但是,相比起开放源代码促进会(OSI)和 TODO Group 这样,在通用开源和企业开源领域能够提出见解和倡议的组织,开源社在掌握开源话语权这个议题上显得比较弱势。随着中国开源力量的崛起,如何引导各方参与者正确认识开源,在开源环境当中高效协作创新,将是一个无可回避的问题。我热切期望开源社能够发挥自己所在生态位的优势,联合开源社的志愿者,向社会不断输出批判性观点,帮助中国开源茁壮成长。
Betterified VI – Bestified 我肝了一个多月,剪出来的攻略视频超过17个小时,视频原稿有多长更没法统计了,录制盘容量根本不够用,已经删了一堆了,剩下的没删的还有30多个小时。是的,带解谜而谜面又极其晦涩或者根本没有谜面的游戏就这么恶心,你就得到处跑,有些元素第一次找到的时候和再次找到的时候给的玩意都不一样,生怕误打误撞把第一次就这么给趟过去了,所以大部分原稿都是一直留到杀青了才敢删。
制作攻略
Betterified VI – Bestified 这游戏秘密太多,而且也不知道作者是有意还是无意的,塞了一堆根本没头绪的隐藏秘密也就算了,还在特明显的地方塞了一堆根本没实现的解谜要素。
所以一个 async-crossbeam 可能是目前我最想看到的社群库,或许它可以是 futures-util 的扩展和优化。这些东西不进标准库或者事实标准库,各家整一个,真的有 C++ 人手一个 HashMap 实现的味道了。
第二个缺失点,顺着说下来就是 Async Runtime 的实现。Tokio 虽然够用,但是它出现的时间真的太早了,很多接口设计没有跟 Async Rust 同步走,带来了很多问题。前段时间 Rust Async Working Group 试图跟 Tokio 协商怎么设计标准库的 Async Runtime API 最终无疾而终,也是 Tokio 设计顽疾和社群摆烂的一个佐证。
我想,作为面向开发者的大会,最希望看到 CommunityOverCode Asia 顺利举办的,是每一位热爱开源的开发者。我向组织者建议,明年筹款的时候,其一可以实时公布筹款进度,让潜在的赞助者知道要想会议成功举办,还需要自己的多少支持;其二可以开通个人赞助的渠道,我想参与开源的开发者们众志成城,并不难凑齐这样一场年度盛会所需要的小几十万元人民币。
我在这里承诺,如果明年开通了个人赞助的渠道,我将以本人的名义或届时所在公司的名义,捐赠不少于十万元人民币以作支持。期待明年 CommunityOverCode Asia 越办越好!
DataFusion is great for building projects such as domain specific query engines, new database platforms and data pipelines, query languages and more. It lets you start quickly from a fully working engine, and then customize those features specific to your use.
-- Select all rows from the system_metrics table and idc_info table where the idc_id matches SELECT a.*FROM system_metrics a JOIN idc_info b ON a.idc = b.idc_id;
-- Select all rows from the idc_info table and system_metrics table where the idc_id matches, and include null values for idc_info without any matching system_metrics SELECT a.*FROM idc_info a LEFTJOIN system_metrics b ON a.idc_id = b.idc;
-- Select all rows from the system_metrics table and idc_info table where the idc_id matches, and include null values for idc_info without any matching system_metrics SELECT b.*FROM system_metrics a RIGHTJOIN idc_info b ON a.idc = b.idc_id;
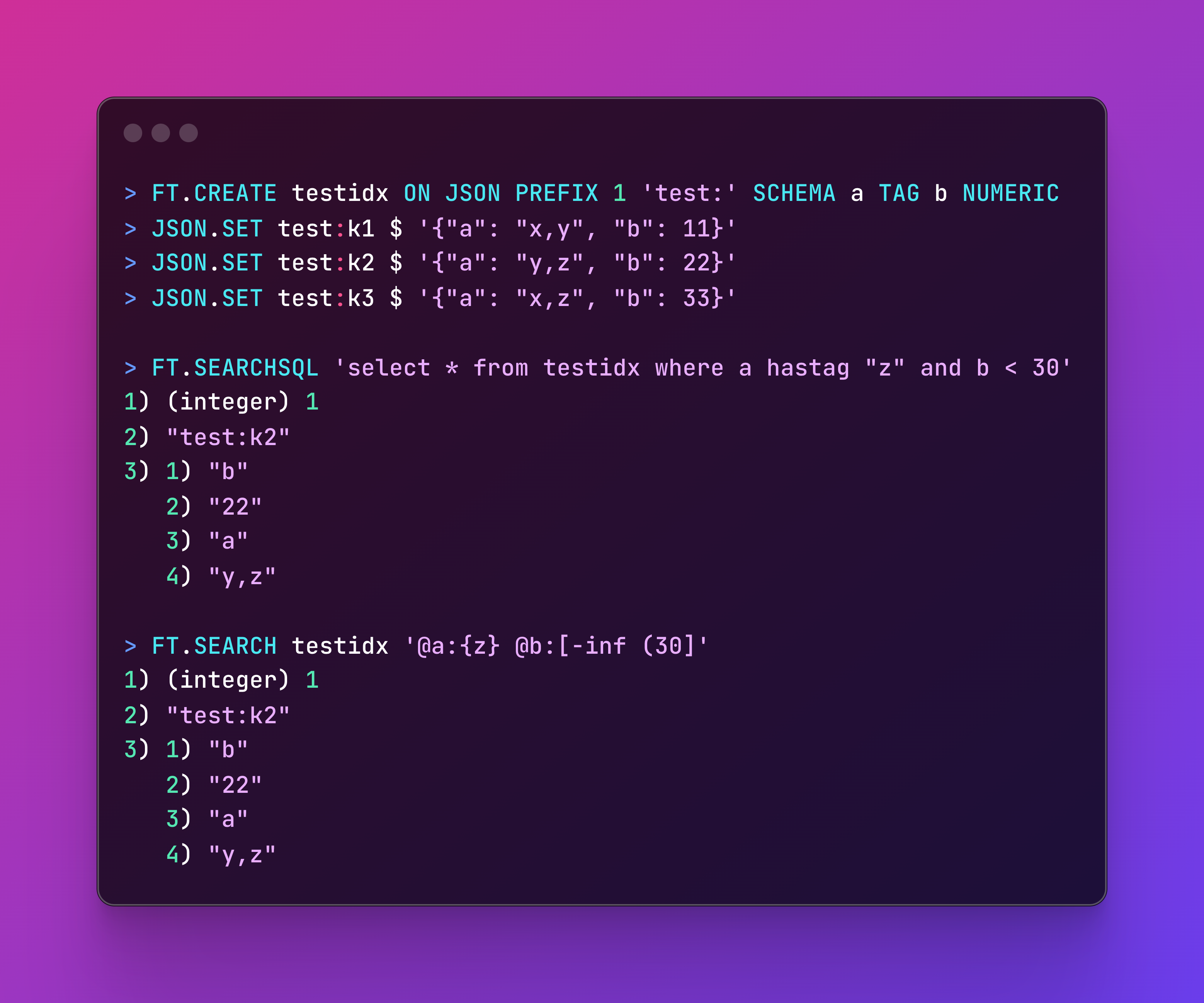
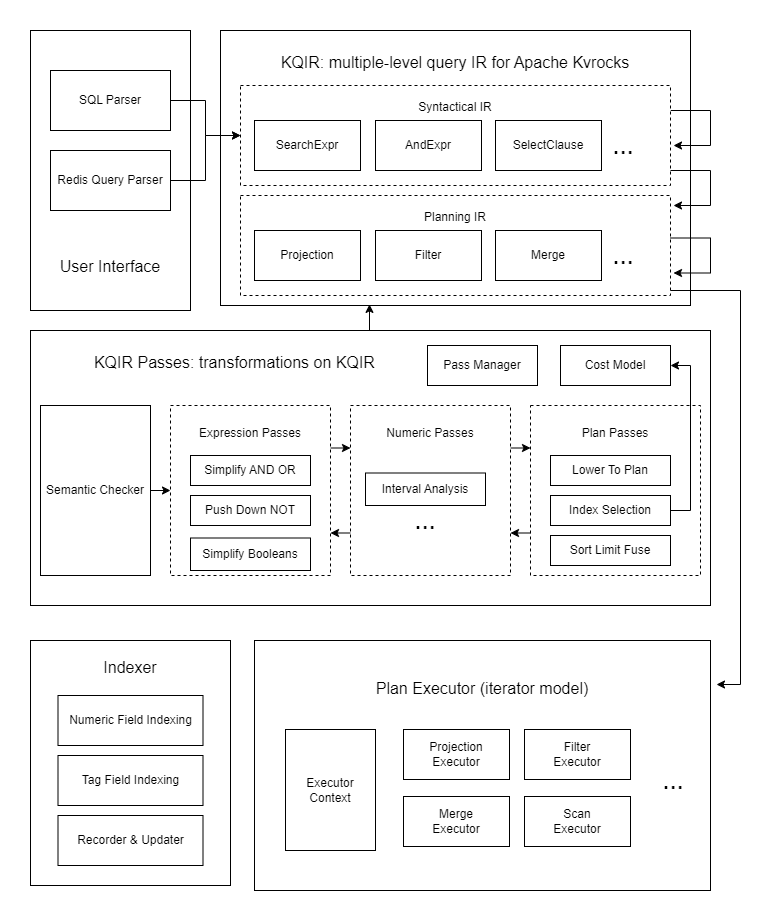
目前,Kvrocks 已经实现了一个支持 MySQL 语法和 RediSearch 查询语法的一个子集的语法解析器。它能够将这两者对应的抽象语法树统统转换为 KQIR 的形式。
KQIR 是一个多层级的中间表示,可以表示优化过程中不同级别的查询结构。抽象语法树首先会转换成 Syantatic IR 的形式,这是某些语法表达式的高级表示。这个形式的 IR 经过优化器处理后,会转变为 Planning IR 的形式。Planning IR 则是一种在查询引擎中表达查询执行计划的低级表示。
此外,我们将在优化之前对 IR 进行语义检查,以确保查询在语义上是正确的。这包括验证它是否不包括任何未定义的模式或字段,并使用适当的字段类型。
IR 优化器
KQIR 优化器由多个阶段(Pass)组成。这仿照了 LLVM 的概念和设计。每个阶段都以某种形式的 IR 作为输入,执行相应的分析和更改,然后生成新的 IR 作为输出。
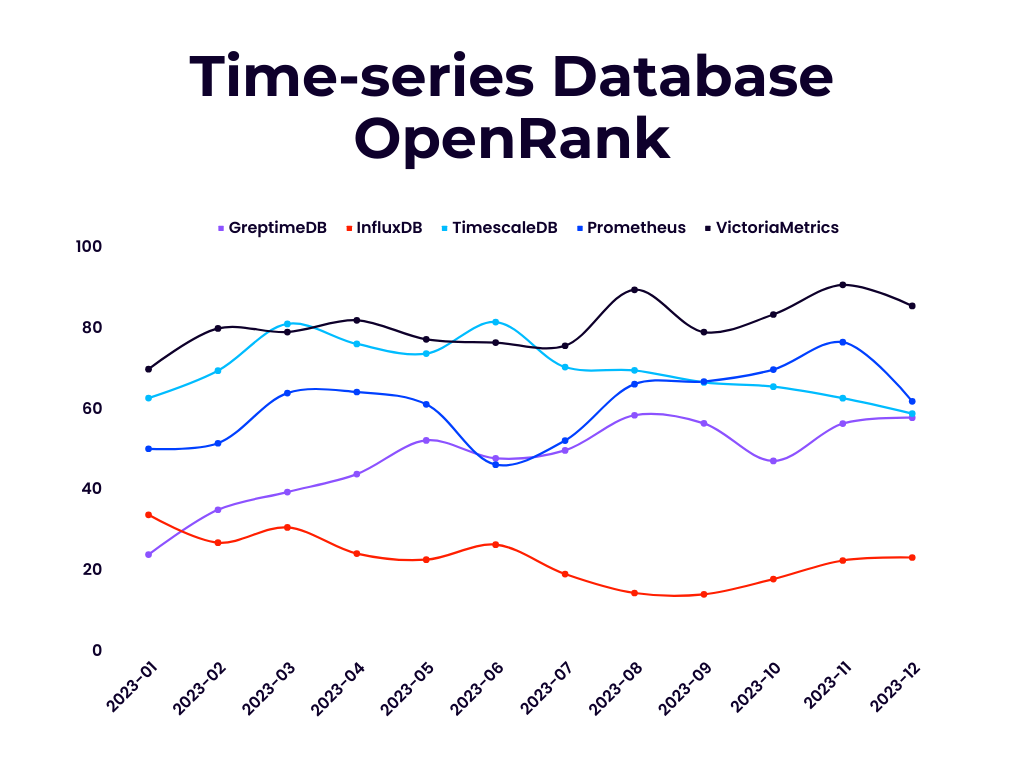
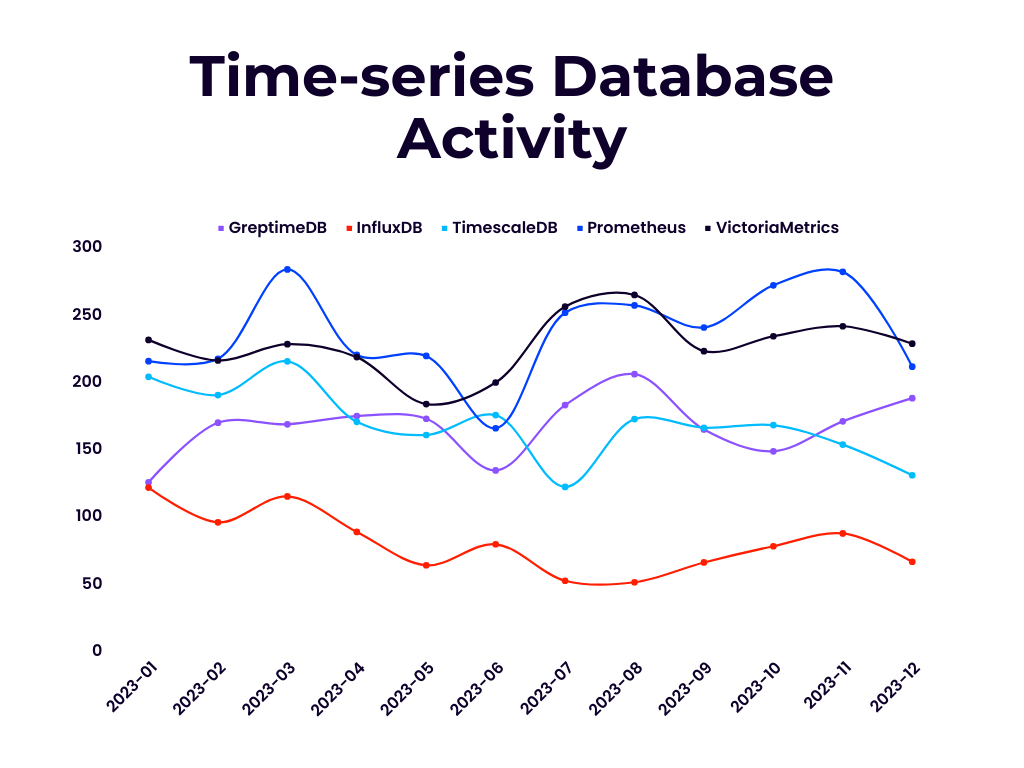
OpenRank 是同济大学赵生宇博士定义的一个开源价值流分析指标。相比于容易受先发优势影响的 Star 数和 DB Engines 分数等指标,上面展示的每月 OpenRank 和 Activity 变化情况更能体现出项目当前的发展情况和未来趋势。
GreptimeDB 的社群运营情况
前面提到,我真正开始关注 GreptimeDB 社群的契机是发现他们的 Community Program 并非船货崇拜,而是明显经过思考,有一定可行性的。事实证明,确实如此。2023 年 GreptimeDB 按照 Community Program 的设计发展了两名公司之外的 Committer 新成员:
此外,Community Program 虽然已经相比其他船货崇拜的同行删减了许多内容,以保证它能够务实地运作,但是仍然存在一些空洞的组织结构。例如设计出的 Steering Committee 做技术和社群发展决策,但是实际上当前阶段大部分工作就是公司团队商议决定后公开;例如还是定义了 SIG 乃至 OSPO 的组织,但是根本没有人力填充运营这些机构。
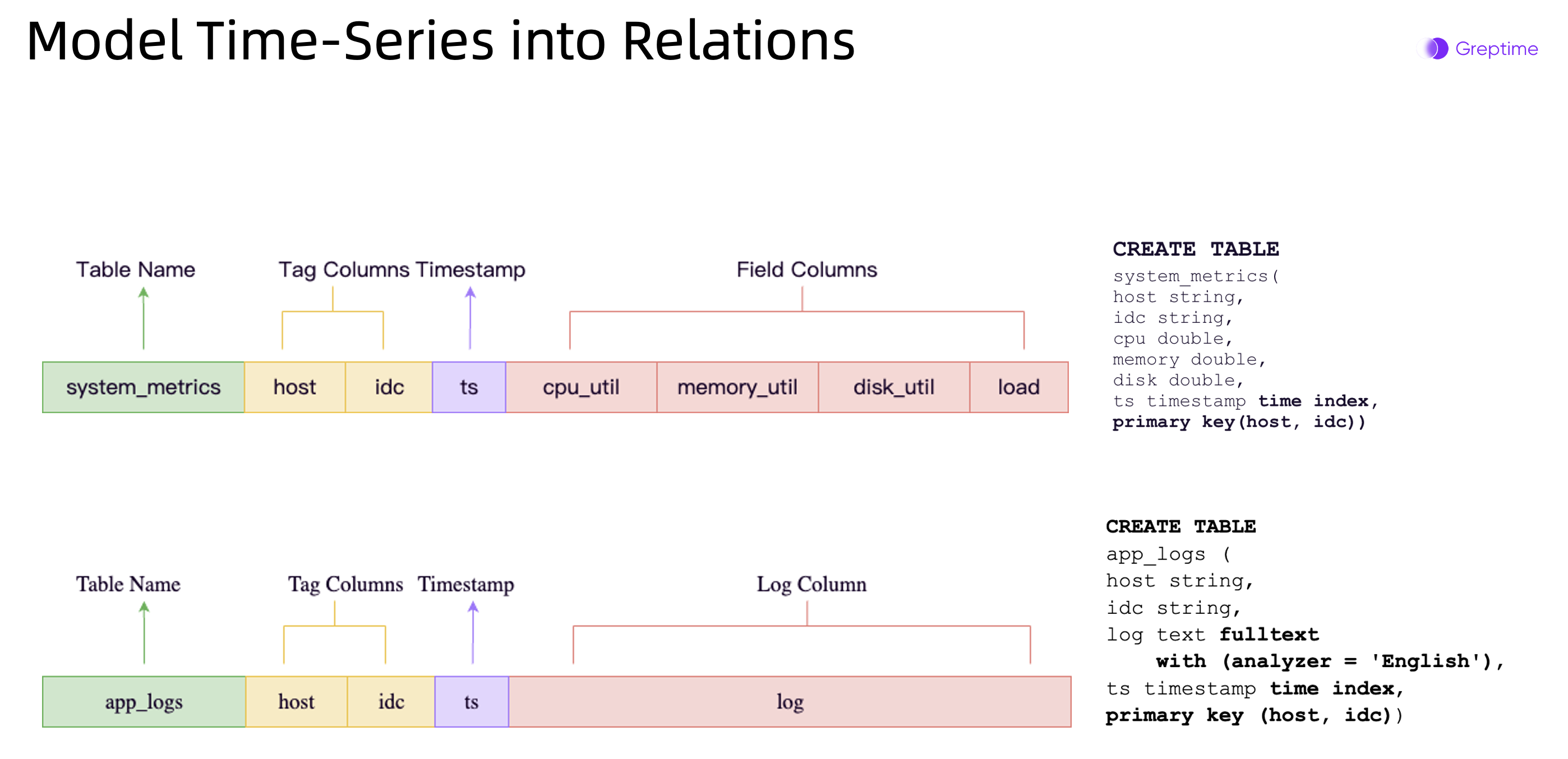
GreptimeDB 的创始团队认为,这三类数据可以共用同一套查询层和对象存储层能力,只需要针对各自的数据特性实现各自的存储引擎即可。其中大部分 DB 的架构和能力,例如数据分片、分布式路由,以及查询、索引和压缩等都可以共享。这样,GreptimeDB 最终能够成为同时提供所有时序数据最优化的存储和访问体验的单一系统。
GreptimeAI 是为 AI 应用提供可观测性的服务。不同于其他数据库在赶上 AI 浪潮时采用的 PoweredBy AI 增强自身产品的思路,GreptimeAI 是 For AI 增强 AI 产品的思路。其实本轮语言大模型带动的 AI 浪潮对 Database 服务本身的提升还十分有限,反而是这些 AI 应用自身产生的数据需要 Database 来存储和管理。
就语言绑定技术而言,Rust 本身支持 C FFI 决定了 C Binding 的实现是非常流畅的。大部分语言也会提供访问 C API 的集成方式,于是通过 C Binding 可以产生其他语言的绑定。这也是 OpenDAL Haskell / Lua / Zig 等一众绑定的实现方式。
在这种大量利用现有技术的方案之外,上面提到的 jni-rs 和 napi-rs 等技术,则是在已有的 C API 集成方式之上,封装了一层符合 Rust 习惯的接口,从而在开发层面只需要涉及 Rust 语言和绑定目标语言。PyO3 更进一步,为这个开发过程研发了一套脚手架,中间打包和配置对接的工作也全部简化了。应该说,这是 Rust 生态主动向绑定目标语言靠拢。底层技术上,两边仍然是基于 C ABI 在通信。
现在回头看,其实一开始 Justin 的表达是 “I found a few minor issues where some name and branding work needs to be done.” 并不十分强烈。但是在 Xuanwo 首次回复没有做到 Justin 期望的完美符合 ASF 政策之后,他表示 PMC 应该要“好好学习相关政策”。
The ASF is well past the point where a small number of folks who have huge “tribal knowledge” can guide the number of projects and podlings that we now have.
This is no different to any project that comes to the ASF via the incubator. Many of them need to change names, often before joining the incubator, and all need to change their name to be in the form “Apache Foo”.
OpenZipKin 本是监控领域的明星项目,它愿意进入 ASF 并宣传 The Apache Way 是对 ASF 品牌的巨大帮助。然而,在这封令人伤心的退出提案中,ZipKin 的主创 Adrian Cole 无不失望的写到:
Process and policy ambiguity has been ever present and cost us a lot of time and energy. The incubator spends more energy on failing us than helping us.
“Daul branding” is nothing new, but recently, some entities have taken unfair advantage of this (including one you mentioned), and I feel the Incubator should take care that others do not also do this.
诛心言论,死了也证明不了自己只吃一碗粉。我就觉得你未来要 taken unfair advantage of this 了,你说你不是,我觉得你是。
Why a company would be unwilling to give up that brand or trademark just because it may be convenient in the future is a concern.