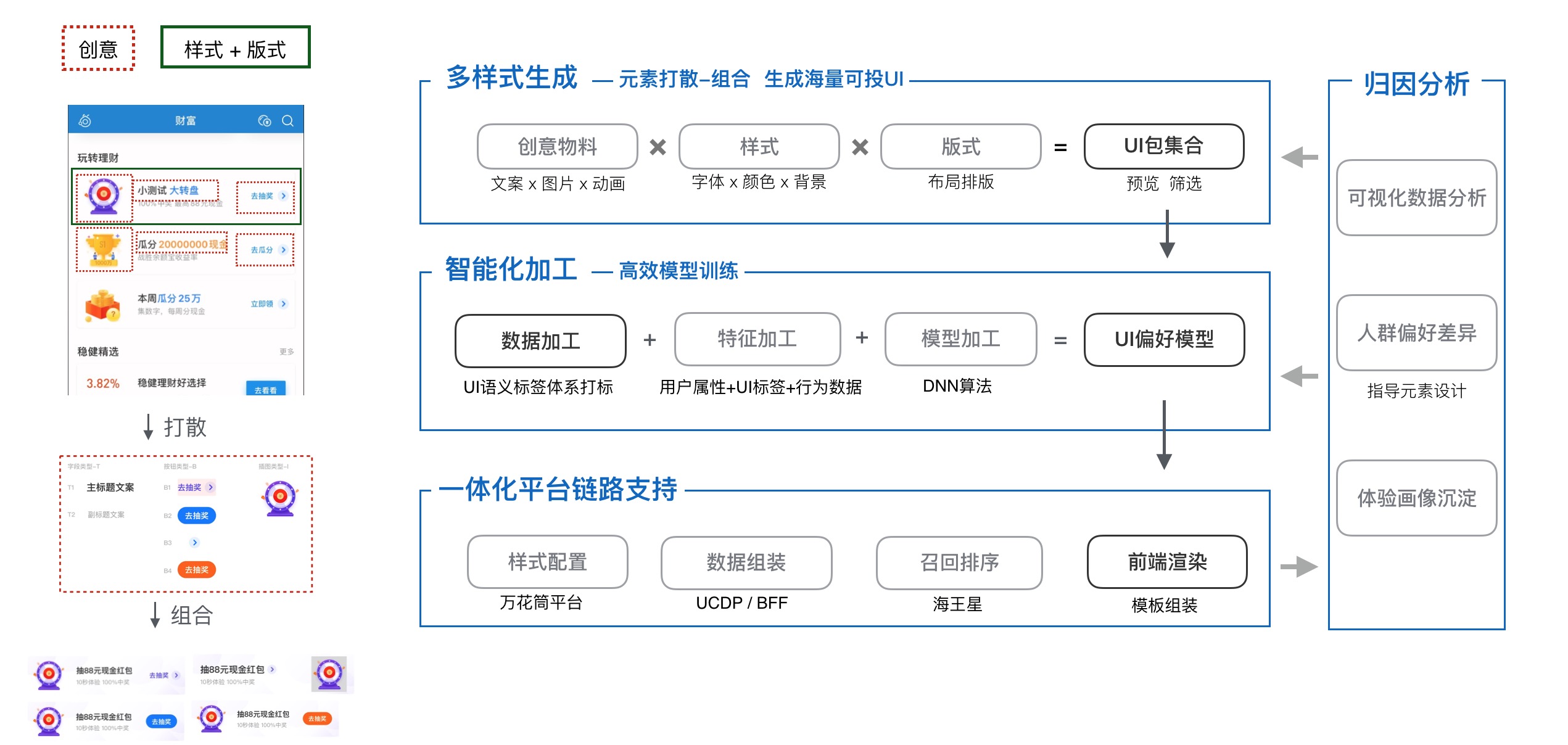
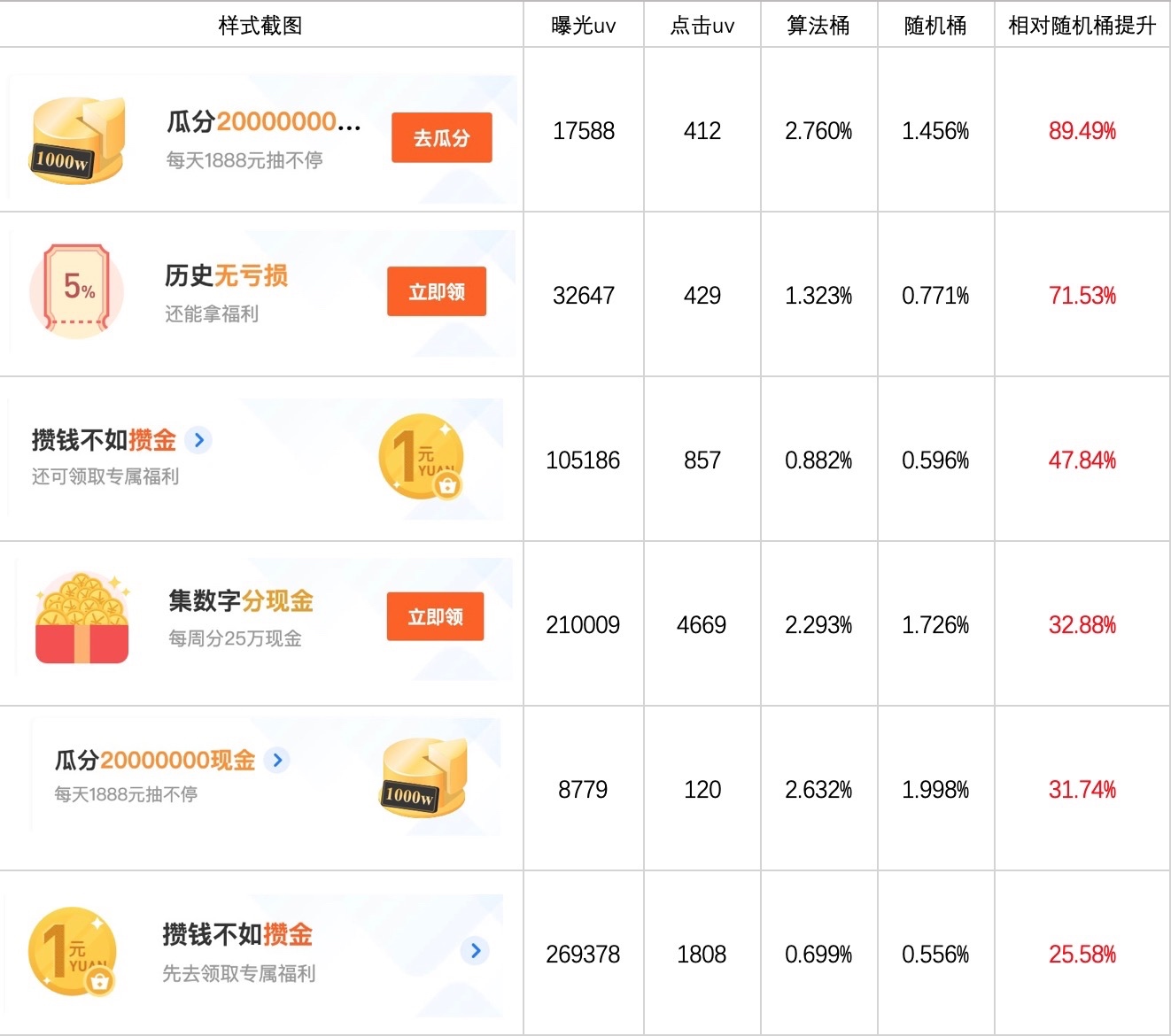
接上篇,继续优化我们的黏土风 workflow。
引导图控制
来看看上篇里的最后一个case:

黏土风格效果还可以,但人物动作总会跟原图不一致,一会双手放地板,一会侧身。图生图一般希望整体轮廓、人物姿态与原图一致,有没有办法控制?
我们可以给它加上 ControlNet 节点,用 canny 边缘检测,试试控制画面主体的轮廓结构:

这下就比较准确地还原了原图的姿势了。
ControlNet 介绍
ControlNet 是一种神经网络架构,能做到通过添加额外的引导图片输入(如边缘图、姿态图等)来控制 SD 模型的扩散生成方向,实现对图像生成过程的精确引导。
通过这套架构,可以训练出每种控制方式对应的模型,生图过程中应用这个模型,输入对应的引导图,就能生成对应的图。
以下是 ControlNet 作者训练好的几种模型,以及用这些引导图生成的图片效果:sketch草稿、map法线贴图、depth深度图、canny边缘、line线、edge边缘、场景、Pose人物姿势

看下 ComfyUI ControlNet 相关的这几个节点:

- 每个 ControlNet 模型的输入,都是预处理好的一张引导图,一般用简单的算法就能处理出来,这里用的是 ControlNet canny 边缘控制的一个模型,对应一个 canny 算法节点,一个古老的算法,python 的 OpenCV 库就有。
- 接着加载 canny 对应的 ControlNet 模型。
- 这张边缘图片输入到 ControlNet 模型,跟文本一起,作为模型降噪生成过程中的引导,指引降噪方向,生成符合文本描述、符合图片边缘形状的图。
这里的 canny 可以替换成 sketch、depth、pose 等算法,搭配上对应的 ControlNet 模型,就能实现不同的控制方式。
ControlNet 原理
扩散生图模型出现后,就有很多人探索怎样更好控制它的生成,显然如果只能用文字生图,可控性太差,最直观的还是能通过草图指引控制它画什么。
怎么解这个问题?对模型简单做一个端到端微调是否可行?例如想让模型按 canny 检测出来的边缘去生成图片,那造一堆 原图 – canny图 的配对作为训练集,微调让模型学习到边缘图和最终生图的关系,是否就可以?大思路是这样,但需要解决微调带来的过拟合、破坏原模型能力的问题,需要设计一个网络结构,能很好认得 canny 引导图特征、跟扩散模型很好结合、效果稳定。
有很多人做过不同的研究,提出过多种方法,ControlNet 的方法相对前人有很大优势,能稳定用在各种场景上,效果最佳,应用广泛。
网络架构
来看看 ControlNet 的这张架构图,我把相应的输入输出示意图加上:

理解这个网络结构前,可以看回这篇文章理解下 SD UNet 网络。上采样 = encoder,下采样 = decoder,为了方便和与上图对应,下面就只提 encoder 和 decoder。
这个图左边是 SD 原 UNet 网络,右边是 ControlNet 新加的网络。首先是把 SD 原网络的参数冻结,不参与训练,这跟前面介绍的 LoRA 套路是一样的,训练不影响原网络,只调整新网络,有诸多好处。
接着它把 SD UNet 网络里的 encoder 和 middle 部分复制出来,再用零卷积(zero convolution)连接到原 SD 网络对应的 decoder 层。几个要点:
- 与 decoder 的连接:
- 整个 ControlNet 网络的目的并不是按 UNet 网络流程有一个输入和输出,ControlNet 网络是只有输入没有输出的,它的目的是在 encoder 识别处理引导图(外加与降噪图/文字Prompt/步数的关系),再把这些信息跳跃连接回原 SD 网络的 decoder,所以 ControlNet 网络本身是不需要 decoder 的,图上的零卷积只是把 encoder 层跳跃连接回 decoder 对应的层。
- 为什么这样做?SD UNet 网络里 encoder 各层保留了图片的细节信息,decoder 只有宏观信息,所以把 encoder 各层都跳跃连接回 decoder 对应的层,这样 decoder 拥有宏观和微观细节所有信息,进行一步步生图。那 ControlNet 这里做的,就是为 decoder 增加信息,不止是原降噪图的细节信息,还加上引导图信息,指引降噪生成方向。
- 为什么用 1×1 卷积作为连接,而不是做一个简单的叠加?
- 如果叠加,会破坏原生图能力。这个 1×1 的卷积,最开始训练前初始化值为0,encoder 里的参数经过这个零卷积相乘,最终输出是0,叠加作用在 SD 网络里的值也是0,也就是训练一开始这个网络对 SD 生图完全没有影响,保留完整的生图能力。随着训练进行,这里的 1×1 不再是零卷积,会逐渐变成一个个权重值,那参数经过这个卷积叠加到 SD 网络,影响就不再是0,可以指引降噪方向。我理解为整个训练过程中生图能力都没被破坏,引导图 ControlNet 对网络带来的影响是一点一点叠加上去的。
- 另一点,自己猜的,与 1×1 卷积 相乘的主要作用是降维,引导图信息有限,低通道低维度的数据已经能比较好地表示,不需要跟降噪生图那么大的数据量,对原网络的影响也小些?
- 其他几个小点:
- 它这里原样地复制了 SD UNet 网络一半的参数,并没有像 LoRA 那样对数据进行压缩,也可以理解为因为这样所以对网络的控制可以更细致。所以它的模型大小是比LoRA大很多,但比原 SD 模型小的。
- 一开始输入的 Condition 是像边缘图这样的图片,图上没画出来的是这个图片还会经过一个四层卷积层,把这张图片转化为隐空间的表示。
- SD 的输入,包括噪声图、文字 prompt 和 timestep 步数,都会进入到 ControlNet 网络参与训练,因为 ControlNet 是从 UNet 原网络复制出来的,有完整的处理这些输入的能力。
训练过程
沿着上面这张图再复述一下训练过程:
- 准备好训练数据:原图 – canny引导图 – 文本描述(可选)
- 前向传播:
- ControlNet:在 SD 每一步降噪过程中,噪声图与引导图 c 叠加,与文本prompt、步数 一起进入 ControlNet 网络,这里的输入跟 SD 原网络是一样的,每层的输出也一样,每一层推理出的噪声图数据表示,都通过 1×1 卷积连接回到 SD 网络。
- Stable Diffusion:噪声图、文本 prompt、步数,一起输入网络推理出下一步噪声图,跟原 SD 训练和推理流程一致,只是这里的 decoder 网络已经叠加了 ControlNet 的网络。
- SD 这里的文本输入也可以为空,训练网络只拟合边缘图信息,实际上 ControlNet 作者训练的那几个模型,训练过程中有一半数据集是无文本输入。
- 损失函数计算:我们知道每一步期望这个网络输出的图是什么(参考SD扩散训练过程),评估预测和输出的差异。
- 反向传播:把差异(损失函数梯度)回传网络,更新网络参数值。SD 网络是锁住的,不回传,参数不变。只在 ControlNet 网络做回传和参数值更新,这里的更新包括每个 encoder 块的参数值,以及1×1卷积的权重值。
训练完后,ControlNet 部分就变成了一个“认得” canny 边缘图片条件的网络,给这个网络输入其他的 Canny 图,经过 ControlNet 作用叠加在 SD 模型上,引导 SD 降噪方向。
论文上还提到一个现象:突然收敛,模型没有逐渐学习识别输入的边缘图片条件,而是在训练到6000多步的时候,突然认得边缘图开始遵循这个输入条件生图。为什么是会突然收敛,也没说为什么,特定架构下的现象,有些玄学。

这是非常通用的架构,只要是跟原图关联的引导图,像上面示例的 sketch、depth、pose 等都可以用同样的方法训练出对应的 ControllNet 模型。
若要自己训练一个 ControlNet 模型,作者有篇详细的教程和探讨:《Train a ControlNet to Control SD》
消融实验
消融实验(Ablation Study)是机器学习领域常用概念,指通过修改或移除模块,来测量这些模块/结构设计对结果的影响,也就是 ABTest。
作者这篇文章分享了做的两个消融实验:《Why ControlNets use deep encoder》。尝试了 ControlNet-Lite 和 ControlNet-MLP 这两个更简单的网络对比效果。这俩不是从原 UNet 网络复制出来,而是自定一个网络,再把这网络作用回原 UNet 网络,ControlNet-Lite是简单的卷积网络,ControlNet-MLP是用像素级多层感知机(Multilayer Perceptron)构造这个网络。

文中可以看出,在 prompt 充足的情况下,这俩简单的架构都能得到很好效果,甚至更简单的架构也能起作用,要指引图片按轮廓生成,并没有很难,难点在与生图模型的结合。在 prompt 不清晰、或没有 prompt 的情况下,这俩架构表现就差多了,生成的图无意义。
之前也有不少其他人的尝试各种方法,比如这篇论文《Sketch-Guided Text-to-Image Diffusion Models》,不足的地方也是与 SD 图生成的语义没法很好结合,只认识边不能让物体与边很好结合。作者认为 ControlNet 现在的架构能做到跟原网络很好结合,两个关键点:
- 用零卷积连接,确保了训练刚开始时对原网络无影响。上面也有说到,沿用 SD 原网络对物体的理解能力,再逐步调节,每一步训练都完整应用 SD 原本的高质量生图能力。否则按随机初始化叠加,一开始几个训练步骤下来,整个网络识别物体的能力很快被破坏。
- ControlNet 的网络也需要接收 Prompt 作为输入,这样 ControlNet 编码器才能认识 Prompt 对象,不会与用户输入脱节,比如训练过程中 ControlNet 网络认识了房子的轮廓,如果没有 Prompt 参与训练,就算用户输入蛋糕,网络也会引导向生成房子,而不是蛋糕模样的房子。
ControlNet 先学到这里,我们继续来优化黏土风 workflow。
人脸保持
我们拿目前加了 ControlNet 的 workflow 试试人物的效果:

效果还行,但人脸跟原图有些对不上,如果我们想让人脸更接近原图,做一个人物美化的黏土风,有没有什么办法?
可以试试给 workflow 加上 IPAdapter 节点,IPAdapter 有强大的风格迁移、人脸保持的能力,先看看效果:

用的是针对人脸训练的 ipadapter-face 模型,人脸美化多了,相比之前相似度高一些,算是人脸美化风格的黏土风,但也不怎么像。
提高 IPAdapter 的权重,能得到越来越像的脸,但跟黏土风融合得不是很好,权重越大黏土风格的感觉越弱:

IPAdapter 还有一个专门为人脸保持做的版本 IPAdapter-FaceID,与黏土风格的融合效果好一些,但人脸特征保持程度也一般:

在进一步优化前,先来认识一下IPAdapter。
IPAdapter 介绍
IPAdapter 是垫图神器,提供风格迁移能力,输入一张参考图,模型会按这张参考图的风格去生成图片。IPAdapter 目前有两类模型:
- IPAdapter
- 提供整图风格迁移能力,与直接图生图有本质区别,原理上图生图是在原图加噪点基础上做演化生成,IPAdapter 是让模型认识图片风格要素,生成跟原图宏观风格一致的图片。

- 结合 ControlNet 等插件,在一些场景下能得到很惊艳的效果:

- IPAdapter 针对 SD1.5 和 SDXL 训了好几个模型,也针对人脸迁移做了优化, **ip-adapter-plus-face** 就是其中之一,使用裁剪的人脸图像作为训练集,对人脸的迁移效果好一些。上面第一步用的就是这个模型。

- IPAdapter-FaceID
- 在 IPAdapter 的架构下,使用人脸特征代替用 CLIP 编码的图片特征,模型对人脸识别能力更强。这个版本实验中,不允许商用。

- 跟着上面 IPAdapter-FaceID 的 workflow 说明一下各模块:

- 用 InsightFace 提取人脸特征
- 人脸特征不像图像特征那么容易学习,因此这个模型配套训练了一个 LoRA 提高学习效果。
- 仅使用人脸特征,模型生成结果不稳定,受 Prompt 的影响很大,因此 IPAdapter-FaceID-Plus 版本尝试将人脸特征和 CLIP 编码的图像特征结合起来,所以这里还是需要一个 CLIP 模块。
IPAdapter 原理

IPAdapter 由两部分组成:提取图像特征的编码器,以及把图像特征接入网络而新增的解耦交叉注意力模块。
- 图片编码器:对参考图编码,提取图像特征
- IPAdapter 对参考图的编码,使用了 CLIP 模型,但不是 SD 内置的 CLIP,CLIP 是一个模型家族,作者应该是挑了对图像特征识别编码效果更好的 CLIP 模型。
- 后续新出的 IPAdapter-FaceID,是使用了 人脸特征 FaceID 代替图像特征,具体来说是用 InsightFace 库提取人脸特征向量进入网络,更好保留参考图里的人脸身份特征。
- 编码后的图像,这里加一个可训练小型投影网络,通过 Linear layer 和 Layer Normalization 投影到长度4的特征序列中,进入网络。
- 解耦交叉注意力(decoupled cross-attention):
- 回顾 SD UNet 网络的构成,整个网络有16个 Transformer 模块,每个 Transformer 模块里有一个自注意力层和一个交叉注意力层。
- 将编码后的图像特征加入到 SD UNet 网络,常规做法是图片特征与文字特征相加,再一起进入 Transformer 模块里训练。但 IPAdapter 用了另一种方式,它向这些 Transformer 模块另外增加一个交叉注意力层,用以处理图像特征,然后把文字和图像两个交叉注意力层相加,称为解耦交叉注意力。
- 为什么这样做?不跟文本 prompt 混合,这样图片的特征可以在网络中完整保存下来,跟文字一样具有独立引导能力。
- 如果不用解耦交叉注意力机制会怎样?作者做了消融实验,用一般的方法 — 图片特征与文本特征直接连接,一起嵌入到 UNet 的交叉注意力层中,结果如下图的 Simple adapter 所示,能根据图像风格生图,但质量低很多。

ComfyUI 上 IPAdapter 的两个节点,一个是 CLIP 图片编码器,一个是包含架构图里红色区域可训练参数的 IPAdapter 模型。
训练时跟 ControlNet / LoRA 等一样,也是冻结原 SD 网络,只训练新加的 IPAdapter Transformer 网络,大概2200万个参数,IPAdapter SD 1.5 的模型大小基本 44M,对应着 22M 个参数。但 IPAdapter SDXL 的模型大了20倍,原因不明(原 XL 参数量只比 1.5 大 7 倍)。
InstantID
IPAdapter 在很多场景生图场景下做风格迁移和人脸保持都是神器,但在我们黏土风 workflow 下表现一般,我们试试另一个专门针对人脸迁移的技术:InstantID。

人脸特征的保持以及黏土风格融合的效果比 IPAdapter 好很多。试过其他图,人脸轮廓特征也很明显能更好保留下来:

InstantID 原理
InstantID的 原理很简单,可以近似理解为 InstantID = IPAdapter-FaceID + 人脸ControlNet。
看这两张图,ComfyUI 里使用 InstantID 的几个模块,跟架构图对应,由三部分组成:


- 用 InsightFace 库提取人脸特征,用一个 projection layer 投影映射成跟文本的特征空间一致的向量表示。
- 添加解耦交叉注意力层,与 IPAdapter 一致。
- 加一个面部识别的 ControlNet,但有些小改动:
- 只使用五个面部关键点(两个用于眼睛,一个用于鼻子,两个用于嘴巴)作为条件输入,而不是细粒度的 OpenPose 面部关键点。防止强调多余的面部特性,比如嘴巴闭合这种是可以由prompt控制,而不需要保持的。
- 原 ControlNet 文本 Prompt 是加入网络训练的,这里没有加入,只用人脸信息作为ControlNet 中交叉注意力层的条件,主要是希望这个网络只控制人脸,不受文本对人脸描述的影响。
前两步基本就是 IPAdapter-FaceID,第三步就是一个特制的 ControlNet。
从前面效果看起来,第三步这个人脸特征 ControlNet 对人脸特征保持作用很大,用已有的技术方法做组合微调,已经能很好解决一些问题。
最后
我们使用 ControlNet、IPAdapter、InstantID 对黏土风格 workflow 做优化,希望能达到跟原图一致性较高、人脸迁移较好的效果,其中 InstantID 组合了前面两个技术,有很强的人脸迁移能力,但这也带来副作用。在原网络上叠加各种修改,对原生图模型都会造成不同程度的破坏,比如加了 InstantID 后,原文字 Prompt 和 Canny ControlNet 的控制就没那么精准了,上面几个例子可以看出,原来的 ControlNet Canny 边缘图已经很难起作用了,这很好理解,在原网络上叠加的处理,各部分是相对独立的,很难有非常好的融合,InstantID 把方向强力往人脸保持上引,其他输入条件就会被弱化。
这种 Adapter 类,需要在效果和原模型侵入程度间保持平衡,不同场景选择不同的方案,在某些场景要更好的效果,还是得自行微调模型,目前还没看到很完美的方案。
到这里已经可以有一个还算可以、对人脸风格化友好的黏土风格图生成 workflow 了。目前黏土风 workflow 要再进一步优化到生产环境,就是继续调整 Prompt、调整各组件参数,或者训练专有的 LoRA 模型了。
目前对应 workflow 见下图,可在 ComfyUI 上导入:

参考资料
ControlNet 论文:https://arxiv.org/abs/2302.05543
ControlNet如何为扩散模型添加额外模态的引导信息:https://zhuanlan.zhihu.com/p/605761756
精确控制 AI 图像生成的破冰方案,ControlNet 和 T2I-Adapter:https://zhuanlan.zhihu.com/p/608609941
浅谈扩散模型的有分类器引导和无分类器引导:https://zhuanlan.zhihu.com/p/582880086
使用 diffusers 训练你自己的 ControlNet:https://huggingface.co/blog/zh/train-your-controlnet
深入浅出完整解析ControlNet核心基础知识:https://zhuanlan.zhihu.com/p/660924126
快速理解AIGC图像控制利器ControlNet和Lora的架构原理:https://blog.csdn.net/colorant/article/details/136732221
InstantID技术小结:http://www.myhz0606.com/article/instantID
IP-Adapter 原理和实践:https://zhuanlan.zhihu.com/p/683504661
IPAdapter使用:https://www.runcomfy.com/zh-CN/tutorials/comfyui-ipadapter-plus-deep-dive-tutorial
新一代“垫图”神器,IP-Adapter的完整应用解读:https://developer.jdcloud.com/article/3483
如何在 ComfyUI 中使用 IPAdapter Plus 进行风格迁移:https://www.comflowy.com/zh-CN/blog/IPAdapter-Plus
IP‐Adapter‐Face:https://github.com/tencent-ailab/IP-Adapter/wiki/IP‐Adapter‐Face















































































 能,但还比较勉强。
能,但还比较勉强。