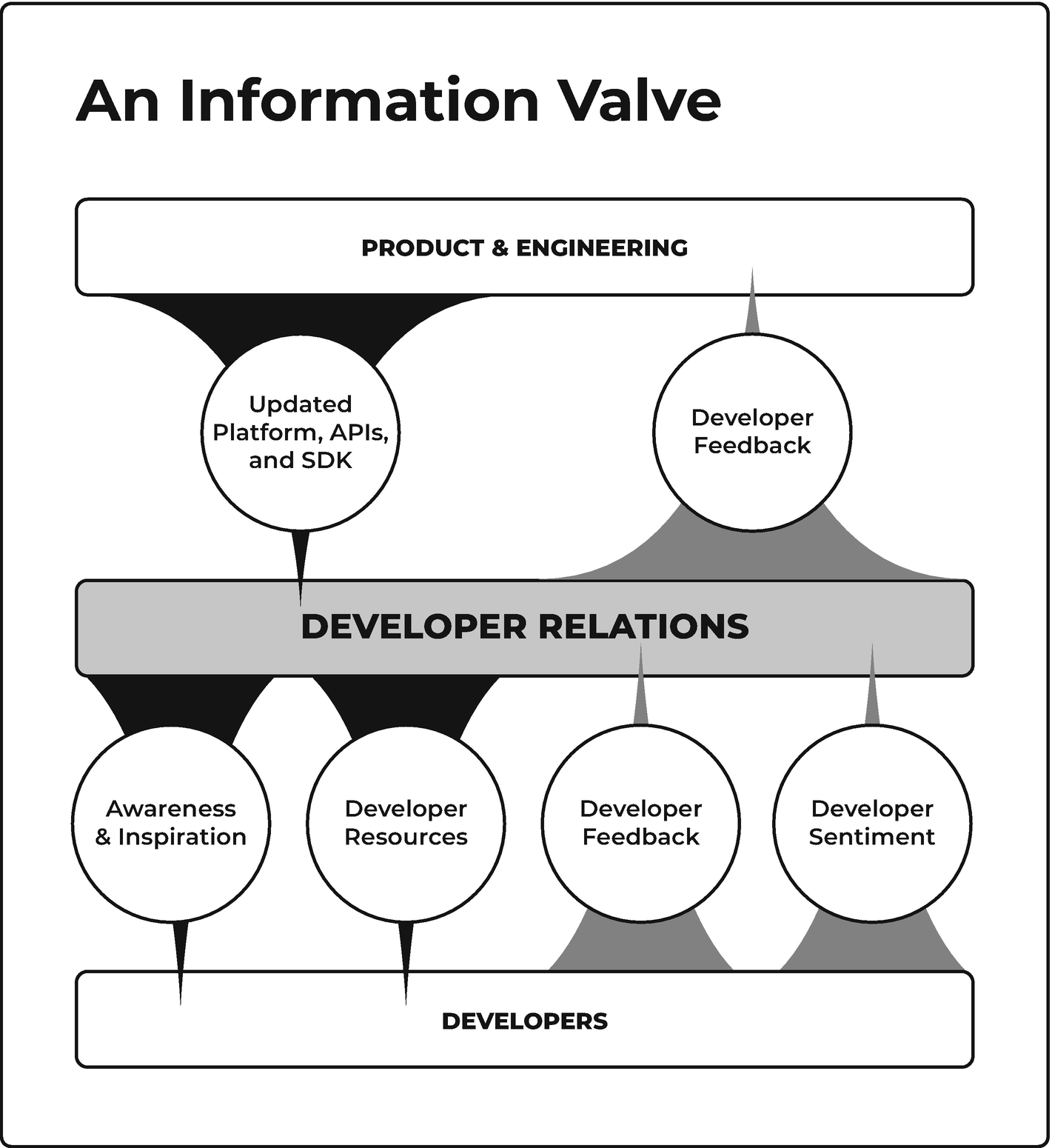
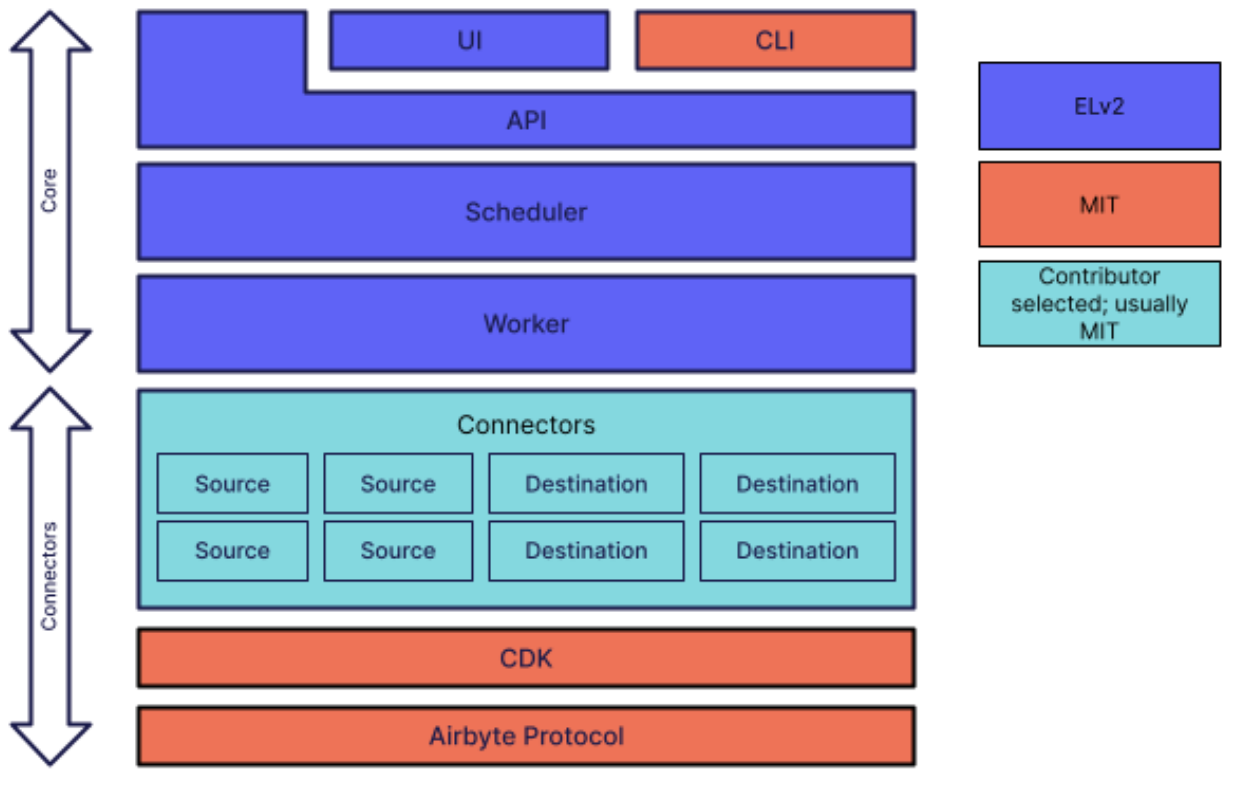
我在《企业开源该选什么软件许可证?》一文当中,已经从软件许可证的角度讨论过不同协议对企业开源的意义。
不过,那篇文章主要是从许可证内容出发的,即先给定了协议,分析完协议细节,再判断是否符合企业和计划公开的软件的情形。本文从企业开源的不同诉求和风险出发,结合现存的企业组织实践,重新讨论源码公开第一步就要面临的选择软件协议问题应该如何决策。
完全开放源码
完全开放源码,即以符合开源定义的软件协议发布企业自研软件的情形。
在讨论什么样的企业针对什么样的软件会采用完全开放源码的策略之前,我们先讨论完全开放源码的策略会给企业带来什么风险。符合开源定义的软件协议既包括宽容软件协议,也包括 Copyleft 式的协议,这里不做区分,因为企业面临的是相同的问题。
当然,对于企业完全自有产权的情形,企业随时可以改变软件协议以规避下面提到的风险。所以这里提到的风险主要涉及的是将自研软件捐赠给第三方如开源基金会,或者试图坚持完全开放源码策略的企业。
风险:竞争对手的商业竞争
我在《黑客与顾客:开源软件能商业化吗?》一文里讨论过,开源软件的用户包括黑客和顾客两种类型。
对于完全开放源码的创始团队来说,黑客用户既然自己有能力把软件用起来,甚至修改软件以解决自己的需求,那么可以认为开发成本已经付出,不从这类用户身上赚钱,而是寻求合作共建,是合理的。目前绝大部分“开源商业化”企业的逻辑,也是以服务无力或不愿承担开发和维护任务的顾客为主。
这一点,从目前新兴的 Elastic License 2.0 (ELv2) 和 Business Source License 1.1 (BSLv1) 的不少实践都允许在不进行同类商业服务竞争的情形下自由使用可见一斑。而上述两个源码公开的商业软件协议,想要避免的也正是同行黑客的商业竞争。
例如,业内提供 Apache Kafka 托管服务的企业数不胜数。在聚拢了相当数量的核心开发者的 Confluent 之外,Upstash 和 Aiven 这样的 SaaS 企业都提供了 Kafka 托管服务,更不用说大大小小的平台云厂商顺手提供的 Kafka 服务,例如 AWS 的 MSK 服务、阿里云的 Kafka 服务和红帽的 OpenShift Streams for Apache Kafka 服务等等。
这样的竞争使得 Confluent 不得不在简单的提供 Kafka 服务以外寻求新的增长点,例如只在商业版本提供多租户功能,以及在流计算集成上多次失败的尝试。当然,Kafka 的创始工作和捐赠都是在 LinkedIn 公司的主导下完成的。这样 Confluent 公司虽然无法效仿 MongoDB 公司在竞争对手直接提供商业服务的时候变更协议釜底抽薪,但是心里也不至于太不平衡。
ElasticSearch 和 MongoDB 起初分别以 Apache License 2.0 (ALv2) 和 GNU Affero General Public License 3.0 (AGPLv3) 发布,但是在 AWS 等商业公司低技术成本、高平台优势的竞争下,既无法找到新的增重点缓解危机,又无法抗拒近在咫尺的釜底抽薪方案,于是变更协议直接禁止使用源码进行商业竞争。
风险:团队分裂并参与竞争
Confluent 的案例里暗含了另一种完全开放源码的风险,即在软件可以自由演绎和商用的情况下,企业当中的开发者可能分裂出去单独进行商业运作并参与竞争。
Confluent 的创始团队来自 LinkedIn 公司,LinkedIn 本身没有提供云服务的业务,这种竞争尚不明显。其他处于 LinkedIn 情境的公司,甚至可以通过提供早期投资的方式,换取新团队比此前直接雇佣更低成本的支持。
Apache Hadoop 的故事演示了多家势均力敌的企业,同时基于非自有产权的开源软件做简单封装的商业化模式的风险。
在 Hadoop 的孵化公司雅虎不下场的情况下,Cloudera 公司、Hortonworks 公司和 MapR 公司为了竞争 Hadoop 私有化部署和运维服务打得头破血流,最后的结局是 Hortonworks 和 MapR 被收购,Cloudera 私有化退市。而退市以后的 Cloudera 公司,还是面临市面上拿着 Apache Ambari 封装或者自研大数据套件的提供商的剧烈竞争。
Apache Flink 的故事演示了在一家企业主导社群发展的情形下,部分团队寻求独立带来的分裂风险。
起初,Flink 在一所德国大学里开发并捐赠到 Apache 软件基金会。随后创始成员成立了 Ververica 公司,并于 2019 年被阿里巴巴收购。完成收购的阿里巴巴基本形成了对 Flink 社群的主导,并于接下来的一段时间无需顾虑其他基于 Flink 的商业服务的竞争。然而,就在过去的一两年里,核心团队分几次出走,加入到其他基于 Flink 做商业服务的公司,或者单独成立商业公司提供 Flink 服务。其中,走后面一条路的 Immerok 公司在不久前被 Confluent 收购,一下子使得阿里巴巴的流计算业务受到 Confluent 流存储 + 流计算的强势狙击。
在这些戏剧化的商业操作背后,Flink 本身是一个完全开放源码的软件,允许任何人和组织自由演绎和使用,也包括商用和提供商业竞争,是合规层面的一个基础性的支撑。
上面提到的例子里,即使有企业完成对社群话语权主导的案例,但是都全都是企业对开源软件没有自主产权的情形。接下来的这个例子虽然也是 Apache 软件基金会的项目,但是其中使用的方法是可以套用到企业自有产权的软件的。
这个案例就是 Apache Doris 项目。
Apache Doris 由百度的研发团队开发并捐赠给 Apache 软件基金会。凭借其符合国内企业需要的数据分析能力的设计,Doris 在一开始的十年里逐渐发展出一个可观的用户群体,其中相当部分还是有购买商业服务的潜在顾客。百度自己基于 Doris 发布了 Palo 数据分析产品,但是不久以后,部分核心开发者出走,并 fork Doris 发布了后来改名为 StarRocks 的同类竞争产品。没过几年,另一个研发团队出走并成立了 SelectDB 基于 Doris 提供同类的数据分析服务。
单看这个围绕 Doris 的竞争,似乎和 Hadoop 几家公司的竞争也没有什么差别。但是 StarRocks 并不是一个典型的围绕上游的版本,而是从某个版本硬分支的全新版本,目前和 Doris 的关系算得上是“大路朝天,各走一边”。这样硬分支的手段带来的竞争,即使上游是完全自有产权的软件,也无法通过修改协议来避免。
为了表明 Doris 的案例并非孤例,我这里再举几个类似的商业相关的硬分支案例:
- Trino 是基于 Facebook Presto 的硬分支,后续 Trino 团队成立了 Starburst 公司提出数据网格(Data Mesh)概念做为商业化方向。
- Lightbend 公司将 Akka 切换成年收入在一千万美元以上的公司使用就需要商用协议以后,Akka 社群的中立成员随即 fork 了 Akka 并在 Apache 软件基金会的孵化器中以 Pekko 的名字继续运行。
- AWS 在 Elastic 公司将 ElasticSearch 切换到 ELv2 后,发起了 OpenSearch 项目并基于它提供了类似的商业服务。
面对上述风险,企业可以采取以下策略来降低或规避商业竞争的挑战。这些策略不是互斥的,应该根据企业自身的情况灵活组合使用。
策略:运维和高级功能
这是最基本的一个策略,即提供一个比开源版本功能更丰富的企业版本,包含闭源高级功能或运维支持,提供售后、服务水平保证和责任承担。
通常来说,它并不能在策略层面提供明显的竞争优势,因为你的竞争对手在能够自由使用相同软件的情形下,与你在这一层面的竞争是处于同一起跑线的。唯一的区别是你可能拥有更多熟悉软件的工程师,能够提供更好的服务支持。
但是,为了保持开源软件的活力、技术迭代与用户群,不至于变成开源一个闭源专有软件的快照,你的工程师会投入到开源上游核心的开发中去,这些成本由你支出,而你的竞争对手将无偿取得。同时,因此你的企业版本很难做出合适的代差以说服客户使用,而纯粹的运维支持,营收在竞争对手不需要维护一个内核研发团队的价格战下很难支持公司增长。
总的来说,这是一个保护性策略,即你必须要提供运维支持、售后、服务水平保证和责任承担,从而让客户能够像使用一个商业产品一样使用你提供的开源软件发行版或服务。但是它很少成为一个决定性的优胜策略。
策略:独特品牌建设
完全开放源码风险的共同点,是出现了其他企业或团队,以相同的软件代码基础展开商业竞争。企业开源的情形下,软件代码的归属是明确的,不仅创始工作在企业内的研发团队完成,版权所有的也是企业。这样,企业可以通过基于软件建设公司独特的品牌,将软件与公司品牌相关联来赢得在同类产品的用户群体中的心智竞争。
例如,Hashicorp 的基础软件均以 Mozilla Public License 2.0 (MPLv2) 发布。
实践上,MPLv2 可以被简单理解为允许包括提供同类服务的商业用途,可以和商业软件集成而不要求开放集成软件的源代码,可以基于已有接口的开发闭源的新机制实现,但是对软件接口的修改需要公开。MPLv2 许可的软件是完全开放源码的软件,一家公司直接拿走 Terraform 等软件,提供和 Hashicorp 相同接口的服务进行竞争是可能的。
然而,支撑用户采用 Terrafrom 等软件的,是 Hashicorp 对基础设施即代码的解释和实践。用户采购的不仅仅是 Terrafrom 或 Nomad 单独的一个工具,而是 Hashicorp 定义的一整套基础设施即代码的工作方式。如果下游企业仅仅是跟随这些概念,那么面对 Hashicorp 推出的新概念,自然很难第一时间跟进,更遑论超越。这样,用户就没有理由选择一个被上游带着跑的提供商,而是直接接触原创厂商。如果原创厂商的产品不能满足要求,也不太会选择追随者。
同样,商业智能数据分析服务的内核软件,例如 Cube.js 和 Streamlit 也是完全开放源码的。这类场景的定制化和依赖方法论的程度高,厂商基本可以将自己的技术品牌和开源软件相绑定,从而建立起竞争对手难以逾越的心智门槛。
Starburst 公司是另一个佼佼者,它拥有 Trino 即原先的 PrestoSQL 的版权,而 Trino 是联邦查询优秀的解决方案。Starburst 趁热打铁,推出了极具传播效果的 Data Mesh 概念,即不同来源和模式数据在同一个平台下进行分析,从而将数据打造成产品,而要做到这点,联邦查询引擎 Trino 自然能提供强力支持。这个概念的传播性之强,以至于 Confluent 也出书将自家的 Data in Motion 概念和 Data Mesh 捆绑营销,Trino 和 Starburst 借此水涨船高。
不过,对于标准化完成度高的赛道,这样的策略往往就难以提供竞争优势,而成为必须要做的保护型策略了。例如,MySQL AB 公司拥有 MySQL 的版权,但是在后来的发展里,业界对于数据库应该是什么样子的越来越有清晰的共识,甚至不少 MySQL 的运维专家自己都可以开设公司提供商业服务。MySQL AB 公司提供的附加价值有限,相当长时间内也不再提出具有开创性的品牌概念,终于在公有云服务登场以后,彻底被云厂商的关系数据库服务截取几乎所有利润。
策略:赛道维度升级
当完全开放源码的基础软件逐渐取得行业认可,甚至成为行业标准以后,品牌建设带来的心智门槛就会逐渐被抹平。这个时候,单纯提供简单的部署运维服务的商业模式,就会陷入到恐怖的价格战当中。在保持基础软件完全开放源码的前提下,要想另辟蹊径取得商业优势,就需要进行赛道维度升级,即基于开源软件提出新的解决方案。
要想走到这一步并不容易,如果初创企业辛苦研发后开源的核心软件,经过运营真的成为了某种标准,模仿者众,初创企业效仿 MongoDB 和 Elastic 直接切换成专有协议是目前仅有的实践。我们以一个无法切换协议的企业来模拟在这种情况下坚持完全开放源码、升级赛道维度将如何进行,它就是 Databricks 公司。
起初,Databricks 的商业模式还是 Spark 的简单包装。它和微软 Azure 达成合作,在 Azure 上捆绑销售 Apache Spark 性能优化的发行版。
随后,Databricks 以 AI 为切入点,在 Spark 生态推出了 SparkR 和 PySpark 等集成支持,同时和 edX 合作推出了 Spark 系列课程,强化 Databricks 品牌在 Spark 生态中的地位。同时,在商业产品侧,针对 AI 的典型计算任务提供了标准化算力资源和一揽子解决方案,开始将 Spark 作为公司依赖的计算引擎核心而非差异化卖点。
再后来,Alluxio 和 JuiceFS 的探索让 Databricks 发现了 Spark 的计算能力加上存储以后的巨大需求市场,于是自研了 Delta Lake 软件,提出湖仓一体概念兜售新的解决方案。随着公司逐渐站稳脚跟,Databricks 也有了更多的资源投入到先前 AI 阵线上如今火起来的 AIOps 概念,以及完善整个湖仓一体故事所需的,包括 Delta Live Table 在内的一系列周边产品。
今天的 Databricks 已经不是一个简单的 Spark 提供商,而是一个 Data + AI 领域的企业级方案和云服务提供商。其他简单提供 Spark 作业调度和运维的企业,跟 Databricks 并不在同一个维度内竞争。
策略:市场占有率与开放标准
目前,能够在自有产权的情况下坚持完全开放源码,并在其他维度展开竞争的企业,其开放源码的软件都不是企业盈利的核心软件,而是打开市场和建立开放标准的敲门砖。换言之,企业对此类软件选择和坚持完全开放源码策略的一个主要原因,是企业希望完全开放源码的软件赢得广泛的市场占有率,甚至形成开放标准。
以开源的程序设计语言实现为例,在语言本身赢得用户之前,很少有企业能够直接通过售卖语言实现的编译器或解释器来盈利。瑞典电信公司 Ericsson 支持工程师 Joe Armstrong 开发 Erlang 语言之后,将整个 Erlang/OTP 平台完全开放。从当年的发布文稿中,我们可以看到开放标准的典型思路:
Erlang/OTP was invented within Ericsson and most Erlang/OTP users are still within Ericsson. In order to speed development of Erlang/OTP, ensure a good supply of Erlang/OTP fluent programmers, minimise maintenance and development costs for the language, and keep the OTP applications up to world class, we need to spread the technology outside of Ericsson.
也就是说,Ericsson 内部的电信系统高度依赖 Erlang/OTP 平台,为了保证劳动力市场上一直有人熟练掌握这一语言和开发平台,从而保证 Ericsson 内部系统不至于无人能够维护,Ericsson 希望完全开发源码,以期在公司以外的广阔生态中推广 Erlang/OTP 平台。事实证明,这一决定为 Erlang/OTP 平台起初在电信行业内的推广,以及后来在游戏行业中的广泛应用,再到近些年其底层虚拟机 BEAM 借助新语言 Elixir 的发展再次得到关注,都起到了至关重要的作用。Joe 为 Ericsson 创建高可用的服务打造了一个完整的开源软件和开发平台,但是如果没有开放源码,这将只是 Ericsson 这个如今已不那么有名的企业的一个内部系统。或许会成为一个仅存于谈话之中的传说,但是不可能有今天的生态。
同样是 Erlang 生态的一部分,José Valim 设计的 Elixir 语言及其开发的解释器和网站开发套件,代表了开放源码以赢得市场占有率的策略。
José 起初在自己参与联合创办的 Plataformatec 开发出了 Elixir 语言的解释器,以及 ecto 工具和 Phoenix 框架。后来,Elixir 的使用率日益增长,José 于是另外创办了 Dashbit 公司来提供 Elixir 应用的开发和运维支持。
从 Dashbit 公司的视角出发,其拥有部分 Elixir 核心生态软件的知识产权,但是它却没有通过限制核心软件使用,要求用户购买 LICENSE 的方式来盈利。这是因为,Elixir 毕竟还是一个小众的语言,用户使用量的增长才是做企业支持的基本盘。如果小有成就马上杀鸡取卵、竭泽而渔,那么新用户就很难有信心上车,而存量用户也会想办法跳车,最终生态凋敝,没人有理由购买 LICENSE 授权。
José 本人在 LinkedIn 上的头衔就是 Chief Adoption Officer 即首席(用户)采用官,可见 Dashbit 的开源策略当中对市场采用率的重视程度。同类的案例还有 VMWare 的 Greenplum Database、Spring Framwork 和 RabbitMQ 等项目,这些公司(在相关方向)的主要商业模式是提供支持和咨询,而不是售卖软件或提供云服务,因此其提供支持和咨询的对象的使用率越高越好。
再来看一种竞争型的开放标准策略,其中典型的当属 Google 的开源矩阵:
- Chromium 打下了浏览器内核的半壁江山。如今,多少网页应用都注明仅在 Chrome 上经过测试。
- Android 从 iOS 和 Symbian 的夹缝中取得了移动端市场的船票,并最终和 iOS 二分天下。
- Kubernetes 和 Istio 是 borg 技术溢出以后,Google 主动建立生态的尝试。在相当一段时间里,用上 Kuberneets 就“等于”云原生。
Google 是重度参与 C++ 标准讨论或者说竞争的,这可从 C++ 之父 Bjarne Stroustrup 的论文 Thriving in a Crowded and Changing World: C++ 2006–2020 中关于 C++ 标准委员会的讨论中窥见端倪。应该说,标准之争是激烈甚至残酷的。企业内部总有领先与行业标准所做的尝试,一旦行业后续面对相同问题时将另一种解法确定为标准,那么本公司不说此前的研发投入打了水瓢,至少也需要付出可观的额外努力来兼容新标准。Google 深知这点的厉害,而 Kuberneets 打赢容器战争,对比失败的 OpenStack、Docker Swarm 和 Apache Mesos 与重金投入它们的公司,Google 账面之外的获利不可计数。
无独有偶,Facebook 的 React 前端应用开发框架已经成为无可置疑的标准,对应 Google 推出的 Angular 势弱,多少投资 Angular 的企业和开发者损失惨重。
国内也不乏出于这个动机完全开放软件源码的企业。例如,Apache InLong 是腾讯大数据平台里数据集成能力的开放,Apache Dubbo 和 Nacos 是阿里巴巴微服务架设和治理经验的开源表现,CloudWeGo 是字节跳动中间件能力的系列开源行动,Go Kratos 是 Bilibili 开源的微服务框架。当然,这些软件集中在所谓的“中间件”领域,是另一个值得探讨分析的话题。
最后,上面提到的都是体量巨大或至少相对较大的公司,对于初创公司来说,有没有实践市场采用率和开放标准这一策略的空间呢?
肯定还是有的。例如,近期已被 Apache 孵化器接受的 OpenDAL 数据访问库,就是由 2021 年初创的企业 DatafuseLabs 捐赠的。又例如,CockroachDB 的存储引擎 Pebble 以 BSD-3-Clause 协议开源,连 PingCAP 的数据导入工具 Lightning 都在使用。
一般来说,初创公司更容易在细分领域或者新兴领域,通过开放源码软件来赢得大量声誉和共同维护生态成员都有需要的基础软件。
源码公开但禁止商业竞争
完全开发源码的策略会面临其他企业直接拿走软件代码,提供同类接口展开商业竞争的风险。即使是 Copyleft 式的协议,也很难逃过这样的竞争。
例如,红帽公司的 Red Hat Enterprise Linux (RHEL) 以 GPLv2 发布,这就使得 CentOS 可以利用相同的代码提供自己的发行版和服务。国内运维应该都了解,CentOS 在相当一段时间内是国内企业环境部署量最大的 Linux 发行版。这对红帽的商业模式造成了很大的冲击,最终红帽在 2014 年收购了 CentOS 公司。而 2021 年 CentOS 的作者再次复刻代码开发 Rocky Linux 进行商业竞争,或多或少再次冲击了 RHEL 的市场。
当然,今天的红帽已经不是单纯 RHEL 发行版的订阅提供商了,这样的冲击未必造成多大影响。然而,红帽面临这些问题毕竟是因为它是上游 Linux 的一个追随者,没有代码版权。对于新兴的初创公司来说,一旦通过开放源码的方式赢得了第一批客户,其他公司复刻代码直接竞争,一个行之有效的手段就是切换到禁止商业竞争的软件协议,杜绝此类事情发生。
然而,这毕竟是诱导转向的手段:切换软件协议后,企业与产品的品牌会收到打击,社群反噬和衰退引起用户客户逃离,生态集成出现问题不再繁荣。这些都是可能出现的问题。对于一开始就采取禁止商业竞争策略的企业,不会受到切换协议带来的打击,但是社群规模和生态集成的问题和进行切换的企业最终面临的状况是类似的。
接下来,我们讨论采用禁止商业竞争的源码公开协议的企业,如何构建其软件协议模型,面临哪些挑战并将如何应对。
核心禁止商业竞争
这一门派的著名选手是 MongoDB 公司和 Elastic 公司,分别创造了 Server Side Public License (SSPL) 和 Elastic License 2.0 (ELv2) 两个协议。
其中 SSPL 并不直接禁止商业竞争,而是要求在向企业之外提供同类服务时,必须将服务所有相关软件的源代码都以 SSPL 公开提供。由于这个条件对于服务所有相关软件的定义非常模糊,在没有判例的情况下没有公司想要测试到底它能不能“传染”到企业所有核心代码。目前,遵循 SSPL 开放服务软件栈的案例应该完全没有。
虽然所有软件源码公开、自由使用和修改是自由软件的追求,但是 SSPL 主要的目的是针对云厂商,限制它们的提供同类服务。因此自由软件阵营的 Fedora 社群明确否认 SSPL 是自由软件协议。同时,SSPL 的文本明确违反了开源定义第九条“不得限制其他软件”,因此也不被开放源码阵营所认可。实际上,它期望起到的作用就是禁止同类服务的商业竞争,虽然实际上由于协议条文的潜在风险,企业在不购买 MongoDB 的商业协议授权时,往往选择完全不使用 MongoDB 软件。
ELv2 对禁止商业竞争的意图和范围描述是清晰的,其文本量也相对较少:在允许用户使用、复制、修改和分发的前提下,不允许用户改变软件协议,不允许破解密钥保护的功能,禁止提供与软件功能相似的商业服务。因此,企业内部使用,以及把 Elastic Search 作为支撑业务逻辑的倒排索引系统是可以的,只要不直接提供跟 Elastic Search 相同或相似接口的服务即可。
另外一个常用的协议,Business Source License 1.1 (BSLv1) 则是由失败过一次的 MySQL 团队的部分成员重新创业的 MariaDB 公司创造的。它被用在 MariaDB 的企业级解决方案核心软件 MaxScale 上,其协议内容禁止用户使用 MaxScale 集成超过三个节点的集群,实际上就限制了有效的商业竞争,同时迫使大规模使用该软件的企业购买商业协议。
最后,介绍 Redis Labs 曾经为了禁止商业竞争,而在 BSD 3-Cluase License 上添加的 Common Clause 条款,它禁止取得软件源码的接收者“售卖”该软件。
Redis Labs 后来在社群大规模反弹下切换回了纯粹的 BSD 3-Cluase License 模型,而 Common Clause 也因为对“售卖”的定义及其模糊而几乎没有其他采用案例。自由软件基金会在对软件协议的评论里更是专门抨击了 Common Cluase 对 “Common” 和 “Sell” 两个词词义的污染,并强烈建议不要使用这个附加条款。
总的来说,使用范围较广的禁止商业竞争的源码公开协议只有 ELv2 和 BSLv1 这两者。我们看看其他公司的采用情况。
Airbyte 是 ELv2 + MIT 最典型的玩家。虽然它起初完全是用 MIT 许可发布的,但是很快就出现了模仿者打价格战。Airbyte 的主要研发投入仍然在其数据集成核心上,而这个需求相对来说是有行业共识的,在数据传输协议公开的前提下,打的就是集成多寡的体力仗。这种情况下,Airbyte 优化核心的投入会被下游无偿获取,其细分领域内建设独特品牌的策略提供不了公司想要的壁垒,而公司的人力又不足以完成升级赛道维度的开发。因此,Airbyte 选择切换核心软件协议,釜底抽薪。
由于 Airbyte 切换协议的时候,大型云厂商尚未关注到它,用户要么是自己部署,要么是使用 Airbyte 的服务,使用竞品服务的用户只是初现趋势,而 ELv2 本身并不禁止用户自己部署使用的情形,因此没有引起巨大的反弹。同时,Airbyte 的命令行工具、连接器代码和开发套件,以及数据传输协议实现仍然是 MIT 许可的,这就不影响社群开发的 Airbyte 集成继续以开源协议发布,对社群生态也没有造成明显的影响。当然,有人不喜欢这类变化,选择其他自由软件的情况是有的。核心模块的开发者规模虽然此前也主要是 Airbyte 员工响应,没有受到太大影响,但是也不会再有想象空间了。
BSLv1 在限制条款上留白,因此应该算是一个协议框架,实际使用 BSLv1 的企业分成两类。
第一类是 CockroachDB 和 Outline 式的禁止提供同类服务,这在模式上和使用 ELv2 大体相同。
第二类会有各种更加严格的限制,不同于第一类只是禁止商业竞争,更像是确定了免费增值的策略,一旦超出“试用额度”,就需要付费。
祖师爷 MariaDB 的做法是限制以其 BSLv1 版本使用 MaxScale 的用户不得链接超过三个节点的集群。
Materialize 在禁止提供同类服务之上还要求只能部署单集群单并发。一般而言,有后面这个限制已经无法进行有效的商业竞争,不知道是不是担心注册多家公司进行公司级 sharding 钻空子。这样彻底抹杀可能性,可以说尽显商业专业协议的特色。
Lightbend 为 Akka 挑选的 BSLv1 版本,要求用户只能将 Akka 用于和 Play Framwork 下的应用进程通信。实际上,Play Framework 以 ALv2 许可发布,且强依赖 Akka 作为基础软件,这个条款更多是对 Play Framework 社群的妥协,保障 Play Framework 的用户不受 Akka 切换协议的影响,但是也不能从中暴露 Akka 接口脱离 Play Framework 使用。
BSLv1 相比 ELv2 还有一个特色,那就是它明确约定许可发布的软件在不超过四年的一个给定期限内,将自动视为以一个版权人挑选的 GPLv2 or later 兼容的协议许可发布。实践中,除了 MaxScale 选择在四年后以 GPLv2 or later 重新发布,其他企业均选择在四年后以 ALv2 重新发布。
对于行业来说,这在长时间轴上允许后来人自由使用这些代码,但是从商业竞争的角度来说,已经足够拉开和竞争对手的技术代差,劝退所有试图模仿的企业。
高级功能需要付费
另外一类包含禁止商业竞争的代码的软件协议模型,是限制高级功能的使用。
这一方案的代表企业是 GitLab 公司,其核心服务端软件代码协议模型有六个分点:
- 文档以 CC BY-SA 4.0 许可发布。
- ee 目录下的代码以商业协议发布,该协议允许测试和开发环境的自由修改和使用,但是生产环境使用必须有对应的订阅席位。
- jh 目录下的代码以商业协议发布,协议内容同上,除了企业主体变成极狐公司。
- 客户端 JavaScript 代码以 MIT Expat 许可发布。
- 第三方软件以其原协议发布。
- 其他代码以 MIT Expat 许可发布。
可以看到,代码在一起开发,但是高级功能需要付费才能商用。
这样的模式基本和完全开放核心源码,以闭源的插件或企业版代差来盈利类似,除了高级功能代码是公开可读的,而限制使用。
初创企业当中也有效仿这一模式的,例如 Bytebase 将高级功能以密钥上锁并禁止破解,Logto 将其云上部署的功能上锁。
总的来说,GitLab 能够成功应用这个模型,是因为它对企业需要什么样的代码托管平台,以及实施服务开发流程和研发效能等完整需求有一整套解决方案。当企业代码安全审计要求上去,或者实际发生过代码泄露问题,或者开发流水线严重拖慢了业务迭代,或者老板迫切想评估研发效能等等,这样的时候 GitLab 能够提供支持,并且其高级功能能打到痛点。至于国内学习这个模型的企业会如何发展,我们拭目以待。