Paxos 本身以晦涩难懂而闻名,更不要说对它的优化了。为了破除大家心中的阴影,UCB 的几个大佬在 Journal of Systems Research 期刊上发表了 SoK: A Generalized Multi-Leader State Machine Replication Tutorial 的论文。这篇文章也是我对这篇论文的阅读笔记了。
https://mwhittaker.github.io/frankenpaxos/ 有不同 Paxos 算法的动画演示。
概览
自从 Lamport 老爷子提出 Paxos 算法以来,许多工程师和学者都投入到对这个算法的实现和改进的工作中。首先最经典的就是将单个 Paxos 算法扩展到分布式状态机复制的 MultiPaxos 还有尝试让 MultiPaxos 变得更加易懂、易实现,将其中细节问题讲清楚的 Raft 算法。他们的特点都是将上层应用的状态视为状态机,共识算法则负责决定这个状态机执行的日志。将状态变更组织成日志的好处是实现简单,但是显而易见的会有性能问题。例如在 Raft 中,日志不允许存在空洞,日志后面的命令需要等到日志前面的日志提交后自己才能提交。例如,两个用户分别更新自己的用户名,两个操作执行的顺序其实并无要求,谁先修改成功都可以,只要所有副本都保证最后的结果一致即可。而日志则强行为两个并发的操作规定了一个全序,将操作串行化了。尽管可以通过 Sharding 的方式来一定程度上缓解串行化执行的问题,但是在一个 Shard 内的操作仍然是有全序的。
Lamport 自己也意识到了这个问题,提出了泛化的 Paxos 算法,也就是 GPaxos。它的思想也很简单,既然日志强行施加了一个全序,那么我们想办法以一种偏序的方法表达操作即可。也就是说,现在需要共识的不是一个线性的日志了,而是一个可以有依赖关系的有向图。在这个有向图中(为什么允许有环在后面讲),顶点就是需要执行的操作,而如果一个操作 b 依赖另一个操作 a,那么就有一条从 b 指向 a 的有向边。很显然,我们只需要按照这个图的逆拓扑序执行操作就可以了,两个没有依赖关系的顶点可以并发执行。
但是,上面提到的算法,都有一个瓶颈:它们实际上都有一个 Leader 节点。Leader 节点负责所有的请求,而且比其他的节点要收发多得多的信息。尽管我们也可以用 Sharding 的方式来缓解 Leader 的热点问题,但是同样的,对于一个 Shard 内部 Leader 还是有可能成为瓶颈。所以大家就开始在泛化的 Paxos 算法基础上去研究多 Leader 的算法。
多 Leader 算法中,不同的节点互相都是平等的,客户端的请求可以随便发往任意一个节点处理,而且那个节点可以自己处理请求,而不是将请求转发到别的节点去执行。
消除了 Leader 节点的瓶颈问题之后,还有一个问题需要解决,那就是请求的延迟问题。在普通的 Paxos 算法中,需要 7 次 RPC 消息延迟才能提交一个操作,显然这个延迟有点太高了。Lamport 老爷子依然神机妙算,提出了 Fast Paxos 算法,在没有冲突的情况下只需要 4 次 RPC 消息延迟就可以提交一个操作。考虑到最理想的情况下也还需要 2 次 RPC 消息延迟才能提交客户端的操作,4 次相比于 7 次已经是一个很可观的改进了。
当然,在多 Leader 的情况下,冲突的可能性更大,而且 Fast Paxos 对于泛化的 Paxos 没有进一步说明,如何将这个快速提交的算法应用到多 Leader 的泛化的 Paxos 算法,就是更进一步的挑战了。
这篇论文从基本的 MultiPaxos 算法出发,按照上面说的思路一步步地去改进基本的算法,通过对比差异之处,来试图给读者一个更清晰的印象,让读者更好地理解不同的算法的优化点是怎么提出来的。文章里没有希腊字母,可以放心食用。
基本 Paxos 算法

在基本的 Paxos 算法中,Phase 1 用来确认是否已经有值被大多数的 Acceptor 接受过,Phase 2 则用来通知 Acceptor 接受值。这个只是针对一个值的共识算法。如果将不同操作视为不同的值,那么就可以引出 MultiPaxos 算法了。我们都知道,假如需要容忍 $f$ 个进程发生故障,那么需要至少 $2f+1$ 个节点,这样才能保证故障前和故障后的大多数有交集,从而避免不一致的情况发生。
MultiPaxos 算法
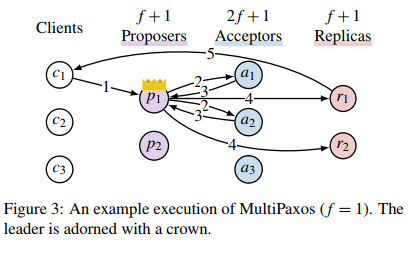
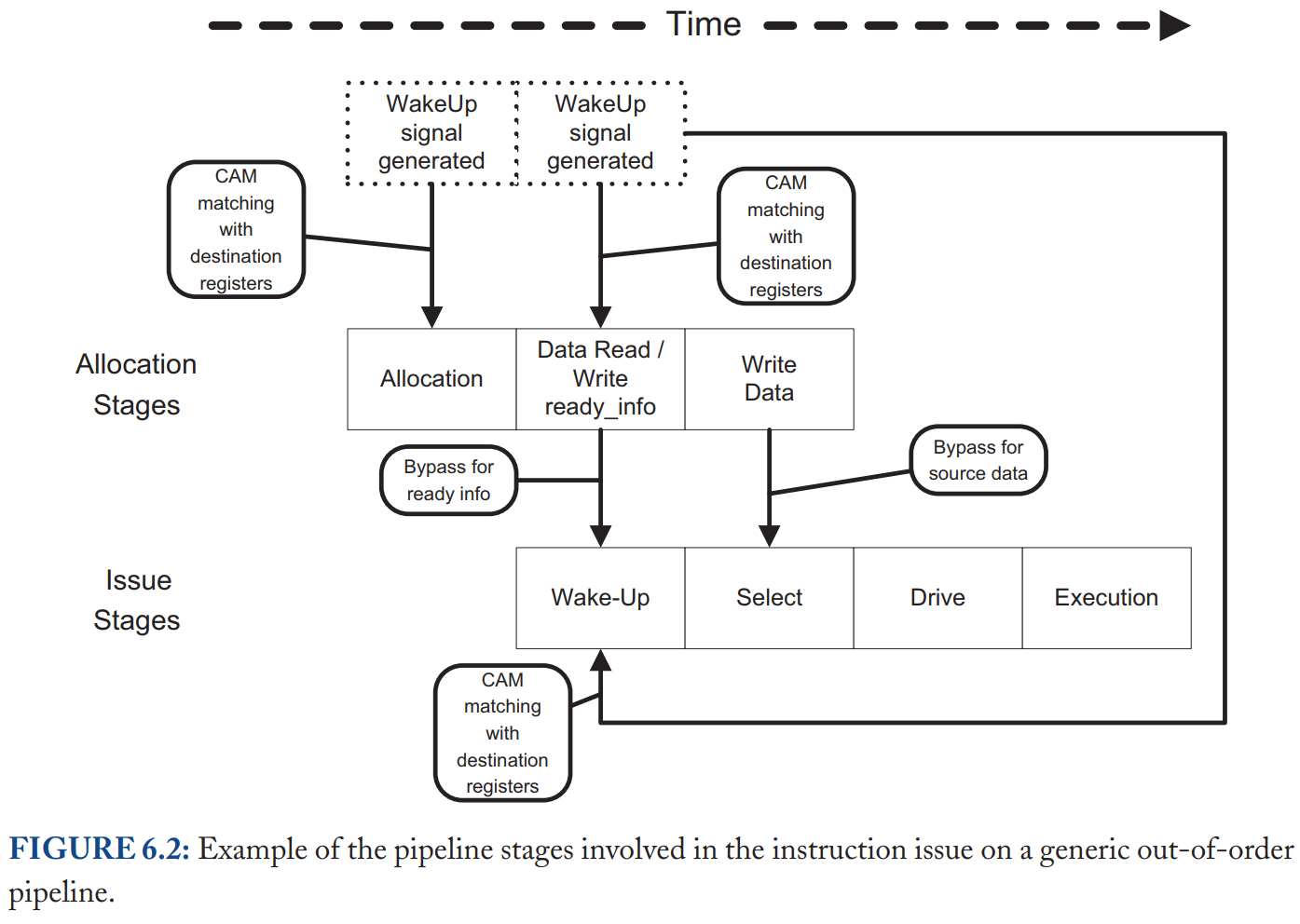
如上图所示,MultiPaxos 首先通过 Leader 选举算法在 $f+1$ 个 Proposer 中选出一个 Leader,选举完成后,Leader 对之前每一个日志项执行一次 Paxos 的 Phase 1,之后这个 Leader 负责所有客户端的交互。Leader 在收到客户端的操作命令之后,确定一个日志编号 $i$,直接执行 Phase 2 进行共识。在收到大多数的 Acceptor 的确认之后,Proposer 就可以确定这个日志项的值了,并将这个日志项发送到 Replica 中执行,Replica 执行完成后通知客户端。当然这里的 Proposer、Accpetor 和 Replica 并不是真的都是独立的进程,可以理解为他们是一个服务进程里的不同线程。可以看到 Leader 需要处理所有的客户端请求,而且 Leader 一共需要收发 7 次消息,而其他进程只需要最多收发 2 次消息,显然 Leader 会成为系统的瓶颈。另外,日志也应该是连续的,Replica 是以一个操作日志的前缀执行操作的,这就使得不同的操作串行化了。
冲突图
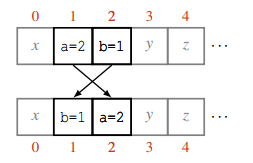
实际上,真实的应用场景中,很多操作都是可以并发执行的,不关心执行顺序,而只有一些操作需要规定严格的依赖关系。为了能最大化执行效率,我们需要定义哪些操作之间是可以并发执行的,哪些是不可以的,也就是冲突的。从日志角度来看,如果两个操作交换了顺序执行,而不影响最终的状态的话,那么这两个操作就是不冲突的,否则就是冲突的。例如,对于不同变量的赋值是没有冲突的,可以并发执行,而那些依赖于赋值后变量的值的操作就是冲突的,需要规定顺序执行。例如在图中,a=2 和 b=1 这两个操作就是可交换的,不冲突的,可以并发执行。而 b=a 如果被交换到 b=1 之前执行,那么最终 b 的值会变为 1,和原来 b 的值为 2 结果不一样,所以这两个操作是冲突的,不能并发执行,因为并发执行不能保证执行的顺序,有可能导致不同副本上的执行结果不一致。
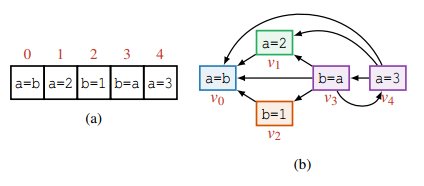
根据上面冲突的定义,可以画出一个执行日志对应的冲突图,图中的顶点就是日志中的操作,而顶点之间的有向边则代表了冲突关系。显然,我们可以以冲突图的任意一个逆拓扑序去执行操作。也就是说,对于不冲突的操作,我们可以并发执行。而如果想要往这个图中添加新的操作,需要检查这个新的操作和已有的所有操作是否冲突,是的话就添加一条边,保证执行的顺序不会错乱。
形式化一点来讲,图中的顶点为 $v$,那么它所依赖的顶点的集合就是 $\text{deps}(v)$。
有了冲突图的定义之后,就可以将普通的 Paxos 算法扩展为泛化 Paxos 算法了。泛化的 Paxos 算法需要满足共识不变式以及依赖不变式。
共识不变式很好理解,就是对于每一个顶点 $v$ ,最多只能够有一个值 $(x, \text{deps}(v))$,就如同 Raft 的日志中,一个日志项要么没有提交,一旦提交了所有节点都是同一个值。
而依赖不变式,则是形式化的描述了依赖图中的冲突关系。对于一个已经确定了值 $(x, \text{deps}(v_x))$ 的顶点 $v_x$ 和$(y, \text{deps}(v_y))$ 的顶点 $v_y$ ,如果 $x$ 和 $y$ 存在冲突,要么 $v_x \in \text{deps}(v_y)$ ,要么 $v_y \in \text{deps}(v_x)$,或者两者同时满足。前面两个都很好理解,因为节点新增的时间可能不同。但是为什么可以同时满足要等到后面实现细节才好理解。
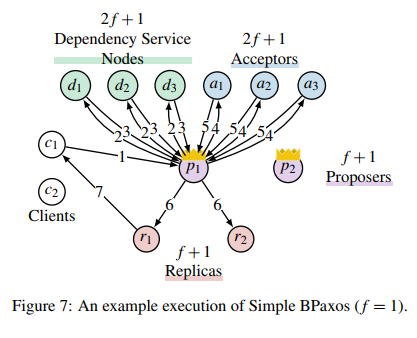
有了偏序定义之后,就可以开始对基本的 Paxos 的算法进行改进了。泛化的 Paxos 算法如上图所示,它和 MultiPaxos 最大的不同就是增加了 $2f+1$ 个 Dependency Service,这个就是用来计算依赖关系的节点。另外,在这个改进的算法中,不再有单一的一个 Leader,所有 Proposer 都可以处理客户端发送过来的操作命令。Acceptor 进行共识的是冲突图的顶点,而 Replica 执行的也不再是日志,而是上面提到的冲突图。相应地,处理客户端请求的步骤也变多了。这个算法处理请求的流程有 7 步:
- 客户端发送请求 $x$ 到任意一个 Proposer;
- Proposer 生成一个全局唯一的顶点 ID $v_x=(p_i, m)$,其中 $p_i$ 是进程的标识符,$m$ 是这个进程里单调递增的一个序列号。然后,将 $v_x$ 以及 $x$ 发送到所有的 Dependency Service;
- 依赖服务计算 $\text{deps}(x)$ 发回给 Proposer;
- 收到至少 $f+1$ 个回复后,Proposer 针对 ID 为 $v_x$ 的顶点发起一次 Paxos 共识算法,值就是操作以及依赖的顶点 $(x, \text{deps}(v_x))$。这里可以直接发起 Accept 请求的原因是因为这个顶点是刚刚生成的全局唯一的 ID,此时应该还没有别的进程发起过 Accept 请求,所以 Proposer 可以安全地发起任何值;
- Acceptor 发送回复;
- 当大多数确定了 $v_x$ 的值之后,Proposer 将确认的值 $(x, \text{deps}(v_x))$ 发送给 Replica 执行;
- Replica 执行操作后,回复客户端。
那么依赖服务如何计算一个操作的依赖呢?首先,每一个依赖服务节点 $d_i$ 都会保存一份无环的冲突图,当一个节点收到了 $x$ 和 $v_x$ 之后,如果检查发现冲突图中已经包含了 $v_x$,那么就不做任何操作,不改变冲突图,直接返回 $v_x$ 指向的所有节点的集合;否则,就将 $v_x$ 加入到冲突图,并检查所有其他的顶点 $v_y$,如果 $x$ 和 $y$ 冲突,就添加一条从 $v_x$ 指向 $v_y$ 的边。遍历完成后,同样返回 $v_x$ 指向的所有顶点的集合。
当 Proposer 收到至少 $f+1$ 个回复之后,取所有回复的并集作为顶点的依赖。例如,假设 $f=1$,$d_1$ 的回复是 $\left\{v_w, v_y\right\}$,$d_2$ 的回复是 $\left\{v_w, v_z\right\}$,那么 $\text{deps}(x)=\left\{v_w, v_y, v_z\right\}$。
经过这样的操作,就可以得到另外一个不变式:如果 $v_x$ 和 $v_y$ 中的操作 $x$ 和 $y$ 冲突了,并且依赖关系服务计算出了 $\text{deps}(x)$ 和 $\text{deps}(y)$,要么 $v_x \in \text{deps}(v_y)$ ,要么 $v_y \in \text{deps}(v_x)$,或者两者同时满足。这个和依赖不变式的不同在于,这个不变式的 $\text{deps}(x)$ 是从依赖服务返回的。
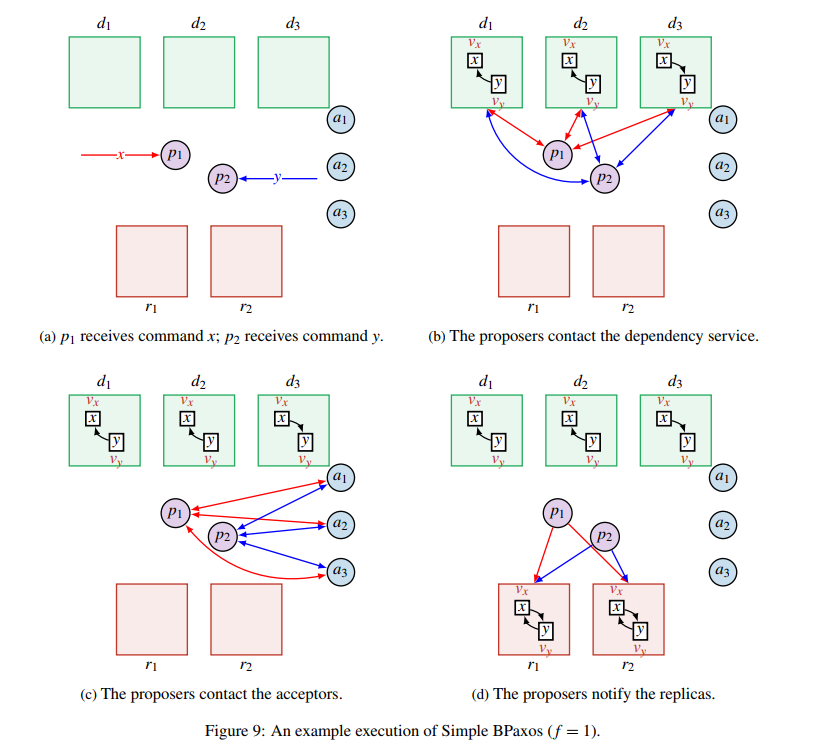
但是,两个冲突的操作,可能是同时发起的,而不同的消息到达不同的依赖服务节点的顺序有可能不同,这就导致了在不同服务节点中的依赖关系可能不同。即使依赖服务维护的冲突图是无环的,Replica 中形成的冲突图也有可能有环。以上图为例,$x$ 和 $y$ 是两个冲突的操作,分别同时发送给了 $p_1$ 和 $p_2$。$p_1$ 发送 $x$ 和 $v_x$ 给依赖服务,同时 $p_2$ 发送 $y$ 和 $v_y$ 给依赖服务。由于网络问题,$d_1$ 和 $d_2$ 先收到了 $x$,然后接收到了 $y$,所以根据这两个节点计算得到 $\text{deps}(v_x)=\emptyset$, $\text{deps}(v_y)=\left\{v_x\right\}$。$d_3$ 则是先收到了 $y$ 再收到了 $x$,所以计算得到 $\text{deps}(v_x)=\left\{v_y\right\}$, $\text{deps}(v_y)=\emptyset$。之后,由于网络问题,$d_1$ 的回复丢失了,$p_1$ 和 $p_2$ 分别都收到了 $d_2$ 和 $d_3$ 的回复,根据上面的算法,因为已经收到了大多数的回复,他们各自对自己关心的节点的依赖取并集,然后向 Acceptor 发送对应的值。$p_1$ 认为 $v_x$ 的值是 $(x, \left\{v_y\right\})$,$p_2$ 认为 $v_y$ 的值是 $(y, \left\{v_x\right\})$。这两个值都能够顺利的被 Acceptor 接受并提交了,然后 Proposer 将确认后的值发送给 Replica。Replica 将 $v_x$ 和 $v_y$ 加入到自己的冲突图中,并在接收到两个操作之后执行操作,并返回操作结果给客户端。可以看到,Replica 中的冲突图成环了。对于这种情况,需要以一种确定的预先规定好的算法来打破循环。
引入依赖图和日志有一个同样的问题,如果一个操作的依赖中有顶点因为各种原因一直没能确定值(比如 Proposer 突然挂了),那么这个操作也永远执行不了。为了解决这种问题,可以设置一定的超时时间,如果一个操作等依赖执行等得太久了,就用一个空操作来取代原来的节点。空操作指的是一个对于状态机安全的,不会改变状态的操作。恢复的过程也很简单,只需要对于那个节点,以第 $r (r\gt 0)$ 轮从 Phase 1 执行一次 Paxos 算法即可。这时需要执行 Phase 1 的原因是,有可能上一个 Proposer 已经让大多数的 Acceptor 接受值了,这时候需要做的就是将没有完成的流程进行下去,不能提交空操作。通过执行一次完整的 Paxos 就完成了恢复,也让整个算法变得更简单。
当然,上面的这个算法为了提交一个操作,需要等 7 次消息的延迟,显然有点不能接受。为了提高性能,还需要想办法减少消息的数量。
快速提交 Fast Paxos
为了改进 Paxos 交换信息次数太多的缺点,Lamport 又提出了 Fast Paxos。这个算法和原始的 Paxos 算法一样,只是用来确定单个值的。
就像之前的 MultiPaxos 一样,如果很确定自己是第一个提出一个值的话,那么就可以安全地跳过第一阶段,直接进入第二阶段提交。类似地,在这个改进版的算法中,客户端不再和 Proposer 通信,而是乐观地直接向 Acceptor 发起 Accept 请求,如果 Acceptor 没有接受过更早的消息(包括第 0 轮),那么就接受这个请求,返回 ${\rm P{\small HASE}2B}\left $ 消息给 Leader。定义多数函数 $\text{maj}(n)=\lceil \frac{n+1}{2} \rceil$,也就是求 $n$ 个人最少需要多少人算大多数。只有当 Leader 收到至少 $f+\text{maj}(f+1)$ 条 ${\rm P{\small HASE}2B}\left $ 回复且 $v’$ 相等之后,才能确定这个值为 $v’$。可见,为了能够安全提交一个值,需要的 Acceptor 比 $f+1$ 多。但随之而来的好处是,提交一个值只需要 4 次消息的延迟。
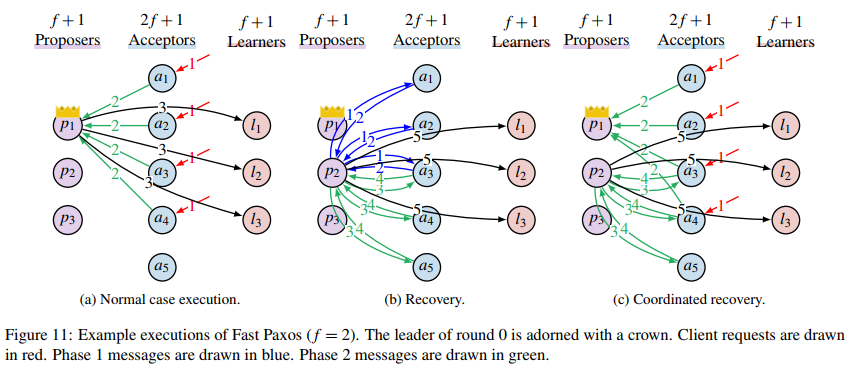
现在来考虑一下出错的情况。如果是 Leader 挂了,那么其他的 Proposer 需要针对这个值从头进行一次 Paxos 算法。Proposer 和普通的 Paxos 算法一样,需要先确定一个轮数 $i$,并且用这个轮数发送 ${\rm P{\small HASE}1A}\left $ 给至少 $f+1$ 个 Acceptor,收到至少 $f+1$ 个 ${\rm P{\small HASE}1B}\left $ 消息之后,Proposer 计算 $k=\max{\{vr\}}$ ,也就是和 Paxos 算法一样取最大的那个数。另外,记收到回复的 Acceptor 的集合为 $A$。如果 $k=-1$,那说明还没有任何值被提交过,Proposer 可以自由地提交任意值;如果 $k\gt 0$,那么 Proposer 就要继续完成没有完成的共识,只能够提交 $k$ 对应的 $vv$ 。
当 $k=0$ 的时候,说明有一些 Acceptor 收到过来自客户端的消息。此时,$v$ 有可能已经确定了某个值,也有可能还没有确定,需要分情况讨论。
如果 $\text{maj}(f+1)$ 个 Acceptor 已在第 0 轮的时候投票给了某个值 $v’$,那么这个值可能已经被决定了。如果 $A$ 集合之外的 $f$ 个进程也投票给了 $v’$,那么这时候就满足了 $f+\text{maj}(f+1)$ 的数量要求,可以安全地提交 $v’$ 了。如果没有哪个值得到了 $\text{maj}(f+1)$ 的票数,那么 Proposer 就可以断定在第 0 轮的时候没有决定一个值,此时它可以提出任意值。换句话说,如果一个值想要被快速提交,它不仅要得到大多数成员的认可,还要在大多数的大多数中得到认可,才能安全地提交。
确定了要提交哪个值之后,Proposer 就可以继续进行 Phase 2 的 Paxos,将值提交了。需要注意的是,想要快速提交一个值的话必须得到至少 $f+\text{maj}(f+1)$ 的票数,否则会出现脑裂的情况。假如 $f=2$,Acceptor 分别为 $a_1, a_2, \dots, a_5$。如果一个值只需要 3 个 Acceptor 同意,那么假如按照上面恢复的过程,接手的 Proposer 使用 $i=1$ 向 $a_3, a_4, a_5$ 发起 Phase 1 请求,此时 $a_3$ 回复它给 $x$ 投票了,$a_4$ 回复它给 $y$ 投票了,$a_5$ 说它没投票。注意它们都是第 0 轮。现在,因为 $a_1$ 和 $a_2$ 的状况未知,如果它们投票给了 $x$,根据我们的假设,满足了至少 $f+1$ 的票数,那么被选中的就是 $x$;但是它们也有可能投票给了 $y$,此时被选中的就是 $y$。Proposer 此时并不能决定提交哪个值才是正确的,算法就无法进行下去了。如果我们要求快速提交的时候需要 $f+\text{maj}(f+1)$ 的票数,那么这种情况就无法发生,要么有一个值得到了剩下的 $f+1$ 个成员的大多数的投票,此时可以断定这个值已经能够提交,要么剩下的 $f+1$ 个成员没有达成大多数的共识,那按照快速提交的规则,没有值能够安全提交,这时候就可以安全地提交任意一个值了。
快速提交发生冲突的情况也是类似的处理,要是没有哪个值能够达到要求的票数,那么就由 Proposer 发起普通的 Paxos 过程。
需要注意的是 $f+\text{maj}(f+1)$ 的限制只是为了安全的快速提交而设的。如果中途 Acceptor 挂了或是发生了别的情况,我们还是可以向剩下的至少 $f+1$ 个进程发起普通 Paxos 请求来提交值的。
这里还有一个可以优化的点,在冲突发生的时候,除了重新进行一次普通的 Paxos 算法,其实在冲突发生的时候 Leader 就已经能够收集到足够的信息了。在第 1 轮的 Paxos 算法中,${\rm P{\small HASE}1B}\left $ 包含的信息和第 0 轮的 ${\rm P{\small HASE}2B}\left $ 信息是完全一样的。所以我们可以将 ${\rm P{\small HASE}2B}\left $ 看成是 ${\rm P{\small HASE}1B}\left $。这样,第 1 轮的 Proposer 就可以直接跳到 Paxos 的 Phase 2 进行恢复了。
不安全的快速泛化 Paxos
了解了 Fast Paxos 算法后,我们可以依葫芦画瓢地改进普通的泛化的 Paxos 算法了。
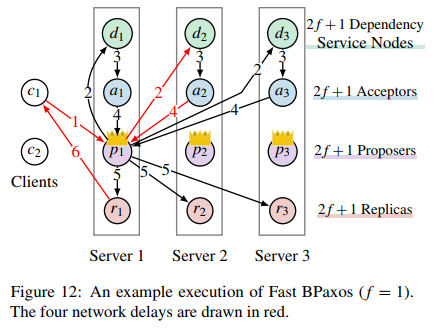
在改进的算法中,同样编号的角色都跑在同一个服务器上,这样同一个编号的不同角色之间的消息传递都是本地通信,不需要引入网络开销。
客户端还是需要通过任意一个 Proposer 来提交操作请求。Proposer 收到请求之后,一样是生成一个编号 $v_x$,并将操作 $x$ 和 $v_x$ 发送到依赖服务节点,和之前不同的是,依赖服务节点收到新的节点之后,并不是直接将 $\text{deps}(v_x)$ 发送回 Proposer,而是直接向自己本地的 Acceptor 发送 $(x, \text{deps}(v_x))$ 作为 $v_x$ 的值。Acceptor 和 Fast Paxos 中的 Acceptor 一样,当接收到值之后,按照规则投票或忽略,并将回复发送回 Proposer。同样的,Proposer 在收到 $f+\text{maj}(f+1)$ 个同样值的回复之后,就返回客户端操作成功,否则执行恢复流程。
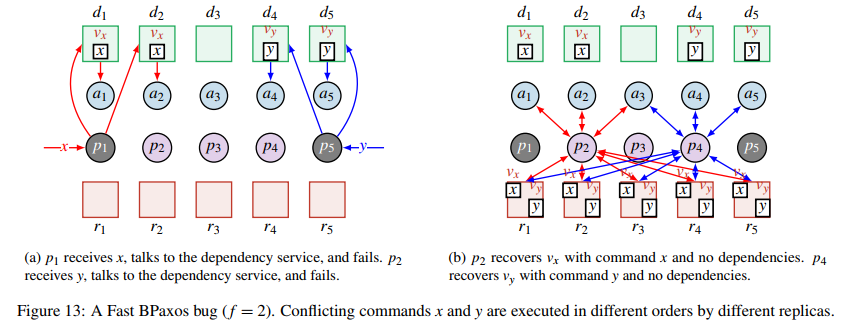
但是这个算法是不安全的。假设还是 $f=2$ 的情景,$p_1$ 和 $p_5$ 分别同时收到了冲突的请求 $x$ 和 $y$,$p_1$ 将节点 $v_x$ 和 $x$ 发送给了 $d_1$ 和 $d_2$,它们由于不知道 $y$,计算得到 $\text{deps}(v_x)=\emptyset$,并向 $a_1$ 和 $a_2$ 提出 $v_x$ 的值为 $(x, \emptyset)$。发给 $d_3, d_4, d_5$ 的消息被丢包了。类似地,$a_4$ 和 $a_5$ 提出 $v_y$ 的值为 $(y, \emptyset)$。$d_3$ 自始至终都没有收到任何消息,所以 $a_3$ 没有投票给任何值。这时候 $p_1$ 和 $p_5$ 都挂了,$p_2$ 负责恢复 $x$ 。它向 $a_1, a_2, a_3$ 发起了 Phase 1 的 Paxos 请求,这时候它收到了 $a_1$ 和 $a_2$ 的回复 $(x, \emptyset)$,因为 $\text{maj}(f+1)=\text{maj}(3)=2$,所以 $p_2$ 只能提交 $(x, \emptyset)$。类似地,$p_4$ 负责 $y$ 的恢复,并最终确定只能提交 $(y, \emptyset)$。这时候,Replica 分别收到 $(x, \emptyset)$ 和 $(y, \emptyset)$,所以在它们看来,$x$ 和 $y$ 不冲突,可以并发执行,就有可能导致不同 Replica 执行顺序不一致导致最终状态的不一致。
问题就出在,$\text{deps}(v_x)=\emptyset$ 并没有得到大多数依赖服务的节点的共识。单独保证共识不变式很简单,单独保证依赖不变式也很简单,但是要同时确保两者就有点 tricky 了。在恢复的过程中,共识不变式强制要求 Proposer 提交一个特定的值,而依赖不变式则强制要求 Proposer 不要提交那个值。这种两个不变式之间的矛盾,论文作者称之为基本矛盾。怎样在恢复过程中解决这个矛盾,是所有泛化的多 Leader 的 Paxos 算法最核心的挑战。EPaxos、Caesar 以及 Atlas 都是类似的,它们的进程组织是类似的,正常的执行流程也是类似的,最大的不同之处就在于它们是如何解决这个基本矛盾的。
解决这个基本矛盾的方法有两种,一种是避免矛盾,另一种则是解决矛盾。避免矛盾是通过调整 Quorum 的大小来避免矛盾的发生;而解决矛盾则更加复杂,需要在发现矛盾之后尝试解决它。
避免矛盾
在 Fast flexible paxos: Relaxing quorum intersection for fast paxos 这篇论文中,作者指出,只要满足以下两个条件,Fast Paxos 算法就是安全的:
- 每一个 Phase 1 的 Quorum 集合(也就是大多数节点的集合)$Q$,和每一个 Phase 2 的 Quorum 集合 $Q’$ 相交。也就是 $Q \cap Q’\ne \emptyset$ 。
- 每一个 Phase 1 的 Quorum 集合 $Q$ 和每一对快速 Phase 2 的 Quorum 集合 $Q’, Q”$ 相交,也就是 $Q\cap Q’ \cap Q”\ne \emptyset$ 。
那么,根据这个结果,只需要将不安全的快速泛化 Paxos 算法的快速提交需要的票数提高到 $f+(f+1)$ 就可以了。但是这意味着要想快速提交一个值得全体进程统一才可以。
和不安全的算法对比,在恢复阶段,当 $k=0$ 时,只有当 Proposer 收到了 $f+1$ 个同样的 ${\rm P{\small HASE}1B}\left $ 回复后,才是被强制提交 $v’$ 的,在其他情况下,Proposer 都可以选择任意的满足依赖不变式的值提交。这个算法用更大的进程集合为代价,完全避免了矛盾的发生。因为在 $f+1$ 个相同的回复后,说明 $\text{deps}(v_x)$ 已经被大多数节点接受了,此时就不会发生依赖不一致的现象了。
显然,如果每一次提交都要和所有进程通信,那么万一有一个进程比较慢,就会拖慢整个算法,如果有一个进程挂了,那么算法就无法继续进行了(虽然还是可以通过其他方法用基本 Paxos 算法执行)。无论是从性能的角度还是可用性的角度这个算法都不太实用,所以还需要进一步的改进。
基本的 EPaxos 改进

通过对上面的算法进一步改进,可以将快速提交的票数要求降低为 $f+f$。
第一个改动是 Proposer $p_i$ 在收到请求之后不再广播请求到所有的依赖服务节点,而只在本地计算依赖。
第二个改动是,本地的 $d_i$ 像普通的算法一样先计算出依赖节点,然后由依赖服务负责将 $v_x, x$ 和 $\text{deps}(v_x)_i$ 广播给其他节点。当其他节点 $d_j$ 接收到之后,按照自己的依赖图计算 $\text{deps}(v_x)_j$,然后向 $a_j$ 提出 $(x, \text{deps}(v_x)_i \cup \text{deps}(v_x)_j)$ 。
Acceptor 还是像之前一样投票给提出的值。
最后一个改动是,当 Proposer 接收到 $f+f$ 票后(包括本地的 $a_i$)就认为这个值确定了,并将确定的值 $v$ 发给本地的 $a_i$,如果此时 $a_i$ 还处于第 0 轮,那么这个值就是真正地确定了。如果不是的话,就拒绝这次请求,回复错误信息给 $p_i$。这整个过程都只涉及本地进程,不需要网络通信。
在正常情况下,$v_x$ 就正式确定了,$a_i$ 将 $v$ 广播到所有 Acceptor,如果有 Acceptor 拒绝了,就执行一次恢复过程。
需要注意的是,上面所说的优化只在 $f\gt 1$ 的时候成立,在 $f=1$ 的时候,所有的 Quorum 集合大小都是 $f+1=f+f=2$ ,不满足前面所说的两条定理,因此是不安全的。这时候,快速提交仍然需要 $f+f+1$ 票才能安全提交。
Atlas 优化
Atlas 优化的思想是放宽一致投票的要求,并增加 Proposer 执行快速提交的可能性。它定义了 $\text{popular}(X_1, X_2, \dots, X_{2f+1})=\left\{x|x 至少在 f+1 个集合中出现 \right\}$ ,其中 $X_i$ 是集合。当 Proposer 收到了来自 $2f+1$ 个 Acceptor 的回复后,如果 $\text{deps}(v_x)=\text{popular}\left(\text{deps}(v_x)_1, \text{deps}(v_x)_2, \dots, \text{deps}(v_x)_{2f+1} \right)$,那么就执行快速提交,并且 $\text{deps}(v_x)=\text{deps}(v_x)_1\cup \text{deps}(v_x)_2\cup \cdots\cup \text{deps}(v_x)_{2f+1}$。也就是说,Proposer 只有在每一个依赖服务计算出的依赖顶点 $v_y$ 也被大多数的依赖服务节点计算出来的时候,才执行快速提交。
解决矛盾
避免矛盾需要很多的节点才可以快速提交,所以并不是很实用。为了达到和 Fast Paxos 一样的 $f+\text{maj}(f+1)$ 的快速提交票数,还需要进一步优化算法,允许矛盾发生,并在发现矛盾的时候去解决矛盾。再回顾一下基本矛盾,在执行恢复的时候,共识不变式要求 Proposer 提出 $(x, \text{deps}(v_x))$,但同时,它无法保证 $\text{deps}(v_x)$ 是由大多数的依赖服务节点计算出来的,这就导致了它不能提交 $(x, \text{deps}(v_x))$。依赖避免算法通过增大 Quorum 大小,保证了 Proposer 提交的 $\text{deps}(v_x)$ 是由大多数的依赖服务节点计算出来的,这也导致了性能和可用性的下降。
矛盾解决算法则并不要求更多的 Quorum 节点,并且允许在恢复的时候出现这种不一致的现象,但通过更复杂的机制,要么确定 $\text{deps}(v_x)$ 没有被提交成功,要么确定 $\text{deps}(v_x)$ 已经被大多数节点接受,可以提交。矛盾解决算法更加抽象复杂,需要更多的逻辑推理。
这个算法需要引入一个剪枝依赖的概念。假如一个 Proposer $p$ 已经知道 $v_y$ 的值是 $(y, \text{deps}(v_y))$,对于依赖里的一个顶点 $v_x\in \text{deps}(v_y)$ ,就没有必要依赖 $v_y$ 了,因为它们的冲突关系已经在 $v_y$ 的值中表达出来了(回忆一下之前的依赖算法没有避免环的产生)。也就是说,对于互相冲突的操作 $x$ 和 $y$,要么 $v_x\in \text{deps}(v_y)$ 要么 $v_y\in \text{deps}(v_x)$ 。注意这时候两者同时成立的可能被排除了。
所以,我们可以剪枝掉一些不必要的依赖节点。假设 $v_x$ 的依赖是 $\text{deps}(v_x)$ ,那么可以计算出一个集合 $P\subseteq \text{deps}(v_x)$ ,对于 P 里面的元素 $v_y$ ,要么 $v_y$ 提交了一个空操作,要么 $v_y$ 提交的 $\text{deps}(v_y)$ 中包含了 $v_x$ 。最后,计算出 $\text{deps}(v_x)-P$ ,就是节点 $v_x$ 的剪枝后的依赖了。
对于这个剪枝后的依赖,提出一个新的剪枝依赖不变式,对于每一个节点 $v_x$,它的值要么提交了 $(\text{noop}, \emptyset)$,要么提交了 $(x, \text{deps}(v_x)-P)$,其中 $\text{deps}(v_x)-P$ 就是按照上面的算法计算出的剪枝后的依赖。
接下来,就开始修改之前的快速泛化 Paxos 算法了。第一个大的改动是,每一个 Acceptor 和 Replica 一样,也需要维护一个冲突图,当 Acceptor 收到消息确定 $v_x$ 提交了 $(x, \text{deps}(v_x))$ 之后,也按照算法,将 $v_x$ 加入到图中,并添加 $v_x$ 指向 $\text{deps}(v_x)$ 每一个顶点的边。其次,Proposer 执行的恢复算法要复杂得多。
具体来说,按照快速泛化 Paxos 算法,Proposer 收到至少 $f+1$ 个 ${\rm P{\small HASE}1B}\left $ 消息(记发送消息的 Acceptor 集合为 $A$)之后,如果 $k=0$ 且 $v’=(x, \text{deps}(v_x))$ 获得了至少 $\text{maj}(f+1)$ 票,按照快速算法,Proposer 需要提交 $v’$。但按照泛化算法,却无法保证 $\text{deps}(v_x)$ 是原来大多数节点所求依赖的并集,所以这个值不能提交。这时候,冲突解决算法需要做一些额外的工作,来断定要么 $v’$ 并没有被提交,要么 $\text{deps}(v_x)$ 是 $v_x$ 的一个剪枝依赖集合。

首先要做的是,Proposer 向发送消息的 $f+1$ 个依赖服务(和对应的 Acceptor 在同一个进程中)发送 $v_x$ 和 $x$,并将这些依赖服务返回的依赖集合求并集,保存到 $\text{deps}(v_x)_A$ 中,并且计算一个差集合 $Y=\text{deps}(v_x)_A-\text{deps}(v_x)$,也就是用返回的依赖和 Acceptor 保存的依赖作差(因为 $\text{deps}(v_x)$ 是 $\text{maj}(f+1)$ 个 Acceptor 返回的,$\text{deps}(v_x)_A$ 是 $f+1$ 个节点返回的,前面的集合是后面集合的自己)。
然后,需要对这个集合开始剪枝操作。一开始 $P=\emptyset$ ,对于 $Y$ 中的每一个顶点 $v_y$,如果还不确定 $v_y$ 是否已经提交值,那么就需要先对 $v_y$ 执行恢复操作。在确定了 $v_y$ 的提交值之后,根据提交的内容来执行进一步的操作。如果 $v_y$ 提交的是一个空操作,或者 $v_x\in \text{deps}(v_y)$,那么就直接剪枝,将 $v_y$ 添加到 $P$ 中。否则,则需要向 Acceptor 的大多数集合 $A’$ 确认 $v_x$ 的状态。如果有 Acceptor 返回 $v_x$ 已提交,那么就直接终止恢复过程。如果所有的 Acceptor 都没有认为 $v_x$ 已提交,那么 Proposer 就可以安全地提出任何一个满足依赖不变式的值 $v$,并向所有 Acceptor 发送 ${\rm P{\small HASE}2A}\left $ 的消息。关于为什么这个时候就可以断定在第 0 轮中没有值被提交,可以提交任意值,需要更复杂的推理,放到后面讲。
循环结束之后,说明剪枝完成,此时 $\text{deps}(v_x)=\text{deps}(v_x)_A-P$,也就是原来的 $v’$ 可以直接提交,这时候,就可以发送 ${\rm P{\small HASE}2A}\left $,以及 $P$ 中每一个顶点的最终提交值给至少 $f+1$ 个 Acceptor 进行 $v_x$ 的提交了。
现在再回头看看,为什么上面说 Proposer 可以断定没有值被提交。首先,执行到这个分支的时候,我们知道 $v_y$ 不是空操作,而且 $v_x \notin \text{deps}(v_y)$ ,根据剪枝依赖不变式,$\text{deps}(v_y)=\text{deps}(v_y)_D-P’$,其中 $\text{deps}(v_y)_D$ 是由至少 $f+1$ 个依赖服务节点 $D$ 计算得到的集合的并集。因为 $v_x\notin \text{deps}(v_y)_D-P’$,要么 $v_x$ 本来就不在依赖中 $v_x\notin \text{deps}(v_y)_D$,要么被剪枝了 $v_x\in P’$。
但是 $v_x$ 是不可能在 $P’$ 中的。因为此时节点已经达成了 $v_y$ 的 $\text{deps}(v_y)=\text{deps}(v_y)_D-P’$ 共识,同时也达成了 $P’$ 中的所有顶点已经提交了的共识,根据相交定理,肯定至少有一个联系到的 Acceptor 确定 $v_x$ 已经提交。如果 $v_x$ 在 $P’$ 中,就产生了矛盾,因为这时候算法认为 $v_x$ 还没有提交。因此,$v_x\notin \text{deps}(v_y)_D$ 成立。所以,$D$ 中的所有节点都先处理了 $v_y$,再处理 $v_x$。又因为 $v_y\notin \text{deps}(v_x)$(因为 $\text{deps}(v_x)$ 是 $\text{deps}(v_x)_A$ 子集,如果 $v_y\in \text{deps}(v_x)$,那它就不可能出现在循环中),这时候就需要有快速提交的大多数达成共识 $v_x$ 在 $v_y$ 前处理,但已经有 $D$ 个节点达成了 $v_y$ 在 $v_x$ 前处理的共识,前面的共识是不可能被提交的。所以 $v’=(x, \text{deps}(v_x))$ 肯定没有被提交,Proposer 可以任选一个值提交。
经过一番推理之后,我们得到了一个解决冲突的算法。但是这个算法有一个缺点:它有可能死锁。这是因为,有可能存在节点 $v_1, v_2, \dots, v_n$ 其中每一个 $v_i$ 都依赖 $v_{i+1 \mod n}$,那么在递归解决未提交的顶点的时候,就会死锁。
为了解决死锁问题,我们还需要修改算法,具体来说,Proposer 会在两个条件都满足的情况下,认为一个顶点 $v_x$ 快速提交了 $v=(x, \text{deps}(v_x))$。首先当然是这个值得到了来自快速提交所需的 $f+\text{maj}(f+1)$ 票,并且记投票了的 Acceptor 集合为 $F$,并且对于每一个 $v_y\in \text{deps}(v_x)$ ,都有 $f+1$ 个 Acceptor $A\subseteq F$,在投票的时候知道 $v_y$ 已经提交了。其次,在 Acceptor $a_i$ 发送 ${\rm P{\small HASE}2B}\left $ 回复($v=(x, \text{deps}(v_x))$)的时候,顺带发送 $\text{deps}(v_x)$ 中 $a_i$ 知道已经提交了的节点和它们的值。
最后,在恢复的过程中,要检测出是否发生了循环依赖。具体来说需要在上面的恢复算法中的第 10 行之后插入以下算法:

在获得 $v’=(x, \text{deps}(v_x))$ 的信息之后,首先计算出投票给了 $v’$ 的 Acceptor 集合 $M$,Proposer 检查 $\text{deps}(v_x)$ 是否存在一个 $M$ 中没有 Acceptor 知道是否已经提交值的顶点 $v_y$,存在的话,说明 $v’$ 不可能在第 0 轮中提交。如果 $v’$ 提交了,那么说明 $F$ 中的 Acceptor 投票给了 $v’$,同时存在 $A’\subseteq F$ 中的 Acceptor 知道 $v_y$ 已经提交了。由于 $A’\cap A\ne\emptyset$,但又没有 Acceptor $a$ 同时投票并且知道 $v_y$ 已经提交,这就产生了矛盾。因此,Proposer 可以提出任意值。
其次,Proposer 可能之前正在恢复 $v_z$ ,然后根据算法递归调用来恢复 $v_x$,如果此时 $v_z\in \text{deps}(v_x)$,那么 $M$ 中肯定有 Acceptor $a$ 已经知道 $v_z$ 被提交了,这时候就可以终止 $v_z$ 的恢复过程了。否则,$v_z \notin \text{deps}(v_x)$,那么每一个 $M$ 中的节点的依赖服务都是先处理 $v_x$ 后处理 $v_z$。又因为 $|M|\ge \text{maj}(f+1)$,所以肯定只有少于 $f+\text{maj}(f+1)$ 个节点有可能认为 $v_z$ 早于 $v_x$ 处理。如果 Proposer 在恢复 $v_z$ 的时候需要递归恢复 $v_x$,那么 $v_x\notin \text{deps}(v_z)$(要不然的话 $v_x$ 已经确定提交了,不需要恢复)。因此,如果 $v_z$ 想要带着 $v_x\notin \text{deps}(v_z)$ 快速提交,那么就需要至少有 $f+\text{maj}(f+1)$ 个节点认为 $v_z$ 早于 $v_x$ 处理,但这和之前的条件矛盾,所以 $v_z$ 不可能被快速提交,这时候就可以提出任意值了。
这样,通过对 Paxos 算法循序渐进地改进,我们就得到了一个可以解决冲突的,不会死锁的快速泛化 Paxos 算法了。
总结

作者根据 Leader 的数量、是否泛化、能否快速提交、怎样处理基本矛盾,大致给不同的 Paxos 变种分到不同类别中。
真实算法
作者为了更清楚地说明 Paxos 算法的改进过程,对一些细节忽略或者做了修改。EPaxos 使用了带基本 EPaxos 改进的快速算法,来减少快速提交所需的票数,同时也使用了最后所说的依赖剪枝以及避免死锁的递归恢复算法。Caesar 则进一步地改进 EPaxos 算法,和 Atlas 优化类似,Caesar 在快速提交的时候不需要 Acceptor 都投票给完全一样的值。此外 Caesar 没有使用递归恢复算法,而是使用了逻辑时间戳以及在协议中仔细加入 Barrier 来避免递归的恢复。
和单 Leader 日志型算法的比较
相比于 MultiPaxos、Raft 以及 Viewstamped Replication 这些将所有的操作赋予全序形成线性的日志的算法,泛化的多 Leader Paxos 算法虽然更复杂,但也有性能和可用性上的优势。
首先,多 Leader 避免了单 Leader 成为瓶颈的问题,任何 Proposer 都可以接受处理命令,提高了吞吐量。
其次,多 Leader 算法能更好地应对故障。在 Raft 和 MultiPaxos 这些算法里,一旦 Leader 发生故障,那么吞吐量会立即降为 0,直到新的 Leader 被选举出来后才能恢复。像 EPaxos 这种算法,如果有 Leader 死机了,那么吞吐量虽然也会下降,但不会下降到零,其他 Leader 还是可以继续处理命令。故障的 Leader 恢复后,吞吐量也能回归正常。
第三,对于地理上分开的应用来说,多 Leader 算法可以达到更低的延迟。和单 Leader 对比,可以在不同的数据中心各放置一个 Leader,这样不同数据中心的客户端感受到的延迟都是一样的,整体的延迟也会更低。
最后,泛化的 Paxos 能降低操作之间依赖关系很少的应用的尾延迟。在 Raft 中,一个命令如果因为网络问题没能提交,那么后面所有的命令都会受到影响。任何一个命令的延迟执行,都会影响到串行化到它后面的命令的延迟。而泛化的 Paxos 算法中,即使一个命令延迟执行了,和它不冲突的命令都可以不受影响地并发执行,降低了尾延迟。
更多相关工作
SpecPaxos 和 NOPaxos 采取更加激进的推测执行(Speculative Execution),对 Fast Paxos 改进到最佳情况下只需要 2 次网络延迟就能完成操作。CURP 则进一步地扩展泛化性,允许可交换的命令以任何顺序执行。但是,随着提交延迟的降低,算法的复杂性也在上升,进一步影响了它们在工程中的应用。
Mencius 则是一个多 Leader 的非泛化的 Paxos 变种,其中不同的 MultiPaxos 日志项在不同的 Leader 中分块处理,同样地,一个日志项只有等到它之前的日志项执行完成后才能执行。为了同步日志,Mencius 中的 Leader 会执行 All-to-All 的广播操作。它的优点是相比起 EPaxos 等算法简单很多。这也说明了对 Paxos 算法优化的复杂性主要来自于泛化而不是多 Leader。当然多 Leader 也是会带来一定复杂性的。
Paxos 之外
除了千奇百怪的 Paxos 变种,还有很多其他的分布式共识算法。例如 Chain Replication,不同的节点组成了一条复制链,写的时候往头节点写,然后沿着复制链复制日志,读的时候只从尾节点读。链复制算法比 MultiPaxos 能达到更高的吞吐量,因为负载在不同节点上更加均衡。
Scalog 则使用了一种复杂的批处理方式来复制日志。客户端并不直接将日志项发送到一个中心的 Leader,而是发送到批处理节点中的任意一个。按照一定时间间隔,批处理的每一批数据会被封存,并且分配一个 ID,然后这个 ID 被当做日志 ID,就像 MultiPaxos 的日志编号一样,发往一个状态机复制协议。
这两个算法也说明 Leader 带来的瓶颈可以不通过多 Leader 来解决。
而 PQR、Harmonia、CRAQ 这些算法则实现了对于读操作的优化,对于不涉及状态机修改的命令,都可以不通过 Leader 来执行(Raft 也有类似的 Follower Read 优化),写命令还是要通过 Leader 执行。比较有趣的是,对于泛化后的 Paxos 能不能也实现读优化还是一个值得研究的问题。
Paxos 算法通过限制未来,用大多数集合相交排除可能性达到了各个节点的一致性。它简单,但仍有许多值得深入研究的地方。这正是它最引人入胜的地方。从泛化性和一致性的拉扯也可以看出系统设计中的一些 trade-off,如何找到其中的 sweet point,也是计算机系统研究的乐趣之一。