VuePress网站接入Google AdSense广告位
前言
如果你的网站每月有一定的访问流量,可以考虑通过广告变现来获取一些收入。在自媒体的所有收入来源中,广告是最可观的收入方式。
博客网站想要接入广告位时,可以优先考虑接入Google AdSense,这是全球最成熟的广告系统。
本文会完整记录Google AdSense的账号注册、广告配置、收入提现等全流程的操作,希望能给有需要的读者一些帮助。
一、注册 Google AdSense 账号
1、注册账号
进入Google AdSense 官网 https://www.google.com/adsense/,点击右上角的”登录“按钮,登录Google 账号:

登录Google账号之后,然后在上图中,点击“开始使用”,出现如下界面:

继续:(国家选“中国”)

填写邮寄地址:

注意,这里的地址,一定要填写准确。因为以后你会收到 Google官方邮寄过来的 Pin码。
上图中,点击提交之后,会弹出如下界面:

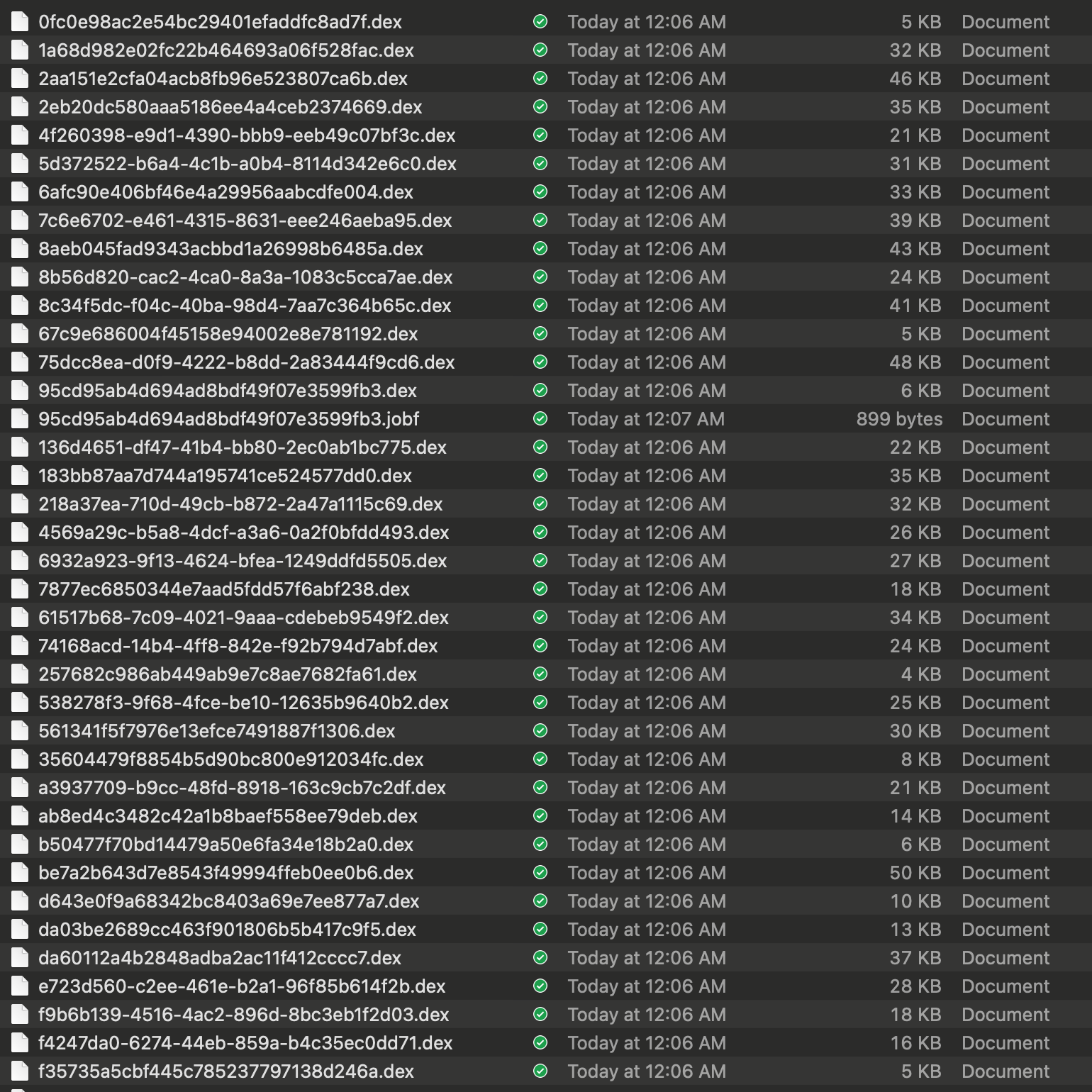
2、将广告代码插入到vuepress网站中
安装上面的步骤注册完成后,我的 广告代码是:
1 | <script data-ad-client="ca-pub-1601618516206303" async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"></script> |
回到 VuePress的项目代码里,配置 docs/.vuepress/config.js文件:
1 | module.exports = { |
然后把上面的代码部署到服务器。打开网站后,就可以看到广告代码生效了:

我这里配置的是二级域名web.qianguyihao.com。但是稍后Google 官方在审核我的网站的时候,审的是一级域名。所以,我还需要在qianguyihao.com里插入广告代码,这部分的操作过程是类似的,读者可以自行研究下。比如说,假如你的网站是 hexo框架搭建的,那可以研究下 hexo配置是怎么加入广告代码。
3、审核网站
将上面的广告代码插入到博客网站之后,我们再回到 Google Adsense官网的首页:

上图中,勾选“我已将代码粘贴到自己的网站”,然后点击“大功告成”按钮,之后会出现下面的弹窗:


上面的这张图表示:我们的广告账户,已经提交申请了。接下来,我们就可以安安静静地等待审核结果的邮件了。
审核时长一般需要一周左右。运气好的话,三天就能通过;运气不好的话,要等两周左右。
补充说明:只能用一级域名(如 qianguyihao.com)申请广告。申请通过后,广告代码可直接用于到该主域名下的任何子域名下, 而不需要对子域名再次审核。
4、审核通过
审核通过后,我们会收到邮件通知:

访问 Google AdSense 官网,会发现首页已经提示可以投放广告了:

参考链接
二、 广告配置
配置ads.txt文件
在网站的申请通过之后,需要继续配置ads.txt文件。即:先下载ads.txt文件到本地,之后上传到网站域名的根目录下。

上图中,点击”设置广告“按钮后,会自动跳到如下页面:

上图中,点击”立即修正“,会出现如下界面:

上图中,点击”下载“按钮,然后我们需要把下载下来的ads.txt文件,上传到服务器的指定目录下。
比如说,我的博客网站页面,是托管在阿里云服务器的/home/www/hexo的目录下,那我就把ads.txt文件上传到/home/www/hexo目录下就行了。
上传完成后,输入qianguyihao.com/ads.txt,如果成功加载到内容,说明配置成功。效果如下:

ads.txt 文件生效之后,在 AdSense官网的首页,就可以看到下图所示的界面:

广告出现的位置
Google 广告分为两种:
- 自动广告:Google 即会自动在所有最佳位置展示广告。这种广告应用之后,我们的网站会出现铺天盖地的广告,很影响阅读体验。所以本文不打算采用这种广告。
- 在自定义位置插入广告:可以按照个人需要,在网站的指定位置插入广告。正好是本文想要采用的广告。
自动广告:

在自定义位置插入广告:

VuePress 添加 Google AdSense
本段讲述如何为 vuepress 站点配置”按广告单元”申请的 adsense 谷歌广告,从而可以在文章的任意位置插入广告。这里采用的技术方案是 vue-google-adsense 依赖库。具体步骤如下。
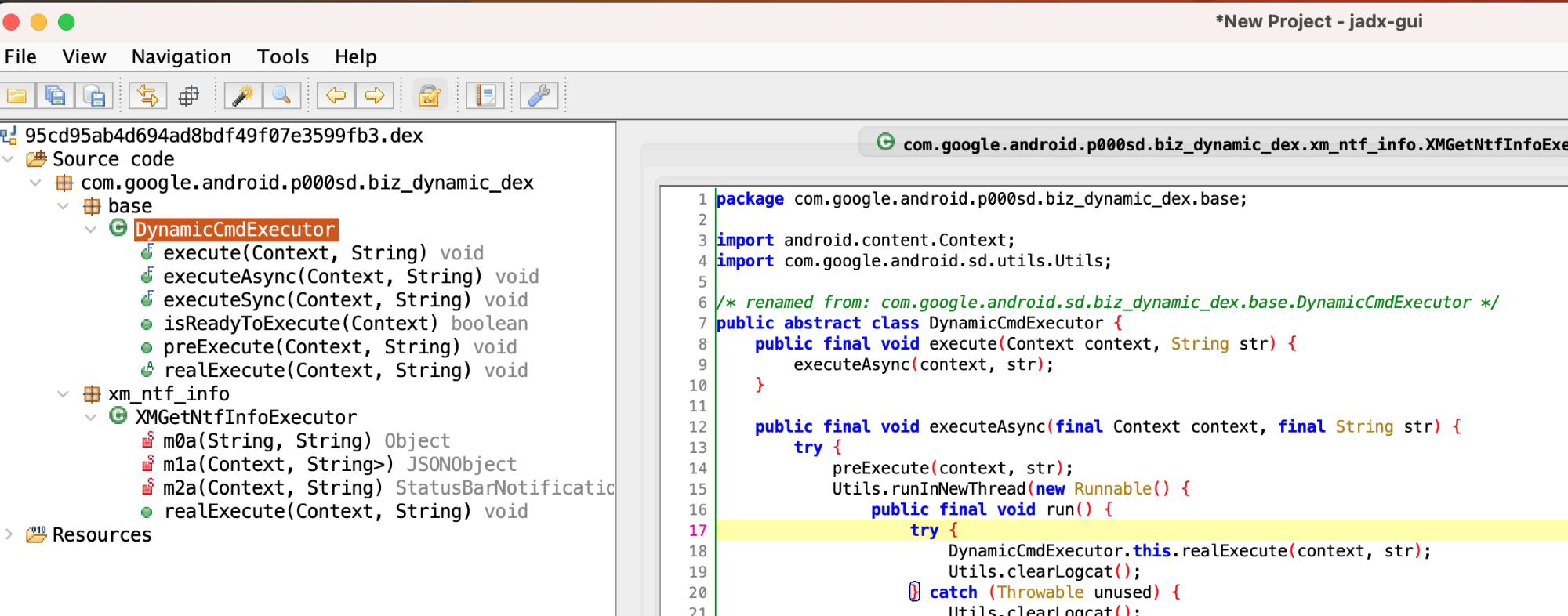
1、申请广告代码
进入Google AdSense官网:

上图中,选择“按广告单元”展示,然后选择其中一个展示方式(这里我选的是左边第一个,红框处所示)。

上图中,选择自己想要的展示尺寸之后,点击“创建”,出现如下界面:

上图表示,成功申请到了广告代码:
1 | <script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"></script> |
记下上方广告代码中的 data-ad-client 和 data-ad-slot,稍后要用到。
2、安装 vue-google-adsense
(1)在项目的根目录下,执行如下命令,安装 vue-google-adsense:
1 | npm i --save vue-script2 vue-google-adsense |
(2)在docs/.vuepress目录下,新建文件enhanceApp.js,在这文件中添加如下内容,载入vue-google-adsense:
1 | import Vue from 'vue' |
3、在文章内插入 AdSense 广告
编辑想要插入广告的 markdown 文档,在合适的位置插入如下代码即可:
1 | <InArticleAdsense |
上面的代码中,第一行和第四行是固定的。第二行填的是你的ca-pu-id(发布商ID),第三行填的是你的slot_id(客户ID),这两行内容,在我们刚刚申请到的广告代码中可以获取。
配置完成后,稍等大概一个小时,就可以在我们的网站上看到广告投放了:

上图中,用箭头处围起来的地方,就是我们投放的广告位,可以看到,广告已经成功生效了。我在对应的 markdown 文件中,是这样写的:

大功告成。
4、自定义广告组件
为了方便文档的书写,以及方便广告的管理,建议将广告代码进一步封装为广告位组件。
我们可以定义多个广告位组件, 每个广告位组件唯一对应 adsense 广告的 1 个 slotId。这样就可以把 data-ad-client 和 data-ad-slot 的取值都封装到组件中。
当站点申请了很多的 slotId 时,通过”自定义广告位组件”的方法实现插入广告, 管理或修改广告数据会非常方便。
具体操作步骤如下。
(1)创建 vue 组件:
创建目录docs/.vuepress/components,在 components 目录下新建文件,比如ArticleTopAd.vue,在里面写入如下内容:
1 | <template> |
上面的代码中,需要将 data-ad-client 和 data-ad-slot 的参数值替换为你自己的实际取值。
(2)插入广告:
在md文档的对应广告位处, 注入广告位组件 ArticleTopAd 即可:
1 | # js 模板引擎 mustache 用法 |
参考链接
设置收款方式
当收益达到100$之后就可以提现了。可以使用招商银行进行电汇收款。也就是说,办一张招行一卡通就可以直接收Google的外汇(美元), 然后一键换汇为人民币。我们来详细看看,具体要怎么操作。
验证身份 & 验证邮寄地址
大概过了一个月之后,我的 Google AdSense收入达到了10美元,所以首页出现了这么个提示,让我验证地址:

上图中,点击「操作」,出现了如下界面:

上图中,可以看出:
(1)当您的收入达到进行验证所需的最低限额时,Google官方会将个人识别码(PIN 码)邮寄到您的付款地址。
(2)自 PIN 码生成之日算起,您可以在 4 个月内将该码输入帐号。如果您在 4 个月后还未输入该码,我们会停止在您的页面上展示广告。
(3)如果幸运的话可能会收到pin码,当然也可能收不到。
详情可查看如下链接:
上面这个链接里的内容,我截图存了个档:

付款最低限额
关于付款最低限额相关的信息,详情可以看这个链接:
也就是说,收入达到10美元之后,需要我们验证邮寄地址;收入达到100美元之后,就可以开始提现了。指日可待。
上面这个链接里的内容,我也截图存档: