优雅的处理Git多帐号与代理问题
在工作中,常常会容易遇到一台电脑用多个 Git 账号的场景,比如账号 company 账号是工作用的,而账号 personal 是自己个人用的。 由于 Git 本身并没有多账号的机制,导致我们在默认设置下无法很好的区分哪个仓库使用哪个账号。 同时,在某些众所周知的场景下,我们无法直接访问到 Github 仓库,需要走一层 proxy 来加速我们的代码拉取与推送速度, 本文将使用 SSH config 相对优雅的解决这些问题。
在工作中,常常会容易遇到一台电脑用多个 Git 账号的场景,比如账号 company 账号是工作用的,而账号 personal 是自己个人用的。 由于 Git 本身并没有多账号的机制,导致我们在默认设置下无法很好的区分哪个仓库使用哪个账号。 同时,在某些众所周知的场景下,我们无法直接访问到 Github 仓库,需要走一层 proxy 来加速我们的代码拉取与推送速度, 本文将使用 SSH config 相对优雅的解决这些问题。
在选择比较目录目录的对话框上,点击左下方【Folder:filter/文件夹:过滤器】处的【Select…/选择】按钮,然后在【File Filters/文件过滤器】选项卡中选中【Ignore git】,确定,即可。
进入比较后,这一项也有办法解决。点击菜单【Tools/工具】->【Filters/过滤器】后,同样在【File Filters/文件过滤器】选项卡中选中【Ignore git】,确定,然后刷新重新比较,亦可。
1 | git branch -a | grep -e "fix/" | xargs git branch -D |
1 | git status -s -uall | grep .vue | awk '{print $2}' | xargs git add |
1 | git branch -rv --sort=-committerdate |
更多:How can I get a list of Git branches, ordered by most recent commit?
1 | git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit" |
1 | git cherry -v branch-A branch-B |
1 | git clone -b develop git@github.com:user/myproject.git |
1 | mv bar/{,.}* . |
1 | git log -p branch-name |
1 | git log -p -- filename |
1 | git -c user.name="NEW NAME" -c user.email="new_email@gmail.com" commit --amend --date="Tue Nov 20 03:00 2018 +0100" --author="NEW NAME <new_email@gmail.com>" |
1 | find . -maxdepth 1 -mindepth 1 -type d -exec sh -c '(echo {} && cd {} && git status -s && echo)' \\; |
1 | tar cvfz app.tar.gz --exclude ".git/*" --exclude ".git" app/ |
1 | git log @{u}.. |
1 | git rev-list --all | xargs git grep |
1 | git log --diff-filter=D -- path/to/file |
1 | git push origin :branch |
1 | git config --global alias.git '!git' |
1 | git rebase -p --onto SHA^ SHA |
1 | git filter-branch --tree-filter 'rm -rf my_folder/my_file' HEAD |
1 | permalink = "!f() { echo "https://$(git config --get remote.origin.url | grep --color=never -o -E 'github.com[:/][^\\.]+' | sed s/\\:/\\\\//)/commit/$(git rev-parse @{u})"; }; open $(f)" |
1 | git update-index --assume-unchanged <file> |
1 | git rm --cached <file> |
1 | git branch --no-color 2> /dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)/\1/' |
1 | git show HEAD~5:hello.txt |
在工作中,常常会容易遇到一台电脑用多个 Git 账号的场景,比如账号 company 账号是工作用的,而账号 personal 是自己个人用的。 由于 Git 本身并没有多账号的机制,导致我们在默认设置下无法很好的区分哪个仓库使用哪个账号。 同时,在某些众所周知的场景下,我们无法直接访问到 Github 仓库,需要走一层 proxy 来加速我们的代码拉取与推送速度, 本文将使用 SSH config 相对优雅的解决这些问题。
前一篇我们介绍了如何使用 Hexo 框架及 Next 主题搭建博客。这次来聊聊如何安全的更新博客与主题的版本。
早期写博客时笔者就有考虑过使用 git 来做版本控制,那时 github 私人仓库还没有免费开放,国内虽然有 coding 和码云这些平台有开放少量的私人仓库,但由于懒得折腾就选了最方便同步的 OneDrive(因为它只需将文件夹移入就可以实现跨设备共享)。
后来笔者因为工作的原因,需要在多设备中频繁切换,这种简单同步方式就会暴露出一些问题。比如说,在设备 A 想对博客做一些自定义的修改,其中可能会动到依赖,但此时设备 B 的文件正在同步,那这样可能会导致文件不一致的问题。可能会将旧的文件重新同步过来,这可能会导致程序报错,还不易于排查。
冲突文件合并失败会额外添加如 index-anran758's MacBook Pro.js 之类的同名文件,并且发生冲突时是隐式的,你甚至不知道发生了冲突,这种体验使用不太友好。
因此 OneDrive 的同步方式适用于改动不会太大的文件。
如果你对 git 版本控制比较熟悉的话,那可以通过 git 对 blog 进行版本控制。
使用源码托管平台的话就如上文所说主要有这么几种选择:
国内的 gitee(码云)、coding 是一个不错的选择,代码的上传于下载速度也比较可观。国外可以使用 github,github 的私人仓库是今年才开放无限制免费创建仓库数量的,缺点由于众所周知的问题,有时可能拉代码速度较慢。
笔者使用的是 github 作为源码托管,下文将要介绍的方法对于 git 仓库是通用,因此根据自身的喜好选择对应的平台。
托管 blog 源码的步骤如下:
找到对应的平台,创建私人仓库(注意是 Private,不要将自己的私人配置也开源咯)。
仓库创建完毕后,得到仓库的地址。打开命令行,进入 /blog 目录下并输入命令:
1 | # 初始化 git 项目 |
由于 /theme/next 本身也是一个仓库,git 无法提交嵌套仓库的文件夹,因此需要在 .gitignore 添加配置,忽略该文件夹
1 | # 其他忽略规则... |
提交代码
1 | # 提交代码 |
这样我们就完成了博客的源码托管。
Next theme 官网介绍的安装方式如下:
1 | # 进入 blog 目录 |
在 Next theme 7.0+ 版本中,主题嵌入了检查版本更新的代码,每当运行本地服务器时,都会进行检查版本号的更新。当有新的版本发布时会在命令行输出警告:
1 | WARN Your theme NexT is outdated. Current version: v7.4.2, latest version: v7.5.0 |
这时你想体验 Next 的新特性的话可能会有点麻烦,因为原先我们在旧版本上修改了配置,或添加了一些自定义的布局。这将会造成代码冲突。
因此我们需要独立开两条分支:
master 分支是官方发布的正式版本,我们不去修改 master 分支的中的任何文件。customize, 言下之意为该分支含有我们自定义的修改,包括私人配置等。除此之外,由于主题配置文件(theme/next/_config.yml)中含有某些应用的 appid 或者 secret,这些配置不应该被其他人随意看到以防冒名滥用。因此我们应该将该项目额外添加一个 remote 来保存我们的私人配置。 具体操作如下:
1 | # 此时已经下载到了主题文件夹 |
如此就完成了代码的追踪,以后使用 next 主题就不是从 hexo-theme-next 中获取了,而是我们自己的私人仓库 hexo-xxx-next 中获取,安装方式是一样的。
前文说过我们将源码托管的需求之一就是为了解决代码合并的问题,为了体验新版本的特性,我们需要将新版本的代码合并进我们的分支:
1 | # 从 origin/master 获取最新版本的代码 |
我们最起码修改过 _config.yml,因此会发生冲突也不奇怪,有冲突咱们就解决冲突。
如果你使用 vscode 进行编码,侧边栏有一个源代码管理,打开它可以看到冲突的文件。
打开冲突的文件,判断冲突项确定要保留(删除)的代码,解决冲突后,提交到缓存区(git add .(file))。缓冲区有本次升级所涉及的代码,可以大致预览一下本次的更新都做了什么事
1 | # 将缓冲区的文件提交至 commit |
升级完后运行本地服务器最后会输出一条:
1 | INFO Congratulations! Your are using the latest version of theme NexT. |
若最新版本的 Hexo 引入了你想要的新功能,你想更新 Hexo 版本的话,首先确定版本号变动的是哪一位。
package.json 的版本号格式是数字由点分隔,如 主版本号.功能版本号.补丁版本号。若更新是主(大)版本号的话,则需要先修改 dependencies 依赖中 hexo 的主版本号,再输入 npm update。
以下是 hexo@v3 更新为 hexo@v4 的示例:
1 | { |
命令行输入:
1 | $ npx hexo -v |
若只是后面两位版本号有变更的话,仅需输入 npm update 即可。
单单从升级版本来合并代码的角度来看,实际上本地 commit 也可以做这种事,将 commit 储存在本地(.git)中不提交远端也是没有问题的,OneDrive也可以完成同步。
但从安全和可调试的角度来看,OneDrive的同步方式存在一定风险(懒的代价)。使用 git 版本控制可以清晰看到每一次提交的修改,不会多出奇奇怪怪的东西。必要的时候还可以进行回滚,相对来说更安全。但这种方案需要使用者了解一定的 git 知识。
从操作步骤来看,使用的 git 同步方案会产生多个仓库,这些仓库一般是拥有权限的人才能查看(修改)源码。比如完成了本文中两个仓库源码同步后,在另一台设备初次同步的步骤是:
git clone 下载 blog 本体。git clone 下载私人仓库 next theme 到 /theme 目录下。以上可以在 blog 项目下的 package.json 设置 scripts,通过一条命令来完成这些事。
由此我们可以看到,相比 OneDrive 的懒人方案,git 方案的操作步骤会更繁琐。更新方式也从自动更新变成手动更新。
两者种方案各有利弊,具体采用什么方案就看朋友们的习惯啦~
本文涉及到的 git 命令都是可以在 git 速查方案 查找相应的解释。
Git 版本管理系统由 Linux 的作者 Linus Torvalds 于 2005 年创造,至今不到二十年。
起初,Git 用于 Linux Kernel 的协同开发,用于替代不再提供免费许可的 BitKeeper 软件。随后,这一提供轻量级分支的分布式版本管理系统得到了开源开发者的广泛喜爱,在大量开源项目中投入使用。如今,Git 几乎是版本管理系统的同义词。
Git 最大的创新就是轻量级的分支实现,鼓励分布式的开发者群体创建自己的分支。每个分支都是平等的,只是原始作者的分支或者实现最好的分支会被社群公认为上游,其他分支被认为是下游。下游分支的修改通过邮件列表发送补丁或 GitHub 发起 Pull Request 的方式向上游申请合并,最后大部分用户从上游分支取得源代码使用。
在这个模型下,如何协同不同分支的开发,当上游发布了多个版本,尤其是并行维护多个发布版本时,如何管理分支,就是一个亟需解决的问题。Git 自身的设计不解决这个问题,也不对此做建模。它只提供分支创建和合并等基本功能,而把具体的分支管理策略留给开源软件的开发者。
对于绝大部分的开源软件来说,既没有维护多个版本的需求,又没有重量级的发版检查,最适合自己的分支策略就是唯一上游分支,一路向前。
Apache Curator 采用了这种策略:主分支 master 是唯一的上游分支,版本号一路向前,没有在以前的功能版本发新的补丁版本的说法。
所有的下游修改,一般也是一个小修改一个分支,做完以后迅速提交到上游评审合并,几乎所有用户获取的版本都是从 master 分支上打 tag 得到的。
这种简单的策略被广泛使用,甚至可以做成自动化的流水线:
Apache Flink 是一个典型的并行维护多个发布版本的开源软件。
Flink Release Management 提到,Flink 上游社群维护最近的两个特性版本,而其过往发布记录大致如下:
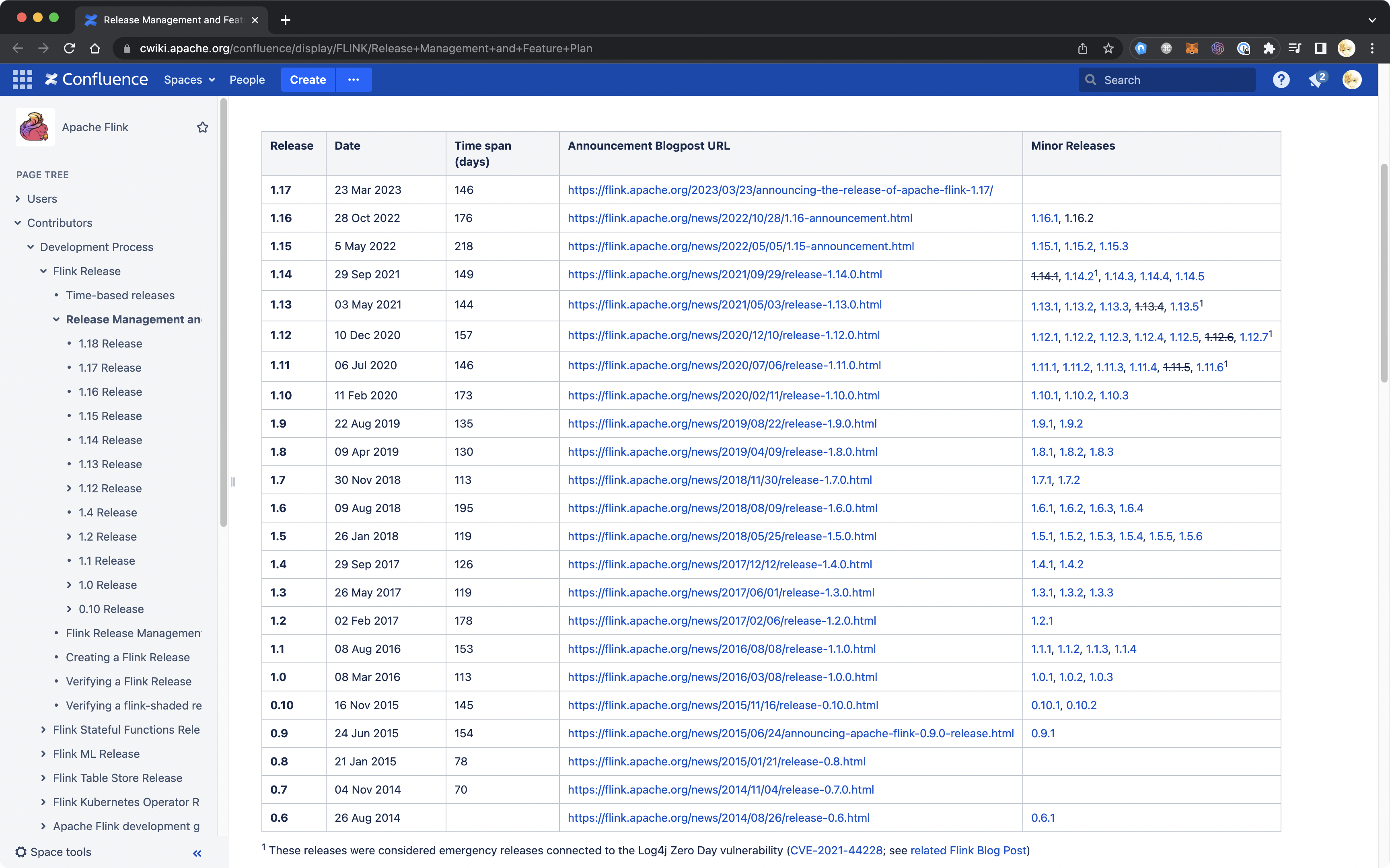
值得注意的是,其版本发布时间并不随着语义版本号单调递增,例如 1.16.0 的发布日期(2022-10-28)就早于 1.15.4 的发布日期(2023-03-15)。
根据语义化版本的定义,patch releases 只包含必要的修复,而不应该包含新功能。如果仍然采取一路向前的分支策略,那么在发布了带有新功能的 1.16.0 版本后,再发布 1.15.4 版本,难道还能 revert 所有功能变更吗?这不现实。
所以 Flink 采取的是和并行维护发布版本线对应的分支策略:
分支是不稳定的 Git 引用,不同时间 check out 同一个分支可能得到不同的结果。Flink 在实际做版本发布的时候,选择的是 tag 的形式来发布不可变的版本:
其他并行维护多个发布版本的开源软件也大多采用这种策略,Apache Pulsar 就是其中之一。除了把 release-X.Y 的分支名模式改成 branch-X.Y 和 release-X.Y.Z.RCn 的标签名换成 vX.Y.Z-candidate-n 以外,两者没有任何差别。
即使没有实际维护多个并行版本,使用这种分支策略仍有一个好处。那就是在发布周期较长的情况下,以切出发布分支的形式来完成 feature freeze 的工作。
例如 Apache Kvrocks 也维护了不同特性版本的分支,但是自进入 Apache 孵化器之后并没有发布 .0 以后的补丁版本。尽管如此,从 2.2 分支的历史可以看出,切出发布分支以后,主分支可以继续正常进功能代码,而 release manager 可以按需 cherry-pick 需要进入到本次发布的变更。这样就不会因为当前有个版本正在发布,而被迫推迟所有不适合进入正在发布的版本的 Pull Request 的评审和合并。
从上面两种分支策略我们可以看到,大部分的开发分支都是一个轻量级的下游分支,其生命周期自开发功能始,终于合并到上游。上游实际要处理的分支策略是与自己的版本发布和管理策略对应的分支管理需求。
不过,对于大型项目来说,有一个变体需要专门介绍,那就是特性分支的分支策略。
特性分支之所以存在,是由于一个特定的功能提案涉及相对复杂的代码修改。为了加速分支内的开发迭代,同时避免把半成品的功能合入上游,提案实现团队拉出一个特性分支进行独立开发,定期合并上游的变更,在功能稳定后提交到上游进行发布。
可以看到,这个模式的特点主要有三个:
OpenJDK 是特性分支的成熟实践者,他们甚至会为特性分支创建单独的代码仓库。
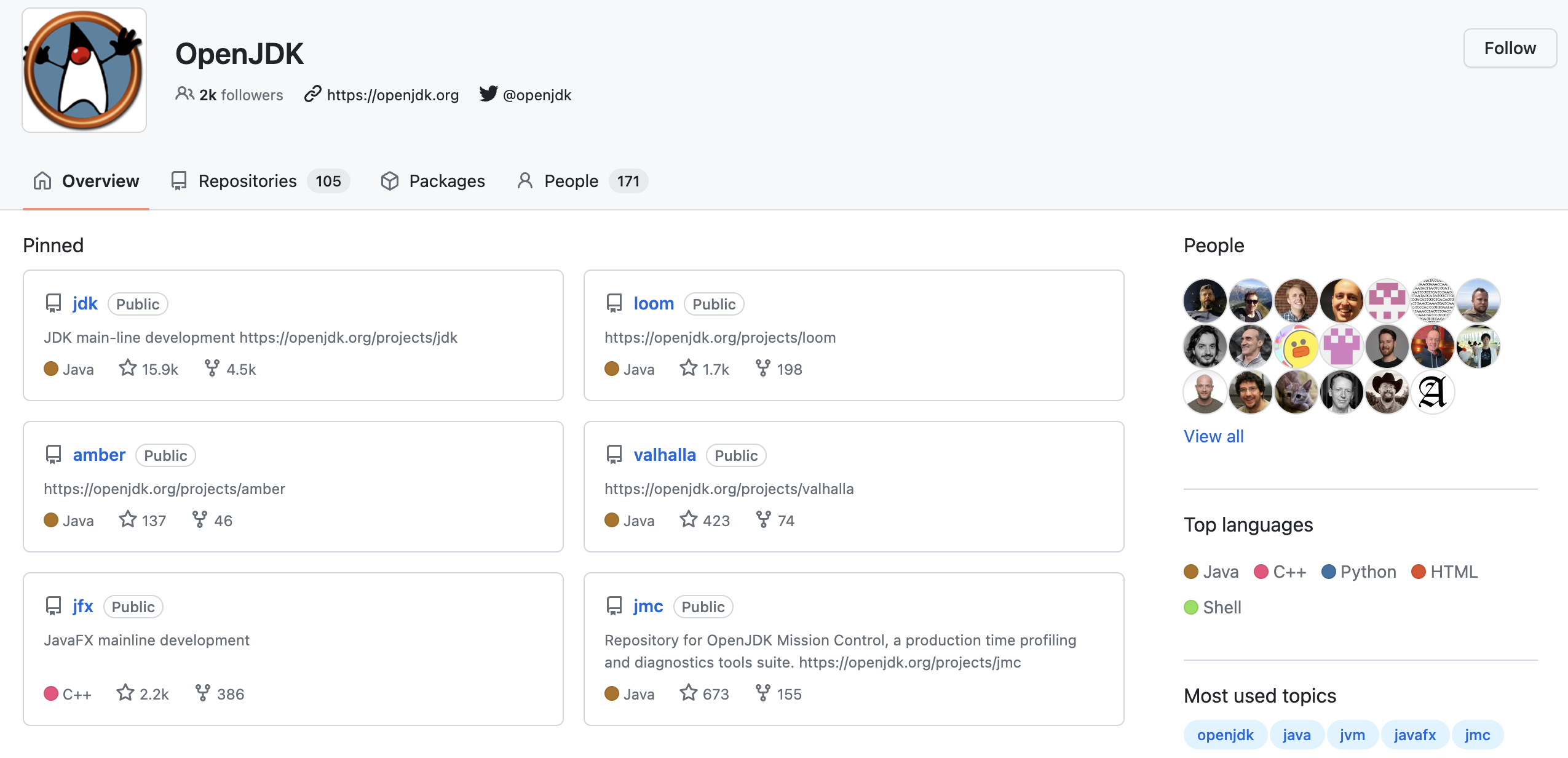
上图中,loom / amber / valhalla 都对应到一个或多个 JDK 功能提案,最终都是会以合入 JDK 主分支结束自己的生命周期。
Implementation of Foreign Function and Memory API (Third Preview) 是一个特性分支在稳定后提交到上游的例子。可以看到,上游 Reviewer 对特性分支进行评审,特性分支的开发者在分支上共同开发,并定期合并上游的变更。最终,整个 Thrid Preview 完成后一次性合入上游。
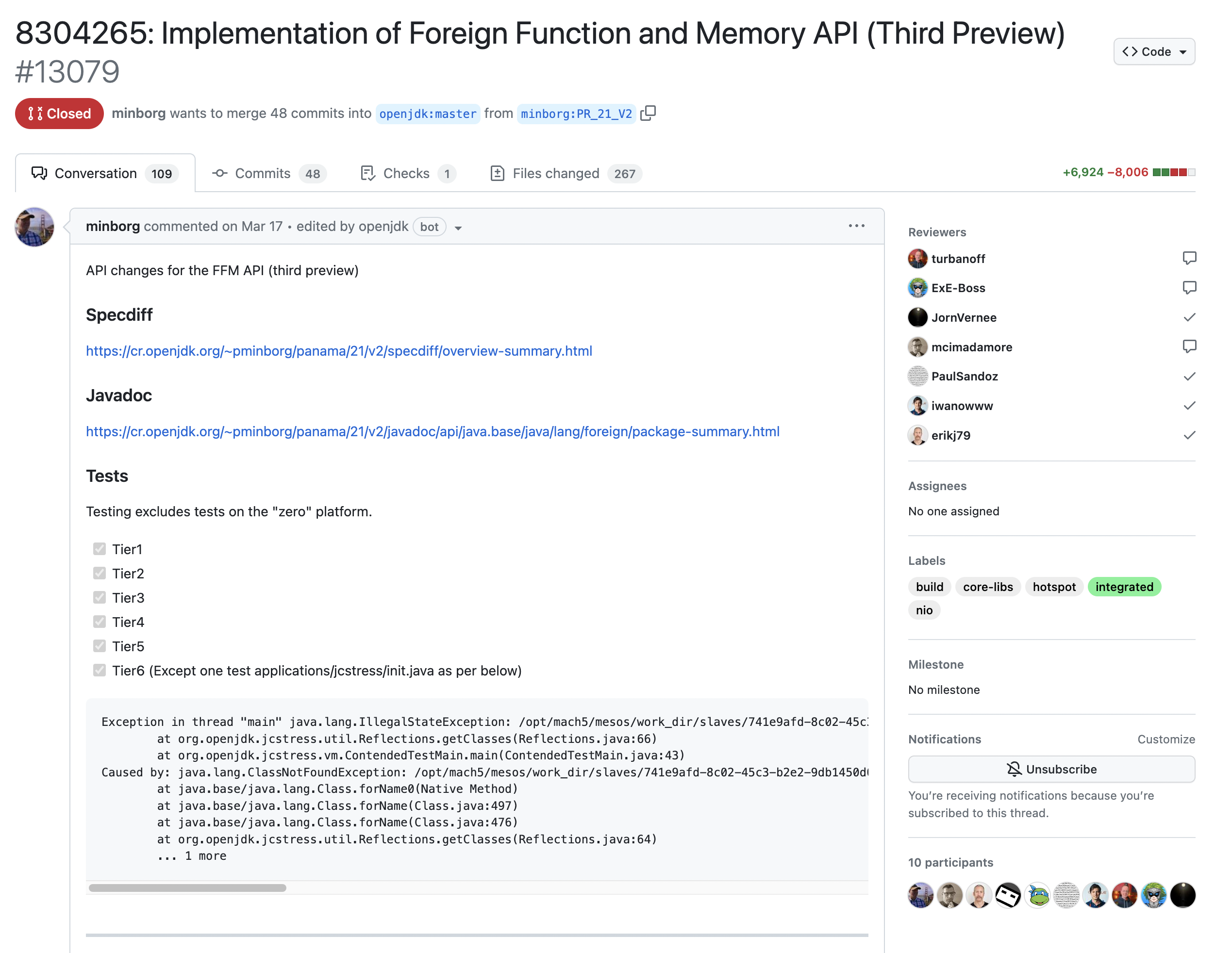
从 feature branch 这种模式来看,实现这一模式的前提是软件代码的模块化。
上面强调的模式特点“定期合并上游的变更”,是特性分支在迭代过程中避免最终提交时和上游冲突,从而需要花大精力调整甚至重做的关键。如果代码的模块化很差,开发者都争先恐后地把自己的提交早点塞进上游以求不要过一会儿就 conflict 又要重新写,那么 feature branch 的模式是不能成功的。
另一方面,稳定后提交到上游其实可以用迭代的方式来看待。类似上面提到的 FFM 提案,其实也不是等到做出一个最终 GA 的版本才合入,而是分成 Incubator 阶段和 Preview 阶段。把通用的接口抽象和必要的重构做在上游,把预览的功能提供给用户试用,这也是 feature branch 能够持续和上游整合并得到用户反馈的关键手段,而不是闭门造车。
从 OpenJDK 的版本策略来看,在切换到三年一个 LTS 版本,其他版本后一个发布前一个即停止维护的策略以后,OpenJDK 上游实质上也只维护了一个 master 分支。对于 LTS 的 8 / 11 / 17 三个版本,OpenJDK 创建了三个单独的维护仓库来合并补丁:
这三个仓库的每一个都只维护一个分支,patch releases 一路向前。
今年新的 LTS 版本 21 发布后,应该会变成只维护 8 / 17 / 21 三个分支仓库。
虽然实现形式略有出入,但是 OpenJDK 针对版本的分支策略其实还是 Flink 齐头并进策略的变种,只不过把 release-X.Y 分支变成了一个仓库,而且引入了 LTS 的概念定义了自己的长期维护分支策略。Python 则是完全符合齐头并进策略,只是分支名和标签名略有出入。
同样作为编程语言,Rust 选择的分支策略略有不同:从 Git branches 页面上看,它维护了 master / beta / stable 三个分支。
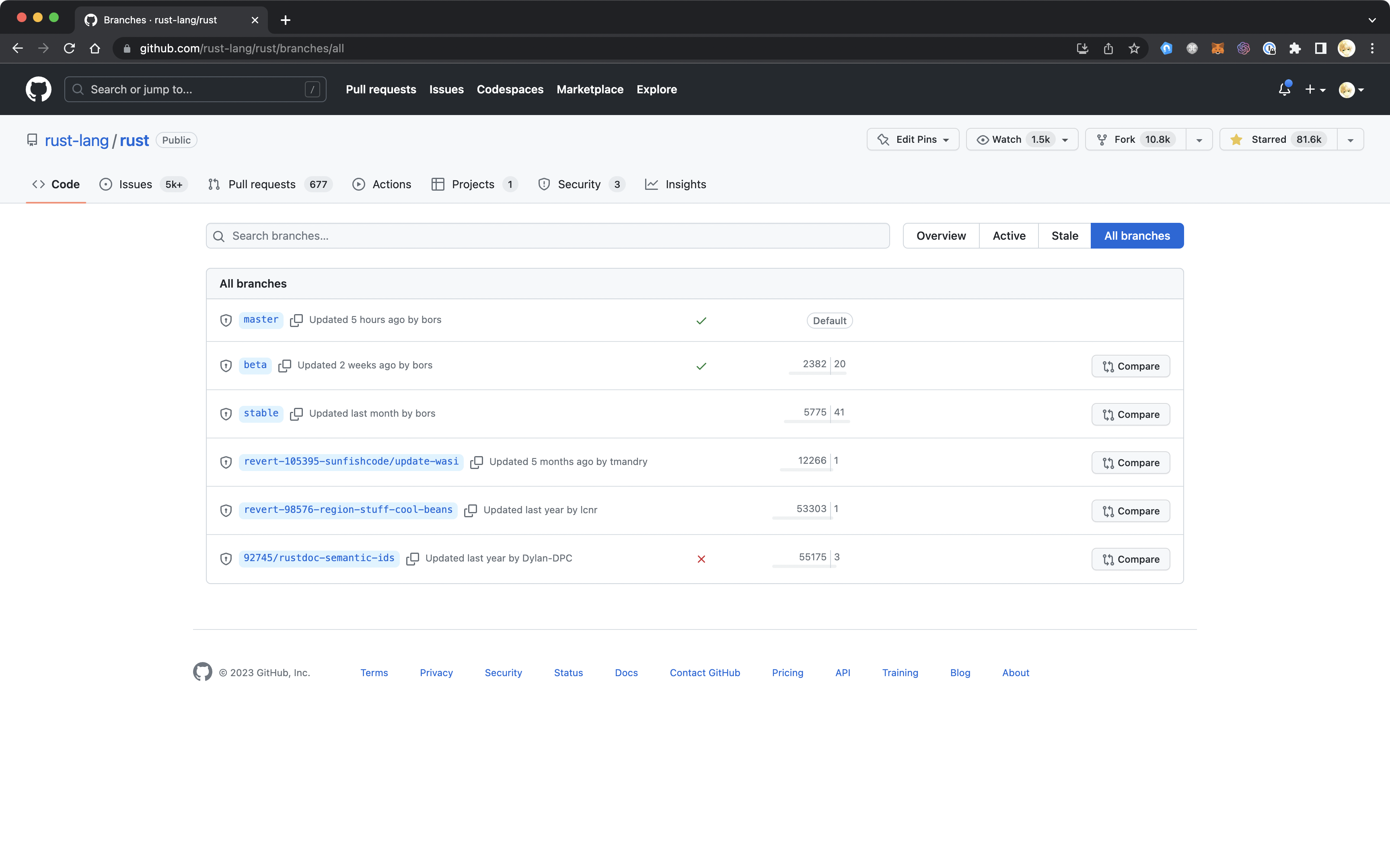
这一版本和分支策略的详细说明可以从 Rust Forge 页面上查到,或者从下游 rustup 的 Channels 说明做补充。
简单来说,master 对应 nightly 版本,每天定时构建后发布。beta 是 stable 前的缓冲。beta 版本发布后六周会发布对应的 stable 版本,然后从 master 切出新的 beta 版本。
Rust 开发者通常要么使用 nightly 版本,要么使用 stable 版本。beta 版本更像是 Rust 团队在发布 stable 前的一个六周的发布测试周期,也就是上面提到的其他软件的 release candidate 时间。
nightly 版本和 stable 版本的另一个重要不同是只有 nightly 版本可以开启 feature flag 启用没打上 stable 标签的功能,所以即使 stable 跟 nightly 版本在代码上仅差大致两三个月,但是很多不稳定的功能可能几年间都只能在 nightly 版本上使用。
Rust 除了直接对应到分支的 Nightly / Beta / Stable 版本以外,还有另外两个版本策略。
其一是语义化版本,目前最新的 Nightly 版本是 1.71.0 版本,最新的 Stable 版本是 1.69.0 版本。Rust 在版本号上其实是一路向前的。即使偶尔发布 >0 的补丁版本,那也是在没有新的功能版本需要发布的情况下,在当前的 X.Y.Z 版本的基础上发的 X.Y.Z+1 版本,而从未出现过版本号回退的现象。
其二是 Edition 策略。语义化版本的约束下,目前所有 1.x 版本的 Rust 都应该是后向兼容的,这种兼容性对于程序开发语言来说尤为重要。但是,保持大方向上的兼容如果变成教条,导致一些小的比如默认值的修改不能调整,那么反而可能是一件坏事。因此 Rust 通过 Edition 来指定一系列默认值和行为的集合,以在实际上保持后向兼容的情况下,优化软件开发的体验。
这个需求由于 Rust 解决的早,可能不这么做的恶性后果不太明显。Perl 7 的提案是一个很好的参考。在 Perl 5 稳定的二十几年后,为了保证后向兼容,即使你用的是今年新发布的 5.36.1 版本,为了用上很多“现代功能”,你需要手动调整一大堆默认行为:
1 | use utf8; |
不过,新版本的 Perl 可以用 use v5.36 一类的办法来实现类似的缩短样板代码的需求,所以 Perl 7 的提案也就被搁置了。
业务代码和基础软件最大的不同,就在于业务代码提交后是立即要运行在生产环境的,而基础软件发布后一般有比较长的采用周期,甚至业务代码可以锁定基础软件在某个稳定的早期版本上。
这一重要不同导致业务代码的分支策略是部署驱动的,其最新的技术探索应该是 GitOps 一类的方案。
不同于基础软件不同分支对应不同版本线,业务代码的不同分支对应的是不同的环境。一个典型的业务开发发布平台会有测试、预发和生产环境,业务代码仓库也分成对应的分支:
某一服务/模块只有一个人负责的情况下,预发环境也可能没有一个专门的分支,而是发布一个开发分支的代码;测试环境有多人一起修改的情况下,也有可能临时拉出一个协同测试分支,保证共同开发的变更都在环境里。
可以看到,在业务自己就是代码的最终消费者的情况下,不同的生产版本或者不同的标签基本是不需要的。
不过,如果是微服务的情况,发布微服务接口定义的 contract 包的时候,还是有版本号的问题的。但是由于访问的流量都可以在企业内监控到,所以一般也不需要维护多个版本,而是在向后兼容的情况下一路狂奔,或者在需要做破坏性改动的情况下依据监控把所有下游服务的负责人都拉到一起讨论升级方案。
最后,介绍一下不同分支策略在 Git / GitHub 上实际操作的一些协同技巧。
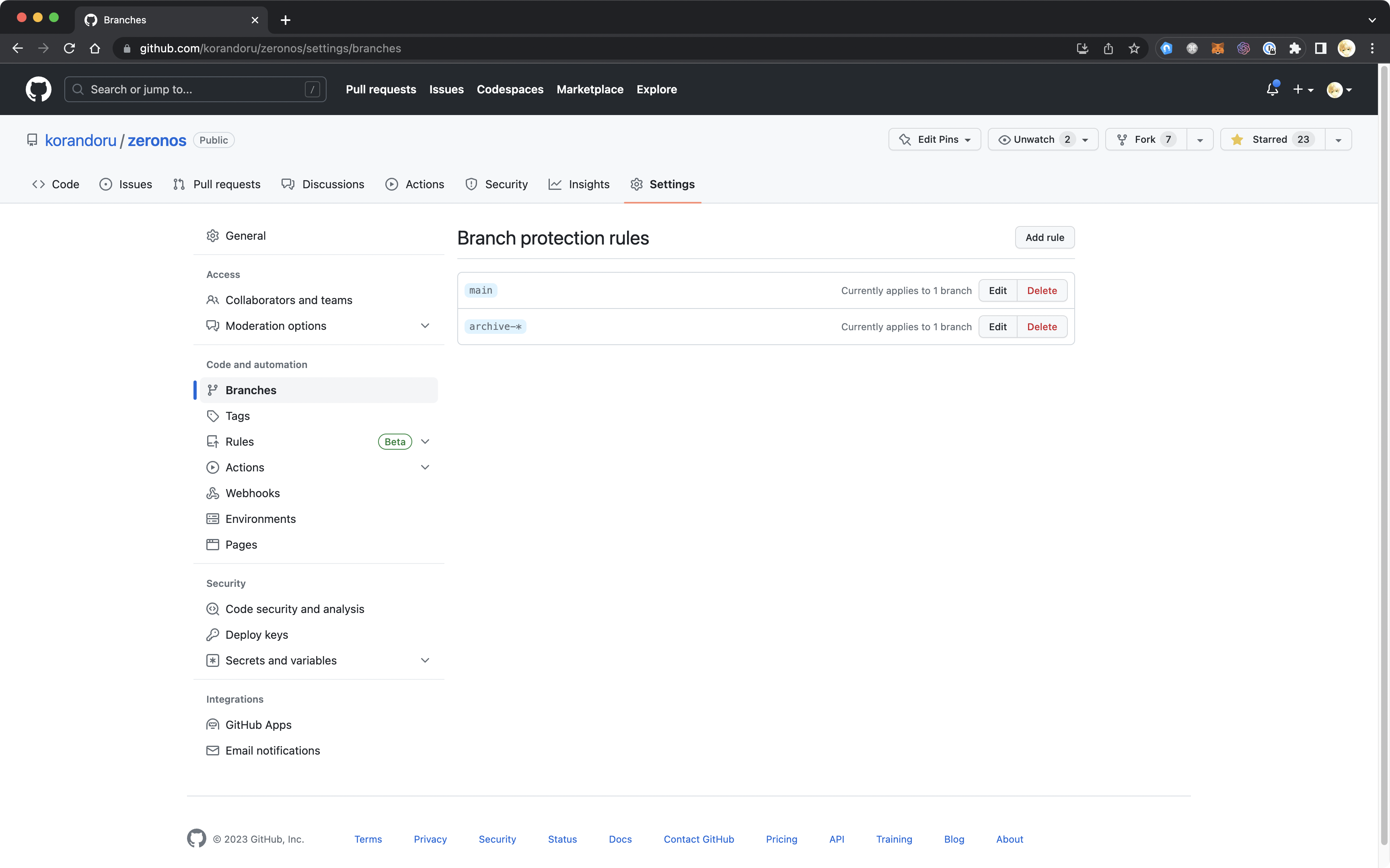
第一个是 GitHub 支持分支保护,避免误删关键分支。
例如,我在 Zeronos 项目里就保护了 main 分支和归档以前尝试的 archive- 分支。
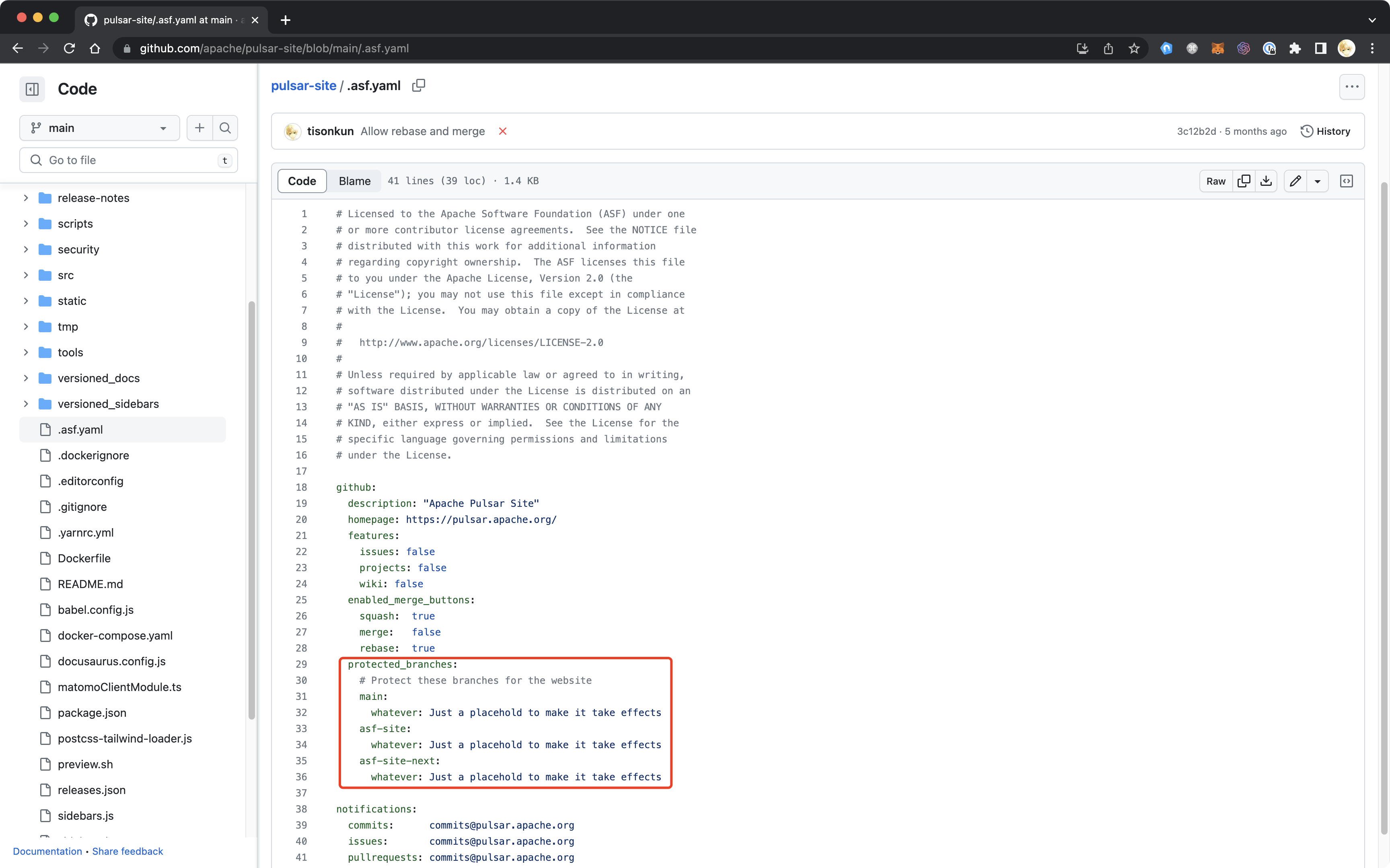
ASF 项目的 committer 没有 GitHub 上 admin 的权限,不过 ASF INFRA 提供了一个 .asf.yaml 的配置文件支持指定保护分支。

第二个是合并策略。GitHub 支持三种合并 Pull Request 的按钮:
我的个人倾向是参考 Flink 社群的经验,禁用 merge commit 的方式,大部分情况下采用 Squash and merge 的方式,少数情况下使用 Rebase and merge 合并。
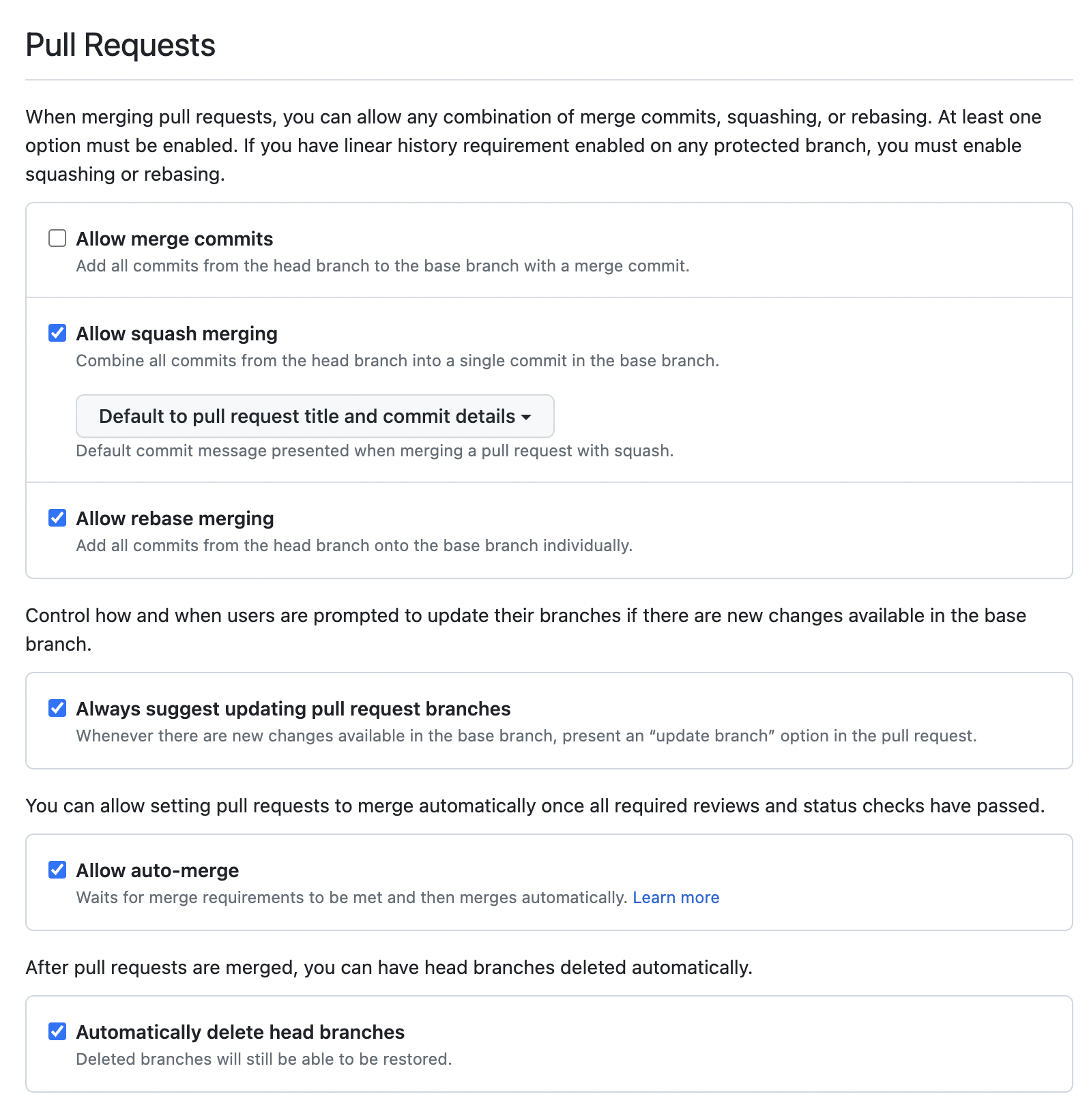
Squash and merge 大于 Create a merge commit 是为了保持主分支相对简洁。很多 Pull Request 尤其是被 GitHub 合并展示 changeset 以后,很容易出现各种 “fix” “save” “tempsave” 的 commit 历史,这些内容极度干扰检索 Git 历史发现问题的效率。Squash and merge 能够把一个逻辑单元以单一的 commit 合到上游,避免了 commit 膨胀。
Rebase and merge 的价值就在确实一个事情需要几个逻辑步骤,但是又是同一个高内聚的主题的场合下,避免 Reviewer 来回 review 多个 Pull Request 和作者反复解决冲突,而是就在一个 Pull Request 里解决,但是把 commit 拆分清楚。最后合并的时候还是线性的历史,但是每一步的 commit 仍然是单独的,而不是 squash 以后的。
其实,在邮件列表时期,这些问题都会被自然解决。因为提交到邮件列表上的就是一个个补丁文件。那么为了能正常的 review 补丁,作者是习惯于自己整理好 commit 的。如果 commit 都是好好写和拆分的,其实 Create a merge commit 也没太大问题。GitHub 在降低了参与门槛的同时,也带来了一些额外的显性教育成本。
本文其实起源于一位朋友凭借旧文《Git 分支整合与工作流》的印象,问我关于保护分支治理的问题。保护分支的动作好做,主要是分支管理的策略,推出哪些分支需要保护,以及推出分支策略背后的版本策略或业务部署策略。
关于 Git 的使用和协作,推荐两本必看好书: