Promise.race([promise1, promise2]) .then((value) => { console.log("succeeded with value:", value); }) .catch((reason) => { // Only promise1 is fulfilled, but promise2 is faster console.error("failed with reason:", reason); }); // failed with reason: two
在服务器端编程,我们经常遇到需要批量处理数据的场景。例如,批量修改数据库中的用户数据。在这种情况下,由于数据库操作的性能限制或者 API 调用限制,我们不能直接一口气修改全部,因为短时间内发出太多的请求数据库也会处理不来导致应用性能下降。因此,我们需要一种方法来限制同时进行的操作任务数,以保证程序的效率和稳定性。
// 分割任务数组为批次 functionsplitIntoBatches(tasks, batchSize) { let batches = []; for (let i = 0; i < tasks.length; i += batchSize) { batches.push(tasks.slice(i, i + batchSize)); } return batches; }
接着就可以在命令行直接使用 mysql 了。输入 mysql -u root -p 登录 mysql,密码是在安装阶段时设置的密码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
➜ ~ mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 13 Server version: 8.0.29 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h'forhelp. Type '\c' to clear the current input statement.
mysql>
数据库操作
DATABASE 可以不区分大小写,但只能要么全小写,要么全大写。一般会将这些参数用大写写出。
创建数据库
1 2 3
-- 还可以通过 DEFAULT CHARACTER SET 选项设置默认的编码集 mysql>CREATE DATABASE DANNY_DATABASE; Query OK, 1row affected (0.01 sec)
当用户执行订阅事件 on 时,回调函数会被添加到相应事件名称的数组中。这样,同一个事件可以被不同组件或模块订阅,而每个订阅者的回调函数都会被正确地保存在事件队列中。最后,当触发事件 emit 时,事件队列中的每个回调函数都会被执行,实现了事件的触发和通知功能。若已经没有订阅需求,则可以通过 off 移除已经订阅的事件。
javascript:(function(){var filterStrings=["tag seen","Stray end tag","Bad start tag","violates nesting rules","Duplicate ID","Unclosed element","not allowed as child of element","unclosed elements","unquoted attribute value","Duplicate attribute","descendant of an element with the attribute"],filterRE=filterStrings.join("|"),i,nT=0,nP1=0,result,resultText,results,resultsP1={},root=document.getElementById("results");if(!root){return}results=root.getElementsByTagName("li");for(i=results.length-1;i>=0;i--){result=results[i];if(result.id.substr(0,3)==="vnu"){if(result.className!=="info"){nT=nT+1}resultText=""+result.textContent;resultText=resultText.substring(0,resultText.indexOf("."));if(resultText.match(filterRE)==null){result.style.display="none";result.className=result.className+"a11y-ignore"}else{resultsP1[resultText.substr(7)]=true;nP1=nP1+1}}}resultText="";for(i in resultsP1){if(resultsP1.hasOwnProperty(i)){resultText=i+"; "+resultText}}var str=nT+" validation errors and warnings.\n"+nP1+" errors that may impact accessibility:\n"+resultText;console.log("%c[WCAG Parsing Validation Filter bookmarklet@v4]:\n","font-weight: bold","https://labs.diginclusion.com/tools/bookmarklets/wcag-parsing-filter/\n\n"+str);alert(str)})();
91 validation errors and warnings. 6 errors that may impact accessibility: Element a not allowed as child of element ul in this context; Element object not allowed as child of element ul in this context; Element style not allowed as child of element body in this context;
// Usage functionApp() { // Similar to useState but first arg is key to the value in local storage. const [name, setName] = useLocalStorage('name', 'Bob');
// Hook functionuseLocalStorage(key, initialValue) { // State to store our value // Pass initial state function to useState so logic is only executed once const [storedValue, setStoredValue] = useState(() => { try { // Get from local storage by key const item = window.localStorage.getItem(key); // Parse stored json or if none return initialValue return item ? JSON.parse(item) : initialValue; } catch (error) { // If error also return initialValue console.log(error); return initialValue; } });
// Return a wrapped version of useState's setter function that ... // ... persists the new value to localStorage. const setValue = value => { try { // Allow value to be a function so we have same API as useState const valueToStore = value instanceofFunction ? value(storedValue) : value; // Save state setStoredValue(valueToStore); // Save to local storage window.localStorage.setItem(key, JSON.stringify(valueToStore)); } catch (error) { // A more advanced implementation would handle the error case console.log(error); } };
return [storedValue, setValue]; }
注意: 自定义 Hook 函数在定义时,也可以使用另一个自定义 Hook 函数。
Hook 使用约束
只能在函数组件最顶层调用 Hook,不能在循环、条件判断或子函数中调用。
只能在函数组件或者是自定义 Hook 函数中调用,普通的 js 函数不能使用。
class 组件与 Hook 之间的映射与转换
函数组件相比 class 组件会缺少很多功能,但大多可以通过 Hook 的方式来实现。
生命周期
constructor:class 组件的构造函数一般是用于初始化 state 数据或是给事件绑定 this 指向的。函数组件内没有 this 指向的问题,因此可以忽略。而 state 可以通过 useState/useReducer 来实现。
经过排查,本次发生错误是由 hexo-related-popular-posts 引发,在该库源码中使用 moment 初始化 list.date 导致了错误。 list.date 通过打印值可以看到是一个 moment 对象,但这个 moment 对象并不规范或者说可能在某处修改了这个 moment 对象的值。
值得注意的是,Travis CI 提倡每次 commit 都是独立较小的改动,而不是突然提交一大堆代码。因为这有助于后续构建失败时可以回退到正常的版本。
运行构建时,Travis CI 将 GitHub 存储库克隆到全新的虚拟环境中,并执行一系列任务来构建和测试代码。如果这些任务中的一项或多项失败,则将构建视为已损坏。如果所有任务均未失败,则认为构建已通过,Travis CI 会将代码部署到 Web 服务器或应用程序主机中(在本文中是指 Github Pages 服务)。
准备
在使用之前,需要准备一个 Github 的账号对 Travis CI 进行授权。
接着通过 Github 的账号登录 Travis CI,点击 SIGN IN WITH GITHUB。
Travis CI 有两个不同域名版本的 API,一个是 .com 新版本,.org 是旧版本的。先确定自己使用的是哪个平台,再设定它:
1 2 3 4 5 6 7
# 默认是 .org travis endpoint # API endpoint: https://api.travis-ci.org/
# 笔者使用的是 .com 的平台,因此需要修改默认的模式。设置 `--com` 和 `--pro` 的效果是相等的。 travis endpoint --com --set-default # API endpoint: https://api.travis-ci.com/ (stored as default)
确定版本后输入 travis login 或 travis login --pro 进行登录。Mac os 系统可能会遇到 Travis Ci CLI 依赖的 ruby 版本和系统自带 ruby 有冲突:
1 2 3 4 5 6 7 8 9 10 11
travis login --com # We need your GitHub login to identify you. # This information will not be sent to Travis CI, only to api.github.com. # The password will not be displayed.
# Try running with --github-token or --auto if you don't want to enter your password anyway.
# Username: anran758 # Password for anran758: *********** # Unknown error #for a full error report, run travis report --pro
若不想处理这些麻烦的依赖问题,可以在 Travis CI 的个人设置页 复制 access_token 到 ~/.travis/config.yml 的配置中:
travis accounts --pro # travis accounts --pro # anran758 (Anran758): not subscribed, 18 repositories # To set up a subscription, please visit travis-ci.com.
WARNING in configuration The 'mode' option has not been set, webpack will fallback to 'production' for this value. Set 'mode' option to 'development' or 'production' to enable defaults for each environment. You can also set it to 'none' to disable any default behavior. Learn more: https://webpack.js.org/configuration/mode/
由于我们输出的文件名被修改了,此时还得修改 html 的引入路径。但每改一次输出目录,HTML 中的引入路径也得跟着改,这样替换的话就比较容易出纰漏。那能不能让 webpack 自动帮我们插入资源呢?答案是可以的。
WARNING in configuration The 'mode' option has not been set, webpack will fallback to 'production' for this value. Set 'mode' option to 'development' or 'production' to enable defaults for each environment. You can also set it to 'none' to disable any default behavior. Learn more: https://webpack.js.org/configuration/mode/ Child HtmlWebpackCompiler: 1 asset Entrypoint HtmlWebpackPlugin_0 = __child-HtmlWebpackPlugin_0 1 module
WARNING in configuration The 'mode' option has not been set, webpack will fallback to 'production' for this value. Set 'mode' option to 'development' or 'production' to enable defaults for each environment. You can also set it to 'none' to disable any default behavior. Learn more: https://webpack.js.org/configuration/mode/
WARNING in asset size limit: The following asset(s) exceed the recommended size limit (244 KiB). This can impact web performance. Assets: img/04.b7d3aa38.png (368 KiB) img/05.875a8bc2.png (499 KiB) img/02.46713ed3.png (744 KiB) img/03.70b4bb75.jpg (529 KiB)
WARNING in webpack performance recommendations: You can limit the size of your bundles by using import() or require.ensure to lazy load some parts of your application. For more info visit https://webpack.js.org/guides/code-splitting/ Child HtmlWebpackCompiler: 1 asset Entrypoint HtmlWebpackPlugin_0 = __child-HtmlWebpackPlugin_0 [0] ./node_modules/html-webpack-plugin/lib/loader.js!./src/index.html 1.01 KiB {0} [built] Child mini-css-extract-plugin node_modules/css-loader/dist/cjs.js!src/css/style.css: Entrypoint mini-css-extract-plugin = * [0] ./node_modules/css-loader/dist/cjs.js!./src/css/style.css 3.09 KiB {0} [built] [3] ./src/images/01.jpg 63 bytes {0} [built] [4] ./src/images/02.png 63 bytes {0} [built] [5] ./src/images/03.jpg 63 bytes {0} [built] [6] ./src/images/04.png 63 bytes {0} [built] [7] ./src/images/05.png 63 bytes {0} [built] + 2 hidden modules
WARNING in configuration The 'mode' option has not been set, webpack will fallback to 'production' for this value. Set 'mode' option to 'development' or 'production' to enable defaults for each environment. You can also set it to 'none' to disable any default behavior. Learn more: https://webpack.js.org/configuration/mode/
WARNING in asset size limit: The following asset(s) exceed the recommended size limit (244 KiB). This can impact web performance. Assets: img/04.b7d3aa38.png (368 KiB) img/03.70b4bb75.jpg (529 KiB) img/05.875a8bc2.png (499 KiB) img/02.46713ed3.png (744 KiB) img/06.5b8e9d1e.jpg (742 KiB)
WARNING in webpack performance recommendations: You can limit the size of your bundles by using import() or require.ensure to lazy load some parts of your application. For more info visit https://webpack.js.org/guides/code-splitting/ Child HtmlWebpackCompiler: 1 asset Entrypoint HtmlWebpackPlugin_0 = __child-HtmlWebpackPlugin_0 [0] ./node_modules/html-webpack-plugin/lib/loader.js!./src/index.html 1.37 KiB {0} [built] Child mini-css-extract-plugin node_modules/css-loader/dist/cjs.js!src/css/style.css: Entrypoint mini-css-extract-plugin = * [0] ./node_modules/css-loader/dist/cjs.js!./src/css/style.css 2.98 KiB {0} [built] [3] ./src/images/01.jpg 63 bytes {0} [built] [4] ./src/images/02.png 63 bytes {0} [built] [5] ./src/images/03.jpg 63 bytes {0} [built] [6] ./src/images/04.png 63 bytes {0} [built] [7] ./src/images/05.png 63 bytes {0} [built] + 2 hidden modules
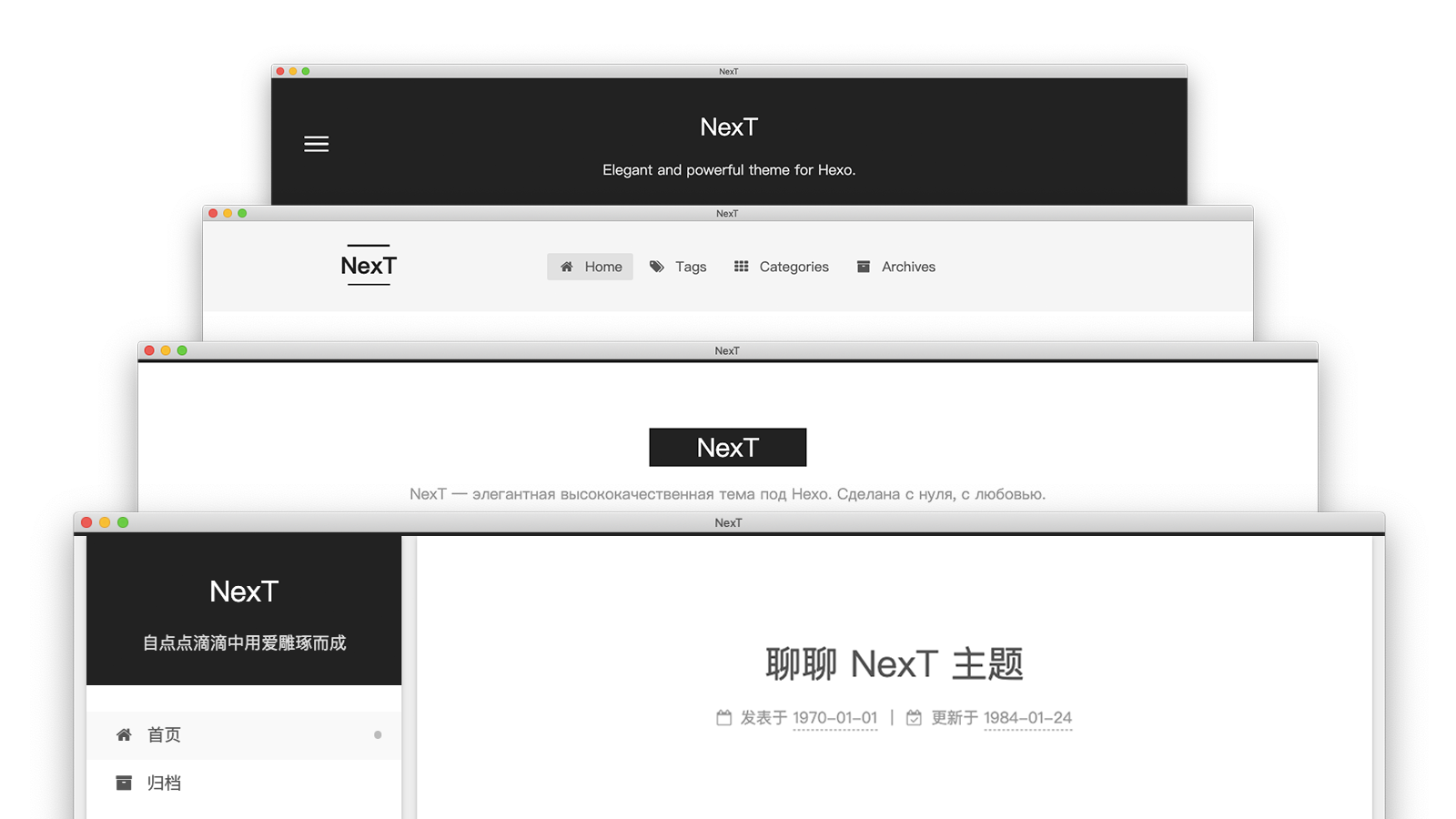
# 言下之意就是将该库克隆到 themes 目录下的 next 文件夹中 git clone https://github.com/theme-next/hexo-theme-next themes/next
在 Next theme 7.0+ 版本中,主题嵌入了检查版本更新的代码,每当运行本地服务器时,都会进行检查版本号的更新。当有新的版本发布时会在命令行输出警告:
1 2 3
WARN Your theme NexT is outdated. Current version: v7.4.2, latest version: v7.5.0 WARN Visit https://github.com/theme-next/hexo-theme-next/releases for more information.
这时你想体验 Next 的新特性的话可能会有点麻烦,因为原先我们在旧版本上修改了配置,或添加了一些自定义的布局。这将会造成代码冲突。






















 注意要妥善保管好 token,重新刷新页面后这个 token 将不会再展示出来。如果忘记了 token 的话,也只能在 token 编辑页中重新生成。这会导致所有用到该 token 的应用都要更新值。 比方说有三个应用使用了该 token,重新生成后只在一个应用更新的值,那其他两个应用不更新就无法使用了。
注意要妥善保管好 token,重新刷新页面后这个 token 将不会再展示出来。如果忘记了 token 的话,也只能在 token 编辑页中重新生成。这会导致所有用到该 token 的应用都要更新值。 比方说有三个应用使用了该 token,重新生成后只在一个应用更新的值,那其他两个应用不更新就无法使用了。 













")