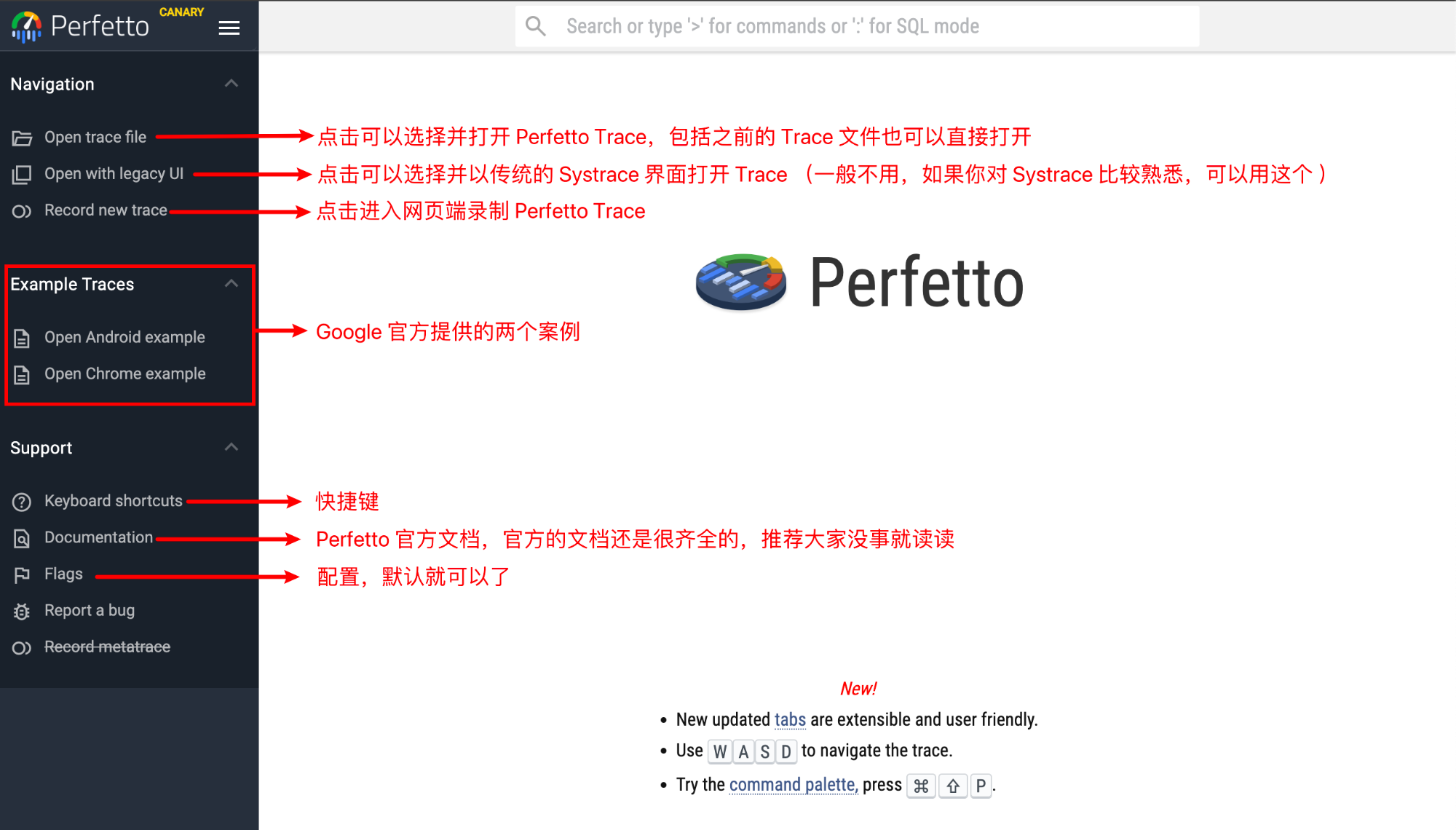
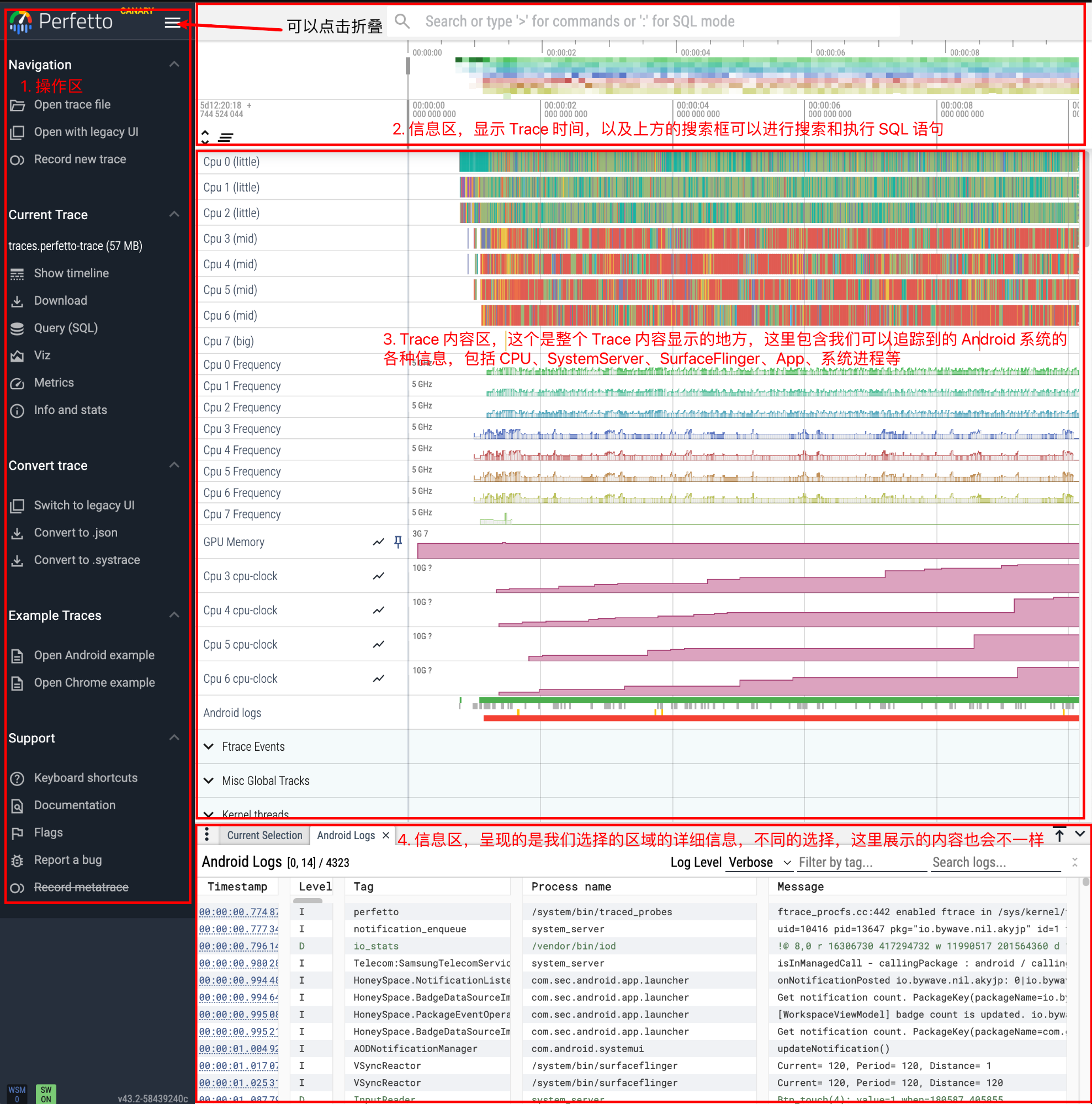
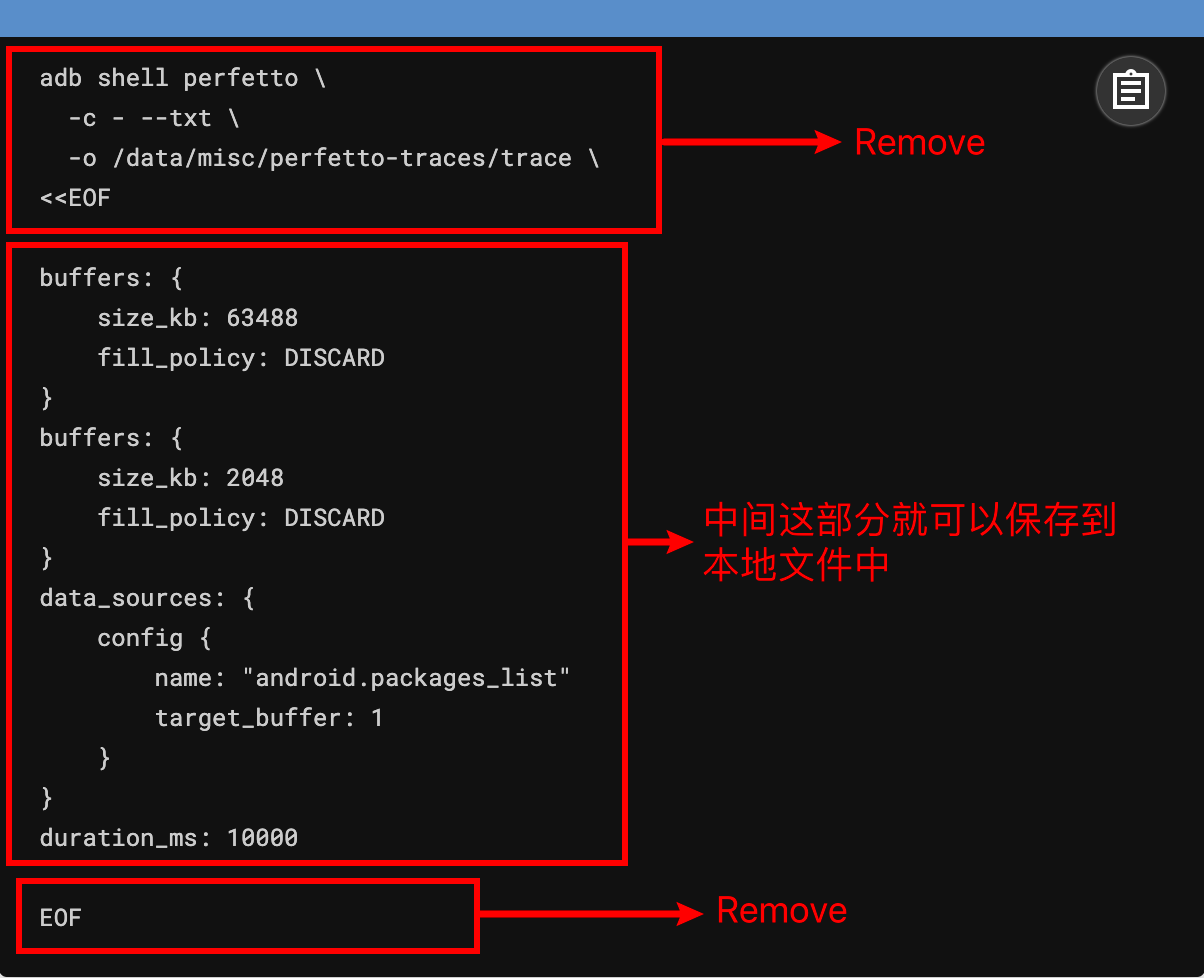
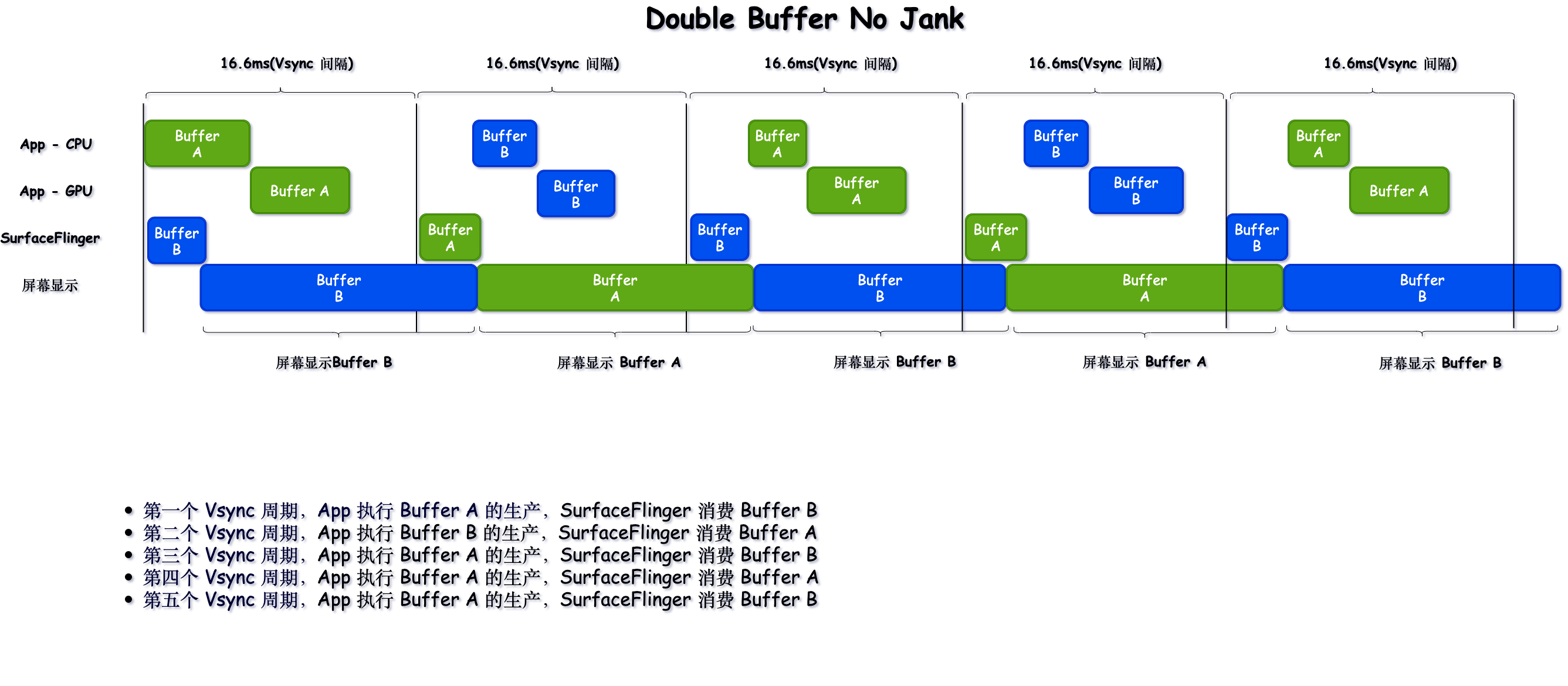
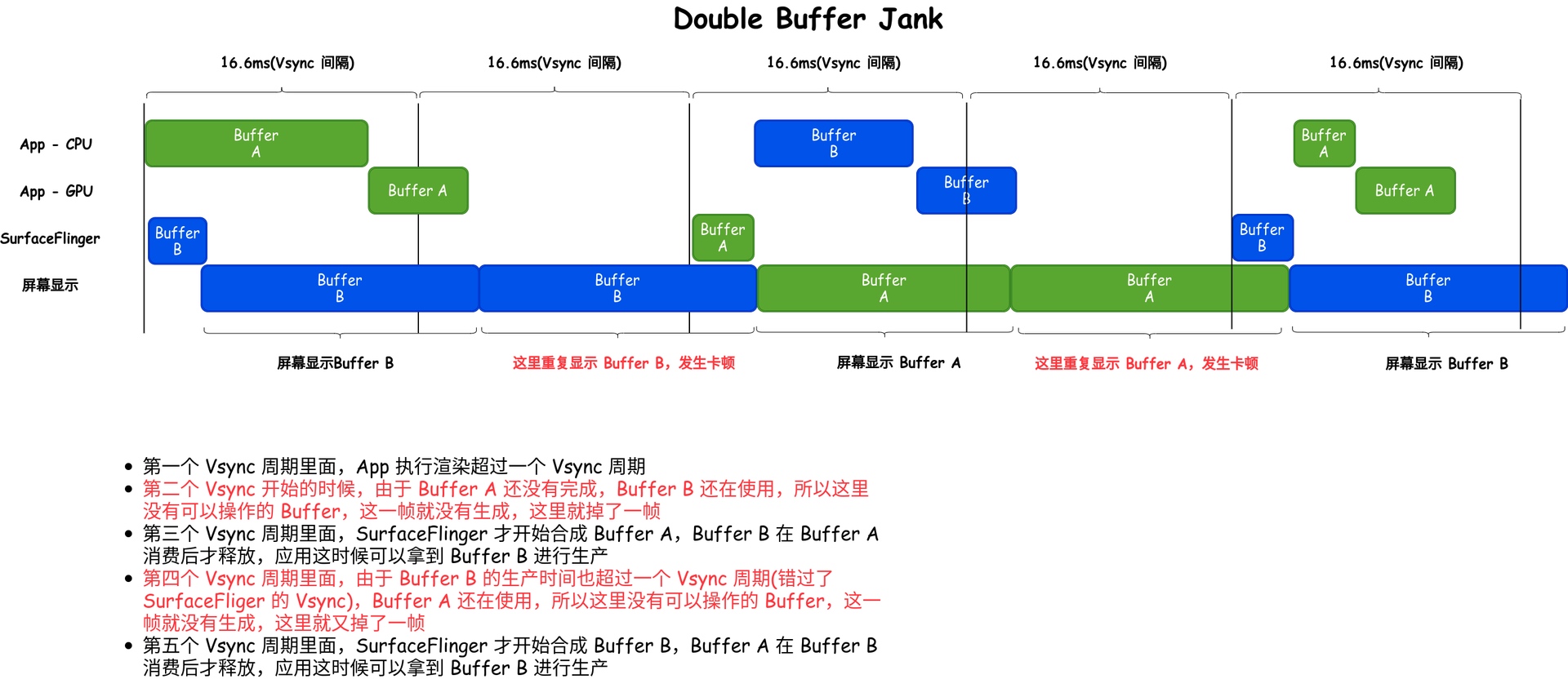
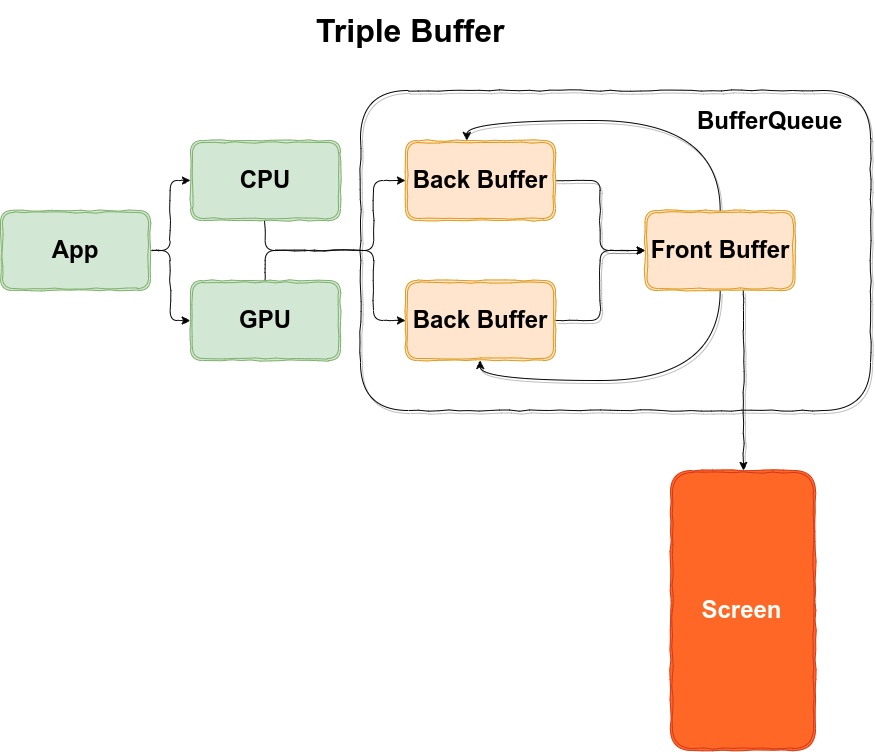
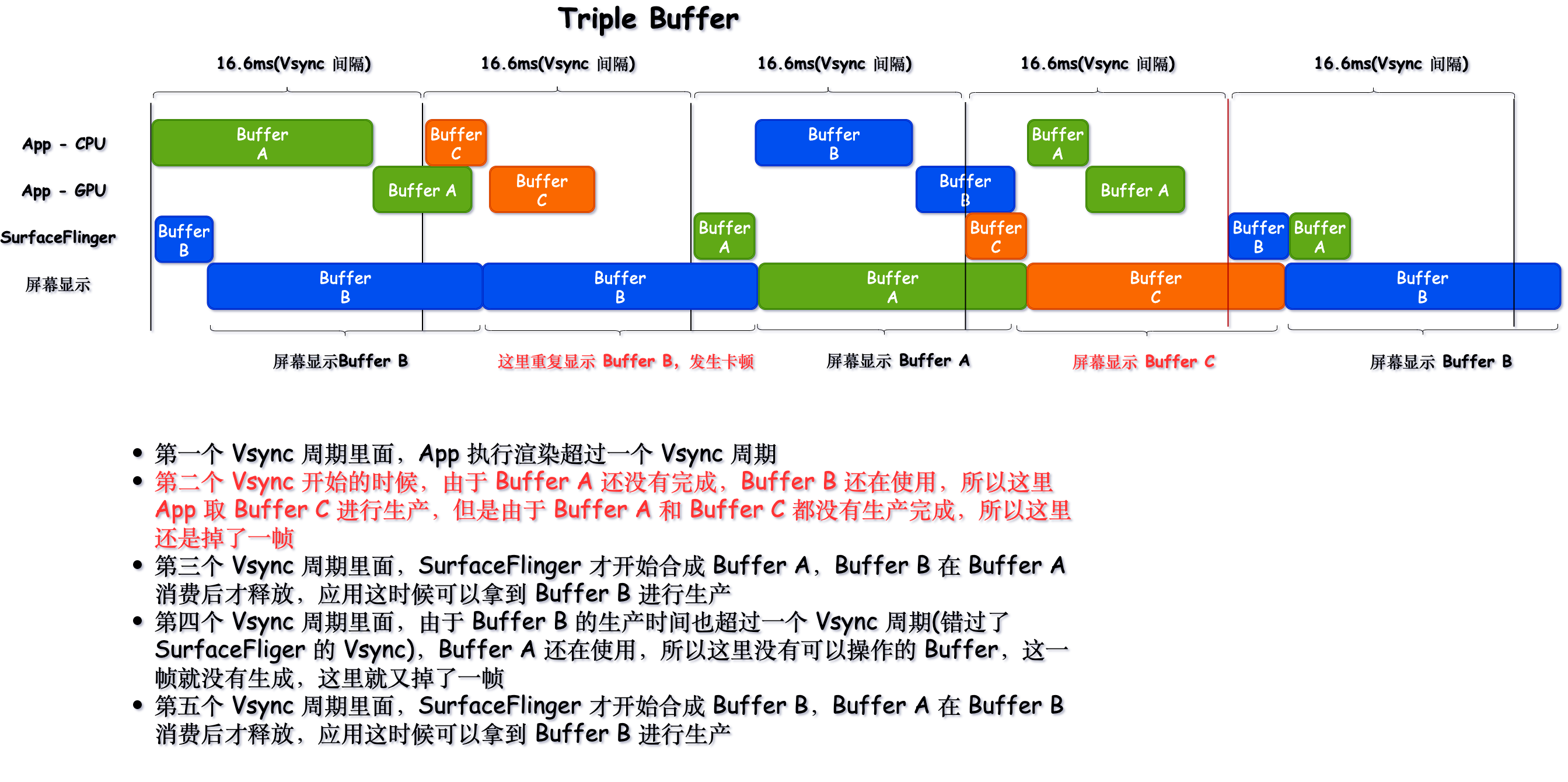
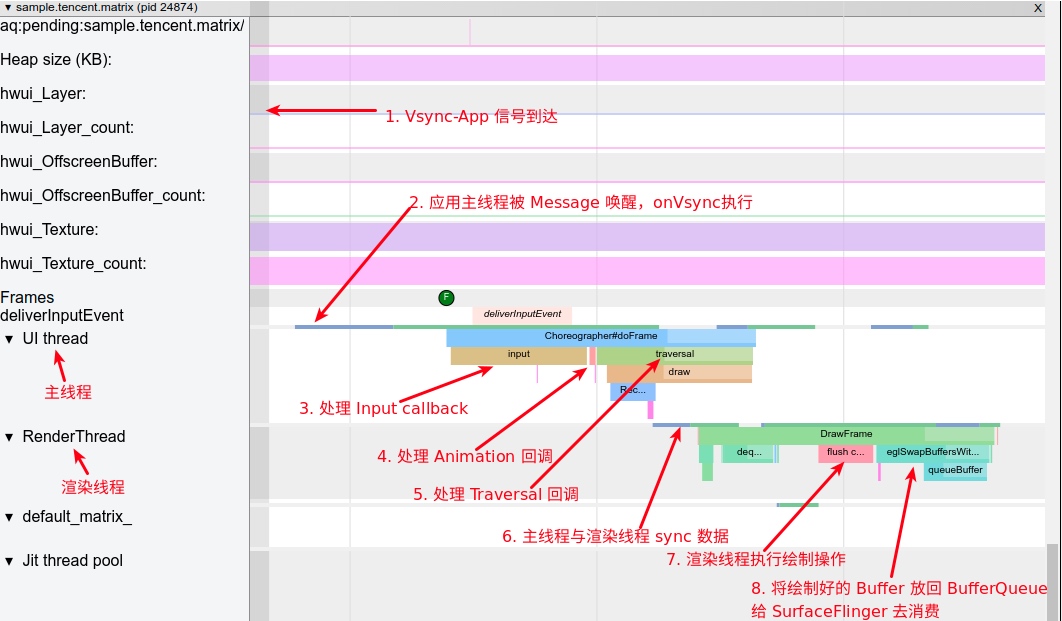
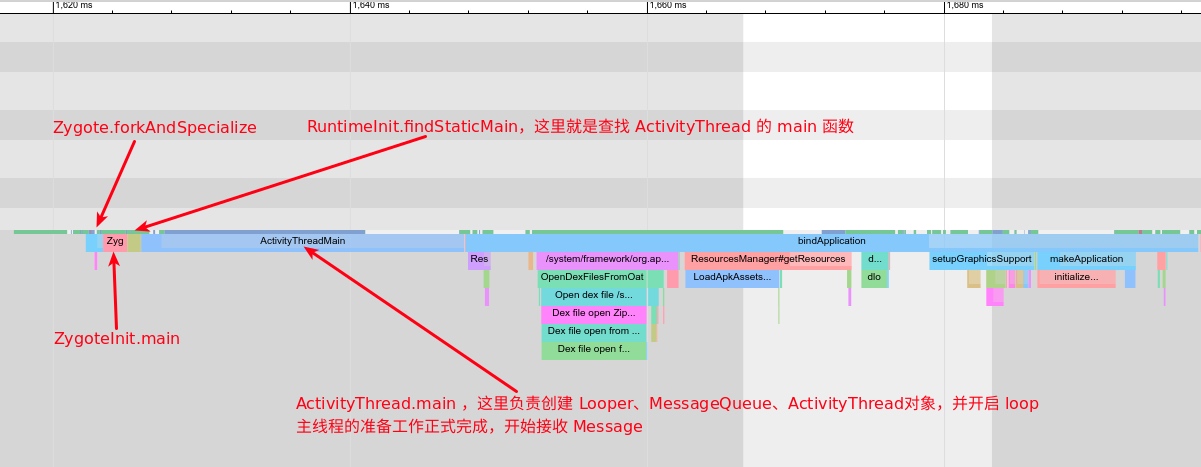
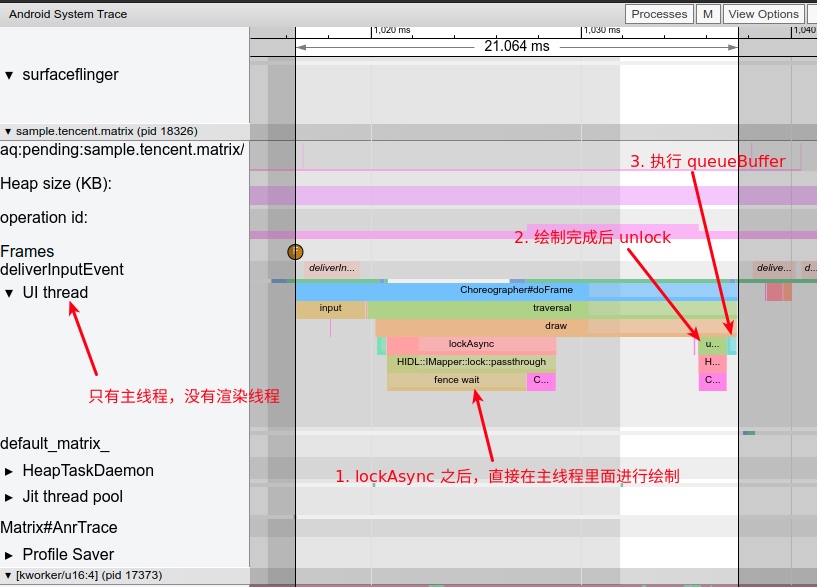
1 Origin
I am embarking on a new series of articles addressing various considerations in OS architecture design. Indeed, these considerations are not limited to OS but are applicable to the design of any large-scale software.
I am limited by my capabilities and knowledge and bring a highly subjective view, and there are undoubtedly inadequacies. I am eager to hear different thoughts and perspectives, and through the collision of ideas, we can achieve a deeper understanding.
In my opinion, the core differences between Android and iOS from the OS perspective are primarily manifested in:
- The IPC mechanism between applications and core services
- Platform development environment, including programming languages, IDE tools, and the construction of the developer ecosystem
- Application lifecycle management mechanisms and strategies
- The runtime organizational structure of the kernel and core services
Why do they adopt different strategic decisions? It relates to the factors considered during architectural design. A software architectural decision is a selection of the most suitable decision for the present and foreseeable future amidst a series of current considerations; it is a collection of decisions. Thus, there’s no absolute right or wrong in architectural design, or rather, rational or irrational. Different projects and decision-makers face different considerations and prioritize different aspects. If architects of similar skill levels switch scenarios, they are likely to make similar decisions. This indicates that architectural design is an engineering process and a technical craft, learnable and following certain patterns.
The challenge in architectural design lies in accurately understanding the environment the organization operates within, current and foreseeable considerations, and finding the most suitable methodologies or tech stacks from existing engineering practices. It is evident that considerations play a significant role. What factors need to be considered in software architectural design? These include, but are not limited to, testability, component release efficiency, development efficiency, security, reliability, performance, scalability, etc. Experienced architects, especially those with operational experience in similar businesses, are better at discerning what to focus on at different times, what must be adhered to, and what can be relaxed or even abandoned. Considering the law of diminishing marginal returns, the consideration of influencing factors and decision-making behavior will permeate the entire lifecycle, introducing another art of decision-making.
We can summarize that:
- Under different stages and constraints of various considerations, software architectural designs on different projects may differ.
- During the entire cycle of software product iteration, such design decisions are always evolving.
Interestingly, one consideration may conflict with another, leading to a situation where one cannot have the best of both worlds. For example, improving component development efficiency might impact program performance. So, what were the considerations for the designers of Android and iOS in the context of mobile OS design? To answer this question, we first need to explain the relationship between the OS, application programs, and the kernel.
2 Mechanisms and Policies
First, it should be noted that the OS is part of the software stack above the hardware. It, along with application programs, constructs the complete software program stack, utilizing the hardware capabilities to provide services to users. From the hardware’s perspective, regardless of the OS or application programs, both are software; however, the OS has higher privileges, allowing it to operate in the CPU’s high-level modes, for tasks such as direct interaction with hardware and executing interrupt handling routines. From the software developer’s perspective, however, the OS and application programs are entirely different entities. Application programs utilize the capabilities provided by the OS to meet their business requirements or use hardware capabilities for tasks like playing music or storing data.
At a higher level, from the user experience perspective, application programs, OS, and hardware are all part of the same entity. When issues arise in their collaboration, ordinary consumers might simply feel that the device is less than ideal. Therefore, all three parties are obligated to cooperate and facilitate each other; only when the consumer is well-served can these entities sustainably profit.
In discussing the OS, it’s crucial to recognize that the vast majority of modern OSes consist of a kernel and system services.
- In macOS/iOS, the kernel is Darwin, formed from the combination of XNU and the MACH microkernel. Its system services are provided by an array of daemon services, encapsulating kernel capabilities, data management, and higher-level APIs like display.
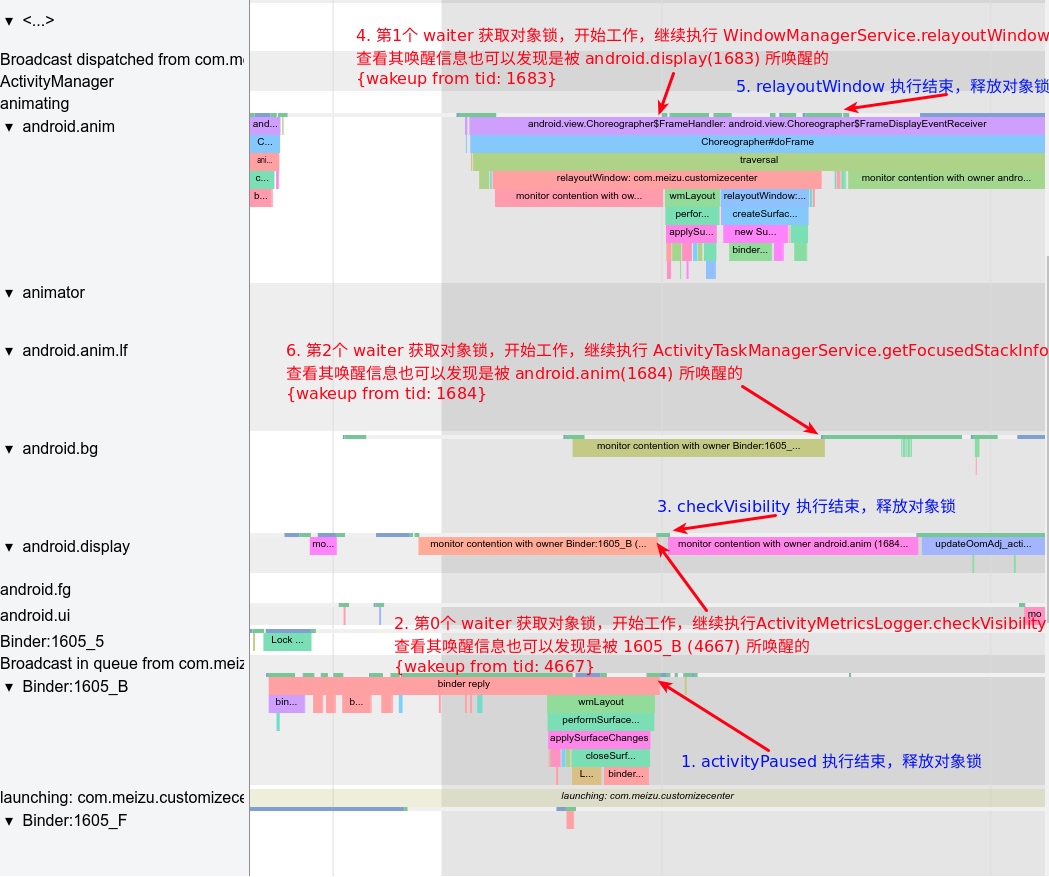
- In Android, the kernel is the Linux kernel, with system services comprising C++ written daemon services (e.g., SurfaceFlinger) and Java written daemon services (e.g., SystemServer). They too encapsulate kernel capabilities, data management, and higher-level APIs concerning display rendering and composition.
Current mainstream operating systems include macOS, Windows, and various derivatives of Linux. Clearly, Android belongs to the Linux derivatives, with another renowned version in the developer community being Ubuntu. Due to the complexity and path-dependent nature of a complete OS, derivatives are often deployed on different hardware and application scenarios. For a while, Linux was lauded for its extensive device radiation and wide application scenario spectrum. However, being able to run an OS and running it well—connecting hardware and application programs to offer an optimal user experience—are two different things.
An increasingly common understanding is that the OS’s mechanisms, policies, and closely associated application programs vary greatly depending on the application scenario.
For instance, even if based on the same Linux kernel, the use and system services built upon it for embedded devices, smartwatches, smartphones, large servers, or even smart cars are distinctly different, as are the operating strategies of application programs. The Linux kernel and device drivers can be seen as the bridge between hardware and system services—a standard bridge—but the vehicles and pedestrians traversing it are entirely distinct.
This leads to another classic OS design concept: mechanism and policy.
The “separation principle” noted in UNIX programming specifies the separation of policy from mechanism and interface from the engine. Mechanisms provide capabilities; policies dictate how those capabilities are used.
In this context, the memory management, process management, VFS layer, and network programming interfaces that Linux provides are mechanisms. Memory allocation and release mechanisms, process schedulers, frequency and core allocators, and different file systems are policies. Going further, identifying which processes interact with users and which are background tasks, synchronizing this information to the scheduler to determine the optimal process for the next scheduling window is fundamentally a policy built upon the Linux process management mechanism. Similarly, notifying future computational task requirements to the CPU frequency allocator for dynamic adjustment (DVFS) involves a policy and a mechanism.
For instance, all modern OSes support memory compression capabilities, but different OSes use this mechanism according to their own characteristics to best meet business needs. iOS exhibits process-level compression, while Android relies on Linux’s ZRAM.
Though OS mechanisms might be similar, policies are diverse. The extent of their differences depends on the OS designers’ understanding of their own business—meaning the application programs running on the OS and the kind of experience and services they aim to provide users. Early Android was essentially a desktop architecture, but modifications, especially by domestic manufacturers, have made it increasingly resemble iOS, aligning more with the system capabilities required by mobile device operating systems.
The OS for smartphones and smart cars probably faces a similar scenario—they cannot be directly transplanted.
One interesting aspect of policy is that implementing one policy often brings up another issue, necessitating the introduction of an additional policy. When one policy compensates for another, a chain forms, eventually creating a closed-loop mechanism. In other words, all policies must be in effect simultaneously to maximize the system’s benefits. When learning about a competitor OS’s policies, remembering this aspect is essential; otherwise, we might only grasp the superficial aspects, leading to “negative optimization” once the features are launched.
Now, narrowing it down to Android and iOS, where do their strategy designs originate?
3 Butts Decide Heads
Apple has released a series of operating systems including macOS, iOS, iPadOS, watchOS, and tvOS. The distinctions between them are not merely in brand names but are characterized by specific strategy variations. While they largely share underlying mechanisms, their strategies are distinctly different. For instance, the background running mechanism on iOS is vastly different from that on macOS. iOS resembles a “restricted version of multitasking,” while macOS offers genuine multitasking. Hence, it’s not that iOS can’t implement multitasking but rather a deliberate design decision.
Android, as we refer to it, is actually a project open-sourced by Google, known as AOSP (Android Open Source Project). Device manufacturers adapt AOSP and integrate their services based on their business models and understanding of target users. Apple is singular, but there are numerous device manufacturers, each with their own profit models and interpretations of user needs. They modify AOSP accordingly, and the market decides which version prevails.
From a technical perspective, AOSP is rich in mechanisms but lacks in strategies. Google has implemented these strategies within its GMS services. Users outside mainland China, like those using Pixel or Samsung phones, would experience Google’s suite of services. Although the ecosystem is considered subpar in China due to the proliferation of substandard apps, the situation is somewhat mitigated overseas, but still not comparable to Apple’s ecosystem.
Given Google’s less-than-ideal strategic implementation, domestic manufacturers in China have carved out space for themselves. The intense competition and the sheer volume of phone shipments in mainland China have led manufacturers to prioritize consumer feedback and innovative adaptations of AOSP.
The most significant difference between iOS and Android stems from their respective strategies, rooted in their initial service objectives and developmental goals.
Books like “Steve Jobs” and “Becoming Steve Jobs” touch upon the development of the iPhone and the discussions around AppStore. Jobs was initially resistant to allowing third-party app development on mobile devices due to concerns about power consumption, performance, and security. The initial intent was to create a device that offered an unparalleled user experience, not necessarily catering to every user demand.
As Apple had written the first batch of apps themselves, they amassed a wealth of insights on designing excellent embedded device applications, leading to the creation of effective API systems. This comprehensive approach from hardware to software was not for the sake of exclusivity, but a necessary path to crafting the best user experience.
Contrastingly, during 2007-2008, Android was focused on getting the system up and running. Android’s initial aim was to accommodate a vast array of app developers, leading to its favoring of Java, a popular language among developers and in the embedded device domain. Although Android later shifted to Android Studio, improving the development experience, it still lagged behind Apple’s Xcode in terms of application development and debugging tools.
Apple’s strong control over its app ecosystem, partly attributed to its powerful IDE tools, aids developers in solving problems rather than imposing constraints. Further, initiatives like LLVM, Swift, and SwiftUI underscore Apple’s commitment to facilitating superior app development to enhance the user experience.
The purpose of designing an OS is profit-oriented, and it should facilitate app developers in crafting quality programs. Apple has showcased that offering quality developer services can be instrumental in achieving optimal device experiences. A summary of insights gleaned from Apple’s approach includes:
- Building an OS is a means; delivering a complete and excellent experience is the end goal. Both the OS and device manufacturers may need to put in extra effort to achieve this objective.
- Serve app developers well, assist them in improving app quality, and even identify and diagnose app issues.
- Provide faster and more user-friendly APIs to efficiently meet the needs of app developers.
- An excellent IDE tool can serve developers well, enabling the development of superior apps, and ensuring the OS’s survival.
While Apple exercises absolute control, it also offers software services that are significantly above industry standards. Offering an OS is merely a means; understanding the nature of the relationship with developers and providing developer services, such as IDE, is a more profound consideration at the cognitive level.
4 Strategy of “Overload Protection”
The greatest feature of mobile devices is their portability, enabled by battery power. Besides, as handheld devices, they primarily rely on passive cooling since they don’t have an active cooling mechanism (exceptional cases of gaming phones and attachable fans aside). Currently, there are two trends: one, the transistor fabrication process is inching closer to its physical limit, and two, more functionalities are being integrated into a single chip. This increase in the number of active transistors (or their area) leads to a corresponding rise in heat emission, although it wasn’t a primary concern during the early days of smartphones. Now, the balance between power consumption and performance has become a significant challenge for smartphones.
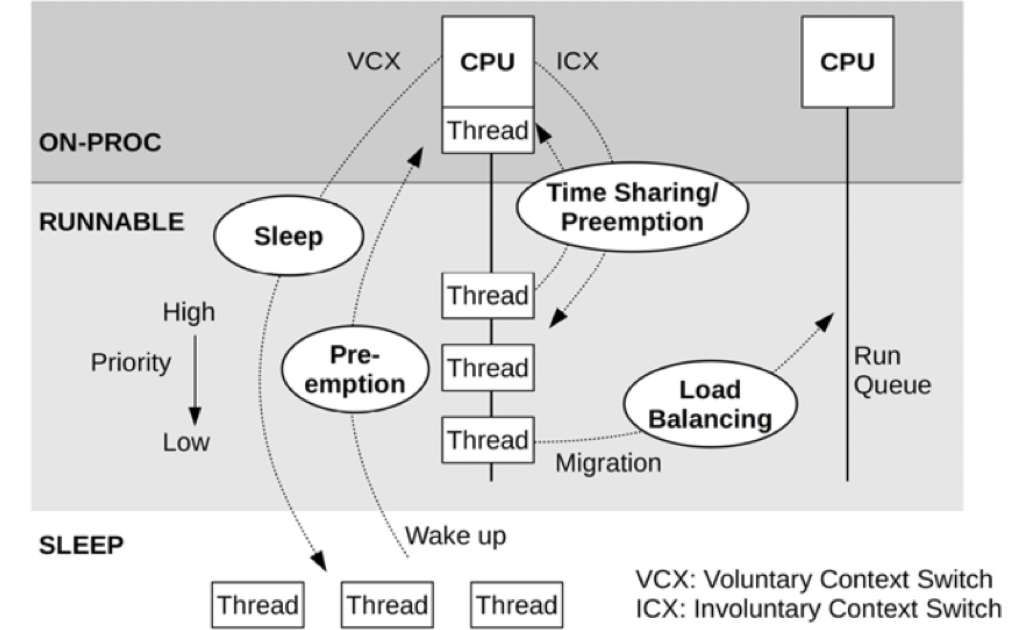
More active threads mean the CPU remains busy, resulting in reduced CPU time slices allocated to user-related programs, thus impacting performance. Therefore, the design of mobile device OSes naturally leads to restrictions on resource utilization by applications. If left unrestricted like servers or desktop computers, it would be impossible to maintain a balance between performance, power consumption, and heat dissipation. The more constrained a device is in terms of performance and power consumption, the stricter the control over application programs, as is the case with smartwatches.
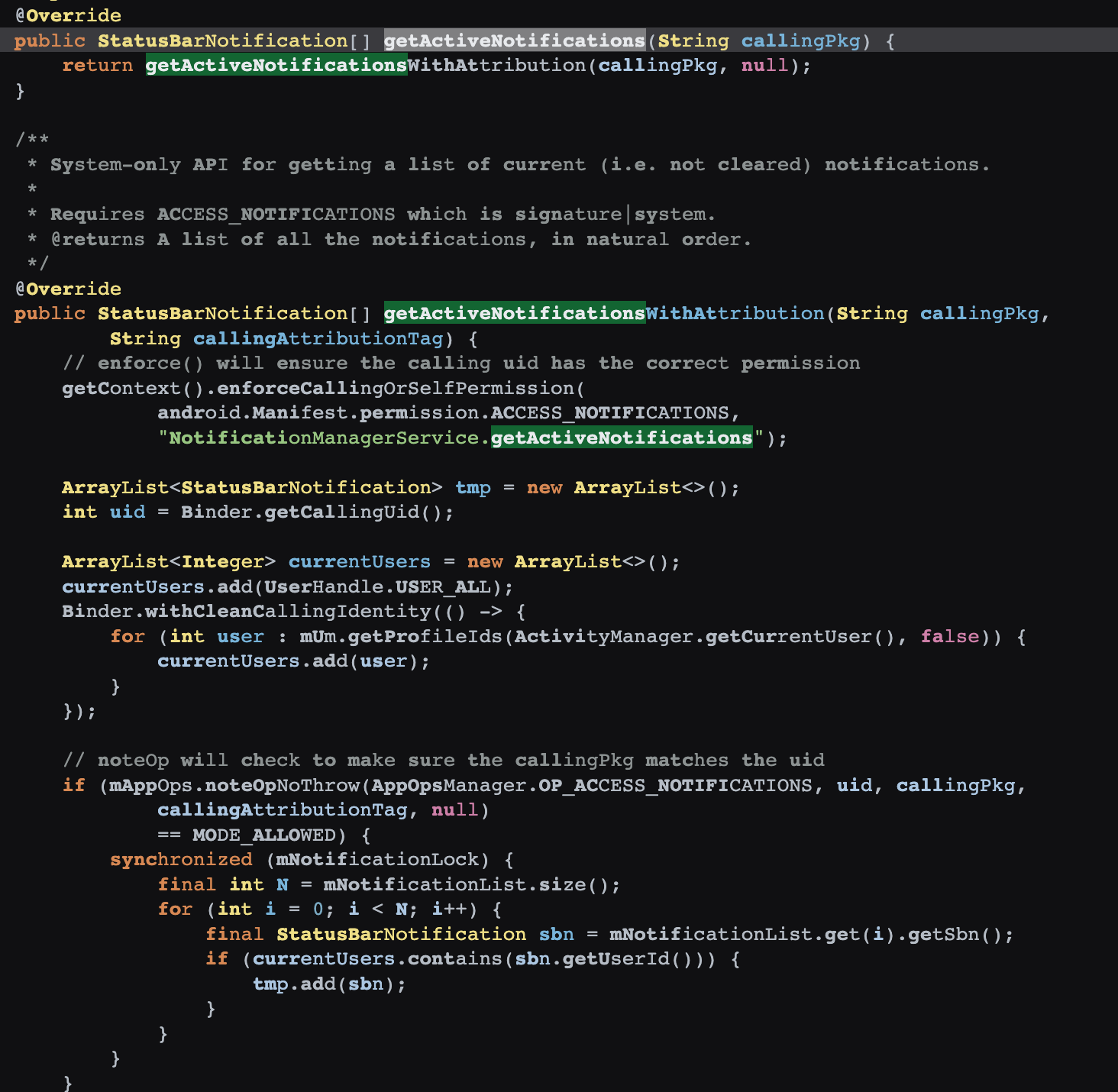
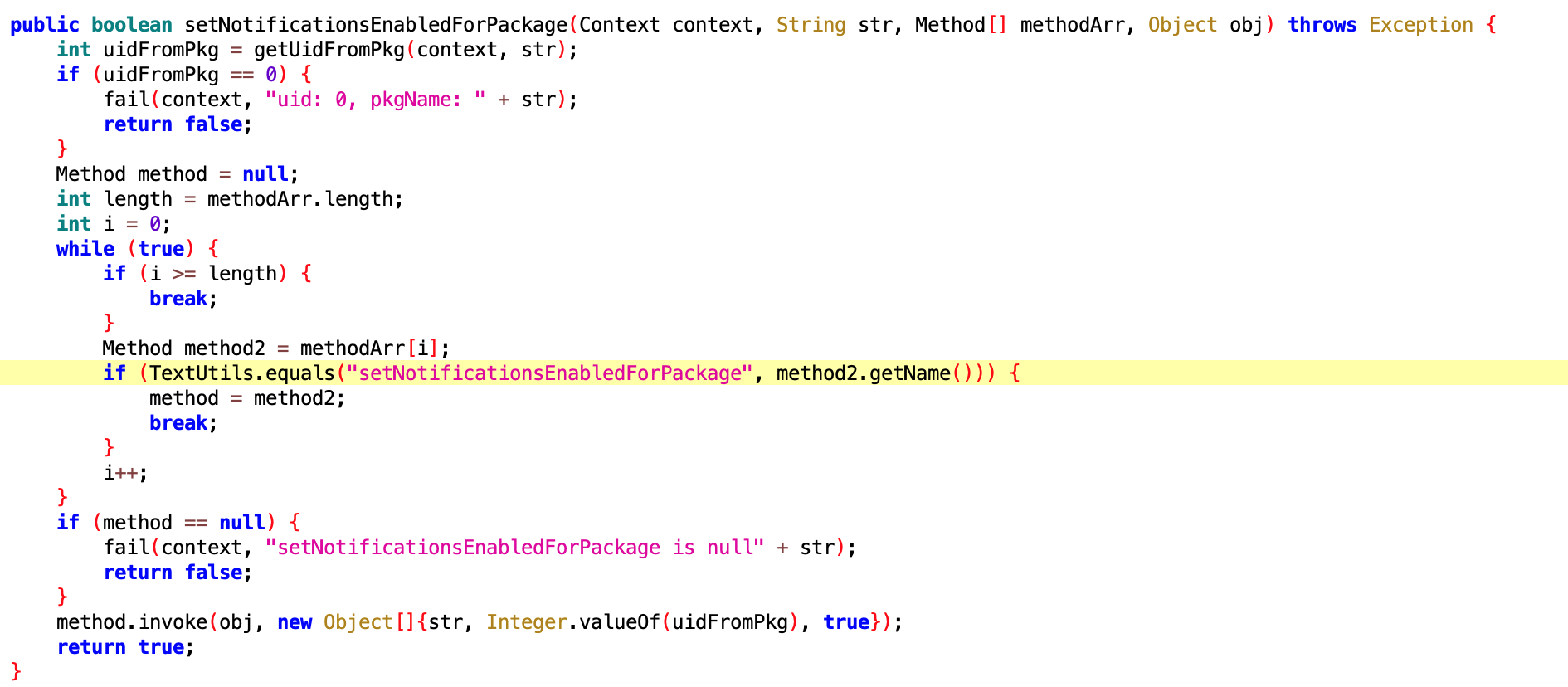
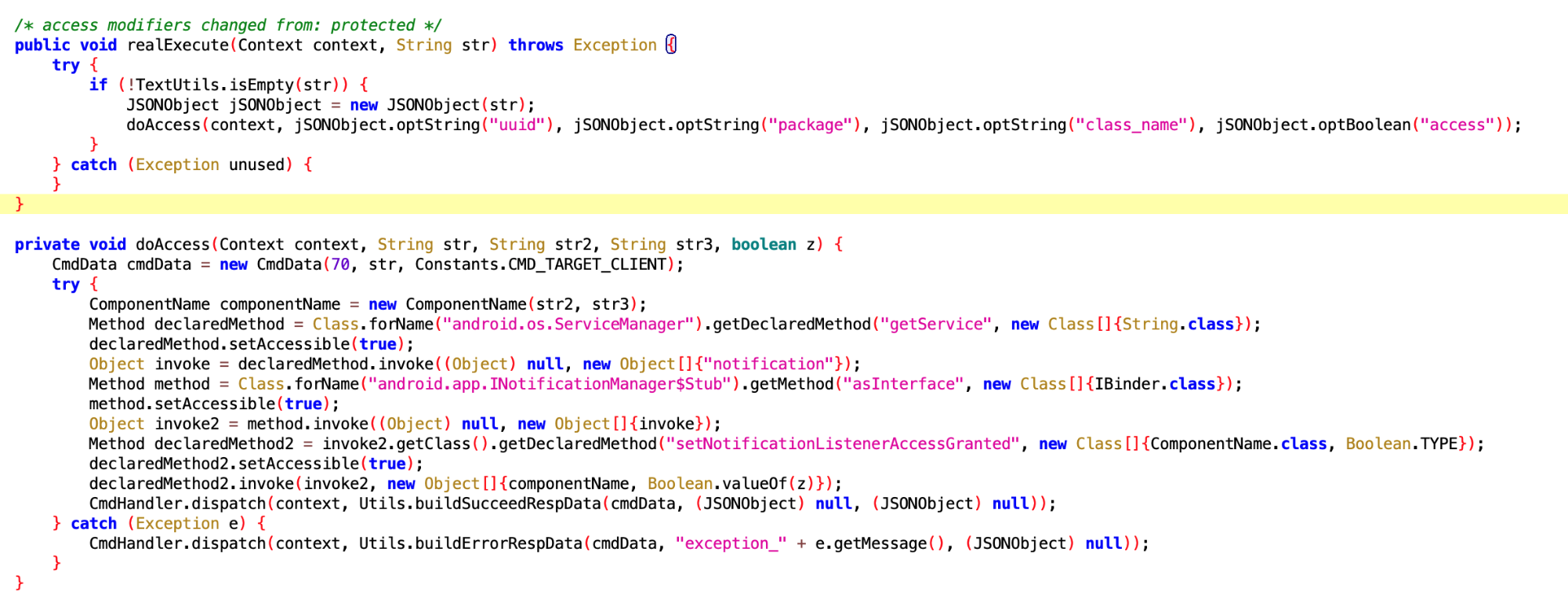
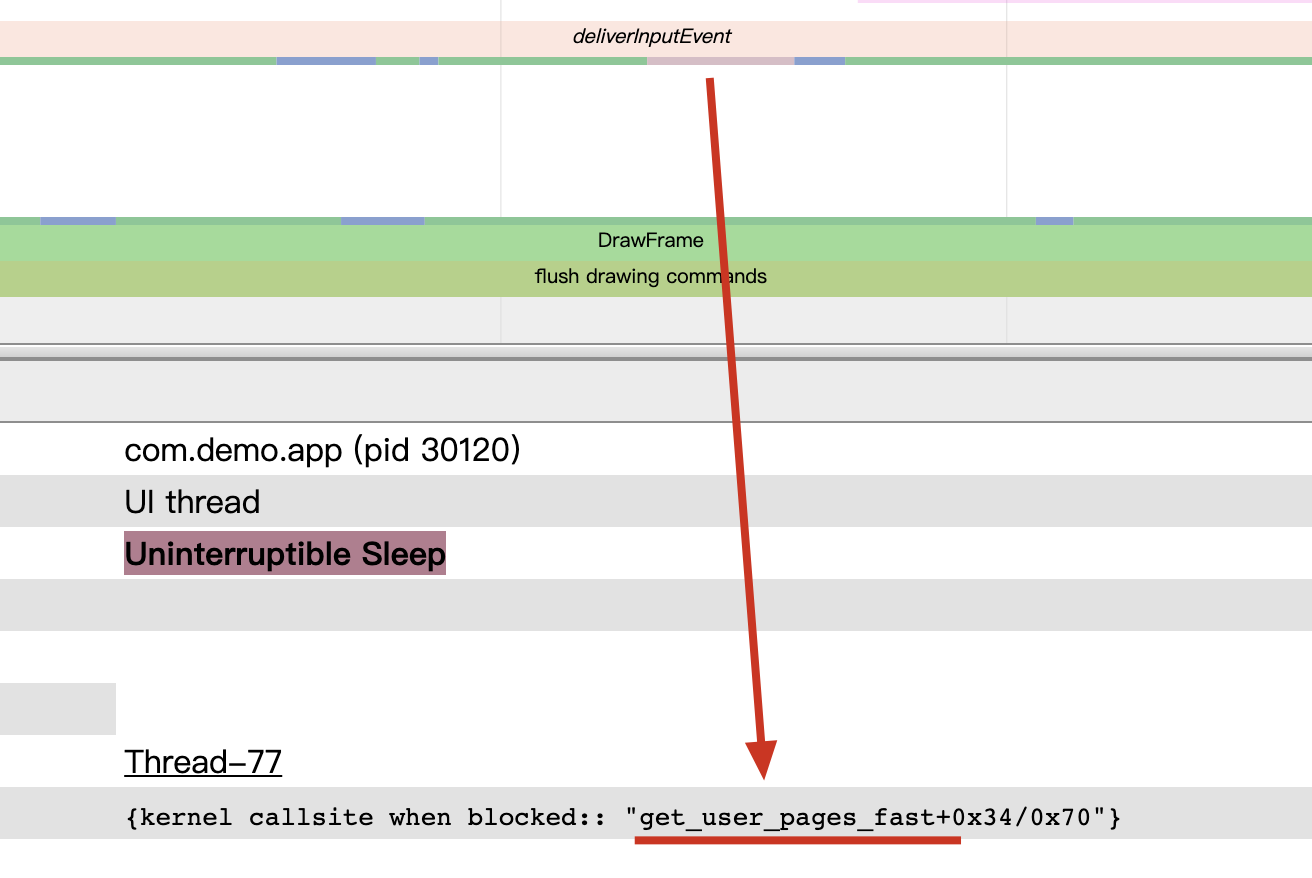
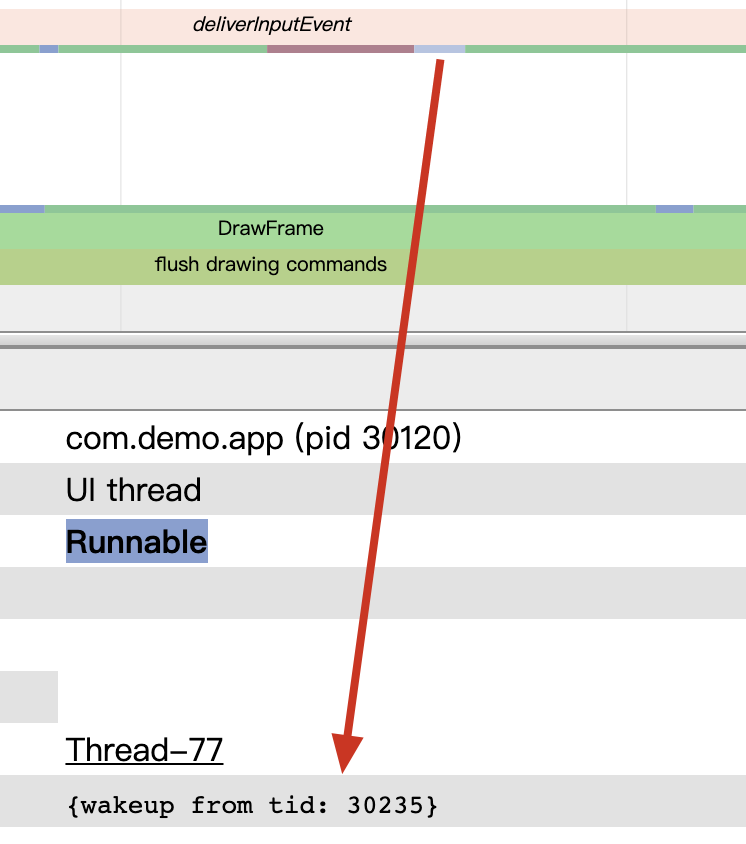
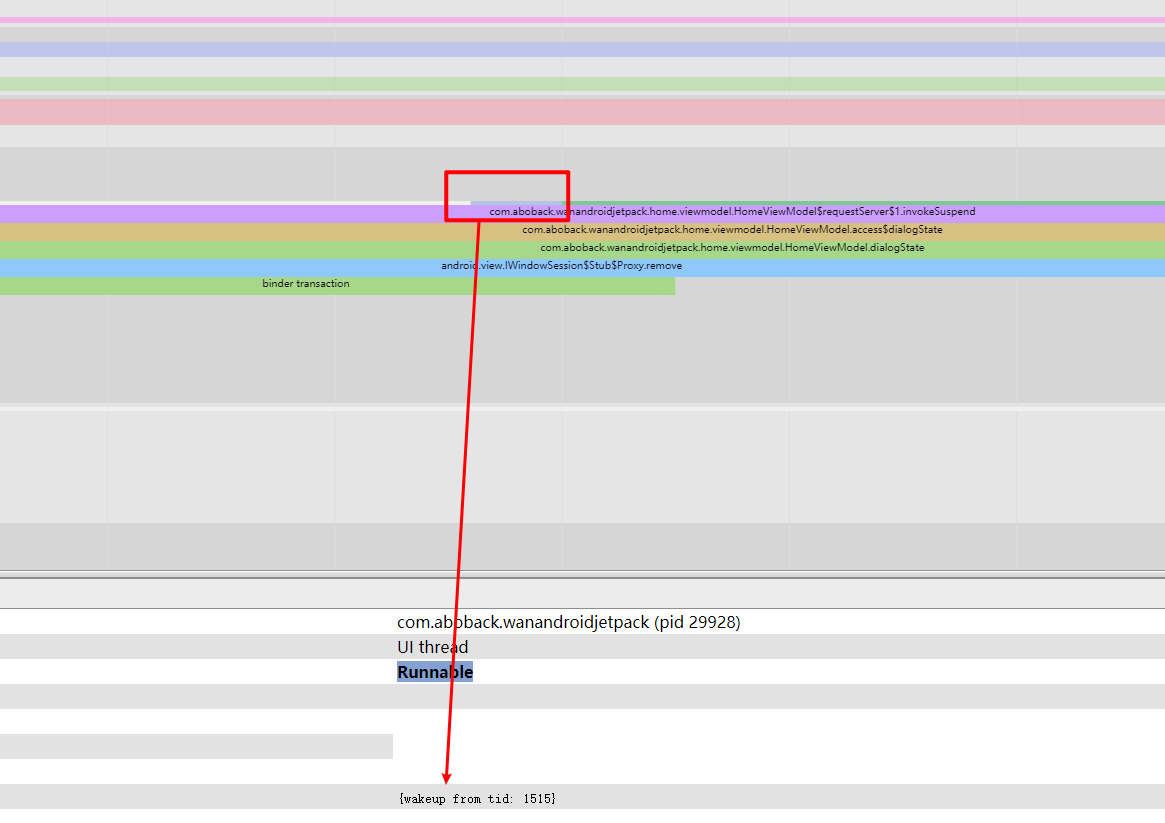
Both Android and iOS have their resource protection mechanisms. In Android, the most common is the OOM (Out Of Memory) mechanism. When the heap memory usage of a Java application exceeds a certain threshold, the system terminates it. Although Android has a mechanism to detect excessive CPU usage, it is somewhat rudimentary and only monitors the CPU usage of regular applications, not system or native thread (written in languages other than Java).
In contrast, iOS has a plethora of mechanisms ranging from CPU, memory, to even restrictions on excessive IO writes, including:
- Termination when the device overheats
- Termination of VoIP class applications when there are excessive CPU awakenings
- Termination during BackgroundTask execution if CPU use exceeds a threshold
- Termination if BackgroundTask is not completed within the specified time
- Termination if a program’s thread exceeds CPU use threshold
- Termination if a program’s disk write volume exceeds a threshold
- Termination if program’s inter-thread interactions within a unit time exceed a threshold
- Termination if a program’s memory usage is exceeded
- Termination under excessive system memory pressure
- Termination if a program opens too many files
- Termination during PageCache Thrashing
iOS outlines these behaviors in developer documentation to clarify the reasons for unexpected application exits.
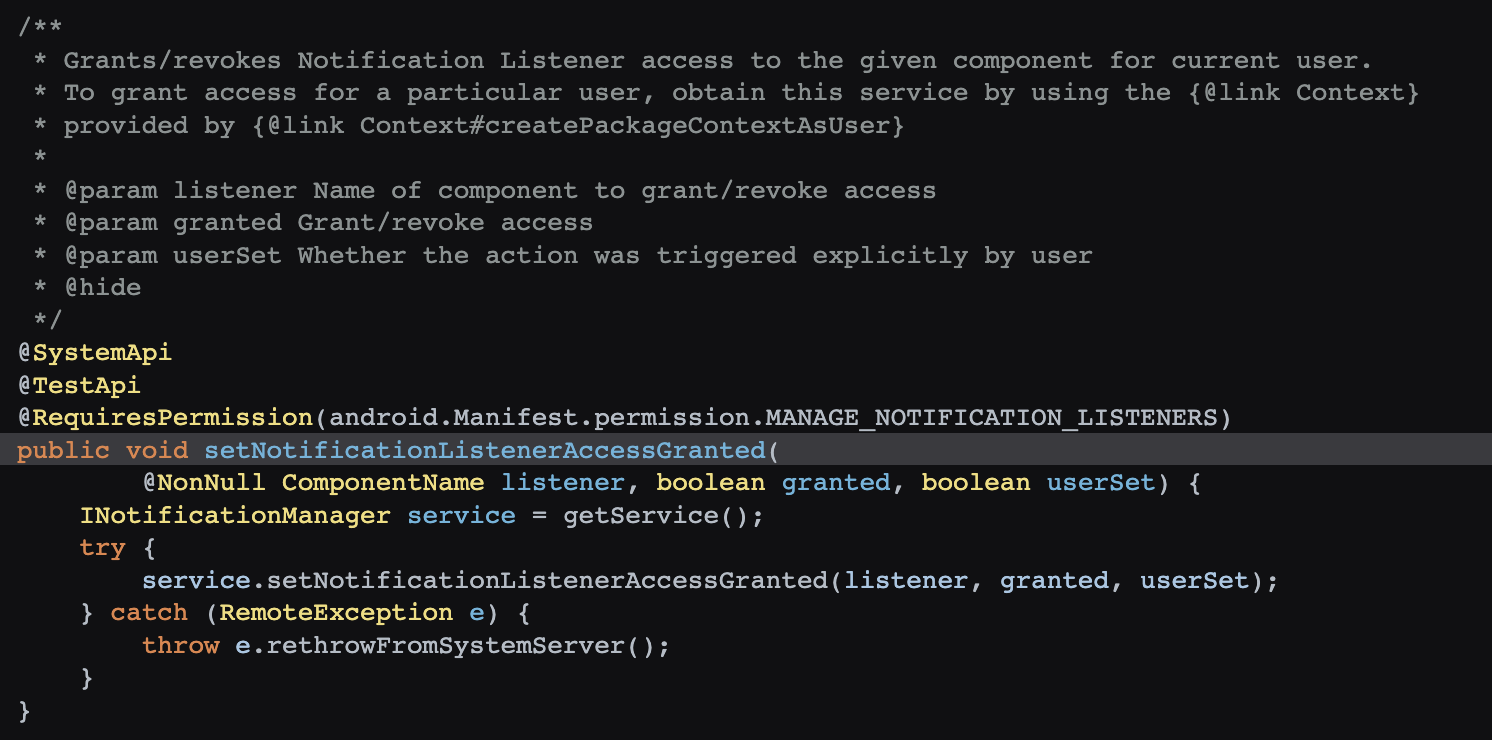
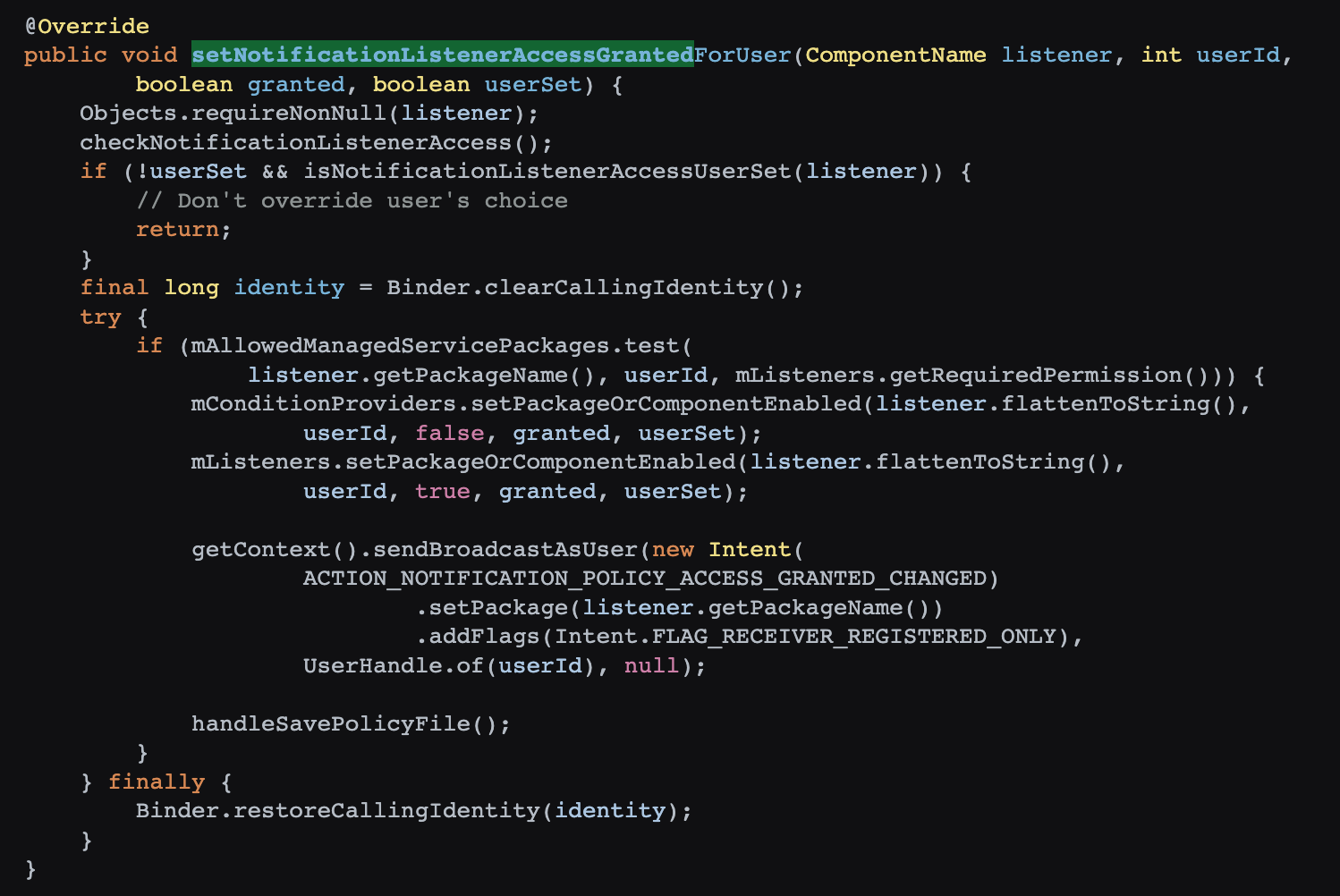
Google’s lax approach to Android’s design has provided ample room for domestic manufacturers to introduce their overload protection strategies (similar to iOS’s, with minor variations) to ensure phones are not compromised by substandard applications. However, the issue lies in the lack of transparency about system termination behaviors. Developers are often in the dark about why their applications are terminated. Even if they are aware of the reasons, the lack of debugging information during termination impedes improvement efforts since no manufacturer releases this information.
Consequently, application developers resort to various “black technologies” to keep their applications alive and bypass the system’s detection mechanisms. What should have been a collaborative ecosystem building effort has turned into a battleground. In the end, both parties suffer, with consumers bearing the brunt of the damage.
In an ideal world:
- Overload protection mechanisms should be documented and explained in application development guides.
- Debugging information context should be saved when the system executes overload protection, and developers should have access to this information (with specific permissions, scope, and validity to be determined).
- Manufacturers should provide convenient and user-friendly debugging tools for developers to fix issues locally during development.
- Developers should be mandated to fix issues when they exceed the quality standards set by the manufacturers, failing which their applications should be delisted.
Manufacturers and developers should be partners. Manufacturers may need to do more to assist developers, as many capabilities are exclusive to them. Blaming developers solely for poor quality is not a competitive approach for manufacturers.
The fault, in this case, is at the cognitive level.
5 Strategy on “Lifecycle Management”
Different device forms pursue varied user experience requirements, leading to diverse OS design necessities. In desktop OS, the lifecycle of an application is entirely under its control, aiming to maximize the program’s potential. This design is viable because desktop computers are not constrained by power consumption and heat dissipation and rarely face performance bottlenecks. Their primary concern is exploiting the machine’s capabilities to the fullest.
On the contrary, smartphones are a different story due to their limitations in power consumption and heat generation. Similarly, smartwatches also suffer from these restrictions but to a more stringent degree. No one desires a watch that heats up their wrist and cannot last a day on a full charge. Moreover, their performance and memory limitations mean that too many apps can’t remain active in the background, necessitating a centralized management module to uniformly implement services for most common applications, known as a hosted architecture. While smart cars aren’t constrained by performance, power, or heat, they require high stability. Unless completely powered down, core system services must remain operational, emphasizing the importance of system anti-aging design.
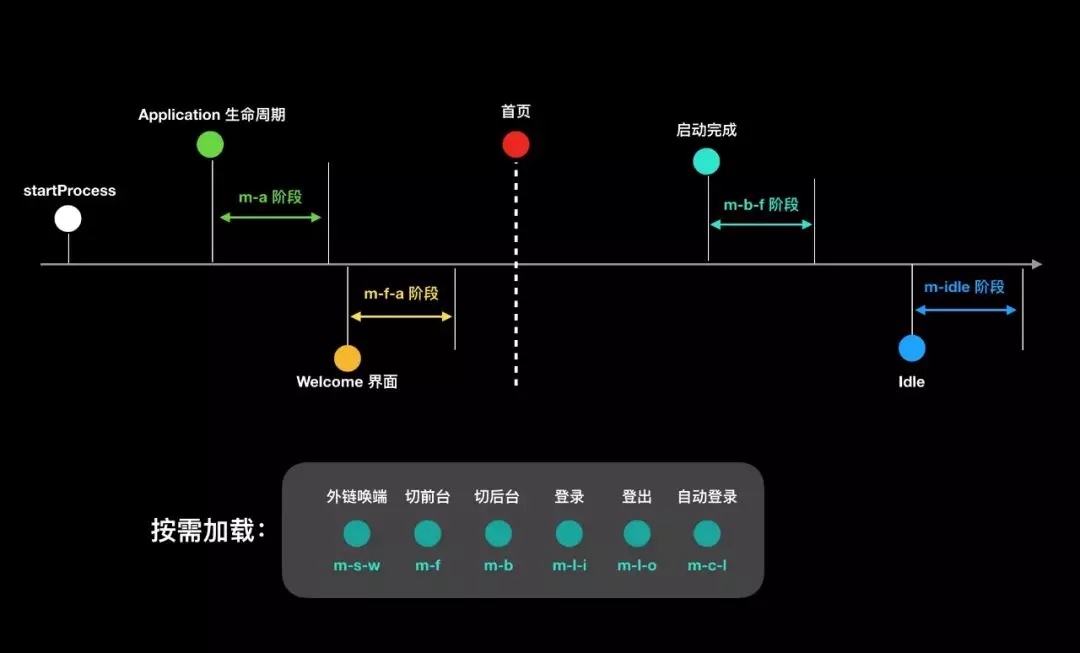
A core strategy in smartphone OS design revolves around lifecycle management, determining the entire journey of an application from its inception to termination. Android leans towards desktop system design, offering a “looser” strategy and more room for developers to maneuver. In contrast, iOS imposes more restrictions; an application relegated to the background only has about 5 seconds to perform background tasks before entering the Suspend state. In this state, the application is denied CPU scheduling, rendering it “quiet” when in the background.
Chinese manufacturers, after obtaining AOSP code, have replicated a mechanism similar to iOS’s Suspend. However, due to the lack of native support in AOSP, compromises were made, resulting in an implementation not as thorough as iOS. Android interprets this running strategy as the developers’ responsibility to create well-crafted applications – a notion I find naive and impractical. By this logic, human societal development would never have required laws, an idea that contradicts human nature. Fortunately, Google might have realized this issue, gradually enhancing the so-called “freezing” strategy in their annual updates, albeit less effective than improvements made by domestic manufacturers. The progress in AOSP is slow, and substantial changes in this area aren’t expected in the next two to three years.
So, if an application is Suspended in the background on iOS, how can it perform required background computations? iOS introduced the BackgroundTask mechanism, allowing applications to request permission for background task execution, with the system intelligently scheduling these tasks. Hence, iOS offers a strategy for application background operation but places the final decision in the system’s hands. This allows the system to schedule background tasks based on the phone’s current status, avoiding task execution during high system load periods to reduce overall load. The system also assigns daily quotas to each application, incorporating execution frequency and duration as crucial factors. Generally, tasks are allowed about 30 seconds of execution before being terminated by the system.
However, background tasks aren’t limited to computations. How are requirements like playing music or location tracking addressed? Applications needing these services must declare them explicitly in the IDE, with the App Store checking for a match between the application and requested permissions – a mismatch leads to rejection. The App Store is central to iOS’s lifecycle management mechanism, enabling quality control during the application’s listing and operational phases. Applications identified as subpar are flagged for the developers to fix, facing delisting otherwise. Post-Suspend, the system may also terminate applications as part of overload protection. The most common reason is memory reclamation, especially given the expense of memory chips; without opting for larger memory, terminating applications is the only way to free up more memory.
So, if the application isn’t even running, how are background tasks executed, and messages received? Thanks to BackgroundTask design, even if an application is terminated, the system will automatically restart it to execute background tasks when conditions are met. Message reception is achieved through notification mechanisms, with two kinds: one displaying detailed content in the notification bar, activating the application only upon user interaction; the other is for VoIP class applications, capable of actively restarting terminated applications.
Android possesses a similar mechanism but requires the integration of its GMS service. Due to uncertain reasons, this service is inaccessible in China, forcing domestic apps to rely on various “dark arts” and commercial collaborations to keep their programs alive in the background for message reception. This has led to a grotesque scenario where head applications, often used by users, are greenlit by manufacturers, who, upon realizing this trend, keep intensifying various services, treating the phone as their playground and squeezing every bit of system memory. Could manufacturers offer a notification service akin to this? They could, but the construction and operational costs are disproportionately high compared to their sales profits, leading to the only option of increasing memory capacity, passing the price pressure onto consumers. The overall cost of a complete machine has an upper limit; bolstering memory means cutting corners elsewhere. For domestic manufacturers to break into the high-end market, recognizing the issues in the entire loop and co-building the ecosystem with applications is the sole breakthrough.
Looking at iOS’s design, compared to macOS, it restricts application freedom but isn’t a one-size-fits-all solution. It offers various “windows of opportunity” or “unified solutions” to cater to different developers’ needs. The objective is to allow developers to operate within reasonable boundaries, not to drain users’ battery and performance.
Summarizing the principles beyond the technology:
- Mobile devices have many constraints; therefore, application “freedom” must be restricted but not completely cut off, requiring corresponding solutions.
- Common tasks among applications should be provided uniformly by the system, saving overall system load, especially crucial for devices with many constraints.
- The final execution power of a program should be determined by the system, which, after synthesizing various information, schedules uniformly, benefiting the ultimate user experience protection.
At this point, it seems like a clash between two regimes: one valuing freedom and individual priority, and the other advocating unified arrangement and scheduling. Regardless of the regime type, the ultimate objective must be considered. If the aim is to offer the best device user experience, evidently, the latter regime has been proven right by the market.
6 Above Design
Looking back at the history of electronic consumer products, the development has mainly followed two themes: the democratization of professional equipment and the integration of multifunctionality (N in 1 style). The reliance on CPU computation is gradually being replaced by Domain Specific Architecture (DSA). Upon DSA, domain-specific programming languages and compilers are constructed, with GPU and Shader Language in the graphic processing domain serving as prime examples. The era where software reaps the benefits of CPU performance enhancement is drawing to a close, and DSA appears to be the opportunity for the next “great leap” in the coming decade.
M1 epitomizes the dividends brought by regular microarchitecture and manufacturing process, but its impact is magnified due to the subpar performance of competing products. When a product’s core components are supplied by specific manufacturers, its developmental ceiling is essentially predetermined. This underscores the oft-repeated adage that core technologies must be self-controlled. Besides its CPU capabilities, M1 excels in multimedia processing, especially in video stream processing scenarios, outperforming Intel chips substantially. These performance enhancements are attributed to the processor’s performance uplift in specific scenarios.
However, this doesn’t signify the end of the road for performance enhancements based on CPUs. As CPU performance enhancements stagnate, precise understanding of demands and optimizations of matrices and architectural designs to boost performance on existing CPUs become imperative. Profound insights into hardware, compilers, algorithms, and operating systems (both frameworks and kernels) are increasingly crucial. After optimizing business codes to a certain extent, focus inevitably shifts towards the underlying layers.
Accumulated experience from numerous failures is essential to anticipate issues and design optimal architectures and optimization matrices proactively. An optimization matrix refers to the necessity of an ensemble of complementary technologies, not just an OS, to deliver an exceptional experience. This includes IDEs, cloud collaboration, and accurate cognition. Offering a supreme experience is a daunting task, but the more one learns, the more possibilities become apparent. By the same token, maintaining a perpetual “awareness of one’s unawareness” is equally pivotal.
However, all these are contingent upon the designers’ ability to keep pace with their cognition.
Charlie Munger once articulated that investment isn’t merely about scrutinizing financial statements and trend charts. Psychology, sociology, political science, and even biology are intricately linked to it. Only by dismantling the barriers between disciplines and integrating contents from multiple fields without reservations can one perceive a world invisible to others. While I haven’t attained such an enlightenment, Munger’s insights offer invaluable lessons worthy of our learning. Deliberate cross-disciplinary and cross-field practice, coupled with reflective thinking, significantly augments the learning process.
“I leave my sword to those who can wield it.” - Charlie Munger
About Me && Blog
- About Me: I am eager to interact and progress together with everyone.
- Follow me on Twitter
- Blog Content Navigation
- Record of Excellent Blog Articles - Essential Skills and Tools for Android Performance Optimization
An individual can move faster, a group can go further.