服务端响应 RST, ACK ,可能是中间安全设备导致的
最近在一个项目中遇到了一个奇怪的问题,项目部署到客户提供的服务器环境中后,从互联网侧访问时好时坏,但是在服务器上访问是正常的,按照常理判断是防火墙的问题,但是客户联系的网络工程师一直没有解决该问题,其华为原厂工程师反馈说是“外网客户端访问时与服务器协商加密协议,服务器没有协商过程直接拒绝了,请再检查一下服务器的配置”,而又把问题抛了回来。
我虽笃定是是客户服务器环境的网络设备导致的,但没有证据也不能服人,所以用 Wireshark 抓包实际测试,这里记录排查过程。
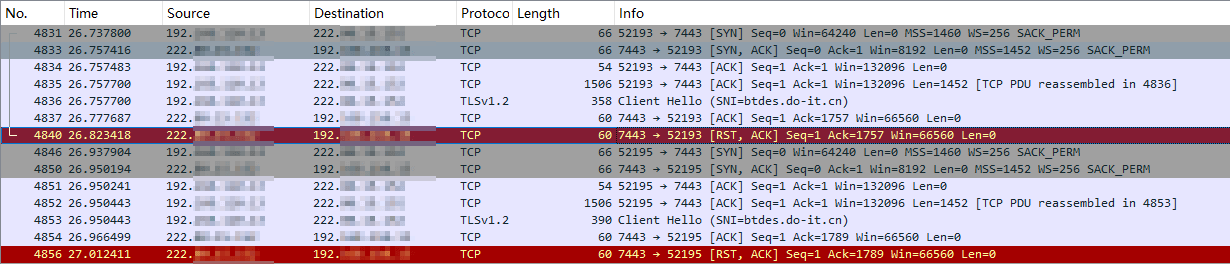
这段抓包记录是一个典型的TLS握手失败的过程,在尝试建立安全连接时出现了问题。在 4835 & 4836 客户端发送了一个 Client Hello 包,这是 TLS 握手的第一步,结果在 4840 服务器突然发送了一个 RST, ACK 包,重置了连接。
由于之前测试过在服务器上是可以正常访问的,所以这这个时候我们需要考虑一个问题:这个 RST, ACK 包真的是服务器回复的吗?
从 RST 报文的 seq 来看确实可以和前序报文对应得上(由于SYN标志位在逻辑上占用1字节序号,所以 RST 报文的序号是第二个报文的序号加1)。
一个很好的判断一条流是否是同一个服务器发送的方法是对比同一个方向的报文的IP头中的 TTL(Time to Live) 值。由于 TCP 对乱序非常敏感,而网络设备逐包转发数据会引入更严重的乱序,因此网络中的设备一般都是逐流转发(按五元组,源目IP、源目端口、协议),所以,大部分情况下,在捕获的数据流中,同一条流的同一个方向的报文总是有相同的 TTL 值。
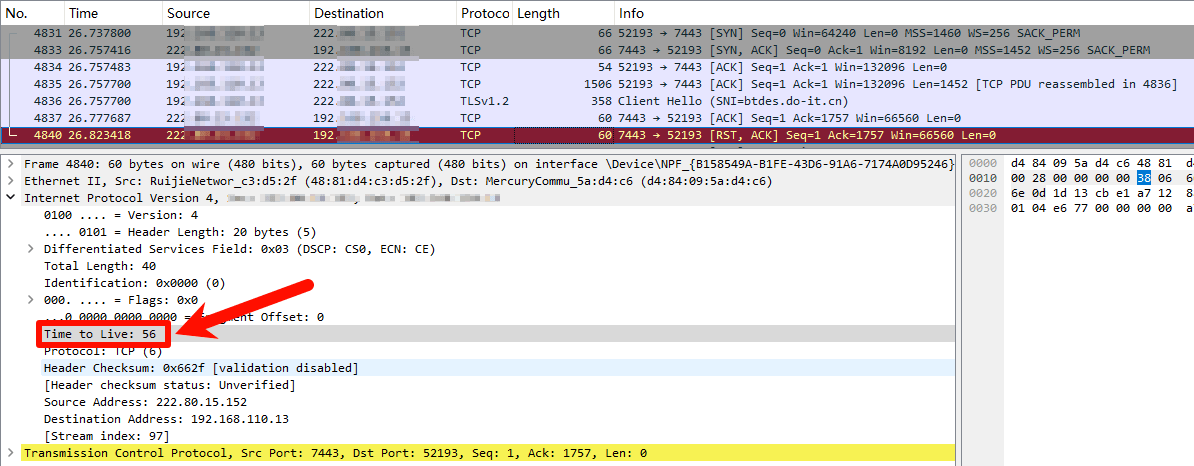
这里排查上面的抓包记录来看,从客户端到远程服务器的 TTL 值都是 128,服务端返回到客户端的包 TTL 值都为 119。而该 RST, ACK 包的 TTL 为 56,因此断定该包并不是真实服务器返回的,而是中间的网络设备伪造的。
将该问题返回给客户后,客户排查网络链路上的安全设备,在 IPS 中找到对应的日志,IPS 冒充服务器向终端发送 RST 报文拆链:

 。
。