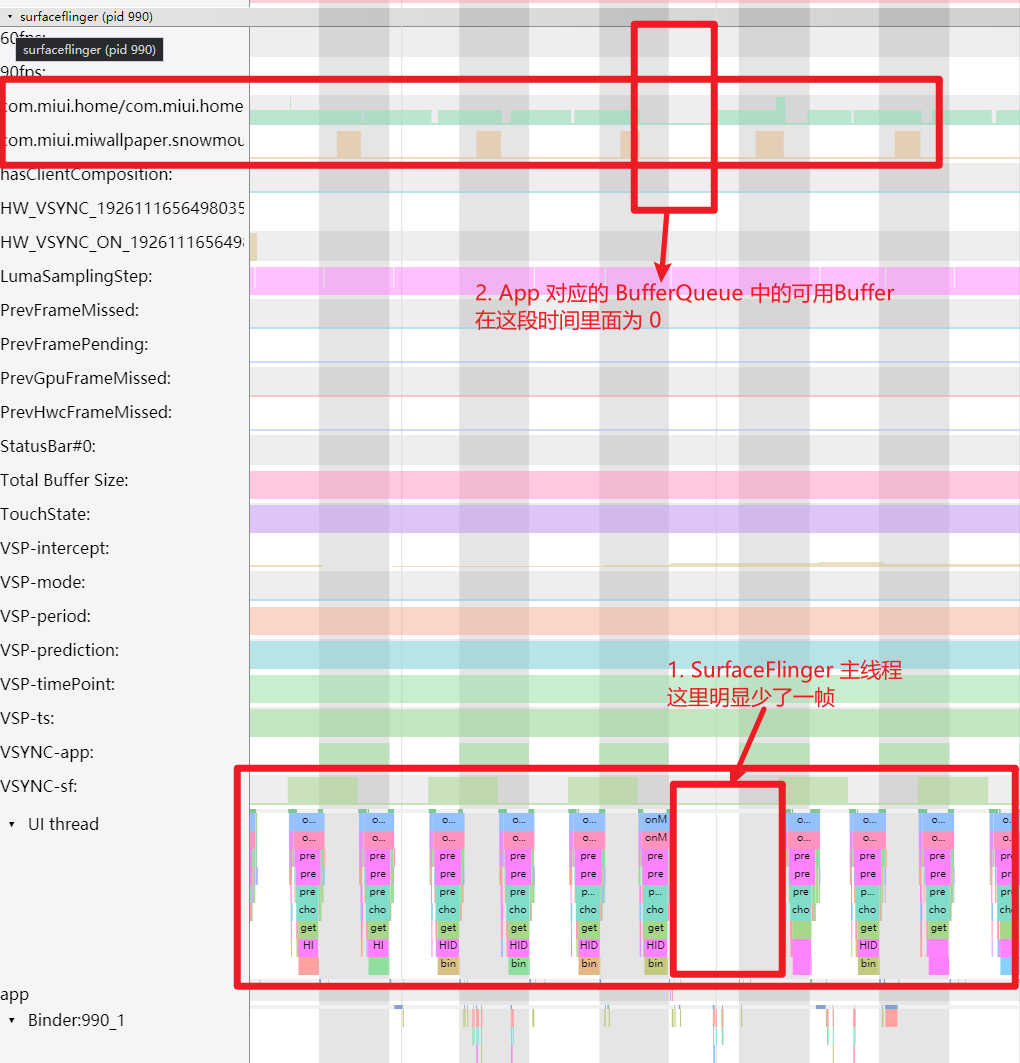
没有红帧就没有掉帧?
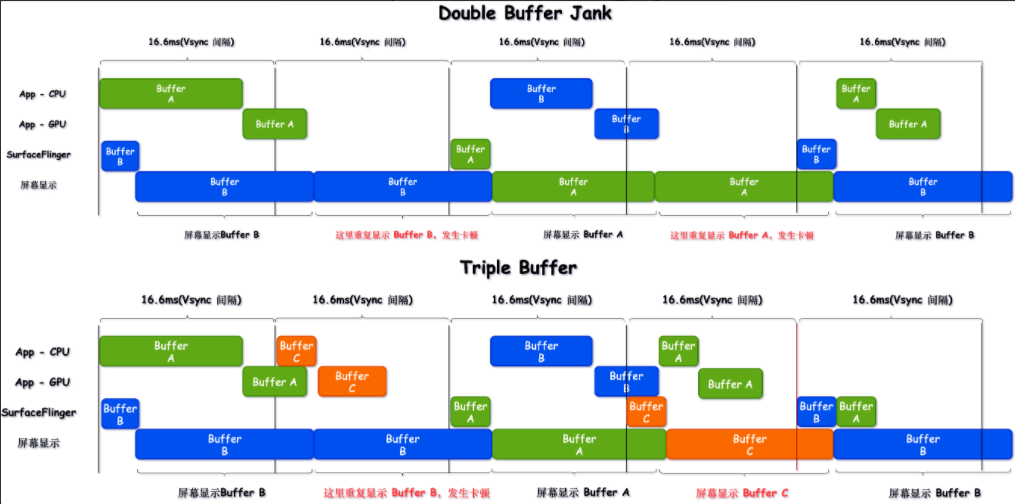
不一定,判断是否掉帧要看 SurfaceFlinger,而不是看 App ,这部分需要有 https://www.androidperformance.com/2019/12/15/Android-Systrace-Triple-Buffer/ 这篇文章的基础
出现黄帧但是不掉帧的情况
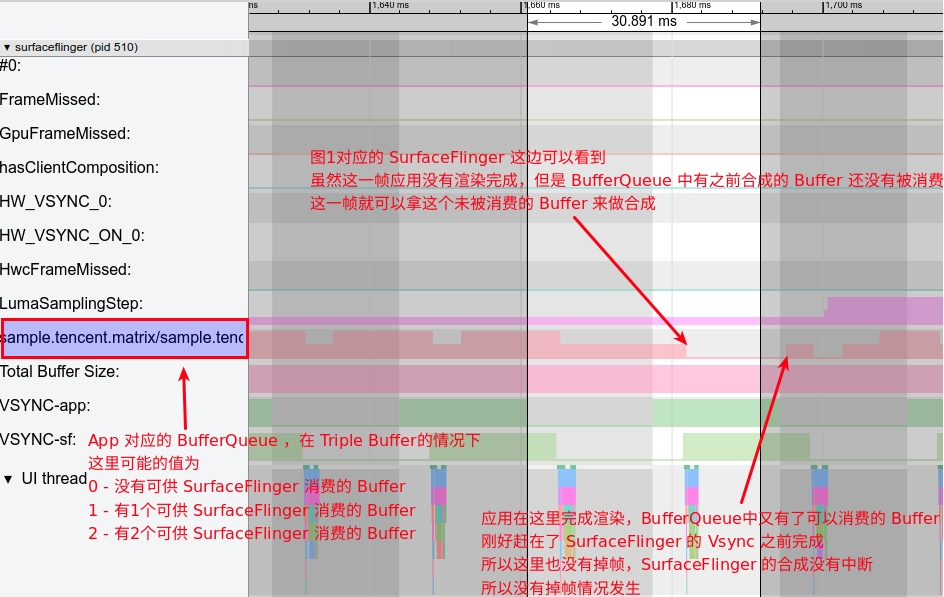
如上所述,红帧和黄帧都表示这一帧存在性能问题,黄帧表示这一帧耗时超过一个 Vsync 周期,但是由于 Android Triple Buffer(现在的高帧率手机会配置更多的 Buffer)的存在,就算 App 主线程这一帧超过一个 Vsync 周期,也会由于多 Buffer 的缓冲,使得这一帧并不会出现掉帧
出现黄帧且掉帧的情况
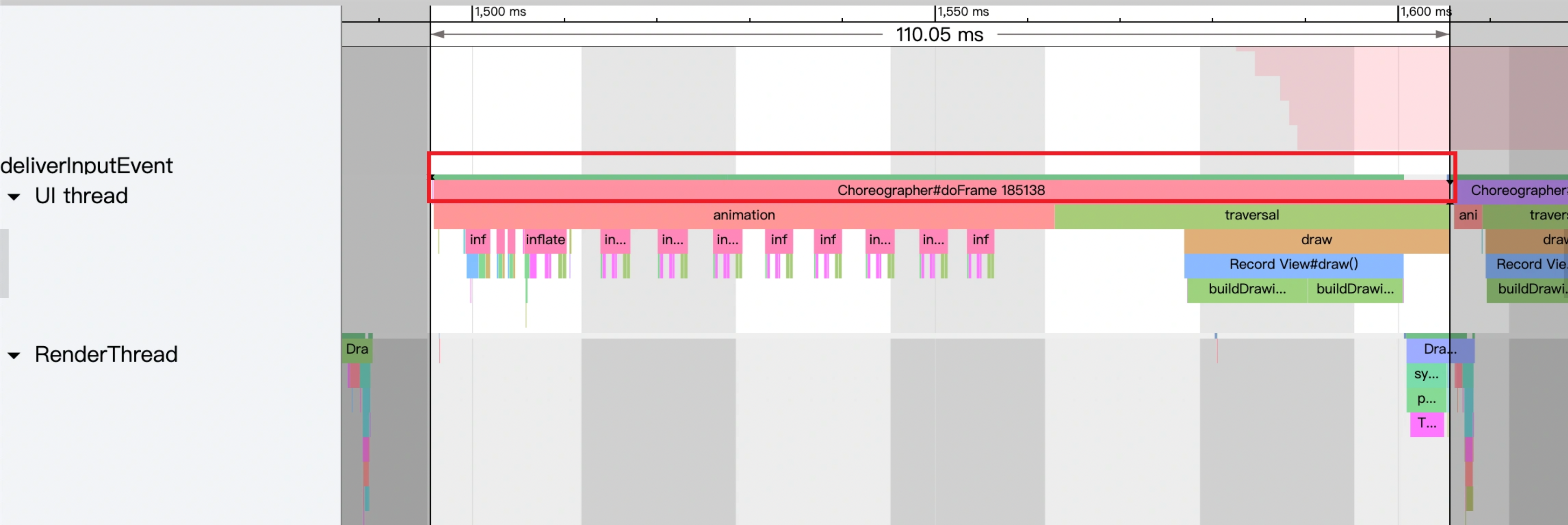
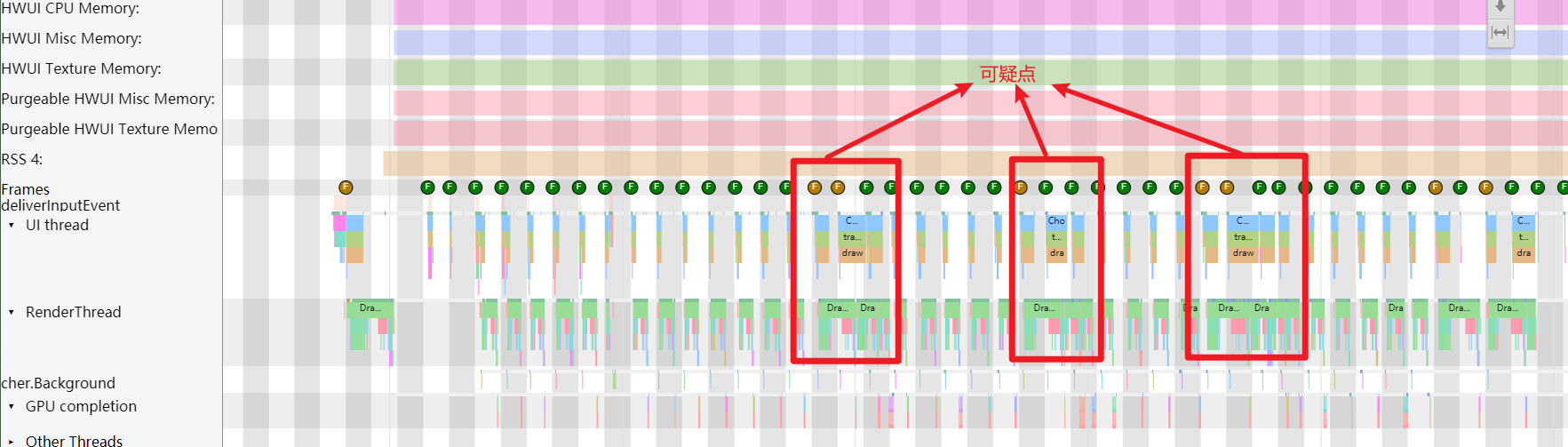
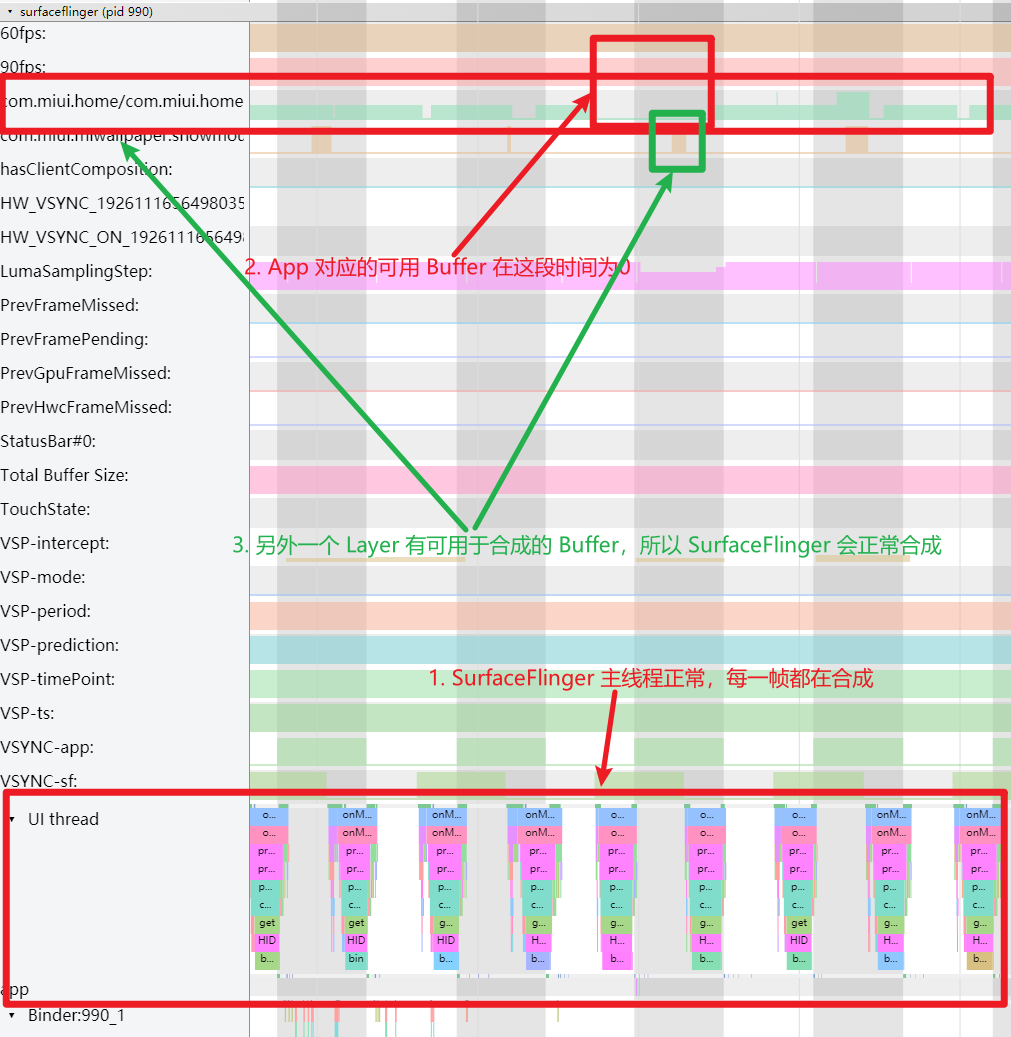
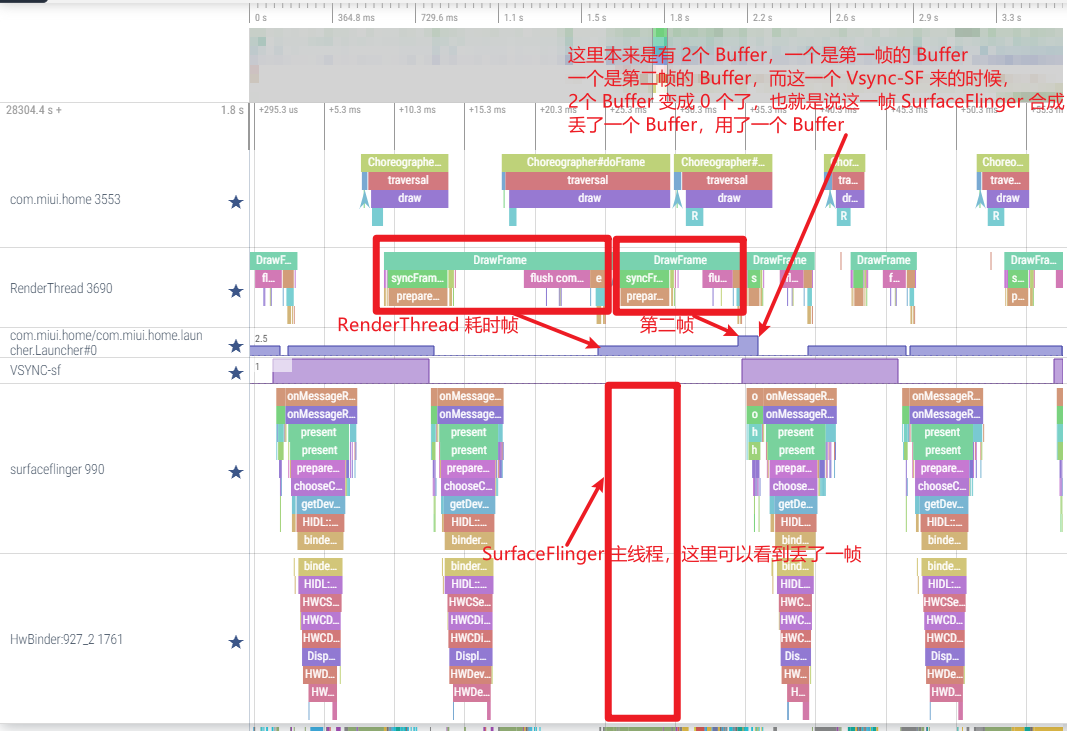
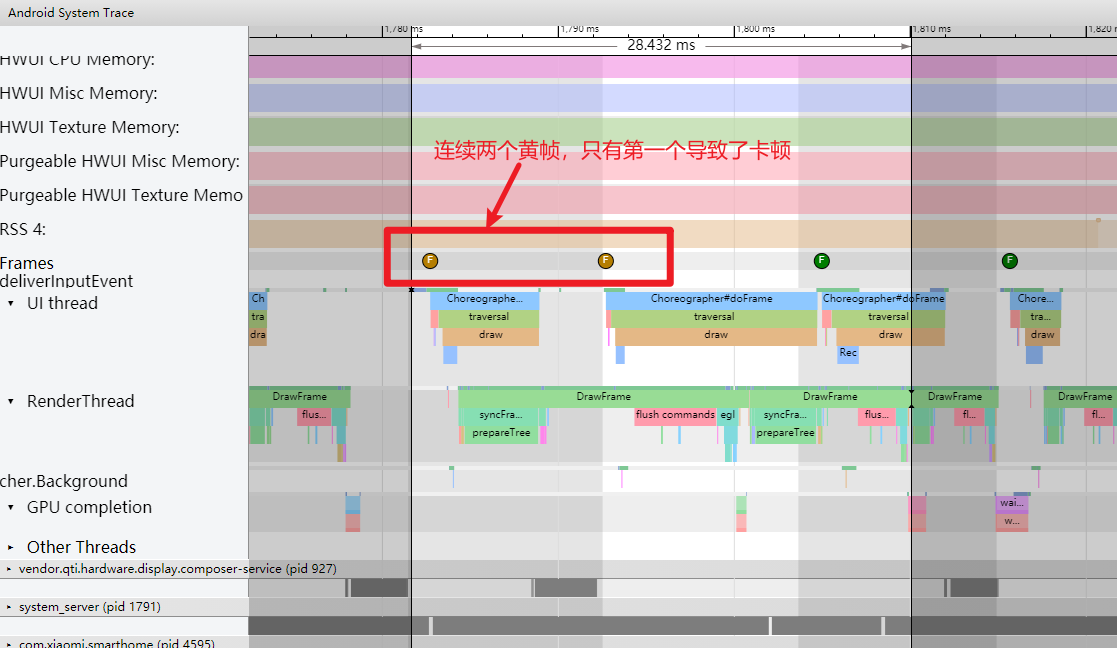
这次分析的 Systrace(见附件),就是没有红帧只有黄帧,连续出现两个黄帧,第一个黄帧导致了卡顿,而第二个黄帧则没有
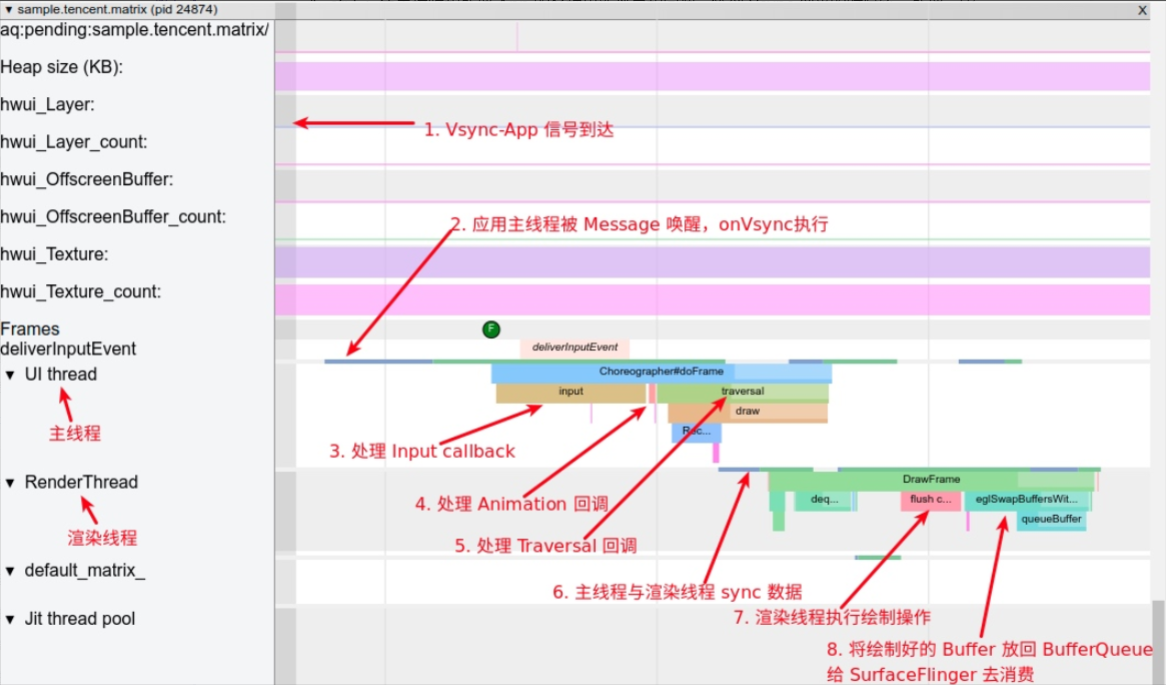
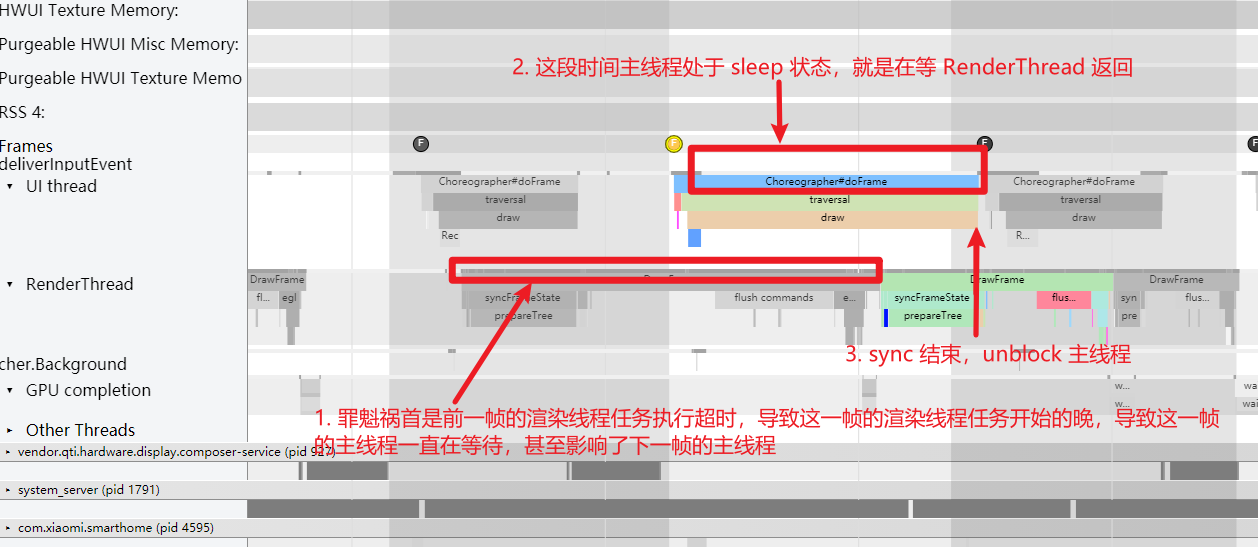
主线程为何要等待渲染线程?
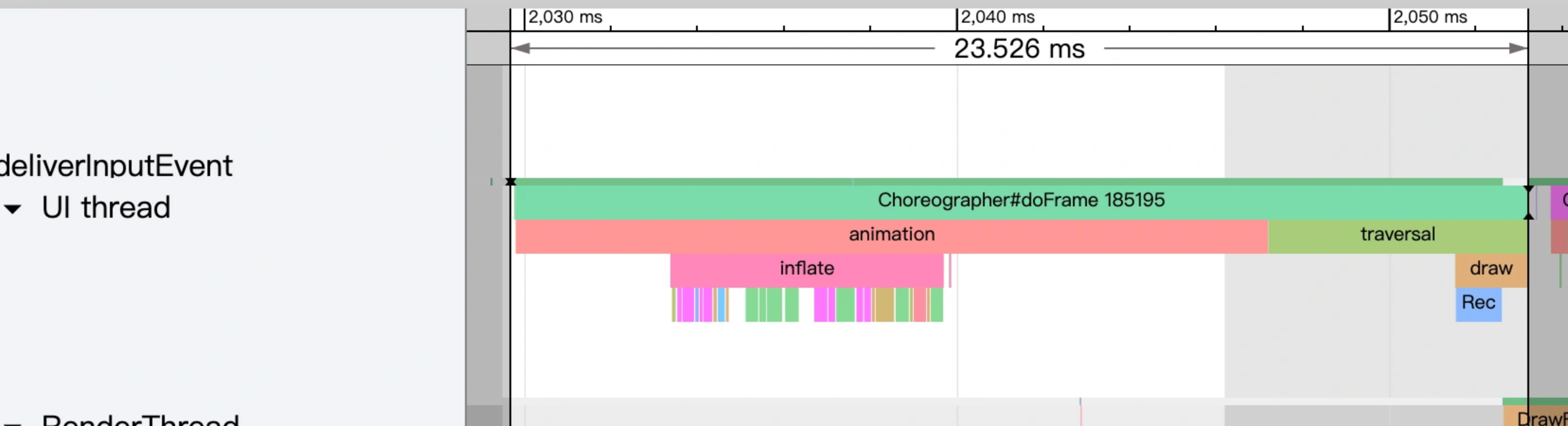
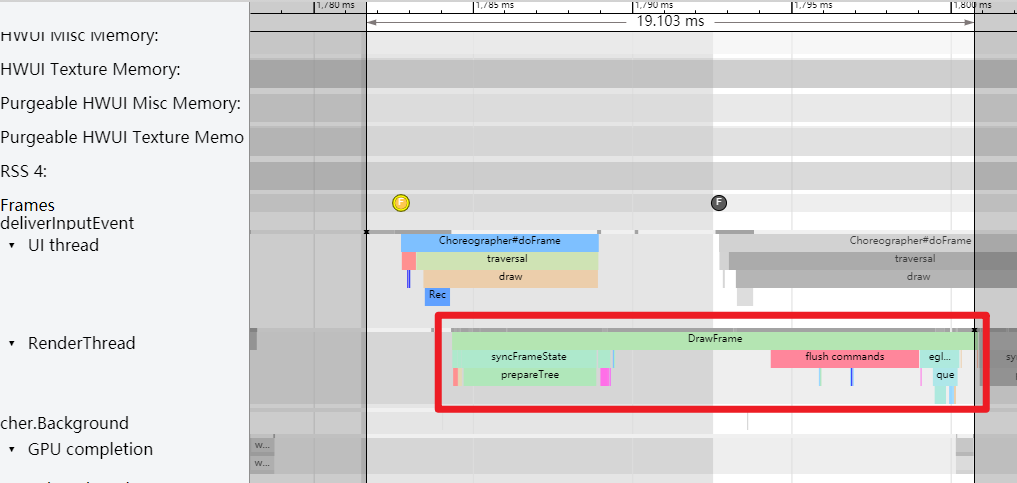
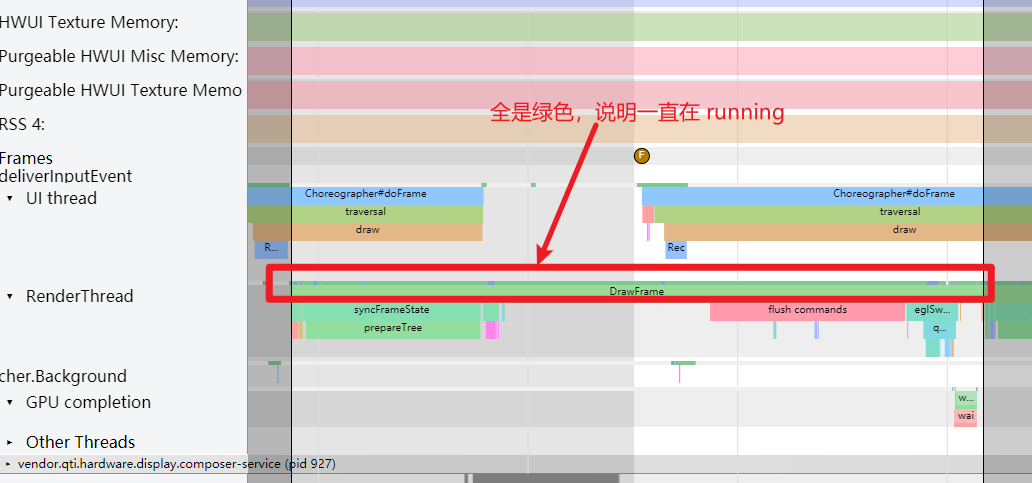
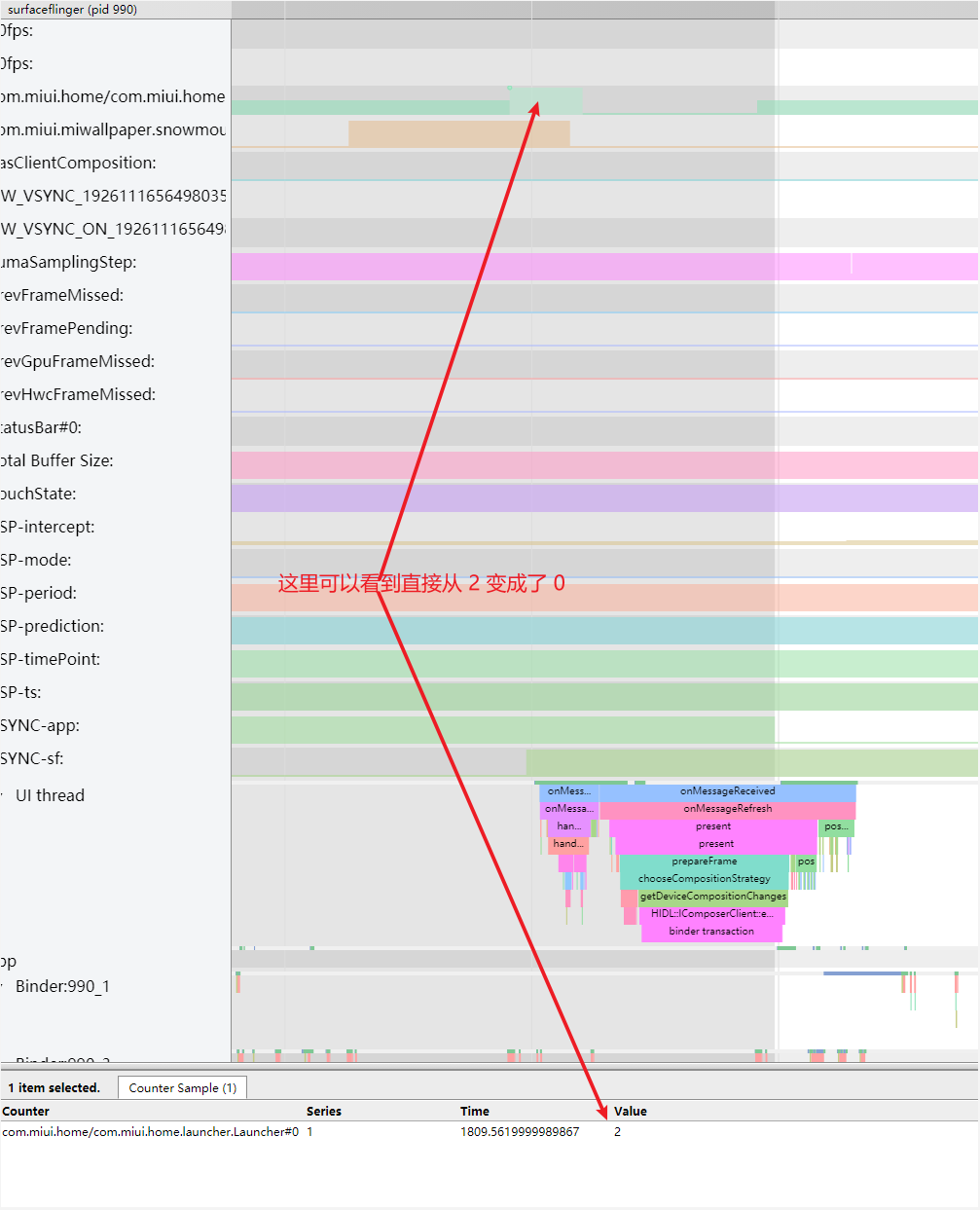
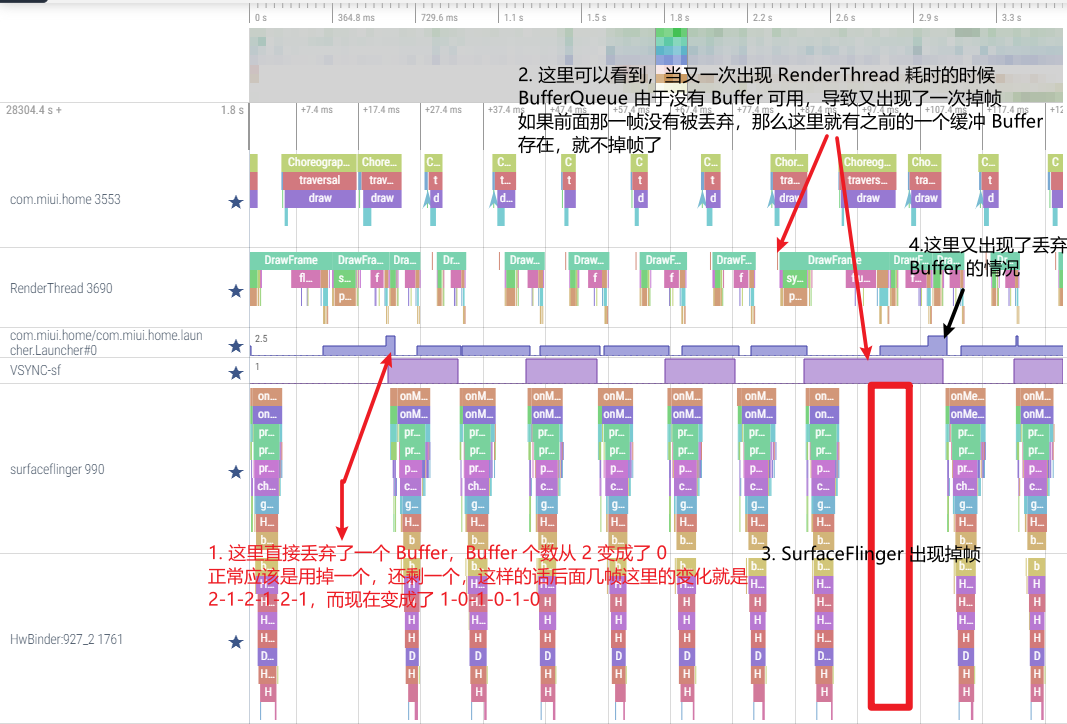
还是这个 Systrace(附件) 中的情况,第一个疑点处两个黄帧,可以看到第二个黄帧的主线程耗时很久,这时候不能单纯以为是主线程的问题(因为是 Sleep 状态)
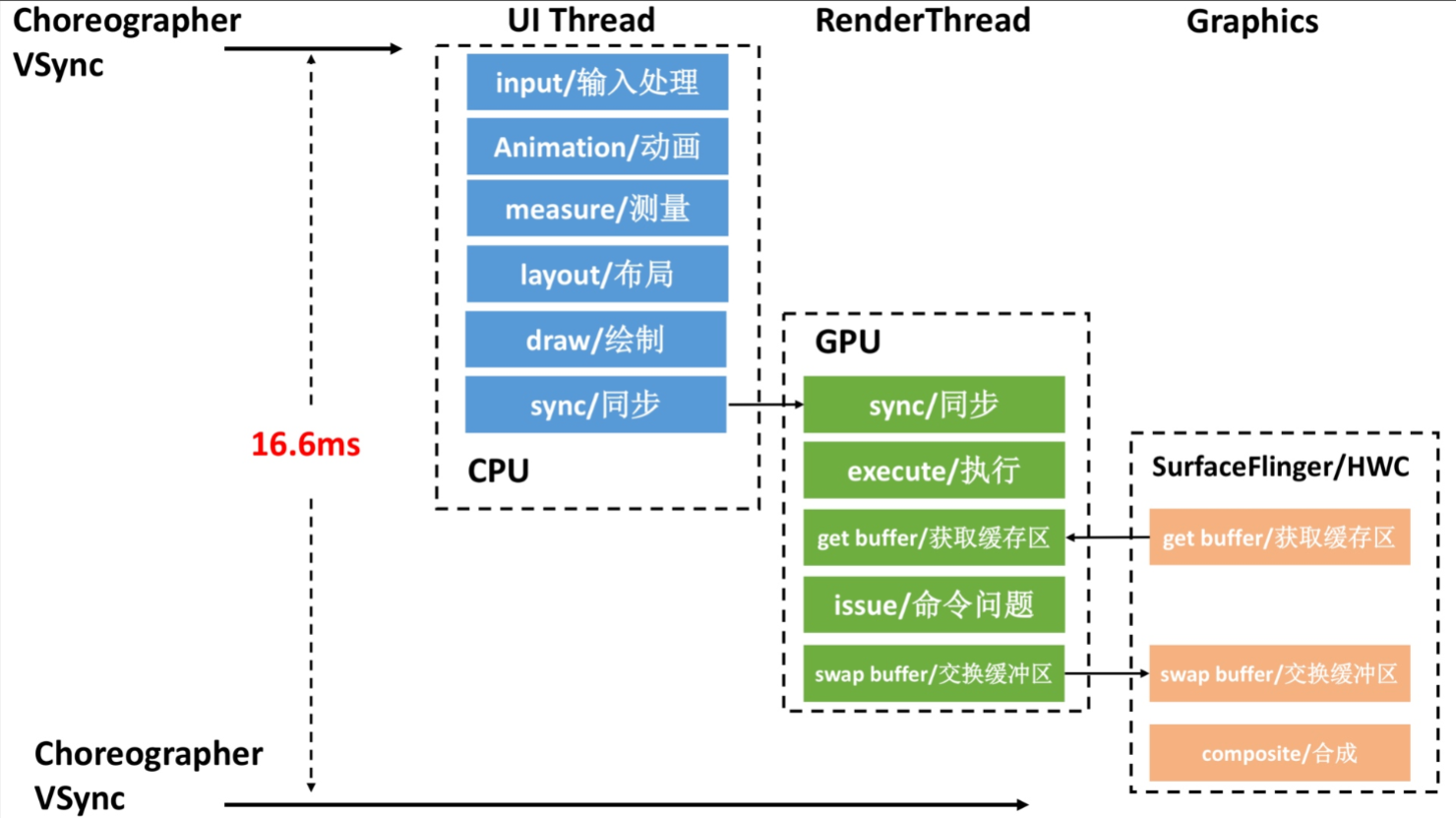
如下图所示,是因为前一帧的渲染线程超时,导致这一帧的渲染线程任务在排队等待,如(https://www.androidperformance.com/2019/11/06/Android-Systrace-MainThread-And-RenderThread/)这篇文章里面的流程,主线程是需要等待渲染线程执行完 syncFrameState 之后 unblockMainThread,然后才能继续。
为什么一直滑动不松手,就不会卡?
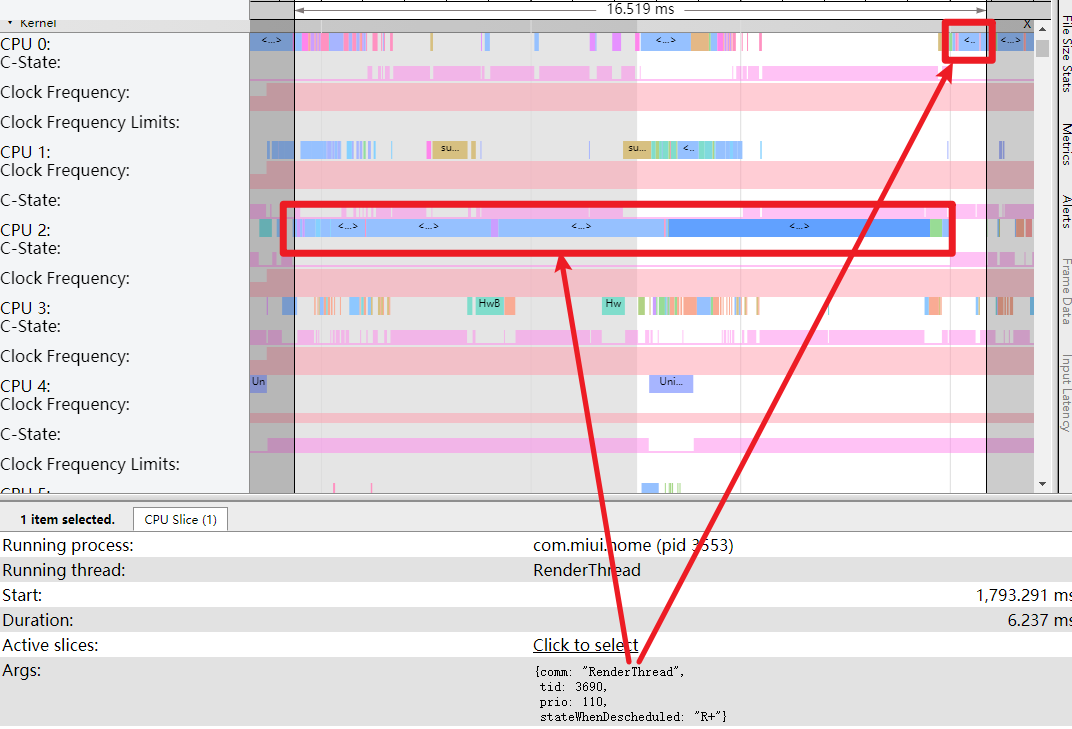
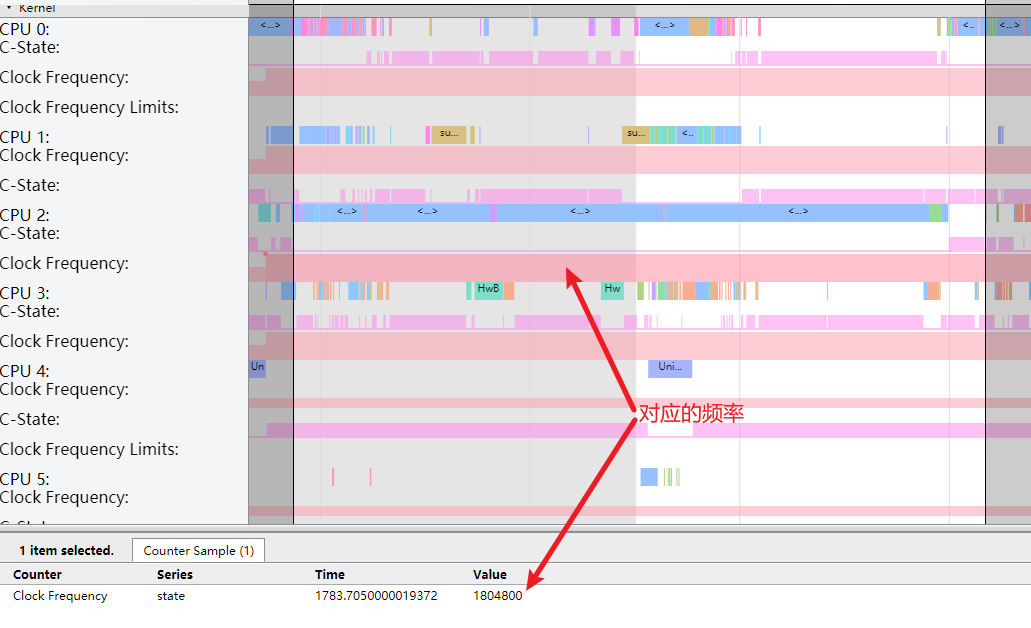
还是这个场景(桌面左右滑动),卡顿是发生在松手之后的,如果一直不松手,那么就不会出现卡顿,这是为什么?
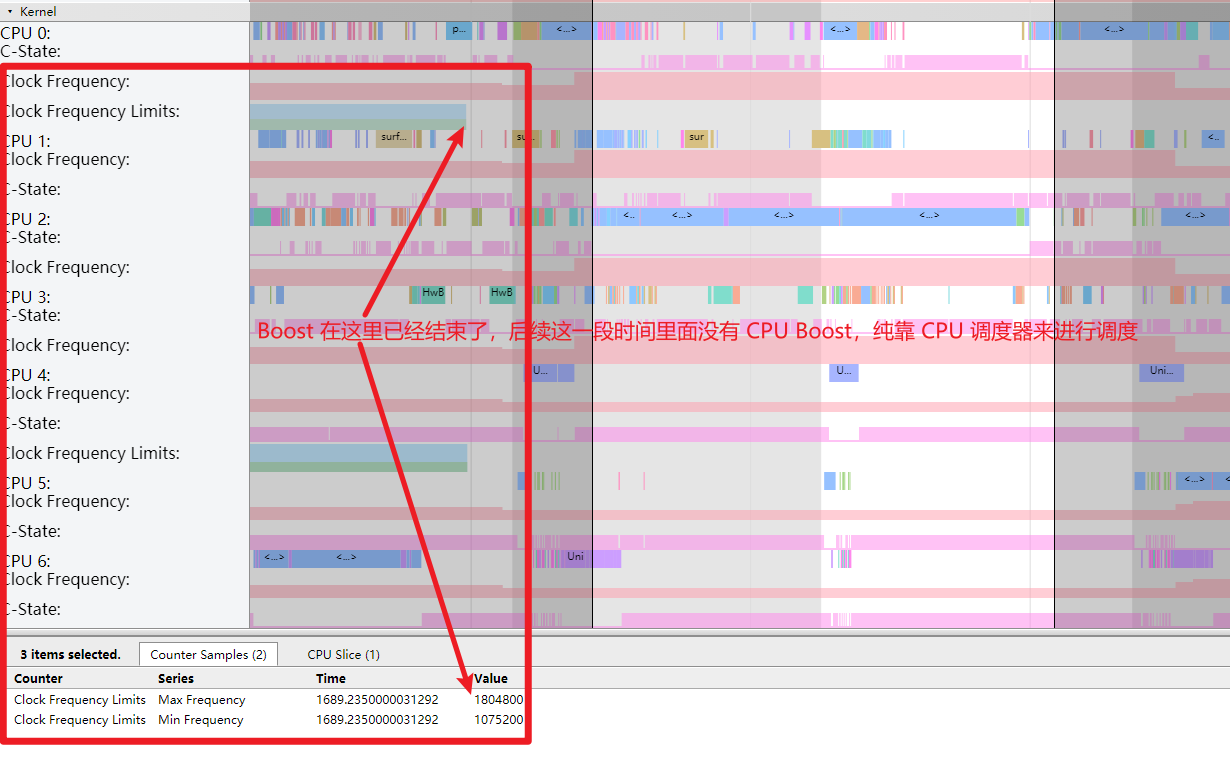
如下图,可以看到,如果不松手,cpu 这里会有一个持续的 Boost,且此时 RenderThread 的任务都跑在 4-6 这三个大核上面,没有跑到小核,自然也不会出现卡顿情况
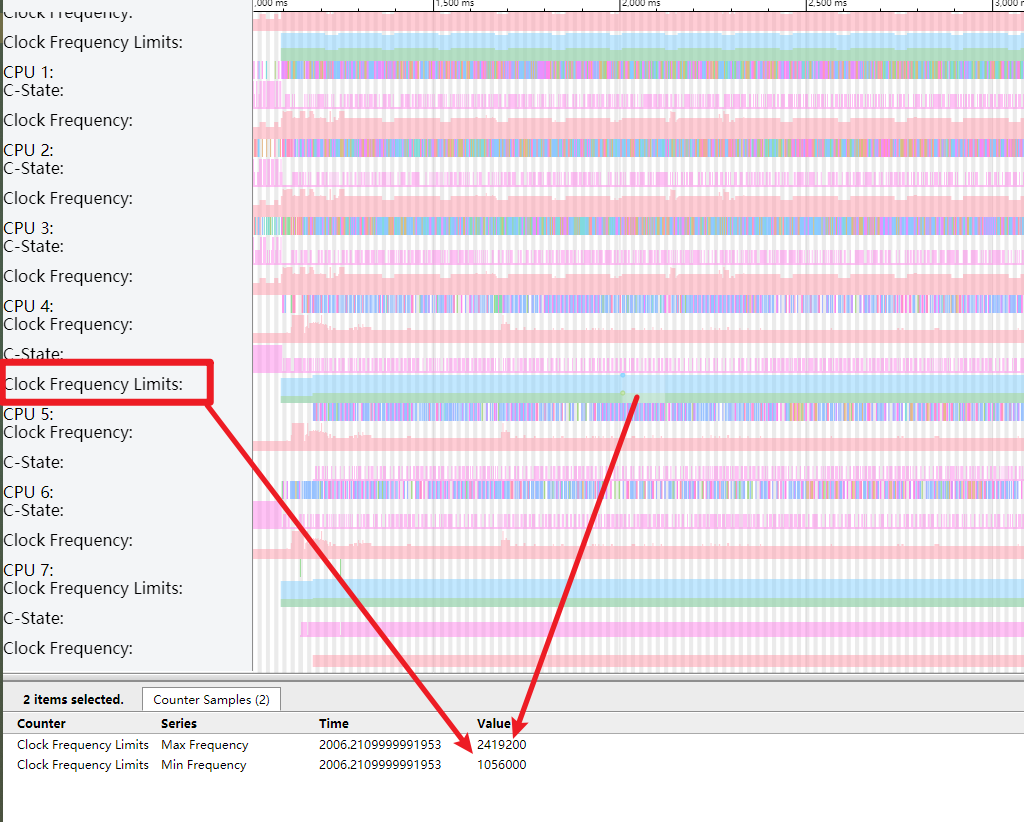
这一段 Boost 的 Timeout 是 120 ms,具体的配置每个机型都不一样,熟悉 PerfLock 的应该知道,这里就不多说了
如果不卡,怎么衡量性能好坏?
如果这个场景不卡,那么我们怎么衡量两台不同的机器在这个场景下的性能呢?
可以使用 adb shell dumpsys gfxinfo ,使用方法如下
- 首先确定要测试的包名,到 App 界面准备好操作
- 执行2-3次
adb shell dumpsys gfxinfo com.miui.home framestats reset,这一步的目的是清除历数据 - 开始操作(比如使用命令行左右滑动,或者自己用手指滑动)
- 操作结束后,执行
adb shell dumpsys gfxinfo com.miui.home framestats这时候会有一堆数据输出,我们只需要关注其中的一部分数据即可 - 重点关注
- Janky frames :超过 Vsync 周期的 Frame,不一定出现卡顿
- 95th percentile :95% 的值
- HISTOGRAM : 原始数值
- PROFILEDATA :每一帧的详细原始数据
我们拿这个场景,跟 Oppo Reno 5 来做对比,只取我们关注的一部分数据
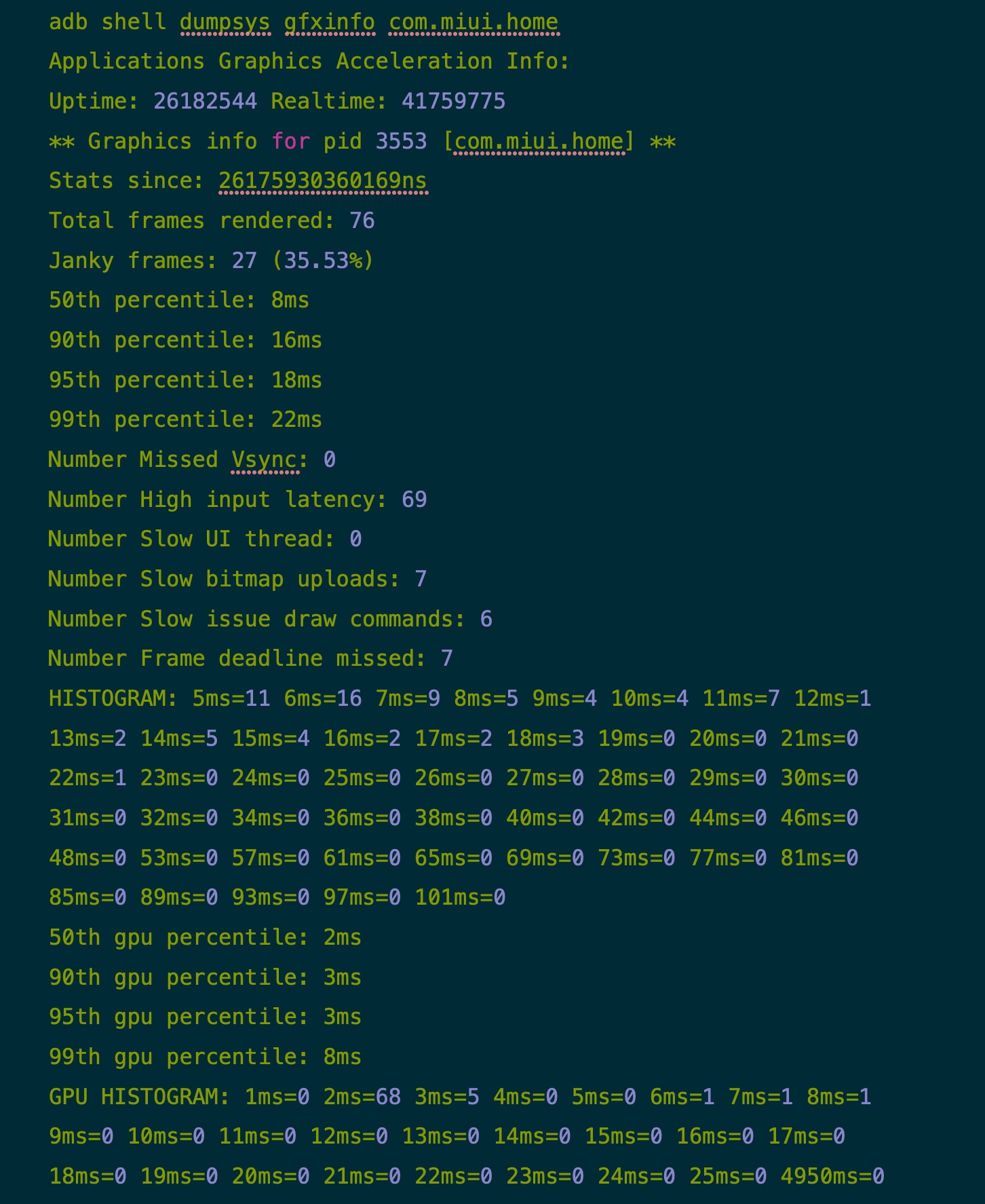
小米 - 90 fps
Oppo - 90 fps
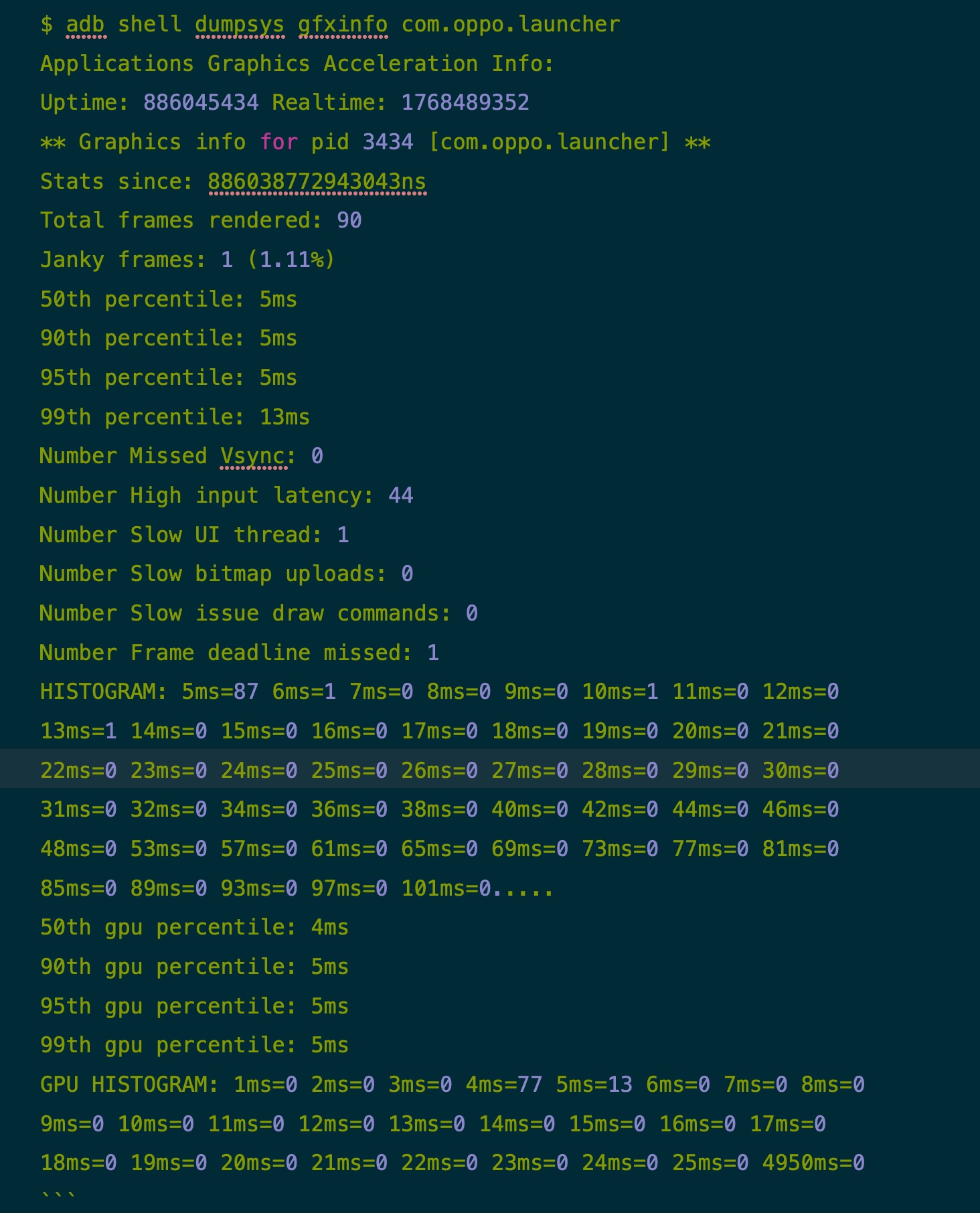
下面是一些对比,可以看到小米在桌面滑动这个场景,性能是要弱于 Oppo 的
- Janky frames
- 小米:27 (35.53%)
- Oppo:1 (1.11%)
- 95th percentile
- 小米:18ms
- Oppo:5ms
另外 GPU 的数据也比较有趣,小米的高通 865 配的 GPU 要比 Reno 5 Pro 配的 GPU 要强很多,所以 GPU 的数据小米要比 Reno 5 Pro 要好,也可以推断出这个场景的瓶颈在 CPU 而不是在 GPU
为什么录屏看不出来卡顿?
可能有下面几种情况
- 如果使用的手机是大于 60 fps 的,比如小米这个是 90 fps,而录屏的时候选择 60 fps 的录屏,则录屏文件会看不出来卡顿 (使用其他手机录像也会有这个问题)
- 如果录屏是以高帧率(90fps)录制的,但是播放的时候是使用低帧率(60fps)的设备观看的(小米就是这个情况),也不会看出来卡顿,比如用 90 fps 的规格录制视频,但是在手机上播放的时候,系统会自动切换到 60 fps, 导致看不出来卡顿
系列文章
附件
附件已经上传到了 Github 上,可以自行下载:https://github.com/Gracker/SystraceForBlog/tree/master/Android_Systrace_Smooth_In_Action
- xiaomi_launcher.zip : 桌面滑动卡顿的 Systrace 文件,这次案例主要是分析这个 Systrace 文件
- xiaomi_launcher_scroll_all_the_time.zip : 桌面一直按着滑动的 Systrace 文件
- oppo_launcher_scroll.zip :对比文件
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远