CDN场景下配置Vaultwarden启用fail2ban
Vaulwarden 是一个开源自托管的密码管理工具,这个项目使用 Rust 实现了一套 Bitwarden Server API, 很多小伙伴都用它来管理密钥与凭证。 本文将利用 fail2ban 来实现在 CDN 场景下的防暴力破解。
Vaulwarden 是一个开源自托管的密码管理工具,这个项目使用 Rust 实现了一套 Bitwarden Server API, 很多小伙伴都用它来管理密钥与凭证。 本文将利用 fail2ban 来实现在 CDN 场景下的防暴力破解。
我们的部分后端服务正在经历容器化的改造, 由于历史包袱,现网的网关等设施无法一次性迁移到 k8s 集群中, 因此使用 Nginx proxy_pass 转发到 AWS ALB 这样一个曲线救国的临时方案。
但是在使用时,我们发现一段时间后 Nginx 出现了 504 的错误,检查后端服务均是正常的,而单独访问 ALB 也是正常响应的,因此便有了此文。
我们在远程办公时通常需要通过内部 OpenV** 来访问公司内部的敏感系统, 默认情况下, OpenV** 会临时修改本地路由表,将所有流量都指向了 v**_gateway,导致一些本地规则被覆盖,甚至无法打开部分国内的网站,带来了很多不便。这里记录一下手动指定路由规则的配置,仅让指定的网段或域名走 gateway。
众所周知,我们可以通过修改本地 hosts 文件来定义一个域名的指向,这个过程我们可以简单的理解为在本机创建了一个优先级很高的 DNS A 记录,实现了某种程度上的域名劫持, 利用这种特性我们可以实现诸如广告屏蔽、本地测试、别名等需求,但 hosts 机制仅仅能定义域名与 IP 对应关系, 并不能模拟其他的 Record 类型, 比如 CNAME 记录。
迫于无法忍受现成的 NAS 系统的限制,Alliot 正在着手将最常用的一些服务剥离出来,方便迁移与定制, WebDAV 首当其冲, Alliot 在许多场景下的同步与备份都依赖它。
WebDAV 作为一种基于HTTP/HTTPS协议的网络通信协议,预想是非常简单的,然而在具体动手的过程中还是遇到了挺多坑,Obsidian 的 Remotely-save 便是其中一个。
本文将基于 Nginx/Tengine 手把手构建一个 WebDAV 服务。
在工作中,常常会容易遇到一台电脑用多个 Git 账号的场景,比如账号 company 账号是工作用的,而账号 personal 是自己个人用的。 由于 Git 本身并没有多账号的机制,导致我们在默认设置下无法很好的区分哪个仓库使用哪个账号。 同时,在某些众所周知的场景下,我们无法直接访问到 Github 仓库,需要走一层 proxy 来加速我们的代码拉取与推送速度, 本文将使用 SSH config 相对优雅的解决这些问题。
一台服务器配置了 logrotate 来对 tomcat 日志进行切割,手动执行 logrotate /etc/logrotate.conf 的时候是正常,但是systemd timer 触发的 logrotate.service 状态为 failure, 手动执行 systemctl status logrotate.service 可以看到报错信息:logrotate[2870734]: error: error opening /usr/local/tomcat/logs/catalina.out: Read-only file system
许多同学家里都有软路由或者小型服务器,用来跑一些个人的小程序,或者跑 TeamTalk 等。现在 IPv6 已经基本普及,好处是每个设备甚至每个容器都能分配到一个公网 IP 地址,坏处也显而易见,那就是,之前靠路由器来充当防火墙的搞法已经不奏效了。为啥捏?因为之前基本都是在路由器上做端口映射,可以有选择地开放端口到互联网上,现在则是整个系统暴露到了互联网。
看到这里,聪明的同学应该都已经知道俺想表达的意思啦。没错,咱们都是通过 SSH 来控制服务器的,一旦它被入侵,后果是很严重滴!删库跑路还不是最大的问题,最大的问题是骇客潜伏在服务器里,三天两头搞些事情,如果你有很多的虚拟机,仅凭一己之力,是很难彻底跟踪入侵踪迹的。
首先,通过终端/SSH 之类的方法登录你的服务器,并进入 /etc/ssh 目录,用 cp 命令备份一下 sshd_config 文件,具体命令俺就不多费口水了。备份好之后,用你习惯的编辑器打开 sshd_config 文件,比如俺喜欢用 nano 编辑器,命令是 nano sshd_config。
找到 #AddressFamily any 这一行,把前面的“#(警号)”删除,改成 AddressFamily inet。往下找到 #ListenAddress 0.0.0.0,再把前面的“#”删除。最后,保存 sshd_config 文件。
这还没完!要想让修改生效,必须重启 SSH 服务端软件,在 CentOS/Debian/Ubuntu 系统上,命令是 systemctl restart sshd,在 Alpine Linux 系统上,命令是 service sshd restart。
切记!先别断开 SSH 连接,一定要看刚才执行命令后是否有报错信息,如果有,赶紧恢复之前的备份,然后重新修改配置文件并再次尝试重启。
当修改完成后,一定要有复查的习惯。咋复查捏?在有 IPv6 连接的内网电脑上,通过 SSH 连接服务器的 IPv6 地址,如果连接不上就表示修改成功了。为了避免误判,俺建议通过 ping 以及连接这台服务器的其他端口(例如 Web 端口)来再次确认。
本文整理了一些 Linux 时钟源 tsc 相关的软硬件知识,在一些故障排查场景可能会用到。

Fig. Scaling up crystal frequency for different components of a computer. Image source Youtube
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
~20MHz 的石英晶体谐振器(quartz crystal resonator)石英晶体谐振器是利用石英晶体(又称水晶)的压电效应 来产生高精度振荡频率的一种电子器件。
- 1880 年由雅克·居里与皮埃尔·居里发现压电效应。
- 一战期间 保罗·朗之万首先探讨了石英谐振器在声纳上的应用。
- 1917 第一个由晶体控制的电子式振荡器。
- 1918 年贝尔实验室的 Alexander M. Nicholson 取得专利,虽然与同时申请专利的 Walter Guyton Cady 曾有争议。
- 1921 年 Cady 制作了第一个石英晶体振荡器。
Wikipedia 石英晶体谐振器
现在一般长这样,焊在计算机主板上,

Fig. A miniature 16 MHz quartz crystal enclosed in a hermetically sealed HC-49/S package, used as the resonator in a crystal oscillator. Image source wikipedia
受物理特性的限制,只有几十 MHz。
计算机的内存、PCIe 设备、CPU 等等组件需要的工作频率不一样(主要原因之一是其他组件跟不上 CPU 的频率), 而且都远大于几十 MHz,因此需要对频率做提升。工作原理:
有个视频解释地很形象,
Fig. Scaling up crystal frequency for different components of a computer. Image source Youtube
图中的 clock generator 是个专用芯片,也是焊在主板上,一般跟晶振挨着。
~20MHz 提升到 ~3GHz 的本节稍微再开展一下,看看 CPU 频率是如何提升到我们常见的 ~3GHz 这么高的。
CLK 引脚结合上面的图,时钟信号的传递/提升路径:
~20MHz)时钟信号连接到 CPU 的一个名为 CLK 的引脚。
两个具体的 CLK 引脚实物图:
Intel 486 处理器(1989)

Fig. Intel 486 pin mapImage Source
这种 CPU 引脚今天看来还是很简单的,CLK 在第三行倒数第三列。
AMD SP3 CPU Socket (2017)
EPYC 7001/7002/7003 系列用的这种。图太大了就不放了,见 SP3 Pin Map。
现代 CPU 内部一般还有一个 clock generator,可以继续提升频率,
最终达到厂商宣传里的基频(base frequency)或标称频率(nominal frequency),例如 EPYC 6543 的 2795MHz。
这跟原始晶振频率比,已经提升了上百倍。
介绍点必要的背景知识,有基础的可跳过。
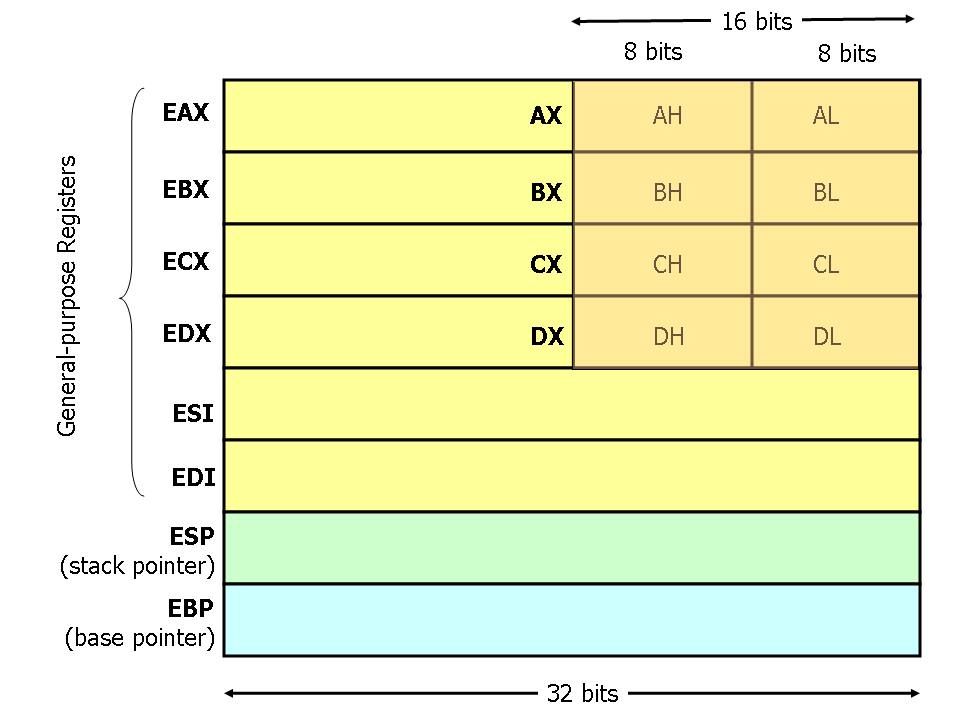
Fig. 32-bit x86 general purpose registers [1]
计算机执行的所有代码,几乎都是经由通用寄存器完成的。 进一步了解:简明 x86 汇编指南(2017)。
如名字所示,用于特殊目的,一般也需要配套的特殊指令读写。大致分为几类:
mode-specific registers (MSR)接下来我们主要看下 MSR 类型。
MSR)MSR 是 x86 架构中的一组控制寄存器(control registers),
设计用于 debugging/tracing/monitoring 等等目的,以下是 AMD 的一些系统寄存器,
其中就包括了 MSR 寄存器们,来自 AMD64 Architecture Programmer’s Manual, Volume 3 (PDF),

Fig. AMD system registers, which include some MSR registers
几个相关的指令:
RDMSR/WRMSR 指令:读写 MSR registers;CPUID 指令:检查 CPU 是否支持某些特性。RDMSR/WRMSR 指令使用方式:
- 需要 priviledged 权限。
- Linux
msr内核模块创建了一个伪文件/dev/cpu/{id}/msr,用户可以读写这个文件。还有一个msr-tools工具包。
MSR 之一:TSC今天我们要讨论的是 MSR 中与时间有关的一个寄存器,叫 TSC (Time Stamp Counter)。
Time Stamp Counter (TSC) 是 X86 处理器
(Intel/AMD/…)中的一个 64-bit 特殊目的 寄存器,属于 MRS 的一种。
还是 AMD 编程手册中的图,可以看到 MSR 和 TSC 的关系:
Fig. AMD system registers, which include some MSR registers
注意:在多核情况下(如今几乎都是多核了),每个物理核(processor)都有一个 TSC register,
或者说这是一个 per-processor register。
cycles 数量前面已经介绍过,时钟信号经过层层提升之后,最终达到 CPU 期望的高运行频率,然后就会在这个频率上工作。
这里有个 CPU cycles(指令周期)的概念:
频率没经过一个周期(1Hz),CPU cycles 就增加 1 —— TSC 记录的就是从 CPU 启动(或重置)以来的累计 cycles。
这也呼应了它的名字:时间戳计数器。
根据以上原理,如果 CPU 频率恒定且不存在 CPU 重置的话,
所以无怪乎 TSC 被大量用户空间程序当做开销地高精度的时钟。
本质上用户空间程序只需要一条指令(RDTSC),就能读取这个值。非常简单的几行代码:
unsigned long long rdtsc() {
unsigned int lo, hi;
__asm__ volatile ("rdtsc" : "=a" (lo), "=d" (hi));
return ((unsigned long long)hi << 32) | lo;
}
就能拿到当前时刻的 cpu cycles。所以统计耗时就很直接:
start = rdtsc();
// business logic here
end = rdtsc();
elapsed_seconds = (end-start) / cycles_per_sec;
以上的假设是 TSC 恒定,随着 wall time 均匀增加。
如果 CPU 频率恒定的话(也就是没有超频、节能之类的特殊配置),cycles 就是以恒定速率增加的, 这时 TSC 确实能跟时钟保持同步,所以可以作为一种获取时间或计时的方式。 但接下来会看到,cycles 恒定这个前提条件如今已经很难满足了,内核也不推荐用 tsc 作为时间度量。
乱序执行会导致 RDTSC 的执行顺序与期望的顺序发生偏差,导致计时不准,两种解决方式:
- 插入一个同步指令(a serializing instruction),例如
CPUID,强制前面的指令必现执行完,才能才执行 RDTSC;- 使用一个变种指令 RDTSCP,但这个指令只是对指令流做了部分顺序化(partial serialization of the instruction stream),并不完全可靠。
如果一台机器只有一个处理器,并且工作频率也一直是稳定的,那拿 TSC 作为计时方式倒也没什么问题。 但随着下面这些技术的引入,TSC 作为时钟就不准了:
还有其他一些方面的挑战,都会导致无法保证一台机器多个 CPU 的 TSC 严格同步。
解决方式之一,是一种称为恒定速率(constant rate) TSC 的技术,
cat /proc/cpuinfo | grep constant_tsc 来判断;较新的 Intel、AMD 处理器都支持这个特性。
但是,constant_tsc 只是表明 CPU 有提供恒定 TSC 的能力, 并不表示实际工作 TSC 就是恒定的。后面会详细介绍。
从上面的内容已经可以看出, TSC 如其名字“时间戳计数器”所说,确实本质上只是一个计数器, 记录的是 CPU 启动以来的 cpu cycles 次数。
虽然在很多情况下把它当时钟用,结果也是正确的,但这个是没有保证的,因为影响它稳定性的因素太多了 —— 不稳拿它计时也就不准了。
另外,它是一个 x86 架构的特殊寄存器,换了其他 cpu 架构可能就不支持,所以依赖 TSC 的代码可移植性会变差。
以上几节介绍的基本都是硬件问题,很好理解。接下来设计到软件部分就复杂了,一部分原因是命名导致的。
clocksource)配置我们前面提到不要把 tsc 作为时钟来看待,它只是一个计数器。但另一方面,内核确实需要一个时钟,
gettimeofday() / clock_gettime()。在底层,内核肯定是要基于启动以来的计数器,这时 tsc 就成为它的备选之一(而且优先级很高)。
$ cat /sys/devices/system/clocksource/clocksource0/available_clocksource
tsc hpet acpi_pm
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource
tsc
tsc:优先ns 级别;hpet:性能开销太大原理暂不展开,只说结论:相比 tsc,hpet 在很多场景会明显导致系统负载升高。所以能用 tsc 就不要用 hpet。
turbostat 查看实际 TSC 计数(可能不准)前面提到用户空间程序写几行代码就能方便地获取 TSC 计数。所以对监控采集来说,还是很方便的。 我们甚至不需要自己写代码获取 TSC,一些内核的内置工具已经实现了这个功能,简单地执行一条 shell 命令就行了。
turbostat 是 Linux 内核自带的一个工具,可以查看包括 TSC 在内的很多信息。
turbostat 源码在内核源码树中:tools/power/x86/turbostat/turbostat.c。
不加任何参数时,turbostat 会 5s 打印一次统计信息,内容非常丰富。
我们这里用精简模式,只打印每个 CPU 在过去 1s 的 TSC 频率和所有 CPU 的平均 TSC:
# sample 1s and only one time, print only per-CPU & average TSCs
$ turbostat --quiet --show CPU,TSC_MHz --interval 1 --num_iterations 1
CPU TSC_MHz
- 2441
0 2445
64 2445
1 2445
但 turbostat 如果执行的时间非常短,比如 1s,统计到数据就不太准,偏差比较大;
持续运行一段时间后,得到的数据才比较准。
rdtsc/rdtscp 指令采集 TSC 计数完整代码:
#include <stdio.h>
#include <time.h>
#include <unistd.h>
// https://stackoverflow.com/questions/16862620/numa-get-current-node-core
unsigned long rdtscp(int *chip, int *core) {
unsigned a, d, c;
__asm__ volatile("rdtscp" : "=a" (a), "=d" (d), "=c" (c));
*chip = (c & 0xFFF000)>>12;
*core = c & 0xFFF;
return ((unsigned long)a) | (((unsigned long)d) << 32);;
}
int main() {
int sleep_us = 100000;
unsigned long tsc_nominal_hz = 2795000000;
unsigned long expected_inc = (unsigned long)(1.0 * sleep_us / 1000000 * tsc_nominal_hz);
unsigned long low = (unsigned long)(expected_inc * 0.95);
unsigned long high = (unsigned long)(expected_inc * 1.05);
printf("Sleep interval: %d us, expected tsc increase range [%lu,%lu]\n", sleep_us, low, high);
unsigned long start, delta;
int start_chip=0, start_core=0, end_chip=0, end_core=0;
while (1) {
start = rdtscp(&start_chip, &start_core);
usleep(sleep_us);
delta = rdtscp(&end_chip, &end_core) - start;
if (delta > high || delta < low) {
time_t seconds = time(NULL); // seconds since Unix epoch (1970.1.1)
struct tm t = *localtime(&seconds);
printf("%02d-%02d %02d:%02d:%02d TSC jitter: %lu\n",
t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec, delta);
fflush(stdout);
}
}
return 0;
}
几点说明:
2795MHz;+/- 5%,就将这个异常值打印出来;rdtscp 指令的开销很小。编译运行,
$ gcc tsc-checker.c -o tsc-checker
# print to stdout and copy to a log file, using stream buffer instead of line buffers
$ stdbuf --output=L ./tsc-checker | tee tsc.log
Sleep interval: 100000 us, expected tsc increase range [265525000,293475000]
08-05 19:46:31 303640792
08-05 20:13:06 301869652
08-05 20:38:27 300751948
08-05 22:40:39 324424884
...
可以看到这台机器(真实服务器)有偶发 TSC 抖动,
能偏离正常范围 324424884/2795000000 - 1 = 16%,
也就是说 100ms 的时间它能偏离 16ms,非常离谱。TSC 短时间连续抖动时,
机器就会出现各种奇怪现象,比如 load 升高、网络超时、活跃线程数增加等等,因为内核系统因为时钟抖动乱了。
用合适的采集工具把以上数据送到监控平台(例如 Prometheus/VictoriaMetrics),就能很直观地看到 TSC 的状态。
turbostat(不推荐)例如下面是 1 分钟采集一次,每次采集过去 1s 内的平均 TSC,得到的结果:

Fig. TSC runnning average of an AMD EPYC 7543 node
但前面提到,
turbostat 如果执行的时间非常短,统计到数据就不太准,偏差比较大;
持续运行一段时间后,得到的数据才比较准。但作为采集程序,可能不方便执行太长时间。
rdtscp基于上面的 rdtscp 自己写代码采集,就非常准确了,例如,下面是 1 分钟采集一次得到的结果展示:

Fig. TSC jitter of an AMD EPYC 7543 node
不过,要抓一些偶发抖动导致的问题,1 分钟采集一次粒度太粗了。比如我们上一小节的 C 程序是 100ms 采集一次, 相当于 1 分钟采集 600 次,一小时采集 3.6w 次。我们 3 个小时总共 10 万多次跑下来,也才能抓到几次抖动,这已经算很幸运了。
rdtscp + 内核模块还是 rdtscp,但作为内核模块 + 定时器运行,应该会比用户空间程序更准,可以避免 Linux 内核调度器的调度偏差。
constant_tsc: a feature, not a runtime guaranteeCPU 信息:
$ cat /proc/cpuinfo
...
processor : 127
vendor_id : AuthenticAMD
model name : AMD EPYC 7543 32-Core Processor
cpu MHz : 3717.449
flags : fpu ... tsc msr rdtscp constant_tsc nonstop_tsc cpuid tsc_scale ...
flags 里面显式支持 constant_tsc 和 nonstop_tsc,所以按照文档的描述 TSC 应该是恒定的。
但是,看一下下面的监控,都是这款 CPU,机器来自两个不同的服务器厂商,

Fig. TSC fluctuations (delta of running average) of AMD EPYC 7543 nodes, from two server vendors
可以看到,
这个波动可能有几方面原因,比如各厂商的 BIOS 逻辑,或者 SMI 中断风暴。
最后定位到是厂商 BIOS (UEFI) 设置导致的,做如下修改之后稳定多了,
| No. | Option | Before | After |
|---|---|---|---|
| 1 | OperatingModes.ChooseOperatingMode | Maximum Efficiency | Custom Mode |
| 2 | Processors.DeterminismSlider | Performance | Power |
| 3 | Processors.CorePerformanceBoost | Enable | Enable |
| 4 | Processors.cTDP | Auto | Maximum |
| 5 | Processors.PackagePowerLimit | Auto | Maximum |
| 6 | Processors.GlobalC-stateControl | Enable | Enable |
| 7 | Processors.SOCP-states | Auto | P0 |
| 8 | Processors.DFC-States | Enable | Disable |
| 9 | Processors.P-state1 | Enable | Disable |
| 10 | Processors.SMTMode | Enable | Enable |
| 11 | Processors.CPPC | Enable | Enable |
| 12 | Processors.BoostFmax | Auto | Manual |
| 13 | Processors.BoostFmaxManual | 0 |
|
| 14 | Power EfficiencyMode | Enable | Disable |
| 15 | Memory.NUMANodesperSocket | NPS1 | NPS0 |
Note:
Processors.BoostFmaxManual option only exists when BoostFmax=Manual;除了以上具体配置,还有一些可能会导致 TSC 不稳的场景。
TSC 可写,所以某些 BIOS 固件代码会修改 TSC 值,导致操作系统时序不同步(或者说不符合预期)。
例如,2010 年内核社区的一个讨论 x86: Export tsc related information in sysfs 就提到,某些 BIOS SMI handler 会通过修改 TSC value 的方式来隐藏它们的执行。
为什么要隐藏?
前面提到,恒定 TSC 特性只是说处理器提供了恒定的能力,但用不用这个能力,服务器厂商有非常大的决定权。
某些厂商的固件代码会在 TSC sync 逻辑中中修改 TSC 的值。 这种修改在固件这边没什么问题,但会破坏内核层面的时序视角,例如内核调度器工作会出问题。 因此,内核最后引入了一个 patch 来处理 ACPI suspend/resume,以保证 TSC sync 机制在操作系统层面还是正常的,
x86, tsc, sched: Recompute cyc2ns_offset's during resume from sleep states
TSC's get reset after suspend/resume (even on cpu's with invariant TSC
which runs at a constant rate across ACPI P-, C- and T-states). And in
some systems BIOS seem to reinit TSC to arbitrary large value (still
sync'd across cpu's) during resume.
This leads to a scenario of scheduler rq->clock (sched_clock_cpu()) less
than rq->age_stamp (introduced in 2.6.32). This leads to a big value
returned by scale_rt_power() and the resulting big group power set by the
update_group_power() is causing improper load balancing between busy and
idle cpu's after suspend/resume.
This resulted in multi-threaded workloads (like kernel-compilation) go
slower after suspend/resume cycle on core i5 laptops.
Fix this by recomputing cyc2ns_offset's during resume, so that
sched_clock() continues from the point where it was left off during
suspend.
上一节提到,BIOS SMI handler 通过修改 TSC 隐藏它们的执行。如果有大量这种中断(可能是有 bug), 就会导致大量时间花在中断处理时,但又不会计入 TSC,最终导致系统出现卡顿等问题。
AMD 的机器比较尴尬,看不到 SMI 统计(试了几台 Intel 机器是能看到的),
$ turbostat --quiet --show CPU,TSC_MHz,SMI --interval 1 --num_iterations 1
CPU TSC_MHz
- 2441
0 2445
64 2445
1 2445
...
例如
本文整理了一些 TSC 相关的软硬件知识,在一些故障排查场景可能会用到。
![]()
![]()
apache 服务器将访问请求记录在 /var/log/apache2 中,因此我们可以分析这个日志文件来找出最后的几个请求。
下面解析 apache2 服务器日志,并逐行打印请求。它基于 BASH 命令:tail 和 awk。
#!/bin/bash
NUMBER_OF_REQUESTS=50
LOG_FILES_PREFIX=/var/log/apache2/access
tail -n $NUMBER_OF_REQUESTS $LOG_FILES_PREFIX* | awk -F'"' '
# 确保 IP 地址、请求和用户代理字段存在
$1 ~ /^[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+/ && $2 ~ /^(GET|POST|HEAD|PUT|DELETE|OPTIONS|PATCH)/ && $6 != "" {
split($1, part1, " ")
ip = part1[1]
split($2, request, " ")
method = request[1]
path = request[2]
user_agent = $6
print ip, path, user_agent
}
'
示例输出(每行包含 IP 地址、URI/URL 和用户代理字符串):

通过 IP、URL 和用户代理向 Apache2 发送的最后几个请求
有了它,我们可以集成到 BASH 脚本中,当 CPU 平均负载较高时发送电子邮件通知,以帮助我们了解导致峰值的原因。
英文:How to Get the Last Requests to Apache2 Server?
本文一共 198 个汉字, 你数一下对不对.
Vaulwarden 是一个开源自托管的密码管理工具,这个项目使用 Rust 实现了一套 Bitwarden Server API, 很多小伙伴都用它来管理密钥与凭证。 本文将利用 fail2ban 来实现在 CDN 场景下的防暴力破解。
yum或dnf)在在线机器上下载这些包。 sudo yum deplist smartmontools
yumdownloader工具: sudo yum install yum-utils
yumdownloader smartmontools --destdir=/path/to/downloaded-packages
yumdownloader <dependency-name> --destdir=/path/to/downloaded-packages
cd /path/to/downloaded-packages
rpm命令安装所有包:
sudo rpm -ivh *.rpm
sudo rpm -ivh --force --nodeps *.rpm
mkdir -p /path/to/local-repo
cp /path/to/downloaded-packages/*.rpm /path/to/local-repo/
cd /path/to/local-repo/
createrepo .
sudo vim /etc/yum.repos.d/local.repo
local.repo文件中: [localrepo]
name=Local Repository
baseurl=file:///path/to/local-repo/
enabled=1
gpgcheck=0
yum来安装: sudo yum clean all
sudo yum install smartmontools

声明:
资源均源自网络,因使用本页面提供的资源链接产生的版权问题或计算机数据安全问题造成的任何损失,本站概不负责。您应该确保在您使用网络资源时已拥有适当抵御病毒的措施和其他安全措施。
本页面含有通向其他网站和资源的链接,这些链接仅供您参考。本站无法控制这些网站或资源的内容,对这些内容或因使用这些内容导致的任何损失或损害,本站亦概不负责。
请根据文件名自行推断其版本号以及使用方式。
链接顺序与版本号无关。
来源:Github Relese,已和谐,无从考证
来源:已和谐,无从考证
来源:https://yuzu.cn.uptodown.com/windows/download/126081659
来源:已和谐,无从考证
来源:已和谐,无从考证
来源:https://archlinux.pkgs.org/rolling/extra-alucryd-x86_64/yuzu-1708-1-x86_64.pkg.tar.zst.html
固件资源可以去来源页面下载,会有更新的版本
来源:https://prodkeys.net/yuzu-firmware/
ProdKeys资源可以去来源页面下载,会有更新的版本
来源:https://prodkeys.net/prod-keys/
不包教包会,yuzu的简易安装说明可以参考我去年的文章:《用我的老电脑玩任天堂Switch模拟器》,只不过 GitHub 的资源已经完全被 DMCA Takedown 了,连 Wayback Machine 的内容都不剩。
百度吃屎去吧。
The post [网盘] 任天堂Switch模拟器 yuzu 下载存档(Windows, Linux)[InfiniCLOUD][腾讯微云] first appeared on 石樱灯笼博客.这几天,我发现我的一两个服务器过载(高于平常的CPU使用率),我查看了 Apache 日志,发现 ChatGPT Bot(也称为 GPTBot/1.0)和字节跳动 Bots(也称为 Bytespider)的访问记录。
您可以通过以下 BASH 命令检查访问您服务器的前 10 个 IP:
#!/bin/bash
awk '{a[$1]++}END{for(v in a)print v, a[v]}' /var/log/apache2/*.log* | sort -k2 -nr | head -10
 LINUX 折腾 资讯 运维")
字节跳动 Bots(Bytespider)访问日志(Apache2)
 LINUX 折腾 资讯 运维")
ChatGPT Bots(GPTBot)访问日志(Apache2)
ChatGPT还有字节跳动都有自己的大模型,他们就是通过抓取你的数据来喂他们的LLMs(大型语言模型)。这些 bots 免费使用您的材料(信息或数据)。它们给您的服务器增加了额外的负担,这是可以避免的。
我不喜欢它们从我的网站获取信息,白撸我的羊毛,但如果您觉得无所谓,可以将它们列入白名单。
一种比较软性的阻止方式是在网站根目录的 robots.txt 文件中添加以下内容:
User-agent: GPTBot Disallow: / User-agent: Bytespider Disallow: /
然而,这些爬虫可能选择不遵守这些规则。比如百度爬虫就不遵守。
另一种更强硬的方法是通过添加一些防火墙规则来阻止它们,例如,您可以添加一个 CloudFlare WAF 规则来阻止它们:
 LINUX 折腾 资讯 运维")
添加 Cloudflare WAF 安全规则以阻止 GPTBot 和 Bytespider Bot 的访问。
比如还可以在表达式编译器(Expression Editor)里加入其它限制:
(http.user_agent contains "GPTBot") or (http.user_agent contains "Bytespider") or // 可以根据需求加入其它限制,比如限制 Amazonbot (http.user_agent contains "Amazonbot") or // 访问 WordPress 博客访问评论链接 (http.request.uri contains "?replytocom=")
您可以通过在服务器配置中设置适当的 HTTP 头来阻止特定的用户代理。以下是如何在 htaccess)加速网站”>Apache 和 Nginx 服务器上实现这一点:
对于 Apache,在您的 .htaccess 文件中添加以下内容:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} GPTBot [NC,OR]
RewriteCond %{HTTP_USER_AGENT} Bytespider [NC]
RewriteRule .* - [F,L]
</IfModule>
对于 Nginx 服务器,在您的 Nginx 配置文件中添加以下内容:
if ($http_user_agent ~* (GPTBot|Bytespider)) {
return 403;
}
如果您对应用程序的服务器端代码有控制权,您可以编写中间件来阻止这些用户代理。
在 Express(Node.js)中的示例:
app.use((req, res, next) => {
const userAgent = req.headers['user-agent'];
if (/GPTBot|Bytespider/i.test(userAgent)) {
res.status(403).send('Forbidden');
} else {
next();
}
});
在 Django(Python)中的示例:
from django.http import HttpResponseForbidden
class BlockBotsMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
user_agent = request.META.get('HTTP_USER_AGENT', '')
if 'GPTBot' in user_agent or 'Bytespider' in user_agent:
return HttpResponseForbidden('Forbidden')
return self.get_response(request)
使用这些方法的组合可以有效地阻止 GPT-4 和 ByteSpider bots 访问您的网站。在服务器级别的阻止(通过 HTTP 头、防火墙规则或 WAF)与 robots.txt 指令结合使用可以提供更强大的解决方案。
英文:Why and How You Should Stop the ChatGPT and Bytedance Bots Crawling Your Pages?
本文一共 702 个汉字, 你数一下对不对.
整理一些 Linux 服务器性能相关的 CPU 硬件基础及内核子系统知识。
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
idle=poll 的潜在风险 5.15 内核文档 “CPU Idle Time Management”5.15 内核文档 “NO_HZ: Reducing Scheduling-Clock Ticks”5.15 内核文档 “AMD64 Specific Boot Options”idle=poll 的潜在风险前面已经介绍过,idle=poll 就是强制处理器工作在 C0,保持最高性能。
但内核文档中好几个地方提示这样设置是有风险的,这里整理一下。
5.15 内核文档 “CPU Idle Time Management”using ``idle=poll`` is somewhat drastic in many cases, as preventing idle
CPUs from saving almost any energy at all may not be the only effect of it.
For example, on Intel hardware it effectively prevents CPUs from using
P-states (see |cpufreq|) that require any number of CPUs in a package to be
idle, so it very well may hurt single-thread computations performance as well as
energy-efficiency. Thus using it for performance reasons may not be a good idea
at all.]
这段写的比较晦涩,基于本系列前几篇的基础,尝试给大家翻译一下:
idle=poll 除了功耗高,还有其他后果;例如,
另外,这个文档是 Intel 的人写的,但看过超频原理就应该明白,这个问题不仅限于 Intel CPU。
5.15 内核文档 “NO_HZ: Reducing Scheduling-Clock Ticks”NO_HZ: Reducing Scheduling-Clock Ticks:
Known Issues
d. On x86 systems, use the "idle=poll" boot parameter.
However, please note that use of this parameter can cause
your CPU to overheat, which may cause thermal throttling
to degrade your latencies -- and that this degradation can
be even worse than that of dyntick-idle. Furthermore,
this parameter effectively disables Turbo Mode on Intel
CPUs, which can significantly reduce maximum performance.
这是归类到了已知问题,写的比前一篇清楚多了:
idle=poll effectively 禁用了 Intel Turbo Mode,
也就是无法超频到 base frequency 以上,因此峰值性能显著变差。5.15 内核文档 “AMD64 Specific Boot Options”这个是启动项说明,里面以 Intel CPU 为例但问题不仅限于 Intel, AMD 的很多在用参数和功能这个文档里都没有,
Idle loop
=========
idle=poll
Don't do power saving in the idle loop using HLT, but poll for rescheduling
event. This will make the CPUs eat a lot more power, but may be useful
to get slightly better performance in multiprocessor benchmarks. It also
makes some profiling using performance counters more accurate.
Please note that on systems with MONITOR/MWAIT support (like Intel EM64T
CPUs) this option has no performance advantage over the normal idle loop.
It may also interact badly with hyperthreading.
idle=poll 在某些场景下能提升 multiple benchmark 的性能,也能让某些 profiling 更准确一些;MONITOR/MWAIT 的平台上,这个配置并不会带来性能提升;Dell Whitepaper: Controlling Processor C-State Usage in Linux, 服务器厂商 Dell 的技术白皮书,其中一段,
If a user wants the absolute minimum latency, kernel parameter “idle=poll” can be used to keep the
processors in C0 even when they are idle (the processors will run in a loop when idle, constantly
checking to see if they are needed). If this kernel parameter is used, it should not be necessary to
disable C-states in BIOS (or use the “idle=halt” kernel parameter).
Take care when keeping processors in C0, though--this will increase power usage considerably.
Also, hyperthreading should probably be
disabled, as keeping processors in C0 can interfere with proper operation of logical cores
(hyperthreading). (The hyperthreading hardware works best when it knows when the logical processors
are idle, and it doesn’t know that if processors are kept busy in a loop when they are not running
useful code.)
超线程硬件的工作原理:
用户报告 idle=poll + hyperthreading 导致并发性能显著变差,
Linus 回复说,
I really don’t think you should really ever use “idle=poll” on HT-enabled hardware,
HT 是超线程的缩写。
看起来 idle=poll 与 turbo-frequency/hyperthreading 存在工作机制的冲突。
需要一些场景和 testcase 来验证。有经验的专家大佬,欢迎交流。
一台惠普机器:
$ dmesg -T
kernel: ACPI Error: SMBus/IPMI/GenericSerialBus write requires Buffer of length 66, found length 32 (20180810/exfield-393)
kernel: ACPI Error: Method parse/execution failed \_SB.PMI0._PMM, AE_AML_BUFFER_LIMIT (20180810/psparse-516)
kernel: ACPI Error: AE_AML_BUFFER_LIMIT, Evaluating _PMM (20180810/power_meter-338)
...
这是 HP 的 BIOS 实现没有遵守协议,实际上这个报错不会产生硬件性能影响之类的(但是打印的日志量可能很大,每分钟十几条,不间断)。
一台联想机器:
$ dmesg -T
kernel: power_meter ACPI000D:00: Found ACPI power meter.
kernel: power_meter ACPI000D:00: Found ACPI power meter.
...
如果是 k8s node 遇到以上问题,可能是部署了 prometheus/node_exporter 导致的 [2], 试试关闭其 hwmon collector。
![]()
![]()
整理一些 Linux 服务器性能相关的 CPU 硬件基础及内核子系统知识。
水平有限,文中不免有错误或过时之处,请酌情参考。
sysfs 相关目录/sys/devices/system/cpu/cpu{N}/ 目录系统中的每个 CPU,都对应一个 /sys/devices/system/cpu/cpu<N>/cpuidle/ 目录,
其中 N 是 CPU ID,
$ tree /sys/devices/system/cpu/cpu0/
/sys/devices/system/cpu/cpu0/
├── cache
│ ├── index0
│ ├── ...
│ ├── index3
│ └── uevent
├── cpufreq -> ../cpufreq/policy0
├── cpuidle
│ ├── state0
│ │ ├── above
│ │ ├── below
│ │ ├── default_status
│ │ ├── desc
│ │ ├── disable
│ │ ├── latency
│ │ ├── name
│ │ ├── power
│ │ ├── rejected
│ │ ├── residency
│ │ ├── time
│ │ └── usage
│ └── state1
│ ├── above
│ ├── below
│ ├── default_status
│ ├── desc
│ ├── disable
│ ├── latency
│ ├── name
│ ├── power
│ ├── rejected
│ ├── residency
│ ├── time
│ └── usage
├── crash_notes
├── crash_notes_size
├── driver -> ../../../../bus/cpu/drivers/processor
├── firmware_node -> ../../../LNXSYSTM:00/LNXCPU:00
├── hotplug
│ ├── fail
│ ├── state
│ └── target
├── node0 -> ../../node/node0
├── power
│ ├── async
│ ├── autosuspend_delay_ms
│ ├── control
│ ├── pm_qos_resume_latency_us
│ ├── runtime_active_kids
│ ├── runtime_active_time
│ ├── runtime_enabled
│ ├── runtime_status
│ ├── runtime_suspended_time
│ └── runtime_usage
├── subsystem -> ../../../../bus/cpu
├── topology
│ ├── cluster_cpus
│ ├── cluster_cpus_list
│ ├── cluster_id
│ ├── core_cpus
│ ├── core_cpus_list
│ ├── core_id
│ ├── core_siblings
│ ├── core_siblings_list
│ ├── die_cpus
│ ├── die_cpus_list
│ ├── die_id
│ ├── package_cpus
│ ├── package_cpus_list
│ ├── physical_package_id
│ ├── thread_siblings
│ └── thread_siblings_list
└── uevent
里面包括了很多硬件相关的子系统信息,跟我们本次主题相关的几个:
下面分别看下这几个子目录。
/sys/devices/system/cpu/cpu<N>/cpufreq/ (p-state)处理器执行任务时的运行频率、超频等等相关的参数,管理的是 p-state:
$ tree /sys/devices/system/cpu/cpu0/cpufreq/
/sys/devices/system/cpu/cpu0/cpufreq/
├── affected_cpus
├── cpuinfo_max_freq
├── cpuinfo_min_freq
├── cpuinfo_transition_latency
├── related_cpus
├── scaling_available_governors
├── scaling_cur_freq
├── scaling_driver
├── scaling_governor
├── scaling_max_freq
├── scaling_min_freq
└── scaling_setspeed
/sys/devices/system/cpu/cpu<N>/cpuidle/ (c-states)每个 struct cpuidle_state 对象都有一个对应的 struct cpuidle_state_usage
对象(上一篇中有更新这个 usage 的相关代码),其中包含了这个 idle state 的统计信息,
也是就是我们下面看到的这些:
$ tree /sys/devices/system/cpu/cpu0/cpuidle/
/sys/devices/system/cpu/cpu0/cpuidle/
├── state0
│ ├── above
│ ├── below
│ ├── default_status
│ ├── desc
│ ├── disable
│ ├── latency
│ ├── name
│ ├── power
│ ├── rejected
│ ├── residency
│ ├── time
│ └── usage
├── state1
│ ├── above
│ ├── below
│ ├── default_status
│ ├── desc
│ ├── disable
│ ├── latency
│ ├── name
│ ├── power
│ ├── rejected
│ ├── residency
│ ├── s2idle
│ │ ├── time
│ │ └── usage
│ ├── time
│ └── usage
│...
state0、state1 等目录对应 idle state 对象,也跟这个 CPU 的 c-state 对应,数字越大,c-state 越深。
文件说明,
desc/name:都是这个 idle state 的描述。name 比较简洁,desc 更长。除了这俩,其他字段都是整型。above:idle duration < target_residency 的次数。也就是请求到了这个状态,但是 idle duration 太短,最终放弃进入这个状态。below:idle duration 虽然大于 target_residency,但是大的比较多,最终找到了一个更深的 idle state 的次数。disable:唯一的可写字段:1 表示禁用,governor 就不会在这个 CPU 上选这状态了。注意这个是 per-cpu 配置,此外还有一个全局配置。default_status:default status of this state, “enabled” or “disabled”.latency:这个 idle state 的 exit latency,单位 us。power:这个字段通常是 0,表示不支持。因为功耗的统计很复杂,这个字段的定义也不是很明确。建议不要参考这个值。residency:这个 idle state 的 target residency,单位 us。time:内核统计的该 CPU 花在这个状态的总时间,单位 ms。这个是内核统计的,可能不够准,因此如有处理器硬件统计的类似指标,建议参考后者。usage:成功进入这个 idle state 的次数。rejected:被拒绝的要求进入这个 idle state 的 request 的数量。/sys/devices/system/cpu/cpu<N>/power/$ tree /sys/devices/system/cpu/cpu0/
/sys/devices/system/cpu/cpu0/
├── power
│ ├── async
│ ├── autosuspend_delay_ms
│ ├── control
│ ├── pm_qos_resume_latency_us
│ ├── runtime_active_kids
│ ├── runtime_active_time
│ ├── runtime_enabled
│ ├── runtime_status
│ ├── runtime_suspended_time
│ └── runtime_usage
/sys/devices/system/cpu/cpu<N>/topology/$ tree /sys/devices/system/cpu/cpu0/
/sys/devices/system/cpu/cpu0/
├── topology
│ ├── cluster_cpus
│ ├── cluster_cpus_list
│ ├── cluster_id
│ ├── core_cpus
│ ├── core_cpus_list
│ ├── core_id
│ ├── core_siblings
│ ├── core_siblings_list
│ ├── die_cpus
│ ├── die_cpus_list
│ ├── die_id
│ ├── package_cpus
│ ├── package_cpus_list
│ ├── physical_package_id
│ ├── thread_siblings
│ └── thread_siblings_list
└── uevent
/sys/devices/system/cpu/cpuidle/:governor/driver这个目录是全局的,可以获取可用的 governor/driver 信息,也可以在运行时更改 governor。
$ ls /sys/devices/system/cpu/cpuidle/
available_governors current_driver current_governor current_governor_ro
$ cat /sys/devices/system/cpu/cpuidle/available_governors
menu
$ cat /sys/devices/system/cpu/cpuidle/current_driver
acpi_idle
$ cat /sys/devices/system/cpu/cpuidle/current_governor
menu
除了 sysfs,还可以通过内核命令行参数做一些配置,可以加在 /etc/grub2.cfg 等位置。
5.15 内核启动参数文档:
// https://github.com/torvalds/linux/blob/v5.15/Documentation/admin-guide/kernel-parameters.txt
idle= [X86]
Format: idle=poll, idle=halt, idle=nomwait
1. idle=poll forces a polling idle loop that can slightly improve the performance of waking up a
idle CPU, but will use a lot of power and make the system run hot. Not recommended.
2. idle=halt: Halt is forced to be used for CPU idle. In such case C2/C3 won't be used again.
3. idle=nomwait: Disable mwait for CPU C-states
idle=pollCPU 空闲时,将执行一个“轻量级”的指令序列(”lightweight” sequence of instructions in a tight loop) 来防止 CPU 进入任何节能模式。
这种配置除了功耗问题,还超线程场景下可能有副作用,性能反而降低,后面单独讨论。
idle=halt强制 cpuidle 子系统使用 HLT 指令
(一般会 suspend 程序的执行并使硬件进入最浅的 idle state)来实现节能。
这种配置下,最大 c-state 深度是 C1。
idle=nomwait禁用通过 MWAIT 指令来要求硬件进入 idle state。
内核文档 CPU Idle Time Management
说,在 Intel 机器上,这会禁用 intel_idle,用 acpi_idle(idle states / p-states 从 ACPI 获取)。
intel_pstate// https://github.com/torvalds/linux/blob/v5.15/Documentation/admin-guide/kernel-parameters.txt#L1988
intel_pstate= [X86]
disable
Do not enable intel_pstate as the default
scaling driver for the supported processors
passive
Use intel_pstate as a scaling driver, but configure it
to work with generic cpufreq governors (instead of
enabling its internal governor). This mode cannot be
used along with the hardware-managed P-states (HWP)
feature.
force
Enable intel_pstate on systems that prohibit it by default
in favor of acpi-cpufreq. Forcing the intel_pstate driver
instead of acpi-cpufreq may disable platform features, such
as thermal controls and power capping, that rely on ACPI
P-States information being indicated to OSPM and therefore
should be used with caution. This option does not work with
processors that aren't supported by the intel_pstate driver
or on platforms that use pcc-cpufreq instead of acpi-cpufreq.
no_hwp
Do not enable hardware P state control (HWP)
if available.
hwp_only
Only load intel_pstate on systems which support
hardware P state control (HWP) if available.
support_acpi_ppc
Enforce ACPI _PPC performance limits. If the Fixed ACPI
Description Table, specifies preferred power management
profile as "Enterprise Server" or "Performance Server",
then this feature is turned on by default.
per_cpu_perf_limits
Allow per-logical-CPU P-State performance control limits using
cpufreq sysfs interface
AMD_pstatAMD_idle.max_cstate=1 AMD_pstat=disable 等等,上面的内核文档还没收录,或者在别的地方。
*.max_cstateintel_idle.max_cstate=<n>AMD_idle.max_cstate=<n>processor.max_cstate=<n>这里面的 n 就是我们在 sysfs 目录中看到
/sys/devices/system/cpu/cpu0/cpuidle/state{n}。
// https://github.com/torvalds/linux/blob/v5.15/Documentation/admin-guide/kernel-parameters.txt
intel_idle.max_cstate= [KNL,HW,ACPI,X86]
0 disables intel_idle and fall back on acpi_idle.
1 to 9 specify maximum depth of C-state.
processor.max_cstate= [HW,ACPI]
Limit processor to maximum C-state
max_cstate=9 overrides any DMI blacklist limit.
AMD 的没收录到这个文档中。
cpuidle.offcpuidle.off=1 完全禁用 CPU 空闲时间管理。
加上这个配置后,
CPU architecture support code 使硬件进入 idle state。不建议在生产使用。
cpuidle.governor指定要使用的 CPUIdle 管理器。例如 cpuidle.governor=menu 强制使用 menu 管理器。
nohz可设置 on/off,是否启用每秒 HZ 次的定时器中断。
可以从 /proc/cpuinfo 获取,
$ cat /proc/cpuinfo | awk '/cpu MHz/ { printf("cpu=%d freq=%s\n", i++, $NF)}'
cpu=0 freq=3393.622
cpu=1 freq=3393.622
cpu=2 freq=3393.622
cpu=3 freq=3393.622
某些开源组件可能已经采集了,如果没有的话自己采一下,然后送到 prometheus。
这里拿一台 base freq 2.8GHz、max freq 3.7GHz,配置了 idle=poll 测试机,
下面是各 CPU 的频率,
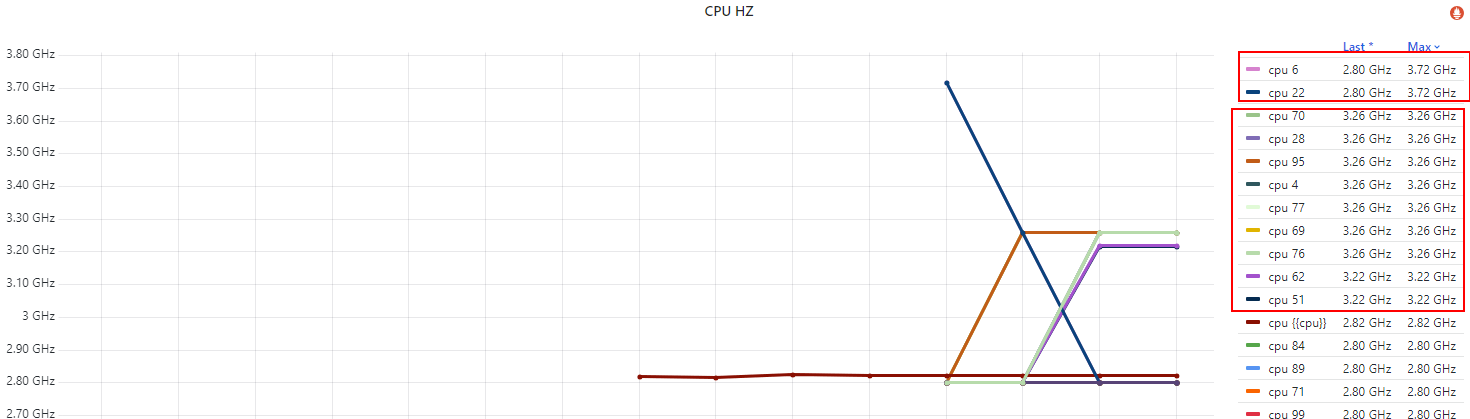
Fig. Per-CPU running frequency
几点说明,
idle=poll 禁用了节能模式(c1/c2/c3..),没有负载也会空转(执行轻量级指令),避免频率掉下去;max/turbo freq,原因我们在第二篇解释过了;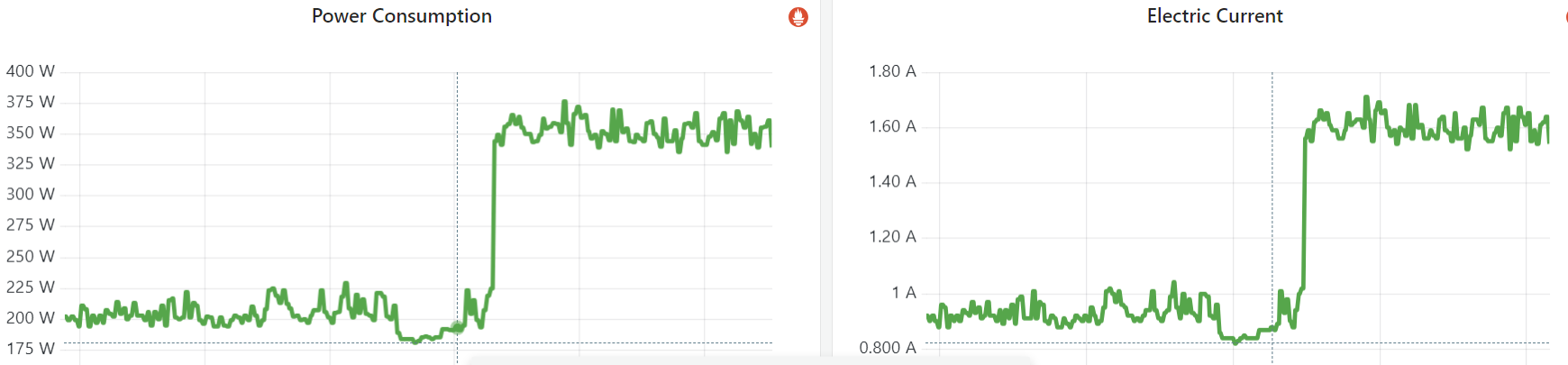
Fig. Power consumption and electic current of an empty node (no workload before and after)
after setting idle=poll for test
服务器厂商一般能提供。
按需。
除了通过 sysfs 和内核启动项,还可以通过一些更上层的工具配置功耗和性能模式。
tuned/tuned-admgithub.com/redhat-performance/tuned, 版本陆续有升级,但是好像没有 release notes,想了解版本差异只能看 diff commits:
$ tuned-adm list
Available profiles:
- balanced - General non-specialized tuned profile
- desktop - Optimize for the desktop use-case
- latency-performance - Optimize for deterministic performance at the cost of increased power consumption
- network-latency - Optimize for deterministic performance at the cost of increased power consumption, focused on low latency network performance
- network-throughput - Optimize for streaming network throughput, generally only necessary on older CPUs or 40G+ networks
- powersave - Optimize for low power consumption
- throughput-performance - Broadly applicable tuning that provides excellent performance across a variety of common server workloads
- virtual-guest - Optimize for running inside a virtual guest
- virtual-host - Optimize for running KVM guests
Current active profile: latency-performance
$ tuned-adm active
Current active profile: latency-performance
$ tuned-adm profile_info latency-performance
Profile name:
latency-performance
Profile summary:
Optimize for deterministic performance at the cost of increased power consumption
$ tuned-adm profile_mode
Profile selection mode: manual
turbostat:查看 turbo freq来自 man page:
turbostat - Report processor frequency and idle statistics
turbostat reports processor topology, frequency, idle power-state statistics, temperature and power on X86 processors.
例子:
$ turbostat --quiet --hide sysfs,IRQ,SMI,CoreTmp,PkgTmp,GFX%rc6,GFXMHz,PkgWatt,CorWatt,GFXWatt
Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz CPU%c1 CPU%c3 CPU%c6 CPU%c7
- - 488 12.52 3900 3498 12.50 0.00 0.00 74.98
0 0 5 0.13 3900 3498 99.87 0.00 0.00 0.00
0 4 3897 99.99 3900 3498 0.01
1 1 0 0.00 3856 3498 0.01 0.00 0.00 99.98
1 5 0 0.00 3861 3498 0.01
2 2 1 0.02 3889 3498 0.03 0.00 0.00 99.95
2 6 0 0.00 3863 3498 0.05
3 3 0 0.01 3869 3498 0.02 0.00 0.00 99.97
3 7 0 0.00 3878 3498 0.03
Busy%:C0 状态所占的时间百分比。Note that cpu4 in this example is 99.99% busy, while the other CPUs are all under 1% busy. Notice that cpu4’s HT sibling is cpu0, which is under 1% busy, but can get into CPU%c1 only, because its cpu4’s activity on shared hardware keeps it from entering a deeper C-state.
c-state 太深导致网络收发包不及时tuned 配置都一样,但不同厂商机器的 cstate/freq 不一样发现在某环境中,同样的 CPU、同样的 tuned profile (cstate) 配置,
不同服务器厂商的机器运行频率差异很大。
以 CPU Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz 服务器为例,


Fig. Per-CPU running frequency, same CPU model, but different server vendors
根据 spec,
base 2.3GHz(晶振频率)max all-core turbo 2.8GHz(所有 CORE 能同时工作在这个频率)max turbo 3.9GHz(只有两个 CORE 能同时工作在这个频率)接下来看看使用了这款 CPU 的 DELL、INSPUR、H3C 三家厂商的机器有什么配置差异。
tuned-adm:查看 active profileroot@dell-node: $ tuned-adm active
Current active profile: latency-performance
root@dell-node: $ tuned-adm profile_info
Profile name:
latency-performance
Profile summary:
Optimize for deterministic performance at the cost of increased power consumption
Profile description:
三家都是 latency-performance。
cpupower:查看各 CPU 实际运行 cstate/freq根据之前经验,latency-performance 允许的最大 cstate 应该是 C1。
通过 cpupower 看下,
root@dell-node: $ cpupower monitor
| Nehalem || Mperf || Idle_Stats
PKG|CORE| CPU| C3 | C6 | PC3 | PC6 || C0 | Cx | Freq || POLL | C1 | C1E | C6
0| 0| 0| 0.00| 0.00| 0.00| 0.00|| 86.19| 13.81| 2776|| 0.02| 13.90| 0.00| 0.00
0| 0| 32| 0.00| 0.00| 0.00| 0.00|| 84.13| 15.87| 2776|| 0.01| 15.78| 0.00| 0.00
0| 1| 4| 0.00| 0.00| 0.00| 0.00|| 11.83| 88.17| 2673|| 0.03| 88.74| 0.00| 0.00
...
看着是启用了 POLL~C6 四个 cstate,与预期不符;但这个也有可能是 cpupower 这个工具的显示问题。
cpupower idle-info:查看 cstate 配置通过 idle-info 分别看下三家机器的 cstate 具体配置:
root@dell-node: $ cpupower idle-info | root@inspur-node $ cpupower idle-info | root@h3c-node $ cpupower idle-info
CPUidle driver: intel_idle | CPUidle driver: acpi_idle | CPUidle driver: intel_idle
CPUidle governor: menu | CPUidle governor: menu | CPUidle governor: menu
| |
Number of idle states: 4 | Number of idle states: 2 | Number of idle states: 4
Available idle states: POLL C1 C1E C6 | Available idle states: POLL C1 | Available idle states: POLL C1 C1E C6
| |
POLL: | POLL: | POLL:
Flags/Desc: CPUIDLE CORE POLL IDLE | Flags/Desc: CPUIDLE CORE POLL IDLE | Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0 | Latency: 0 | Latency: 0
Usage: 59890751 | Usage: 0 | Usage: 11962614826464
Duration: 531133564 | Duration: 0 | Duration: 45675012585533
| |
C1: | C1: | C1:
Flags/Description: MWAIT 0x00 | Flags/Description: ACPI HLT | Flags/Description: MWAIT 0x00
Latency: 2 | Latency: 0 | Latency: 2
Usage: 4216191666 | Usage: 149457505065 | Usage: 3923
Duration: 828071917480 | Duration: 30517320966628 | Duration: 280423
| |
C1E: | | C1E:
Flags/Description: MWAIT 0x01 | | Flags/Description: MWAIT 0x01
Latency: 10 | | Latency: 10
Usage: 9180 | | Usage: 1922
Duration: 8002008 | | Duration: 593202
| |
C6 (DISABLED) : | | C6:
Flags/Description: MWAIT 0x20 | | Flags/Description: MWAIT 0x20
Latency: 92 | | Latency: 133
Usage: 0 | | Usage: 10774
Duration: 0 | | Duration: 123049218
可以看到,
DELL
INSPUR:只允许 POLL/C1;
H3C:允许 POLL/C1/C1E/C6;
5 和 66.5 倍。| Server vendor | cpuidle driver | tuned profile |
Enabled cstates |
|---|---|---|---|
| DELL (戴尔) | intel_idle | latency-performance | POLL/C1/C1E |
| INSPUR (浪潮) | acpi_idle | latency-performance | POLL/C1 |
| H3C (华三) | intel_idle | latency-performance | POLL/C1/C1E/C6 |
同样的 tuned profile,不同厂商的机器,对应的 cstate 不完全一样(应该是厂商在 BIOS 里面设置的 mapping);
另外,运行在每个 cstate 的总时间,可以在 cpupower idle-info 的输出里看到。
不同厂商设置的 max freq 可能不一样,比如 DELL 设置到了 3.9G(max turbo), 其他两家设置到了 2.8G(all-core turbo),上面监控可以看出来;下面这个图是最大频率和能运行在这个频率的 CORE 数量的对应关系:

cpupower idle-info,
确保启用的 cstates 列表与预期一致,
例如不要 enable 唤醒时间过大的 cstate;这个跟 BIOS 配置相关;![]()
![]()
{kind=link}