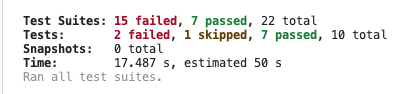
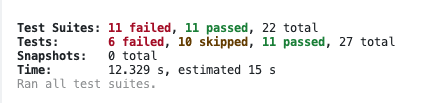
尝试升级 WordPress 版本 和 PHP 版本,然后失败了
尝试把 WordPress 从 5.2 版本 升级到 6.6 版本,把 PHP 从 7.4 版本升级到 8.3 版本。
任务艰巨得完成不了。
非常的崩溃。
前提
我现在的线上的博客,以及线下的开发环境,以及(如果还在不为我知的某个角落存在的话)商用用环境,都是 PHP 7.4 的。
最早些时候,应该算是2015年,正式入坑 PHP ,那时候基本是公司用啥,我用啥。PHP 5.2 5.4 5.6 都用过了,尤其是 5.2 大坑一大堆,摔过很多次。然后到 2016 年的时候终于用上了革新的版本 PHP 7.0。真爽。再后来开始自己独立开发环境,直接开了 DAMP 的坑,最初也是用的 7.0 版本,然后就很随意的升到 7.3 版本,主要是当时开发负担少。然后博客站也都升级到了 PHP 7.3。
再后来 2021 年接了一个外包项目。虽然当时 PHP 8.0 已经发布了,但是貌似周边支持都不怎么地。为了保证开发速度,直接用了 PHP 7.4 版本。当时还涉及到前端开发,Node环境也是大更新,很早之前一直用的各种热门前端库基本都死绝了。博客和本地开发环境也都升级到了 PHP 7.4,博客的 WordPress 程序倒是没变,还是 5.2 版本(这里埋了个大坑),只是偶尔会从官网下载代码包然后手动更新对应的文件,以修复些潜在的安全问题。
现在是2024年年末,就连PHP 8.0 都已经停止维护快满一年了,最新版本 PHP 8.3 也已经发布快满一年了。WordPress 都到了 6.6 版本了,一堆 WordPress 插件都已经停止 5.2 版本的支持了。
想趁着有时间有机会,把 PHP 和 WordPress 都升级了。
天真了。
第一天
首先是把线上的代码全备份一遍。这个毫无工作量,我之前写了个备份代码,直接就把自己的整站扒下来。然后把备份的站再部署到本地的开发环境上,再改几个数据库字段,就完事了。打开后台,先禁用所有插件,以便升级之需。
Apache2 和 MySQL 不用动,因为用的一直都是 Docker 的最新版本,这几年也没什么巨大的兼容性变化。
PHP 这块我不知道算不算麻烦。我把 PHP 从 7.4 到 8.3 的所有 不向后兼容变更 和 废弃功能 全都看了一遍。没多少,就几页,几分钟就看完了。个人感觉这么多变更,只有一条能实际影响到我日常开发工作,就是自 8.0 起不再支持 带有默认值的参数后面跟着一个必要的参数 。

其实个人工作中也很少这么用,因为易读性有点烂。论性能来讲的话这么写性能也很差,只不过以前工作过的公司里就有很多人这么写,主要是为了防止其他同事调用函数忘记传参(空参也是参)。
其余的改动基本影响不到我。我使用的基本都是 PHP 的官方建议用法,最多也就是会遇到某些外部库被遗弃然后有个平替的情况,比如数据库接口啥的,即使出错了立刻就能发现。
于是很自信的先把 PHP 环境升级到了 8.3 。因为是基于 Docker 的所以也完全不用担心环境污染的问题。
然后就崩了,WordPress 就打不开了。
这倒是意料之中,毕竟当年 WordPress 4.3 版本当年连 PHP 7.0 都不支持。我现在用的是 5.2 版本,最高能支持的 PHP 版本也才 7.3 ……

什么?7.3?但我已经用 PHP 7.4 跑了 WordPress 满 3 年了啊???
什么兼容性测试……
下载了个 wordpress-6.6.2 的包,按官方文档手动安装。 崩得一塌糊涂
全部删除了重新来,这回用官方的自动升级功能,直接从 5.2 升级 6.6。真神奇,WordPress 官网被墙了这么久了竟然能秒下 WordPress 的安装包,我也不知道他是走的什么渠道。PHP 就这点恶心,前台所有操作你都看不到任何细节,就像是在用 Windows 一样。
成功安装。然后 崩得一塌糊涂 。这回不仅崩得稀烂,而且由于没手工删除后台的旧文件,新旧文件混在一起,更是手足无措。
就这么搞了超过6个小时,一直干到后半夜三点多,搞不定。
放弃,睡觉。
然后严重失眠,抽搐。

第二天 白天
首先考虑下到底是 PHP 的问题还是 WordPress 的问题。
按理来讲我已经把 PHP 的升级文档都看完了,并没有什么会天塌一般的变更,但是 WordPress 这边的确天塌了。
先在 PHP 8.3 环境下运行一下我的其他项目看看,结果我的个人主页就崩了。

我用的是 2023 年 3.1.48 版本 的 Smarty,其基础版本是给 PHP 7.0 做的,可能旧了吧。
下载了最新版本的 smarty-5.4.1 ,然后

什么玩意? implode is Deprecated ,我怎么不知道?
又去重新看了一遍 PHP.net 官网的 implode 文档和 PHP 升级文档。根本没有 Deprecated 。
然后在网上搜了一下,发现是 Smarty 的锅。而且 Smarty 还在 join 和 implode 之间反复横跳。更恶心的是,implode 和 join 在 PHP 7.4/8.0 中已经声明并废弃了 先数组后分隔符 的用法,但是在 Smarty 中却是强制要求 先数组后分隔符 ?甚至官方在 issue 里来来了句 Smarty is Smarty and PHP is PHP. 有病吧。而且你就算有病,你特么连个文档都没有,谁知道你有这种抽风的设计啊。
你要知道之所以我还用 Smarty 这种超级古董,就是因为这是一种 靠谱的、前后端分离、完全后端渲染、仅需要 HTTP 和 PHP 环境、不需要臃肿框架和特定语法,的网页渲染模式,是提供给搜索引擎最靠谱的传统模式。没有网页模板系统的话,想写这种纯后端渲染前端显示的页面,就只能 php 和 html 代码混写,非常的恶心。
现在 Smarty 抽风了,真就不知道以后还怎么不依赖框架写这种页面。我搜了下,Laravel 的 Blade ,和 Symfony 框架下的 Twig,貌似也可以独立使用,但是我对 Laravel 和 Symfony 基本一无所知,作为一个 PHP 开发者真是有点丢人。
话题扯远了,回到刚才。
我目前是不太想动我的个人主页的,这 WordPress 是大头,是主要内容。主页只是个入口。虽然主页改动起来并不困难,代码量少,Smarty 抽风的部分比较好找。但主页这一块我其实并不满意,主要是多语言这块用的传参而不是独立页面,很受搜索引擎嫌弃,基本上没收录,收录的也搜不到。但我的确没有精力和欲望去重做。
另一方面,WordPress这边,崩溃得最多的部分其实是插件。WordPress的代码质量本来就很堪忧了,第三方插件更是三脚猫,各种天花乱坠的不规范语法,可以说基本上都不能在 PHP 8.3 上运行。
另外我虽然看了 不向后兼容变更 和 废弃功能 ,但是 PHP 新版新增的语法糖也有点天花乱坠。我用的是最新版的 php-cs-fixer_v3.64.0 ,没配置好的话就会把那些插件的奇葩写法转写成 8.3 的语法糖,有时结果更是瞎眼,基本没有易读性。
综上考虑,先放弃 PHP 8.3 的升级。先把能通的条通。PHP 的升级难度应该不是最高的,但是底下这些撇不掉的小垃圾目前是必须要保且支持不到 PHP 8.3,没精力做修改。
放弃 PHP 8.3 继续用 PHP 7.4 。
第二天 晚上
看兼容性列表,WordPress 6.6 也是支持 PHP 7.4 的。
但是实际上 API 改动实在太大了,而 PHP 前端应用最恶心的一点,就是 出错了,不报错 。
即使开启了 define('WP_DEBUG', true); define( 'WP_DEBUG_LOG', true ); define( 'SAVEQUERIES', true ); ,也经常是
- 功能好像开了但是没开
- 功能好像崩了但是啥日志都没有
- 功能正常使用但是页面上打了一堆不知道哪里来的错误日志
面对如此大的一个工程而大部分代码逻辑都是不可靠的。升级到 6.6 实在是消受不起。
放弃 WordPress 6.6 ,只升级到比较近的版本。
要不然试试 5.5 吧,毕竟我在用的一款插件,作者自评最高支持到 5.5。
下了个 WordPress 5.5 的安装包,装完了。崩,但是崩得没有 6.6 多。
主题 graphene
不开插件,只看主题,首先就是文章的评论显示不出来。检查后发现是评论的API变了,而我的主题 graphene 是 1.9.4.3 版本的,不支持 5.5 。

有时候看其他人的代码就是折磨,代码里写法五花八门,空格TAB混着,一会拼接字符串,一会替换字符串。单引号双引号混着用,左边括号有空格,右边括号换行了。
说实话我都不知道这算不算改好了,反正现在是能显示出来。我更担心的是其实还有哪个不知道的角落还有错,但是看不到,毕竟 PHP 前端 出错了 不报错 。
官方倒是有个新版的 graphene,但是我现在用的这个主题就是我大量改动过的,因为 graphene 原版的代码实在是, 太错了 。好多代码完全不符合前端的理念。然后是颜色和界面也是要一点一点从设置里调,那复杂和麻烦程度,说真的我更乐意重写 HTML 和 CSS 。
我真的想过很多次自己做一个 WordPress 主题,这个想法可是足够老了。但是当时 WordPress 3 版本的主题文档就恶心到我了,真的超级麻烦。而到如今就 WordPress 现在的代码质量,我估计开发主题会更困难更恶心。
也是怪不得其他更轻量的博客程序能后追直上。
插件 Disable WordPress Core Updates
接下来是 Disable WordPress Core Updates 这个插件。
这个插件是为了禁用 WordPress 的界面更新的。但是其实只有一行有意义的代码:
add_filter( 'pre_site_transient_update_core', create_function( '$a', "return null;" ) );
首先 create_function 这个函数在 PHP 7.2 废弃,在 8.0 中删除,所以我改写成了。
add_filter('pre_site_transient_update_core', function ($a) { return null; });
然后就见证奇迹了。能用是能用,但是 pre_site_transient_update_core 这个字段我在整个 WordPress 代码中都没找到。为什么做一个 pre_site_transient_update_core add_filter 就能抑制 WordPress 界面提示升级? 魔法啊?
然后开启这个插件的时候,更新页面是崩的。

魔法。
插件 NIX Gravatar Cache
接下来是 NIX Gravatar Cache 插件。
这是个把 Gravatar 头像缓存到本地服务器的插件,只不过早就死透了。我当时随便改了点代码对付着用,大部分时间没出错也就那样了。
首先是这段代码。(红色部分是我添加的改动)

不能直接执行 wp_enqueue_script 和 wp_enqueue_style ,要先执行个 add_action('wp_enqueue_scripts', 引用能调用那俩玩意的函数); 。外国人看这种超长的单词时不会眼花吗?
然后是这么一段代码。

WordPress 的 register_啥啥啥_hook(__FILE__, array($this, '函数名')); 写法全都作废了,要改成 register_啥啥啥_hook(__FILE__, array($this, '函数名'));
接下来底下那一节:
- 假如 路径不可写 且 路径为目录,报错
否则
- 假如 创建目录(权限777)失败 且 路径不为目录,报错
就这烂判断条件看得我脑子都快炸了也没弄明白为什么这破玩意能在我线上服务器上跑几年没报错,而我本地开发环境却根本跑不通。

而且这玩意讨厌就讨厌在于,确在我的测试环境下报错了,但是 WordPress 只是多了个 .php-error 的样式并且高出来 2em 的一节,但是一点错误日志都没有!!! 出错了 不报错 。
最后还是靠自己写 debug 代码定位的问题。
这 TM 都是些不该是问题的问题,竟然多得到处都是。
2天,一点有效进展都没有。唯一有效收获就是这些屎山不碰就没事,一碰能崩得全身是屎。
反而自己写的没有引用那些垃圾玩意的插件和程序,没发现啥大毛病。
第三天
2天没啥进展,给我干懵了。
俗话说没事别升级,升级必出事。
原本的想法是先试着升级,如果不能平滑升级的话,大不了全摧毁了,然后把整个博客文章用导入的方法塞回去重建。如果插件出问题了,大不了找找看是否有新的替代品。结果搜了一下,靠谱的插件基本没有,一大堆商业推广的插件,和一大堆复合性插件,而且这些插件无论对 5.x 版本 还是 6.x 版本的兼容性都乱七八糟,问题解决不了,还有可能引入更多的问题。主题这边则是更不想换,一方面本身现在用的主题就是我大量修改过的,因为网上的各种主题,仅安全性就一塌糊涂,更别说 HTML 标准了。我这主题还是专门针对 1366×768 分辨率优化过的,能在 小屏幕 150% 比例正常显示。让我再去改个新的,工作量也是太大。
现在基本上没辙了。
PHP 这边其实还行,而且版本活跃度比较稳定。

在 https://packagist.org/php-statistics 能看出各版本使用占比都跟维护相关。但 7.4 版本 比 8.0 版本还受欢迎 属实乐了。
但是周边应用真的是质量山体滑坡。WordPress自 3.0 版本就开始崩,后面很多发展都很魔幻,就连编辑器都是靠社区兜底,到现在已经想不清楚这玩意的产品路线是啥了。
其他生态我也不清楚,毕竟作为一个 PHP 开发,我连 Laravel 和 Symfony 都没用过,商用产品都是用 ThinkPHP 应付的,当然最爽不过不依赖框架没有条条框框自己从头写。
但是像 Smarty 这种原行业标志都走奇葩路线了。可以说整个IT行业,基本上,正常的元老人物都退出舞台了,剩下的这些,刨去臭鱼烂虾,就只有偏执而扭曲了,假若走向歪路,那就没得旧,而这一点在开源社区上也极为明显(因为闭源商业的死不死没人关心),Godot 基金会开搞政治正确炮轰特朗普和动画头像用户,Linux 基金会直接开踢俄罗斯的代码贡献者。IT 行业现在就像是一个患了早期癌症的癌细胞轻微扩散病人,看似有救但却是谁都不想救。
结论
给我干哑火了,懵逼了,现在不知道咋整了。
The post 尝试升级 WordPress 版本 和 PHP 版本,然后失败了 first appeared on 石樱灯笼博客.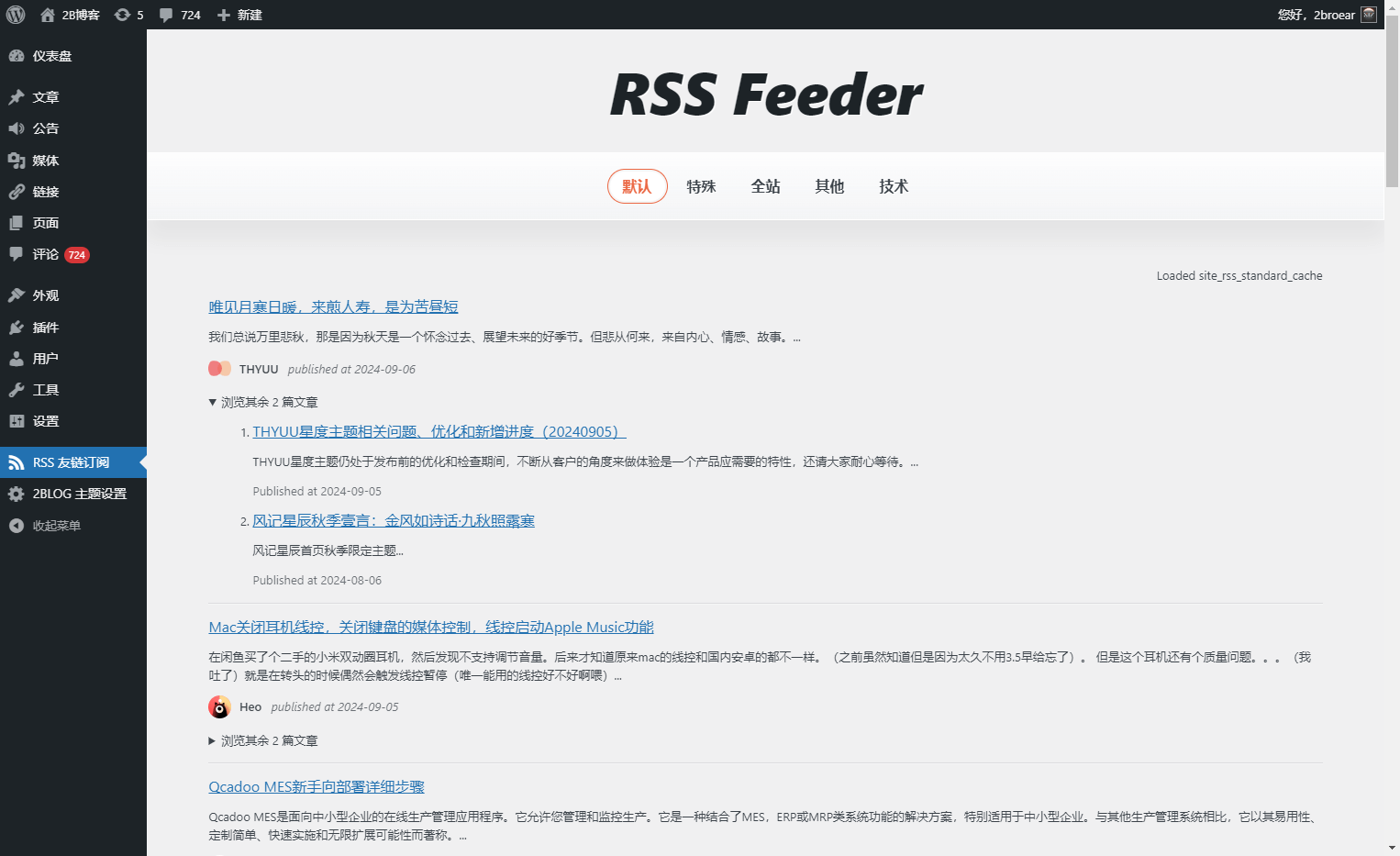




 使用 localStorage 修复了授权用户操作失败(弱网、并发)后再次访问时自动更新本地/远程记录。bug:
使用 localStorage 修复了授权用户操作失败(弱网、并发)后再次访问时自动更新本地/远程记录。bug: 更新方案(v1.3.9.5):标记或删除后等待远程响应,返回后再写入(补全)或删除(更新)本地记录,对应逻辑如下:
更新方案(v1.3.9.5):标记或删除后等待远程响应,返回后再写入(补全)或删除(更新)本地记录,对应逻辑如下:
 动画)bug: 每次接收数据后输出时未即使更新data
动画)bug: 每次接收数据后输出时未即使更新data