I Dug Up the Biggest Files on My Linux PC, Here's What I Found
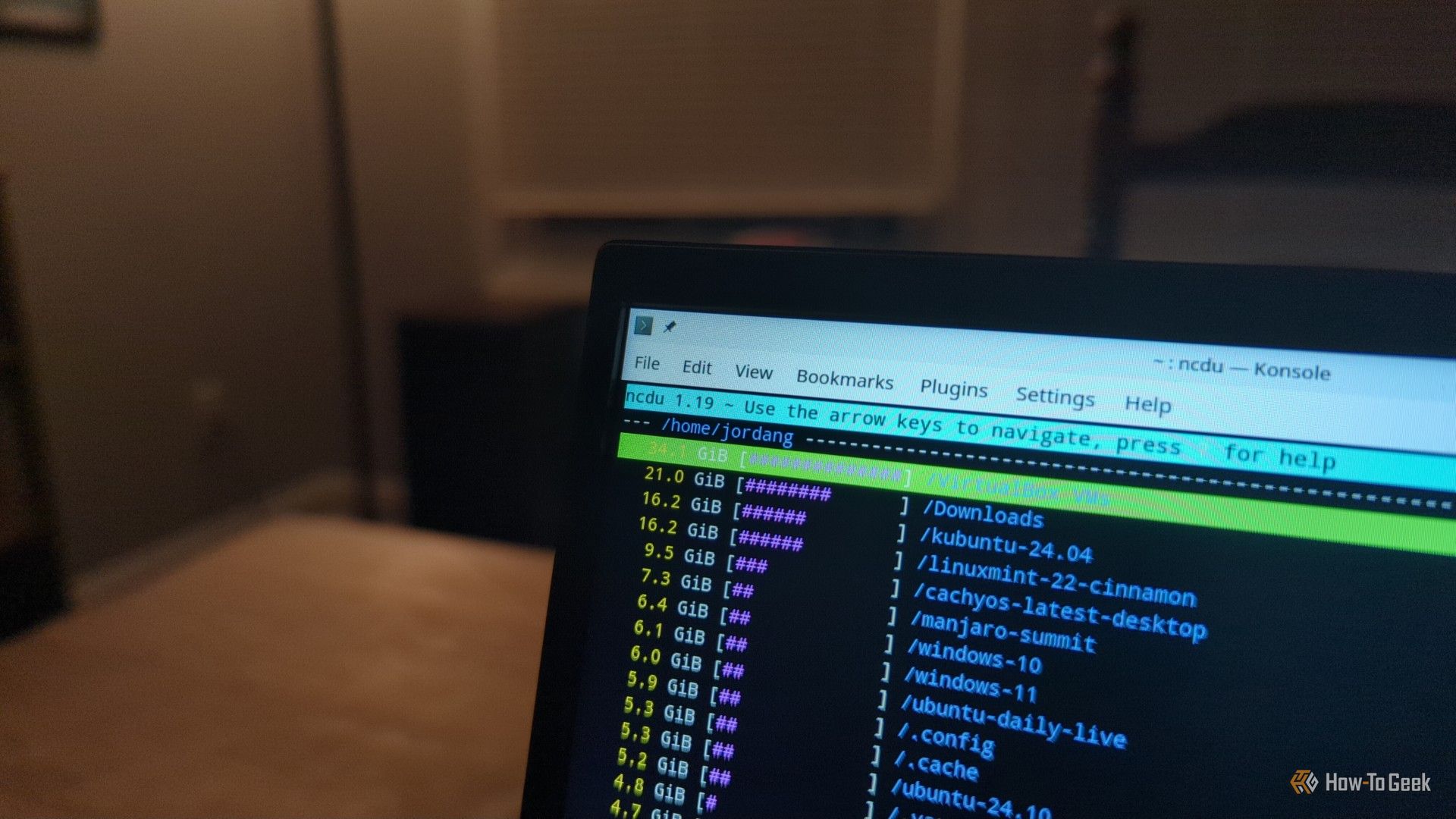
I can't be alone in noticing how, no matter how much storage I buy for my computer, digital refuse always piles up. Fortunately for me, on Linux, there's a simple terminal command that let me easily drag up the heftiest files. I wasn't too proud of the results.