Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
以上版权声明及本许可声明应包含在本软件的所有副本或主要部分中。
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
这些工具大多提供为应用软件生成软件物料清单(Software Bill of Materials, SBOM),即罗列出软件所有依赖项的名字、协议属性和代码数字签名等等。这应当会成为未来软件供应链一个必然的趋势,欧盟今年出台的《网络弹性法案》就有此要求,从制造业的发展来看,物料清单也是产业发展成熟的一个最佳实践。
其实,前段时间 Linux 基金会移除 Linux 项目中特定开发者的 MAINTAINERS 权限,跟上面分析的“开源断供”风险还有一些不同。
首先,根据目前的信息,Linux 基金会实际做的操作是根据一份美国政府的制裁名单,确保被制裁的个人或为被制裁企业提供服务的个人不出现在 MAINTAINER 列表上。这在规则上,并不影响 Linux 项目接收这些人提交的代码补丁。此外,被制裁的个人和企业实际上仍然可以自由地使用 Linux 软件。从供应链角度上看,没有直接的“断供”风险。
但是,这样的行为对特定下游用户的使用仍然是有实际影响的。例如,移除特定 MAINTAINERS 可能会导致 Linux 的某些模块现在事实上处于无人维护的状态,因此,原本将这些模块视为可靠依赖的下游,将不得不重新评估如何处理对相关模块的依赖。此外,企业由于受到制裁,而无法将任何员工培养成关键开源项目的维护者,可能会严重影响企业采用该开源项目的成本评估。这些就是更加复杂而大部分企业暂时遇不到的情况了,本文不做展开讨论。
但是,相比起开放源代码促进会(OSI)和 TODO Group 这样,在通用开源和企业开源领域能够提出见解和倡议的组织,开源社在掌握开源话语权这个议题上显得比较弱势。随着中国开源力量的崛起,如何引导各方参与者正确认识开源,在开源环境当中高效协作创新,将是一个无可回避的问题。我热切期望开源社能够发挥自己所在生态位的优势,联合开源社的志愿者,向社会不断输出批判性观点,帮助中国开源茁壮成长。
所以一个 async-crossbeam 可能是目前我最想看到的社群库,或许它可以是 futures-util 的扩展和优化。这些东西不进标准库或者事实标准库,各家整一个,真的有 C++ 人手一个 HashMap 实现的味道了。
第二个缺失点,顺着说下来就是 Async Runtime 的实现。Tokio 虽然够用,但是它出现的时间真的太早了,很多接口设计没有跟 Async Rust 同步走,带来了很多问题。前段时间 Rust Async Working Group 试图跟 Tokio 协商怎么设计标准库的 Async Runtime API 最终无疾而终,也是 Tokio 设计顽疾和社群摆烂的一个佐证。
我想,作为面向开发者的大会,最希望看到 CommunityOverCode Asia 顺利举办的,是每一位热爱开源的开发者。我向组织者建议,明年筹款的时候,其一可以实时公布筹款进度,让潜在的赞助者知道要想会议成功举办,还需要自己的多少支持;其二可以开通个人赞助的渠道,我想参与开源的开发者们众志成城,并不难凑齐这样一场年度盛会所需要的小几十万元人民币。
我在这里承诺,如果明年开通了个人赞助的渠道,我将以本人的名义或届时所在公司的名义,捐赠不少于十万元人民币以作支持。期待明年 CommunityOverCode Asia 越办越好!
DataFusion is great for building projects such as domain specific query engines, new database platforms and data pipelines, query languages and more. It lets you start quickly from a fully working engine, and then customize those features specific to your use.
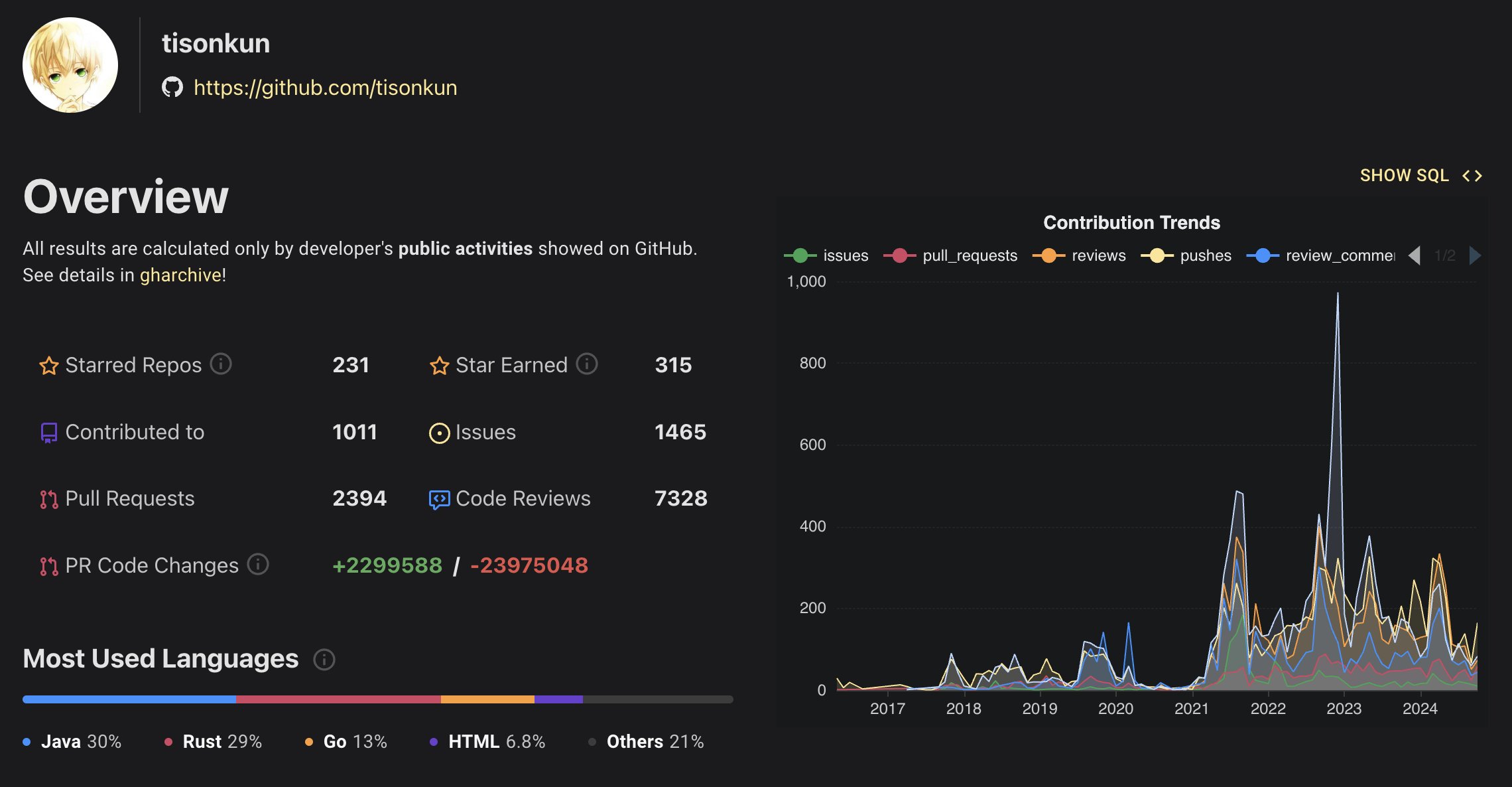
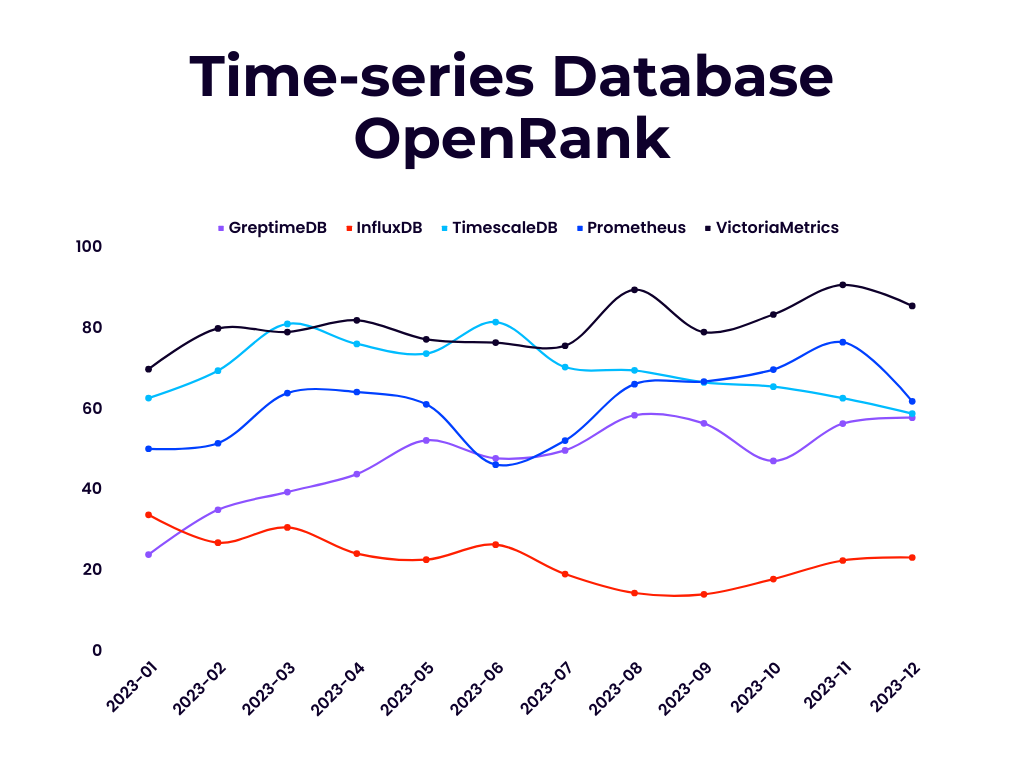
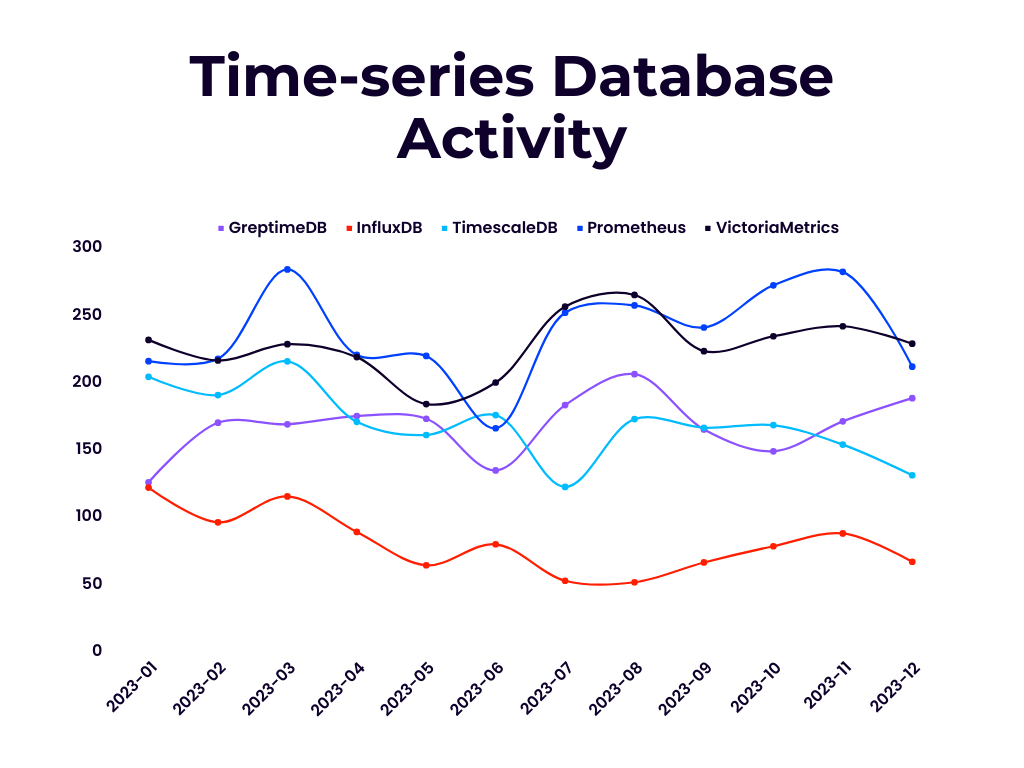
OpenRank 是同济大学赵生宇博士定义的一个开源价值流分析指标。相比于容易受先发优势影响的 Star 数和 DB Engines 分数等指标,上面展示的每月 OpenRank 和 Activity 变化情况更能体现出项目当前的发展情况和未来趋势。
GreptimeDB 的社群运营情况
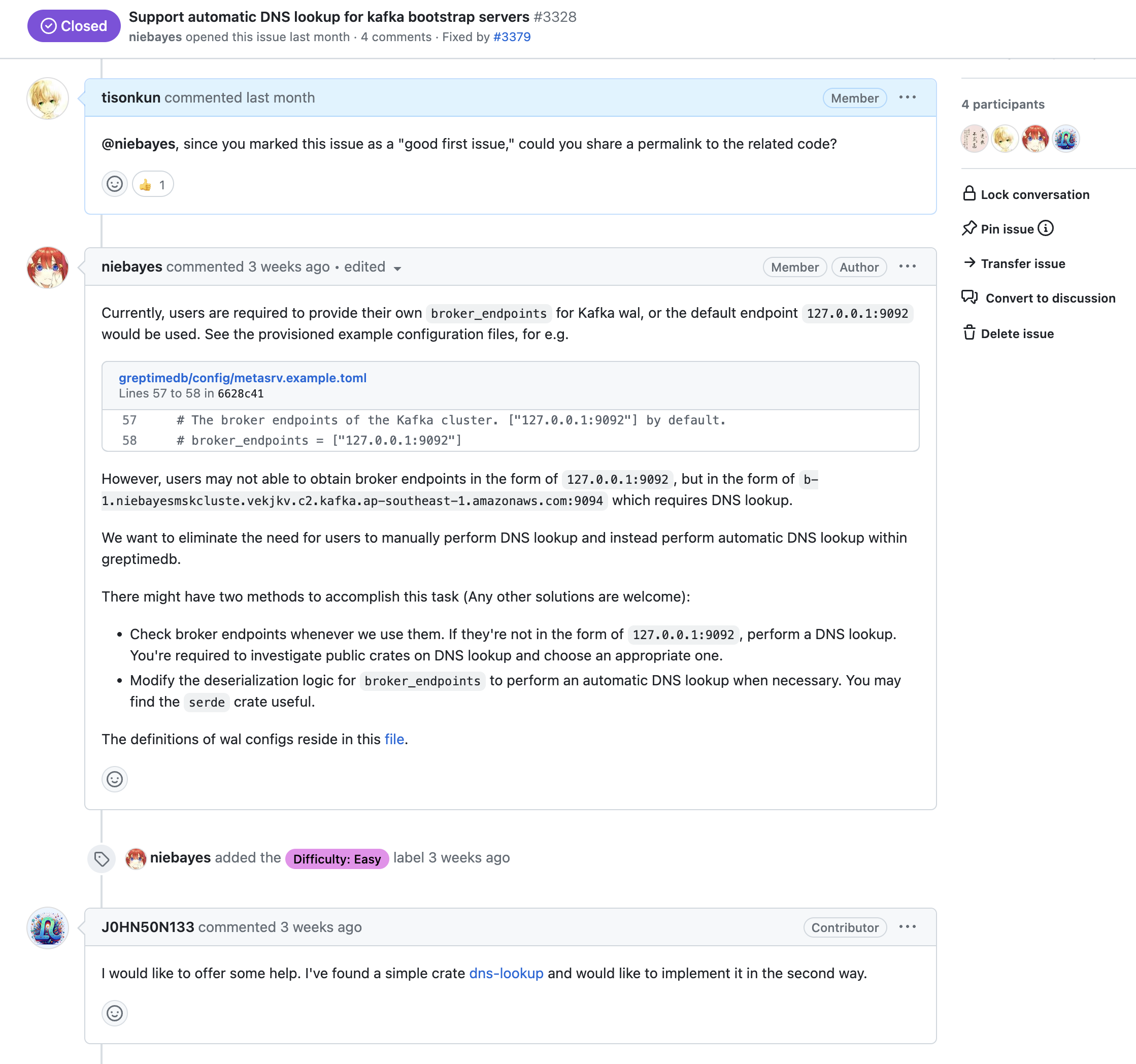
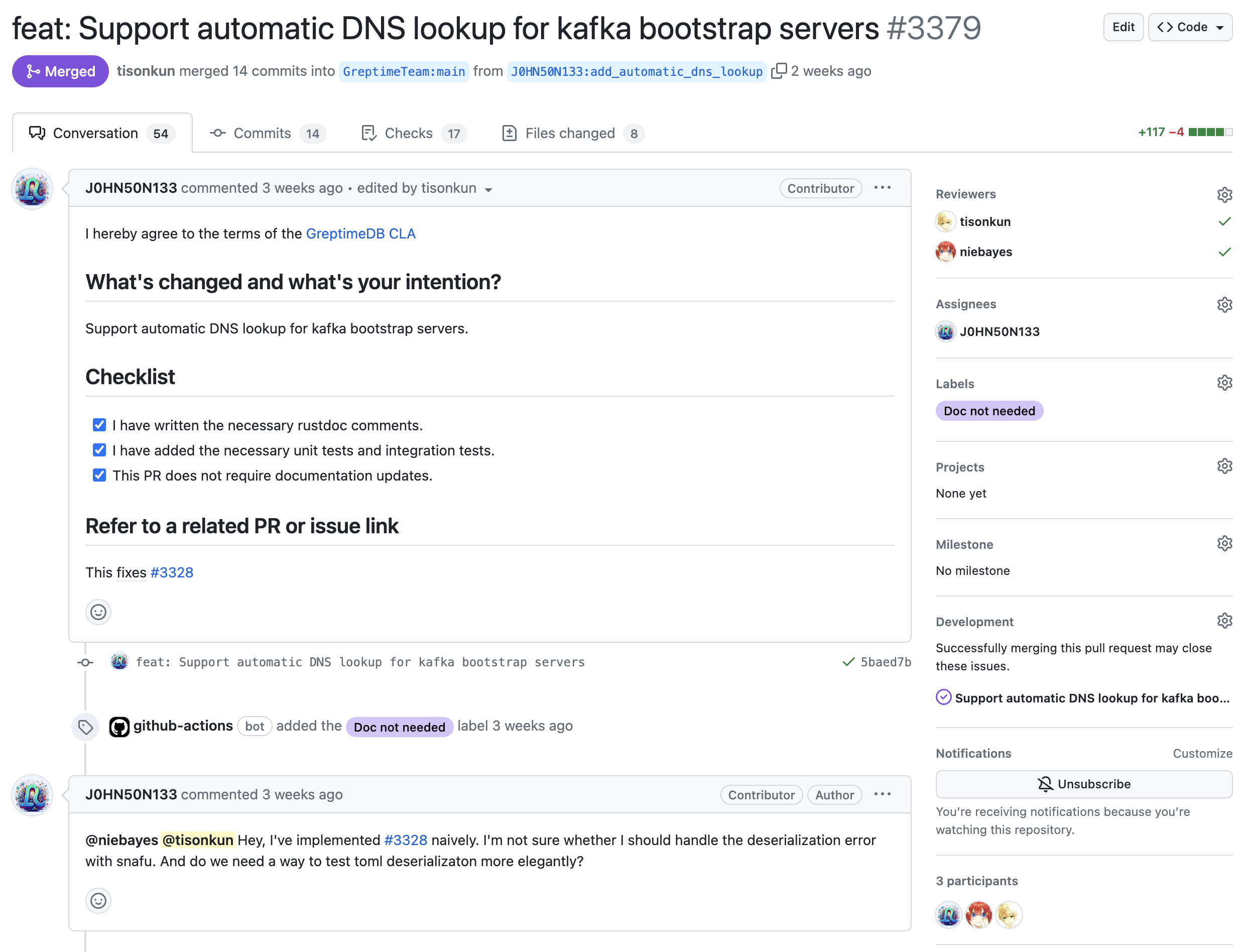
前面提到,我真正开始关注 GreptimeDB 社群的契机是发现他们的 Community Program 并非船货崇拜,而是明显经过思考,有一定可行性的。事实证明,确实如此。2023 年 GreptimeDB 按照 Community Program 的设计发展了两名公司之外的 Committer 新成员:
此外,Community Program 虽然已经相比其他船货崇拜的同行删减了许多内容,以保证它能够务实地运作,但是仍然存在一些空洞的组织结构。例如设计出的 Steering Committee 做技术和社群发展决策,但是实际上当前阶段大部分工作就是公司团队商议决定后公开;例如还是定义了 SIG 乃至 OSPO 的组织,但是根本没有人力填充运营这些机构。
GreptimeDB 的创始团队认为,这三类数据可以共用同一套查询层和对象存储层能力,只需要针对各自的数据特性实现各自的存储引擎即可。其中大部分 DB 的架构和能力,例如数据分片、分布式路由,以及查询、索引和压缩等都可以共享。这样,GreptimeDB 最终能够成为同时提供所有时序数据最优化的存储和访问体验的单一系统。
GreptimeAI 是为 AI 应用提供可观测性的服务。不同于其他数据库在赶上 AI 浪潮时采用的 PoweredBy AI 增强自身产品的思路,GreptimeAI 是 For AI 增强 AI 产品的思路。其实本轮语言大模型带动的 AI 浪潮对 Database 服务本身的提升还十分有限,反而是这些 AI 应用自身产生的数据需要 Database 来存储和管理。
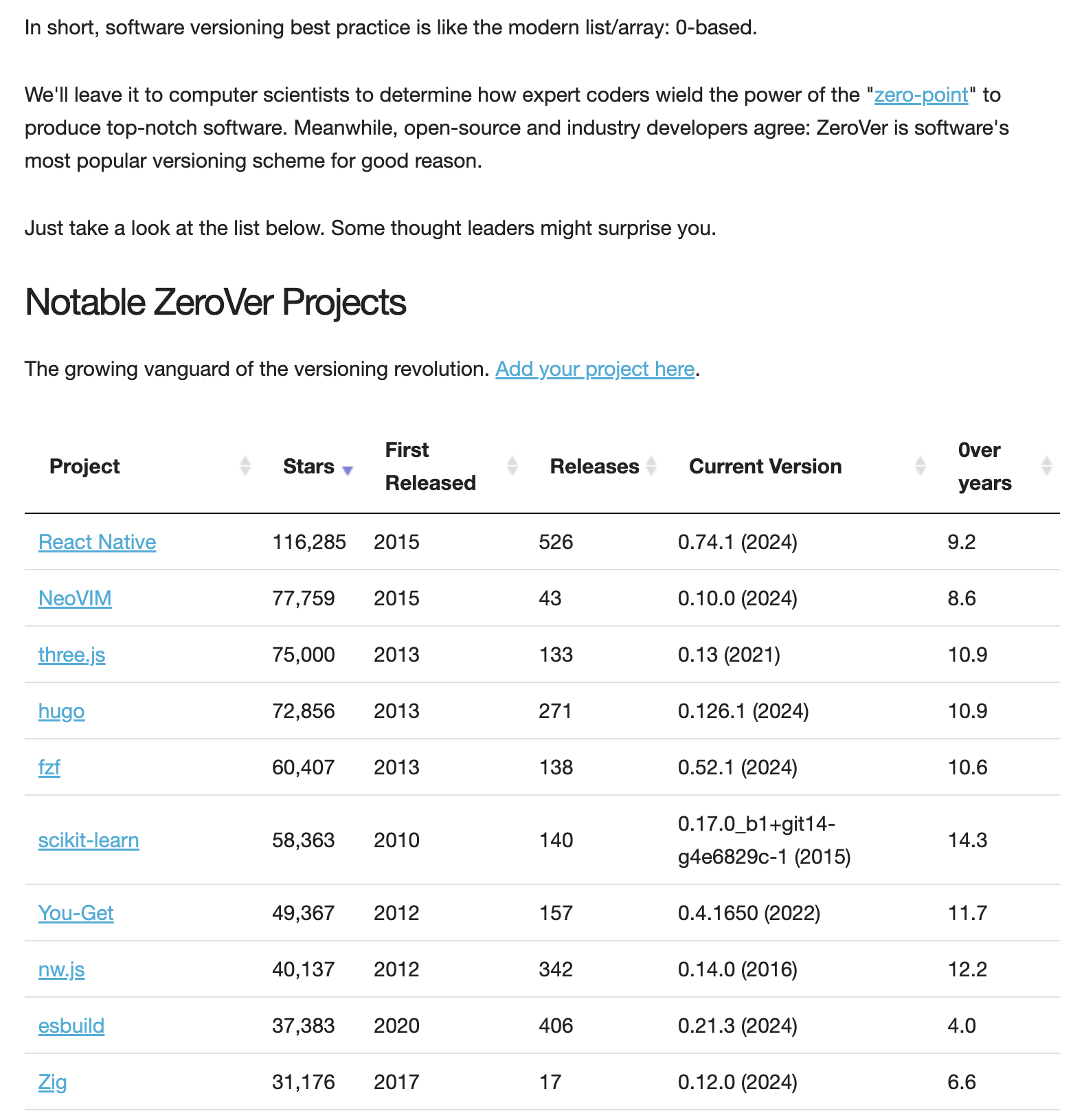
典型的虚荣指标包括点击量和下载量,放在如今开源运动盛行的开发者关系工作上,还有软件代码仓库的 star 数等等。
这些指标共同的实际问题在于信息量太少。例如要做 star 数的指标,我们做过去几年中反复看到,被分配此项任务的运营人员用小礼物在各式活动现场以扫街地推的方式引诱开发者点击 star 按钮。对于单纯的下载量指标,我很清楚自动化流水线会对此产生多大的噪音,以至于使用这一指标的团队完全无法从一个每月下载几万到几十万的数据当中得到任何有用的信息。
信息量太少的原因是行为太简单或者说成本太低。任何一个路人,即使不是开发者,也可能为了小礼物而点击 star 按钮,或许他点完 star 拿了礼物,还会顺手再按一次取消。不加区分的页面点击量和下载量也是如此,除了作为某种谈资,很难指导开发者关系工作的开展。
Star 数这个指标没什么额外的变化空间,唯一能想到的价值是在做广告宣传时跟同类产品做比较,给到一个虚假的直观印象。但是,页面点击和下载行为是可以通过一些精细化的分析来增强的。
针对页面点击行为,简单的有 Google Analytics 分析点击来源的不同地区、不同源网站,分析各个页面的跳入跳出率。复杂一点的有 ReadMe 做的访客全路途分析,甚至集成到 API 页面调用和结果反馈。在数字指标以外,类似 Vercel 和 GitHub 的官方网站尤其是文档,都会添加交互反馈的小组件。这些指标或组件的目的都是优化网站内容的组织呈现,改善用户访问体验。
最简单的一个市场声量数据就是 Google 指数,但是在如今的自媒体多媒体传媒时代,单纯看 Google 指数很容易掉进坑里,尤其是当项目刚刚起步的时候,很少有开发者是通过 Google 进入到你的范围的。
某些细分领域有成熟的市场声量定义,例如数据库领域的 DB Engines 排行榜。它详细地说明了分数的计算因子,同时提供了细分领域的排名。重要的是,数据库领域内部对比和用户选型时,真的会把 DB Engines 作为一个参考指标。对于一个新兴的数据库软件来说,可以先确定自己所处的细分领域,主要的竞争对手,在多长的时间内要超越哪些对手或者进入到前几名的位置。
就语言绑定技术而言,Rust 本身支持 C FFI 决定了 C Binding 的实现是非常流畅的。大部分语言也会提供访问 C API 的集成方式,于是通过 C Binding 可以产生其他语言的绑定。这也是 OpenDAL Haskell / Lua / Zig 等一众绑定的实现方式。
在这种大量利用现有技术的方案之外,上面提到的 jni-rs 和 napi-rs 等技术,则是在已有的 C API 集成方式之上,封装了一层符合 Rust 习惯的接口,从而在开发层面只需要涉及 Rust 语言和绑定目标语言。PyO3 更进一步,为这个开发过程研发了一套脚手架,中间打包和配置对接的工作也全部简化了。应该说,这是 Rust 生态主动向绑定目标语言靠拢。底层技术上,两边仍然是基于 C ABI 在通信。
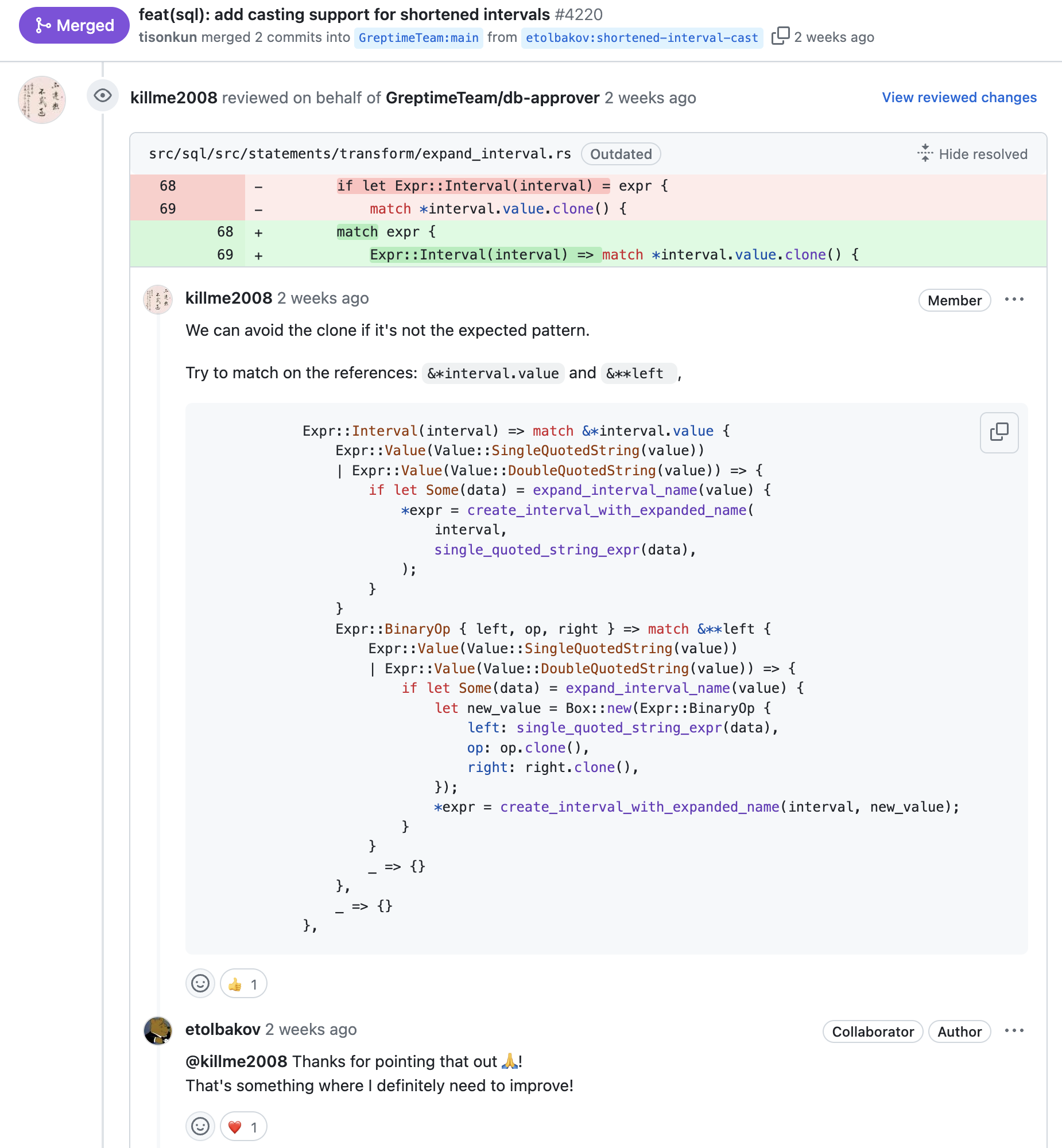
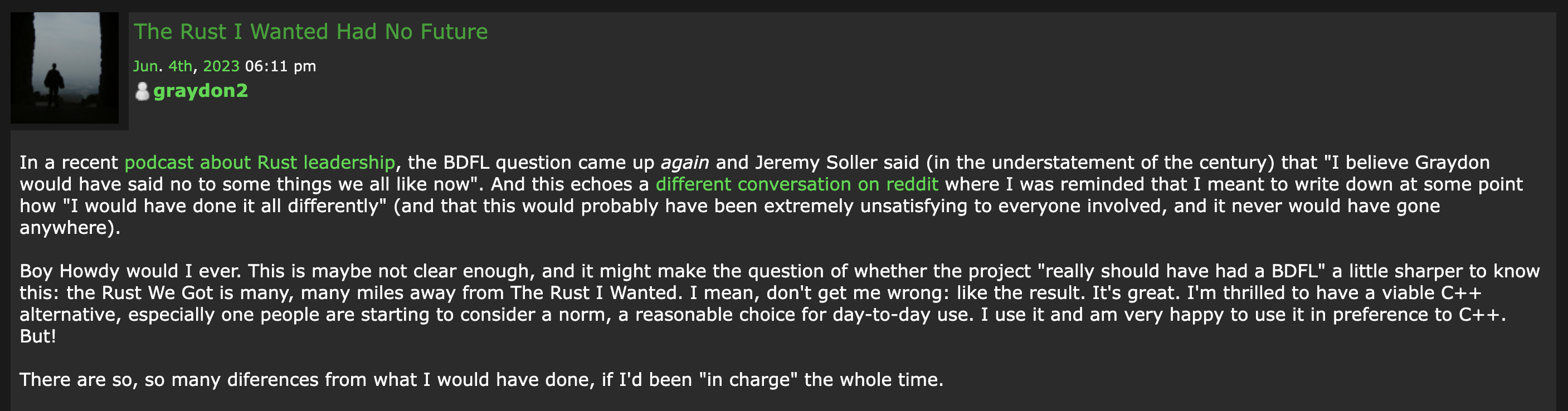
现在回头看,其实一开始 Justin 的表达是 “I found a few minor issues where some name and branding work needs to be done.” 并不十分强烈。但是在 Xuanwo 首次回复没有做到 Justin 期望的完美符合 ASF 政策之后,他表示 PMC 应该要“好好学习相关政策”。
The ASF is well past the point where a small number of folks who have huge “tribal knowledge” can guide the number of projects and podlings that we now have.
This is no different to any project that comes to the ASF via the incubator. Many of them need to change names, often before joining the incubator, and all need to change their name to be in the form “Apache Foo”.
OpenZipKin 本是监控领域的明星项目,它愿意进入 ASF 并宣传 The Apache Way 是对 ASF 品牌的巨大帮助。然而,在这封令人伤心的退出提案中,ZipKin 的主创 Adrian Cole 无不失望的写到:
Process and policy ambiguity has been ever present and cost us a lot of time and energy. The incubator spends more energy on failing us than helping us.
“Daul branding” is nothing new, but recently, some entities have taken unfair advantage of this (including one you mentioned), and I feel the Incubator should take care that others do not also do this.
诛心言论,死了也证明不了自己只吃一碗粉。我就觉得你未来要 taken unfair advantage of this 了,你说你不是,我觉得你是。
Why a company would be unwilling to give up that brand or trademark just because it may be convenient in the future is a concern.
Seata is being developed by the development team inside Alibaba who’s responsible for building internal distributed system too. Since Seata was open-sourced on GitHub, it has gained significant traction, receiving up to 24k stars, being forked over 8k times, and having more than 40 versions released. Besides being widely adopted inside Alibaba and Ant Group, Seata is also widely adopted by hundreds of other companies, including … For more information, please click here. We aim to expand the contributor by inviting all those who make valuable contributions and excel in adhering to The Apache Way. The Seata project and its side projects always accept contributions from individuals outside of Alibaba.
Currently, Fury has only three core developers, but they are not homogenous: although Chaokun and Weipeng work at the same company, they know each other only due to their common interest in Fury. Mingyang Liu joined the Fury community recently, and he mainly contributed to C++ part of Fury. We don’t have enough diversity for now. It’s a risk, although we’re optimistic about future developer diversity. Since Fury is open-source, we have attracted more than 20 developers to contribute. We will keep building community diversity following The Apache Way.
tison’s comment: Although only three initial committers are listed above, PJ (who contributes to Jackson also) and I, as mentors, would participate in the development. Also, another podling that I mentored, named OpenDAL, has four initial committers but so far invited nine (days before its tenth) committers and two PPMC members, done eight (now during its ninth) releases. From my experience with Fury’s initial committers, I saw several shared characteristics with OpenDAL’s members. So, I’d invest efforts to help this project grow within the ASF Incubator.
Currently, the lead developers for Hudi are from Uber. However, we have an active set of early contributors/collaborators from Shopify, DoubleVerify and Vungle, that we hope will increase the diversity going forward. Once again, a primary motivation for incubation is to facilitate this in the Apache way.
Reliance on Salaried Developers 这点跟同质化开发者有相似之处,不过其实并不一定是坏事。Flink 的开发如果不是拿钱,一个纯粹的志愿者是很难撑起社群的需要的。所以关于这个问题,我认为要么是不依赖,表达出项目核心团队对技术本身的追求和认同,要么是确实就是一直有钱雇佣开发者做这个项目,都没有问题。同样这里容易产生一些不真诚的地方,明明就是一群拿钱办事的人,编造出自己没钱也会做的谎言就显得很可笑。
HoraeDB 的提案里并没有回避这个问题:
We acknowledge that most developers are supported by their employers to contribute to HoraeDB, which poses a significant risk. However, HoraeDB has already been extensively deployed within Ant Group, with no internal forked versions. The version available on GitHub is the actual production version used in practice. As a result, Ant Group can ensure long-term commitment. We believe that within this timeframe, we can attract more maintainers and developers from diverse backgrounds to address this risk.
Although Fury is created at work time in Ant Group, Chaokun and Weipeng contribute to Fury in their spare time. They love the process of building such a versatile framework and the value it brings to all users and organizations. They will continue to work on Fury even if they leave their current cooperation, and Mingyang Liu also contributes to Fury in his spare time. We plan to attract more committers to address this risk.
Relationships with Other Apache Products 如实回复即可。
A Excessive Fascination with the Apache Brand 这个问题是整个提案模板里最容易被误会的一条,反应了我一开始说的撰写提案时最主要的两个问题,第一个是英语技能不熟练。
这个问题的意思是,项目是否只是“对 Apache 品牌的过度迷恋”而捐赠,而不是孵化器关注的按照 The Apache Way 建设社群。换句话说,是不是只想借 Apache 的品牌做营销。不少草案写作时不知为何理解成要表达对 Apache 品牌的认可,洋洋洒洒写了一堆说 Apache 品牌是如何如何的好,完全是背道而驰。
Although we expect that the Apache brand may help attract more contributors, our interest in starting this project is based on the factors mentioned in the fundamentals section. We are interested in joining ASF to increase our connections in the open-source world. Based on extensive collaboration, it is possible to build a community of developers and committers that live longer than the founder.
此前的 Core Team 和 Moderation Team 不仅相互之间缺乏沟通,甚至本身成员也相对独立于其他顶级团队,这导致本应作为协同社群反馈和各个顶级团队之间合作的两个独立团队,跟其他顶级团队之间也可能缺乏互信基础和合作机制。新的 Leadership Council 成立并以九个顶级团队代表为成员,期望在维持先前 Core Team 所要解决的问题的基础上,提高团队之间的协同效率。
对于基金会,可以明显的看到在机制上它相当于 Linux Foundation 之于 Linux 或是 Python Foundation 之于 Python 的形式,前两者在运行过程中间并未出现如同 Rust 社群这样的戏剧性发展。其原因部分在于它们有一锤定音的 BDFL 主导技术开发和项目团队合作,另一方面也是在这样长期的运作方式下,项目团队成员发展出一套自己解决问题的办法,而不是被不满意的现状困扰,转而祈求外部力量奇迹般的解决问题。
Rust Foundation 的性质是 501(c)6 行业联盟,这跟 Linux Foundation 是一致的,它们存在的目的除了写下来的维持 Rust 的存续发展,从性质上说是要为商业联盟中的成员企业服务的。相反,Python Foundation 和 Perl Foundation 的性质是与 Apache Software Foundation 相同的 501(c)3 慈善组织,纯粹是为项目本身的发展和公众利益服务。与此相匹配地,就是慈善机构型基金会往往在募集资金上不如商业联盟型基金会。
如前所述,由于 Mozilla 无法或不愿入局,如今 Rust Foundation 的四个创始会员分别是 AWS、谷歌、华为和微软。它们并没有像 Oracle 在 JCP 执行委员会中那样继承自 Sum 并再次发展得到的垄断权,甚至 Rust Foundation 本身也没有 JCP 那样直接指导语言项目技术发展方向的权限。但是,既然 Core Team 可以改组,Rust 社群整体对于基金会干涉项目发展存有期望,那么在未来社群治理的发展或者至少每次讨论当中,基金会就有可能发挥出自己的影响力。
不像 C# 之父 Anders Hejlsberg 和 Python 之父 Guido van Rossum 这样在很长一段时间里可以代表语言本身的人物,也不像 Brian Behlendorf 早期经常代表 Apache Web Server 项目发言,Rust 项目社群的一大特色就是不仅没有所谓的终身的仁慈独裁者(BDFL),甚至很难找到一个有足够权威拍板的人。
由于实现尾调用的计划和其他成员对“性能上胜过 C++ 语言”的目标有冲突,我最终被说服不要使用尾调用。于是,我写了一篇悲伤的帖子来表达我对这个结果的不满,这是这个话题中最令人悲伤的事情之一……如果我是“终身的仁慈独裁者”,我可能会让语言朝着保留尾调用的方向发展。早期的 Rust 有尾调用,但主要是 LLVM 的原因让我们放弃了这个功能,而对跟 C++ 在性能上比拼的执著,使得这个结论几乎永远不会被推翻。
Rust 基金会的成员就像 C++ 标准化委员会里的成员那样,哪个不是行业大鳄,哪个不是已经有或者打算有海量 Rust 生产代码。为了保护自己生产代码不被 Rust 演进制造出庞大的维护迁移成本,这些厂商势必要尽己所能的向 Rust 项目社群发挥自己的影响力。
由于 Rust 的第一作者和绝大多数早期核心作者已经长期离开项目社群,即使现在回来也不可能再建影响力。唯一有足够长时间和技术经验的 Niko Matsakis 又只关心语言技术发展,甚至 Leadership Council 的语言团队代表也让其他成员参与。这种情况下,Rust 项目社群的个人开发者,是不可能跟基金会里的企业有对等的话语权的。
实际上,如果 Rust 真能发展到 C++ 那样的状况,即使 C++ 有公认的第一作者 Bjarne Stroustrup 存在,他也无法在 C++ 委员会中强力推行自己的主张。
原注 “Modification of Final Judgment,” August 24, 1982, filed in case 82-0192, United States of America v. Western Electric Company, Incorporated, and American Telephone and Telegraph Company, U.S. District Court for the District of Columbia web.archive.org/web/20060827191354/members.cox.
自由软件运动以及随后的开源运动是对 UNIX 私有化的回应。它们试图防止基础设施软件再次走向封闭。这个运动以 UNIX 的自由软件替代品 Linux 为中心,并很快发展成一个认为“所有软件生而自由”的具有巨大影响力的运动。这个运动的核心理念包括用户有权访问源代码、改进软件和分享软件的改进版本。这些原则体现在 GNU 通用公共协议(GPL)中,该协议要求二进制文件的分发者必须向接受者免费提供相应的源代码。
随着云服务的业务规模增长,这种范式转变激化了部分开源社群和 AWS 等企业之间的紧张关系。云厂商没有任何法律义务分享他们的改进。有点讽刺的是,这种情况有时被称为“Google 漏洞”。“Google 漏洞”这一称谓之所以说讽刺,是因为尽管谷歌依赖 Linux 来支持其搜索服务,但是谷歌和许多其他顶级云厂商(如 IBM 等)为包括 Linux 在内的开源社群做出过重大贡献。
If you modify the Program, your modified version must prominently offer all users interacting with it remotely through a computer network … an opportunity to receive the Corresponding Source of your version by providing access to the Corresponding Source from a network server at no charge, through some standard or customary means of facilitating copying of software….
If you make the functionality of the Program or a modified version available to third parties as a service, you must make the Service Source Code available via network download to everyone at no charge, under the terms of this License. Making the functionality of the Program or modified version available to third parties as a service includes, without limitation, enabling third parties to interact with the functionality of the Program or modified version remotely through a computer network, offering a service the value of which entirely or primarily derives from the value of the Program or modified version, or offering a service that accomplishes for users the primary purpose of the Program or modified version.
“Service Source Code” means the Corresponding Source for the Program or the modified version, and the Corresponding Source for all programs that you use to make the Program or modified version available as a service, including, without limitation, management software, user interfaces, application program interfaces, automation software, monitoring software, backup software, storage software and hosting software, all such that a user could run an instance of the service using the Service Source Code you make available. [emphasis added].
You may not provide the software to third parties as a hosted or managed service, where the service provides users with access to any substantial set of the features or functionality of the software.
You may not move, change, disable, or circumvent the license key functionality in the software, and you may not remove or obscure any functionality in the software that is protected by the license key.
The Apache Software Foundation (ASF) exists to provide software for the public good. We believe in the power of community over code, known as The Apache Way. Thousands of people around the world contribute to ASF open source projects every day.
所以这其实是一个很典型的商业协议,甚至没有跟源码公开协议、开源协议放在一起讨论的价值。只是因为它是一家开源商业公司 CockroachLabs 创造,且在相当一段时间内被其他开源商业公司使用,所以做一个解释。同时它的名字 Community License Agreement 也非常的令人费解:这就是一个商业软件协议,跟 Community 没有任何关系。
You may make use of the Licensed Work, provided that you may not use the Licensed Work for a Database Service.
A “Database Service” is a commercial offering that allows third parties (other than your employees and contractors) to access the functionality of the Licensed Work by creating tables whose schemas are controlled by such third parties.
You may make use of the Licensed Work, provided that you may not use the Licensed Work for a Streaming or Queuing Service. A “Streaming or Queueing Service” is a commercial offering that allows third parties (other than your employees and individual contractors) to access the functionality of the Licensed Work by performing an action directly or indirectly that causes the creation of a topic in the Licensed Work. For clarity, a Streaming or Queuing Service would include providers of infrastructure services, such as cloud services, hosting services, data center services and similarly situated third parties (including affiliates of such entities) that would offer the Licensed Work in connection with a broader service offering to customers or subscribers of such of such third party’s core services.
Within a single installation of Materialize, you may create one compute cluster with one single-process replica for any purpose and you may concurrently use multiple such installations, subject to each of the following conditions: (a) you may not create installations with multiple clusters, nor compute clusters with multiple replicas, nor compute cluster replicas with multiple processes; and (b) you may not use the Licensed Work for a Database Service. A “Database Service” is a commercial offering that allows third parties (other than your employees and contractors) to access the functionality of the Licensed Work by creating views whose definitions are controlled by such third parties.
You may make use of the Licensed Work, provided that you may not use the Licensed Work for a Document Service.
A “Document Service” is a commercial offering that allows third parties (other than your employees and contractors) to access the functionality of the Licensed Work by creating teams and documents controlled by such third parties.
If you develop an application using a version of Play Framework that utilizes binary versions of akka-streams and its dependencies, you may use such binary versions of akka-streams and its dependencies in the development of your application only as they are incorporated into Play Framework and solely to implement the functionality provided by Play Framework; provided that, they are only used in the following way: Connecting to a Play Framework websocket and/or Play Framework request/response bodies for server and play-ws client.
写得非常复杂,但是总结下来是很简单的一句话:任何情况都不能在生产环境部署 Akka 应用,除非你是用 Play 框架开发应用,且应用中没有直接和 Akka 的接口通信。
这个涉及到一些历史背景:Play 框架和 Akka 都是 Lightbend 公司的产品,早在几年前 Lightbend 公司就宣布不在以公司投入维护 Play 框架,而是转为“社群维护”。这也是个后来被广泛应用的话术,用以指代公司放弃某个开源软件的开发。由于 Play 框架的底层就是 Akka 支撑的,修改 Akka 协议时,或许出于避免级联影响到此前已经弃养的 Play 框架的用户,Lightbend 公司通过这一条款规避了原 Play 框架用户可能收到的冲击。
毫无意外,HashiCorp 选择了四年的“保护期”,变更协议是此前它们采用的 Mozilla Public License 2.0 协议。其生产环境使用的条款如下:
You may make production use of the Licensed Work, provided such use does not include offering the Licensed Work to third parties on a hosted or embedded basis which is competitive with HashiCorp’s products
HashiCorp considers a competitive offering to be a product or service provided to users or customers outside of your organization that has significant overlap with the capabilities of HashiCorp’s commercial products or services. For example, this definition would include providing a HashiCorp tool as a hosted service or embedding HashiCorp products in a solution that is sold competitively against our offerings. If you need further clarification with respect to a particular use case, you can email licensing@hashicorp.com. Custom licensing terms are also available to provide more clarity and enable use cases beyond the BSL limitations.
关于增长受挫的问题,其之一是资本的本性就是扩张,所以增长受挫确实是资本所不能接受的。其之二是云厂商搭建起来的完善交付体系,确实挤压了采用原先商业模式的开源商业公司的生存空间。作为反制,Red Hat 虽然不能修改 Linux 的软件协议,但是通过改变其发行版的打包流水线,实际上增加了云厂商在其企业级发行版上原封不动打包交付的难度。
企业选择带有商业保护条款的源码公开协议,可以看做是从完全闭源的商业协议,到冒进的全面开源协议,在之后的一次螺旋上升的准备。我相信开源协议是完善的,它解决了源代码如何自由分享的问题。在《大教堂与集市》的论述中,Eric Raymond 从未指望供应商自己转变,而是试图通过说服用户理解开源的价值,以及鼓动任何企业开源其非盈利软件来实现开源的未来。这也是我认可的方式。