但是,相比起开放源代码促进会(OSI)和 TODO Group 这样,在通用开源和企业开源领域能够提出见解和倡议的组织,开源社在掌握开源话语权这个议题上显得比较弱势。随着中国开源力量的崛起,如何引导各方参与者正确认识开源,在开源环境当中高效协作创新,将是一个无可回避的问题。我热切期望开源社能够发挥自己所在生态位的优势,联合开源社的志愿者,向社会不断输出批判性观点,帮助中国开源茁壮成长。
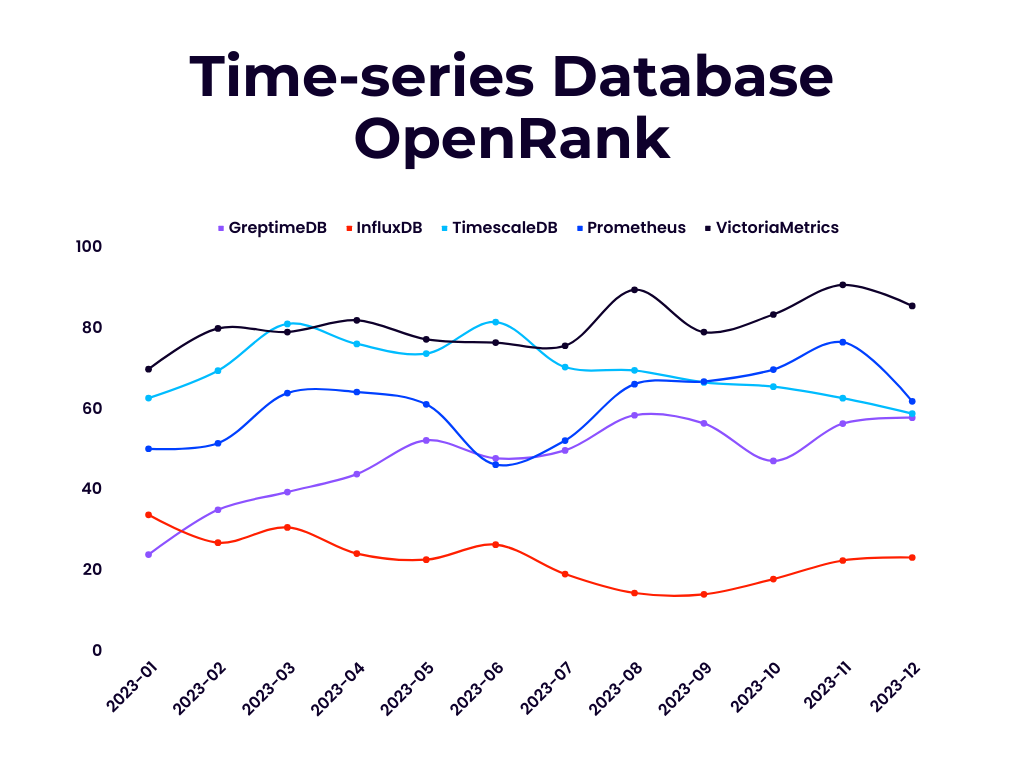
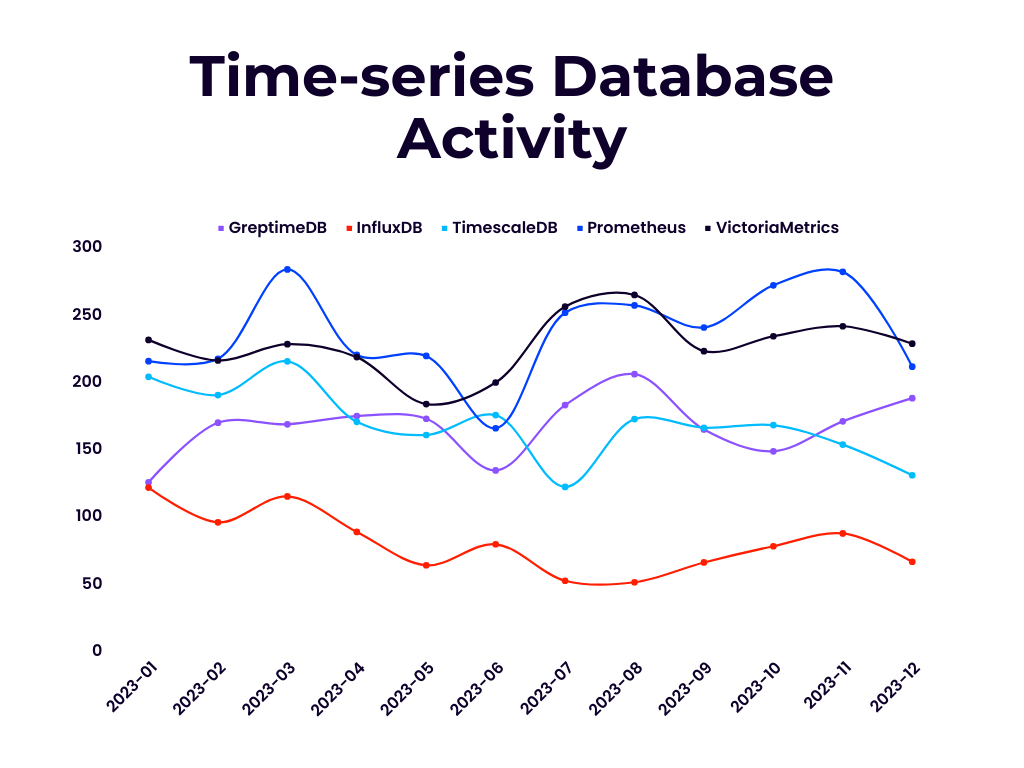
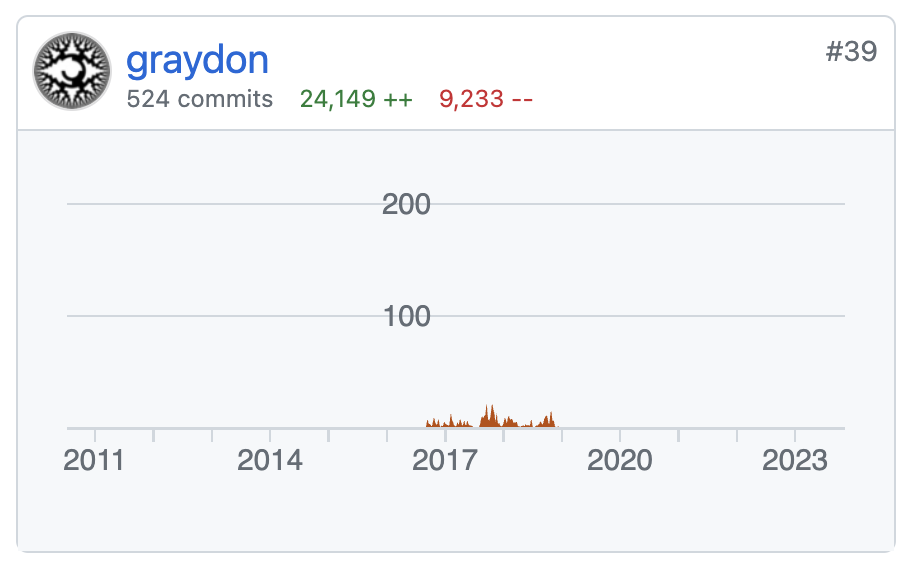
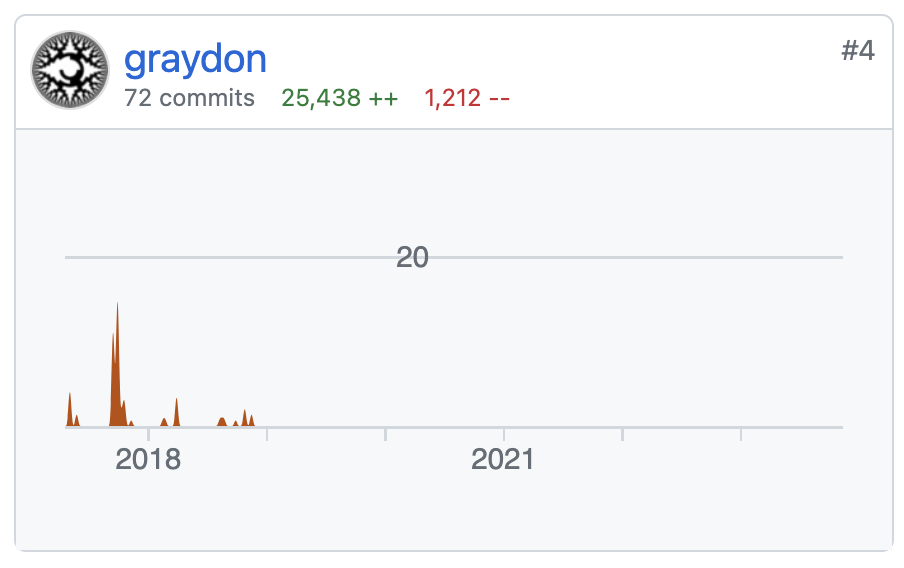
OpenRank 是同济大学赵生宇博士定义的一个开源价值流分析指标。相比于容易受先发优势影响的 Star 数和 DB Engines 分数等指标,上面展示的每月 OpenRank 和 Activity 变化情况更能体现出项目当前的发展情况和未来趋势。
GreptimeDB 的社群运营情况
前面提到,我真正开始关注 GreptimeDB 社群的契机是发现他们的 Community Program 并非船货崇拜,而是明显经过思考,有一定可行性的。事实证明,确实如此。2023 年 GreptimeDB 按照 Community Program 的设计发展了两名公司之外的 Committer 新成员:
此外,Community Program 虽然已经相比其他船货崇拜的同行删减了许多内容,以保证它能够务实地运作,但是仍然存在一些空洞的组织结构。例如设计出的 Steering Committee 做技术和社群发展决策,但是实际上当前阶段大部分工作就是公司团队商议决定后公开;例如还是定义了 SIG 乃至 OSPO 的组织,但是根本没有人力填充运营这些机构。
GreptimeDB 的创始团队认为,这三类数据可以共用同一套查询层和对象存储层能力,只需要针对各自的数据特性实现各自的存储引擎即可。其中大部分 DB 的架构和能力,例如数据分片、分布式路由,以及查询、索引和压缩等都可以共享。这样,GreptimeDB 最终能够成为同时提供所有时序数据最优化的存储和访问体验的单一系统。
GreptimeAI 是为 AI 应用提供可观测性的服务。不同于其他数据库在赶上 AI 浪潮时采用的 PoweredBy AI 增强自身产品的思路,GreptimeAI 是 For AI 增强 AI 产品的思路。其实本轮语言大模型带动的 AI 浪潮对 Database 服务本身的提升还十分有限,反而是这些 AI 应用自身产生的数据需要 Database 来存储和管理。
This is no different to any project that comes to the ASF via the incubator. Many of them need to change names, often before joining the incubator, and all need to change their name to be in the form “Apache Foo”.
OpenZipKin 本是监控领域的明星项目,它愿意进入 ASF 并宣传 The Apache Way 是对 ASF 品牌的巨大帮助。然而,在这封令人伤心的退出提案中,ZipKin 的主创 Adrian Cole 无不失望的写到:
Process and policy ambiguity has been ever present and cost us a lot of time and energy. The incubator spends more energy on failing us than helping us.
“Daul branding” is nothing new, but recently, some entities have taken unfair advantage of this (including one you mentioned), and I feel the Incubator should take care that others do not also do this.
诛心言论,死了也证明不了自己只吃一碗粉。我就觉得你未来要 taken unfair advantage of this 了,你说你不是,我觉得你是。
Why a company would be unwilling to give up that brand or trademark just because it may be convenient in the future is a concern.
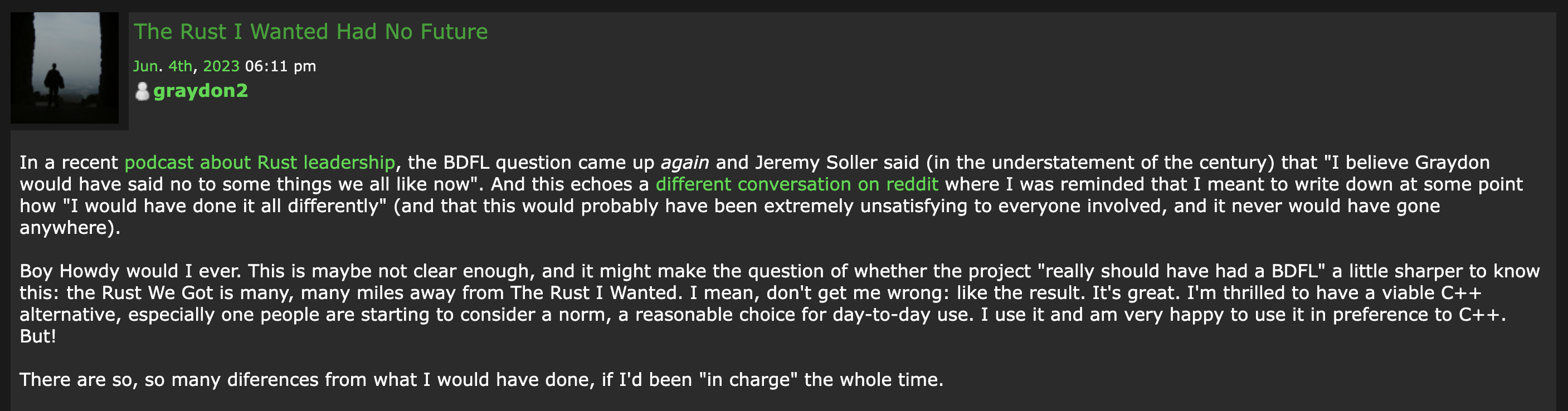
不像 C# 之父 Anders Hejlsberg 和 Python 之父 Guido van Rossum 这样在很长一段时间里可以代表语言本身的人物,也不像 Brian Behlendorf 早期经常代表 Apache Web Server 项目发言,Rust 项目社群的一大特色就是不仅没有所谓的终身的仁慈独裁者(BDFL),甚至很难找到一个有足够权威拍板的人。
由于实现尾调用的计划和其他成员对“性能上胜过 C++ 语言”的目标有冲突,我最终被说服不要使用尾调用。于是,我写了一篇悲伤的帖子来表达我对这个结果的不满,这是这个话题中最令人悲伤的事情之一……如果我是“终身的仁慈独裁者”,我可能会让语言朝着保留尾调用的方向发展。早期的 Rust 有尾调用,但主要是 LLVM 的原因让我们放弃了这个功能,而对跟 C++ 在性能上比拼的执著,使得这个结论几乎永远不会被推翻。
Rust 基金会的成员就像 C++ 标准化委员会里的成员那样,哪个不是行业大鳄,哪个不是已经有或者打算有海量 Rust 生产代码。为了保护自己生产代码不被 Rust 演进制造出庞大的维护迁移成本,这些厂商势必要尽己所能的向 Rust 项目社群发挥自己的影响力。
由于 Rust 的第一作者和绝大多数早期核心作者已经长期离开项目社群,即使现在回来也不可能再建影响力。唯一有足够长时间和技术经验的 Niko Matsakis 又只关心语言技术发展,甚至 Leadership Council 的语言团队代表也让其他成员参与。这种情况下,Rust 项目社群的个人开发者,是不可能跟基金会里的企业有对等的话语权的。
实际上,如果 Rust 真能发展到 C++ 那样的状况,即使 C++ 有公认的第一作者 Bjarne Stroustrup 存在,他也无法在 C++ 委员会中强力推行自己的主张。
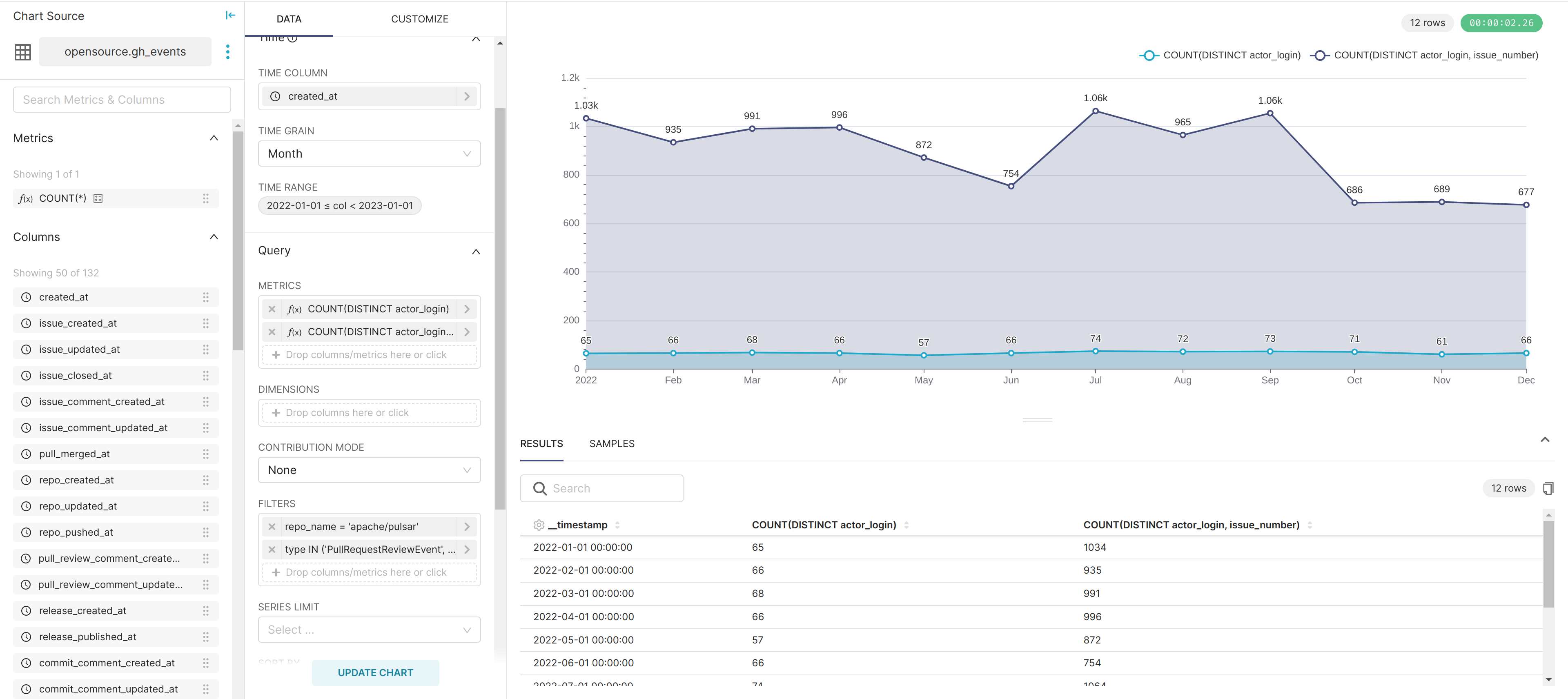
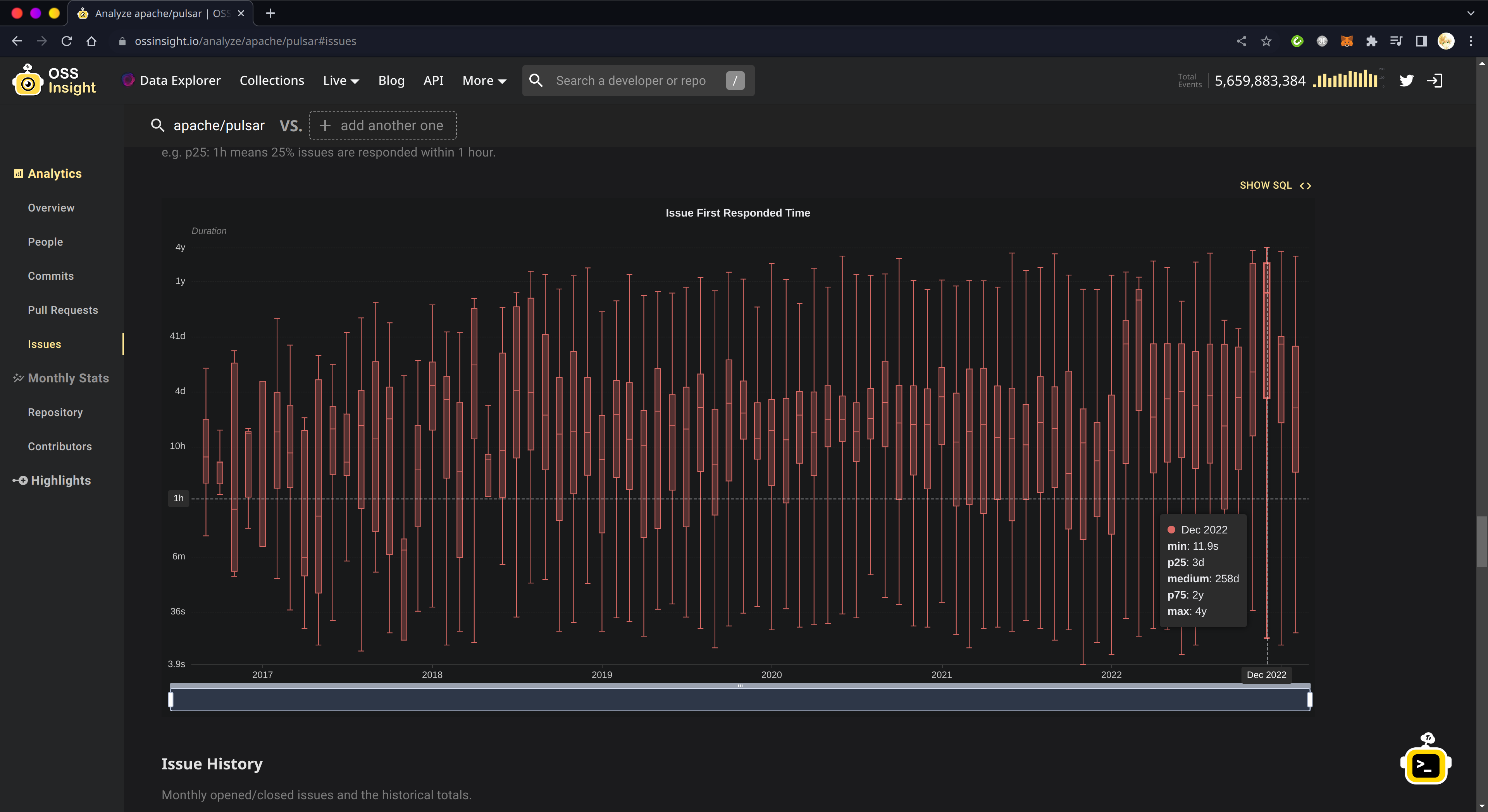
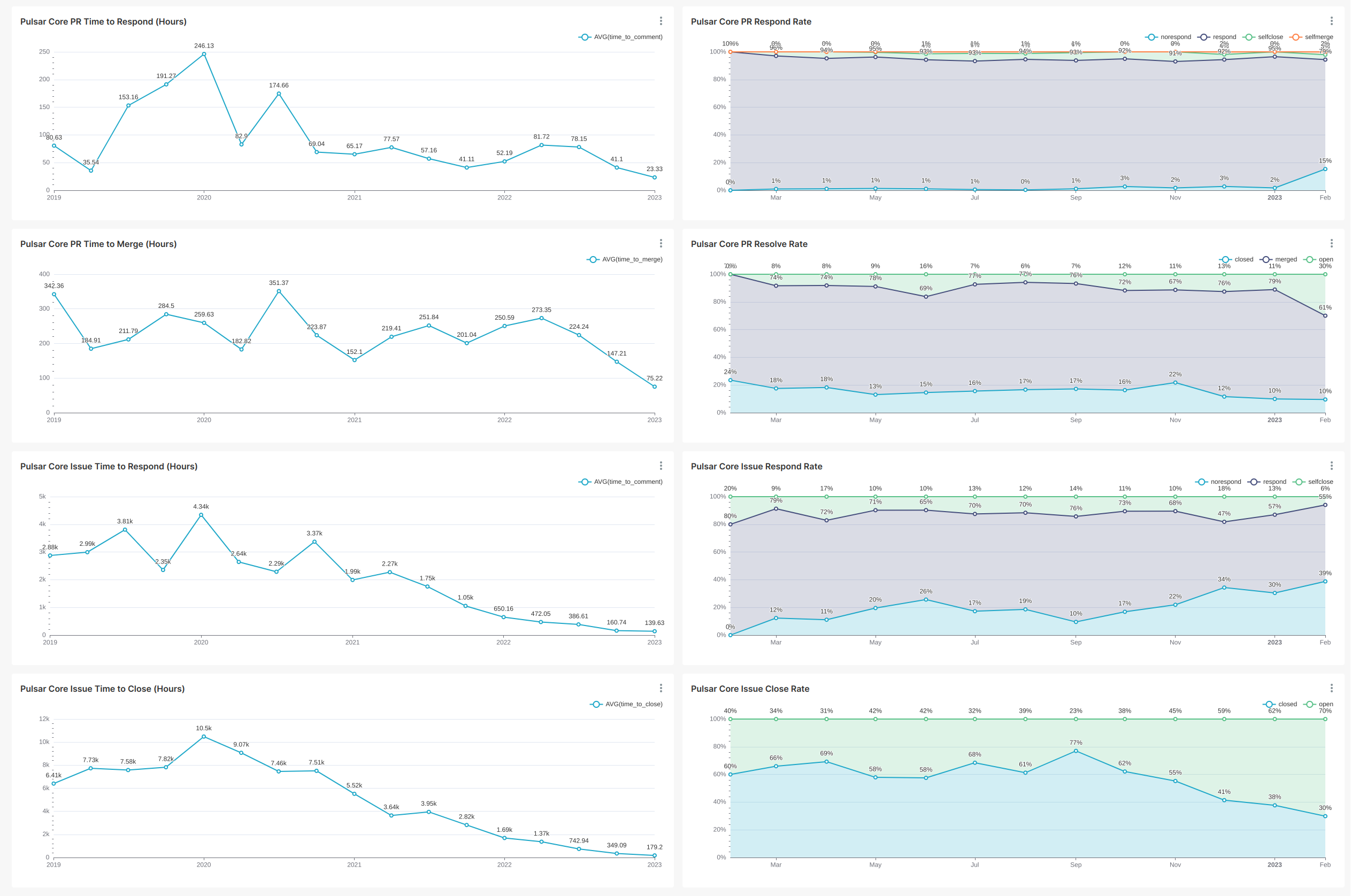
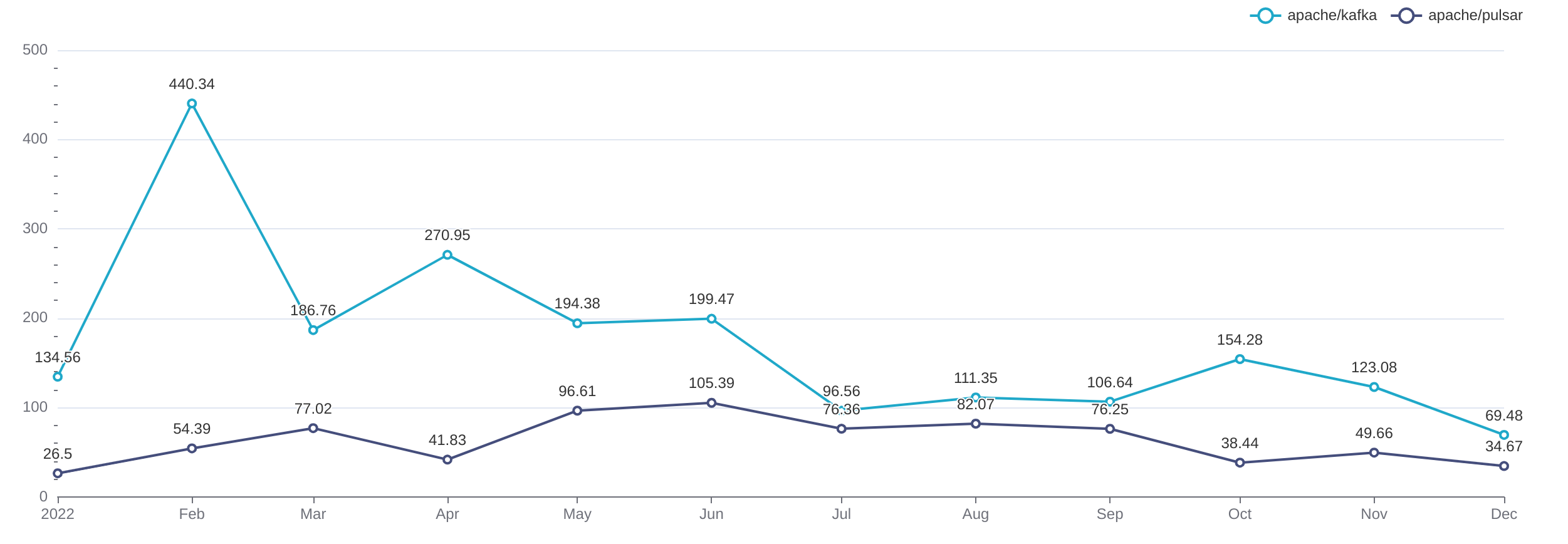
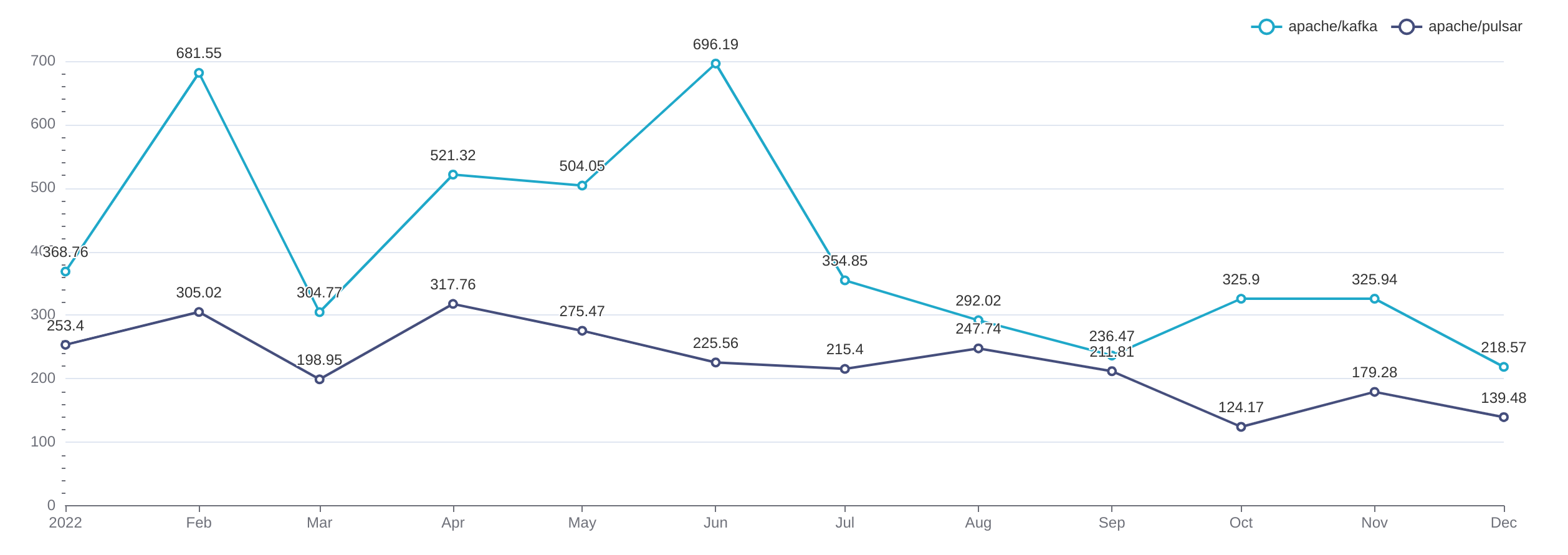
SELECT toStartOfMonth(toDateTime(`created_at`)) AStimestamp, COUNT(DISTINCT actor_login), COUNT(DISTINCT actor_login, issue_number) FROM `opensource`.`gh_events` WHERE `created_at` >='2022-01-01 00:00:00' AND `created_at` <'2023-01-01 00:00:00' AND `repo_name` ='apache/pulsar' AND `type` IN ('PullRequestReviewEvent', 'PullRequestReviewCommentEvent') GROUPBYtimestamp ORDERBYtimestamp
SELECT issue_number, groupArray(b.actor_login)[1] AS author, groupArray(actor_login)[1] AS reviewer, dateDiff('hour', opened_at, commented_at) AS time_to_comment, groupArray(b.created_at)[1] AS opened_at, groupArray(created_at)[1] AS commented_at, groupArray(type)[1] AS type, groupArray(action)[1] AS action_type FROM (SELECT actor_login, created_at, type, action, issue_number FROM `opensource`.`gh_events` WHERE repo_name ='apache/pulsar' AND type IN ('PullRequestEvent', 'PullRequestReviewCommentEvent', 'PullRequestReviewEvent', 'IssueCommentEvent') AND actor_login NOTIN ('github-actions[bot]', 'codecov-commenter') ORDERBY created_at) a JOIN (SELECT actor_login, created_at, issue_number FROM `opensource`.`gh_events` WHERE repo_name ='apache/pulsar' AND type ='PullRequestEvent' AND action ='opened') b ON a.issue_number = b.issue_number WHERE a.actor_login != b.actor_login GROUPBY issue_number ORDERBY issue_number
由于 X-Lab 的数据做了一些预聚合,计算 PR 合并时效可以不用 JOIN 语句:
1 2 3 4 5 6 7 8 9 10 11
SELECT issue_number, MIN(issue_created_at) AS opened_at, MAX(pull_merged_at) AS merged_at, dateDiff('hour', opened_at, merged_at) AS time_to_merge FROM `opensource`.`gh_events` WHERE repo_name ='apache/pulsar' AND type IN ('PullRequestEvent', 'PullRequestReviewCommentEvent', 'PullRequestReviewEvent') GROUPBY issue_number HAVING notEmpty(groupArray(pull_merged_at))
计算比例的 SQL 查询结构相同,但是在最外层 SELECT 仅保留 issue_number 和 opened_at 两列,并用 CASE WHEN 来区分类别:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- Respond -- (CASE WHENCOUNT(DISTINCT actor_login) >1THEN'respond' WHEN notEmpty(groupArray(pull_merged_at)) THEN'selfmerge' WHEN notEmpty(groupArray(issue_closed_at)) THEN'selfclose' ELSE'norespond' END) AS status
-- Merge -- (CASE WHEN notEmpty(groupArray(pull_merged_at)) THEN'merged' WHEN notEmpty(groupArray(issue_closed_at)) THEN'closed' ELSE'open' END) AS status
这个回应也得到了项目作者 Patrick Hunt 的认可。每个软件都有自己的定位,解决它所要解决的问题。用户永远不可能在一个软件当中解决所有问题,适当的组合不同的软件形成解决方案,是应用工程师的本职。对于开源社群来说,这也意味着它总是不能期待解决所有问题,而应该创造出可组合的基础构建块,并积极地和其他社群联合。如果你想解决所有的问题,那么结果往往是每个问题都解决得不好。
例如,Apache Flink DataStream API 的核心作者 Gyula Fora 在 2014-2015 年完成这项工作后,六年间几乎销声匿迹。最近被 Apple 招募之后,在新的需求和开源领域影响力的驱动下,又开始了 Flink Kubernetes Operator 的密集开发。他所做的代码贡献,出自于自己的需求,也契合 Flink 社群中用户的需要,因为这样的原因提交的代码贡献,才能避免形式主义和为做而做的误区,直面需求并解决需求。
我想系统性地做一个开源案例库已经很久了。无论怎么分类筛选优秀的开源共同体,The Apache Community 都是无法绕开的。然而,拥有三百余个开源软件项目的 Apache 软件基金会,并不是一篇文章就能讲清楚的案例。本文也没有打算写成一篇长文顾及方方面面,而是启发于自己的新角色,回顾过去近五年在 Apache Community 当中的经历和体验,简单讨论 Apache 的理念,以及这些理念是如何落实到基金会组织、项目组织以及每一个参与者的日常生活事务当中的。
不过,尽管对讨论的对象做了如此大幅度的缩减,由我自己来定义什么是 Apache 的理念未免也太容易有失偏颇。幸运的是,Apache Community 作为优秀的开源共同体,当然做到了我在《共同创造价值》一文中提到的回答好“我能为你做什么”以及“我应该怎么做到”的问题。Apache Community 的理念之一就是 Open Communications 即开放式讨论,由此产生的公开材料以及基于公开材料整理的文档汗牛充栋。这既是研究 Apache Community 的珍贵材料,也为还原和讨论一个真实的 Apache Community 提出了不小的挑战。
纪录片一开始就讲起了 Apache Httpd 项目的历史,当初的 Apache Group 是基于一个源代码共享的 Web Server 建立起来的邮件列表上的一群人。软件开发当初的印象如同科学研究,因此交流源码在近似科学共同体的开源共同体当中是非常自然的。
如同 ASF 的联合创始人 Brian Behlendorf 所说,每当有人解决了一个问题或者实现了一个新功能,他出于一种朴素的分享精神,也就是“为什么不把补丁提交回共享的源代码当中呢”的念头,基于开源软件的协作就这样自然发生了。纪录片中有一位提到,她很喜欢 Apache 这个词和 a patchy software 的谐音,共享同一个软件的补丁(patches)就是开源精神最早诞生的形式。
这是 Apache Community 的根基,我们将会看到这种朴素精神经过发展形成了一个怎样的共同体,在共同体的发展过程当中,这样的根基又是如何深刻地影响了 Apache 理念的方方面面。
Apache Group 的工作模式还有一个重要的特征,那就是每个人都是基于自己的需求修复缺陷或是新增功能,在邮件列表上交流和提交补丁的个人,仅仅只是代表他个人,而没有一个“背后的组织”或者“背后的公司”。因此,ASF 的 How it Works 文档中一直强调,在基金会当中的个体,都只是个体(individuals),或者称之为志愿者(volunteers)。
我在某公司的分享当中提到过,商业产品可以基于开源软件打造,但是当公司的雇员出现在社群当中的时候,他应该保持自己志愿者的身份。这就像是开源软件可以被用于生产环境或者严肃场景,例如航空器的发射和运行离不开 Linux 操作系统,但是开源软件本身是具有免责条款的。商业公司或专业团队提供服务保障,而开源软件本身是 AS IS 的。同样,社群成员本人可以有商业公司雇员的身份,但是他在社群当中,就是一个志愿者。
All participants in ASF projects are volunteers and nobody (not even members or officers) is paid directly by the foundation to do their job. There are many examples of committers who are paid to work on projects, but never by the foundation itself. Rather, companies or institutions that use the software and want to enhance it or maintain it provide the salary.
Apache Community 对个体贡献者组成社群这点有多么重视呢?只看打印出来不过 10 页 A4 纸的 How it Works 文档,volunteer 和 individuals 两个词加起来出现了 19 次。The Apache Way 文档中强调的社群特征就包括了 Independence 一条,唯一并列的另一个是经常被引用的 Community over code 原则。甚至,有一个专门的 Project independence 文档讨论了 ASF 治下的项目如何由个体志愿者开发和维护,又为何因此是中立和非商业性的。
INDIVIDUALS COMPOSE THE ASF 集中体现了 ASF 以人为本的理念。实际上,不止上面提到的 Independence 强调了社群成员个体志愿者的属性,Community over code 这一原则也在强调 ASF 关注围绕开源软件聚集起来的人,包括开发者、用户和其他各种形式的参与者。人是维持社群常青的根本,在后面具体讨论 The Apache Way 的内容的时候还会展开。
这一倾向可以追溯到 Apache Group 建立的基础。Apache Httpd 派生自伊利诺伊大学的 NCSA Httpd 项目,由于使用并开发这个 web server 的人以邮件列表为纽带聚集在一起,通过交换补丁来开发同一个项目。在项目的发起人 Robert McCool 等大学生毕业以后,Apache Group 的发起人们接过这个软件的维护和开发工作。当时他们看到的软件协议,就是一个 MIT License 精神下的宽容式软件协议。自然而然地,Apache Group 维护 Apache Httpd 的时候,也就继承了这个协议。
后来,Apache Httpd 打下了 web server 的半壁江山,也验证了这一模式的可靠性。虽然有些路径依赖的嫌疑,但是 ASF 凭借近似“上善若水”的宽容理念,在二十年间成功创造了数以百亿计美元价值的三百多个软件项目。
Without limiting other conditions in the License, the grant of rights under the License will not include, and the License does not grant to you, the right to Sell the Software.
附加 The Commons Clause 条款的软件都不是符合 OSD 定义的开源软件,也不再是原来的协议了。NebulaGraph 曾经在附加 The Commons Clause 条款的情况下声称自己是 APL-2.0 协议许可的软件,当时的 ASF 董事吴晟就提 issue (vesoft-inc/nebula#3247) 指出这一问题。NebulaGraph 于是删除了所有 The Commons Clause 的字样,保证无误地以 APL-2.0 协议许可该软件。
APL-2.0 的思路与之不同,它允许任何人以任何形式使用、修改和分发软件,因此 ASF 治下的项目,以及 Linux Foundation 治下采用 APL-2.0 的项目,以及更多个人或组织采用 APL-2.0 的项目,共同构成了强大的开源软件生态,涵盖了应用软件,基础库,开发工具和框架等等各个方面。事实证明,“鼓励”而不是“要求”用户秉持 upstream first 的理念,尽可能参与到开源共同体并交换知识和补丁,共同创造价值,是能够制造出高质量的软件,构建出繁荣的社群和生态的。
反观 Linux Foundation 的主要思路,则是关注围绕项目聚集起来的供应商,以行业联盟的形式举办联合市场活动扩大影响,协调谈判推出行业标准等等。典型地,例如 CNCF 一直致力于定义云上应用开发的标准,容器虚拟化技术的标准。上述 ASF Infra 关注的内容和资源,则大多需要项目开发者自己解决,这些开发者往往主要为一个或若干个供应商工作,他们解决的方式通常也是依赖供应商出力。
当然,上面的对比只是为了说明区别,并无优劣之分,也不相互对立。ASF 的创始成员 Brian Behlendorf 同时是 Linux Foundation 下 Open Source Security Foundation 的经理,以及 Hyperledger 的执行董事。
提到匠人精神,一个隐形的开发者福利,其实是 ASF 的成员尤其是孵化器的 mentor 大多是经验非常丰富的开发者。软件开发不只是写代码,Apache Community 成员之间相互帮助,能够帮你跟上全世界最前沿的开发实践。如何提问题,如何做项目管理,如何发布软件,这些平日里在学校在公司很难有机会接触的知识和实践机会,在 Apache Community 当中只要你积极承担责任,都是触手可得的。
当然,如何写代码也是开发当中最常交流的话题。我深入接触 Maven 开始于跟 Flink Community 的 Chesnay Schepler 的交流。我对 Java 开发的理解,分布式系统开发的知识,很大程度上也得到了 Apache Flink 和 Apache ZooKeeper 等项目的成员的帮助,尤其是 Till Rohrmann 和 Enrico Olivelli 几位。上面提到的 Ted Dunning 开始攻读博士的时候,我还没出生。但是我在项目当中用到 ZooKeeper 的 multi 功能并提出疑问和改进想法的时候,也跟他有过一系列的讨论。
谈到技艺就会想起人,这也是 ASF 一直坚持以人为本带来的社群风气。
我跟姜宁老师在一年前认识,交流 The Apache Way 期间萌生出相互认同。姜宁老师在 Apache 孵化器当中帮助众多项目理解 The Apache Way 并予以实践,德高望重。在今年的 ASF Members 年会当中,姜宁老师也被推举为 ASF Board 的一员。
虽然一个开源共同体可能为了推动软件的开发会建立相应的组织结构,但是在所有知识社群当中,知识的交换都是自由的,或者说去中心化的。Apache 软件基金会在 The Apache Way 当中强调了它所构建的开源共同体是由平等的个体所构成的。
Community of Peers: individuals participate at the ASF, not organizations. The ASF’s flat structure dictates that roles are equal irrespective of title, votes hold equal weight, and contributions are made on a volunteer basis (even if paid to work on Apache code). The Apache community is expected to treat each other with respect in adherence to our Code of Conduct. Domain expertise is appreciated; Benevolent Dictators For Life are disallowed.
社群协调员会关注到社群新人的招募,会见潜在的成员,并联络核心成员以对齐社群对关键问题的认识和增强人际连接。思想领袖是社群关注的领域的专家,他们能够定义前沿问题,或者本身是具备丰富经验、德高望重的从业者。思想领袖的加入为社群提供了强有力的凝结核,试想 Ruby on Rails 的作者为 Ruby 社群带来了多少 web 开发者的参与。
We prefer “Do NOT confuse users” because we accepted projects nearly doing the same thing. We always encourage more people could join together and build a more powerful project and community, rather than building several similar projects.