提起 Richard Dawkins, 大部分人想起的是他的第一本书《自私的基因》(the Selfish Gene)。他后来写的 the Blind Watchmaker 从另一个角度探讨了和进化论相关的一些问题,我最近看了后觉得同样有趣和重要。和自私的基因一样,这本书比较老,第一版出版于 1987 年,但是内容一点都没有过时。现在能买到的大部分是 2016 年出的 30 周年纪念版,作者在前言里说他几乎没找到需要修改的地方,看完之后我不得不同意。
这本书的书名来自于一个叫 the watchmaker argument 的支持造物主存在的论证。大致的内容是:如果你在路边捡到一块奇特的石头,尽管它的纹理或者形状很精妙,你也能相信它是通过一个自然的过程偶然形成的。毕竟天下有那么多石头,总有一些会具备看来奇特的性状。但是如果你在路边捡到一块表,你无论如何都不会相信这样精密的物件是一个自然过程的偶然结果,而不是来自于一个制表匠的刻意设计。自然界和生命的复杂度远远高于一块表,所以更不可能是偶然形成的,有意识有目的的造物主一定存在。这个论证最早出现在英国人 William Paley 的书里,但在他之前的牛顿、笛卡尔等人也都认为宇宙的运转和钟表类似,上帝就是钟表匠,科学家发现的只是上帝设计的规则。看这本书让我想起正好 20 年前的冬季我和导师到 Rutgers 开会,回 New Haven 的路上下着大雪,所以他只能慢慢开车。路上的几个小时里我们在聊为什么宗教吸引了那么多人,大概就是因为人类很难理解几百万年到几亿年这个区间里自然的演化过程能产生的结果,于是必须求助于造物主来解释生命的存在。
我初到美国的时候,最让我惊讶的事之一是在科技发展最前沿的国家竟然有一些州在争论是否应该在中小学教进化论,或者是否应该同时教神创论。直到现在其实也没有多少改变,现在美国大选最主要的议题之一是女性的堕胎权,而且反对者的依据来源是宗教而不是科学和伦理。我一直认为宗教对教育和社会的影响是美国的 bear case 里排前面的。在中国宗教离大部分人的生活很远,对教育更是没有影响力,总的来说是正向的事。但是因为少有争议和质疑,在大众文化中也就缺乏有意义的讨论。大部分人把进化论作为事实简单接受,从没考虑过其中的细节,比如像眼睛这样精密而脆弱的器官,是如何通过进化过程形成的。另外物种的边界在于同一物种个体间可以通过交配产生后代,不同物种的个体间无法产生健康的后代,那么如果不同物种是从共同祖先进化而来,那新的物种刚分化出来时岂不是无法繁衍?
王垠发表在主页和 blog 上给清华的退学信中说到了很多中国的教育以及中国的大学存在的问题。可以说其中涉及到体制的部分大多数是客观和真实的,是很多学生的亲身体会,甚至可以说要是他到读博士才意识到这些问题,已经有些晚了。一些清华的学生和校友针对王垠的退学信设立了一个 blog -清华梦依然在,集中了一些反面的看法。双方各执一词,其实争论主要是集中在一些细节问题,还有王垠信中对清华和他们实验室两位导师的评价,对中国教育大环境存在的问题,其实很少有人真正持不同意见,只是大家有不同的解释。我不在清华,不了解具体情况,所以对涉及到清华和他们实验室的具体情况,自然没资格评论了。
王垠的信让我回想起自己本科的时候。我在武汉大学读的本科,武大在学术上不如清华,类似王垠说的问题表现得可能还更明显一些。那时候的我年轻气盛,嫉恶如仇,想法和态度大约和现在的王垠差不多:不喜欢很多学校里的教授,看不惯学校的很多事情。我从大二结束以后就很少去上课,因为总是觉得有些不屑,认为学不到什么东西。每个学期系里开什么课,我就去书店买对应的影印版英文教材看,到期末最后一节课去听老师划划重点,然后就去考试。往往到了一个学期结束还问同寝室的同学教某门课的老师是男是女。我虽然不像王垠,但也算是个敢作敢为的人,大四时在 BBS 上发过一些帖子,其中有说到武大的计算机科学系教的不是计算机科学,而就是一个电脑培训班。我们院的党委副书记同时也是 BBS 上院版的副版主,他常常把我封了,有时还打电话到寝室教训我。这种事情发生得多了,后来就成朋友了。将要毕业的时候,校学生会从应届毕业生里面找了包括我在内的三个人去给低年级同学做学习经验交流。当时因为院校合并等一系列事情,学生对学校的怨气挺大的,自由问答的时候有个学生问我学校的种种不好对我有没有什么影响。当时在教五楼的礼堂,我对着下面的几百学生说:“武大要强起来就得靠学生自己。每个学生为着自己的理想去奋斗,每个人都做好自己的事,武大自然就强了。靠现在行政大楼里面那帮人去决策,武大不可能强起来的”,不知道有没有把邀我去的那个学生会学习部的 mm 吓到。那时候我还没有拿到毕业证。
凡事都有两面。王垠做出退学的决定,我想他只看到了一面。我本科时所处的环境,促使我养成了独立学习,独立思考的习惯和能力。我在软件工程实验室虽然常常在做些无谓的事情,不过大量的阅读使我对软件工程发展的概况有了全面的认识。王垠对他实验室的教授有颇多抱怨。本科时有一个数学系的教授在瞒着我的情况下把我交的作为一门课的 term project 的程序带到高交会做演示,后来还是一个去了的人说起我才知道。到后来买方提出一些要求,他因为搞的是数学,不熟悉编程,无法解决,才又来找到我。当时曾因此很不愉快,并非我想从那个程序得到什么商业利益,而是因为我最不喜欢被人欺瞒。可是要是不是因为他开了那门课,我也不太会对那个领域进行深入的学习,也就不会认识我现在的导师。所以要是没有他,我现在会是另外一个情况,或许差一些,或许好一些。人生际遇,从独立的一件事是难以判断祸福的。最重要的是以平和的心态看待问题,不管处于什么样的环境,都要 make the best out of it。
环境的不尽如人意并不是一件坏事,以其说“天将降大任于是人”之类的空话,不如看看真实的例子。很多人说中国的教育体制不能培养出世界一流的科学家,真是这样吗?现在在清华大学高等研究所的王小云在对 MD5 和 SHA-1 等一系列 hash function 的分析方面得到了突破性的进展,现在美国搞 computer science 的人基本都听说过她的名字,密码学界就更不用说了。可以说她和她学生的研究代表着理论密码学的 state of the art。 Wikipedia上说:
At the rump session of CRYPTO 2004, she and co-authors demonstrated collisions in MD5, SHA-0 and other related hash functions. (A collision occurs when two distinct messages result in the same hash function output). They received a standing ovation for their work.
在一个学术会议上,所有人起立为一个 talk 鼓掌,这是很少见的。她的简历上说:
Education:
B.S., Mathematics Department , Shandong University, 1987.
M.S., Mathematics Department , Shandong University, 1990.
Ph. D, Mathematics Department , Shandong University, 1993.
王垠说他打算退学后出国找一个喜欢的学校做他心目中真正的科学研究。我想他会失望的,因为理想的学术殿堂不存在,失望的结果可能有两种,他或许会明白一些事情,从此有一个比较平和的心态;或许会做出更极端的选择。2他信中说的很多问题都是 universal 的,有人的地方都存在这些问题,只是因为中国发展变化得太快,所以各方面的矛盾也表现得更为明显和极端。美国也是一个功利的国家。在美国教授同样要靠发 paper 申请 funding 和拿 tenure,很多研究生同样要做很多无聊的表面工作。很多美国实验室的老板,特别是还没有拿到 tenure 的教授,不管学生愿不愿意都要逼着学生干他觉得需要完成的活,比起国内有过之而无不及。我认识的一些别的学校的中国学生,放暑假想要回国探亲老板都不让,就算让也只给很短的假期。况且在美国你的学费生活费都是靠导师从科研经费出的,和导师关系搞僵了就得卷铺盖走了。3王垠在信中说国外大学都有 common room,而国内没有。另外他觉得学生之间的讨论很重要,而实验室组织的讨论每个学生讲讲对自己看的论文的看法,他又觉得那样的讨论不好。有没有 common room 只是一个形式,形式决定不了内容。我就基本不去 common room ,因为我不喜欢人多的地方,我喜欢一个人静静地思考。有时在走道遇到一个人想说什么事情,就靠着墙一说就是一两个小时,也没有觉得需要一个 common room。在国外大学里的学术讨论其实和他所描述的他们实验室的讨论差不多。通常也就是一个人说一说对某篇论文的看法,经常也是很长时间没有什么结果,很多想法被提出来被否定掉。要找一个他心目中理想的科学研究的殿堂,恐怕穷其一生也找不到。科学研究中的大部分工作都是要静下心来独立完成的。讨论的真正目的是在有一定结果的时候告诉别人,让别人挑刺,所谓的 peer review。他说导师不鼓励学生之间的讨论就不知道别人在做什么,什么已经做了,什么没做,有些什么有趣的问题。以什么样的方式做研究是自己的事,导师鼓励不鼓励只是一个参考意见,毕竟已经不是小学生了。我的导师每个星期和我见一次面,听我说说自己的点子,给我一些指点,除此之外都是我自己安排。我觉得对计算机科学来说,到了博士阶段,正确的研究方式是独立查找资料、独立思考、独立完成工作,这个只是个人的看法,但有一点我可以肯定:要知道他所说的那些东西,最好的方法不是讨论,是 Google。
我并不是要写那么长一篇文章批评王垠。这三天来正正反反的文章已经很多了,只是联系到自己,颇有感触。对王垠我首先是欣赏的,当年看他写的关于 Linux 和 TeX 的文章,受益很多,现在看到他的退学信,觉得他是个有激情、有勇气的理想主义者。中国需要很多能坚持自己理想,不被环境所同化的人。可是一个人光有理想和激情是不够的,在坚持原则的同时,还要有一颗宽厚、平和、和乐观的心,这样才不会因为对现实的失望而最终放弃自己的理想。我本来不喜欢李敖,不过他在清华的演讲其中一段让我很感动:
我曾经觉得自己在这方面很幸运,在中国的同龄人里较早开始接触计算机,从小就知道未来想做什么,所以在别人纠结专业的时候我完全不需要选择,而自己的兴趣也正好是发展很快、机会很多的领域。但是随着年龄和经历的增长,我越来越觉得因为过早地在某方面产生强烈兴趣而排除了其他可能性未必是一件好事。Nike 创始人 Phil Knight 在他的自传 Shoe Dog 里说:
I feel sorry for the people that know exactly what they’re going to do from the time they are sophomores in high school. I think the process really needs to go through a time period before you really find what it is.
如果你关注 Charlie Munger 的文章或演讲,会知道他在很多场合强调过多学科思维的重要性。他认为具备多学科的基础知识和思维模式对于做正确的决策是至关重要的。只精于一门的人,一方面容易管中窥豹,拿着锤子就觉得什么都是钉子1,另一方面在某方面的资历越高,就越容易自信、越看不到自己的盲区、越可能在自己的称职范围之外做错误的决定。Liberal arts 教育对本科的定位是有所侧重的通识教育,所以很多美国大学都是先进入学校学习一段时间后再选专业。耶鲁的很多本科生到最后一年才选定专业,并且本专业的学分只需要占到毕业所需总学分的三分之一,所以拿双学位是很常见的事。在我们系即使是博士,前两年也要上各方面的课程,必须通过所有四个领域的综合考试2才能选择导师和具体的研究方向。我的导师在计算机科学的多个方向都有很高的成就,所以无论我选择在哪个方向深入下去,他都可以指导我。有一次我告诉他我对很多东西都挺感兴趣的,苦恼于如何决定博士论文的主题。他对我说「不用担心,大部分人的问题是专业化得太早,那并不是一件好事」。
过去一两年有多位投资人朋友和我讨论过 AI 相关的创业机会。我的观点一直都是:大的机会基本上是巨头的,小公司没有特别好的机会。
当技术上的突破让小公司有机会颠覆大公司时,新技术最初的应用都在巨头看不上的新兴细分市场。随着这些市场快速扩大,小公司在成长起来后迅速地进入主流市场抢占原主导者的份额。随着原本不存在的个人电脑市场兴起的 Intel、Microsoft 等是最好的例子。近年来 AI 的发展在技术上有很大突破,但商业上的局面却没有给创业公司颠覆性的机会。一方面这是巨头们从一开始就重视的领域,投入很大;另一方面机器学习本身就需要大量的资源和数据,所以大公司或者他们投资的企业往往更有能力持续产出最好的成果。
另一个原因是新 AI 技术的应用往往是对现有场景和过程的改进或补充,没有创造出以前不存在的全新场景,所以对于已经掌握了用户关系的产品来说,后来者无法形成威胁。我喜欢举的例子是 Adobe 能在 Photoshop 中增加 AI 功能,Stable Diffusion 和 Midjourney 却不可能做出替代 Photoshop 的产品。在这种情况下,谁掌握了与消费者的直接关系,谁就掌握了市场。没有什么是比随身携带的手机和消费者关系更密切的,在可见的未来仍然如此。手机不仅仅是设备,还是包括应用和开发者在内的整个生态。Humane 和 Rabbit 之类的公司错误就在于试图做一个完全独立于手机但是又无法让用户不用手机的产品。Apple 的产品与消费者之间的密切关系决定了短期在技术上有没有走在最前面不是特别重要。OpenAI 做不出 iPhone 的替代品,更别说 iOS 的整个生态。但 Apple 可以把 OpenAI 的能力整合进自己的产品。如果 OpenAI 不愿意合作,还有 Claude 等众多选项,虽然不一定是最好,但差别也不大。
Apple 的设备会把一部分非个性化的请求发送给 ChatGPT。有一些媒体说与 Apple 的合作对 OpenAI 是利好,但是我认为 OpenAI 的收益是非常短期的。第一,Apple 与 OpenAI 的协议规定他们不能存储用户数据1;第二,Apple 在技术上也有措施避免 OpenAI 把同一用户的多次请求关联到一起。所以 OpenAI 得到的基本上仅限于财务收益,和用户之间建立不起有意义的关系。Apple 之所以在使用 ChatGPT 的时候明确告诉用户,一方面是为了透明,让用户知道信息发送到了哪里;另一方面恐怕也是要避免为 ChatGPT 引起的问题背锅。考虑到 Apple 走的从芯片到整机、到软件、到服务的垂直集成路线,以及 OpenAI 与 Microsoft 的密切关系,Apple 一定会在尽可能短的时间内用自己的方案替代 ChatGPT。可以说在战略上 OpenAI 是比较被动的,这是个他们无法拒绝的 offer。无论接不接受,他们自己的独立 C 端产品在 Apple 的平台上都不再有存在的意义,但自己赚这笔钱总比让竞争对手赚好。而且无论如何 Tim Cook 都会说「我们找了市面上最好的 partner 合作」,OpenAI 可不愿把这个背书给别人。
现在的 OpenAI 让我想起以前的 Nuance. Nuance 曾经是语音识别做得最好的公司。据说 Google Voice Search 最早是用 Nuance,但同时 Google 也用 Nuance 返回的结果训练了自己的语音识别系统,最后向第三方推出了语音识别服务,成了 Nuance 的竞争对手。过程是否真是这样我没能找到实证。很多知名汽车品牌的车机系统和 Siri 的早期版本都使用过 Nuance 做语音识别,但这家公司后来一直没发展到很大,最后被 Microsoft 收购了。即使是现在股价已经上天的 Nvidia,从长期来看在整个生态中的地位也并不是坚不可摧。芯片设计生产和相关的底层技术门槛当然很高,但是往后绝大部分面向消费者的 AI 应用的集成点会是 Apple、Google、Microsoft 在操作系统层面提供的 API,而不是 CUDA.
Apple Intelligence 是目前为止最让我兴奋的 AI 产品。之前的各种 chatbot 都仅限于给用户提供答案,实际根据这些答案执行动作还要靠用户,而 Apple 则有条件让 AI 代替人完整执行一些任务。当然这样让 AI 的决策直接造成现实中的结果是有风险的,如何尽量把人工操作在流程中减少,同时又让风险可控,这是个需要仔细平衡的问题。Apple 的另一个独特优势是可以访问用户的大量私有数据,从而能帮助用户完成高度个性化的任务。说到这个,Google 曾经有个叫 Desktop Search 的产品,是帮助用户检索 Windows 和 Mac 上的本地文件的,后来被关闭了,如果留到现在会很有价值。
Apple Intelligence 带来的可能是类似 2007 年 iPhone 一代发布所引起的从功能机到智能机那样的重要变化。Apple 的商业模式不依赖于所谓 user engagement2,在隐私保护方面也有比较好的 track record,在几大巨头里或许是最适合推动这个历史进程的公司,结果应该会更符合大众利益。
不但视觉上和原生广告完全融合,而且首屏已经被广告占满。这个结果可以说是必然的,不做任何试验就能知道广告样式越接近于原生结果,点击率必然越高。之前做的种种实验无非是 Google 创立之初的价值观和与之矛盾的商业模式相纠结的漫长而耗资巨大的过程。
很多人都读过 Google 的两位创始人在创立公司之前写的 PageRank 论文,但很少人会看附录。这篇论文的附录 A 是 Advertising and Mixed Motives:
… The goals of the advertising business model do not always
correspond to providing quality search to users. … It is clear that a search
engine which was taking money for showing cellular phone ads would have
difficulty justifying the page that our system returned to its paying
advertisers. … we expect that advertising funded search engines will be
inherently biased towards the advertisers and away from the needs of the
consumers.
Since it is very difficult even for experts to evaluate search engines, search
engine bias is particularly insidious. … Furthermore, advertising income
often provides an incentive to provide poor quality search results. … This of
course erodes the advertising supported business model of the existing search
engines. … But we believe the issue of advertising causes enough mixed
incentives that it is crucial to have a competitive search engine that is
transparent and in the academic realm.
不难看出在刚有 Google 的时候两位创始人认为基于广告的商业模式与用户的利益和高质量的搜索结果是有根本冲突的。只是当时 Google 还不是一家公司,所以他们可以义正辞严地批评其他搜索引擎并说明 Google 做为一个无广告的、学术界的搜索引擎的重要性。他们似乎认为靠广告盈利和作为学术性的、非盈利的服务是一个搜索引擎的唯二选择。
第二是完善的家长监护功能。我小孩会花过多的时间看 YouTube 上的 Minecraft 视频,虽然我可以在 Screen Time 把 YouTube 禁用,他还是会用 Google 结果里的内嵌视频看。我买了 Kagi 的 family plan,设置好他的儿童账号,在 Kagi 把 YouTube 禁掉,再在 Screen Time 把 Google 禁掉就完美解决了这个问题。
第三是如果订阅 Kagi Ultimate,除了搜索外还可以使用 OpenAI、Anthropic、Google、Mistral AI 的所有语言模型,价格只相当于其中一个的订阅费用,是很划算的。
我一直很喜欢 Out of the Gobi1 的作者单伟建。他的三本书我都读过。他在文革时被流放到戈壁六年,失去了上中学的机会,但从没放弃学习。没有放弃对更好未来的追求。在文革结束后他抓住了机会到美国留学,在金融界取得了很高的成就,并创立了亚洲最大的私募基金集团 PAG。他在母校旧金山大学的一次演讲中说2,在任何领域取得成功,最重要的是三方面:
我最早接触计算机从 DOS 用起,直到后来的 Windows 3.0/3.1、Windows 95。我中学时看了 Bill Gates 的传记和他本人写的《the Road Ahead》,他的故事也是最早让我产生创业梦想的原因。Bill Gates 的成功除了自己的天分和努力外,也离不开他出生的时代和家庭背影。他 13 岁的时候就读的湖滨中学由家长集资购买了一台可以访问通用电气西雅图分部的 PDP-10 小型机的终端。当时微处理器、Atari、Intel 都还不存在,他学编程的时候全美国没有几个同龄人能接触到计算机。他父亲是成功的律师,当时已经在做天使投资,她母亲虽然从没全职在商业公司任职,但是因为家族是很成功的银行家,在很多公司的董事会里。他童年时每天家里晚餐的客人不是 CEO 就是议员。后来他母亲与 IBM 董事长的社交关系也帮助他得到了 IBM 的合同7,这是微软起飞最重要的一步。在那之后微软的快速成功也很仰赖于合作伙伴的局限性和竞争对手的失误。微软一开始的重心在程序设计语言上,唯一的产品是 BASIC 的解释器,对操作系统并不重视。在与 IBM 合作的初期,他们推荐 IBM 去找开发 CP/M 操作系统的 Digital Research 合作。而 Digital Research 的 CEO 因为未知原因没有见 IBM 派去的代表,所以双方没有达成合作,微软只能另想办法。当时有一家当地硬件公司 Seattle Computer Products 克隆了 CP/M 用来测试 Intel 8086 处理器,这个操作系统叫 QDOS8。微软向他们购买了 QDOS,并雇它的作者来基于 QDOS 开发了 MS-DOS,而从它开始的操作系统成了微软帝国的根基。可以说微软的成功是非凡的天赋、正确的策略、和令人难以置信的好运合力作用的结果。
大家向成功的人或公司学习的时候,往往会带着一种偶像情节,希望通过复制他们的所有特点和行为方式来复制成功。所以学 Steve Jobs 的 CEO 们往往先学到了他性格上的弱点,学阿里等企业的公司,往往先学会了一种畸形的企业文化,因为最流于表面、最没有深度的东西最容易学。成功当然是值得学习的,但是需要分辨不同因素起到的作用:有哪些是因为出现在正确的时间正确的地点,又具备了正确的条件,被时代的趋势所推动;有哪些是偶然事件;有哪些是主观作用。对主现因素,应该分清楚成功者是因此而成功,还是虽然如此但还是成功了。这样才知道该学的到底是什么。
不久前一个朋友说有个曾在 IBM 做过中层管理者的人建入群费 200 的微信群教人职场和生活方面的经验。很快就有几千粉丝入群,后来大概觉得价格定低了,又建了一个入群费一万的 VIP 群,马上就有大几十人报名。现在可以说是学习最容易、成本最低的时代。无论哪方面的信息在互联网上都唾手可得,而且大部分是免费的。当然,好的老师、课程、书籍是有价值的,因为虽然大部分信息都能免费找到,如果被组织成更体系化、更容易理解的形式,吸收起来就更快,也更容易让人得到启发。但是没有任何微信群是值一万进群费的。9
商业模式往往是以某种信息不对称为基础。互联网消除了很多信息上的不对称后,就有人人为制造出一种信息不对称的错觉和神秘感。卖成功学的人往往要用各种理论包装一番,因为如果看起来很简单就无法赚钱。成功的要点单伟建和 Charlie Munger 的几句话已经总结得很好,简单但不容易,如果能长期坚持就会比大多数人成功。
Google 的很多软件工程实践都在对外发布的各种 Tech Talk、CppCon 的演讲以及多本已出版的书里提到过(比如 Software Engineering at Google、Site Reliability Engineering 等),所以这篇文章的内容并不算新鲜事,只是贡献一些个人视角。另外我在 Google 工作已经是 10 多年前的事,现在可能已经变化很大,但我认为 2000~2010 年的时候是 Google 最有创造力、最高效、对人才的吸引力也最强的时候。
我在 Google 的三年是在一个叫 Google Web Server(简称 GWS)的团队。这个项目可以说是 Google 历史最悠久的项目,从 Google 存在开始就有 GWS,到现在 20 多年,Google 的 HTTP header 里 server 还是 GWS,应该还是同一个项目、同一个 code base 和 binary。
GWS in Google’s HTTP header
一开始的时候 Google Search 就是 GWS。后来从它里面拆出了一部分放到前面承担类似 SLB 的角色,叫 GFE(Google FrontendEnd);又把实现单纯搜索的部分拆了出来叫做 Superroot。GWS 更多地成为了一个实现搜索相关的整体业务逻辑的服务,它后面有 15~20 个后端服务,除了 Superroot 外,还有广告、拼写检查、搜索词修正、query rewrite、用户偏好等等。经过多年的演变,GWS 的开发语言也从 Python 变成了 C,再变成 C++,后来又为了方便快速做试验内嵌了 Python 解释器。在整个过程中,GWS 从来没被真正意义上重写过,因为 Google 一直都有大量的业务需求等着实现,不可能有停下来重写或者重构的机会。所有大的改变都必须以渐进的方式来实现,包括换语言。尽管只有 Google 一家公司在用,但是 2010 年的时候 GWS 就支撑了全球 13% 的活跃网站,是排在 Apache、Nginx、IIS 之后的第四大 web server,因为 Google host 的网站很多都是 GWS 来 serve 的,包括自定义域名的 custom search 以及 enterprise search。
因为这是我的第一份全职工作,其实在 Google 期间并没有觉得有多好,以为大公司都是这样的。但是离开之后才觉得,能有这段各团队之间能顺滑地高效协作的工作经历是很幸运的。这样的工作模式在大部分其他公司很难完全复制,因为它需要一些很强的基础设施做支持。以我们目前的工作模式,很难想象能达到同样的吞吐量,可能也很难复制同样的模式。但是分析一下别人做得好的地方还是能给我们提供一些方向上的参考,做一些努力能提高的空间还是很大的。下面我就介绍一下支撑 Google 团队间高效协作最重要的几个方面。
代码管理和安全
Google 的每个工程师都可以访问全公司 99.9% 的代码,这是决定 Google 的工作方式最根本的条件。剩下只有少数人能访问的那部分叫 HIP (High-value Intellectual Property),主要是防 SPAM 的逻辑。这部分代码如果泄露了,很快就会被恶意网站利用使得搜索质量显著下降,并且没有可以迅速补救的办法。其他所有项目的所有代码都是对所有工程师开放的。
很多人都会问,这样代码不会泄露吗?在那么大的公司可以肯定一定是会泄露的。2010 年前后有很多 Google 中国的人去百度,人民搜索(云壤)、盘古搜索也都是 Google 的人出来做的,要说没有知识产权外泄谁都不信。但是对公司而言,让自己跑得更快远比让竞争对手跑得慢一点更重要。所以大部分情况下保密措施应该是以不伤害效率为前提的。对用户数据的保密除外,但是保护用户数据的措施通常不会影响到大部分人的工作效率。
每个项目会有一个 Wiki 页面介绍怎么在本地运行和调试,通常来说是描述需要传递什么命令行参数来连接本服务依赖的线上或测试环境的其他服务。对于需要实际运行、进行人工验证的复杂改动,看了 Wiki 以后就能自己在本地跑一个实例,这类改动在 code review 时也通常会要求提供一个本地 demo 的地址。所以任何一个工程师都可以把 Google 的任何一个服务从源代码编译并运行起来。
自动化测试
GWS 作为一个 C++ 的项目,测试覆盖率保持在 90% 以上,这是非常不容易的。用静态语言的项目测试难度比动态语言大很多,因为对象的属性和方法无法动态替换,想要能在测试中 mock 掉 side effects 需要在设计上做更多的努力。自动化测试的好处相关的书上有很多,就不赘述了。我只说两点:第一,对自动化测试的要求确实可以产生更好的设计,比如鼓励面向接口的设计;第二,对于 Google 那样的协作模式来说,自动化测试不是一件锦上添花的事,而是必须。因为无论是去修改其他项目的信心,还是让其他人来修改自己的项目的信心,都来自于很高的测试覆盖率。
Google 在内部做版本管理的方式就是不做版本管理,所有项目都 live at head。当然,每个项目都有对公司外的版本发布流程,live at head 是对内依赖的策略。一般不会出现一个项目依赖一个组件的 1.1,而另一个项目依赖这个组件的 1.2 这样的情况。每个项目在每次编译的时候,都会把所有依赖从最新的代码编译,使用到的依赖的版本是由编译的时间点决定的。这自然就意味着每一次提交后的代码状态都应该作为稳定版本对待。
一般外部的开源项目,会分不同的版本号,由用户决定什么时候升级,并且由用户做升级所需要的改动。按照 2015 年的数据,Google 有 20 亿行代码,其中的依赖关系错综复杂。而 C++ 对于一个项目用到的两个组件依赖同一个组件的不同版本的场景(菱形依赖)支持是很脆弱的。所以不太可能使用 SemVer 之类的版本方案,除了纯技术上的问题外,每个组件要为内部用户维护多个版本也是成本巨大的。所以 Google 把版本管理完全倒了过来,每个项目/组件都只要维护一个最新版,所有的改动最重要的原则是不能破坏任何测试。所以如果有人在一个共享组件里做了向前不兼容的改动,就会需要在同一个 changelist 里把整个代码库里所有调用到这个接口的地方改过来。有的改动会动到十多个项目,需要十几个 owner 来 review,这并不少见。当然 Google 有强大的代码搜索工具来辅助这样的事。据几年后 Google 工程师在 CppCon 上的分享,他们还用 MapReduce 做了大规模重构工具,不过是在我离开之后了。
除了 binary push 外,还有 data push,也就是数据发布。数据包括 GWS 的配置文件、各种黑名单白名单、模版文件等。Data push 比较轻量,每天有多次,都是采用灰度发布到全球的方式。
以上这样 live at head 的方式意味着不太可能有长期存在的功能分支。如果一个工程师在独立功能分支上开发了几周,那基本上是不太可能合并回主线的。无论是多大的新功能,都会需要拆成很多小的 changelist,高频地提交到主线。只是未完成的功能会用一个 flag 屏蔽掉,在生产环境不会运行。所有用户可感知的改动都是用与试验一致的方式发布,从单个数据中心千分之一的流量开始灰度到全量。如果发现问题,只要做 data push 把 flag 的值改回来就行,因为老的 code path 已经在线上运行了很久,所以改回来一定没问题。这让发布很安全,大家也有信心做大胆的尝试。
关于项目管理和排期
排期这个词在 Google 其实很少出现,离开 Google 之后都在小创业公司就更不会出现。如果大部分事情都需要项管排期,一件很小的事情也可能被排到一两个月后,而这件小事可能 block 了很多其他工作。把一个工程师的时间按开发任务线性地排列,完全做完一件事再开始做另一件事,也并不是高效的方式。工程师确实是需要专注的、避免多任务切换的时间,但这样的时间应该是以小时计,而不是以天或周计的。一个工程师应该把任务分割成尽可能小的单元,写完代码和测试后及时提交给别人 review,并且也需要 review 其他人的 merge request。从天和周的维度看,本来就是需要在多件事情之间切换的。
在 Google 的三年多里,我们团队的 project manager 对于工程师来说存在感一直比较低,项管不会过多干预个人的工作计划。每个工程师都相当于自己的项管,工程师之间会互相就优先级进行沟通达成共识和妥协。这样的好处是工作量小但 block 了其他人的事情会被快速完成;实际做事情的人用专业的语言沟通,不需第三者传话,也不容易造成误解;一些重要但不紧急的事情,比如重构、还技术债,也可以由工程师在日常工作中穿插地推进。我无法想象在 Google 当时的团队能按集中排期来安排工作。过去十多年里,硅谷比较成功的互联网公司都是用与 Google 相似的方式来工作的,这不是偶然现象。网状的沟通协作与传统的树状比,表面可能感觉混乱,但是因为不容易形成瓶颈、沟通中信息损耗少,效率是很高的。
我们能先从哪些事做起
Google 的人喜欢说 Google 的工程实践是为连续运行十年以上的软件设计的。10 年不是很长时间,已经基本站稳脚跟的公司需要探索在开发协作上更 scalable 的方式。我们不太可能去复制 Google 的所有东西,Google 的方式也未必放在所有公司都是适用的,但是有一些方向性的结论在整个业界是得到了共识的,我们也应该朝那个方向去努力。以下是我们可以在公司推动改进的一些方向。
在工程师团队里培养测试文化
在这个年代写完代码就交给 QA 去测试,靠人工来保证质量,是很落后的方式,因为它不能 scale。人工的测试做十次就是十倍的成本,哪怕每次内容都一样。自动化测试是所有人都知道好,很少人实际做,更少人能做好的事。Google 也不是从一开始就把测试做得很好,而是由一小群人努力地在全公司推动起来。最可见的一件事是 Testing on the Toilet,内部简称 TotT。他们在全球办公室的几百个马桶前都装上了这样的海报,这样大家在上厕所的同时还能学习如何写测试。久而久之,重视的人越来越多,开始在 code review 中执行测试覆盖率的要求,大部分的项目都逐步建立起高质量的测试。
最近难过地得知 Stan Eisenstat 教授在 12 月 17 日去世,我在 2017 年回学校时还去找他聊了会儿天。这也让我想起几年前去世的 Paul Hudak。这两位教授虽然不是我正式的导师,但都对我影响很大,所以就想写一写我对他们的记忆。
Stan Eisenstat
我在去耶鲁上学之前就在 Joel Spolsky 的 Joel on Software 里读到过 Stan Eisenstat。他教的 CS323: Systems Programming and Computer Organization 在学生中是一门传奇性的课程。选课的人往往在那个学期会需要花大量时间熬夜甚至通宵来完成他布置的几个大作业,而在课程完成后都会觉得收获很多。进入耶鲁后我抓住机会申请做了这门课的助教。当年(1998 - 2002)我在国内接受的计算机科学本科教育说实话和美国好的大学比还有很大差距,直到后来国内大学有越来越多留学回来的人加入,这个差距才缩小,所以其实读博期间还要弥补一些知识面上的裂缝。给本科生课程做助教对于提升自己也是非常有益的。他在一个学期里会让学生完成几个大作业:实现一个 UNIX shell,一个 LZW 文件压缩/解压程序,重新实现 make 等等。每个项目 Stan 都会准备好一套测试,学生提交完后他跑一遍测试就能马上得出正确性的得分。他也准备了详尽的代码风格文档,所有的作业和考试都有正确性和风格两部分分数。到期末他会让助教自己设计一个期末项目给学生作为期末考,助教也要负责给这个项目写一套自动化测试来给学生提交的代码打分。所以每一届学生遇到的期末项目都不同,而每个助教也有自己的发挥空间,参与这个过程的每个人都很有收获。我现在还记得给学生出的题目是做一个支持用 telnet 登录的多线程 BBS 服务器,我写了一个 telnet 机器人来测试他们实现的各项功能。Stan 在耶鲁计算机科学系将近 50 年,这门课和他教的 CS223: Data Structures and Programming Techniques 一直都是计科系的核心编程课,无数学生在 Zoo(系里的机房)耗费了无数夜晚来完成这两门课的作业。
Paul Hudak
我对 Paul Hudak 也是在去耶鲁前就有很多了解。我本科的毕业设计是函数式语言的课题,所以找了一些 Haskell 的资料看。Paul 是 Haskell 的主要设计者,当时他正好出了一本新书。那时市面上还几乎没有正式出版的 Haskell 的书,国内更是完全没有。我给他发邮件问问题时提了一句很遗憾在中国买不到他的书。过了两周多就收到了他给我寄过来的书。后来进了耶鲁我选了另一位教授开的 functional programming 课,因为这方面基础薄弱学得比较差。后来 Paul 教这门课时我又去报名做助教,相当于自己也又学了一遍。虽然后来我没有选择在程序语言方面深入下去,但因为他的原因一直保持着对这个领域的兴趣和关注,所以当 Clojure 这样更具实用性的函数式语言出现时我很早接触并应用到实践中,后来创业时也选择它作为主要开发语言,使团队能在早期很高效地开发出产品。
Paul Hudak’s book
耶鲁的计科系格外地重视教育。这句话听起来似乎有点奇怪,所有的大学都应该是重视教育的,但其实各个学校在研究和教学上的投入还是很不一样的。很多地方的教授更愿意把时间投入到研究上,多发几篇论文,而教学更多地是必须完成的义务和负担。耶鲁的很多教授,包括 Paul、 Stan、Stan 的妻子 Dana Angluin(也是同系教授)、我导师 Mike Fischer 都对教学有一种很纯粹的热爱,他们年复一年地打磨同一门课程,不吝惜花大量的时间做到尽善尽美,把培养出的学生看作最重要的遗产。我在 Yale Daily News 上看到,Stan 对学生的爱持续到了生命最后一刻,他要求等期末考结束再宣布他去世的消息,所以他离世后系里还不知道,第二天在 Zoom 上的虚拟节日聚会里大家还录制了一些祝他早日康复的消息。
from fastai2.vision.utils import download_images
from pathlib import Path
object_types ='woman','man','camera', 'TV'path = Path('objects')
ifnot path.exists():
path.mkdir()
for o in object_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing(key, o)
download_images(dest, urls=results.attrgot('content_url'))
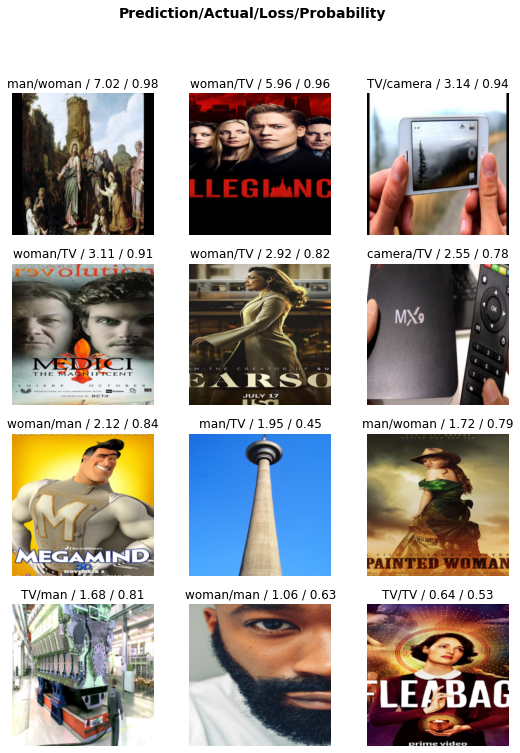
接下来终于可以开始训练了。对于图像识别这样的应用场景来说,往往不会从零开始训练一个新的模型,因为有大量的特征是几乎所有应用都需要识别的,比如物体的边缘、阴影、不同颜色形成的模式等。通常的做法是以一个预先训练好的模型为基础(比如这里的 resnet18),用自己的新数据对最后几层进行训练(术语为 fine tune)。在一个多层的神经网络里,越靠前(靠近输入)的层负责识别的特征越具体,而越靠后的层识别的特征越抽象、越接近目的。下面的最后一行代码指训练 4 轮(epoch)。
如果你有 Nvidia 的显卡,在 Linux 下,并且安装了合适的驱动程序的话,下面的代码只需要几秒到十几秒,否则的话就要等待几分钟了。
from fastai2.vision.learner import cnn_learner
from torchvision.models.resnet import resnet18
from fastai2.metrics import error_rate
import fastai2.vision.all as fa_vision
learner = cnn_learner(dls, resnet18, metrics=error_rate)
learner.fine_tune(4)
epoch
train_loss
valid_loss
error_rate
time
0
1.928001
0.602853
0.163793
01:16
epoch
train_loss
valid_loss
error_rate
time
0
0.550757
0.411835
0.120690
01:42
1
0.463925
0.363945
0.103448
01:46
2
0.372551
0.336122
0.094828
01:44
3
0.314597
0.321349
0.094828
01:44
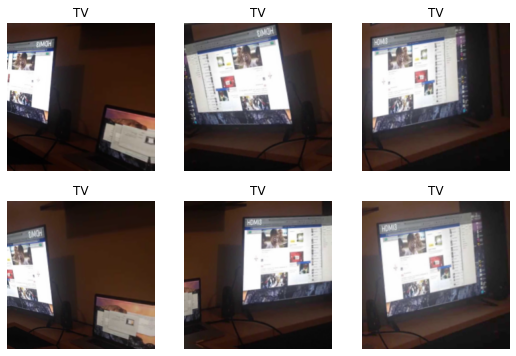
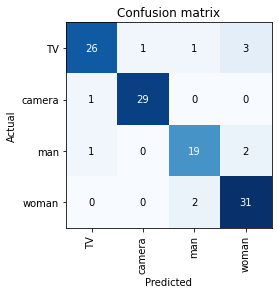
最后输出的表格里是每一轮里训练集的 loss,验证集的 loss,以及错误率(error rate)。错误率是我们关心的指标,而 loss 是控制训练过程的指标(训练的目标就是让 loss 越来越接近于 0)。需要这两个不同的指标是因为 loss 要满足一些错误率不一定满足的条件,比如对所有参数可导,而错误率不是一个连续函数。loss 越低错误率也越低,但他们之间没有线性关系。这里错误率有差不多 10%,也就是准确率是 90% 左右。













{kind=link}