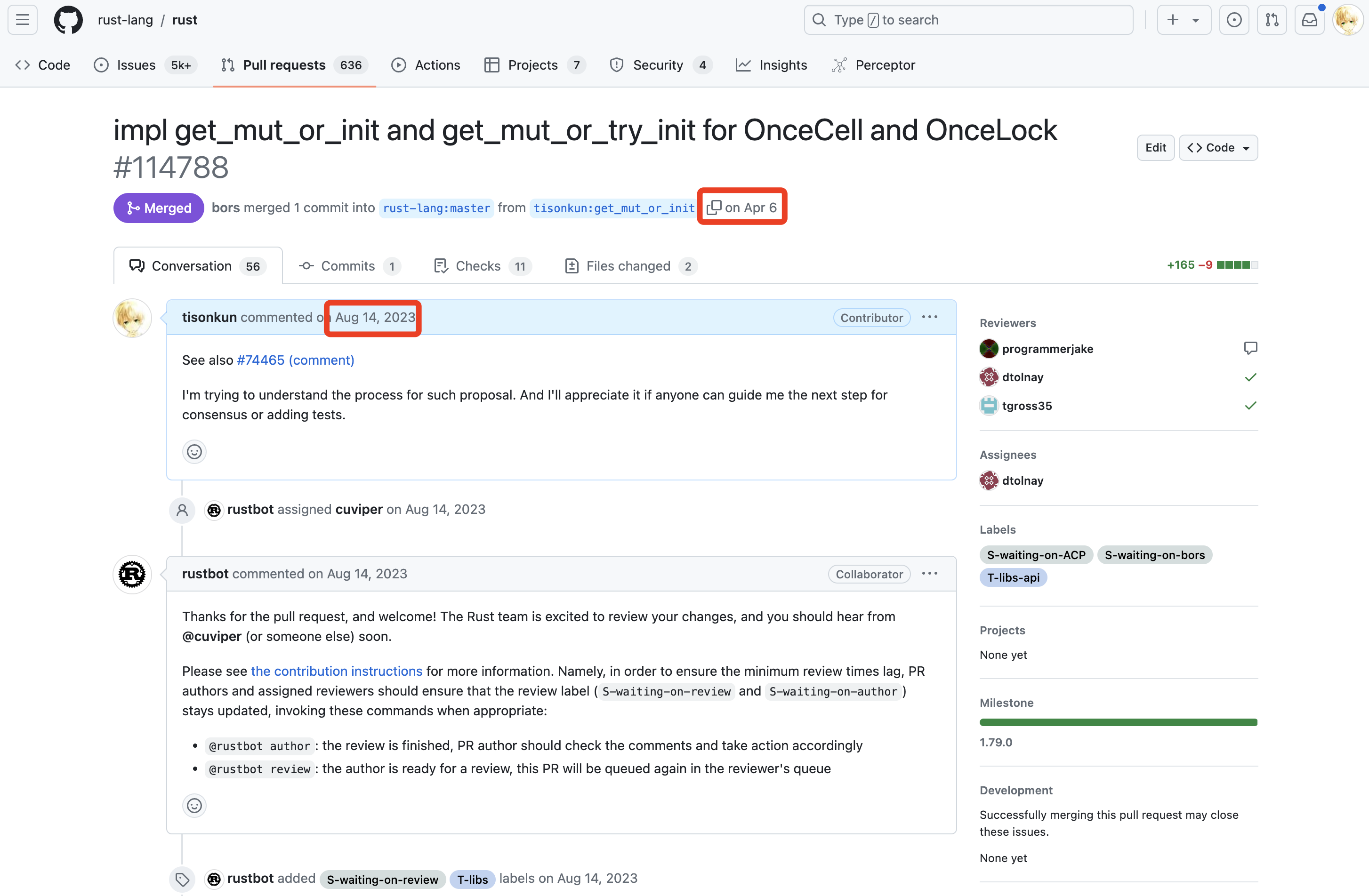
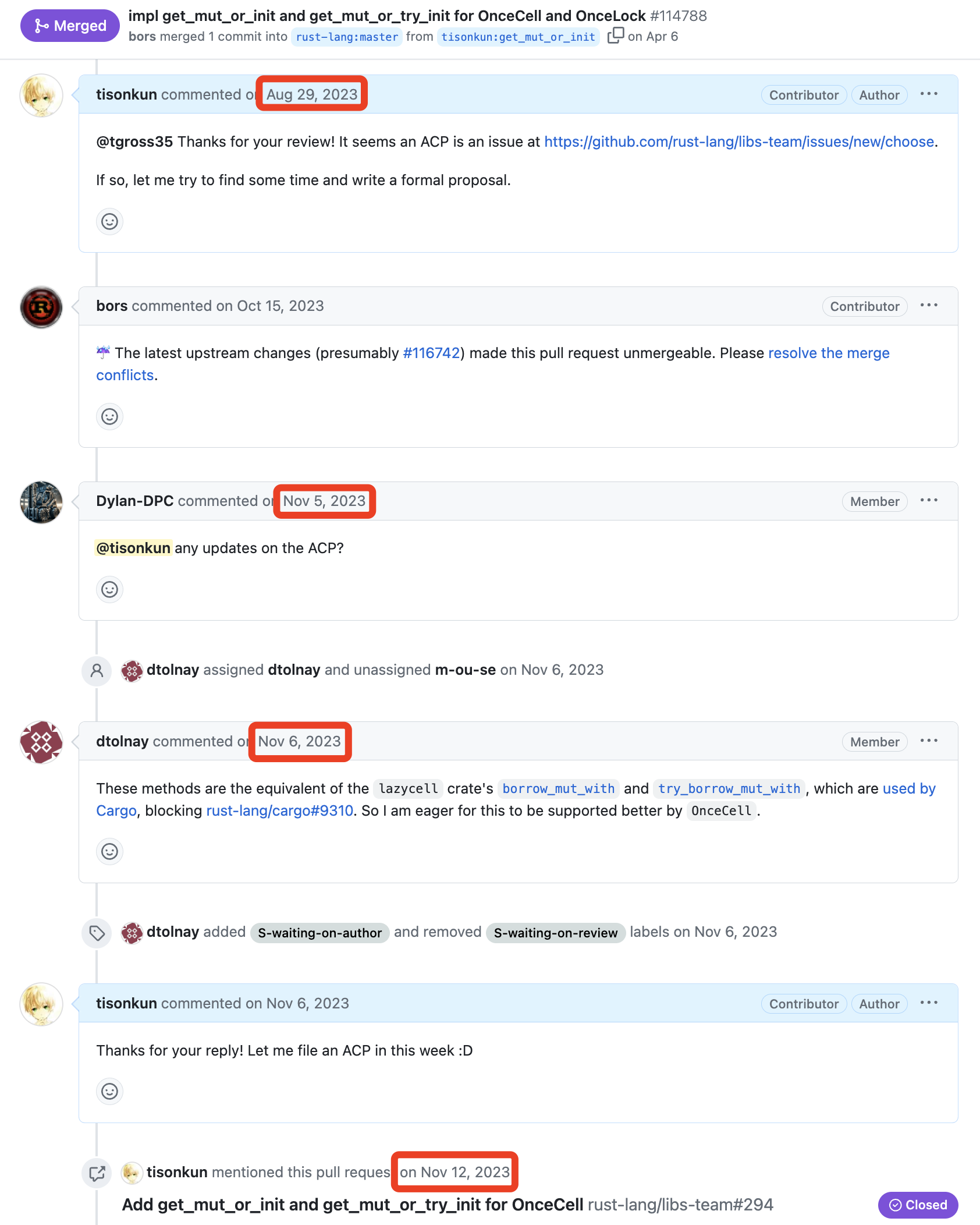
开源软件的用户在使用过程中遇到问题时,几乎总是先在自己的环境上打补丁绕过或快速修复问题。开源协同的语境下,开源软件以及维护开源软件的社群统称为该软件的上游,用户依赖上游软件的应用或基于上游软件复刻(fork)的版本统称为下游。上游优先(Upstream First),指的就是用户将下游发现的问题、做出的修改反馈到上游社群的策略。
网络上已经有不少文章讨论上游优先的定义、意义和通用的做法。例如,小马哥为极狐 GitLab 撰写了《Upstream First: 参与贡献开源项目的正确方式》。不过,这些文章往往是站在社群、平台或布道师的层面做笼统的介绍。本文希望从一个开发者的角度出发,由几个具体的上游优先的故事,讨论开发者角度实践上游优先策略的动机和方法。
故事和经历
Spotless
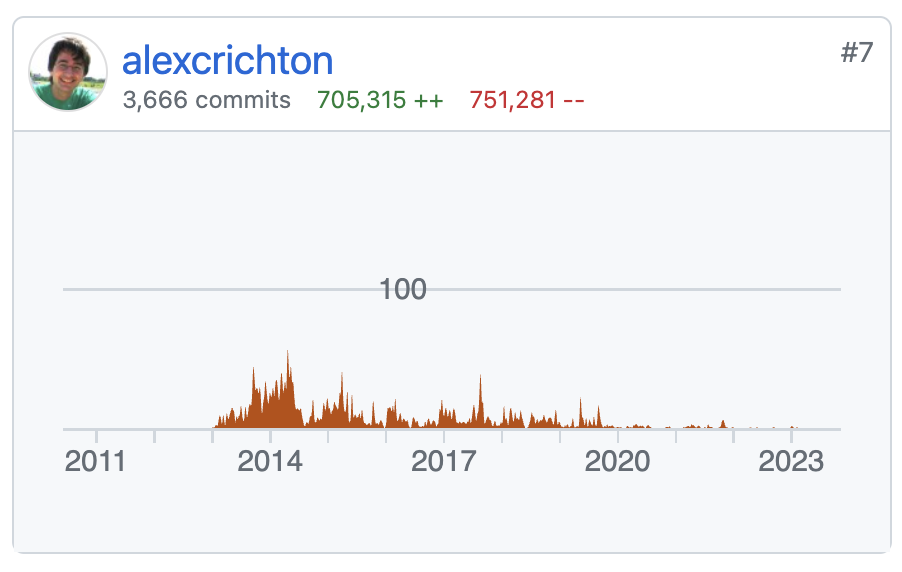
第一个要讲的是我在 Spotless 社群的参与经历。Spotless 是一个主要关注在 JVM 系语言的代码自动格式化软件,被 Apache Flink 等项目广泛采用。
我第一次给 Spotless 提交补丁是因为在一个个人项目当中同时使用 Java 17 和 Spotless 插件,遇到了 Java 17 严格约束 JDK 接口导致的 Spotless 插件启用 google-java-format 规则时不工作的情况。
起初,我按照 issue-834 上的绕过方法解决了问题。但是一方面绕过方法不太舒服,需要用户感知和主动修改;另一方面,这个解法不向后兼容:如果一个项目想要同时支持 Java 8 和 Java 17 编译,该绕过方法会导致 Java 8 编译失败。
我遇到这个问题的时候,这个问题已经发生一年了。而且这种 Java 上游改内部接口导致下游爆炸的情况,一般很容易导致其他项目出问题。于是我尝试搜索相关问题,幸运地发现了 Kotlin 提供了解决问题根源的方法:
依样画葫芦就在 Spotless 上游把问题解了。
听起来简单,其实搜索到的代码片段只是提示了核心解法,减少了思考可行方案的时间。要把相关代码移植到另一个项目里,并且理解原项目的构建方式打包后测试,以及按照项目的惯例完成文档更新等等工作,最终让上游接受合并请求,就需要积极和上游维护者沟通,也需要发现和理解上游社群运行规则的方法和耐心。
好在 Spotless 的维护者 Ned Twigg 相当外向,很快进行代码评审并解释了代码以外需要做的工作,一周以内就完成了补丁合并。通过自动化发布的流程,补丁合并以后新版本就会自动发布,下游几乎能在合并当天就更新版本用上自己提交的补丁。
这里有个小插曲。虽然这个修复乍一看也可以在 google-java-format 上游做,但是我经历了 GCP 相关的一个 pull request 被挂数月的折磨以后,对 Google 项目实在没什么期待,所以选择在 Spotless 解决问题。事后发现这个解法是正确的,因为这样解能搞定 Spotless + google-java-format 1.7 的组合,而在 google-java-format 修大概率是不会为早期版本 pick 的。此外,Spotless 上的修复是模块化的,起初只是在 google-java-format 的路径上启用,随后发现了其他格式化规则也有类似的问题,只要简单地把修复模块在其他规则上启用就可以了。
一周以内上游合并发布以后,我在下游使用新版本的 Spotless 解决了之前的问题。然后,趁着热乎劲,我把之前搜索解法的时候搜到的其他有同样问题的项目,看着顺眼的就把我的修复版本提交给他们。今天我再去看原来的 issue 和提交的补丁,能够看到一系列下游项目引用我的工作修复他们的问题,我很开心。
然后,就在国庆假期前给 Flink 更新 Spotless 版本解决这个问题的时候,我又发现了另外一个问题,原先可以用过 skip 参数跳过某些 Maven 模块 Spotless 检查的功能在升级以后不管用了。
我的第一反应就是到上游搜索相似问题,发现 issue-1227 也报告了这个问题。由于升级前的版本是好的,升级后的版本出了问题,加上我能定位到好的版本里 skip 参数起作用的相关代码是哪些,很快我就二分找到了引入问题的提交,并且在一个小时之内提交了修复。
这次轻车熟路,所有该办的我能办的事情,我都一次性搞完了。Ned Twigg 的反应还是很迅速,半小时内就反馈了 review 意见,我再求助其他开发者进行验证以后,当天 Ned Twigg 就合并了补丁并且自动发布了新版本。我接着在 Flink 提交的补丁上更新了依赖版本,第二天经过 review 以后 Flink 的补丁也合并了。而我本来还以为要到假期后才能搞定。
atomic
这个例子是我在 Golang 生态的参与。不同于上一个例子,我在 contribute back 相关改动的时候并没有急切的下游需求,只是我在使用的过程里发现上游有可以做得更好的地方,于是就顺手实现了。首先讲这个例子是因为 uber-go/atomic 的参与经历给了我一个催发布的定型文。
我应该是在迁移 TiDB 测试的时候,发现了部分代码使用了 Golang 早期只有操作指针的函数的 atomic 库。这种代码要求操作对应的变量必须都用 atomic 库提供的方法,一旦直接访问就有破坏一致性的风险。在其他语言的实现里,往往都会有原子类型,例如 Java 里的 AtomicInteger 和 AtomicReference 类,来保证所有操作都是在原子类型的方法上的,也就避免了应用逻辑上是 atomic int64 但是只能定义成 int64 的问题。
我从其他开发者那里得知了 Uber 的 atomic 库提供了原子类型定义,马上就愉快的用上了。在使用的过程里,虽然没有实际的需求,但是从完整性上我发现 Uber 的 atomic 库没有定义 uintptr 和 unsafe.Pointer 对应的原子类型,而 Golang 的 atomic 库函数里有操作相应类型的函数。因为闲暇时候我也是写点代码打发时间,所以我先提交 issue 询问维护者添加这两个原子类型是否合适,得到肯定的答案之后就顺手实现了一个补丁提交。
因为改动很简单,所以几轮 review 过后 24 小时内就合并了。
不过,不像 Spotless 通过自动化发布流水线,合并补丁之后基本一天内就可以从 Maven 中央资源库引用新版本,大部分的项目包括 Uber 的 atomic 库都需要人来触发或完成发布流程的。非自动化的发布的节奏,Apache Pulsar 和 Apache Flink 这样的项目会有一个相对稳定的发布周期,并且社群成员能够从文档上看到发布的时间规则,因此我也能知道大致什么时间会发布新版本,而且急也没用。但是有些项目开发活动并不活跃,它们会倾向于开发一段时间后“差不多了就发布”。
虽然 go.mod 其实允许直接引用一个 commit 标识的版本,但是我出于软件工程的最佳实践,我当时认为只有已经正式发布的版本里包括了我的更改,这个 contribution 才算正式完成。于是我用下面这段话向维护者请求发布一个包含我的改动的新版本:
@abhinav is there a release cycle or trigger description. I may hurry a bit but it is the nature a developer want to know how and when the work released :P
维护者表示他们确实是“差不多了就发布”的风格,但是很乐意在当周就发布一个包含我的改动的新版本。实际上,一天以后就发布了 v1.8.0 版本。
这段经历不仅带给我一个日后重复使用的催发布定型文,也是在偶然之后提醒我可以更加积极地与维护者沟通:如果你有什么需求,为什么要假设其他人不接受,而不是试着问一下呢?
一个有趣的后续是,目前 Golang 最新的 1.19 版本包含了从 Uber 的 atomic 库“借鉴”的原子类型。虽然我很好奇他们为什么只选取了一部分类型,比如没有包括 float 和 duration 等类型,但是我发现我写的 Uintptr 类型也被包含其中。尽管 Golang 的作者并没有在代码里说明这段代码是来自 Uber 的 atomic 库的,或许是因为他们觉得这是平凡的实现,在具体的方法集合上也有裁剪,但是 Golang 的开发者都知道是怎么回事(笑)。
Maven Shade Plugin
这个案例的起因是我在 Pulsar 社群恰好和其他几个开发者同时发现 Pulsar 的 pom.xml 配置触发了 Maven Shade Plugin 的一个缺陷。
一般来说,Java 开发者对于应用代码和库函数是比较熟悉的,而一旦涉及到构建系统比如 Maven 或 Gradle 等,则会天然地产生一种陌生的刻板印象。这对于其他语言生态也是类似的,C++ 开发者哪怕能够写出很复杂的模板代码,也很有可能在调试 CMake 的配置的时候抓瞎。因此,除非专门的构建系统开发者,其他开发者几乎总是优先考虑绕过问题,而不是怀疑构建系统本身有缺陷,或者把构建系统的缺陷都当成需要理解和共处的特性。
我也不例外。不过我折腾构建系统的时间还算有一些,知道 Maven 增量构建问题一堆,所以马上发现了执行 mvn clean 清理构建产物以后再跑构建流程(“重启一下试试”)就可以绕过问题。
然而,一周以后,这个 issue 还是开着,不像有上面的绕过方法就算了的样子。我一时强迫症上来了,就开始搜索同类问题。很快,我就发现 Hadoop 和 Elastic 都有人遇到过类似的问题:
不过,他们的解决方法都不是我想要的。Hadoop 的开发者发现先 clean 就行以后就心满意足的关掉了问题。Elastic 把会导致问题的依赖给重构掉了来绕过这个问题,而 Pulsar 的情形里这个依赖是无法规避的。
几乎确定是上游的问题,我在 Maven Shade Plugin 的问题列表上提交了一份报告。没错,不像之前几个例子马上开始尝试实现,出于上面提到的开发人员的惯性,我还是下意识地规避构建系统的问题,只是提交一个 issue 并期望上游维护者能够帮我解决。
不过,提交问题后不久,机缘巧合之下我开始替换 Pulsar Docker Image 构建的 Maven 插件以支持在 Apple M1 平台上运行:这或许归功于公司给我配备的新机器。这个过程里,我理解了数个构建容器镜像的 Maven 插件具体执行的逻辑,以及为什么在 Apple M1 上会报出相应的错误。这让我对以前认为看也看不懂并敬而远之的 Maven Plugin 生态有了新的看法:好像也不怎么难嘛。
顺理成章地,半个月后我看到上面 Shade 插件的问题还是杳无音讯,就决定动手调试解决了。
这一次,不像 Spotless 的经历那样有现成可以借鉴的代码,需要我自己定位问题。不过从调试 Maven 插件的经历里,我大致知道了 Mojo 抽象的基本概念和执行路径。从报错信息里定位到相关类以后,我在代码中间加入了一系列日志来打印中间变量。在不好使用 debugger 来劫持执行流程的环境里,直接用 print 输出变量值是最值得依赖的手段。
因为问题的表征是创建 Zip 文件的时候有重复的被压缩的 Service 文件,我重点打印了 Shade 插件里合并 Service 文件时候的文件名,立刻发现被 relocate 的文件没有正确合并,而是重复处理了两次。顺着这个事实回过去看 Shade 插件的代码,很容易发现一个基本的逻辑错误。一开始,Shade 插件没有处理 relocate 规则。后来改了两次,但都没改完全。
虽然报告问题以后半个月上游没有处理,但是我定位了问题,明确分析出原因和提供了易懂的解法以后,加上从 commit 历史逮捕最近比较活跃的 maintainer at 上,第二天就有两位 reviewer 参与 review 并且最终合并了我的补丁。这改变了我打破了 Maven 社群的刻板印象。
合并以后,这次确实有下游 Pulsar 的用例等着升级版本来修复问题,因为我自己没有权限发布新版本,所以我再次使用上面提到的定型文催促发布:
@rmannibucau @slawekjaranowski I may be a bit in a hurry but I’d like to know whether/when we can have a release for this fix. It resolves one or several downstream use cases and I’m happy to upgrade for this fix.
It’s not a request, though.
两位 reviewer 告诉我可以到邮件列表上寻求帮助。我就订阅了 dev@maven.apache.org 邮件列表,直接请问有没有维护者愿意帮我这个忙。
没想到 Maven 的 PMC Chair Karl Heinz Marbaise 马上回复可以在周末的时候发起新版本发布的投票,最终也确实在当周就发布完成,我也在下游升级到新版本解决了问题。
这段经历给我的启示是,上游优先可以是无处不在的。Hadoop 和 Elastic 社群里报告问题的人没有想过相对陌生的构建系统也可以接受补丁修复问题,而是习惯性把它当做一个外部的依赖,一个自己无法干涉的依赖。但是,或许我们还有更好的方式来解决自己的问题。如果一个问题技术上应该在上游解决,为什么不试着就在上游解决呢?
Protobuf
虽然我给 GCP SDK 的 pull request 被挂了几个月,直到现在也还没人搭理,但是参与 Google 的另一个开源项目 Protobuf 的体验还是不错的。
我在瞎鼓捣 Pulsar Ruby Client 的时候,碰到了 Pulsar 的 Proto 文件定义的枚举类型内部字段是小写字母开头,而由于 Ruby 没有枚举类型,Protobuf 把枚举类型的字段映射成 Ruby 里的常量,Ruby 的常量又必须是大写字母开头,最终导致定义失败的问题。
虽然这个问题看起来前提条件很复杂,但实际上是一个 Ruby 开发者和 Proto 定义的消息交互时非常容易遇到的情形。上游在 2016 年就有相关报告:
逻辑上的解法其实很简单,在定义枚举字段映射到 Ruby 的常量的时候,自动把字段名首字母大写就行了。这样既不会影响现有代码,又能够解决原来常量定义失败的故障。虽然对字段名做了自动调整,但是原本小写字母开头的常量定义是失败的,根本也用不了,而实际到二进制转换不看名字只看编号,到文本的转换走的是符号解析支持小写字母开头。
经过这轮分析以后,我确定这个路径是可以走通的。于是从报错信息定位到相关代码,把“自动大写字段名首字母”的逻辑原地打了个补丁上去。当时我也不懂怎么触发测试,也不知道会不会有其他问题,但是先做自己能做的事情,提交到上游让其他干系人发现有人在努力解决这个问题,并且已经有一些进度了,这能够在原本大家都观望的环境里抛出一个凝结核,吸引用户测试补丁和维护者评审代码。
不同于 GCP SDK 的源码只读状况,Protobuf 的维护者隔天就帮我触发了测试,这让我感觉到这个社群还是会关注我的工作的。一周以后,Ruby 模块的维护者之一 Jason Lunn 开始 review 我的代码,由此开始了近一个月的 review 循环。
中间过程我就不再赘述,如果你去看我提交的补丁的对话,你就会发现:
- 因为虽然我对这个改动有需求,但是不是特别着急,所以对话经常是以周为单位。每周末我闲着没事的时候,有时就能想起来还有这件事没搞完,于是看一下 review 意见和测试结果还有哪些要改的,集中思考和解决一波。
- 因为我对 Ruby 并不熟悉,而且一上来搞的就是 Ruby + C 和 JRuby 的元编程,所以这个过程里我其实不是一开始就知道符号的部分不用动,写出了一堆问题。解决问题的方向错了,reviewer 好像也没看出来,大部分时间都是我自己在纠结、测试和补丁之上的补丁,碎碎念的状态活像一个孤独患者自我拉扯。
- 因为 contribute code 最好还是本地可以跑全量测试提升反馈效率,所以整个过程下来我把 bazel 这套构建尤其用于 Ruby 项目编译的各种 trouble shooting 都搞了个遍。以前我总觉得 bazel 的概念晦涩难懂,但是实际直接用起来一个配置好的项目,不仅体验不错,还帮我理解了很多设计的原因。
- 最后,虽然我在错误的道路上走了太远,甚至一度以为这件事情没法实现,不过就像我上面对问题的总结,我回归到一开始要解决的问题,加上一个月来对这段代码的深入理解,终于发现了正确的解法,最终用不到 50 行代码就把问题给解决了。
代码合并以后,我自然是再次用定型文催上游发布我好早点用上。不过这次上游没有给我反馈,于是我主动观察了一下发布的规律,发现 21.x 的版本每半个月到一个月就会发布新版本,然而由于我的补丁只在 master 分支上,只有等到 22.0 发布的时候才能用上。我觉得这个改动不大,所以就询问维护者能不能 backport 到 21.x 的分支上赶上下一个短周期的发布。
另一个维护者 Mike Kruskal 支持这个做法,并且跟我确认了 21.x 和 22.0 的发布节奏。我得到支持以后就把这个不到 50 行的补丁轻松地 backport 到了 21.x 版本,并在三天前得到合并。期待发布中。
这个故事可以拓展成一个典型的上游优先模式。许多程序员在面对自己的问题的时候,一开始做出的改动就跟我原地打一个 monkey patch 一样,对自己的用例有效,其他自己用不到的地方就不管了。但是把自己的修改提交到上游接受评审的时候,才发现原来这个改动可能牵扯到这个那个模块。上游同时被许多下游依赖着,因此它们所选择的解决方案很可能不是 monkey patch 的方式。通过这样的上游优先参与,能够逐渐锻炼自己下游使用修改时候符合上游的设计哲学,从而尽力避免由于理念不同而最终不得不分支的情况。
当然,这个例子可能稍显简单了。一个年代比较久远的例子是 2019 年前后我在 Flink 社群参与发起和实现的 FLIP-73、FLIP-74 和 FLIP-85 这三个提案。我在腾讯内部其实做了不一样的实现,在上游社群和其他 committer 沟通以后形成了最终上游的解决方案。不过关键的思路是一样的,所以内部版本追上上游也不困难,不会因为有截然不同的假设导致被存量拖死。
另外,Protobuf 的问题是 2016 年提出的,今年我解了,参考某司解决一个 etcd 悬挂三年的边缘问题吹上天,我是不是可以标题党地写一个《震惊!他竟然解决了 Protobuf 一个长达六年的痛点!》。
Apache Ratis
Ratis 是一个 Raft 算法的 Java 实现,完成了 Raft 共识算法的核心逻辑,实现了一个服务框架,包括网络层,日志同步和落盘的功能,状态机及其快照的抽象,还支持运行时增减成员、动态配置和同时运行多个 Raft Group 等高级功能。
我对分布式共识算法的关注由来已久,可能跟我第一个稍有难度的工作就是改良 Flink 基于 ZooKeeper 的高可用模块有关。Ratis 作为共识算法 Raft 的实现,自然也进入我的视野。
真正开始探索 Ratis 的实现,起源于我从分布式计算做到分布式存储以后,了解到 Spanner、TiKV 和 Oceanbase 等等系统都是基于共识算法来实现数据的复制和一致性的。在理解相关的代码和论文之余,我也想要自己写一个个人项目来实践自己的理解。Ratis 自己曾经想过做一个 Replicated Map 实现,类似于 ZooKeeper 或 etcd 来解决大部分用户的简单读写场景,但是最终没做成。我顺着这个思路,时不时做一些实验和源码阅读,并在今年以 zeronos 为项目名开始做一个完整的实现。
在这个过程里,我发现过 RATIS-1619 Group 创建时约束的问题,顺手就解了。这跟前面给 atomic 提补丁没什么区别,不做展开。
重点要说的是下面这个例子。我在琢磨怎么实现类似 etcd 的 watch 功能的时候,发现 Ratis 在框架层面实现了网络通信,虽然方便了下游只需要定义状态机就可以起集群,但是网络通信只实现了简单的 request-response 模式,不能照搬 etcd 的全双工长连接实现。
在之前跟 Ratis 的作者施子和博士的沟通过程里,我发现主要能找到他的渠道在邮件列表上,于是我就把自己的需求在 user@ratis.apache.org 上反馈。
果然,施子和博士在一小时内就回复了我的问题。经过几轮沟通,我们得出结论:watch 和 put 主要的区别在于乱序返回,也就是一个 watch 请求到来之后,必须先处理完后续的写请求才能出发 watcher 并返回给客户端。而 Ratis 同一个客户端的请求默认是排序的。解决了这个问题,只要在请求和返回的时候带上键值状态机里 key (range) 的 revision 就能保证获取变更信息不会错过,至于是不是采用全双工链接来实现,反而不是特别重要。
得出结论以后,我又开始 push 上游推进。当然,开源社群的参与者都是志愿者,没有催促别人做事情的道理。但是我可以做我力所能及的事情,激励其他参与者发现这件事情有人在关注从而提升优先级。所以,在两天之后没有后续的情况下,我就把 user 邮件列表上的结论总结成一个技术上的问题报告,提交到 Ratis 的 JIRA 项目上。
几分钟后,施子和博士在 issue 上问我是否已经开始实现了,我只能坦诚地说没有。于是他表示他可以实现,并且确实在三天之后就提交了补丁。经过几轮 review 以后,我 approve 了相关变更。
然后,就是定番询问发布的计划。因为我知道 master 分支上要等 3.0 版本发布才能用上,而 3.0 发布还没确切的日子,相对而言这个改动并不大,包含在 2.x 版本按照以往的节奏一两个月以内就可以发布了。施子和博士也同意了这个说法。
这个案例是一个代码以外的参与案例。本文开篇就提到,上游优先包括提交代码,也包括报告问题。实际上,将自己创作的软件开源发布,对于软件工程师来说很关键的一个好处就是收获同行评审和用户反馈。相反,仅作公司内部使用的软件往往少有人关注代码的技艺,只关心最终效果,并且通常使用场景有限,很难得到解决复杂问题的锻炼机会。
从参与者的角度看,这个案例体现出来的仍然是积极和上游沟通,尤其是做一些力所能及的工作。开源社群的成员都是志愿者,他们不会因为某个需求是你提出的就另眼相待。他们几乎总是从完成需求的难度和回报来衡量自己是否应该投入时间。做一些力所能及的工作,哪怕是前期调研和技术分析,一方面能降低解决问题的难度,另一方面让其他成员看到你为这个问题付出的努力,你有相当的主动性,解决这个问题能帮助到你。谁又不想和这样的同伴合作呢?
match-template
站在维护者的角度,我也处理过其他社群成员出于上游优先理念提交的请求。
TiKV 的 maintainer @andylokandy 参与到另一个 Rust 数据系统项目 Databend 的开发以后,在实际编码的过程里发现自己需要和 TiKV 里内部的模块 match-template 相似的功能。
虽然 match-template 模块的代码不过几百行,不过 Andy 没有想着简单拷贝代码,而是希望 TiKV 社群能够把这个模块 promote 成一个顶级项目,并且在 Rust 的中央资源库 crates.io 上发布。
这个提案得到了其他 maintainer 的支持。作为 TiKV Infra Team 的在编人员,我自然很乐意帮忙完成相关设定和发布的工作。在一个简单的社群投票之后,我花了一个小时左右的时间把新仓库创建、match-template 库发布和相关权限设置的工作都做好了。隔天,Andy 就在 Databend 的 PR-6712 里用上了这个库。
Andy 其实比我还要晚毕业一年,不过我们都是从刚一毕业甚至还在学校的时候就开始参与开源社群的。开源社群广泛合作的理念根植在这样环境里成长起来的新一代开发者,对于他们(我们)来说,上游优先是再正常不过的事情了。
Pulsar Flink Connector
这个例子里,我同时拥有公司员工和上游维护者两顶帽子。
一方面,作为 Flink Committer 的我是 Flink 社群的维护者,拥有合并补丁的权限。另一方面,作为公司员工的我因为 Flink 的经历自然地想要帮助公司业务依赖的 Pulsar Flink Connector 和上游更好的协作。
在我和公司同事 Yufan 的合作下,我们把 Pulsar Connector 的端到端测试覆盖、一系列缺陷修复和新功能实现推到了上游。由于公司的客户和 Pulsar 软件的用户不都是使用最新版本,我们还把缺陷修复和端到端测试的部分推到了上游维护的其他过往版本。
这可能是公司员工角色的开发者一个典型的特征。作为个人开发者,往往没有太多版本依赖包袱,只需要最新版本里有自己提交的补丁,追到最新版本就行。但是在公司里许多历史问题累积的应用系统的环境中,激进地升级版本可能会带来其他问题。因此他们做上游优先的反馈的时候,可能会更加关注修复能否被 backport 到自己使用的版本上。
通过与上游的紧密合作,Pulsar Flink Connector 成为了 Flink 官方维护和发布的 Connector 的一部分,让 Flink PMC 为这一软件背书,从而使得用户采用的倾向性更强。同时,代码进入上游跟随上游迭代,添加的相关测试保证 Connector 功能的测试被上游回归测试所包含。如果上游在核心模块做了影响 Connector 的改动,可以提醒开发者相应调整关联代码,或者至少维护这个 Connector 的 Yufan 能够知悉。
这也是我时隔一年以后重新参与 Flink 开发活动,并间接导致了阅读代码的过程中发现和解决了上面提到的 Spotless 的问题。可以看到,存在一定用户基数的开源软件的生命周期相对都比较长,作为上游维护者,有可能因为公司上游优先的活动而重新回到社群。
这里值得一提的另一个例子是 Gyula Fora 和 Márton Balassi 发起的 Flink Kubernetes Operator 项目。
Gyula Fora 和 Márton Balassi 是 Flink Streaming API 的核心作者,在 2014 年向 Flink 提交了几乎改变项目性质的重要改动并成为 PMC 成员之后,他们从 2016 年起几乎就从上游社群消失了。
今年一月份,这两位开发者一起加入苹果公司并开始用 Flink 搭建数据流水线,在生产部署的场景里遇到了需要 Flink Kubernetes Operator 的需求。由于上游没有提供相应的软件,加上苹果公司的数据流水线只是成本的一部分,并不需要依靠 Flink Kubernetes Operator 来提供商业竞争力,他们于是在公司内部实现了初版以后,就在上游社群提交议案发起新项目。
目前,Flink Kubernetes Operator 已经发布了 1.2.0 版本,并且持续快速迭代中。这个软件现在不止是苹果自己在用,蚂蚁集团和阿里巴巴集团也开始关注和整合这部分代码,回推公司内部的实现,避免内部实现和上游软件产生方向上分歧。
go-redis
最后一个正面的上游优先的故事,我想讲一下 Apache Kvrocks (Incubating) 和 go-redis 相互的合作。
上游优先,进一步分析,并不只是 fork 到 upstream 的方向,也不总是从依赖的软件到被依赖的软件的方向;上游优先换个角度看,可以说是一个包含软件 A 和 B 的整体解决方案,自己作为软件 A 的开发者,在发现解决方案的部分问题更适合在软件 B 解决的时候,首先选择在软件 B 的范畴内解决,而不是在自己的“领地”里费尽心思的绕过。
Kvrocks 是一个兼容 Redis 协议的分布式 NoSQL 系统,go-redis 是实现 Redis 协议的 Golang 客户端。我在选型替换 Kvrocks 社群里无人熟悉的 TCL 测试的时候,最终选择基于 go-redis 来写集成测试。
当然,这里选型的主要是 Golang 语言 Kvrocks 的开发者都比较熟悉,而且写起测试这样非关键路径的代码简单粗暴,而 go-redis 是 Redis Golang 客户端几乎最好的实现。不过,有一件小事让我对选用这个软件更有信心。
偶然之中,我发现 go-redis 其实很早就在 README 里提及了自己支持访问 Kvrocks 服务端。由于 Kvrocks 今年四月份捐赠到 Apache 孵化器,我顺手改正了上游 README 的表述和链接。go-redis 维护者 @vmihailenco 不仅很快合并了修改,还对 Kvrocks 捐赠这件事表达了祝贺。
当时我就觉得,我很愿意和这个人合作。因此我在下面留言说明我将要做的替换工作,而他也很热心地表示如果出现什么问题,欢迎和他反馈。
一开始的迁移很顺利,我就夸赞了 go-redis 真不错。随后一些复杂测试用例的迁移过程里,我逐渐发现了 go-redis 的一些问题,其中有部分是 Kvrocks 的实现和 Redis 不一致需要改进。每次遇到问题,我基本都会 @vmihailenco 告知他我们用例测出来的问题,并且向他寻求 go-redis 使用上的帮助。
迁移过程中,我还发现 go-redis 没有实现部分 Redis 命令的封装接口。跟 @vmihailenco 确认这只是工程工作量太大没有全部实现,其实是需要的之后,我随手就提交了一个补丁帮助 go-redis 实现了相关接口。
因为 Kvrocks 可以使用底层接口完成测试,而且我知道上游会在 v9 版本包括这个改动,也就是说发布是确定的,而我不着急使用,所以这一次我没有用定型文催促上游明确发布时间。
这种上游优先是相互的。显然我为 go-redis 提交了一些代码,并且向上游反馈了不少使用案例,不过 @vmihailenco 也为 Kvrocks 和 Redis 的兼容性提供了非常有价值的输入,并且帮助 review 替换过程中遇到的问题。
应该说,这是开源社群当中的一种常态。大家不是完全基于契约和合同行动,不在契约之内的事情就想方设法避开,而是基于善良和合作的假设,帮助别人,并时不时得到别人的帮助。上下游的合作是相互的,作为积极反馈上游社群的下游,往往也更能得到上游社群反过来的帮助。
Trino
第一个印象深刻的遭受挫折的故事,来自给 Trino 提交的一个补丁。
这个补丁来自于 Pulsar 实现 Pulsar Trino Plugin 的过程中发现上游核心模块里的 AvroColumnDecoder 类功能可以增强。其实在此之前,Pulsar 社群就想过把整个 Pulsar Trino Plugin 捐赠给 Trino 上游维护。
但是 Trino 作为一个公司项目,对待他们眼里的 “external contributor” 的要求不可谓不高。如果一视同仁,我还可以理解成项目一贯的高要求。然而就像我在 PR-13070 里回复的,分明 Starburst 公司自己的员工,就可以分批交付功能,发布在不同版本上,怎么到了 “external contributor” 身上,就要我啥都调研一下,啥都尝试着做呢?
更不用说每次我有什么回复,上游没有个一二十天是不会回复的,甚至我如果不到 Slack 频道上 pop 这个合并请求,根本不会有人再看。当然,我个人其实是支持如果你的补丁被上游忽略了,应该尽可能的增大声量,哪怕上游拒绝合并你的修改,也是一个结果。但是重复做这样的事情,只会让我觉得像是一个垃圾信息制造者。
这就引出来一个要点,上游有可能出于种种原因没能和你找到一个最大公因数完成上游优先的代码反馈,这种情况并不少见,作为下游项目,此时也要有自己的解决方案。
比如,虽然我们说尽可能在上游解决,但是上游已经不维护了,那也只能绕过或者替换了。前面故事里客串出场的 Docker Maven Plugin 就是我替换已经不维护了的 Dockerfile Maven Plugin 的选择。尽管我知道可以怎么修,但是上游也不想修了。
另一个手段是分支。对于上面 Dockerfile Maven Plugin 的例子来说,我也想过分支维护的思路,但是它其实又依赖了同一个组织下另一个已经不维护了的核心库,这一下维护成本暴涨,我也就没了兴趣。但是下游分支的情况并不少见。比如 Google 的 cpplint 几乎不维护,就有人拉出一个 cpplint 组织来重新维护这个项目。
回到 Pulsar Trino Plugin 的例子上来,如果上游不接受我回推到核心模块的补丁,大不了我就像现在的实现一样在 Plugin 里把我需要的修改后的类单独写出来用就是了。虽然这样有不必要的代码重复,但是至少是个方法。进一步的,如果上游不接受 Pulsar Trino Plugin 捐赠,Pulsar 社群也可以自己维护。只不过确实 Trino 的后向兼容性极差,如果不能和上游同步迭代发版的话,外部的插件很可能很难和上游 Trino 服务端保持兼容。从用户层面看,就是同时使用 Pulsar 和 Trino 很难找到一个所有需要的功能都有,而且两者还能融洽相处的版本向量。
goleak
虽然 Trino 的情况让实践上游优先策略难度陡增,但是上游优先的失败案例并不总是上游的问题。
最典型的情况是,如果你对项目的理解和项目维护者不一致,或者说和项目的定位和要解决的问题方向不同,那么上游优先的反馈就很可能被拒绝。
我在迁移 TiDB 测试的时候,部分工作是使用 goleak 库来替换手写的 leaktest 工具。这主要是因为手写的工具功能有限,甚至后来发现与漏报的情况,而由于没人维护这个手写的工具,这些问题长期都无人解决。
替换成 goleak 的过程里,我发现了一个重复的模式。由于 goleak 的接口设计,在调用检查方法之后,如果失败就调用 os.Exit 直接退出进程,这导致任何 teardown 的逻辑都没有办法执行。面对这个问题,我设计了一个 goleak.TestingM 的子类型和一组接口来支持退出逻辑。
这个包装类型用的还不少,正好 goleak 也是 Uber 开源的 Golang 库,我前不久在 atomic 库有不错的合作体验,于是就提议直接在上游提供这样定制退出逻辑的功能。
虽然上游维护者对实现方式有自己的想法,但是我觉得我的实现方式更合适一些。于是我直接怼了一个补丁上去:
然后就是一年杳无音讯。直到上个月一个新加入 Uber 不久的员工按照上游原来的想法实现了这个能力,并把 issue 关联关闭了。虽然我觉得他的实现其实跟我当时指出的问题一样,不能很好地在编译时就阻止错误用法,而为了追求接口的“一致性”,有可能在运行时才抛出异常,但是既然这是上游的决定,这又是个公司项目,我也没什么好说的。
当然,哪怕不是公司项目,只要你不能做约束性投票,或者说你的理念不被项目核心维护者认同,那么下游更改无法推回上游也是很常见的。Apache SkyWalking 的作者吴晟就多次拒绝方向上不符合自己理念的反馈,或者确认问题,但是按照自己的理解来实现。
我自己作为维护者的时候也时有拒绝 contribution 的情况。这其实也是对开源项目维护者的一个要求:你不能对 contribution 来者不拒。开源软件的制造不是纯粹的人多力量大,而是一种精英主义。项目维护者需要依赖自己对项目的设计和理解,有选择性地吸纳社群成员和接受补丁。Linus 曾经说过,他做开源软件的过程中觉得最愉快的事情,就是可以只跟自己想要合作的人合作。
当然,这就意味着总有一些出于上游优先理念提交补丁或反馈问题的成员得不到正面反馈。但是,失败并不总是坏事。批判性的看待上游的反馈,我仍然觉得 Trino 的维护者不如我了解那部分代码,甚至我都解释累了;goleak 上游的实现我也觉得不如我的视线。还有上游的实现更好,我被折服了也学到许多的例子。
尾声
上面的故事和经历包括了十个不同类型的上游优先案例,包括代码的非代码的、有需求的纯顺手的、顺利的失败的、自己提交的做 reviewer 的。相信在开源社群当中和他人协作,或者想要参与开源社群的读者都能从中找到似曾相识的画面。
希望你在开源参与的过程里锻炼自己的技艺,收获友谊和成就!