实时关注豆瓣租房信息,几行代码帮你轻松搞定
现代年轻人的日常生活已经离不开互联网,无论是订机票,点外卖还是网购,本质上,我们都已经习惯从互联网获取信息,并从中筛选、鉴别,作出决策。
但有时,如何从浩瀚的信息之海找到我们所需要的东西,则是一个大问题。这时,技术就派上了用场。
设想这样一种场景,你租住的房子很快就要到期,可你却诸事缠身,没办法花费诸多精力寻找合适的房源。你第一时间想到了房屋中介,但又投鼠忌器,害怕自己的个人信息被人不经意间「分享」,你还希望直接和一房东对话,找一套直租房源。
你想到了论坛,你看到了密密麻麻的帖子,并从中仔细挑选符合你期望的房源。结果你发现,看了半天,满意的似乎并不多,只能再刷刷看有没有新发布的帖子。
生活中诸如此类的情景还有很多,其实,在精力有限的情况下,可以让你的电脑替你去论坛搜索所期望的信息,收集打包并呈现在你眼前。
下面以租房和寻找二手物品为例,介绍我们是如何用简单的方法筛选出相关信息并进行定时更新的。
豆瓣小组获取租房信息
豆瓣上有很多专门的租房小组,尽管这些年也逐渐「沦陷」为房屋中介的战场,但由于历史悠久,我们还是能从中筛选出合适房源。
接下来的尝试,我们以「上海租房」小组为例,从该主页可以看到,相同类型的小组不少,当然也适用于这个方法。
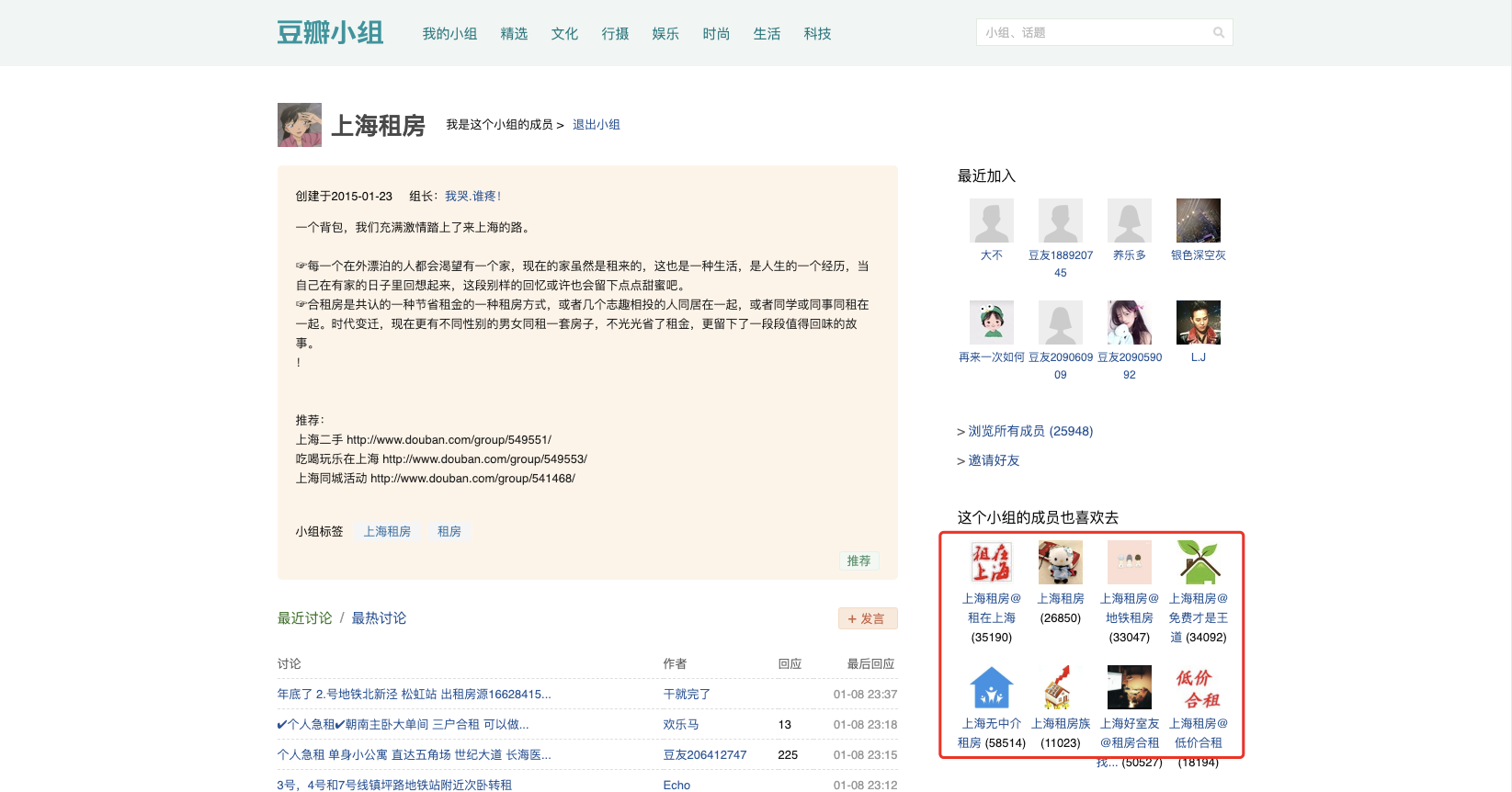
知己知彼,百战不殆。在抓取该页面信息之前,我们先来看看页面结构是怎样的。
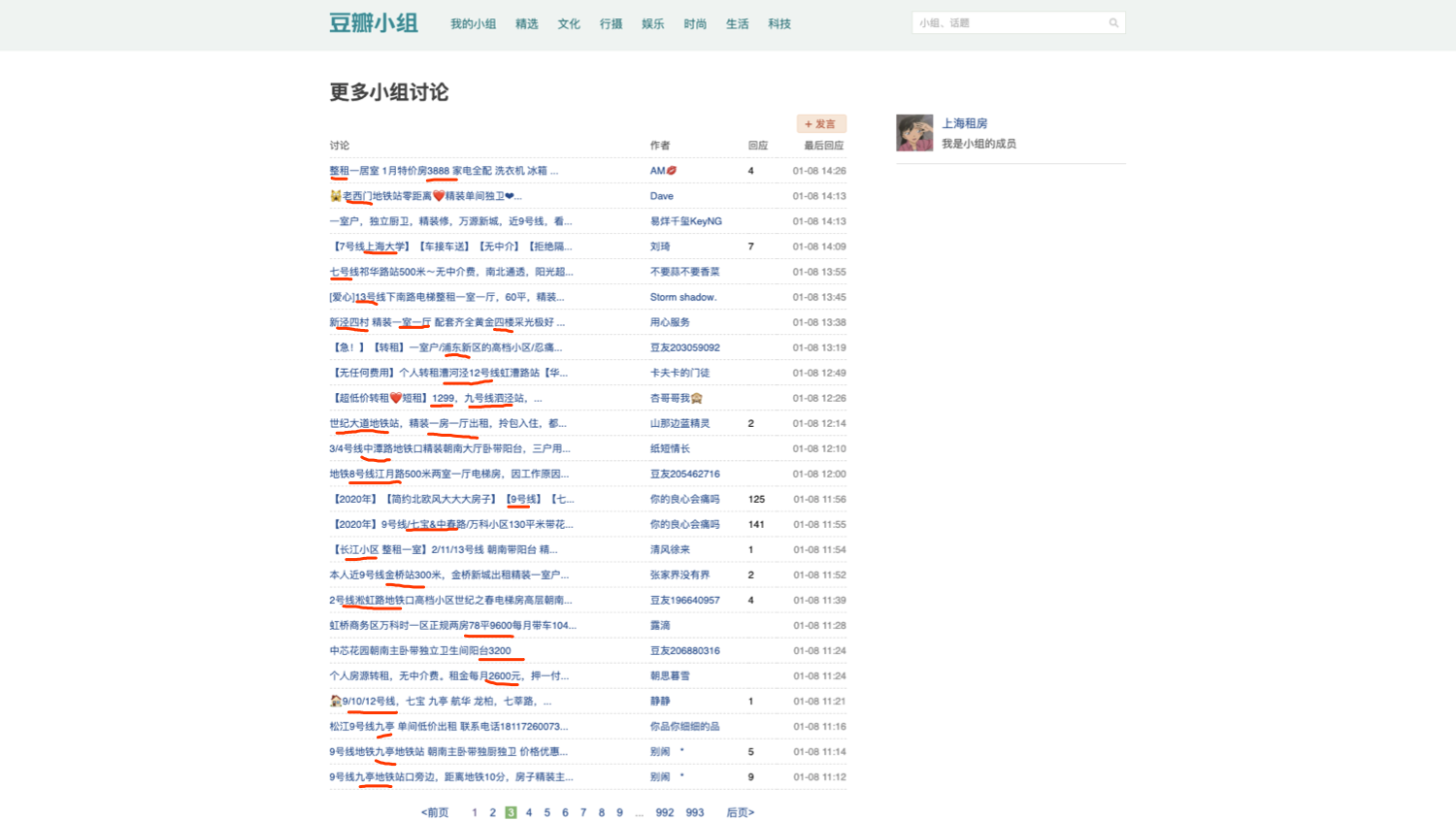
点击豆瓣页面中的「更多小组讨论」后,会发现帖子标题涵盖了我们关心的地铁线路、站名以及周边位置等信息。因此,我们的目标就可以概括为定时获取包含某些关键字的帖子标题以及链接,并去重。
「人生苦短,我用 Python」,我们的这个小工具就是基于 Python 3 实现的。而且方便的是,小组讨论不必登录就可以浏览,这就省去了模拟浏览器登录的麻烦。
安装 python
首先,我们需要 安装 Python ,详细方法可见这篇教程。建议使用 3.x 版本,毕竟今年 1 号起, 2.X版本官方都停止维护了。
Windows 下载安装包后,运行安装即可。
终端处输入 Python 显示版本信息则表示安装成功。
图为在 Windows cmd 中的效果。
虽然 Python 以短小精悍闻名,但我们还是想再精简下工作量,我们使用 Scrapy 框架来抓取网页上的信息,Scrapy 是 Python 的一个知名第三方爬虫库,Windows 平台可以直接通过安装Python后自带的 pip 安装,一行命令解决。
pip install Scrapy但 Mac OS 系统自带的 Python 2.7 会和 Scrapy 产生冲突,Mac OS 用户建议使用 virtualenv 在虚拟环境中进行安装。 都安装完毕后,就可以创建项目了。
创建项目
我们创建一个用以提取信息发送邮件的项目,将其命名为 ForumSpider。新建项目,首先 cd 到相应的目录,执行如下的命令:
scrapy startproject ForumSpider一个初始的 Scrapy 项目就生成了,下图是这个项目的目录结构,由于我们实现的功能比较简单,可以暂时不用关心其他文件,我们只需在 settings.py 中进行简单设置,然后在 spiders 目录下定义一个我们自己的爬取工具就够用了。

首先,我们需要在 settings.py 中设置 USER_AGENT,即用户代理,
User Agent中文名为用户代理,简称 UA,是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
简而言之,这就是客户机器的身份标识。我们需要设置此项以便能够隐藏机器的身份,不容易被网站拒绝。settings.py 中已经自带了一些配置。在浏览器中按下 F12,选择 Network 标签页,随意点击一个链接,就可以从 Header 中获取 USER_AGENT:
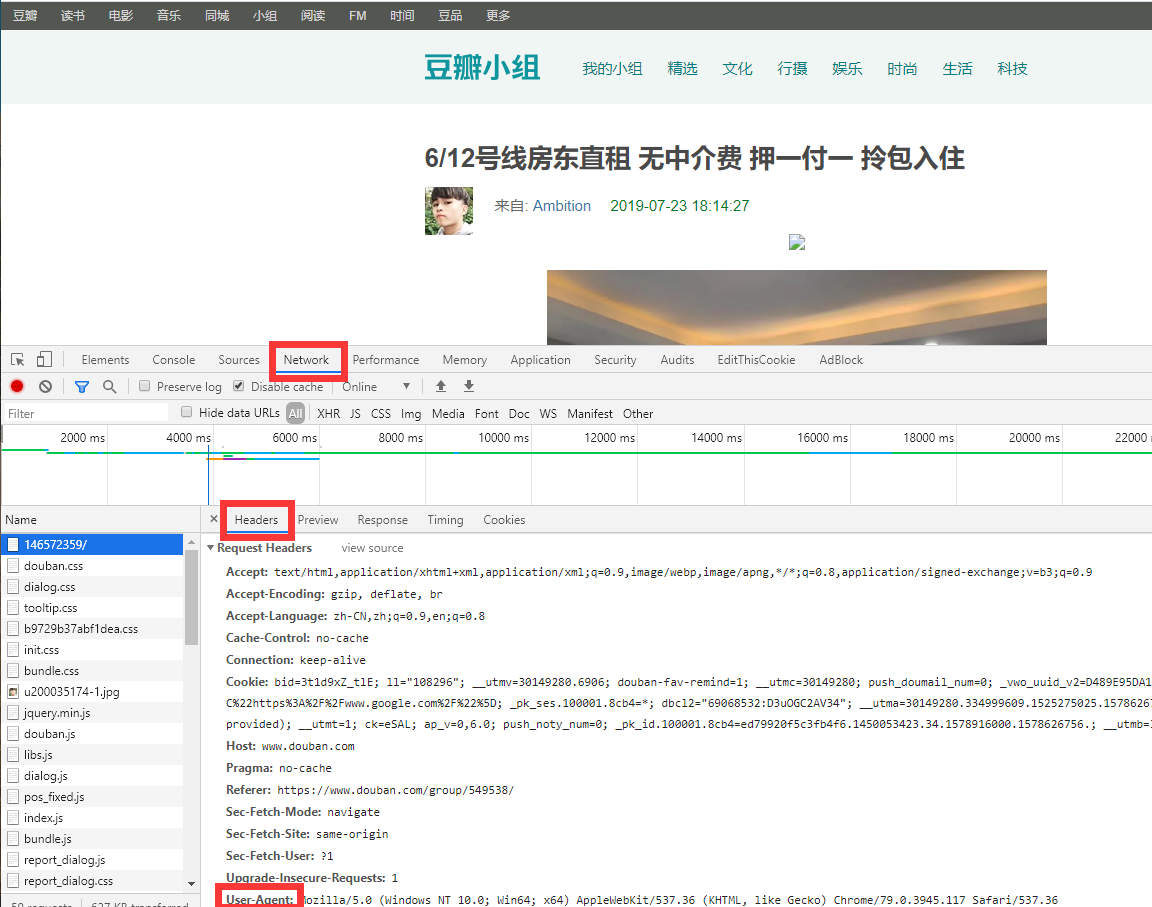
将其替换 settings.py 中的 USER_AGENT:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'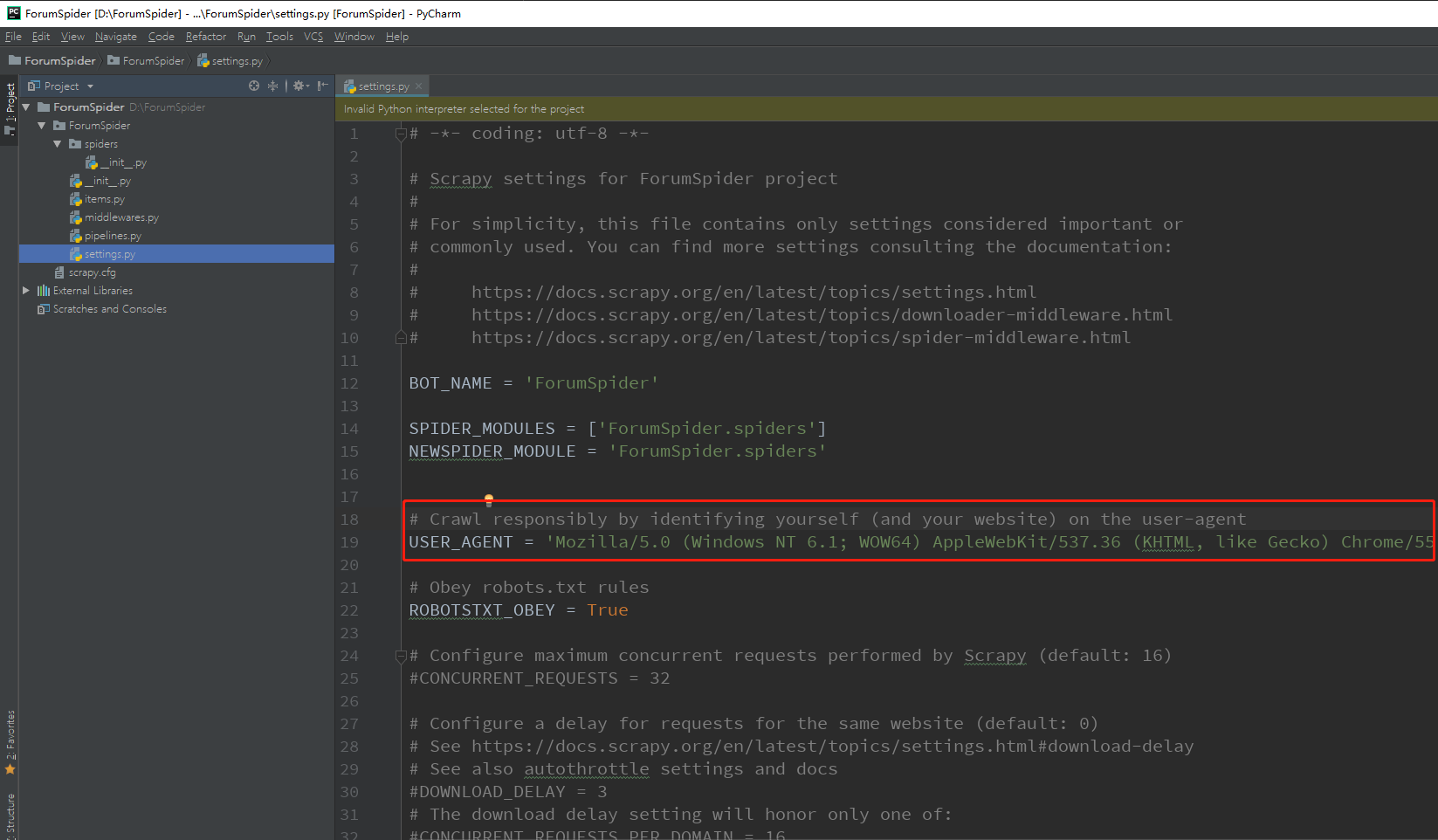
另外,我们选择遵循 Robots 规则,
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
Robots.txt中定义了我们可以爬取的范围,符合对应该网站的爬取规范,以避免不必要的爬虫风险。之后,我们就可以新建一个工具定义我们的爬取规则。在此之前,我们需要从网站中找寻一定的规律来编写我们的脚本,我们打开刚才的「更多小组讨论」的帖子列表页面,观察 url 的规律,下图分别是第一页的 url 和第二页的 url,可以看出,分页参数 start 代表开始的元素编号,每页 25 个帖子:
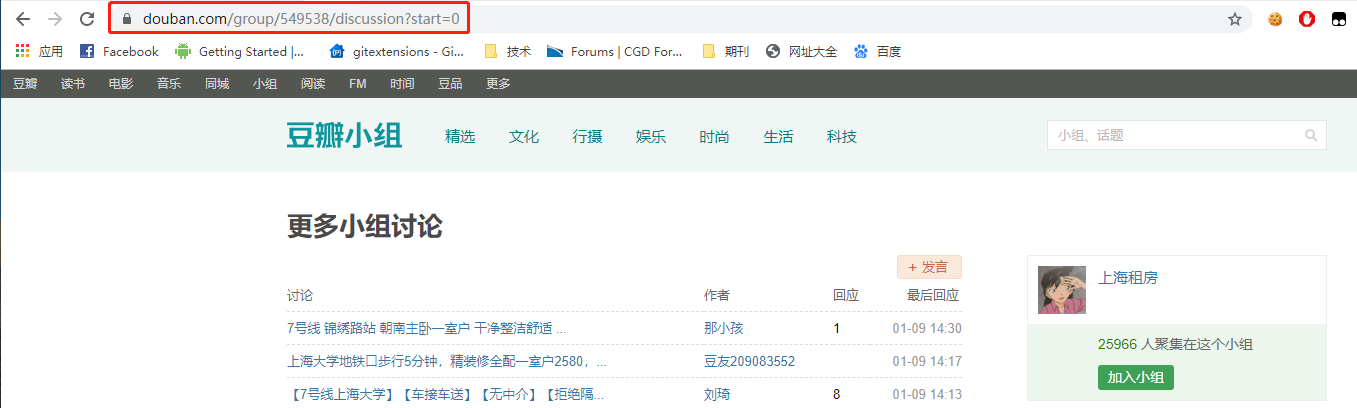
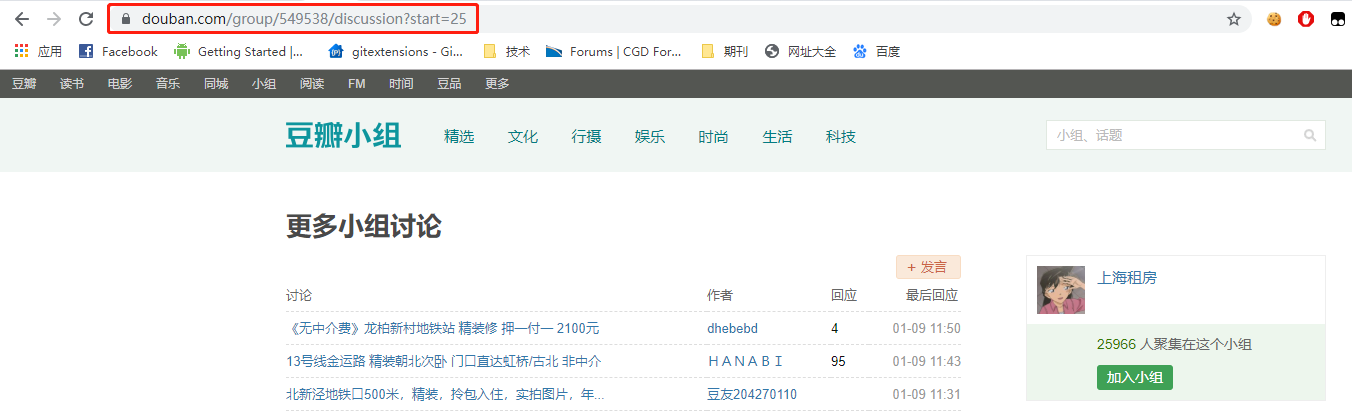
了解了每次爬取的 url 的变化规律,接下来我们需要了解爬取内容的 DOM 树结构,进入控制台,选择 Elements 标签页,使用旁边的选择器定位标题所在的结构:
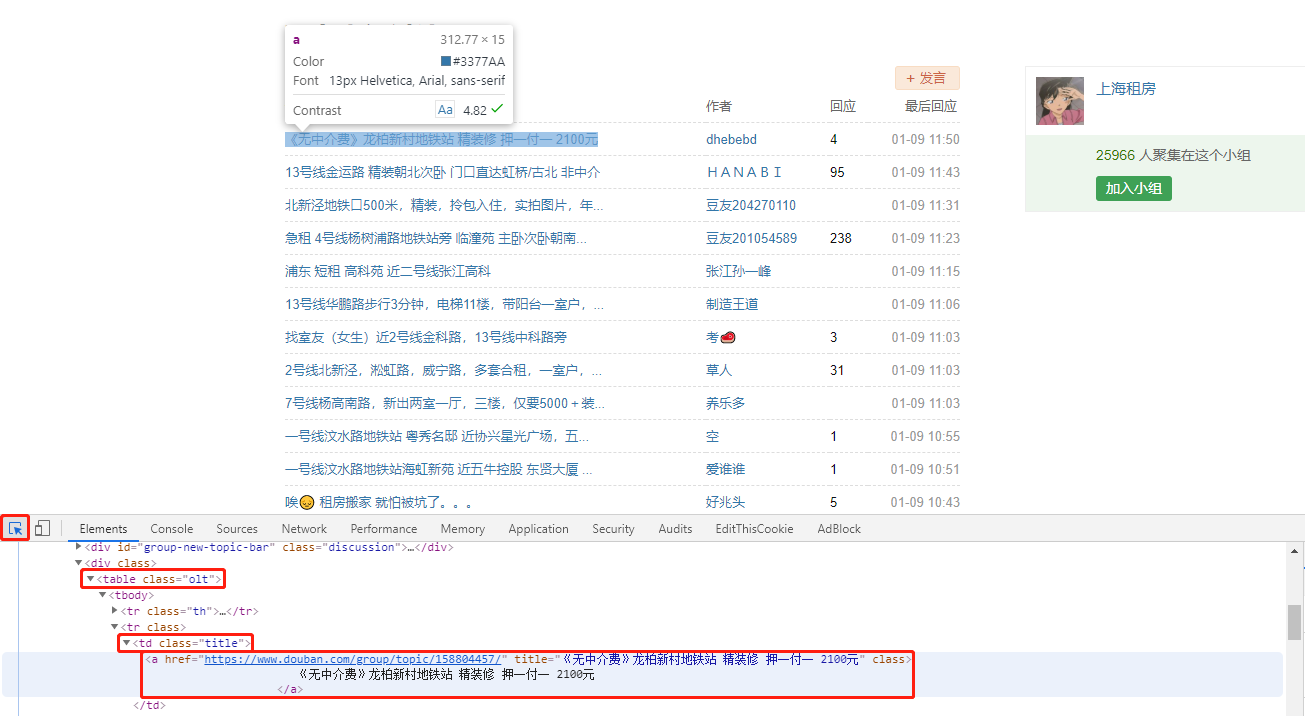
我们发现,整个列表是在一个名为 olt 的 class 中呈现的,标题所在的 class 名为 title,并且其中的超链接标签中包含了我们需要的所有信息,标题和链接。由于页面中可能包含有多个名为 title 的 class,因此我们将其父级元素 olt 同时作为条件选择以便更方便地定位。
回到刚才的项目,我们此时需要新建一个名为 douban 的爬取工具:
scrapy genspider douban "douban.com"douban.com 是我们设定的爬取域,生成的文件如图所示:
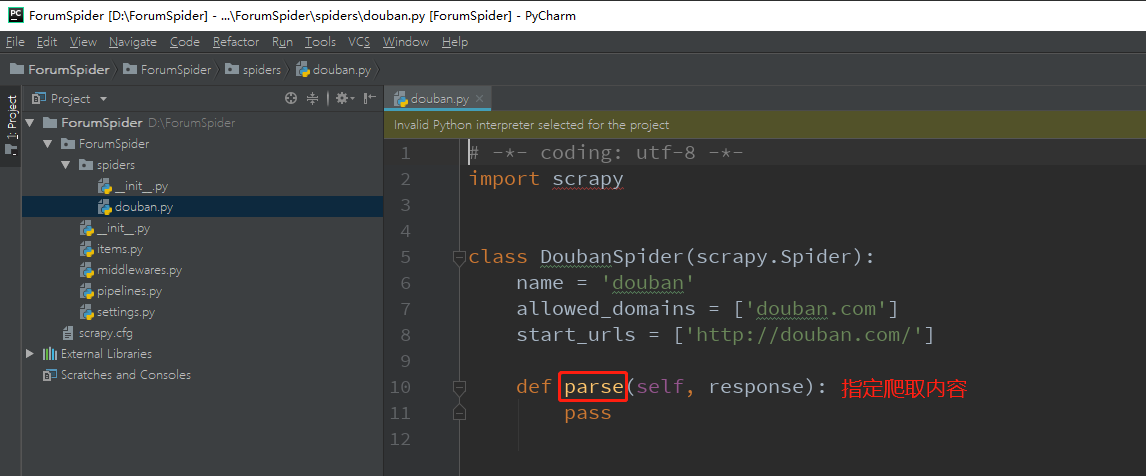
start_urls 代表了爬取的 url,但实际上我们如果需要爬取多个页面的话, url 则是动态的。因此我们可以将 allowed_domains 和 start_urls 变量删去,用 start_requests 方法来动态生成爬取的 url:
def start_requests(self):
for i in range(0, 5 * 25, 25):
url = 'https://www.douban.com/group/549538/discussion?start={page}'.format(page=i)
yield scrapy.Request(url=url, callback=self.parse)这个方法的功能就是循环爬取 start=0 到 start=100 的页面内容,每次共爬取 5 页,爬取时调用 parse 中指定的规则。 在刚才我们探索页面结构的基础上,parse 方法定义为:
def parse(self, response):
for title in response.css('.olt .title'):
yield {'title': title.css('a::text').getall(), 'link': title.css('a::attr(href)').getall()}这个方法的含义是获取 olt 的子元素 title 下的 a 标签的文本和 href 属性,即内容和链接。getall 代表获取符合上述条件的所有元素的内容和链接。 到这里,爬取的功能已经全部编写完毕了,一共是 7 行代码。但我们所需要的功能是在获取到新发布的帖子的信息时,收到推送或提醒。Scrapy 中内置了 mail 模块,可以很轻松地实现定时发送邮件的功能。那我们可以考虑先把爬取到的信息存储到文件中进行分析,再将由关键词筛选得到的信息与上一次筛选过后的信息进行比较,如果存在更新,就更新存储筛选信息的文件,并发送邮件。我们可以用以下的命令来将爬取到的信息输入到 JSON 文件中:
scrapy crawl douban -o douban.json
既然需要定时执行,那我们就需要在根目录中创建一个 douban_main.py,用 time 库编写一个简单的定时器,用以爬取之前清空存储爬取信息的文件,并每 21600 秒(6 个小时)执行一次爬取分析:
import time, os
while True:
if os.path.exists("douban.json"):
with open("douban.json",'r+') as f:
f.truncate()
os.system("scrapy crawl douban -o douban.json")
time.sleep(21600)
最后一步,就是筛选信息并发送邮件了,发送邮件需要引用 MailSender 类:
from scrapy.mail import MailSender
首先,我们要确保发送邮件的邮箱 SMTP 服务开启,并获取授权码,以 QQ 邮箱为例:
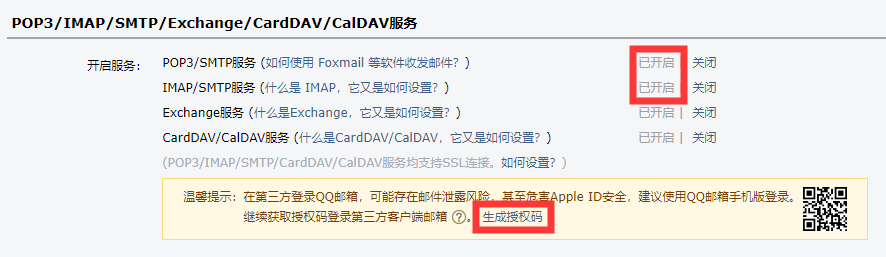
获取授权码之后,配置 MailSender 实例:
mailer = MailSender(
smtphost="smtp.qq.com",
mailfrom="xxxxxxxxx@qq.com",
smtpuser="xxxxxxxxx@qq.com",
smtppass="16 位授权码",
smtpssl=True,
smtpport=465
)
最后,我们需要指定一些关键词,为了便于理解,匹配的写法比较简易,注重性能的朋友们可以使用正则匹配。注意每次分析完毕之后,我们将迄今为止出现的符合关键词的信息写入到 douban_store.json 中,并在新信息出现时保持更新。这个过程写在爬虫程序结束之后调用的 close 方法中。附上 douban.py 的所有内容:
# -*- coding: utf-8 -*-
import scrapy, json, os
from scrapy.mail import MailSender
class DoubanSpider(scrapy.Spider):
name = 'douban'
def start_requests(self):
for i in range(0, 5 * 25, 25):
url = 'https://www.douban.com/group/549538/discussion?start={page}'.format(page=i)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for title in response.css('.olt .title'):
yield {'title': title.css('a::text').getall(), 'link': title.css('a::attr(href)').getall()}
def close(self):
mailer = MailSender(
smtphost="smtp.qq.com",
mailfrom="xxxxxx@qq.com",
smtpuser="xxxxxx@qq.com",
smtppass="xxxxxxxxxxxxx",
smtpssl=True,
smtpport=465
) # 配置邮箱
obj_store, new_info = [], []
key_words = ['枫桥路', '曹杨路', '11 号线']
if os.path.exists("D:\\ForumSpider\\douban_store.json"):
with open("D:\\ForumSpider\\douban_store.json", 'r') as f:
obj_store = json.load(f) # 读取之前爬取的符合关键词的信息
with open("D:\\ForumSpider\\douban.json", 'r') as load_f:
load_dict = json.load(load_f)
for info in load_dict:
content = info["title"][0].replace('\n', '').replace('\r', '').strip() #按标题进行筛选
for k in key_words:
if k in content:
tmp = {"title": content, "link": info["link"][0]}
if tmp not in obj_store: # 如果之前的爬取没有遇到过,则加入到新信息列表
new_info.append(tmp)
obj_store.append(tmp)
if len(new_info) > 0:
with open("D:\\ForumSpider\\douban_store.json", 'w') as writer:
json.dump(obj_store, writer) # 更新到旧信息列表
return mailer.send( # 发送邮件
to=['lolilukia@foxmail.com'],
subject='【豆瓣脚本】上海租房',
body='\n'.join([str(x['title'] + ':' + x['link']) for x in new_info])
)
运行 douban_main.py 即可定时运行这个信息爬取脚本:
python douban_main.py
包含主函数,这个脚本一共 51 行,现在已经能满足使用需要,当然还可以进一步精简优化。执行脚本之后,很快我就收到了第一封邮件:
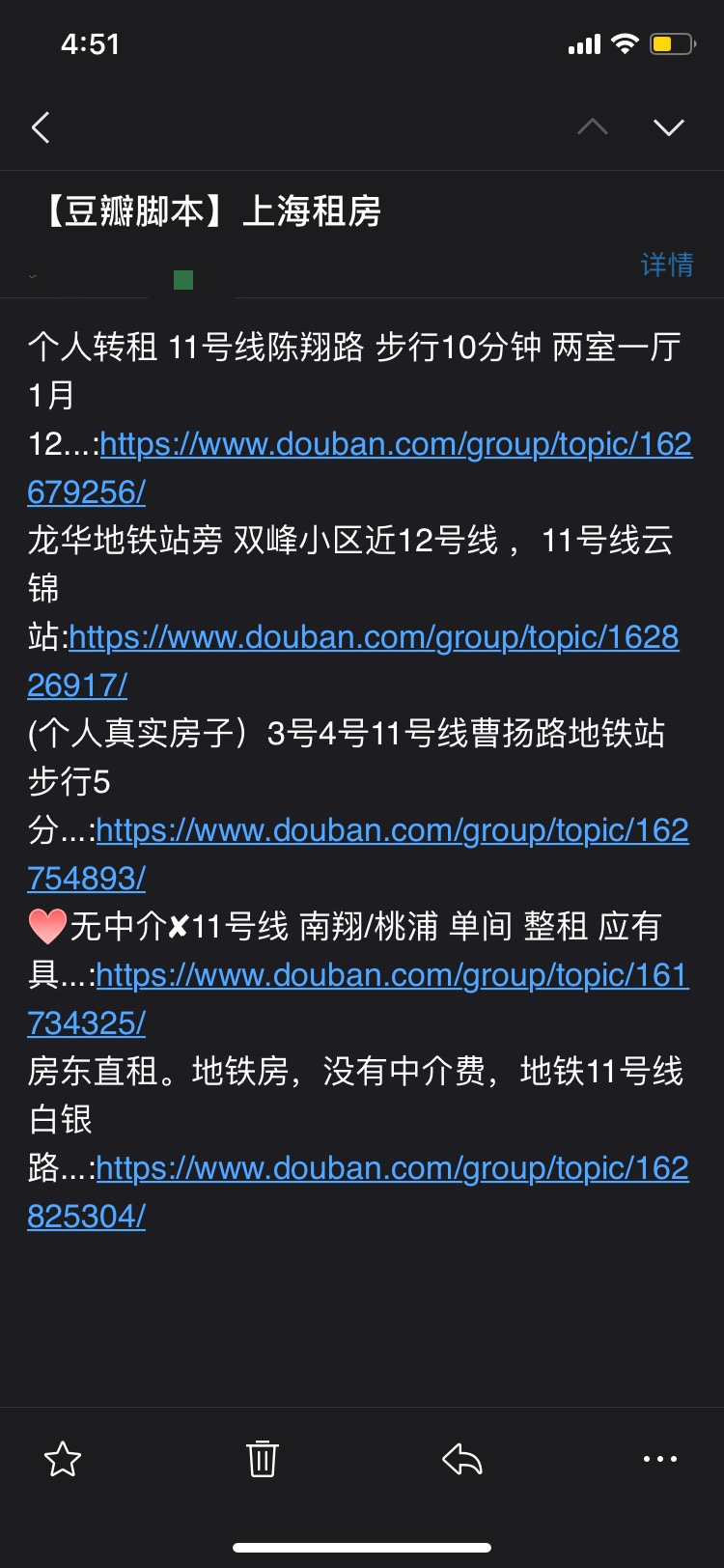
上述脚本适用于所有豆瓣小组,稍改改动优化过后也可以应用于获取留学信息、追星八卦等等方面。
场景 2:获取二手物品信息
上述的场景适用于不需要登录就能查看信息的一些网站,然而大多数情况下,更多的信息需要登录之后才能查看。很多网站登录的时候使用了验证码,扫码等策略避免自动登录,cookie 的模拟登录方式又极容易过期,使用简单的策略爬取网站信息似乎有些困难,下面以 v2ex 论坛为例,介绍另一种爬取网页信息的半自动方法。
为何称为半自动方法呢,进入 v2ex 的登录页,我们发现登录框的下方需要输入验证码,如果我们需要模拟登录的话,可能还需要写一个模式识别的程序,甚至比我们浏览论坛的时间成本还高。如果能够人工输入一次验证码,然后让程序自动定时爬取,好像也可以接受。这样的话,我们可以采用模拟人工操作浏览器行为的框架 selenium。
selenium 依旧可以使用 pip 来进行安装:
pip install selenium
selenium 3 之后需要单独安装浏览器驱动,因此我们需要下载 geckodriver 和 chromedriver。
,其他浏览器需要安装对应的驱动),并将它们都加入到环境变量 PATH 中。
首先,我们先使用 selenium 调用浏览器,打开 v2ex 的登录页面:
from selenium import webdriver
sigin_url = 'https://www.v2ex.com/signin'
driver = webdriver.Chrome('D:\\chrome_driver\\chromedriver.exe')
driver.get(sigin_url)
以下是运行效果:
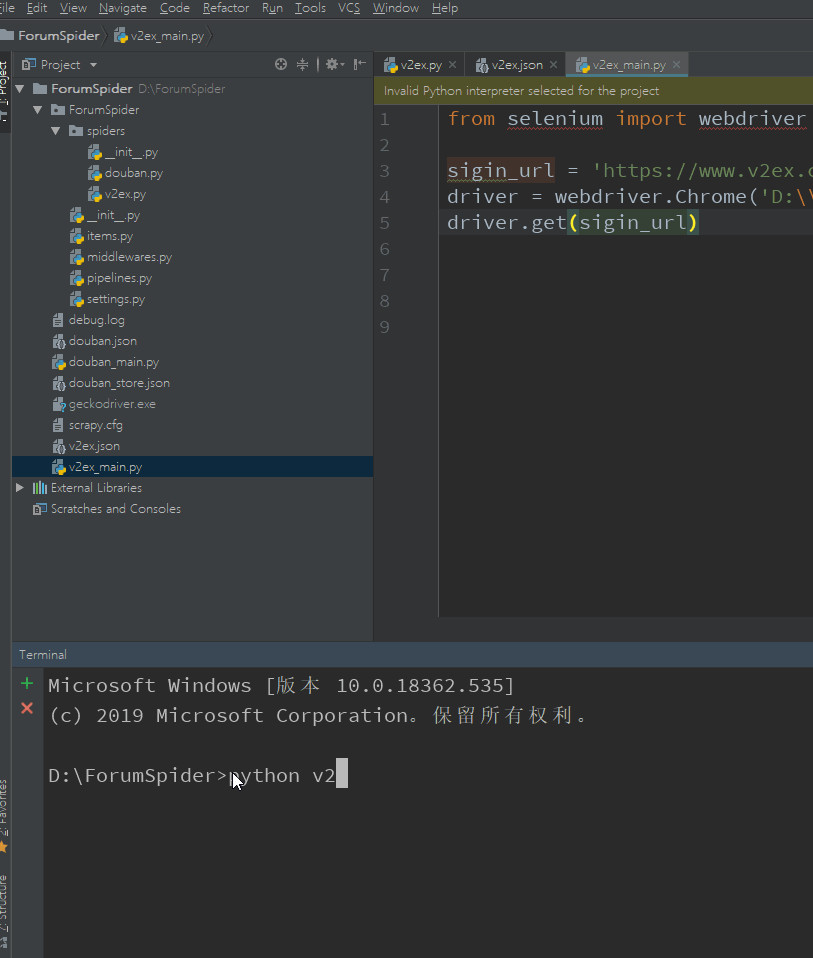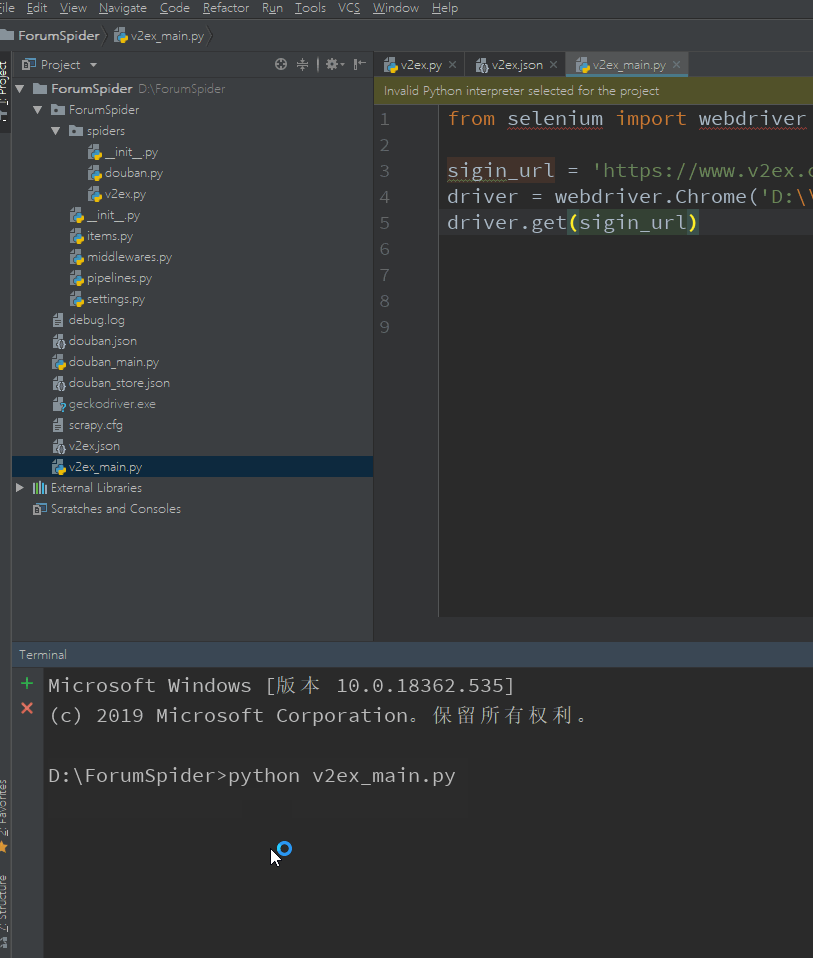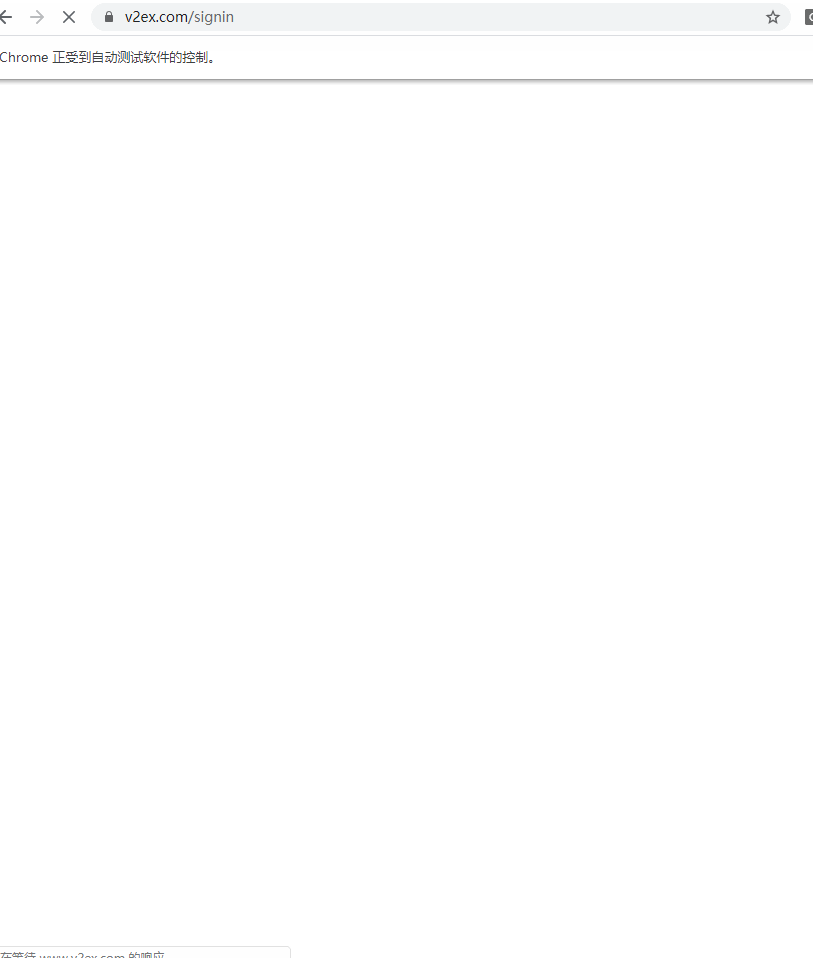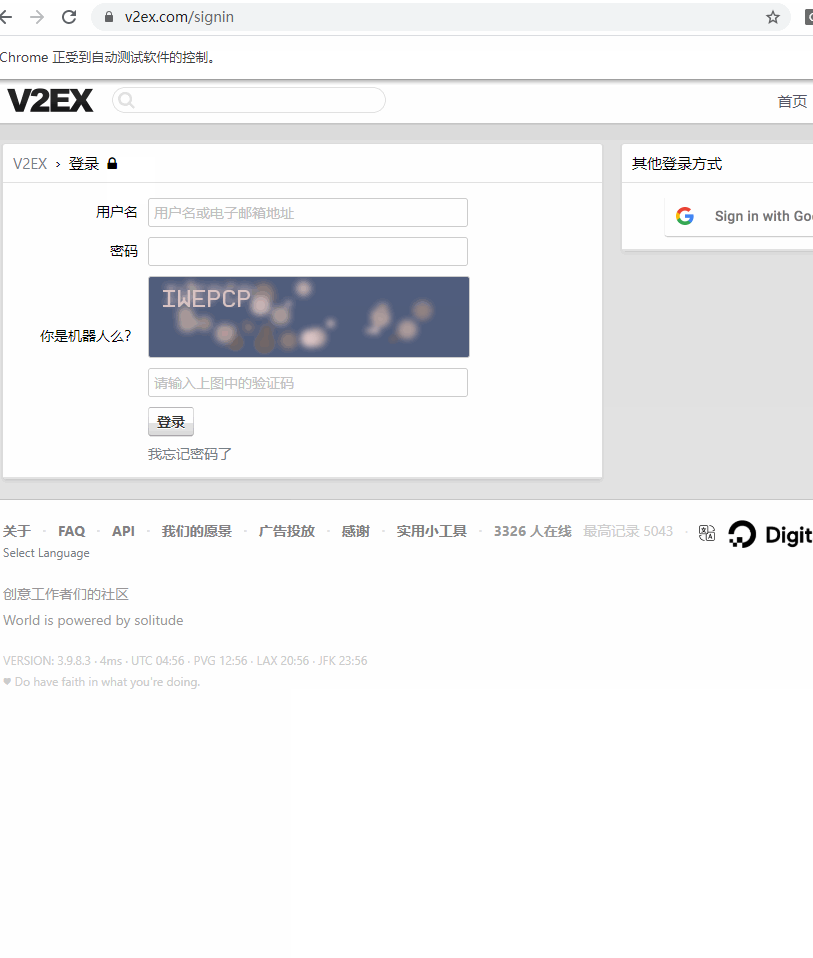
接下来,我们需要自动填充用户名和密码,然后等待我们人工输入验证码进入论坛。我们还是使用 CSS Selector 的方式定位元素,找到用户名和密码所在的输入框:
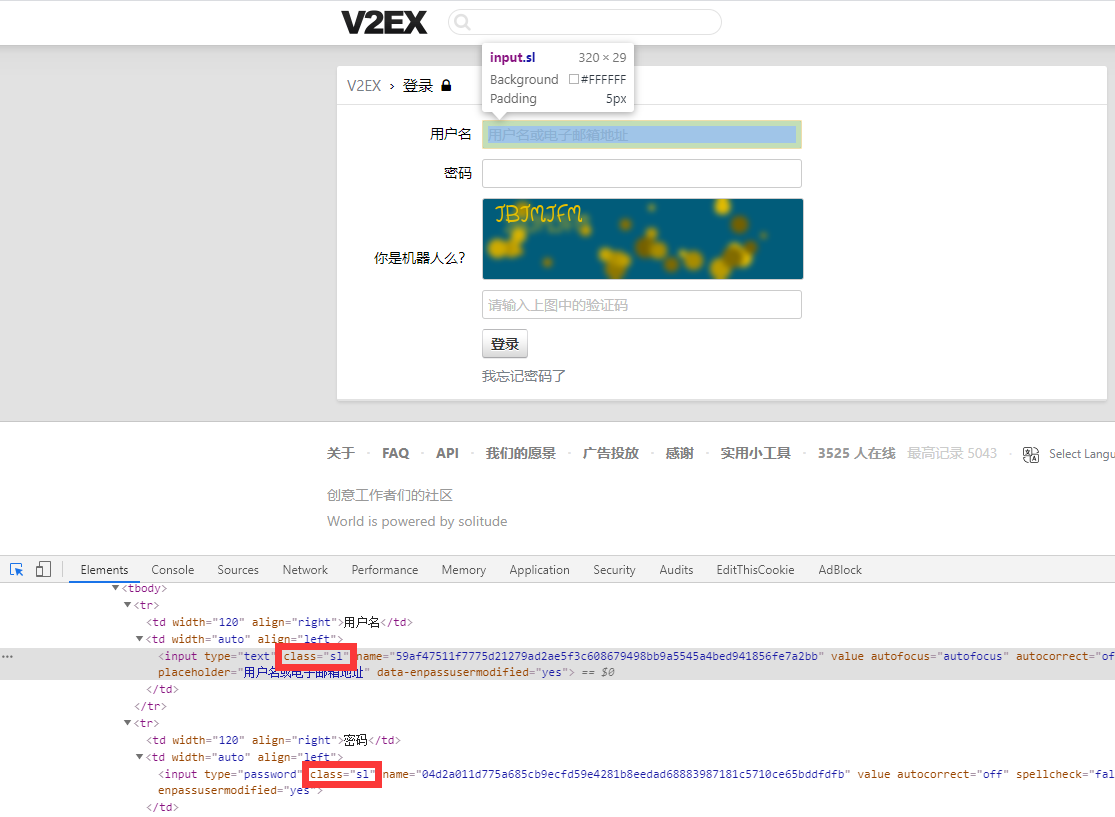
我们发现这两个输入框没有标识 id,也没有特别的 class 名称,因此我们可以使用 find_elements_by_css_selector 返回这一类元素的列表,幸运的是登录页一共只有 3 个输入框,因此我们可以通过索引迅速锁定它们,并填充我们的用户名密码。当然这里也可以用 tag 来定位:
user_name = driver.find_elements_by_css_selector('.cell .sl')[0]
user_name.send_keys('v2ex 用户名')
user_pwd = driver.find_elements_by_css_selector('.cell .sl')[1]
user_pwd.send_keys('v2ex 密码')
运行效果如下:

验证码需要我们自行输入,为了让程序等待我们输入完毕验证码并点击登录按钮之后再进行爬取,我们设定一个 while 循环,当页面跳转到论坛列表页,出现特定元素时跳出:
while True: # 等待人工输入验证码
table = driver.find_elements_by_id('Tabs')
if len(table) != 0:
break
其余的逻辑与场景 1 大抵相仿,在此不多加赘述。模拟浏览器行为的写法比较简单,访问页面时调用形如 driver.get(url) 的方法即可,抓取的写法也很好理解,只是由于调用了浏览器,爬取速度会稍慢。不过这也无妨,我们要做的就是在点击登录按钮之后等待邮件即可。由于这个场景不再使用 Scrapy 进行抓取,发送邮件我们改用 Python 内置的 smtplib 和 email 模块,进行简单的配置(16 位授权码的获取方式参见场景 1):
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = 'xxxxxx@qq.com'
subject = '【v2ex 脚本】二手交易'
smtpserver = 'smtp.qq.com'
passcode = '场景 1 出现过的 16 位授权码'
然后需要构造一个 MIMEText 实例,用以定义发送的内容、发件人、收件人和主题等等:
msg = MIMEText(body, 'html', 'utf8')
msg['From'] = sender
msg['To'] = sender
msg['Subject'] = Header(subject, charset='utf8')
这里的 body 就是我们筛选出的新信息的字符串,发送邮件的过程也十分简单:
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(sender, passcode)
smtp.sendmail(sender, sender, msg.as_string())
如果需要多次运行,则可以使用 JSON 文件记录筛选过的信息,如果仅运行一次,将 obj_store 放置在 while 循环外即可。注意尽量避免较短时间内多次进行登录操作,否则可能会被封 IP。另外,如果新增回复,链接会发生变化,因此此处只判断 title 是否出现过。附上 v2ex_main.py 的所有内容:
from selenium import webdriver
import time, os, json
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = 'xxxxxxxxx@qq.com'
subject = '【v2ex 脚本】二手交易'
smtpserver = 'smtp.qq.com'
passcode = '16 位授权码'
sigin_url = 'https://www.v2ex.com/signin'
driver = webdriver.Chrome('D:\\chrome_driver\\chromedriver.exe')
driver.get(sigin_url)
user_name = driver.find_elements_by_css_selector('.cell .sl')[0]
user_name.send_keys('v2ex 用户名')
user_pwd = driver.find_elements_by_css_selector('.cell .sl')[1]
user_pwd.send_keys('v2ex 密码')
while True: # 等待人工输入验证码
table = driver.find_elements_by_id('Tabs')
if len(table) != 0:
break
key_words = ['mbp', 'AirPods', '触摸板']
obj_store = []
while True:
new_info = []
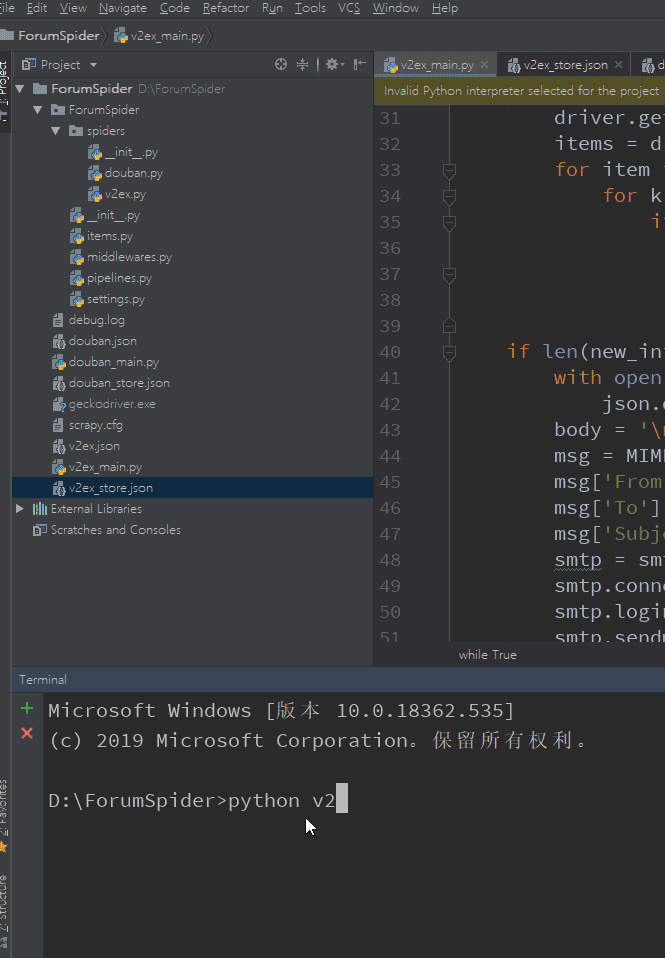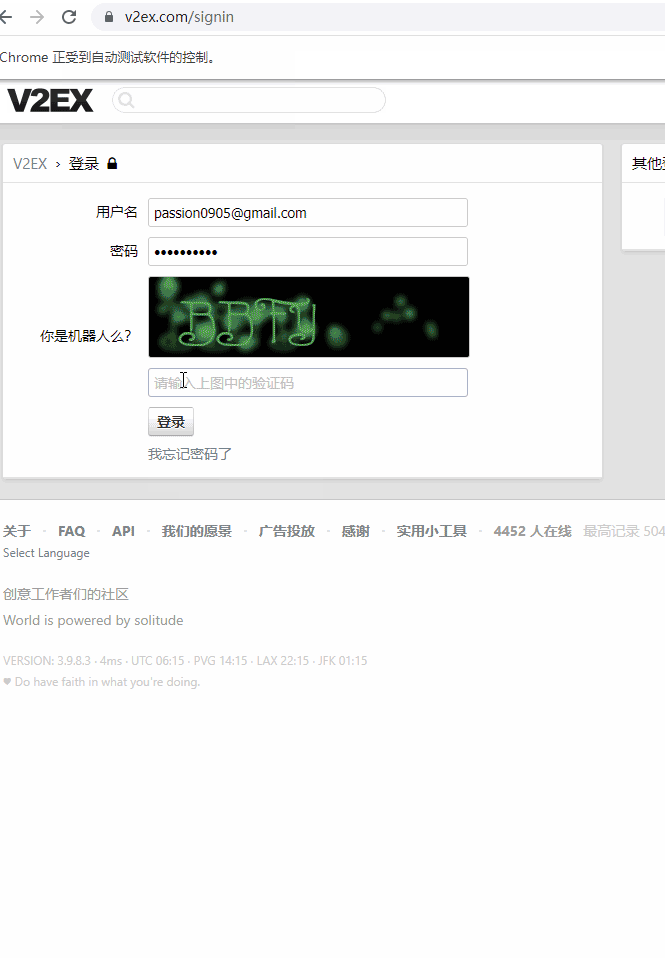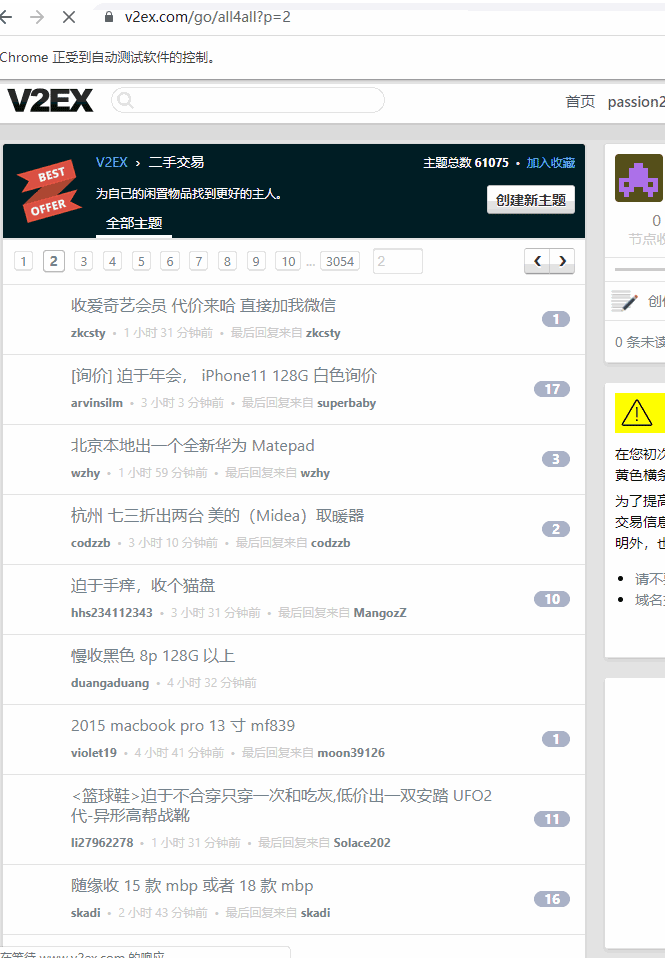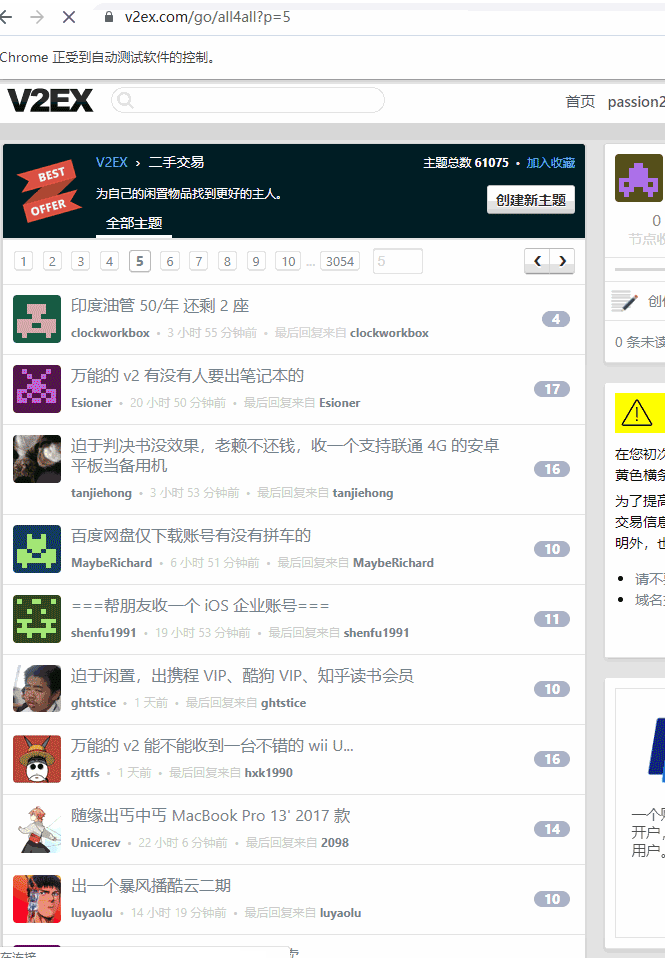
for i in range(0, 5):
driver.get('https://www.v2ex.com/go/all4all?p={page}'.format(page=i+1))
items = driver.find_elements_by_css_selector('.item_title a')
for item in items:
for k in key_words:
if k in item.text:
tmp = {'title': item.text, 'link': item.get_attribute('href')}
if tmp['title'] not in obj_store:
new_info.append(tmp)
obj_store.append(tmp['title'])
if len(new_info) > 0:
body = '\n'.join([str(x['title'] + ':' + x['link']) for x in new_info])
msg = MIMEText(body, 'html', 'utf8')
msg['From'] = sender
msg['To'] = sender
msg['Subject'] = Header(subject, charset='utf8')
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(sender, passcode)
smtp.sendmail(sender, sender, msg.as_string())
smtp.close()
time.sleep(1800)
爬取的过程如下图所示:
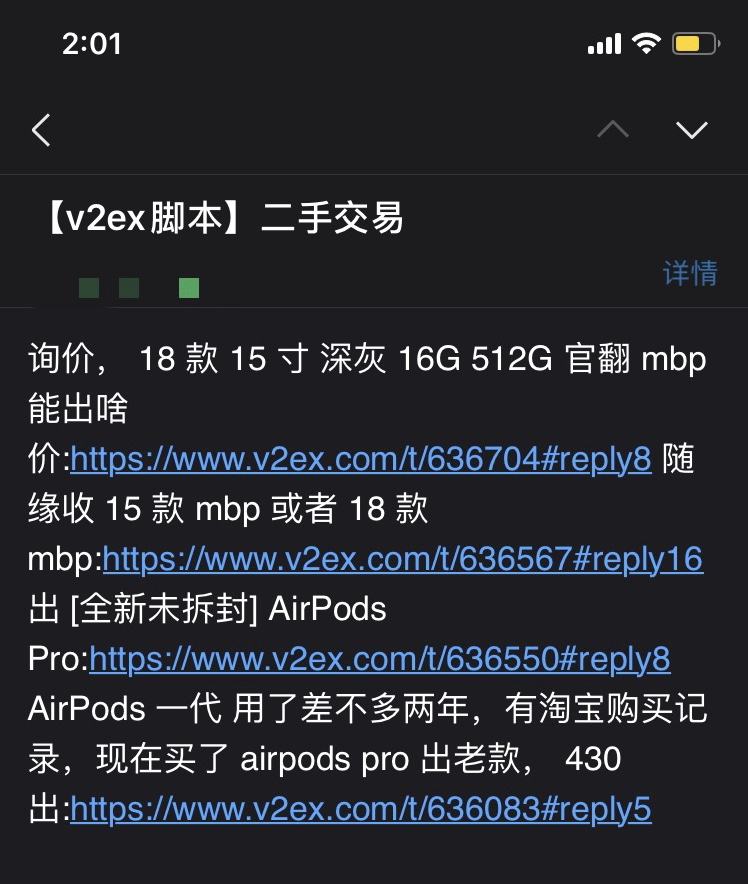
切记不要关闭浏览器,随后会收到一封来自脚本的邮件:
总结
以上仅是相应于场景提出的小规模样例,生活中其实有相当多的应用,比如最近一段时间抢购口罩等等。这样的小工具能够一定程度上提高我们生活的效率,避免花费不必要的时间。
最后,虽然网页爬虫能够给我们的生活带来一定的便利,免去人工筛选信息的烦恼,但还是要注意道德与法律的边界,防止带来一系列负面影响。