那个折腾了半个的 Hugo 主题算是折腾完了
一个月前,折腾起了 Hugo 主题(太久没用主题功能,插入文章短代码都忘记了)。 因为当时刚好看到木…
很早之前就想做了,然后一直拖……一直拖……想起有这么个事,但天气不好……一直拖……一直拖……一直一直拖……
终于在了一个晴天多云的日子,找了个看起来还不错挺干净的景,背着一大包的设备,在同一时间段同一角度拍照片。
根据设备购买年份排序
都是古董。
本来手里能拍照的设备还有一个小米平板1和iPad4,但是反复检查了好几遍这俩机器,还检查了定期备份,都没发现当日的照片。可能是忘记拍摄了?
红米1虽然也能拍照,但是早就自杀无法开机了。
因为是无限远景,所以均未使用手动对焦。而且非触屏设备也没有手动对焦的功能。
所有图片均为原图,保留了EXIF信息但删除了所有GPS相关的meta。文件使用 Leanify 的 mozjpeg 进行无损压缩。
想要查看具体的EXIF信息,可以另存图片到本地,然后用EXIF工具查看。
图片是走 Cloudflare CDN 的,因为都是原图所以文件比较大,国内打开很慢很正常。
1600万像素(4608 × 3456)。CCD。未使用光学变焦。




30万像素(640 × 480)。
2007怀旧画质。


30万像素(640 × 480)。未使用3D效果。
2007怀旧画质 x2。老任个抠逼用这么低端的硬件也是传统艺能了。


500万像素(2592 × 1944)。使用 Free Xperia Project, CyanogenMod-7.2.0-mango 系统的相机应用。
不对比都发现不了,这手机拍照发黄?赶紧翻了下2013年时拍的照片,发现还真的偏黄,只是不严重,单拿出来发现不了。


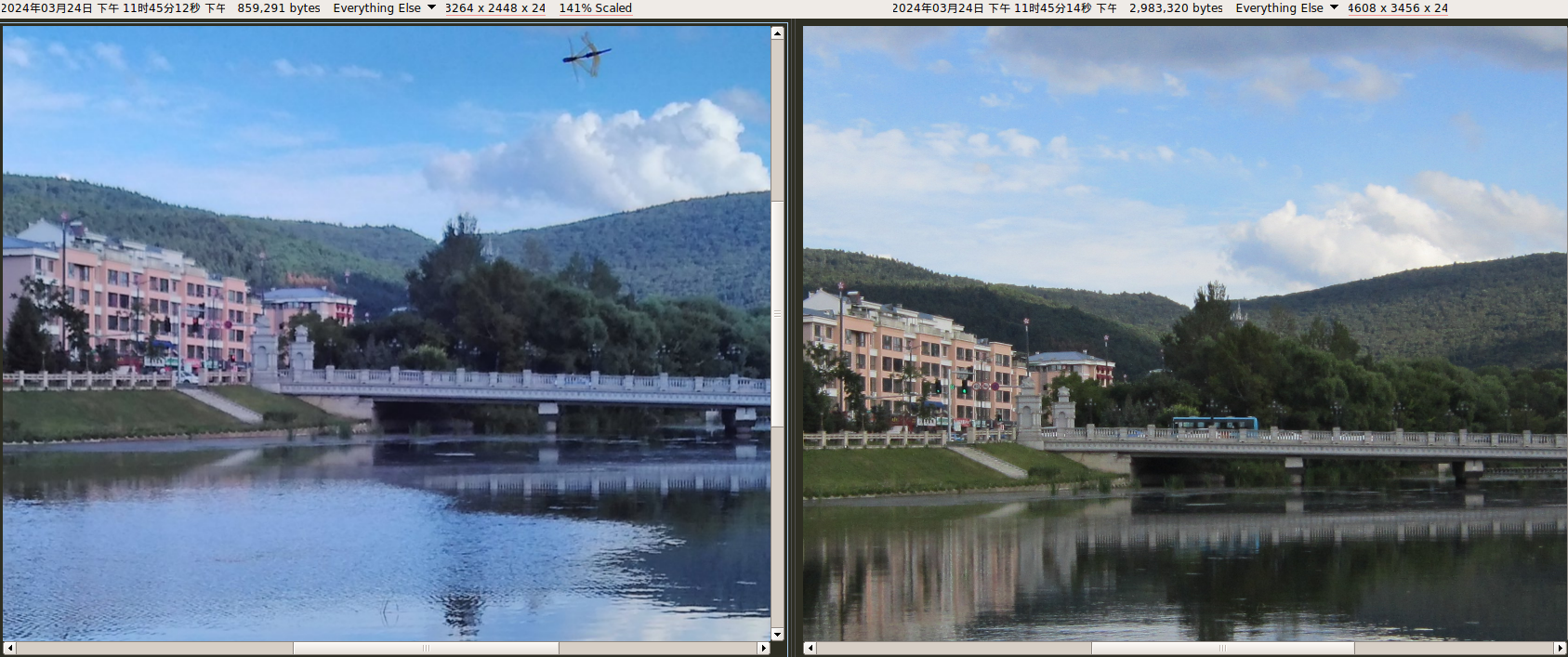
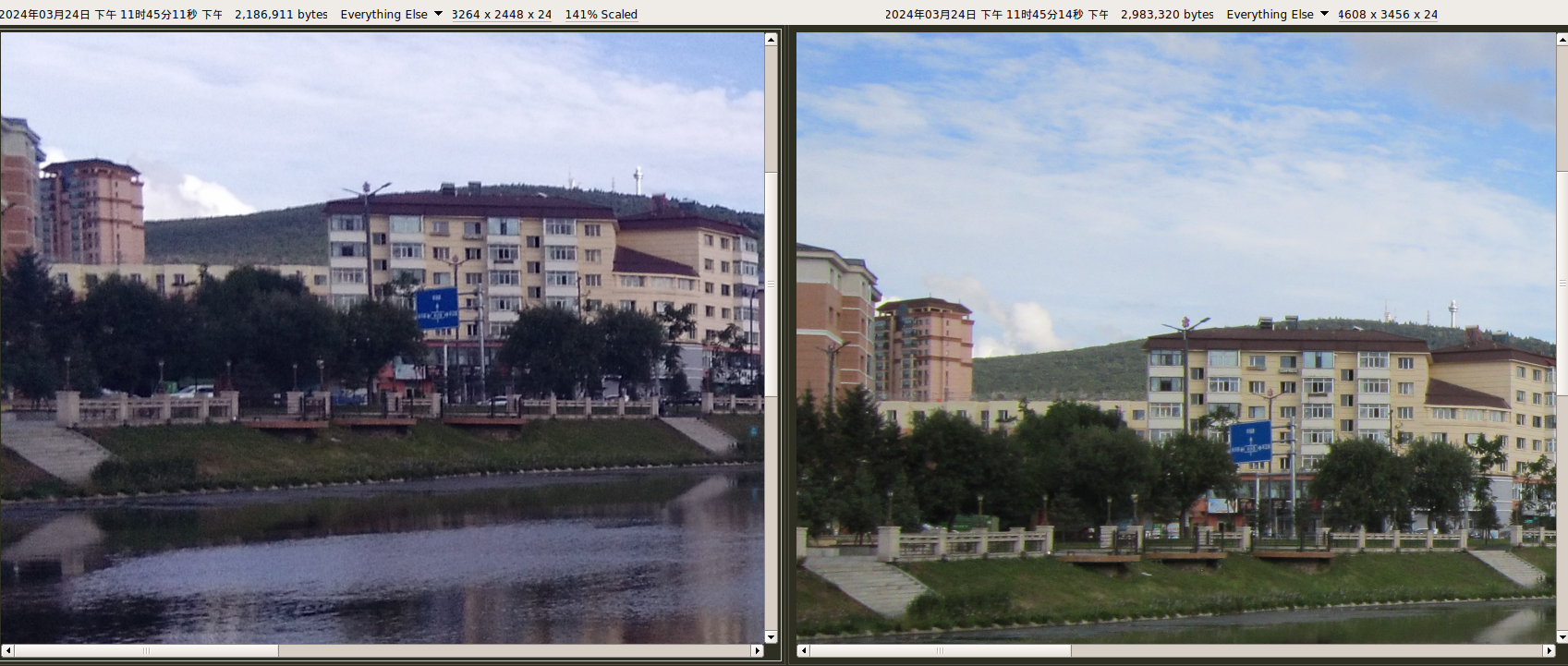
800万像素(3264 × 2448)。使用 LineageOS 15.1-20200223-NIGHTLY-wt88047 系统的相机应用。
拍第一张的时候自动光圈抽风,非常暗。
拍第二张的时候,这镜头前飞过来的这是个啥虫子???
反正这画质是够烂了,当年那么多人吹小米拍照(现在也很多人吹),也不知道有多少是水军。


800万像素(3264 × 2448)。使用系统自带拍照应用。
如果说 SK17i 是发黄,那 Y51A 就是发蓝。

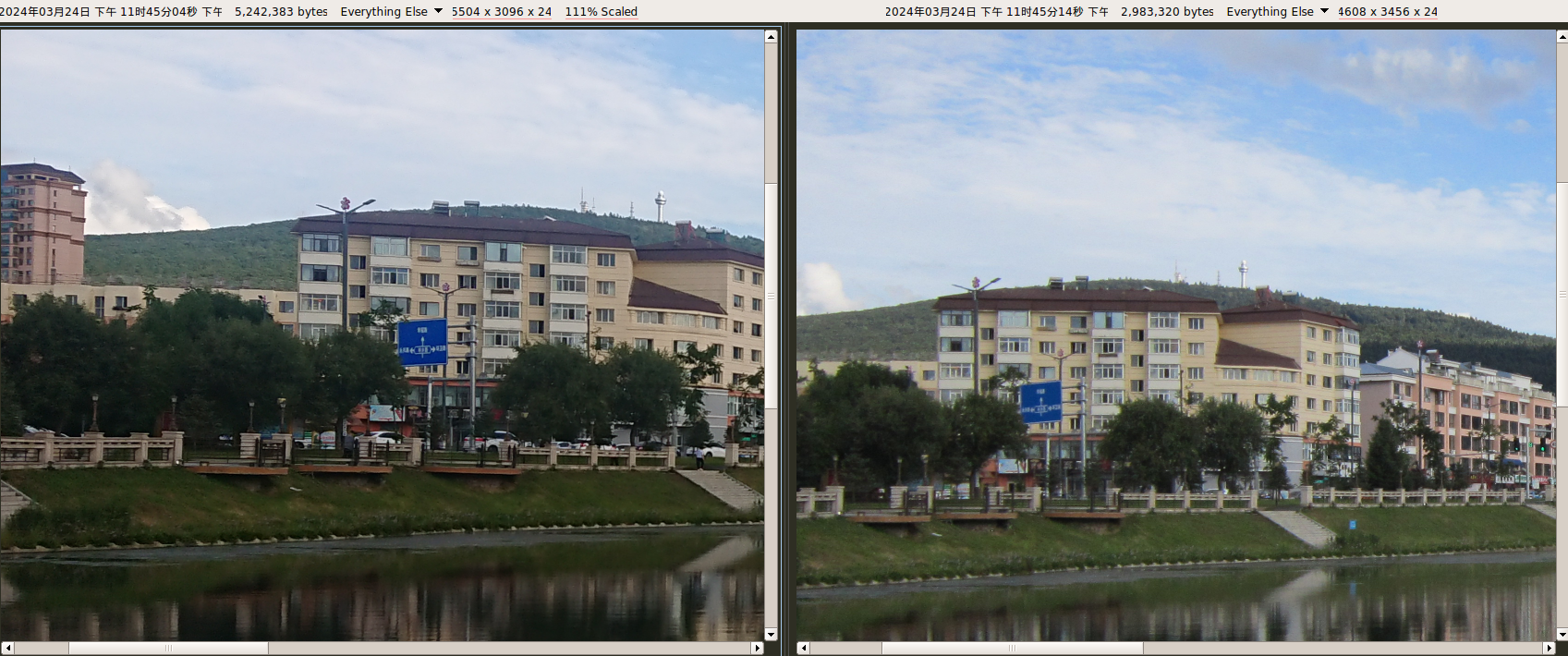
1700万像素(5504 × 3096)。使用系统自带拍照应用。自动模式,未开启 HDR。
像素比相机A3300还高,清晰度明显更占优势。但在手机镜头的硬件功能上差很多,相机永远是相机。


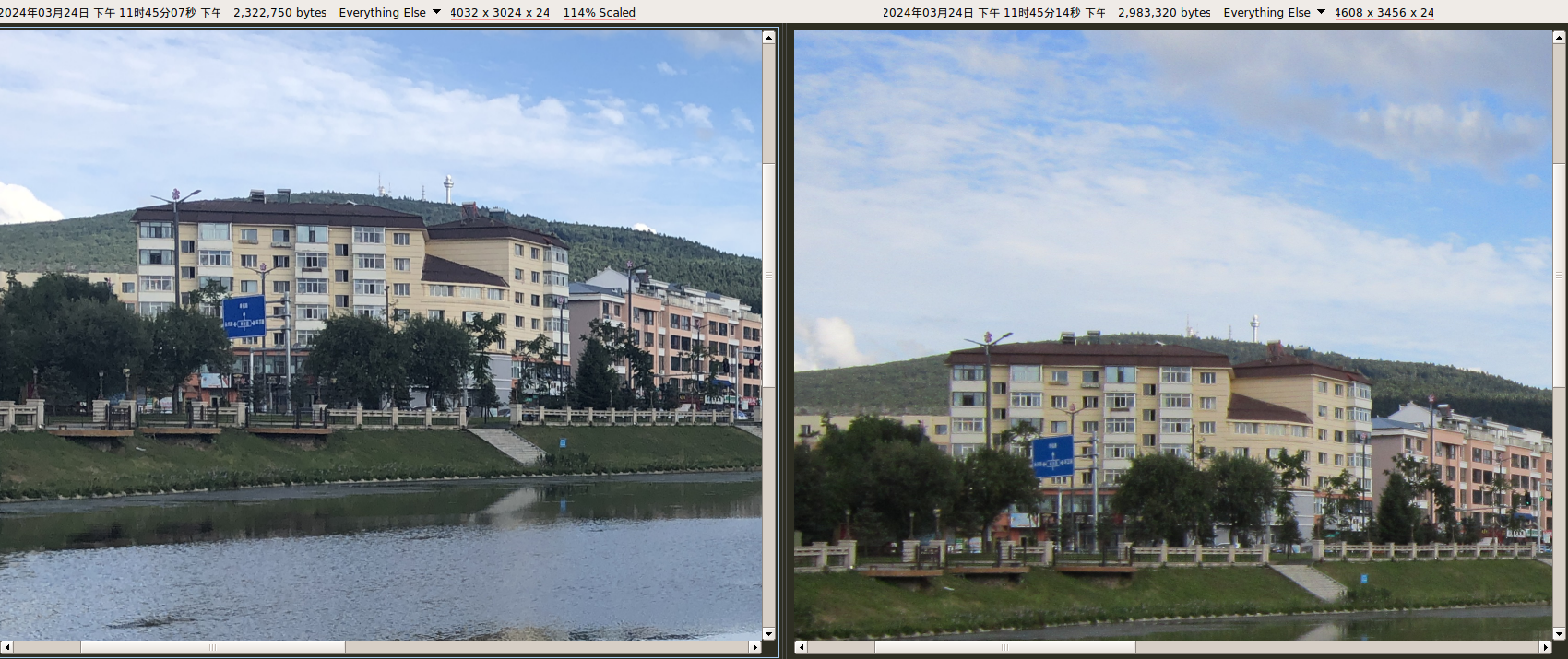
1200万像素(4032 × 3024)。使用系统自带拍照应用。自动模式,开启 HDR。使用JPG作为保存格式。(垃圾HEIF)
破玩意卖得贼拉贵,像素低,颜色微微发蓝(当然可能是太阳光照角度的问题。天气嘛,变幻莫测)。



以佳能A3300为基准做对比。
使用 BCompare 进行对比。对像素较少的图片进行缩放,以高度未基准(这意味着XZ1这个有更高分辨率但图像高度低,要被放大后才能追上A3310)。
几个不是一个级别的硬件就不跟 A3300 比了,其实也就 3DS 和 C2-00 单拿出来比一下就好。


都是古董。
以 A3300 的战斗力仍然能坚挺。2011年的千元卡片机直到2017年才被高端手机追平(还得是无光学变焦的前提下)。
只不过现在有 HDR 这种东西存在,解决了高对比度高点光源的问题,拍照难度下降一大截,而且现在手机都是多镜头(个人认为屁用没有,我甚至怀疑各个APP是否有真的调用过多镜头)。
而且索尼的运营策略也太过奇葩,就如同applemiku说的:索尼的产品总是把本应能做的功能,硬是留到下一代产品当卖点,恶心人,明显拥有两个版本周期的巨大优势,硬是要拖到下一个版本,然后发布出来时仍是半成品,然后半个版本周期内友商就做出来完成品,两个版本周期的巨大优势 被硬搞成 半个周期的一般特性,手机照相APP的HDR功能就是,默认不开启,必须进入手动模式才开启,然后内核不支持RAW进而导致第三方应用无法支持硬件HDR,作为一个卖点是照相的拍照手机来讲,这一块做得实在太拉胯了。更别说索尼还搞了个基于相机+六轴感应实现的3D建模扫描,做到一半服务器也崩了,谷歌Drive接口也崩了,崩得一塌糊涂,结果三星下一个版本就做出来了更好的应用,并作为核心卖点进行宣传,行业内甚至都没人想得起这玩意其实是索尼先开始做的。
反正现在我拍照也不拍场照了,漫展什么的自从荷花遍地之后就不感兴趣了,跑展甚至看不到什么原创商品,以前认识的作者基本上全都退圈了(不然呢,快40多岁还跑展摆摊,那身体得多棒才跑得动)。
现在拍照基本上就是拍拍景。点光源特别亮的那种景,即使是现在有 HDR 的手机也没见谁拍出来(猜测是人的拍照技术问题)。拍人的话顶多就是给家里老人拍照片,人家要求必须要用短视频APP开美颜拍照然后自动配乐……就当哄老人乐子了,什么构图什么清晰度都不需要。
再说现在遍地魔怔人。前几天我说我有台 Xperia ,结果某个群里就嘲讽上「这么破旧的手机你也用」,我也没说我用的是啥型号,Xperia 1 V 是2023年5月发布的,还不满一年。这就有人跳起来嘲讽,这互联网上疯子是真多了。
当然我是想买新手机新相机的,但是没钱。
The post 一堆可拍照的古董设备的成像效果「多图」 first appeared on 石樱灯笼博客.今天(9月8日)是我在多邻国 Duolingo 上学习法语的第100天。当前的数据统计:

这100天里,我最大的心得是感受到无压的新语言学习过程,没有强制考试,也没有面临具体考核的压力。唯一感受到紧迫感的机制可能来自等级排名。多邻国课程安排与大部分科班课程有较大不同。
多邻国的课程结构从大到小为:阶段 – 部分 – 单元 – 题目,每一种语言都有特定的课程设定。例如法语分为四个阶段(初入密林、挑战山地、横渡险滩、勇者无敌,还有隐藏的第5阶段),每一个阶段分为若干部分,每一个部分有6至10个单元,每个单元有15至20个题目(或称练习),其中单元是每天学习的最小单位,只有完成了一个单元才算完成一次学习,然后根据单元类型获得不同的经验。我当前已经到达第7部分。法语课程的第一阶段有8个部分,但到了第三阶段就有高达33个部分。
每一个部分有一个“部分指南”,这里会告诉用户这个部分即将学习到的重点语句和语法点,在看不懂具体的单元内容时,通常翻看部分指南就能搞明白。举两个例子,法语中的阴阳性是一个难点,第7部分指南会告诉用户“我的”这个词阳性为 mon,阴性为 ma;第5部分的题目里出现“在”这个词的 à 和 en 两种用法,我搞不明白,于是翻了翻部分指南,指南中解释道 à 用于城市,en 用于国家。这样下来,我在过关时碰到这类问题,翻阅部分指南就能避免一头雾水。
在每个单元中,具体的学习有选择题、连线题、填空题和听力题等,在网页端还会多一个跟读练习(在移动端反而没有,这有一点奇怪)。在目前的阶段里,学习内容还是比较简单的,从最简单的单词和句子开始,一步步培养阅读、听力和语感。与在学校中跟着教科书按部就班从字母拼写、音标发音开始学习不同,在多邻国学完前几个单元之后,感受如同已经踏入这个语言的大门。这是一种巨大的激励,这种激励会在学习过程中一直持续正向反馈。
根据官方给出的信息,多邻国会根据用户学习进度和效果调整课程,以及针对每一个用户个性化定制学习计划。在用户方面,用户可以更改每日目标,分为基础模式、休闲、正常、好学到密集模式,每日经验从1到50皆有,根据自己的计划灵活调整。在后端,多邻国根据用户过往学习的效果指定复习的内容,例如某些单词或者语法经常出错,在复习单元中会重复出现,直到彻底学会这个知识点为止。在练习集模块中甚至还错题本和专项复习(听力、口语),不过需要付费。
多邻国与众不同的地方就是大量吸收了游戏的机制和特点。除了上面提到的激励机制,还有特别挑战、快闪挑战、每日特别任务等。这些挑战会随机出现,完成后的奖励通常是经验和宝石或者其他道具。在每天的学习里,我几乎没有错过任何一个挑战,只要出现就必然参加,由此可以获得丰厚的经验,对我而言经验是最重要的激励机制,它能保证我持续学习下去,具体下一节细说。
宝石可以用来购买红心。红心是有限资源,免费用户只有5个,但付费用户有无限个。红心最主要的作用是错题机会,答错会扣掉一个红心,一旦错了5次,当天便不能再学习单元,只能通过宝石购买红心或者通过做练习恢复。一次练习有十几题,做完一次练习只能恢复一个红心。因此,在这个机制下,学习单元的过程会更加审慎而不是随意乱答,保证每一次完全答题获得额外奖励,并且保住5个红心。
宝石还能用作筹码,作为连胜的赌注:保证7天连胜,投入的宝石赢回双倍。这是比较明显的赌博性质,对于特定人群应该能够产生很大激励,但我对其比较无感。另一个宝石购买的道具叫做连胜激冻,能够给你一次一天不学习也不中断连胜的机会,我因参加过许多小挑战,已经获得上限5个,但从来没用过,因为其他机制保证我每天都会学习。
我最喜欢做的是快闪挑战,因为经验收益最丰富,每一次能有80经验。如果碰上做完一个单元随机获得“接下来15分钟经验翻倍”的 buff,再加上完美答题奖励,一次快闪挑战里能获得高达三百多经验,是所有练习和挑战中收益最高的。
每日特别任务就像 RPG 网游的日常活动,种类分为固定任务和随机生成任务,比如今天我的每日挑战任务是:获取50经验,4个单元达到至少80%正确率,在4个单元里连对5道题。我很难抗拒这种把每日任务做完的设定,我相信有网游经验的朋友大多如此。固定任务通常有获取 X 经验和学习 X 小时这类,能够作为当日最低限度的学习时间。这也变相激励用户每天都去学习。
在完成一个单元之后,用户可以再过一遍单元晋升传奇,能够获取40或80经验,也是收益非常高的项目,还能把知识点记得更牢些。如果碰上经验翻倍则高上加高。我在获得经验翻倍 buff 之后,必然会在15分钟之内完成一次传奇挑战、一次快闪挑战和一次新单元学习,这样能让自己在排行榜上升许多位。
排行榜是激励我每天在多邻国学习的核心设定。如同游戏中的天梯榜或段位榜,基本能大致反应你的效率和成果。每一周的排行榜随机分配近似学习程度的30个用户,排名根据用户当前获得的经验值动态刷新,一周结束后更新一次段位并重置经验值,总经验值在前五名的晋升下一等级,后七名滑落至上一等级,其他的保持原位置不变。多邻国中有10个等级、4个难度阶梯,用【金银铜牌】、【蓝红绿宝石】、【水晶、珍珠、黑曜石】、【钻石】来区分。
我本周达到黑曜石级别,花了很多时间只能堪堪维持在第十三名左右,排行榜上的头几位已经是四五千经验以上了,而最初在金银铜牌阶梯时的排行榜上的用户经验不过两三百,在不努力刷题的情况下每一两周都能晋升一个等级,这一周只能维持在黑曜石。此时的我应该调整策略,把重心完全放在学习质量上,而不是花太多心思刷排行榜。我有时会怀疑排行榜会不会大部分都是机器人。
多邻国的排行榜是可选项,用户可以一个人专注学习内容而不参与排名,这一点非常好评。有些用户会同时学习几个语言,使用不同设备参加不同挑战,让自己能在排行榜一骑绝尘。不过我想那已经背离学习语言的初衷了。
另外就是连胜成就机制。7天是一个小连胜,在30天、60天、100天、125天等等直到365天都有连胜成就。连胜的奖励有道具、新图标等,但是对我来说,填满连胜日历才是对我最大的奖励。
多邻国是多平台应用,包括两个移动端和 web 端,没有找到客户端的选项。我最常用的是在移动端,app 放在手机首屏最显眼处,每天固定在晚上学习,偶尔在中午。在100天后这已经形成一种习惯和肌肉记忆,不打开刷一遍题就浑身难受。
在这段时间的使用中我发现多邻国的一些问题。例如在账号方面区分了国内版本和国际版本,但是在官网或者 app 中没有明显提示信息。在国内版本注册的多邻国账号不能设置邮箱地址,也不能修改用户昵称,要在国际版本中才有这个选项。我曾经有一个旧帐号,但是一直碰到登陆不上、注册新账号又提示邮箱已使用的错误,网上查询一番后才发现有如此设计。
两个版本主要在一些无伤大雅的功能上有所区分,例如网页端国内版本没有排行榜和每日任务,也不能邀请好友;移动端的国际版本没有当天复习内容模块,网页端却两个版本都有。这些对于学习本身没有太大影响,但是总觉得有些别扭。
法语有一些特殊字母,所以需要专门的输入模式,就像中文的拼音输入法。我在手机上常年使用 Gboard 输入法,只要在设置里添加一个法语语言并开启建议栏就能轻松输入。有一个小细节,在需要输入单词的题目里,Gboard 会自动识别为法语输入法而不会是英语或中文,不知是多邻国的设定还是输入法本身如此智能。Gboard 的法语默认是 AZERTY 键位布局,区别于 QWERTY,导致经常输入错误,于是切换到 QWERTY 布局。电脑上就没这么方便了,没有合适的输入法,折腾一段时间后暂时放弃在电脑输入法语的想法。
起初使用多邻国学习法语是出于一时冲动,事实证明这个选择是正确的。想学习一门新语言,但是没有动力和信心走多一遍学习教材的路径,毕竟曾经有买了标日只学会了五十音图和两句日语的经历。又想起多年前曾经听说过多邻国 Duolingo 这个应用,不如直接下载下来,然后随意注册一个新账号(这是无法修改昵称和邮箱的原因),选择法语后就直接开始学习第一个单元。结果竟意外地有些轻松,又有些学到新知识惊喜。也许是有英语基础,法语学起来比想象中轻松许多,也没有一个明确目标,因此在三个多月的学习过程中最大的体验就是无压。在没有压力的前提下能保持一个轻松的心态,收获常常超出预期,学习效果也会更好。这种经验我想也可以应用到其他领域。
 今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
先说一下为什么要用etcd。先从一个我们自己做的一个API网关 – Easegress(源码)说起。
Easegress 是我们开发并开源的一个API应用网关产品,这个API应用网关不仅仅只是像nginx那样用来做一个反向代理,这个网关可以做的事很多,比如:API编排、服务发现、弹力设计(熔断、限流、重试等)、认证鉴权(JWT,OAuth2,HMAC等)、同样支持各种Cloud Native的架构如:微服务架构,Service Mesh,Serverless/FaaS的集成,并可以用于扛高并发、灰度发布、全链路压力测试、物联网……等更为高级的企业级的解决方案。所以,为了达到这些目标,在2017年的时候,我们觉得在现有的网关如Nginx上是无法演进出来这样的软件的,必需重新写一个(后来其他人也应该跟我们的想法一样,所以,Lyft写了一个Envoy。只不过,Envoy是用C++写的,而我用了技术门槛更低的Go语言)
另外,Easegress最核心的设计主要有三个:
对于任何一个分布式系统,都需要有一个强一制性的基于Paxos/Raft的可以自动选主机制,并且需要在整个集群间同步一些关键的控制/配置和相关的共享数据,以保证整个集群的行为是统一一致的。如果没有这么一个东西的话,就没有办法玩分布式系统的。这就是为什么会有像Zookeeper/etcd这样的组件出现并流行的原因。注意,Zookeeper他们主要不是给你存数据的,而是给你组集群的。
Zookeeper是一个很流行的开源软件,也被用于各大公司的生产线,包括一些开源软件,比如:Kafka。但是,这会让其它软件有一个依赖,并且在运维上带来很大的复杂度。所以,Kafka在最新的版本也通过内置了选主的算法,而抛弃了外挂zookeeper的设计。Etcd是Go语言社区这边的主力,也是kubernetes组建集群的关键组件。Easegress在一开始(5年前)使用了gossip协议同步状态(当时想的过于超前,想做广域网的集群),但是后发现这个协议太过于复杂,而且很难调试,而广域网的API Gateway也没遇到相应的场景。所以,在3年前的时候,为了稳定性的考量,我们把其换成了内嵌版本的etcd,这个设计一直沿用到今天。
Easegress会把所有的配置信息都放到etcd里,还包括一些统计监控数据,以及一些用户的自定义数据(这样用户自己的plugin不但可以在一条pipeline内,还可以在整个集群内共享数据),这对于用户进行扩展来说是非常方便的。软件代码的扩展性一直是我们追求的首要目标,尤其是开源软件更要想方设法降低技术门槛让技术易扩展,这就是为什么Google的很多开源软件都会选使用Go语言的原因,也是为什么Go正在取代C/C++的做PaaS基础组件的原因。
好了,在介绍完为什么要用etcd以后,我开始分享一个实际的问题了。我们有个用户在使用 Easegress 的时候,在Easegress内配置了上千条pipeline,导致 Easegress的内存飙升的非常厉害- 10+GB 以上,而且长时间还下不来。
用户报告的问题是——
在Easegress 1.4.1 上创建一个HTTP对象,1000个Pipeline,在Easegres初始化启动完成时的内存占用大概为400M,运行80分钟后2GB,运行200分钟后达到了4GB,这期间什么也没有干,对Easegress没有进行过一次请求。
一般来说,就算是API再多也不应该配置这么多的处理管道pipeline的,通常我们会使用HTTP API的前缀把一组属于一个类别的API配置在一个管道内是比较合理的,就像nginx下的location的配置,一般来说不会太多的。但是,在用户的这个场景下配置了上千个pipeline,我们也是头一次见,应该是用户想做更细粒度的控制。
经过调查后,我们发现内存使用基本全部来自etcd,我们实在没有想到,因为我们往etcd里放的数据也没有多少个key,感觉不会超过10M,但不知道为什么会占用了10GB的内存。这种时候,一般会怀疑etcd有内存泄漏,上etcd上的github上搜了一下,发现etcd在3.2和3.3的版本上都有内存泄露的问题,但都修改了,而 Easegress 使用的是3.5的最新版本,另外,一般来说内存泄漏的问题不会是这么大的,我们开始怀疑是我们哪里误用了etcd。要知道是否误用了etcd,那么只有一条路了,沉下心来,把etcd的设计好好地看一遍。
大概花了两天左右的时间看了一下etcd的设计,我发现了etcd有下面这些消耗内存的设计,老实说,还是非常昂贵的,这里分享出来,避免后面的同学再次掉坑。
首当其冲是——RaftLog。etcd用Raft Log,主要是用于帮助follower同步数据,这个log的底层实现不是文件,而是内存。所以,而且还至少要保留 5000 条最新的请求。如果key的size很大,这 5000条就会产生大量的内存开销。比如,不断更新一个 1M的key,哪怕是同一个key,这 5000 条Log就是 5000MB = 5GB 的内存开销。这个问题在etcd的issue列表中也有人提到过 issue #12548 ,不过,这个问题不了了之了。这个5000还是一个hardcode,无法改。(参看 DefaultSnapshotCatchUpEntries 相关源码)
// DefaultSnapshotCatchUpEntries is the number of entries for a slow follower // to catch-up after compacting the raft storage entries. // We expect the follower has a millisecond level latency with the leader. // The max throughput is around 10K. Keep a 5K entries is enough for helping // follower to catch up. DefaultSnapshotCatchUpEntries uint64 = 5000
另外,我们还发现,这个设计在历史上etcd的官方团队把这个默认值从10000降到了5000,我们估计etcd官方团队也意识到10000有点太耗内存了,所以,降了一半,但是又怕follwer同步不上,所以,保留了 5000条……(在这里,我个人感觉还有更好的方法,至少不用全放在内存里吧……)
另外还有下面几项也会导致etcd的内存会增加
(很明显,etcd这么做就是为了一个高性能的考虑)
Easegress中的问题更多的应该是Raft Log 的问题。后面三种问题我们觉得不会是用户这个问题的原因,对于索引和mmap,使用 etcd 的 compact 和 defreg (压缩和碎片整理应该可以降低内存,但用户那边不应该是这个问题的核心原因)。
针对用户的问题,大约有1000多条pipeline,因为Easegress会对每一条pipeline进行数据统计(如:M1, M5, M15, P99, P90, P50等这样的统计数据),统计信息可能会有1KB-2KB左右,但Easegress会把这1000条pipeline的统计数据合并起来写到一个key中,这1000多条的统计数据合并后会导致出现一个平均尺寸为2MB的key,而5000个in-memory的RaftLog导致etcd要消耗了10GB的内存。之前没有这么多的pipeline的场景,所以,这个内存问题没有暴露出来。
于是,我们最终的解决方案也很简单,我们修改我们的策略,不再写这么大的Value的数据了,虽然以前只写在一个key上,但是Key的值太大,现在把这个大Key值拆分成多个小的key来写,这样,实际保存的数据没有发生变化,但是RaftLog的每条数据量就小了,所以,以前是5000条 2M(10GB),现在是5000条 1K(500MB),就这样解决了这个问题。相关的PR在这里 PR#542 。
要用好 etcd,有如下的实践
MADV_FREE 的内存回收机制,而在1.16的时候,改成了 MADV_DONTNEED ,这两者的差别是,FREE表示,虽然进程标记内存不要了,但是操作系统会保留之,直到需要更多的内存,而 DONTNEED 则是立马回收,你可以看到,在常驻内存RSS 上,前者虽然在golang的进程上回收了内存,但是RSS值不变,而后者会看到RSS直立马变化。Linux下对 MADV_FREE 的实现在某些情况下有一定的问题,所以,在go 1.16的时候,默认值改成了 MADV_DONTNEED 。而 etcd 3.4 是用 来1.12 编译的。最后,欢迎大家关注我们的开源软件! https://github.com/megaease/
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
 Go语言的1.17版本发布了,其中开始正式支持泛型了。虽然还有一些限制(比如,不能把泛型函数export),但是,可以体验了。我的这个《Go编程模式》的系列终于有了真正的泛型编程了,再也不需要使用反射或是go generation这些难用的技术了。周末的时候,我把Go 1.17下载下来,然后,体验了一下泛型编程,还是很不错的。下面,就让我们来看一下Go的泛型编程。(注:不过,如果你对泛型编程的重要性还不是很了解的话,你可以先看一下之前的这篇文章《Go编程模式:Go Generation》,然后再读一下《Go编程模式:MapReduce》)
Go语言的1.17版本发布了,其中开始正式支持泛型了。虽然还有一些限制(比如,不能把泛型函数export),但是,可以体验了。我的这个《Go编程模式》的系列终于有了真正的泛型编程了,再也不需要使用反射或是go generation这些难用的技术了。周末的时候,我把Go 1.17下载下来,然后,体验了一下泛型编程,还是很不错的。下面,就让我们来看一下Go的泛型编程。(注:不过,如果你对泛型编程的重要性还不是很了解的话,你可以先看一下之前的这篇文章《Go编程模式:Go Generation》,然后再读一下《Go编程模式:MapReduce》)
我们先来看一个简单的示例:
package main
import "fmt"
func print[T any] (arr []T) {
for _, v := range arr {
fmt.Print(v)
fmt.Print(" ")
}
fmt.Println("")
}
func main() {
strs := []string{"Hello", "World", "Generics"}
decs := []float64{3.14, 1.14, 1.618, 2.718 }
nums := []int{2,4,6,8}
print(strs)
print(decs)
print(nums)
}
上面这个例子中,有一个 print() 函数,这个函数就是想输出数组的值,如果没有泛型的话,这个函数需要写出 int 版,float版,string 版,以及我们的自定义类型(struct)的版本。现在好了,有了泛型的支持后,我们可以使用 [T any] 这样的方式来声明一个泛型类型(有点像C++的 typename T),然后面都使用 T 来声明变量就好。
上面这个示例中,我们泛型的 print() 支持了三种类型的适配—— int型,float64型,和 string型。要让这段程序跑起来需要在编译行上加上 -gcflags=-G=3编译参数(这个编译参数会在1.18版上成为默认参数),如下所示:
$ go run -gcflags=-G=3 ./main.go
有了个操作以后,我们就可以写一些标准的算法了,比如,一个查找的算法
func find[T comparable] (arr []T, elem T) int {
for i, v := range arr {
if v == elem {
return i
}
}
return -1
}
我们注意到,我们没有使用 [T any]的形式,而是使用 [T comparable]的形式,comparable是一个接口类型,其约束了我们的类型需要支持 == 的操作, 不然就会有类型不对的编译错误。上面的这个 find() 函数同样可以使用于 int, float64或是string类型。
从上面的这两个小程序来看,Go语言的泛型已基本可用了,只不过,还有三个问题:
fmt.Printf()中的泛型类型是 %v 还不够好,不能像c++ iostream重载 >> 来获得程序自定义的输出。== 等find() 算法依赖于“数组”,对于hash-table、tree、graph、link等数据结构还要重写。也就是说,没有一个像C++ STL那样的一个泛型迭代器(这其中的一部分工作当然也需要通过重载操作符(如:++ 来实现)不过,这个已经很好了,让我们来看一下,可以干哪些事了。
编程支持泛型最大的优势就是可以实现类型无关的数据结构了。下面,我们用Slices这个结构体来实现一个Stack的数结构。
首先,我们可以定义一个泛型的Stack
type stack [T any] []T
看上去很简单,还是 [T any] ,然后 []T 就是一个数组,接下来就是实现这个数据结构的各种方法了。下面的代码实现了 push() ,pop(),top(),len(),print()这几个方法,这几个方法和 C++的STL中的 Stack很类似。(注:目前Go的泛型函数不支持 export,所以只能使用第一个字符是小写的函数名)
func (s *stack[T]) push(elem T) {
*s = append(*s, elem)
}
func (s *stack[T]) pop() {
if len(*s) > 0 {
*s = (*s)[:len(*s)-1]
}
}
func (s *stack[T]) top() *T{
if len(*s) > 0 {
return &(*s)[len(*s)-1]
}
return nil
}
func (s *stack[T]) len() int{
return len(*s)
}
func (s *stack[T]) print() {
for _, elem := range *s {
fmt.Print(elem)
fmt.Print(" ")
}
fmt.Println("")
}
上面的这个例子还是比较简单的,不过在实现的过程中,对于一个如果栈为空,那么 top()要么返回error要么返回空值,在这个地方卡了一下。因为,之前,我们返回的“空”值,要么是 int 的0,要么是 string 的 “”,然而在泛型的T下,这个值就不容易搞了。也就是说,除了类型泛型后,还需要有一些“值的泛型”(注:在C++中,如果你要用一个空栈进行 top() 操作,你会得到一个 segmentation fault),所以,这里我们返回的是一个指针,这样可以判断一下指针是否为空。
下面是如何使用这个stack的代码。
func main() {
ss := stack[string]{}
ss.push("Hello")
ss.push("Hao")
ss.push("Chen")
ss.print()
fmt.Printf("stack top is - %v\n", *(ss.top()))
ss.pop()
ss.pop()
ss.print()
ns := stack[int]{}
ns.push(10)
ns.push(20)
ns.print()
ns.pop()
ns.print()
*ns.top() += 1
ns.print()
ns.pop()
fmt.Printf("stack top is - %v\n", ns.top())
}
下面我们再来看一个双向链表的实现。下面这个实现中实现了 这几个方法:
add() – 从头插入一个数据结点push() – 从尾插入一个数据结点del() – 删除一个结点(因为需要比较,所以使用了 compareable 的泛型)print() – 从头遍历一个链表,并输出值。type node[T comparable] struct {
data T
prev *node[T]
next *node[T]
}
type list[T comparable] struct {
head, tail *node[T]
len int
}
func (l *list[T]) isEmpty() bool {
return l.head == nil && l.tail == nil
}
func (l *list[T]) add(data T) {
n := &node[T] {
data : data,
prev : nil,
next : l.head,
}
if l.isEmpty() {
l.head = n
l.tail = n
}
l.head.prev = n
l.head = n
}
func (l *list[T]) push(data T) {
n := &node[T] {
data : data,
prev : l.tail,
next : nil,
}
if l.isEmpty() {
l.head = n
l.tail = n
}
l.tail.next = n
l.tail = n
}
func (l *list[T]) del(data T) {
for p := l.head; p != nil; p = p.next {
if data == p.data {
if p == l.head {
l.head = p.next
}
if p == l.tail {
l.tail = p.prev
}
if p.prev != nil {
p.prev.next = p.next
}
if p.next != nil {
p.next.prev = p.prev
}
return
}
}
}
func (l *list[T]) print() {
if l.isEmpty() {
fmt.Println("the link list is empty.")
return
}
for p := l.head; p != nil; p = p.next {
fmt.Printf("[%v] -> ", p.data)
}
fmt.Println("nil")
}
上面这个代码都是一些比较常规的链表操作,学过链表数据结构的同学应该都不陌生,使用的代码也不难,如下所示,都很简单,看代码就好了。
func main(){
var l = list[int]{}
l.add(1)
l.add(2)
l.push(3)
l.push(4)
l.add(5)
l.print() //[5] -> [2] -> [1] -> [3] -> [4] -> nil
l.del(5)
l.del(1)
l.del(4)
l.print() //[2] -> [3] -> nil
}
接下来,我们就要来看一下我们函数式编程的三大件 map() 、 reduce() 和 filter() 在之前的《Go编程模式:Map-Reduce》文章中,我们可以看到要实现这样的泛型,需要用到反射,代码复杂到完全读不懂。下面来看一下真正的泛型版本。
func gMap[T1 any, T2 any] (arr []T1, f func(T1) T2) []T2 {
result := make([]T2, len(arr))
for i, elem := range arr {
result[i] = f(elem)
}
return result
}
在上面的这个 map函数中我使用了两个类型 – T1 和 T2 ,
T1 – 是需要处理数据的类型T2 – 是处理后的数据类型T1 和 T2 可以一样,也可以不一样。
我们还有一个函数参数 – func(T1) T2 意味着,进入的是 T1 类型的,出来的是 T2 类型的。
然后,整个函数返回的是一个 []T2
好的,我们来看一下怎么使用这个map函数:
nums := []int {0,1,2,3,4,5,6,7,8,9}
squares := gMap(nums, func (elem int) int {
return elem * elem
})
print(squares) //0 1 4 9 16 25 36 49 64 81
strs := []string{"Hao", "Chen", "MegaEase"}
upstrs := gMap(strs, func(s string) string {
return strings.ToUpper(s)
})
print(upstrs) // HAO CHEN MEGAEASE
dict := []string{"零", "壹", "贰", "叁", "肆", "伍", "陆", "柒", "捌", "玖"}
strs = gMap(nums, func (elem int) string {
return dict[elem]
})
print(strs) // 零 壹 贰 叁 肆 伍 陆 柒 捌 玖
接下来,我们再来看一下我们的Reduce函数,reduce函数是把一堆数据合成一个。
func gReduce[T1 any, T2 any] (arr []T1, init T2, f func(T2, T1) T2) T2 {
result := init
for _, elem := range arr {
result = f(result, elem)
}
return result
}
函数实现起来很简单,但是感觉不是很优雅。
T1 和 T2,前者是输出数据的类型,后者是佃出数据的类型。init,是 T2 类型func(T2, T1) T2,会把这个init值传给用户,然后用户处理完后再返回出来。下面是一个使用上的示例——求一个数组的和
nums := []int {0,1,2,3,4,5,6,7,8,9}
sum := gReduce(nums, 0, func (result, elem int) int {
return result + elem
})
fmt.Printf("Sum = %d \n", sum)
filter函数主要是用来做过滤的,把数据中一些符合条件(filter in)或是不符合条件(filter out)的数据过滤出来,下面是相关的代码示例
func gFilter[T any] (arr []T, in bool, f func(T) bool) []T {
result := []T{}
for _, elem := range arr {
choose := f(elem)
if (in && choose) || (!in && !choose) {
result = append(result, elem)
}
}
return result
}
func gFilterIn[T any] (arr []T, f func(T) bool) []T {
return gFilter(arr, true, f)
}
func gFilterOut[T any] (arr []T, f func(T) bool) []T {
return gFilter(arr, false, f)
}
其中,用户需要提从一个 bool 的函数,我们会把数据传给用户,然后用户只需要告诉我行还是不行,于是我们就会返回一个过滤好的数组给用户。
比如,我们想把数组中所有的奇数过滤出来
nums := []int {0,1,2,3,4,5,6,7,8,9}
odds := gFilterIn(nums, func (elem int) bool {
return elem % 2 == 1
})
print(odds)
正如《Go编程模式:Map-Reduce》中的那个业务示例,我们在这里再做一遍。
首先,我们先声明一个员工对象和相关的数据
type Employee struct {
Name string
Age int
Vacation int
Salary float32
}
var employees = []Employee{
{"Hao", 44, 0, 8000.5},
{"Bob", 34, 10, 5000.5},
{"Alice", 23, 5, 9000.0},
{"Jack", 26, 0, 4000.0},
{"Tom", 48, 9, 7500.75},
{"Marry", 29, 0, 6000.0},
{"Mike", 32, 8, 4000.3},
}
然后,我们想统一下所有员工的薪水,我们就可以使用前面的reduce函数
total_pay := gReduce(employees, 0.0, func(result float32, e Employee) float32 {
return result + e.Salary
})
fmt.Printf("Total Salary: %0.2f\n", total_pay) // Total Salary: 43502.05
我们函数这个 gReduce 函数有点啰嗦,还需要传一个初始值,在用户自己的函数中,还要关心 result 我们还是来定义一个更好的版本。
一般来说,我们用 reduce 函数大多时候基本上是统计求和或是数个数,所以,是不是我们可以定义的更为直接一些?比如下面的这个 CountIf(),就比上面的 Reduce 干净了很多。
func gCountIf[T any](arr []T, f func(T) bool) int {
cnt := 0
for _, elem := range arr {
if f(elem) {
cnt += 1
}
}
return cnt;
}
我们做求和,我们也可以写一个Sum的泛型。
T 类型的数据,返回 U类型的结果T 的 U 类型的数据就可以了。代码如下所示:
type Sumable interface {
type int, int8, int16, int32, int64,
uint, uint8, uint16, uint32, uint64,
float32, float64
}
func gSum[T any, U Sumable](arr []T, f func(T) U) U {
var sum U
for _, elem := range arr {
sum += f(elem)
}
return sum
}
上面的代码我们动用了一个叫 Sumable 的接口,其限定了 U 类型,只能是 Sumable里的那些类型,也就是整型或浮点型,这个支持可以让我们的泛型代码更健壮一些。
于是,我们就可以完成下面的事了。
1)统计年龄大于40岁的员工数
old := gCountIf(employees, func (e Employee) bool {
return e.Age > 40
})
fmt.Printf("old people(>40): %d\n", old)
// ld people(>40): 2
2)统计薪水超过 6000元的员工数
high_pay := gCountIf(employees, func(e Employee) bool {
return e.Salary >= 6000
})
fmt.Printf("High Salary people(>6k): %d\n", high_pay)
//High Salary people(>6k): 4
3)统计年龄小于30岁的员工的薪水
younger_pay := gSum(employees, func(e Employee) float32 {
if e.Age < 30 {
return e.Salary
}
return 0
})
fmt.Printf("Total Salary of Young People: %0.2f\n", younger_pay)
//Total Salary of Young People: 19000.00
4)统计全员的休假天数
total_vacation := gSum(employees, func(e Employee) int {
return e.Vacation
})
fmt.Printf("Total Vacation: %d day(s)\n", total_vacation)
//Total Vacation: 32 day(s)
5)把没有休假的员工过滤出来
no_vacation := gFilterIn(employees, func(e Employee) bool {
return e.Vacation == 0
})
print(no_vacation)
//{Hao 44 0 8000.5} {Jack 26 0 4000} {Marry 29 0 6000}
怎么样,你大概了解了泛型编程的意义了吧。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)






