其实“快 2 倍”这个说法,好像也是当年乔布斯在发布会上吹出来的(也可能是当年某本苹果杂志的编辑写出来的)。最早苹果在宣传广告中提到,PowerPC G3 比当时的奔腾 II 要快 2 倍;后续说 G4 比奔腾 III 快很多;G5 比奔腾 4 快很多。差不多就是这样。(我高中时期,时代一脚刚刚跨入到奔腾 4 等灯等灯)
当年乔布斯曾经公开对比过 Mac 和 Windows PC,对比的方式是双方自动执行一组 Photoshop 任务。当时 Mac 以快得多的速度完成工作,碾压奔腾处理器的 Windows PC……当年奔腾正在搞超长流水线,处理器主频不知道飞跃到哪里去了。PowerPC 那会儿走的线路更偏宽核心,频率是低很多的。苹果那一时期还做过一个叫“The Megahertz Myth”的宣传,主要就是教育公众,别迷信时钟频率。
拿某些固定工作单元去比性能的意义,其实没那么大,尤其是对通用性很重要的 CPU 而言。这一例中,且不说究竟有多少程序代码能用上 AltiVec 单元(就像现在很多人质疑 AVX512,说用不到它);应该要比的还是日常消费用户比较频繁的操作,在效率上怎么样。苹果日常就非常善于呈现一些他想让你看到的数字,虽然没在说谎,但也未展示事物全貌。
MacBook Pro
我觉得,在 CPU 通用计算发展思路,该用的技术基本上都用过一遍以后(比如乱序执行、分支预测、超线程等近代技术),CPU 单线程性能推进本来就遇上了瓶颈。这时候是需要引入专用处理单元的,这也是一个常规思路——典型的像是在 GPU 领域,NVIDIA 为光线追踪引入了专用处理单元,这是提升性能和效率明显收益更高的方案。
苹果面向消费用户,或者目标群体时,一向都十分清楚自己需要针对硬件(或软件)做什么样的强化。所以事实上,苹果自己掌控处理器的设计,对目标群体的确是一件好事——就像它也掌控操作系统和软件一样。比如历史经验告诉我们,大量 Mac 用户用苹果电脑来剪片子,而 Final Cut Pro 在软件优化上的苹果平台加成,就是 Premiere 和 Davinci 都望尘莫及的,不管是视频编辑时的实时渲染、编码预览,还是输出速度。硬件层面为此若进一步做加成,还能再度提升效率。
iPad Pro 实现一些简单视频后期,效率明显比 x86 的 MacBook 更高,即是这一思路的集中体现。不过我也始终觉得,这种思路是有明确目标用户定位的。大部分人,并没有这些需求,如果我压根儿不用 Photoshop,那么像 AltiVec 这样的专用单元只能成为一种资源浪费。至于很多人,把这类思路解读为苹果在芯片设计上的黑科技,那也大可不必;毕竟 Intel 在服务人群的思路上和苹果是大相径庭的;就像高通也不可能面向 Android 阵营极为草率地,推出一颗性能与苹果 Ax SoC 相当的产品一样。
Arm 效率真的高过 x86 吗?
自从苹果宣布 Mac 要开始用 Apple Silicon,就一大堆媒体说了,看那个 iPad Pro 牛逼坏了——A12Z,一个功耗那么一点点的处理器,性能那么彪悍了,要是苹果给它提个主频、核心数,那岂不是立马把 Intel/AMD 之流轰出地球了吗?
有关这一点,早前的文章《MacBook 要采用 Arm 处理器,难度有多大?》我也用一个段落提到过,即 A12/A13 这些芯片的能效比,似乎还挺美好的。但实际上,如果苹果给这些芯片暴力提频,提到桌面处理器的程度,则其功耗和能效也会立马崩边——因为频率提升,越往后,给功耗带来的压力就会显著更大,而不是平缓变化的。当然我觉得这种描述略有些片面了。
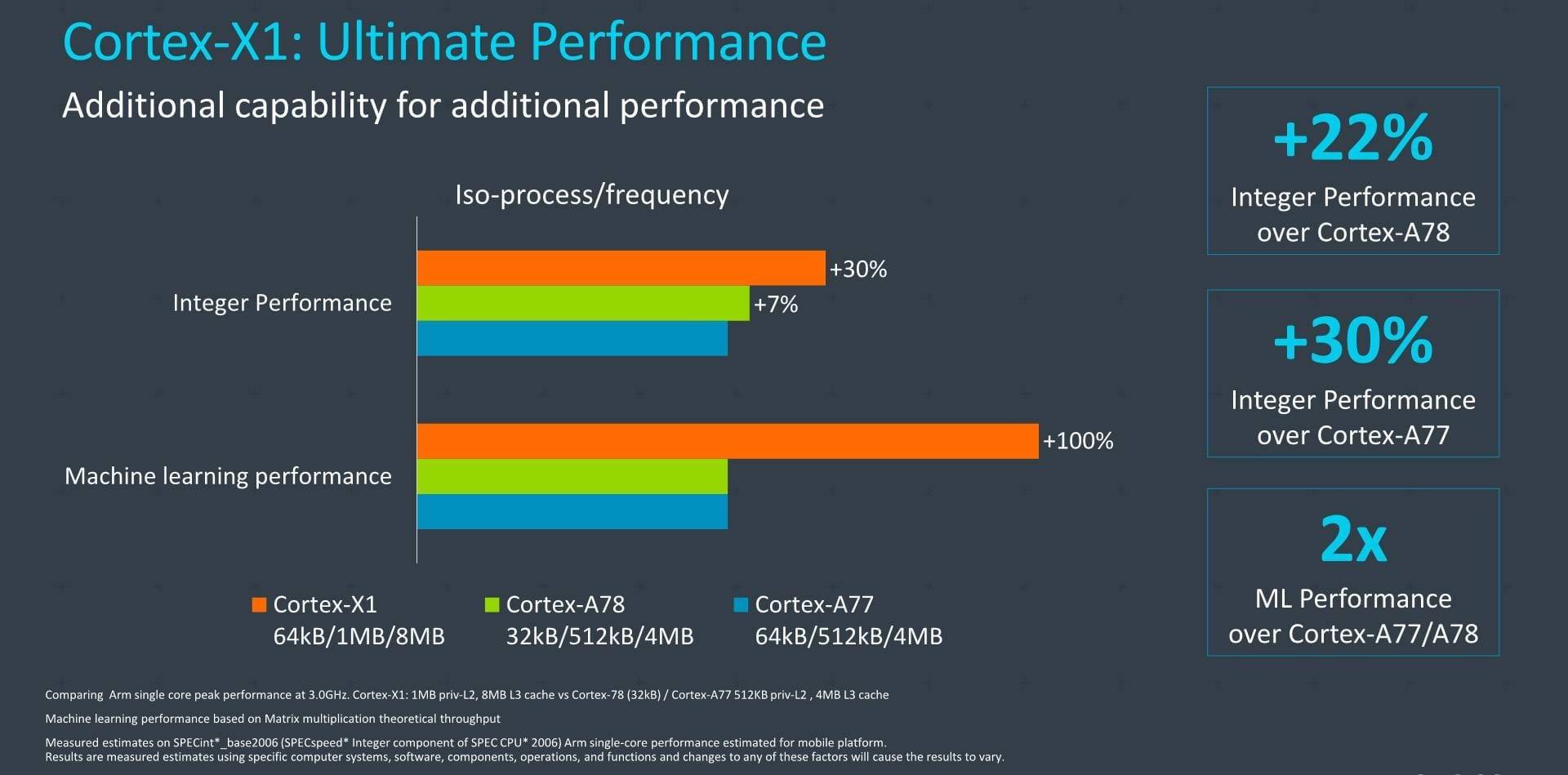
我们还可以来看看 Cortex-X1 的设计——就是前不久 Arm 发布的一个微架构 IP。这个微架构被 Arm 设计出来的初衷,很大程度上就是面向高性能的。而且需要注意的是,它是以一定程度牺牲功耗和能效,来提升性能的——这跟 Cortex A78 的设计就很不一样。Cortex A78 是纯面向移动平台的那种传统核心,就是必须在 PPA 上做权衡,面积、性能、功耗都必须考虑在内,做到针对手机这类设备尽可能的最优解。
Arm Cortex-X1 与 Cortex-A78/A77 微架构性能对比。其实我也挺想说,CPU 层面增加一些扩展指令集的能力,包括上面这张图列出了机器学习性能提升,也表明:现在很多人认定,x86 CPU 增加 AVX512 这样的支持没有必要,是在浪费芯片尺寸和功耗(Linus Torvalds 为代表),而应该完全让专用处理器(比如 NPU、GPU)去处理这些事——这类想法可能是十分片面的
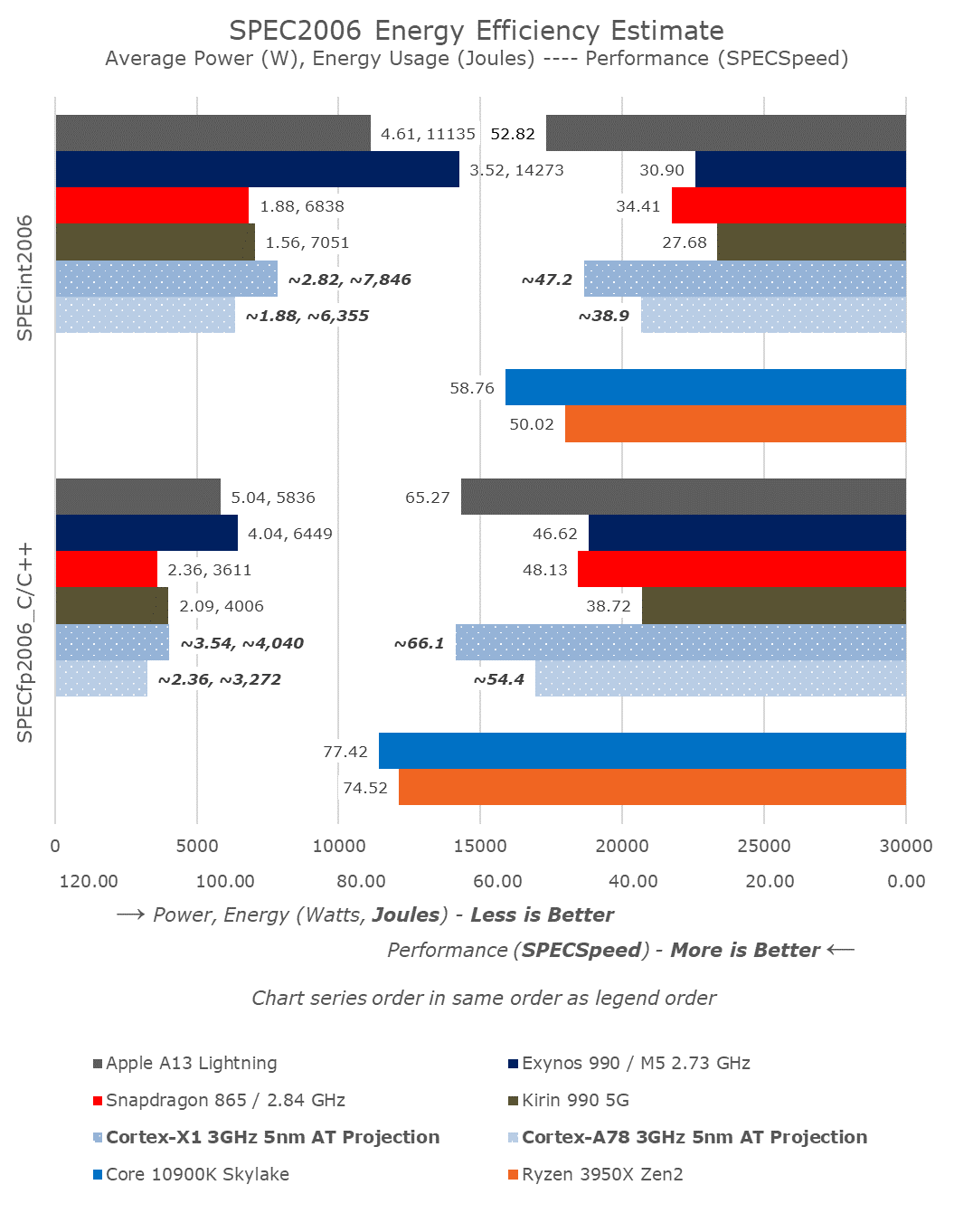
AnandTech(Andrei Frumusanu 博士)假想的一张图,可以表示 Cortex-X1 3GHz 5nm AT Projection(蓝色点状条)的能耗与绝对性能情况。这张图的左边柱状条表示的是 SPEC2006 测试全程消耗的能量(单位:焦耳),柱状条右边有两个数字,一个是平均功耗(单位:瓦特),另一个就是柱状条长度表示的能量(单位:焦耳)。右边柱状条则表示绝对性能,即跑分数字。
但这至少表明了 Arm 并没有什么黑科技,像很多人想象的那样,跟 Intel x86 比起来效率高到天上去——上面这些数据还是在台积电的 5nm 工艺不要出什么大纰漏的情况下;Arm 要做高性能,牺牲效率和功耗也是必须的,这事情真不像很多人想的那么简单,苹果做个高性能处理器就等比放大下 A 系列处理器就可以的。
之前我写 Mac 要用 Arm 处理器有多难的时候就提到过了,性能提升和功耗提升,这不是线性的关系。把 A12Z 提到 3GHz 频率,你看它功耗会崩到哪里去…
所以针对以上段落的总结是:苹果给 Mac 上自家芯片自然是好事——这里的“好”,体现在苹果收拢自家生态,Mac 迭代节奏也能完全掌握在自己手里;更重要的是,面向目标群体(比如做设计的、vlogger、搞摄影的等等)实现硬件层面更高效的支持,因为苹果可以更具针对性地去做硬件和芯片,Mac 设备的体验也因此可以更好。这也是苹果一直以来,对生态掌控力的固有经验——iPhone 即是这个思路下的产物。之所以等到现在,Mac 才使用 Apple Silicon,也是因为苹果现有的技术储备已经足够。
但这并不意味着,其芯片技术领先到了哪里去,更不表示 Arm 现如今在桌面市场比 x86 平台已经表现出了多大的技术优势。
番外:苹果需要做几颗处理器?
苹果用自家处理器,另一个我觉得挺现实的问题是,Mac 产品线有那么多不同的产品,比如 MacBook Air/Pro、iMac、Mac Pro 之类。如果要全线用自家芯片,那是不是要做一堆不同型号的处理器出来?
好吧,就算苹果能通过芯片体质的 binning 来自己划分个 A14-a,A14-b,A14-c 几个档位的 SoC 出来(比如针对较弱体质的就屏蔽掉两个核心之类的,或者用更低的频率,用在低端产品线上,那这样还节约了设计成本,桌面 CPU 本来也是这么搞的嘛)。问题是,Mac 一年的销量才多少(而且还要划分不同设备类型的不同芯片)?
Mac 年销量才多少?开一个 5nm 的产线要多少钱?如果走不起量,就不可能用得起最先进的制程。去年 Mac 全产品线的销量是 1800 万台左右;iPhone 预期是在 1.9 亿部上下。这个就有 10 倍出货量差距。
如果给 Mac 重新设计高性能处理器,这里面的设计成本负担其实也非常高,尤其是配合每年的最先进制程——每年还要迭代,苹果又不是专门做芯片的,没有客户摊薄成本(这一点和 Intel、高通这些厂商就显著不同);生产成本已经说了,走不走得起这个量,我觉得有兴趣的同学可以算一下(苹果肯定也算过这笔账了,或者苹果有某种高端的解决方案,衰 O_o)。
当然苹果也可以不去刻意设计高性能处理器,比如跟 iPad 用一样的处理器,或者也就改个款,或者可能有什么黑科技,规模化放大设计(有了解芯片设计的朋友跟我说,有这样的可行性)…那我觉得这样的话,至少就现在来看,苹果的 A 系列芯片起码在通用性上,日常操作在 Intel 面前真没什么特别的效率、性能优势(虽然 Intel 现如今正在渡过自己非常难堪的一段时间)。
Mac Mini
另外,在 GPU 方面——看很多分析文章提到,未来苹果极有可能完全采用自家集成在 SoC 内部的 GPU,放弃 AMD 家的独立 GPU 设计——这一点从苹果现在的开发者文档能看出些端倪,AMD、NVIDIA 统统被苹果归到旧款 Mac 设备行列了,这也符合苹果一贯以来的尿性;毕竟苹果的 Metal API 也搞这么久了。如果是这样的话,Radeon GPU 还真是做了这么长时间的嫁衣——可见老黄不愿意支持苹果 Metal API 的决策是正确的…(逃
这篇文章谈的比较散了,真像 Intel 的软文——实际上,我的确不希望 Intel 在 PC 市场没落。
关注苹果 MacBook Air 产品线的同学应该知道,从前两年开始,MacBook Air 已经换上了 retina 显示屏,设计也改头换面了。不过在产品线布局上,MacBook 系列发生了一些变化:12 寸 MacBook 已经退出人们视野(这个产品系列应该已经开始和 iPad Pro 打架了,所以退出也是必然的),MacBook Air 正式接棒了 12 寸 MacBook 的 fanless 无风扇设计。
说是无风扇设计,其实 MacBook Air 还是有风扇的,只不过这个设计相当奇特——后面我们再谈。但有一个核心资讯是 MacBook Air 用户需要在意的:如今的 MacBook Air 全部采用 Intel 超低压酷睿 Y 系列处理器。注意是超低压,而不是低压 U 系列(MacBook Pro 13″ 一直在用低压 U 系列)。也就是说,MacBook Air 已经正式成为 Mac 家族中性能最弱的设备,加上其价格——尤其 2020 款 MacBook Air 起价 7999 元,MacBook Air 成为了 Mac 系列中最低端的一个系列。
这也算是产品布局的一个精准调整了,当年乔布斯从信封里拿出 MacBook Air 之时,这个产品的价格可实在是不菲的,定位绝对不亚于 MacBook Pro。
总之,MacBook Air 现在在用的处理器是一种更省电的方案。TDP 9W 听起来好像的确可以不需要风扇了,人隔壁 iPad Pro 的 A12X 大概 7、8W 的平均功耗就没风扇。当然了,这里咱不说,这个 TDP 本身现在所具备的参考价值可能越来越脱离于其原本热设计功耗的意义,毕竟现在大家都把睿频当基频在看,连什么 cTDP up/down 之类的数据看起来都不靠谱。
来源:iFixit[2]
不过 MacBook Air 从改头换面以来的风扇设计就相当之奇特,上面这张图是 2018 款 MacBook Air 拆开后壳以后的内部结构图。内部左上角位置显然就有风扇,不过你知道 CPU 在哪儿吗?CPU 本尊并不在风扇附近,而在中央那块散热片下面,下图用红框将其标出了。
CPU 上方的散热片
需要注意的是,从各种拆解来看,CPU 之上并没有一根导热管连接至风扇。那么这枚风扇究竟在给谁降温?迷之风扇!针对这个问题,我查了一些资料,发现网上对此的猜测颇多。YouTube 有一些技术向的 up 主提到,这颗孤独的风扇 “just for ventilation”,它负责带走 MacBook Air 内部主板的整体热量,而且在内外造成气压差,这样内部也会主动“吸入”一些冷风。
Reddit 上面也有一张帖子是专门讨论此事的[3]:这张帖子是针对 2019 款的 MacBook Air,表明这种设计后续没有变。这张帖子里有人提到,这种设计可能是依赖于内部的密闭结构,空气流向通路上会带到 CPU 上方的散热片。不过无论如何,这种设计针对 CPU 的散热效率都是比较低的,可能与 MacBook Air 追求极致轻薄有关(但实际上我们后面还会提到,MacBook Air 如今真的不能算薄)。
单就 CPU 而言,这还真的算是 fanless,因为虽然有风扇但却不是针对 CPU 的;所以 CPU 真的仍然可以说是被动散热;或许在超低压处理器范畴内,这种设计是合理的,真的是这样吗?
与 MacBook Pro 的性能差距
网上已经有部分 up 主,包括上周我在参与 WEB VIEW 的播客节目时,都谈到了,今年的 MacBook Air 真的十分超值;主要是因为 SSD 最低容量升级到 256GB,内存也换用了 LPDDR4x,存储性能会有较大提升(虽然 MacBook Air 的 SSD 速度一直以来都比 MacBook Pro 慢一截);另外就是处理器更新到了酷睿十代,除了最低配的酷睿 i3,更高 i5 配置都开始改用四核处理器(所以苹果宣称快 1 倍),核显也明显上了一个台阶。而且,价格更便宜。
就纸面数字来看,我之前甚至还提到,2020 MacBook Air 已经比 2019 MacBook Pro 13″ 更牛了。不过当时我并没有意识到,2020 MacBook Air 用的虽然是四核处理器,但却是超低压版的酷睿 Y 系列。而 MacBook Pro 用的是低压酷睿 U 系列(2019 款 MacBook Pro 13″ 用的八代酷睿低压 U 系列)。那么除了 TDP 功耗数字差异,这两者到底如今是个什么样的关系呢?
2020 与 2019 款 MacBook Air 内部结构对比,来源:Max Tech
另外,Max Tech 的拆解已经提到,2020 MacBook Air 仍在沿用以前的模具(chassis),所以上述这种加了个风扇,但不吹 CPU 的设计仍然存在,如上图所示。
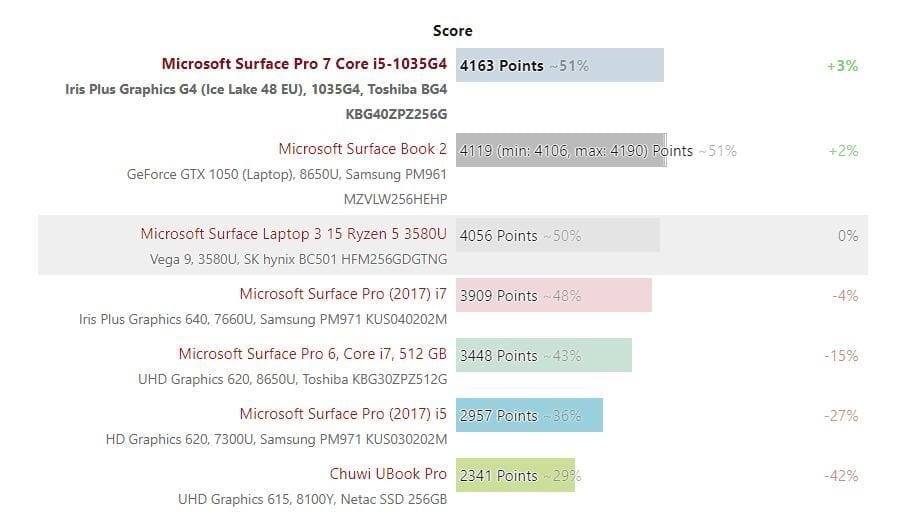
Intel 酷睿 Y 系列四核处理器,没风扇能镇压吗?其实从理论上来说问题也不大,被动散热中的典范是 Surface Pro。之前我花了很大的篇幅来探讨无风扇的 Surface Pro 性能如何,结论是无风扇的 Surface Pro 相比同配其他有风扇的超级本,持续性能差距大约有 25%[4]。即便如此,Surface Pro 的表现依然令人满意,可以认为是被动散热设计中的楷模。而且 Surface Pro 用的还是酷睿 U 系列即低压版的处理器,MacBook Air 用的 Y 系列更不成问题了吧?
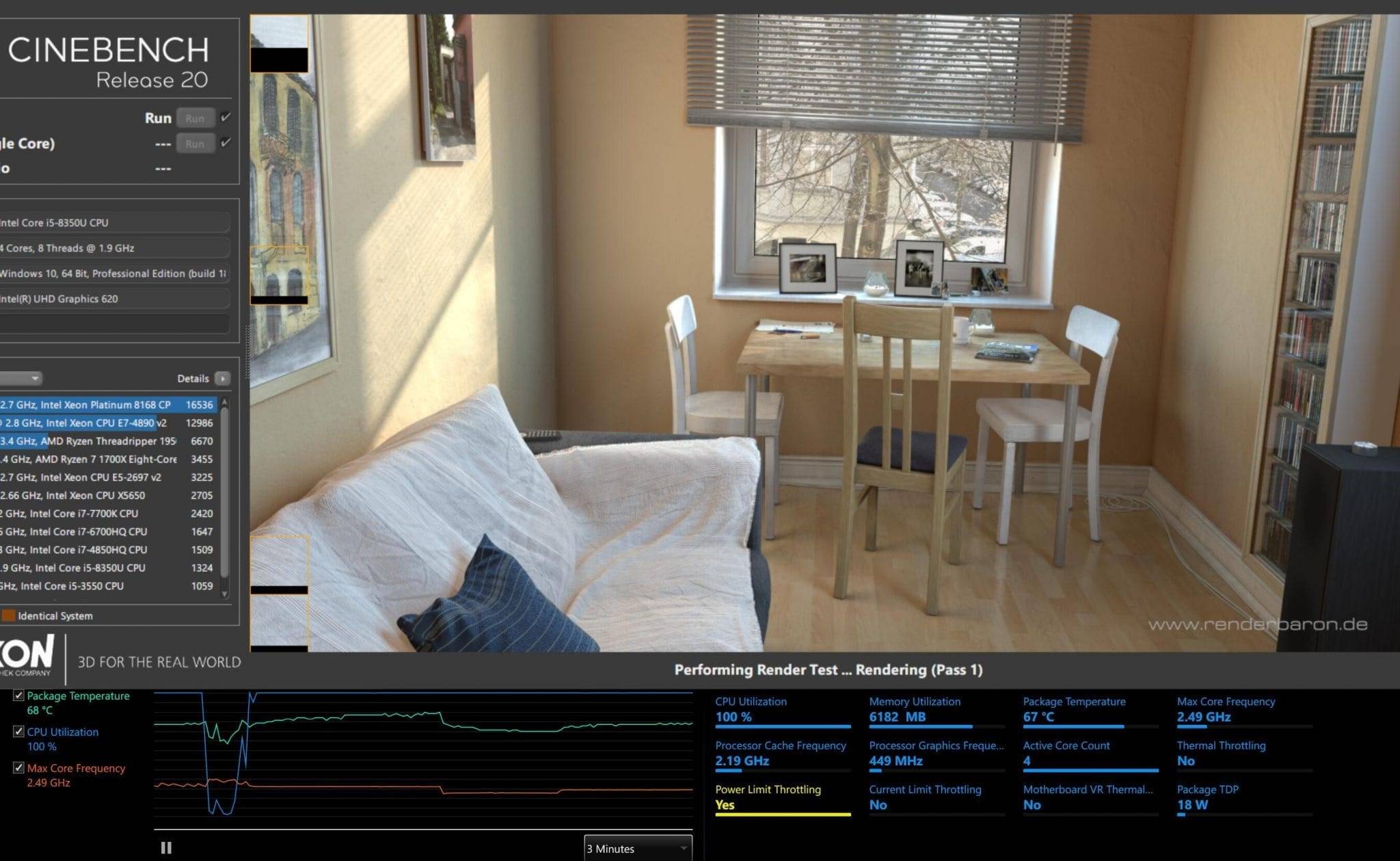
市面上貌似还没有可参照对比的十代酷睿 Y 系处理器实际性能,所以我们就只能看 2020 MacBook Air 自己的实际表现了。严肃技术向的科技媒体还没有十分严谨的测试数据——NBC 的数据库里面也还没有这几款 CPU 的成绩,这里我捡一些不够可靠的分数,都是 CineBench R20 测试:
Luke Miani 给 MacBook Air 酷睿 i3 版(Core i3-1000NG4,双核)的测试得分为 640 分,酷睿 i5 版(Core i5-1030NG7,四核)测试得分大约在 1060 分左右 ;但 Max Tech 针对酷睿 i5 版的测试得分一次是 863 分,一次是 1019 分 ——我猜这可能与设备测试前的运行状态有关(真心是不负责任的 up 主啊!),这里的 863 分很有可能是持续性能成绩,而超过 1000 分的成绩则是在设备温度较低时第一第二轮跑分能够获得的成绩。
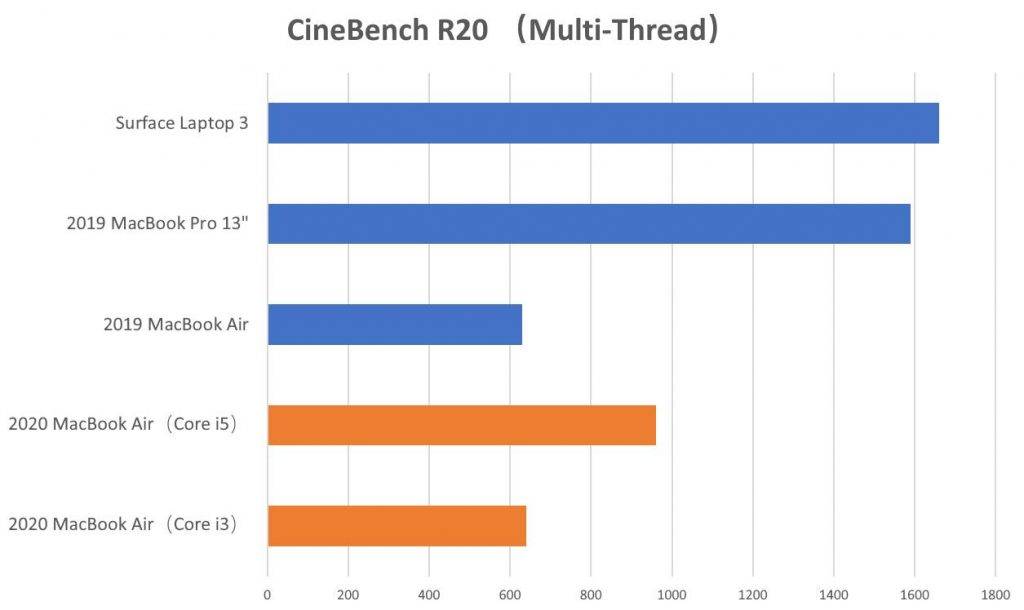
MacBook Air 与 MacBook Pro 13″ 的 CineBench 测试成绩
毕竟不是什么正经测试,那我们就取个中间值吧:960 分——恰好和一家日本测试站点 PC Watch 给的结果差不多 [7]。上一代的酷睿 i5 版(Core i5-8210Y) MacBook Air 的 CineBench R20 得分为 632 分[8]。所以粗略估算,2020 MacBook Air 酷睿 i5 版相比上一代的 CPU 性能提升幅度大约是 52%-60%,也算是很给力的成绩了(知乎上貌似有数据说是提升 200%,不知这个数据是怎么来的;另 Geekbench 5 多核测试成绩有将近 80% 的性能提升)。当然我们暂时还没有机会了解多轮测试的持续性能表现。
不过这个成绩相较酷睿低压版 U 系列处理器还是有着相当大的差距,比如 MacBook Pro 13″。这里放上 2019 款 MacBook Pro 13″(Core i5-8279U,八代酷睿低压处理器)以及我自己测试的 Surface Laptop 3(Core i5-1035G7,十代酷睿低压处理器)成绩对照,如上图。
GPU 核显部分其实也是这次提升的一个亮点,尤其酷睿 i5 版用上了满血的 64 EU(不过考虑到 Y 系列超低压处理器的 TDP 限制,我猜其图形性能应该还是会低于 U 系列的低压版)。不过那些 up 主的数据感觉都偏离很大,而且也不标测试工具版本和测试环境。PC Watch 给的数据是,Unigine Valley Benchmark 1.0 测试中,2020 MacBook Air 相比上一代平均帧率提升将近 1 倍——这也基本符合我们对于这次 Iris Plus 提升的认知。在 Max Tech 的 Geekbench 5 Metal 测试中,2020 MacBook Air 相比上一代得分大约有 1.2 倍的提升。
其实针对 GPU,也很想加入 Surface Laptop 3 对照(就能看看同样是满血版 G7,低压版和超低压版上的 Iris Plus 核显有什么差别了),不过这些媒体完全不说测试对象,比如测试 API 是否用的 OpenGL,高画质、抗锯齿与否等,所以我也没法测(而且我的测试也一向那么那么不严谨O_o)。不过从早前笔吧的十代酷睿核显测试来看,GPU 性能提升的确很多,但实际使用却没有这么给力,原因应该是当 CPU 也一同跑起来的时候,CPU 和 GPU 会开始争抢主内存资源,造成数据带宽瓶颈——这在一些需要较多调度 CPU 的游戏中就能体现出来。
MacBook Something…
这里再多插一句,看到有人对比 Unigine Heaven 测试,2020 MacBook Air 最终平均帧率 8.8 帧,2019 MacBook Pro 13″ 平均帧率 10.9 帧。这个数据仅供参考,或与 eDRAM,以及后者 28W TDP 有关。
如果我们只看 CPU 性能的话,即便和 2019 款 MacBook Pro 13″(中配 Core i5-8279U)比,2020 MacBook Air 都有着比较大的差距,两者 CineBench R20 多核性能差距在 58-65% 左右。而且由于散热设计上的差异,持续性能理论上还会拉开更大的差距。
说白了,新款 MacBook Air 在性能上仍然是弱鸡,只不过的确比上一版提升很多。与竞品比较的话,其性能和 Surface Pro 7 甚至都有较大差距,这两者还都是被动散热(MacBook Air 的“被动”散热打个引号);而价格其实还差不多。
超低压 CPU 的发热很低吗?
在之前我们探讨过低压 CPU 的实质以后,我愈发觉得,其实超低压和低压 CPU 的区别,可能本质上也还是比较小的——只在于给了一个人为限制的 TDP,便有了更小的基频。如果不考虑功耗墙和温度墙,那么这两者大概就仅剩 I/O 的那点差别了(未深入考察,纯个人 YY,别当真)。
从 Max Tech 的发热测试来看,在 2020 MacBook Air(Core i5 版)跑 CineBench R20 的时候,四核全开,短时睿频可蹿升至 2.4-2.7GHz,此时的功率大约为 13W(在 Max Tech 刚刚更新的测试中,据说功率可以一度达到 26W,全核在极短时间内达到更高频率[10]。这还是超低压 CPU 的节奏吗???或者苹果的确对其间限制做了改动);但似乎在极短时间内(具体多久不知道)就撞了温度墙,CPU 核心温度很快蹿升到了 100℃,全核心便降到 1.5GHz 左右。
这个时候如果能有主动散热来努力一把,那么睿频还是可以坚持更长时间的。只不过前面也提到了,MacBook Air 如今的散热设计比较奇特,那个独立的小风扇依靠坚强的毅力来为散热片吹风。
另外,MacBook 轻薄本(主要包括 MacBook Air 和 MacBook Pro 13″)在散热设计上还一直有个传统,即宁可降低频率,也要让风扇保持安静。所以 MacBook 用户应该会发现,风扇是几乎不发出声音的,这大概也算保证体验的一种方案吧。有兴趣的同学可以去看看 Linus Tech Tips 做的一个视频 “Macs are SLOWER than PCs. Here’s why.”[9],里面提到了 MacBook Pro 在 macOS 系统下这种调节机制的特性(不过 Linus Tech 一直是著名果黑)。
似乎苹果更相信,让风扇尽可能保持低转速,而在一定限度内牺牲性能,是一种可达成体验加成的方式(其实我也这么认为…)。实际上 2020 MacBook Air 的情况也很类似,即 CineBench R20 测试期间,所有核心全开,CPU 核心温度到 100℃ 了,风扇转速也才 4000RPM(全速是 8000RPM)——不过由于这风扇离 CPU 这么远,估计就算转更快、效果也就那样了。
而苹果在 Mac 设备散热上的黑历史,也实在是一言难尽;也包括大尺寸的 MacBook Pro 移动工作站。实际上,苹果在寻找散热设计与极致轻薄间的平衡点时,指针始终在向后者偏移。或许在苹果看来,如果你那么在意性能,为什么不买个台式机呢?好像也有点道理。
Intel Core Ice Lake
OEM 厂商的市场定位把戏
看看,MacBook Air 性能和 MacBook Pro 13″ 还是存在实质上的差距的(更不用提屏幕亮度和色域覆盖差别)。所以以更低的价格购买一台 MacBook Air,你并不能获得 MacBook Pro 13″ 那样的硬件水准。而且实际上,追求轻薄性的各位不妨去苹果官网看一看 MacBook Pro 13″ 与 MacBook Air 在重量和厚度上的差别,这两者不仅最厚处是一样厚的,而且 Pro 只比 Air 稍重了一点点(当然 Air 还有楔形设计)…
在市场策略上,以 Intel 酷睿超低压处理器(Y 系列,MacBook Air)与低压处理器(U 系列,MacBook Pro 13″)拉开性能差距,再加上前者散热上的负优化(误),这两条线的产品不会存在性能上打架的情况。另外,如果今年 MacBook Pro 13″(或 14″)开始采用 AMD Ryzen 4000 处理器,则这种差距还能被进一步拉大。于是,MacBook Air 成为名副其实 Mac 系列产品中性能最差的存在,优势就是价格便宜。
在笔记本或者超级本市场上,处理器有个概念叫“低压”,再转义一下也就是 TDP 功耗比较低的处理器。低压 CPU 一般是专为超级本设计的,它所专注的市场在低功耗、高能效比、长续航,以及不可避免的就是性能更差。
在之前针对无风扇 Surface 的分析文章里,我大致提到了低压 CPU 的性能表现怎么样,其实很大程度受制于 PC 本身的散热设计[1]。“超级本”这个产品门类本来就十分考验 OEM 厂商的系统与散热设计能力,因为超级本必须很轻、很薄,这与散热系统越大越好是相悖的。所以在合理的空间内做到高效的散热(与科学的 CPU 频率调节),让 CPU 在更长时间内处在低温环境里,那么其持续性能就会明显更好。
在我之前的那篇文章里,我们还提到了 PL1/PL2 长时与短时睿频时间的问题。现在很多的酷睿 i7 低压超级本,在一个较短的时间里,都允许低压 CPU 将 TDP 功耗临时抬升到 45W/51W 这种水平。也就是在很短的时间里,这些低压超级本有一个变身为标压笔记本的机会——有时是半分钟不到,有时是几秒钟。那么至少在这几秒的时间内,低压 CPU 就成了标压 CPU,性能有了与标压 CPU 短时竞争的机会。
那么如果我们假定有这样一款超级本,散热设计逆天,而且我们还不用考虑功耗、续航的问题,那么当低压 CPU 的睿频时间无限久时,它是否就已经成为了一款标压 CPU 呢?或者说,如果把一颗低压 CPU 塞进一台散热设计十分出色、热设计功耗限制比较小的游戏本里,它是否可以当做一颗标压 CPU 来用?因为镇压其温度蹿升的散热系统已经完全可以承受住其睿频的发热了。
不过其实我们仔细想一想,同样采用低压处理器的苹果 MacBook Pro 13′ 似乎从 2016 年开始就有雷电接口了,所以这是怎么做到的?
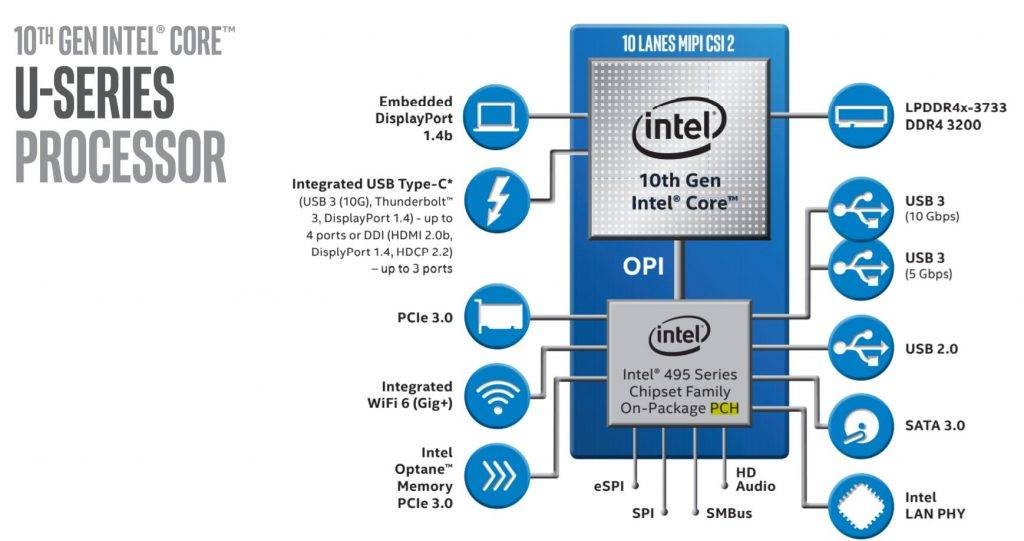
在当代已经不怎么说“北桥”和“南桥”的时候,有个叫 PCH(Platform Controller Hub)的东西就出现了——最早可以追溯到 2008 年。PCH 可以看做是南桥的“迭代”,很大一部分 I/O 功能是在 PCH 上面分配的。比如下面这张图,比较小的那一块 die 就是 PCH(现在应该不会以这种形态出现了)——这颗 PCH 芯片跟 CPU 是封装在一个基板上的,PCH 也可以独立放在主板上。
PCH 与 CPU
对当代低压 CPU 来说,PCH 是集成在整个封装上的(似乎是从 Haswell 开始的),而不是像标压 CPU 那样采用独立 PCH 的形式。PCH 这部分一般相较 CPU 本身,会采用差一代的制造工艺,比如十代 Ice Lake 酷睿 CPU 的 PCH 用的就是 14nm 工艺,而非主体部分的 10nm。
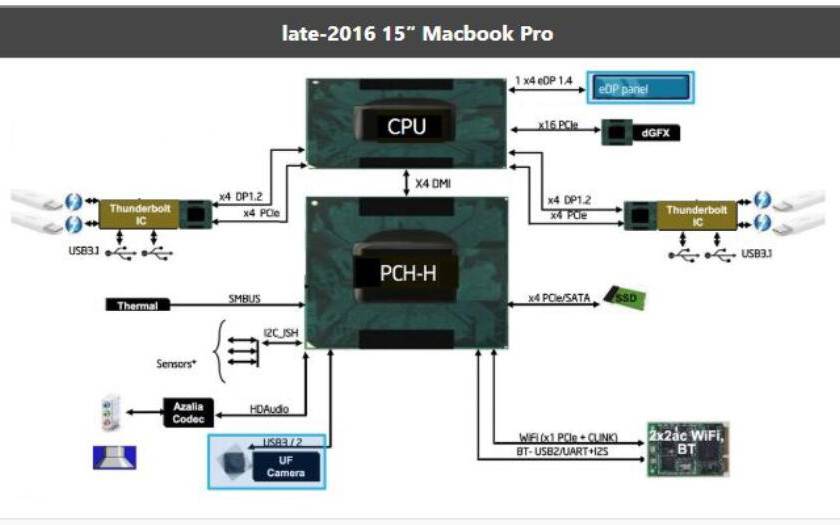
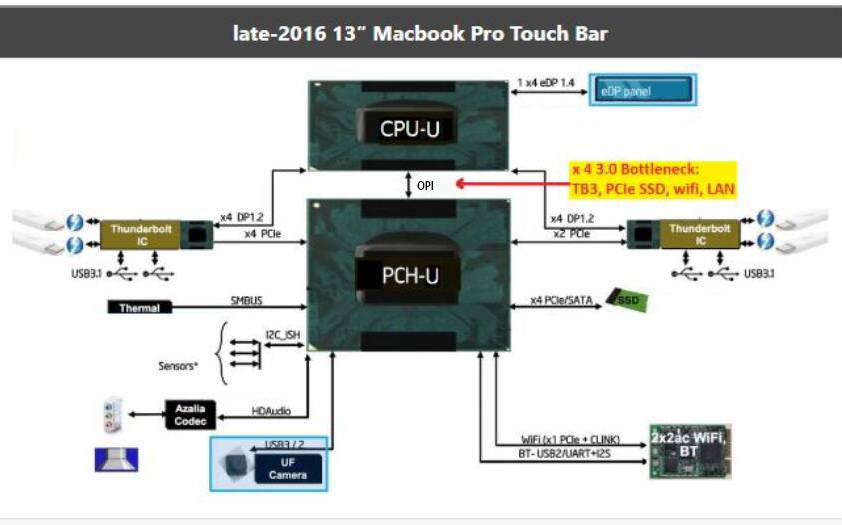
图1:2016 年末款 MacBook Pro 15′ 的 I/O 分配 图 2:2016 年末款 MacBook Pro 13′ 的 I/O 分配
上面这两张图是 2016 年末 15 寸与 13 寸版 MacBook Pro 在 PCH 与 I/O 上的分配。需要注意的是 15 寸的 MacBook Pro 使用的并非低压版 CPU(图 1),而 13 寸则为低压版 CPU(图 2,所以 13 寸的 MacBook Pro 其实一点也不 Pro)。不难发现,当时的第六代酷睿(Skylake)低压处理器自身连 PCIe 通道都没有,而 PCIe 控制器是挂在 PCH 上面的——当时的标压版 CPU 没有这方面的限制。
所以早期 MacBook Pro 13′ 的雷电接口是依托于 PCH 实现的。而且这其中还有两件事值得一提:对标压 CPU 而言,PCH 与 CPU 的连接采用 DMI x4,基本等同于 PCIe 3.0 x4——这真的只能算是个小水管,不过其实问题不算太大,因为标压 CPU 本身不需要依赖 PCH 就有可直连独立 GPU 的通道(当然还有内存控制器),还有额外的 PCIe 通道可支持雷电接口之类;PCH 则负责 SSD 存储、低速 USB、WiFi 等等。
但低压 CPU 这边的情况就相当捉襟见肘了(图 2)。低压 CPU 自身没有 PCIe 通道(也没有为独立 GPU 准备的通道)。如此一来,单纯依靠 PCH 来挂一大堆 I/O,包括雷电 3 这种带宽需求量大户(甚至可能是独立 GPU),再依赖一根小水管连接 CPU,那么带宽资源是可能出现争抢的问题的。
另外,低压 CPU 与 PCH 连接的 OPI 总线(On Package DMI interconnect Interface),根据不同的选择,有时仅有标压 CPU 的 DMI x4 的一半带宽(2 GT/s),就会让问题进一步恶化。这其实也是低压 CPU 在选择低功耗时付出的一部分代价。
似乎在这么多超级本(或采用低压处理器的笔记本)中比较奇特的一款就是 Surface Book 了。众所周知的是,这款设备在 dock 部分可选配独立 GPU。Surface Book 在很多人的心目中,定位都是高性能移动工作站,但实际上即便是 15 寸 Surface Book,都仍在用 Intel 的低压处理器。
其实这一代核显的 G7 最高配,也就是 64 个 EU 的版本,图形跑分已经介于低功耗版和标准版 GeForce MX150 之间了,而且功耗表现也很优秀;但实际游戏测试就不难发现,没上 eDRAM 的带宽瓶颈,令 Ice Lake 在 GPU 和 CPU 同时跑的情况下,会发生主内存资源的争抢,令游戏画面有比较严重的掉帧,实际体验是比不上低功耗版 MX150 的。(推荐各位去看这篇文章:intel 10代酷睿移动版性能测试(四)—— IceLake-U 显卡篇[5])
近期我在家用 Surface Laptop 3(Core i5-1035G7)玩《伊苏 8》这种甜点级别的游戏,大致上也有这种体验,中等画质下的流畅度表现是非常好的,不过一旦 CPU 同时要干点儿什么活,游戏的掉帧问题就会非常严重——等 CPU 干完活儿,帧率立刻又回来。这是个挺诡异的事情。
不过 Ice Lake 这代 CPU 的核显部分提升的确相比八代有了不小的提升,用来玩玩这种对性能要求不高的游戏也非常怡然自得。在这种情况下,类似 MX150 这种在宣传上还比较好听的独显,就显得没那么必要,即便它依然在实际性能表现上优于 Ice Lake 的核显。(MX350 似乎有不错的提升)
总体我想说的是,若选择超级本,大部分情况下就别想着玩什么高级游戏了,尤其是低压 CPU 还对高端显卡存在诸多限制。虽然这话说起来跟屁话似的。另外一点是,低压 CPU 即便在优秀的系统设计中可以达成标压 CPU 的性能水准,它依然存在很大的限制,独立 GPU 即是其中一部分。
最后补充一点,Ryzen 4000 Mobile 对 Intel 十代酷睿的屠杀估计很快就要开始了,如果你不是个技术爱好者的话,就导购的角度来说,现在也绝对不是购买笔记本的好时机。几天前,Intel 的首席财务官 George Davis 在摩根士丹利的会议上已经明确表示,自家 10nm 时代,再也没有当年 14nm、22nm 时期对竞争对手的优势了,而且是“not reach process parity with competitors until it produces the 7nm node at the tail end of 2021”,并且要到 5nm 节点上才能找回制造工艺的优势[6]。对这一点我还是不怀疑的,不过究竟是什么时间呢?
我有一台低配版的 Surface Pro 6,128GB + Intel 酷睿 i5 第八代 CPU。对 Intel 低压版酷睿产品线熟的同学应该知道,Intel 第一次在酷睿第八代低压处理器(也就是型号末尾都带 U 字母的)上将核心数目升级到了四核,以前都是双核。而酷睿八代 CPU 的问世,很大程度上似乎是为了应对 AMD Zen 的来袭。
在市场宣传上,酷睿八代还是相当成功的。基本上酷睿八代超级本(本文只讨论低压版酷睿八代)都获得了不错的名声,也包括 Surface Pro 6。网上的绝大部分基准测试成绩,八代酷睿都比七代有着质的飞跃,毕竟核心数目都翻番了——也算是“一屁股坐在牙膏管上”的操作了,这好像还是要感谢 AMD 的。
图源:我的 Ins
不过讲真的,Surface Pro 6 酷睿 i5 版的使用体验并不算好——一般在低压超级本上,我以前始终觉得酷睿 i5/i7 在性能表现上差不到哪儿去,尤其在低压 i5、i7 超级本的价格差别还那么大的情况下。如果我们不算 binning process 导致 i5/i7 有着体质上的差异,以及一些看起来对一般人并没有什么用的“高级”特性,针对超级本的低压版i7 似乎也就比 i5 略高点儿频率(cache 差别什么的也并不大)。现在看来,我这个观念是错误的,至少在微软这里是完全错误的。
实际情况是,Surface Pro 5、6、7 这三代产品的酷睿 i5 版(分别对应 Intel 酷睿七代、八代、十代),都采用被动散热,也就是无风扇的设计(i7 版是有风扇的)。我觉得在行业内也就微软有这种“魄力”了。不过至少通过对它们的了解和研究,可发现无风扇酷睿低压本(非超低压)的实际性能情况,大致是什么样。因为温控、散热设计对性能有着很直接、显著的影响。
不想看这么多文字的同学,可以直接转到本文最末看结论。
主观体验
聊主观体验的话,其实就不光是处理器的问题了,理论上我应该谈“系统性能”。比如说 Surface Pro 6 低配版选择的闪存比较寒碜,加上 LPDDR3,其存储性能本身就不会很好看,这些实际上都对系统性能成绩造成了比较大的影响。就 NoteBookCheck 的 PCMark 系统性能来看,低配版 Surface Pro 6 的系统性能得分和 Pro 5 差不多[1],主要源于其存储性能实在太烂。不过我不想聊系统性能,我们就单纯说说 CPU。所以主观体验这部分其实不靠谱,各位权当看看。
貌似看这个配置表,我这“主观体验”对比未免也太不客观了。的确,这两个超级本的处理器架构代号都不一样。不过 Whiskey Lake 相比 Kaby Lake Refresh 的主要差别在于,Whiskey Lake 采用改良版的 14nm++ 制造工艺,提供了更高的频率,其余各部分其实是差不多的,貌似还有外围支持的一些小差异。
似乎就存储性能表现,以及处理器频率、L3 Cache 来看,ThinkPad X390 更优的软件使用体验也算必然。只是我没想到两者的差距会这么大,毕竟也算是同期的八代超级本。就我自己看来,这种差异可以认为是散热机制造成的,Surface Pro 6 的无风扇设计导致其性能孱弱,并影响到了用户体验。散热机制差异对性能的影响,超过了上述配置参数差异的影响。下面我们来“片面”地看看,无风扇设计究竟造成了多大的影响。
这三代无风扇设计的 Surface
前文就提到了,Surface Pro 5、6、7 这三代的酷睿 i5 版都采用无风扇设计。就我的理解来看,这应该并非是微软对自己系统设计有多自信,而是在理念上期望打造一款安静的无风扇平板电脑(或许平板模式下,DPTF 动态温度功耗控制需要比一般笔电更严格,毕竟身兼“平板”属性,需要经常与手亲密接触)。它在定位上更偏向便携、轻薄、移动、安静。只不过 Surface Pro 就平板定位来看,真的不轻,且发热不低,我自己觉得就现阶段来看,它完全没有追求“便携、轻薄”的资格。
而且主观体验可补充的是,Surface Pro 6 的温控机制虽然在笔记本中算是比较保守的,但如果你有用 Surface Pen 作图的习惯,在 Photoshop 里面作图,手指和屏幕亲密接触,依然能十分明确地感受到这设备“温暖”得可以:时刻提醒你,这根本就不是一台平板,哪有这么“温暖”的平板啊?所以我觉得,在这一点追求上,Surface 是失败的。或者说,我觉得 Surface Pro 没必要追求这个。
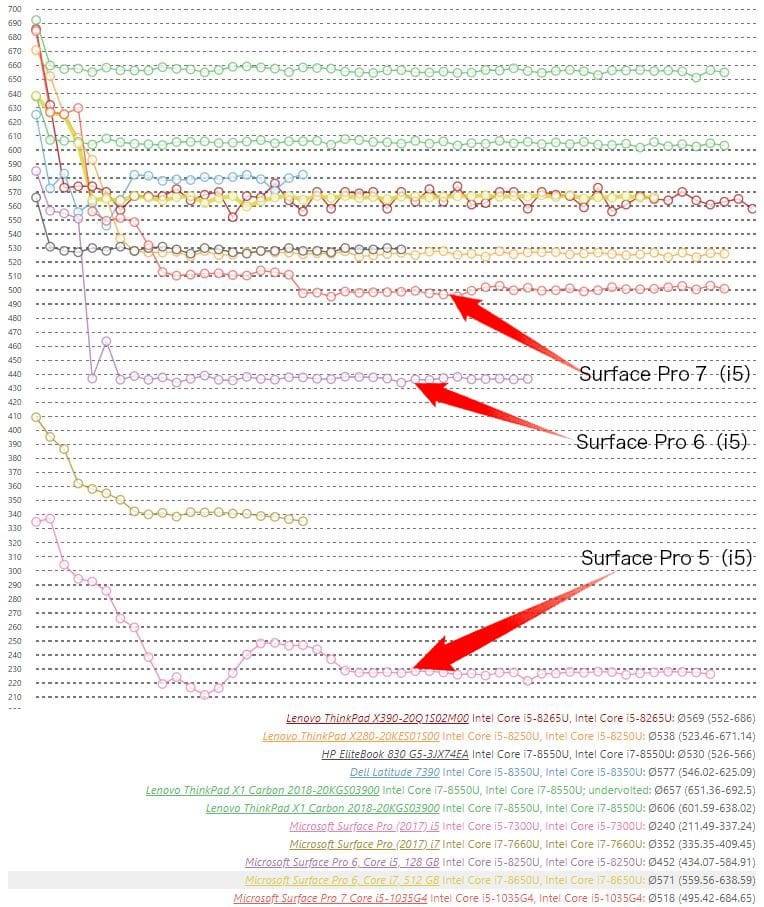
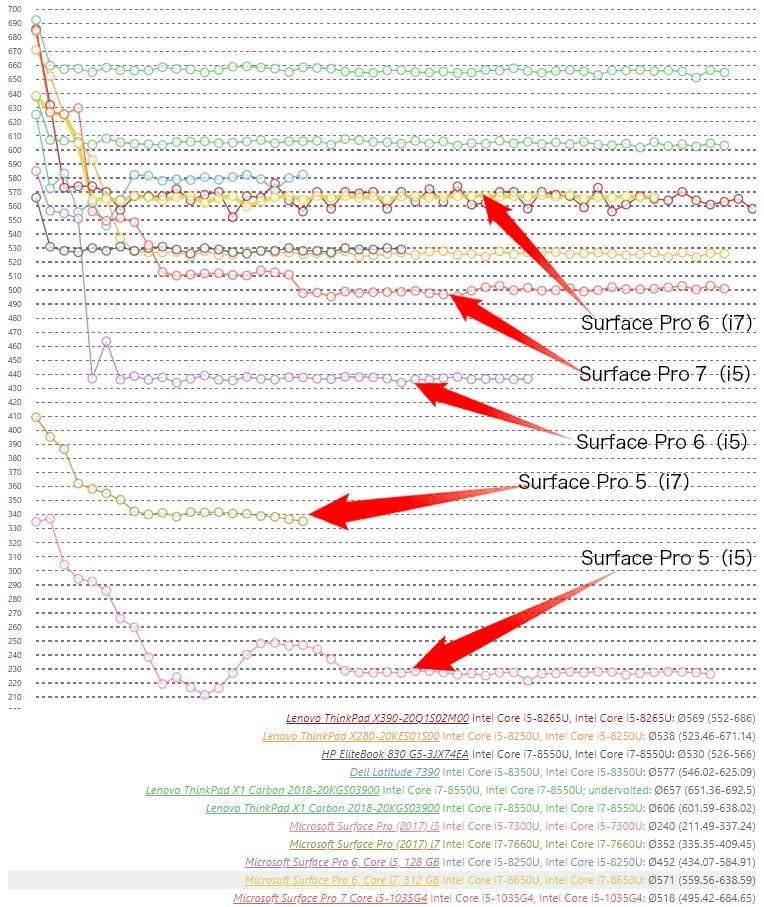
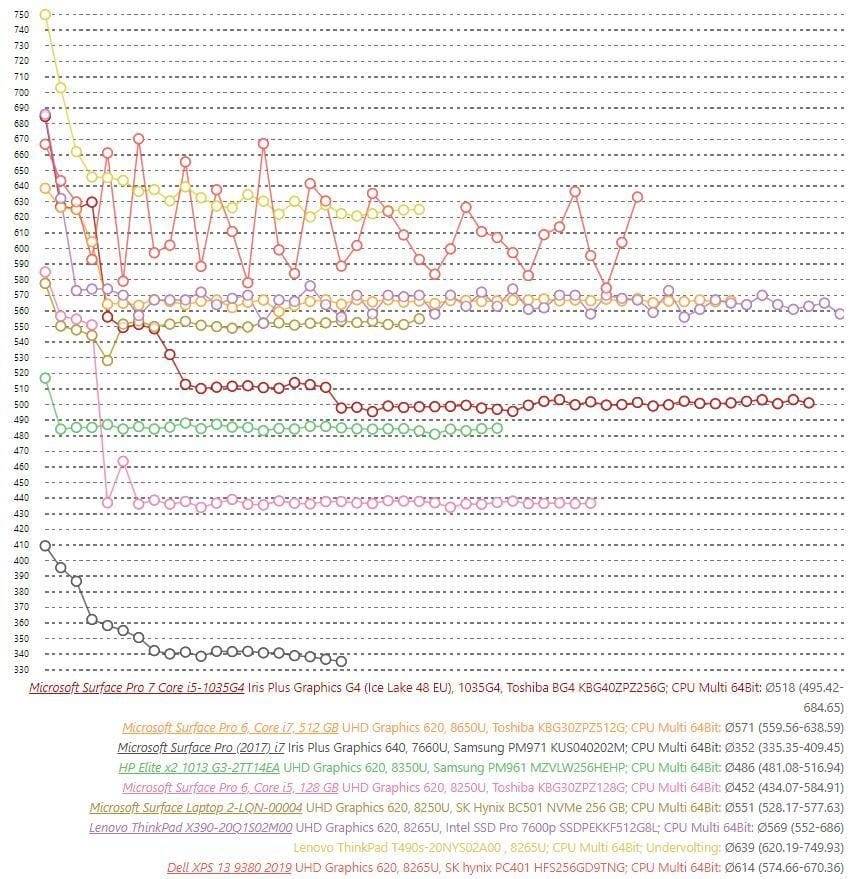
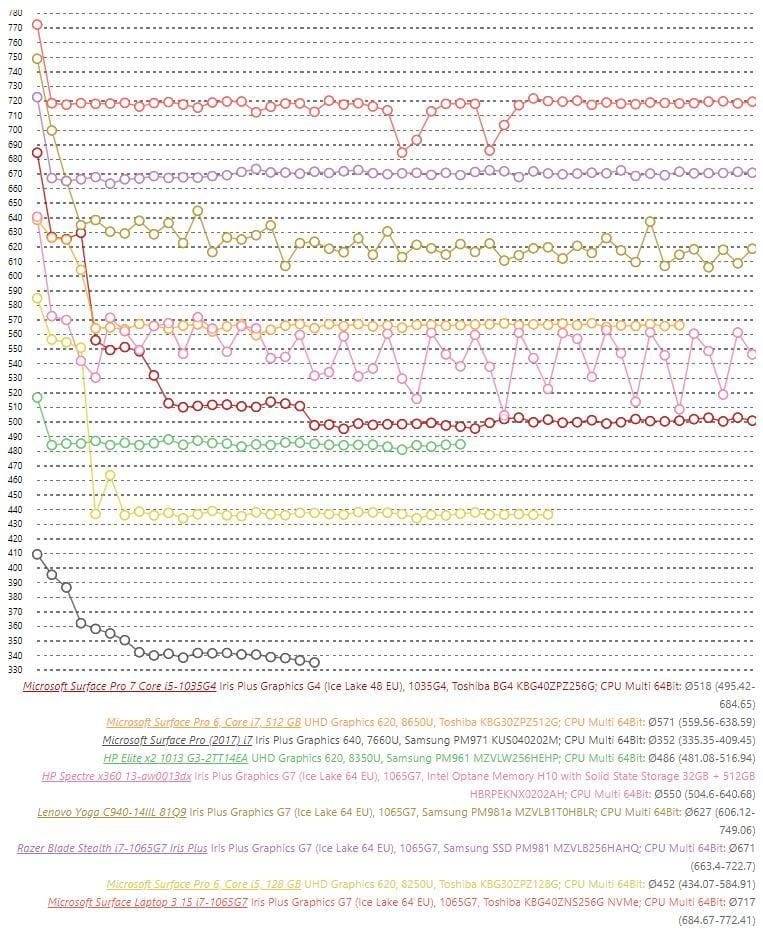
我们来看下,如果只对比这三代产品,其 CPU 性能表现的差异。这里援引 NoteBookCheck 的 CineBench R15 多轮跑分,如下图所示。我将 Surface Pro 5、6、7 的酷睿 i5 版跑分标识出来了。
来源:NoteBookCheck
首先简单谈一谈 CineBench R15 是个什么测试:这个测试基于动画软件 CINEMA 4D 3D 内容创作,可用于衡量 CPU 和 GPU 性能。CPU 测试场景包含 28 万个多边形,GPU 测试基于 OpenGL ——渲染大约 100 万多边形、高分辨率纹理和各种特效。测试中,CineBench 会动用全部系统处理能力,来渲染一个 3D 场景,该场景由各种算法构成,对所有可用处理器核心构成压力测试。CPU 测试场景包含大约 2000 个对象,采用形状、模糊反射、面积光源、阴影、反锯齿等效果。GPU 测试部分就不说了,也不是本文要探讨的重点。
如果我们只用 Surface Pro 自家产品对比,这三代的性能提升还是显著的。而且同样是无风扇,Surface Pro 的性能还是比 Surface Go 高出一大截的——这里没有给出 Surface Go 的成绩,这款设备的 CineBench R15(多线程)跑分稳定在 160 分左右。Surface Pro 6 的酷睿 i5 CPU(酷睿 i5-8250U)性能提升相比 5 还是相当显著的,就 CineBench 来看,其成绩在长时间跑分后的稳定状态位于 440 分上下;而 Surface Pro 5 (酷睿 i5-7300U)是不到 230 分——持续性能提升超过 90%(相比 Surface Pro 5 有风扇的 i7 版提升约 27%)。Surface Pro 7 的酷睿 i5 版(酷睿 i5-1035G4)持续性能跑在 500 分上下,这个提升幅度算是尚可,不过比我想象得要差。
实际上,从这个曲线也反映了这三代设备的一个共性,最初几轮跑分成绩明显比较高,尤其是第一轮跑分成绩,完全不输给那些带风扇同配的超级本,但在跑到大约第五、第六轮的时候,性能开始直线下滑。主要是因为功耗与温控限制,致设备可持续的频率比峰值状态下的频率低很多。Surface Pro 6、7 这两台四核设备的性能损失尤为显著。
留意到 NoteBookCheck 在评测中也提到,”A laptop with ideal cooling is way out of the Surface Pro 6 (2018) i5’s league as the latter was only around 65% as fast.” 比如说,ThinkPad T480s(14 寸超级本,酷睿 i5-8250U)在持续负载中就比无风扇的 Surface Pro 快了 35%;即便是更小 12 寸的 ThinkPad X280(酷睿 i5-8250U)在持续性能上也高出约 20%。
没风扇果然是不行的。不过这里还是再次提醒一下,我没有研究过 CineBench R15 内部的具体测试流程,及其测试数据规模,虽然网上说它是个偏 CPU 的测试,但既然作为软件跑在最上层,它一定和整个系统相关;所以还是需要考虑 CPU 以外的其他配置。这样一来,整个系统的对比会比较复杂。
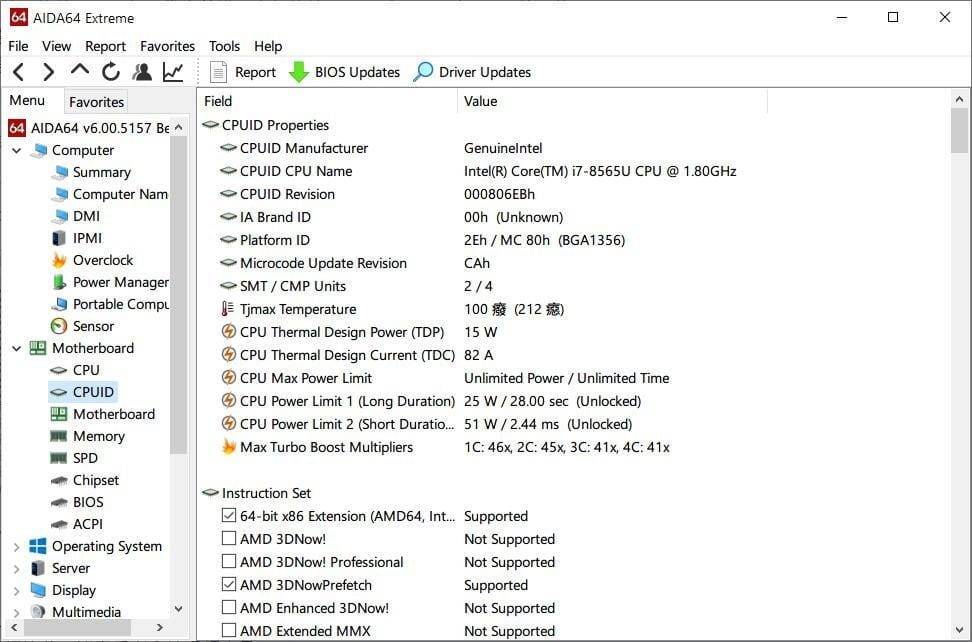
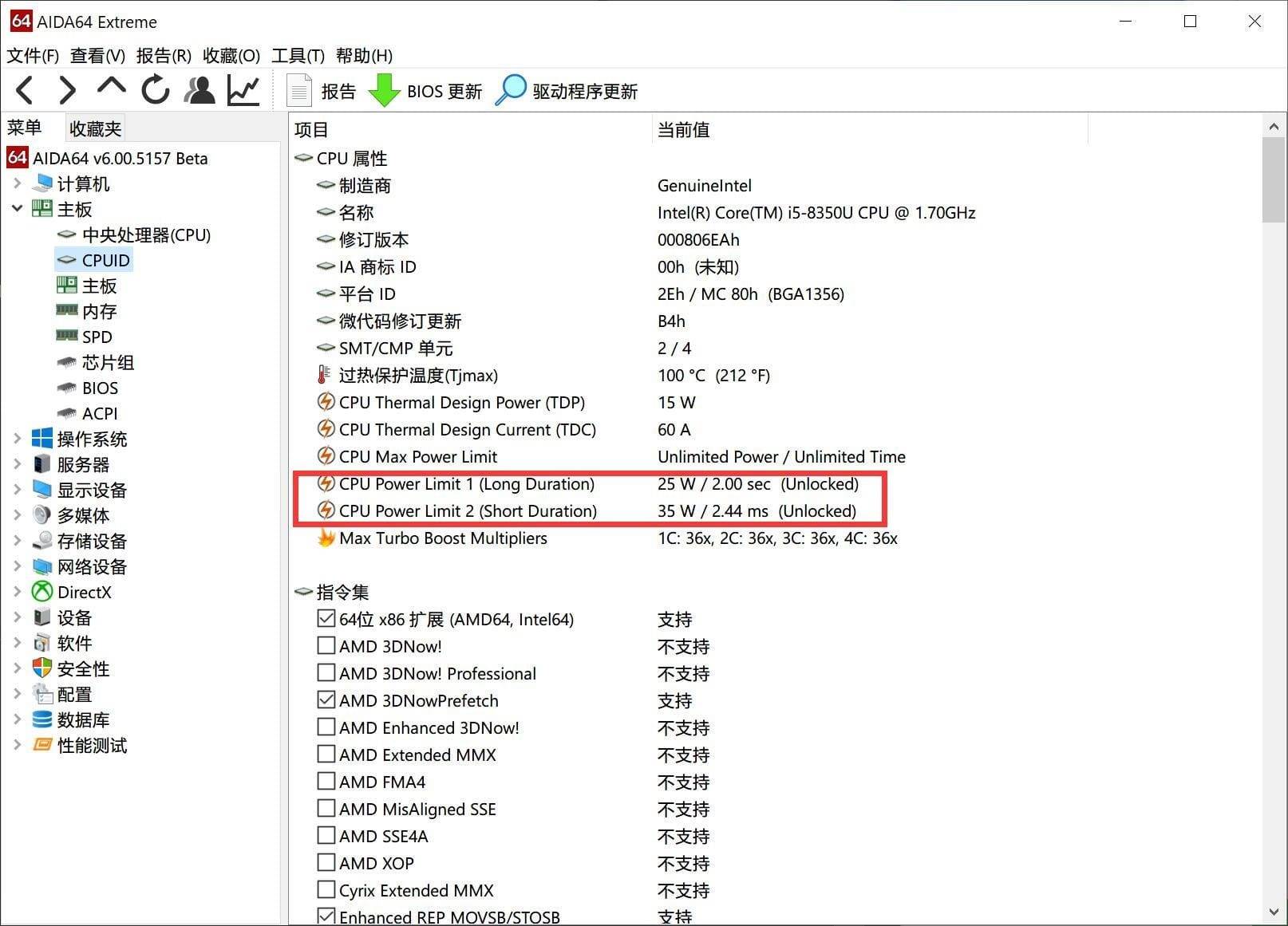
针对本文开头部分所说,我用的这两台笔记本(ThinkPad X390 i7版/Surface Pro 6 i5版),用 AIDA64 看下这两台设备的 CPU 相关信息。这里我比较关注的是 CPU PL1、PL2 参数(下图中的 CPU Power Limit 1/2)。这两个值表示的是长时睿频功耗上限、短时睿频功耗上限,及其相应的持续时间。这个值与 OEM 厂商自己的设计相关。
ThinkPad X390
ThinkPad X390 这台设备(接 AC 电源、高性能模式下)的 PL2 短时睿频 TDP 设定在 51W,睿频可持续时间 28 秒;长时也有 25W。好像很多酷睿 i7-8565U 都采用类似的设定。这在低压本中仍是十分激进的值,虽然前文也把 X390 归类在超级本中,但实际上这台设备在厚度等 ID 设计上都算不上轻薄。可类比小米 Pro 这种八代本短时睿频 TDP 设定在 44W。
这种本子在一个较短时间内允许 CPU 不受性能约束,尔后便会做限制;44W、51W 这种值都是短时间内当标压设备在用了。这个“短时间”在很多场景下,仍对体验十分有帮助。
就这方面的表现来说,Comet Lake 似乎是对 14nm 四核低压处理器的一次完善和补足,或者说可能在八代酷睿低压 CPU 核心和线程数目翻番显得过于匆忙时,在十代 Comet Lake 身上完成了一次比较出色的修正,让四核低压 CPU 真正步入成熟。(本文未探讨六核低压 CPU)
不过去年更新的 Surface 系列采用的十代酷睿并非 Comet Lake 版,而是 Ice Lake 版——也就是新工艺、新架构的版本,听起来好像更美好了。但前文就提到了,可能是 Intel 的 10nm 制程还没有那么成熟(后续我打算把 WikiChip Fuse 针对 Intel 10nm 工艺的文章翻译过来),虽然 Intel 宣称 Ice Lake 有 18% 的 IPC 提升,但市面上的 Ice Lake CPU 在最高频率方面不及 Comet Lake。
来源:笔吧评测室
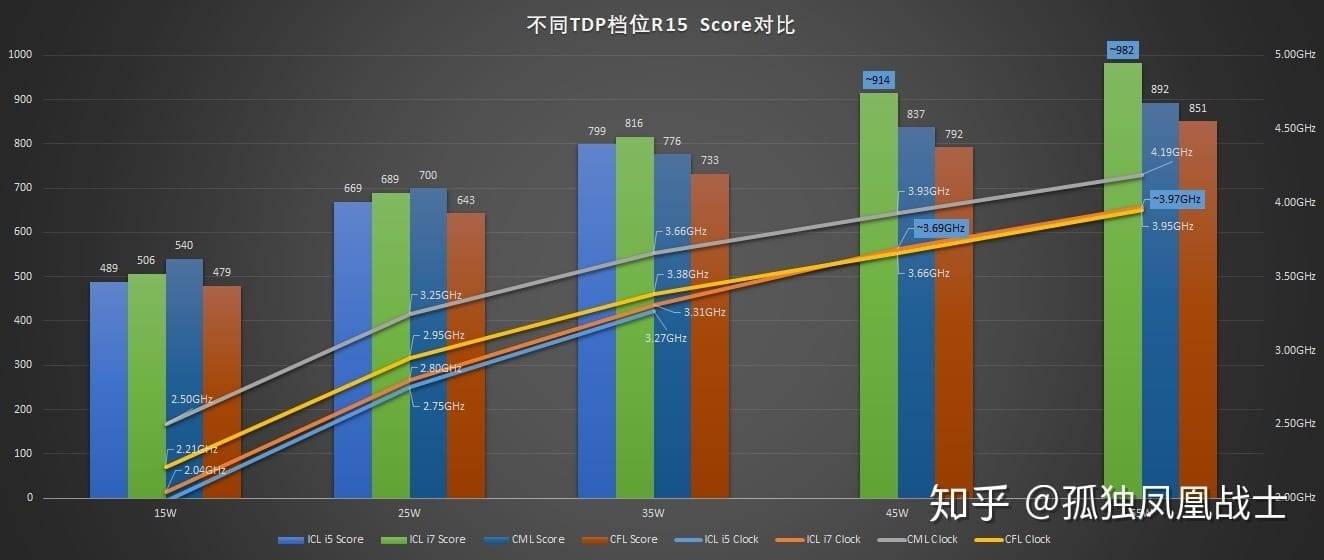
从笔吧评测室的测试数据来看[6],3.5GHz 的 Ice Lake-U 差不多等于 4GHz 的 Comet Lake-U。实际上如果对比同频功耗,Ice Lake 是略高一点的,但 Ice Lake 的同频性能也更高。按照同性能来比较功耗,Ice Lake 还是胜出的(Uncore 以及核显的功耗会明显更高,此处 Uncore 也因为有了四个 Thunderbolt 3 原生支持故功耗更高)。
来源:笔吧评测室
以功耗为尺度做衡量,则在 PL1/PL2 为 15W/25W 的超级本上,Ice Lake 的性能会略低于 Comet Lake;但达到 35W 及更高时就会超越。就这个角度来看,Surface Laptop 3 采用 Ice Lake 应该还是个相当不错的选择;但 Surface Pro 7 的无风扇酷睿 i5 版也选择 Ice Lake,实际就有那么点小问题了。
但就上面我援引的各种数据来说,Surface Pro 7 无风扇酷睿 i5 版在 CPU 性能方面比 Surface Pro 6 高出 14-17% 之间(峰值和持续性能),这实际完全符合在相同散热设计下,十代酷睿(Comet Lake-U)比八代酷睿(Whiskey Lake-U)强约 15% 的预期,而 Ice Lake 在较低功耗设定下的性能相较 Comet Lake 没有优势,所以 Surface Pro 7 的表现完全符合预期。或者说 Surface Pro 6 可能已经在12寸设备上做到了被动散热的最优设计,Surface Pro 7 则延续了这一传统。
当然,在 Surface Pro 体系内,无风扇的被动散热大概的确做得不错,只是被动散热一定意味着性能会打折扣。
另外这里再分享一篇我觉得很有意思的文章,AnandTech 前不久参加 CES 2020 的 Intel 的主题演讲[2]。Intel 在会上对比了自家低压 Comet Lake/Ice Lake 与 AMD Ryzen Mobile 3000 系列,表明自家产品性能、特性领先多少。不过这不是重点,实际上这个对比结果也没什么奇怪的,从 Surface Laptop 3 的酷睿版和锐龙版比较,就能看出在低压版 CPU 的这一局,Intel 还是有相当优势的。
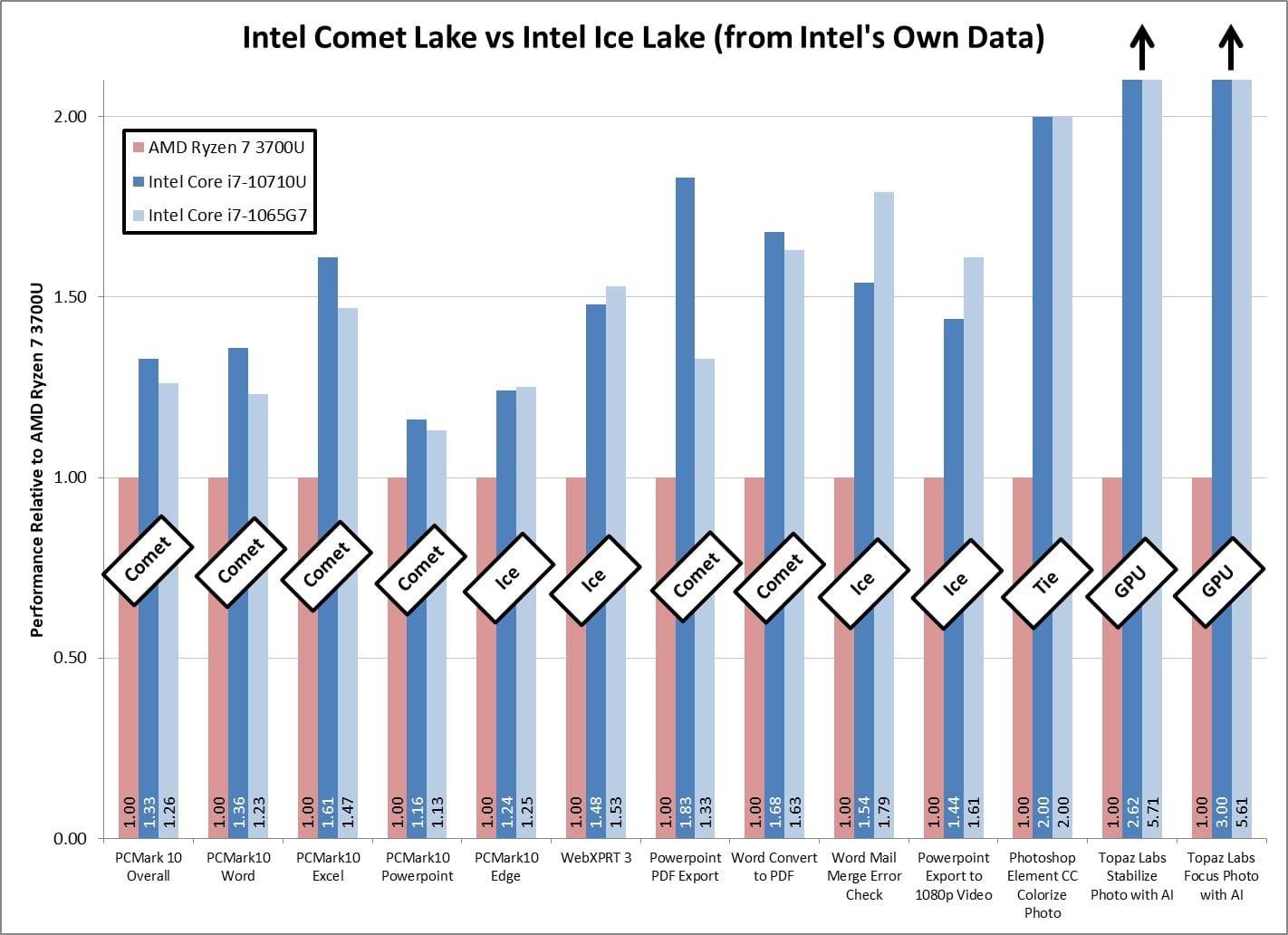
不过在这个对比中, AnandTech 发现,Intel 分别发布了两张 PPT,一张对比 Comet Lake 与 Ryzen Mobile 3000,另一张对比 Ice Lake 与 Ryzen Mobile 3000。三个对比对象分别是酷睿 i7-10710U、酷睿 i7-1065G7,以及 AMD Ryzen 7 3700U。而自家 Comet Lake 与 Ryzen Lake 却没有直观对比。AnandTech 觉得十分好奇,于是他们将两张 PPT 上的成绩放到了一起,一次来比较十代酷睿的两个版本究竟表现如何,如下图所示。
来源:Intel via AnandTech
Intel 宣称这些测试项是最能代表“真实环境的测试”。不过在包括 PCMark 10、WebXPRT 在内的测试中,Comet Lake 在前四项测试中都胜出,浏览器测试(PCMark10 Edge)基本是平手;WebXPRT 浏览器测试两者得分也相近,Ice Lake略胜。Office 真实测试也是对半开,Word 测试互有胜负(PPT PDF 导出测试,Comet Lake 的优势似乎还不小)——比较奇特的是这里的 Powerpoint 转为 1080p 视频测试,日常不知道有谁会这样操作;Photoshop 测试完全打平;至于 Topaz Labs AI 测试,这应该属于小众测试——而且 Intel 还和这家软件供应商合作进行了 GPU 加速(说好的真实环境测试呢?)。
所以就现阶段来看,如果单论性能,则在具体的 CPU 产品上,Comet Lake 仍是更加成熟的选择——即便它采用的是旧架构和旧工艺。另外 Ice Lake 引入了一些消费用户暂时不怎么用得到的东西,比如说 AVX-512 指令原生支持——在现有某些特定冷门项目上,Ice Lake 估计可以获得更好的成绩。这么看来,如果真的说“真实环境测试”,则 Comet Lake 也是优选。虽然这种局面大概是 Intel 不怎么愿意看到的。
最后展望一下今年的 Surface Pro:其实去年发布的 Surface Pro X 真的挺好看,我倒是不在意设备厚不厚,而在意 Surface Pro 的屏幕太小了;Surface Pro X 就弥补了这个短板,屏占比增大了,屏幕变大了。无奈 Surface Pro X 是台 Arm 设备,知乎有几篇谈 Pro X 使用体验,以及 x86/x64 转 Arm64 效率的测试文章,至少现在 Arm 平台的 Windows 本体验是真的不好的。
我觉得很有理由相信,x86 平台的 Surface Pro 在屏幕、外观方面也会有类似 Surface Pro X 这样的升级,或许 Surface Pro 8 身上就能看到。还有一点,AMD 在前不久的 CES 大会上发布了 Ryzen 4000 系列 APU,这仍然会对低压超级本市场产生一次性能、效率上的冲击。Intel 计划中的 Tiger Lake 在路上。不确定 Surface Pro 8 能否赶得上。其实感觉这两年由于 AMD 的搅动,即便“摩尔定律放缓”,桌面 CPU 市场也焕发了一波生机。2020 年的 Surface Pro 或许会具有极大的吸引力。
最后的最后,总结一下本文的一些推论:
无风扇设计的 Surface Pro 在持续性能上,会明显弱于同时代同配置的其他主动散热超级本;持续性能差距可以达到 20-35%。
Surface Pro 的酷睿 i5 版与 i7 版性能差别会比较大,这和其他品牌超级本的情况很不一样;
微软可能已经在 Surface Pro 被动散热设计上做到了最优化;
Surface Pro 6 相比 Pro 5 实现了一次性能飞跃;
Surface Pro 7 无风扇酷睿 i5 版的升级还是值得的,即便其 CPU 性能变化不算太大,但其系统性能提升比较大;
即便十代酷睿的 Ice Lake 用上了更好的工艺、更新的架构,但目前 Comet Lake 仍然拥有更出色的成熟性,和更实用的性能;
未来的 Surface Pro 8 可能相当值得期待,或许 Surface Pro 8 可以实现性能与外观(屏幕尺寸)的双重飞跃。
这里再多说一句,虽然本文花了比较多的篇幅在说被动散热的 Surface Pro 相比同配置超级本性能更孱弱,但我从未对于购买 Surface Pro 无风扇版的设备后悔——只不过我更加认识到 Surface Pro 的 i5 和 i7 版价格差别较大还是有原因的。对于无风扇设计,微软大约也有自己的想法。毕竟移动、安静本身就需要付出代价,就好像超级本的性能远弱于游戏本——但价格却依然可能很高,这是一样的道理,看你愿意为何种元素买单罢了。
感觉这大半年我都在客观上探讨一件事,在刚进入 EE Times 不久,就看到 MIT 2018 年出的一篇 paper。这篇 paper 也在我这大半年写的文章里,被反复提及,题为《通用技术计算机的衰落:为何深度学习和摩尔定律的终结正致使计算碎片化》。在整体观点上,这篇 paper 其实还十分有趣。几个月前,我把这篇 paper 的观点做了浓缩和重构,再加了一些额外的料,构成了一篇《深度学习的兴起,是通用计算的挽歌?》[2]。
各位有兴趣可以去看一下,这篇文章真的细节动人、论据充分、观点鲜明、语句通顺……这里再总结一下,其实观点很简单,就是既然 CPU 现在性能涨幅这么小,工艺节点都难推进,那这条路差不多就快走完了;然鹅,还有专用计算这条路啊:就是针对不同的应用场景,咱们开发专门的芯片,量身定制、量体裁衣:这样的话就能做到性能持续大幅攀升,与此同时效率高、功耗还大幅降低。
这篇 paper 看起来美好而高级、优雅而低调。不过在随后工作的时间里,我基本上是在花全部的时间,尝试听取行业内的参与者们是否赞同这一点。很遗憾的是,几乎我听到的绝大部分声音,都在彻底否定这个论调。有关这一点,实际还可以从 1 月份即将发行的《观点》杂志,我的文章《AI芯片专用好还是通用好?遥想20年前GPU也面临这一抉择》中看到比较详细的论述。这里就不提太多了(下个月就和大家见面哟)。
绝对专用芯片也就是 ASIC,的确效率高、算力也高。但它实际受到两个巨大问题的影响:
第一是成本。这是个看起来非常废话的原因。像 CPU 这种全银河系通用、只在大麦哲伦星系不通用的芯片,你在上面干什么不行啊?都可以,装个 Windows,然后跑个虚拟机,还能装 macOS,写文档、做设计、修图、剪视频、炒股票,各种软件都能跑,医疗、交通、政府、金融,咱都能干。甚至,如果你一定要跑 AI 任务,CPU 其实也可以干。
所以 CPU 的特点,就决定了,这一类产品是全局适用的。它的销量非常大,渗透在人类生活的方方面面。所以即便新制程的设计和工艺成本都在指数级攀升,造个工厂花几十亿美金才可以——未来还要更多。不过这么昂贵的制造成本,实际能够消受得起的产品类型就不多。到最具体的产品上,手机、PC 都是可以承担这个成本的,因为它们每年的销量特别大,单 iPhone 一年就卖超过 2 亿台…每个手机、PC 至少都需要 CPU 才能跑得起来。CPU 有充足的量来摊薄设计与制造成本(实际情况比这还要复杂一些,还是推荐各位去看[2]这篇文章)。
当然,汽车专用芯片仍然可以考虑用成本更低、更早的制程来造芯片(以及某一颗芯片用在大量车型上)——这也是现在绝大部分专用芯片的常规方案。不过当“专用”芯片所覆盖的市场容量本身就不大,以及可能比汽车市场还要小很多的时候,尤其是很多 B 端市场——天花板是明摆着的,又靠什么来抵消芯片设计与制造成本?
这个问题在 MIT 的那篇 paper 中实则有着非常翔实的论述,其中详细列出了关乎特定市场容量、专用芯片产量、专用芯片相较通用处理器的性能与效率优势有多大,这些变量相互之间是什么样的关系。在满足怎样的条件时,专用芯片可以提供更高的成本效益。
在我更早期撰写的采访文章中,针对 ASIC 制造耗费成本这件事,我们有一个更准确地认识,即《摩尔定律失效,FPGA 迎来黄金时代?》[3]。不过这篇采访文章实则忽视了一个重要事实,就是 MIT 提到的上述这几个变量关系。而且专用芯片其实没有必要采用最新的制程,依然可以在性能和能效上碾压通用芯片(或 FPGA)。我在《深度学习的兴起,是通用计算的挽歌?》文中同样浓缩了这部分理论,在文章的第三部分“专用处理器市场过小?”章节内——不过当时为了理解方便,我没有将 MIT 提到的所有变量都放到我的这篇文章中,所以仍然建议去看 MIT 的原文。
第二是通用性差异。
双重标准:通用与性能
CPU 的通用属性就决定了,它在任何一个方面,其实都很难做到精通,或者说针对任何具体应用场景的算力和效率表现其实都一般。因为 CPU 需要耗费大量面积来做多层级 cache,微架构前端也很重要,真正的执行单元所占尺寸就那么点。因为 CPU 需要处理各种类型的工作,各种条件分支之类的东西。
但 CPU 的设计和工艺都是具备相当难度的,至少显著难于绝大部分专用芯片。用 GPU 去比 CPU 的 AI 算力,这种对比的价值显然是不大的。这其中的核心就在于,GPU 实际上本来就算是一种专用芯片。至少早年,GPU 就用于图形计算,它只做这一件事。而且实际在 GPU 诞生的更早期,它本来就以 ASIC 的面貌出现——它从骨子里是一种专用芯片。用 CPU 这样绝对通用的芯片,去比较 GPU 这种专用芯片,又有什么价值?尤其如果你还比较浮点运算能力,那就更奇特了。
不过 GPU 这个类型的芯片,在发展中后期发生了一些很显著的变化。它开始越来越具备通用属性(这个转变原因也可以从《观点》杂志中找),shader 核心这种非固定功能单元的地位越来越重要。即便 GPU 仍然没有 CPU 那么通用,但 cuda 编程这种东西是现如今人尽皆知的;GPU 的可编程性,或者叫灵活性变得越来越高。所以 GPU 现在早就不只用于图形计算了。
我们说将 GPU 应用于 AI 计算,不管是云端 training 还是终端 inferencing,其本质都是 GPU 通用属性的某一个方向;AI 计算在 GPGPU 世界里,不过是其中一个组成部分罢了。只不过是因为 AI 计算这个方向实在是潜力太大了,所以 GPU 厂商开始将 AI 计算作为一个着重发展的方向来对待,以及还针对 AI 计算特别加入了一些专用单元,比如张量核心。
然鹅这个时候,AI 专用芯片华丽丽地出现了,比如谷歌的 TPU、比如特斯拉的 FSD(Full Self-Driving Computer),以及一众国内外的 AI 芯片新品。
AI 专用芯片如果专用、固化到 TPU 那样的程度,只针对卷积神经网络,采用 Systolic Array 技术;前述第一个成本问题之外,它具有的第二个局限性就在于几乎没有灵活性可言。尤其在 AI 算法每个月甚至每周都可能发生变化的情况下,芯片 18 个月开发周期,当芯片问世的时候,这颗芯片就极有可能已经落后了。
但我们仍然不得不承认,AI 芯片在它所擅长的任务上,可能具备在效能与算力上大幅领先 GPU 的能力。所以 AI 芯片厂商几乎清一色地会在发布会上宣布,自家产品可以吊打某 N 字头企业的 GPU 某明星产品。
这件事,本质上约等于拿 GPU 去和 CPU 比浮点运算能力。而且实际上,AI 芯片比较的“AI 算力”大部分情况下是低精度的,比如很多终端 inferencing 芯片 INT8 计算能力很强——那你怎么不比比双精度?因为你不能做双精度运算?这种对比是将 GPU 放在通用计算的地位上,用专用计算的 AI 芯片——包括专门设计的 cache 或 HBM、低精度执行单元等——来吊打 GPU。这同样是件没有价值的事情。
不过更有意思的是,GPU 此刻为自己辩驳的方式,大部分是说:我能做的事情更多啊,比 TPU 之流的 AI 芯片能做的事情多太多了,它们那些 AI 芯片就只能做一件事。
这属于典型的双标,在和 CPU 比较时,宣称自己 AI 算力高出一大截;在和 AI 芯片比较时,宣称自己更通用。这不是双标吗?
是否存在第三类通用芯片?
其实我花了比较长的时间去理解,为什么 MIT 的这篇 paper 并不能成立;至少它成立的概率会很低。因为就历史经验来看,它是不对的:当我们参考 CPU 和 GPU 的兴衰史,其实就很容易发现,专用芯片在大部分历史条件下都不会成为主流,而只能成为某个历史时期的特定过渡产品。有关这一点仍然推荐去看 1 月份即将发布的《观点》杂志文章,这在前文已经提到了。
不过 AI 芯片是顺应时代潮流产生的一种芯片类型——除了前文提到的 TPU、FSD 这类相对极端的绝对专用 AI 芯片,当代越来越多的 AI 芯片都已经产生弱编程特性了,就跟当年的 GPU 一样。就连 Arm 的 NPU IP 实则都融入了一定的灵活性。也就是说,如今有一大批 AI 芯片实际是具备灵活性或通用性的,它们不只能做一件事,从结构上它还为未出现的算法做考量。
Graphcore IPU、华为昇腾都在其列。也就是说,AI 芯片在 AI 计算时,不仅效率相较 GPU 更出色,而且它还具备一定的通用性。这实则才是很多 AI 芯片企业在宣传中提到,在 CPU、GPU 之外,第三类芯片出现的原因,就是 AI 芯片。它可能将拥有自己的适用领域、迭代周期、开发生态。未来 CPU、GPU 和 AI 芯片就要成为三条并行的线了。
从应用场景来看,这个观念好像是成立的。至少我觉得,它比 MIT 说的专用芯片成为未来这一点要靠谱多了。
但我仍然觉得,这种畅想的实现概率也会比较低——至少在云端 AI training 这部分市场,GPU 可能将长期占据垄断地位,且难以撼动。因为 GPU 不仅具备制程优势(有能力采用最先进制程的少数派),而且具备开发生态优势——大量开发者都愿意投入其中,因为它相比 AI 芯片,具备了先天的生态基础,且发展多年。GPU 开发生态优势巨大的程度在从上至下、上天入地、贯彻电子科技行业,GPU 是无处不在的。
某 N 字头企业在如今的 AI training 市场已经占据了绝对统领地位,这种地位的不可撼动性就体现在开发生态的绝对优势上。且其发展经验积累,又令其具备了充足的资本优势可持续完善这个闭环生态,从软件到硬件。这就不是哪家 AI 芯片厂商随便对比一下性能、能效足以完事儿的了。生态优势可以彻底无视性能、能效的那点差别,尤其当这种性能、能效差别并没有数量级差别时。
科技本身在用户层面的最佳体现,就是让你感觉不到科技的存在,同时又让你觉得你离不开它,而不是时刻提醒你:我这个东西很高级的哟!最典型的例子就是苹果对指纹识别在手机领域的普及,Touch ID 主体上需要 Secure Enclave、电容指纹识别传感器,以及操作系统层面的三方配合。几方配合实现的是一种技术的无感,你把手贴上去,跟按下普通 Home 按键一样,手机就解锁了,全过程非常符合直觉,就好像根本不存在这项技术一样。但 Touch ID 实际解决的包括了 Biometric Credential 的加密与存储机制(以及全盘数据加密),指纹识别过程的极佳体验(体现在高识别率、容差也比较大),以及具体的应用场景。这几个实现起来其实都不容易,都需要花很多的时间。但在用户看来,这东西就跟不存在一样,与此同时也离不开了。
这家智能家居公司在我离开时,已经着手做 AI 了。除了我前面提到的这些应用场景都能完成——但他们毕竟还是需要你去设定规则,比如 IF 门窗磁传感器==关 & 红外传感器==从左到右移动,THEN 触发离家场景。这东西还是需要你自己去设定规则,但当AI加入的时候,去学习你的使用习惯。你每天回家,第一件事情就是开某个家电:那我就知道你需要这个东西;以及,在你离家前你究竟做了些什么,那么我们自动去生成一些规则。












 Processors Brief
Processors Brief