越来越多的开源软件占领了各个领域依赖链条的关键环节,越来越多的程序员也以参与知名开源软件的开发为荣,将开源贡献和在开源社群当中获得的头衔作为简历当中浓墨重彩的一部分。
在这样的背景下,技术驱动型公司的 HR 也随之需要掌握从开源社群当中找到组织需要的人才的方法。如果企业的业务依托于开源软件的发展,甚至公司直接投入人力参与开源社群,那么 HR 还需要了解开源项目运作的基本流程。
我在最近三年间陆续遇到人力资源相关的从业者询问如何解决这两个问题。目前,大部分的开源项目代码都托管在 GitHub 平台上。本文从我接触到的问题出发,从 GitHub 提供的能力和 GitHub 上项目协作的常见形式入手,回答这两个问题。
由于 GitHub 没有像 LinkedIn 那样提供直接的 endorsement 机制,HR 无法简单的通过标签筛选来圈出符合要求的候选人。GitHub 上的活动几乎全是围绕着软件仓库进行的,因此最合适的筛选条件,就是根据职位描述上要求掌握的开源软件技能,到相应的代码仓库当中查看活跃的参与者。
第一步,找到要求对应的代码仓库地址。
如果业务团队已经标明相关的开源软件,例如流式计算工程师最好掌握 Storm / Flink / Spark Streaming 等技能,那么使用 GitHub + 对应词组的关键词 Google 搜索,认准 github.com 地址的网页,很容易就能导航到对应的代码仓库。
Google Search Flink
否则,如果业务团队只提供了模糊的关键词,就需要先发现对应的仓库。一般来说,最好是反馈到业务团队重新提供候选仓库,哪怕只有一个,也可以从代码仓库为自己打上的标签里找到靠谱的那个点进去发现其他类似的仓库。
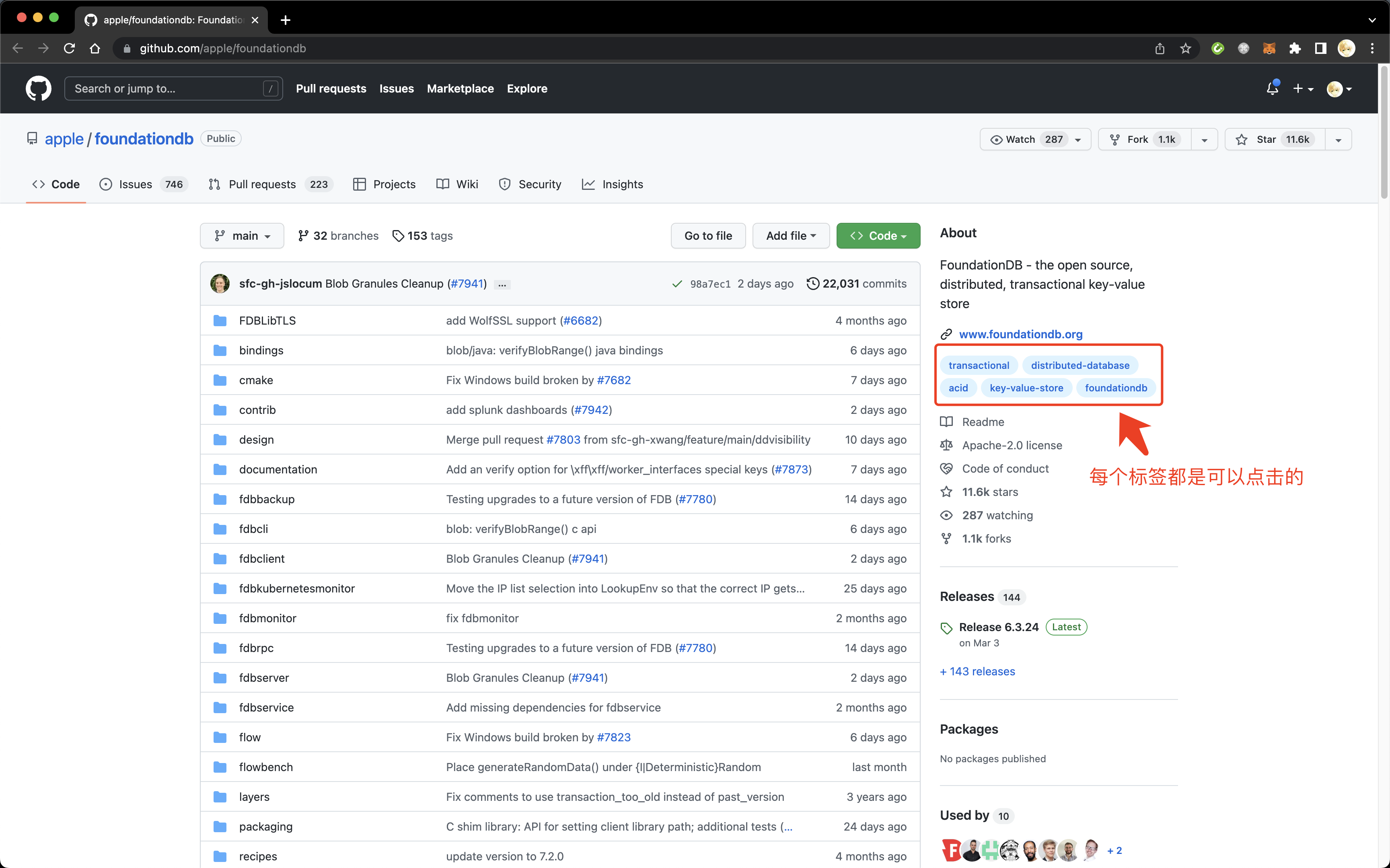
FoundationDB 的标签
例如想要招募存储方向的人才,如果知道了 FoundationDB 是符合条件的,从标签里的 key-value-store / transactional / distributed-database 都可以顺藤摸瓜抓出一批来。
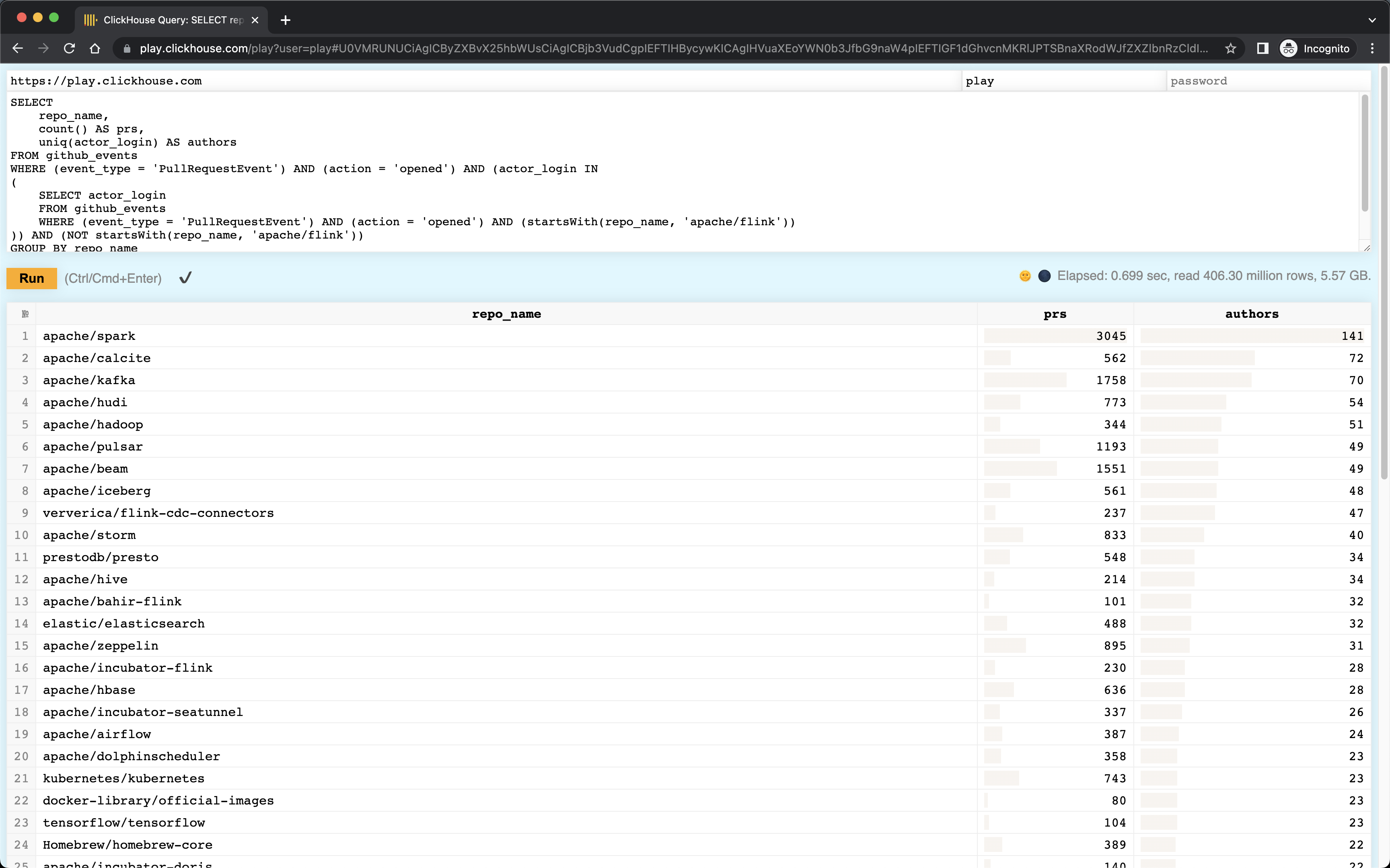
如果想要再仔细的圈选,就需要数据分析团队或者开源社群运营团队开发对应的分析工具了。比如基于 ClickHouse 的 GitHub 事件公开数据集,可以以提交补丁为维度圈选出关系最紧密的项目。下面就是一个发现和 Apache Flink 项目相关的其他项目的示例。
基于 ClickHouse 的公开数据集发现关联项目
第二步,从代码仓库的 Contributors 页面发现活跃的参与者。
跳转 Contributors 页面
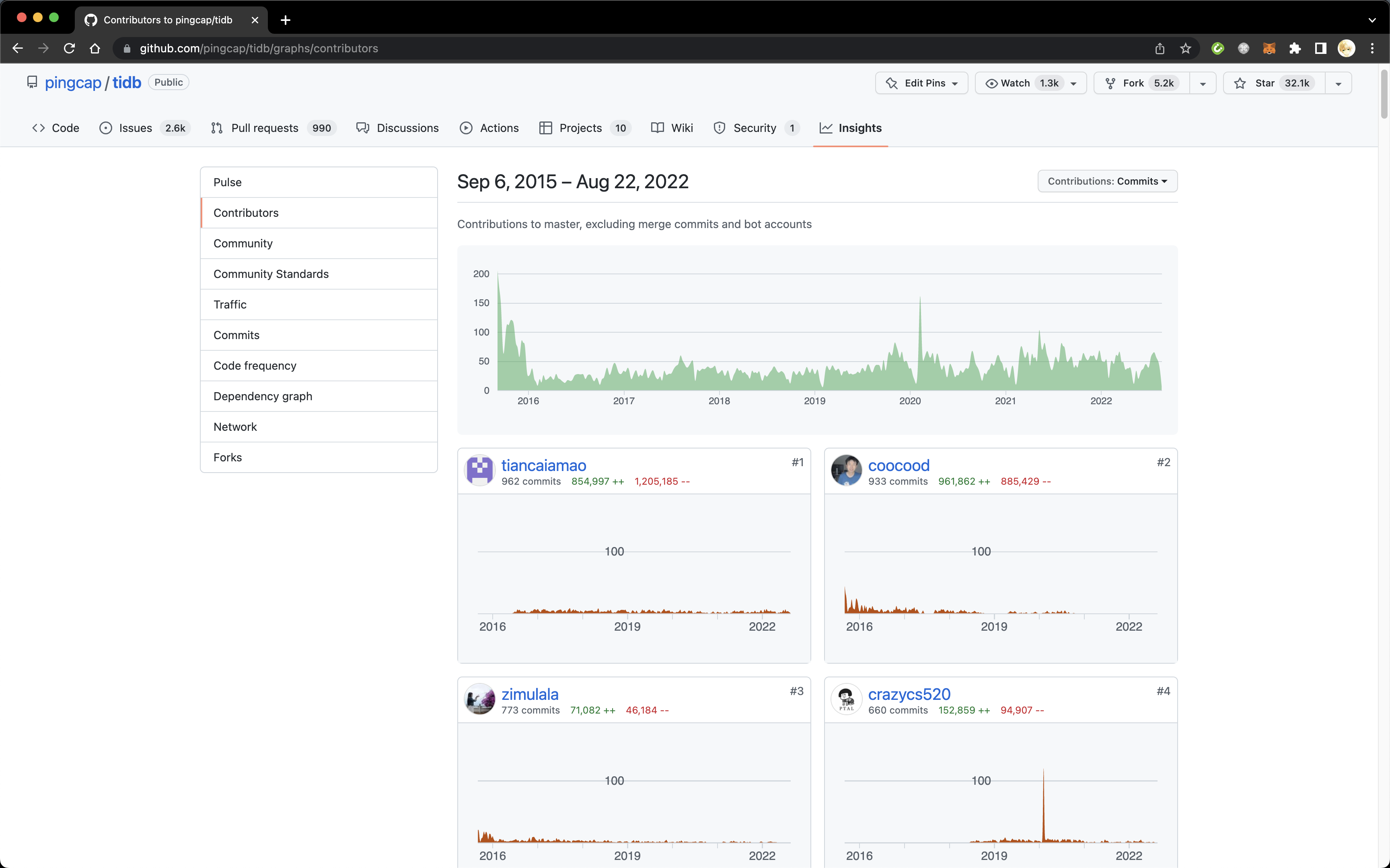
例如从 TiDB 的 Contributors 页面当中,我们就可以看到 @tiancaiamao / @coocood / @zimulala / @crazycs520 几位是提交最多 commit 的开发者。GitHub 支持以 commit 数或代码增减行数来排序,最多显示前一百名参与者。虽然有其他手段列出所有有代码提交的参与者,但是对于圈选候选人来说,前一百名应该已经足够。
TiDB Contributors
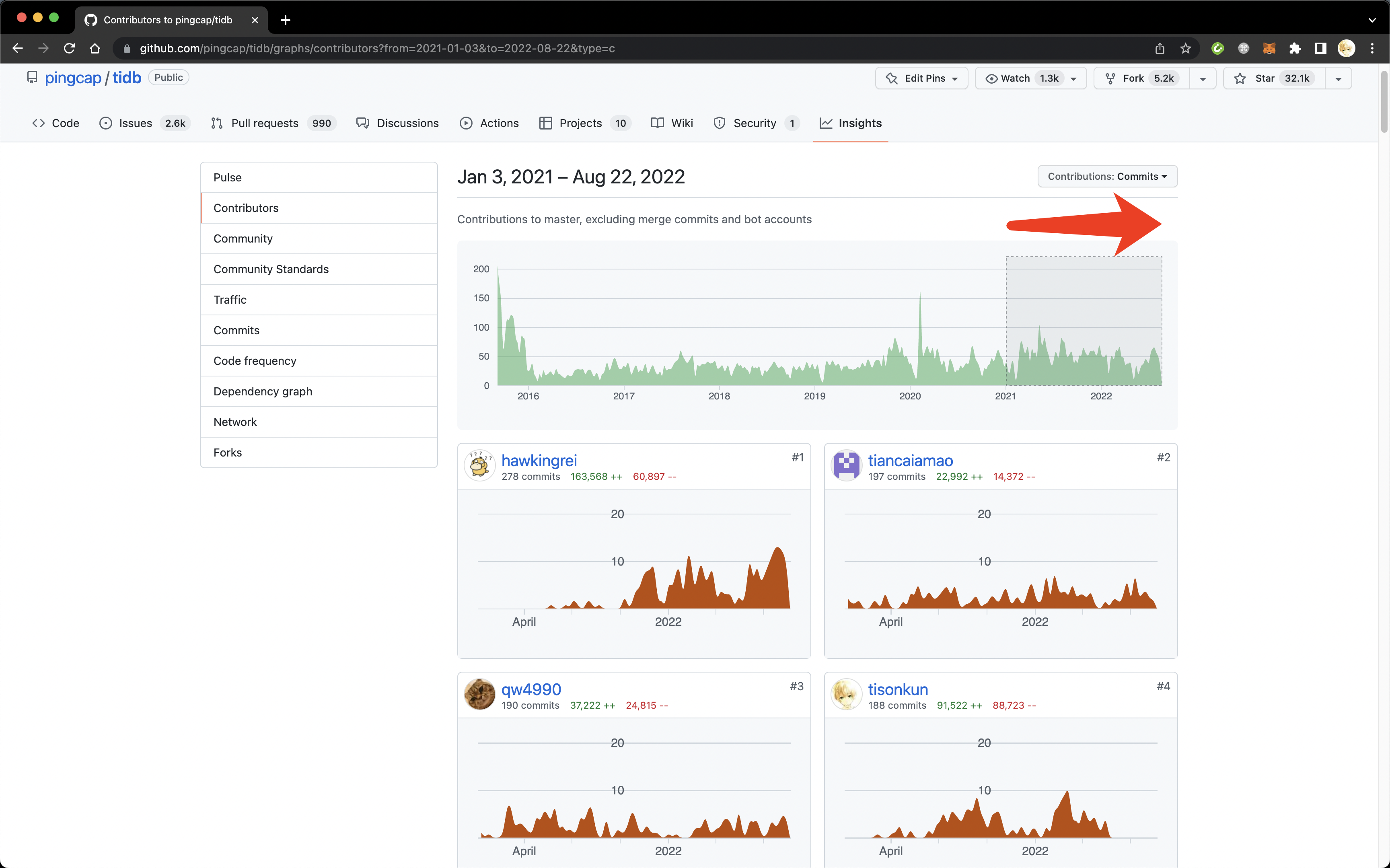
另外,默认的排序是基于历史全部事件的。HR 圈选的时候可能会更关注最近还活跃在项目上的开发者,这点可以通过鼠标在上图的时间线里拖出一段时间来筛选。下图显示出从 2021 年至今最活跃的参与者。可以看到 @coocood 工作重点转向之后前一百名都看不到人了,而虽然我在图上名列第四,但是具体曲线图可以看出和前三名相比,我在最近一段时间都没有新的 commit 了。
TiDB Contributors after 2021
第三步,全面评估圈选出的候选人,并找到联系方式。
现在,我们找到了一批不错的候选人。那么接着就需要做一些简单的背景调查和找到候选人的联系方式了。
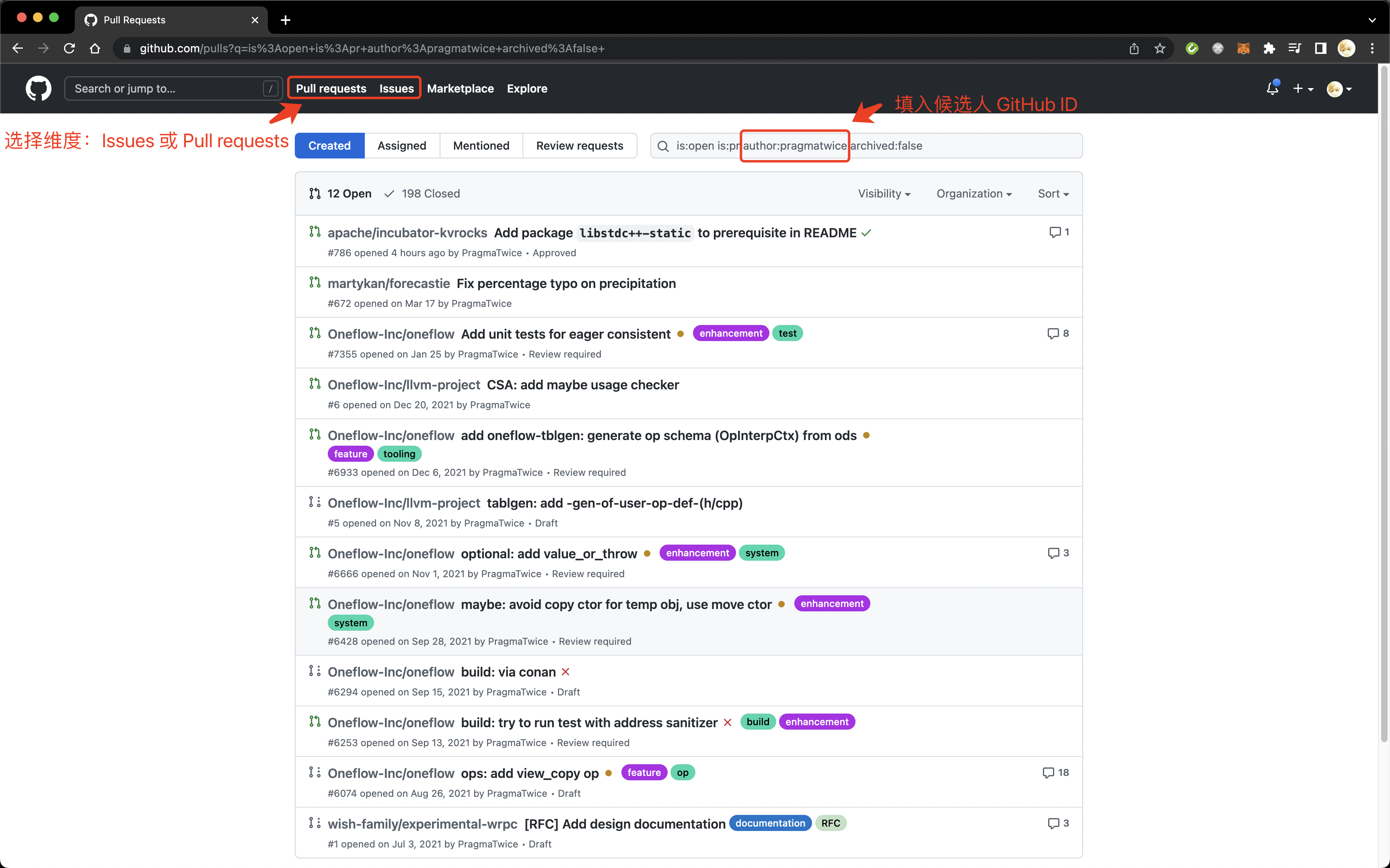
通过点击 Contributors 页面参与者的头像或用户名,或者直接输入 http://github.com/ + 用户名可以看到候选人的 GitHub 个人主页。
@PragmaTwice 个人主页
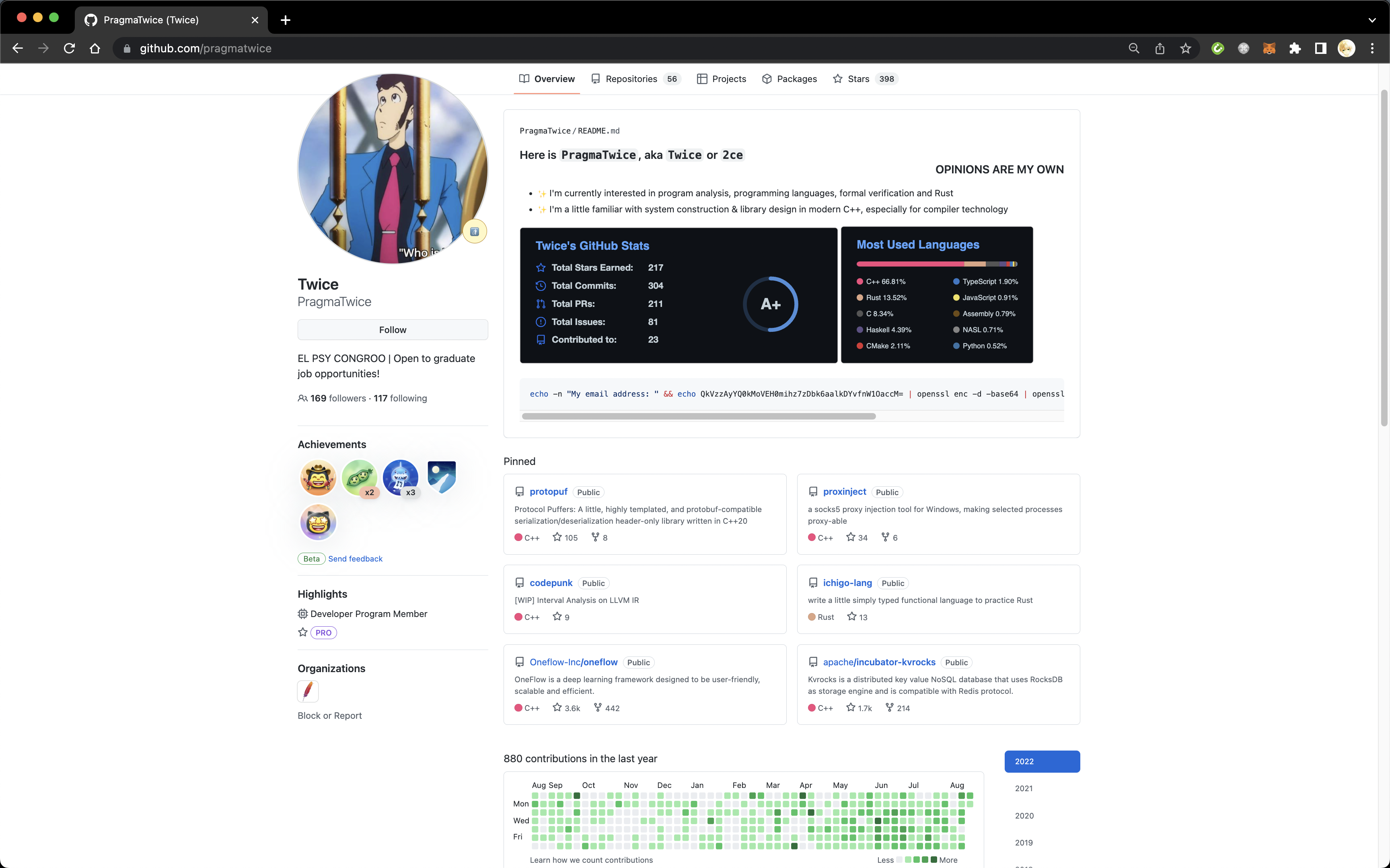
例如,想要招聘熟悉分布式系统开发的 C++ 工程师,从 Kvrocks 或 OneFlow 等项目里发现 @PragmaTwice 之后,查阅 @PragmaTwice 的个人主页 。
可以看到,他在自己的个人主页里有 Open to graduate job opportunities! 的描述,可以看出他是一个正在求职的应届生。 接着看他的个人简介,是有精心设计过的,至少不是三无用户,可以交给业务团队负责人进一步筛选。 从下面绿色砖块的代码提交墙上可以看出,他在过去一年当中积极活跃在 GitHub 上。 上图界面再往下拉,可以看到他的贡献 67% 是代码提交,code review 和 PR 都在 15% 左右,issue 仅占百分之五。这是一个典型的独立开发者,并且大部分时间都直接推送 commit 到仓库上,在团队协作上暂时不能看出是否具备足够的经验。 最后看 Pin 的项目,这里只能展示用户曾经参与开发的项目,也就是候选人是这些项目的开发者。@PragmaTwice 参与过两个知名项目 OneFlow 和 Kvrocks 的开发,他的个人项目 protopuf 和 proxinject 都收获了还算不错的 star 数(不能被少部分头部项目误导,绝大部分项目根本没有几个 star 的。Open Collective 设置的门槛是 100 stars 已经是个比较有效的筛选器了),可以点进这些项目筛选出他实际的参与内容,进一步分析。 上面列举了几个可以参考的角度。实际上,评估一个候选人不是死板的套公式,往往需要启发式地发现候选人的亮点。一般来说,从他参与过的项目和参与项目的具体内容可以做出一定的判断。由于 GitHub 上的身份只是候选人的一个侧面,我建议 HR 尽量从发掘亮点的角度看待,而不能从 GitHub 的活动上缺少什么就推断出候选人缺少什么。
再介绍其他一些常见的评估工具和角度。要想看到一个候选人在 GitHub 上全时间的活跃情况,从个人页一年一年看是一种方式,但是也可以在 github-contributions 网站上输入用户名直接列出来会简便一些。
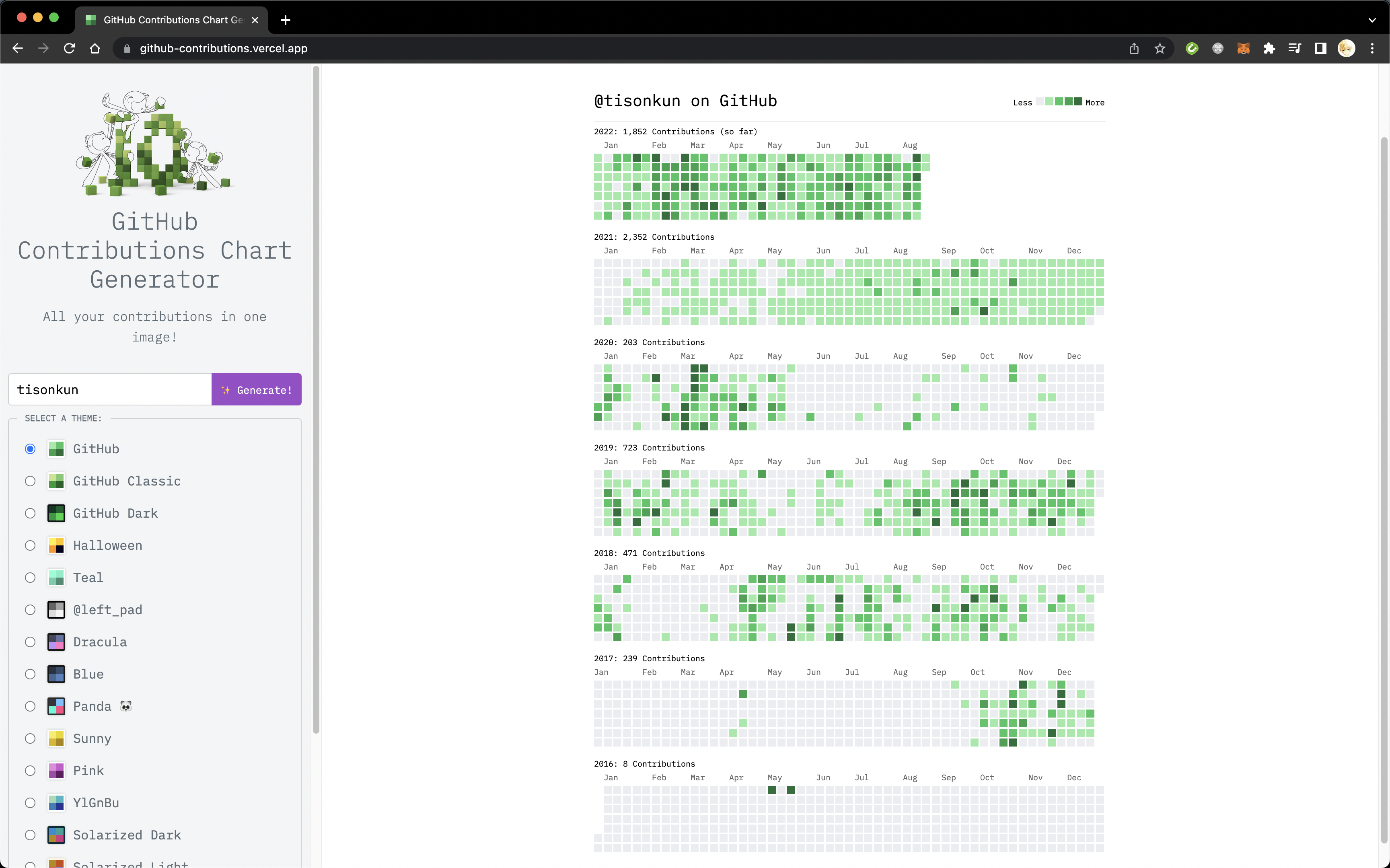
@tisonkun's Contributions
可以看到,我从 2017 年底开始涉足开源软件开发。陆续参与到 2020 年 5 月加入拼多多,明显出现了一段真空期。2021 年初加入 PingCAP 后工作又和开源软件相关,活跃程度逐渐恢复并超越过去。当然,从 HR 的角度没办法知道这么详细的个人工作变动,但是可以从活跃度的变化做出相应的假设并验证,勾勒出候选人的工作经历。
另一个问题是前面提到的确认候选人贡献的质量。
如果想要不区分代码仓库的查看一个 GitHub 用户的活动,可以从以下界面搜索筛选。
GitHub 用户搜索
这个页面的搜索功能是很丰富的,除了直接从用户界面的按钮探索以外,也可以从 GitHub 搜索文档 里发现更多的筛选方法,这里就不展开了。
如果想要具体看一个 GitHub 用户在某个仓库的参与,可以用以下几个链接来调查,其中的用户名部分相应替换。
这三个链接分别展示了用户在当前仓库的 commits / issues / PRs 活动。同样,从用户界面上或 GitHub 的搜索文档里可以发现更丰富的筛选方式,这里尤其想提出的是 involves 和 reviewed-by 筛选器,分别能够看到用户参与的 issue 和 review 的补丁。
根据 HR 对行业的熟悉程度,可以从这些具体的活动当中对候选人做进一步的判断。基本地,如果用户的 commit 基本是 fix typo 字样的,那么他在这个仓库的参与就很有限,这个项目的声誉并不能为候选人站台。
最后,HR 需要找到候选人的联系方式发出邀约。
有些用户(包括我)直接在个人页就展示了个人邮箱和推特账号,可以很容易地发送邀约。
此外,类似 @PragmaTwice 这样主动求职的用户,往往会用醒目的手段留下自己的联系方式。他的个人主页里包括这样一段代码:
1 echo -n "My email address: " && echo QkVzzAyYQ0kMoVEH0mihz7zDbk6aalkDYvfnW1OaccM= | openssl enc -d -base64 | openssl enc -d -aes-128-cbc -iv 205731624 -K 230549126 2>/dev/null
把它放到终端里执行,会得到以下输出:
1 My email address: twice@apache.org
这就是典型的程序员介绍自己的方式,一方面展现了自己的黑客精神,另一方面也避免纯粹爬取个人信息发送邮件的机器人的骚扰。
对于没有公开邮箱的用户,就得采用一些特殊的方法来挖掘了。我是通过下载下来候选人参与的仓库,用 git log 命令查看找到候选人提交的 commit 上的个人信息。比如我的提交显示成:
1 2 3 4 5 6 7 commit 9053519c0b81b765919aad9a9695910580586ea1 (origin/main, origin/HEAD) Author: tison <wander4096@gmail.com> Date: Sun Aug 21 23:07:49 2022 +0800 post over-communication Signed-off-by: tison <wander4096@gmail.com>
这里就有我的个人邮箱。
由于 git log 里的 commit 信息跟 GitHub 的用户名未必有关系,把候选人和具体某个 commit 的 author 对于起来需要一些洞察力。
对于商业模式依托于开源软件,并且大力投入到项目开发的公司来说,托管在 GitHub 上的项目承担着公司研发部门重要乃至主要的工作内容。HRBP 和参与绩效制定的 COE 员工有时也会希望理解 GitHub 上项目管理的基本方法,我以回答被问过的问题的角度做个简单的介绍。当然,项目管理的方法维护者各有所爱,也有些项目根本不遵守业内的共识,这里介绍的是经过选择的一些我个人比较认同的方法。
第一个,研发通常是一个一个版本的发布软件,软件版本是如何确定的,版本之间又有什么关系呢?
首先需要知道的一点,软件版本发布后就是不可变的了。比如,Pulsar 2.10.1 版本发布后,就一行代码,一个字符也不会再动了。哪怕代码里面有 BUG 要修,也是通过发布一个 2.10.2 版本的方式在 2.10.1 版本的基础上包括修复的补丁,而不是直接改动已发布的版本。实际上,类似 Java 生态的 Maven 中央资源库和 Rust 生态的 Cargo 资源库,都不允许修改已经发布的版本的内容。
这个很好理解,如果同一个版本号,今天拉取是一个内容,明天拉取是另一个内容,用户的构建就不稳定,不可预测了。尤其是开发者虽然希望在新版本里修复缺陷,但是谁又能肯定新的变更不会引入新的问题呢?对于开发者来说,确保版本号对应确定的内容,也是排查问题的重要前提。我曾经见过私有化部署当中同一个版本号交付给不同的用户,每个用户后续又提供了各自不同的 bugfix 热更新,到最后开发者根本无法知道某个用户线上的版本到底包含哪些改动不包含哪些改动,很难排查线上问题。
因此,合理的软件,同一个版本对应着相同的软件逻辑,相同版本的两个软件包,行为是完全一样的。在这个基础上,业界在长期实践的基础上逐渐聚拢到语义化版本 的标准上。
语义化版本以形如 X.Y.Z 的版本号来命名软件版本,上面提到的 Pulsar 2.10.1 就符合这个标准。其中第一个数字代表“主版本号”,递增主版本号意味着可能引入了不兼容的 API 修改。第二个数字代表“次版本号”,通常意味着新增向下兼容的功能。比如 Flink 1.14.0 发布后,Pulsar Flink Connector 实现的 Sink 最早也只能包含在 1.15.0 当中,而不能进入 1.14.1 等 1.14 系列的后续补丁版本。第三个数字代表“修订号”或“补丁版本”,相同的主版本和次版本,补丁版本越高,包含的缺陷修复越多。新的补丁版本不会引入新功能,更不可能引入不兼容改动,只会包含缺陷修复。
因此,用户遇到 BUG 时,如果不能直接从使用层面解决,往往会选择升级补丁版本,升级补丁版本整体是比较放心的。如果用户想要使用新功能,则需要升级次版本号,升级次版本号需要经过测试,避免新逻辑引入缺陷或回退。如果用户想要的功能需要升级到更高的主版本号,或者由于旧版本不再维护需要升级主版本号,用户一般会严阵以待,准备好迁移不兼容的接口和应对未知的兼容问题。升级主版本号是个重大的决定。
还有其他软件选择不同的版本定义方式。例如,JetBrains 的 IDE 系列用年份 + 当年的第 n 个版本来定义。例如,Linux 总是保持向后兼容,主版本号递增也不意味着不兼容更改。例如,Trino 的版本号只有一个数字,每次发布新版本递增,每个版本之间都可能引入不兼容的改动。例如,Rust 有按照语义化版本发布的流程,也有按照日期每日发布一版的 nightly 系列,还有按需以年份命名的大版本,不同大版本包含默认选项不同。总之,每个项目根据自身特点,可能有不同的策略。
最后,版本号含义的定义只是人为规定的,由于 BUG 随时有可能被不经意的引入,版本号的语义保证并不总是可靠的,唯一可以确定的是软件版本发布后就不可变。
第二个,如何确定哪些 feature 会被包含在下一个版本,如何保证版本计划能够被执行?
这个问题的答案是看情况,没办法客观推理确定。
虽然软件执行的逻辑大部分是确定的,但是软件开发是一个关于人的知识生产过程。从《人月神话》到《人件》,软件工程领域一直以来都在不断强调以人为本的管理理念,但是时至今日仍然有大量的公司在重蹈覆辙。不过,就像其他非确定性的工作一样,虽然我们没有办法像执行程序那样确保版本计划一定按部就班的执行,但是我们还是有一些手段以在社群当中达成共识,最大限度地保障交付高质量软件。
比如,确定研发发布周期。
对于开发活动不那么活跃或者刚起步的项目来说,这点倒不是必要的,往往是社群维护者发现软件已经包含了一系列新的补丁,应当发布新版本了就会开始进入发布流程。这样的软件也很少并行发布补丁版本,往往是线性地递增版本号,如果只包含修复,就递增补丁版本,如果有新功能,就进入下一个次版本。
随着项目聚集起越来越多的开发者,社群维护者总会发现需要在社群当中建立起对研发发布周期的共识,这样才能避免大家都想将自己的变更加入到下一个版本,从而无限延后下一个版本的发布时间。试想,总有开发者会说他的变更将在几天内完成。因此延后几天之后,又会有新的开发者跳出来说他的变更再过几天也能完成。对于一个热闹的项目来说,这并不稀奇,Pulsar 和 TiDB 每天都有十个左右的新提交。
确定研发发布周期,也就是基于时间来发布新版本。比如我见过的分布式系统软件往往以三个月为一个周期,接近周期末尾的时候版本发布的负责人会广播 feature freeze 的消息,也就是在某一天会切出新版本的分支,在那之后分支里就只接受已经包含的功能的巩固和缺陷的修改,不再接受新功能。
至于哪些 feature 会被包含在下一个版本,一般来说,在 feature freeze 并切出新分支之前合并到主干的 feature 就会被包含在下一个版本。当然,也有 feature 的作者对功能不够有信心,主动推迟到再下一个版本发布,甚至把已经合并到主干的部分工作回滚。
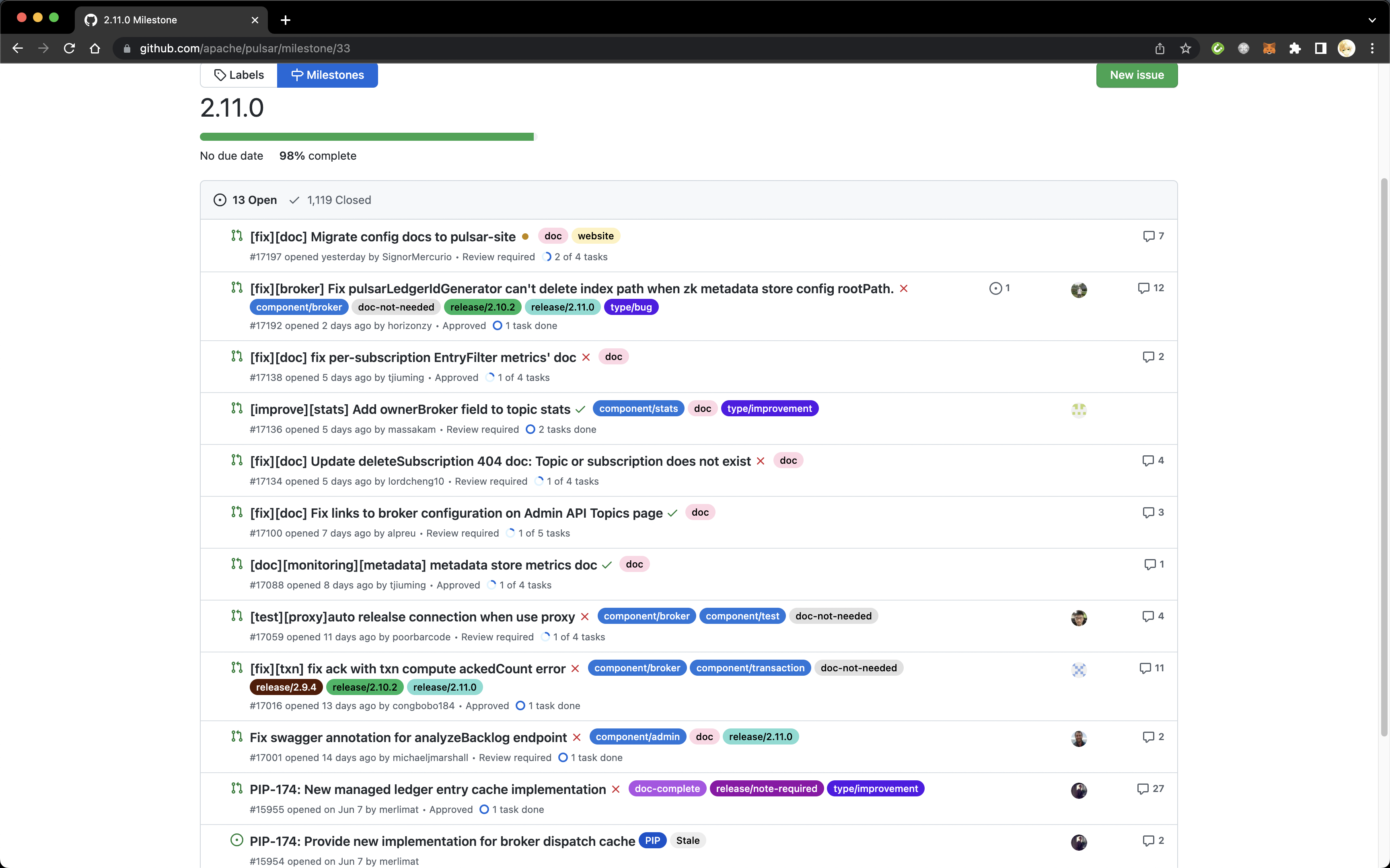
对于项目管理者来说,GitHub 提供了 milestone 功能,可以将 issue 或 PR 和某个里程碑相关联。通常,里程碑就是某个版本。可以从 Issue 页面点击看到项目的里程碑,或者直接输入 http://github.com/ + 项目名 + /milestones 跳转对应页面。下图展示了 Apache Pulsar 目前正要发布的 2.11.0 版本的里程碑,Release Manager 会从这个面板里重点关注仍然 open 的 issue 和 PR 并推动解决,尽数解决后着手打包发布新版本。
Apache Pulsar 里程碑
第三个,项目管理的主要对象有哪些?
前面两个问题里提到的版本发布是主要的迭代流程。不过,项目管理的对象更多还是关注到人及人的活动上。观察社群成员及其活动的维度,方式前面全面评估圈选出的候选人的内容基本重叠。唯一需要补充的是在不知道应该看谁的情况下找到高效开发者的方式。
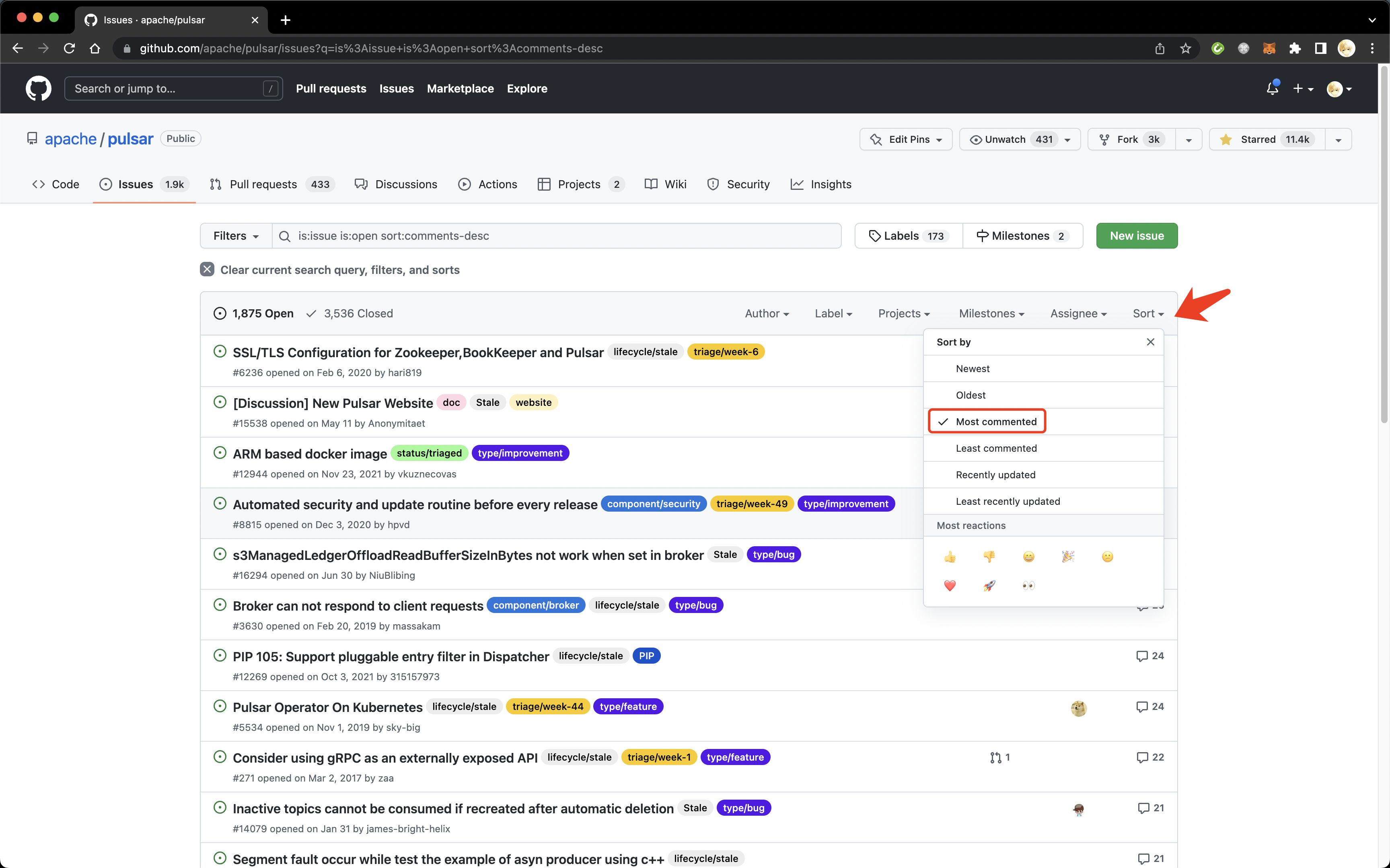
GitHub 仓库本身只提供 issue 和 PR 维度的筛选和排序,Contributions 页面是少有的排序参与者的页面。我们可以从讨论度高的 issue 里找到潜在的高效开发者。以 comments 数量为指标找到最热烈的 issue 可以直接从 Issues 页面点击 Sort 按钮选择 Most commented 排序来实现。
Most commented
我个人比较喜欢的方式,是找到被 requested review 最多的开发者,这些人通常是社群成员公认的专家和领袖。另一个维度是按照年份或月份罗列出某个项目或项目群上最活跃的开发者,以此来描绘出社群生产力的变迁。这些指标就需要额外的开发工作了,我会在闲暇时间逐步在开源小镇的社群看板 页面一个个开发和发布。
还有部分人力资源的从业者对技术研发的流程有着浓厚的兴趣,不仅希望知道项目层面的管理方法,还想知道研发的日常开发流程。
要想了解研发的日常开发流程,最好的参考资料就是开源项目的开发者指南。
这些手册都包含了项目开发者所需要了解的开发流程和最佳实践。当然,本文是面向人力资源的科普,不会展开里面的所有内容。
首先,简要介绍一下开发流程的分类。
开发流程不只是一个笼统的概念,我编写 TiDB 开发者指南的时候特地分门别类的解释。
报告缺陷。流程是发现缺陷的社群成员首先查找是否有同类问题,有则在相同 issue 下报告新案例,没有则重新创建一个。内容包括环境配置,软件和系统版本,复现步骤和预期结果。社群成员共同定位问题,如果不是代码缺陷而是使用问题或理解问题,则直接关闭议题。否则,提交补丁修复后关闭。 议题分类。如果项目参与者众多,每天都有复数的 issue 提交,分类这些 issue 也将成为一个独立的流程。我所知道的最佳实践是按照议题类型和模块这两个维度分出一系列的标签,分类者为议题打上对应的标签,并处理一些简单的情况。比如,要求提交者补充必要信息,或者针对已知的 non-issue 直接关闭。 提交代码。软件说到底是由代码组成,编译而来的。通常所理解的开发流程也是提交代码补丁和评审合并的流程。一般来说,代码补丁的描述里要说清楚解决了什么问题,做了哪些具体的修改。成熟项目一般还会要求补丁作者在改动关键路径或用户接口时明确提出,以及回答是否为代码变更添加测试和文档,如果没有,为什么的问题。 评审代码。提交代码的作者当然需要先做一个自我评审,尽量避免补丁当中包含初级错误,浪费评审人的时间。成熟项目一般要求两个以上有提交权限的人评审过补丁以后才能合并。评审代码总的应该以包容的心态提出建设性的意见,积极鼓励作者做得好的地方。如果补丁不能达到要求或者方向错误,则应该果断拒绝合并。TiDB 开发者指南当中评审代码一节 值得一读。 提出议案。对于重大变更,许多开源项目会要求开发者提出包括背景动机、设计方案、实现方案和相关工作的正式提案。这种统称 RFC (Request for Comments) 的形式可以认为是提交代码的进化版。大多数议案最终还是要靠代码实现,只不过对于重大变更,社群维护者希望明确议案的来龙去脉并正式公告所有社群成员,充分收集意见后由维护者投票决议。决议通过以后,实现过程基本是重复多次提交代码和评审代码。 撰写文档。对于文档即代码的项目来说,这在流程上跟提交代码没什么区别。只是需要掌握的领域知识略有不同。 这其中,我想着重强调的是对背景动机的说明。
不少开源社群的新成员容易上来就怼一个补丁,PR description 放空或者模板一个字不改。我作为维护者看到这种补丁,尤其如果作者素未谋面,基本没有兴趣 review 补丁的内容。
如同我在上一篇文章《饱和沟通:开源社群的消息传递准则 》里讲的,在信息爆炸的时代,大部分人都会先判断这件事情是否与自己有关,是否应该付出时间了解细节。好的 PR description 能够让维护者快速理解提交补丁想解决的问题和补丁做了哪些实际的改动,往往看过描述以后,维护者心里对这个问题应该怎么解,具体的改动应该怎么做会有一个预期。Code review 的过程说白了就是这个预期和 PR 作者实际写出的补丁的一个对比:快速略过跟预期相同的部分,集中在不同的部分。如果只是方式不同效果一样,我一般不会要求改。如果 PR 作者的方式比我想的要精彩,我会忍不住夸赞。如果 PR 作者遗漏了部分内容或者逻辑出错,我再评论指出。
刚开始开发软件的时候,很容易把写代码当成主要的创造过程,在撰写议案的时候不厌其烦地说明如何代码级的实现某段逻辑。但是作为项目的维护者,其实更加关心的是为什么要做这些改动,做出改动的技术方向是怎么定的。很多局部看起来应该做的改动,放到全局可能有着其他原因导致它演化成今天的样子。只要方向决策对了,实现上的改进可以细水长流。很多时候代码变更并不能一次就做好,需要经过一系列细分的步骤逐渐逼近最优的实现。实际上,软件开发主要的创造过程是考虑要不要做某个改动,改动的方向应该怎么定。至于代码的实现,很多时候是个体力活。当然,这不是说代码实现不重要,如果对代码实现的最终过程不熟悉,是不可能在方向决策上做出正确判断的。
有人会问,背景动机这么重要,那么它应该包含在流程的哪个环节里呢?
其实,这个问题同样没办法武断地回答。从最终的结果倒推,对软件施加影响的每一个 PR 都需要讲清楚动机。有些 PR 顾名思义,动机就是“如题”,比如 fix typo 或者升级版本以解决安全缺陷,这样也就够了,不必为了形式主义再弄出些什么别的流程来。其他 PR 在 description 里也都应该说明动机。其中,有些 PR 是一个大的议案的一部分,或者先提出 issue 说明 enhancement 的背景和方法,再有对应的 PR 提交。这种情况下议案或 issue 当中应该包含背景动机的说明,PR 针对相应解决的部分做简述,或者引用前者的表述即可。对于 PR 是修复 BUG 的,动机显而易见,不过修复 BUG 而已。
最后,常说没有文档的代码是只写不可读的,那么文档和代码的关系是怎么样的呢?
原始的问题是“怎么看代码对应的文档,还是应该是看文档对应的代码”。要讲清楚这里面的对应关系,还得对文档这个笼统的概念做分类讨论。
用户文档通常分成概念(Concept)、任务(Task)和参考(Reference)。参考文档主要由 API 文档构成。API 文档和软件代码大抵是一一对应的,代码里有什么接口,API 文档里也就解释什么接口。实际上,很多 API 文档是直接从接口注释上生成出来的。任务文档主要解决的是 how to do x with y 的问题,典型例子是如何在 Python 程序里连接 Pulsar 集群,进而如何生产、消费消息,如何配置鉴权信息,如何关闭攒批发送功能等等。任务文档一般在逻辑上对应一个或多个模块,如果读者具备区分功能模块的知识,通常也能反向找到模块对应的任务文档。不过,如果文档结构组织混乱,任务散落在各个分类下,就很难找了。概念文档基本不再对应到具体的代码,而是对软件领域核心概念的解释。比如 Pulsar 的概念文档主要包括系统架构图,消息队列基本对象的解释,消息生产和消费的关键语义的说明等等。
开发文档除了上面提到的通用流程文档,通常还包括对代码模块划分和各模块职责的解释,这里的模块和代码实际的模块结构是一一对应的。一般来说,只有想要了解系统运行的原理,参与到某个具体模块的开发的成员才会需要阅读开发文档。开发文档和代码的关系也是最紧密的。
对于用户来说,绝大部分情况下他们并不关心“对应的代码”是怎么回事,更多关注到如何解决眼前的使用问题。只要使用体验流畅,对应的代码爱怎么样就怎么样。
限于篇幅,本文到此为止。前半部分面向招聘 HR 的猎头,后半部分面向 HRBP、绩效管理和培训专员,业务团队也不妨一读。如果有意犹未尽之处,或者有其他开源和软件工程相关的问题,欢迎向我提问。