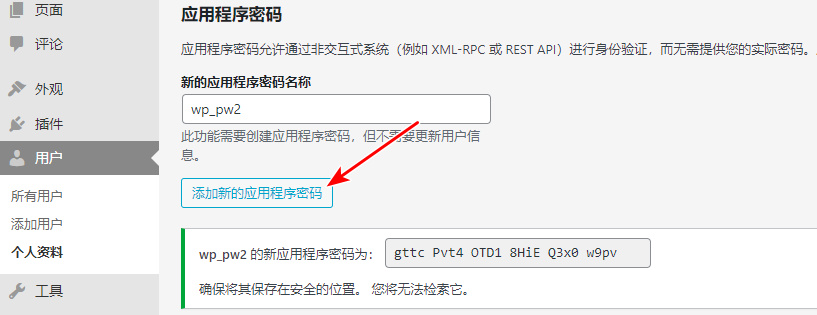
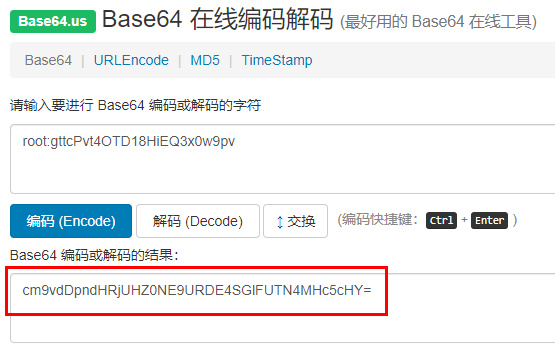
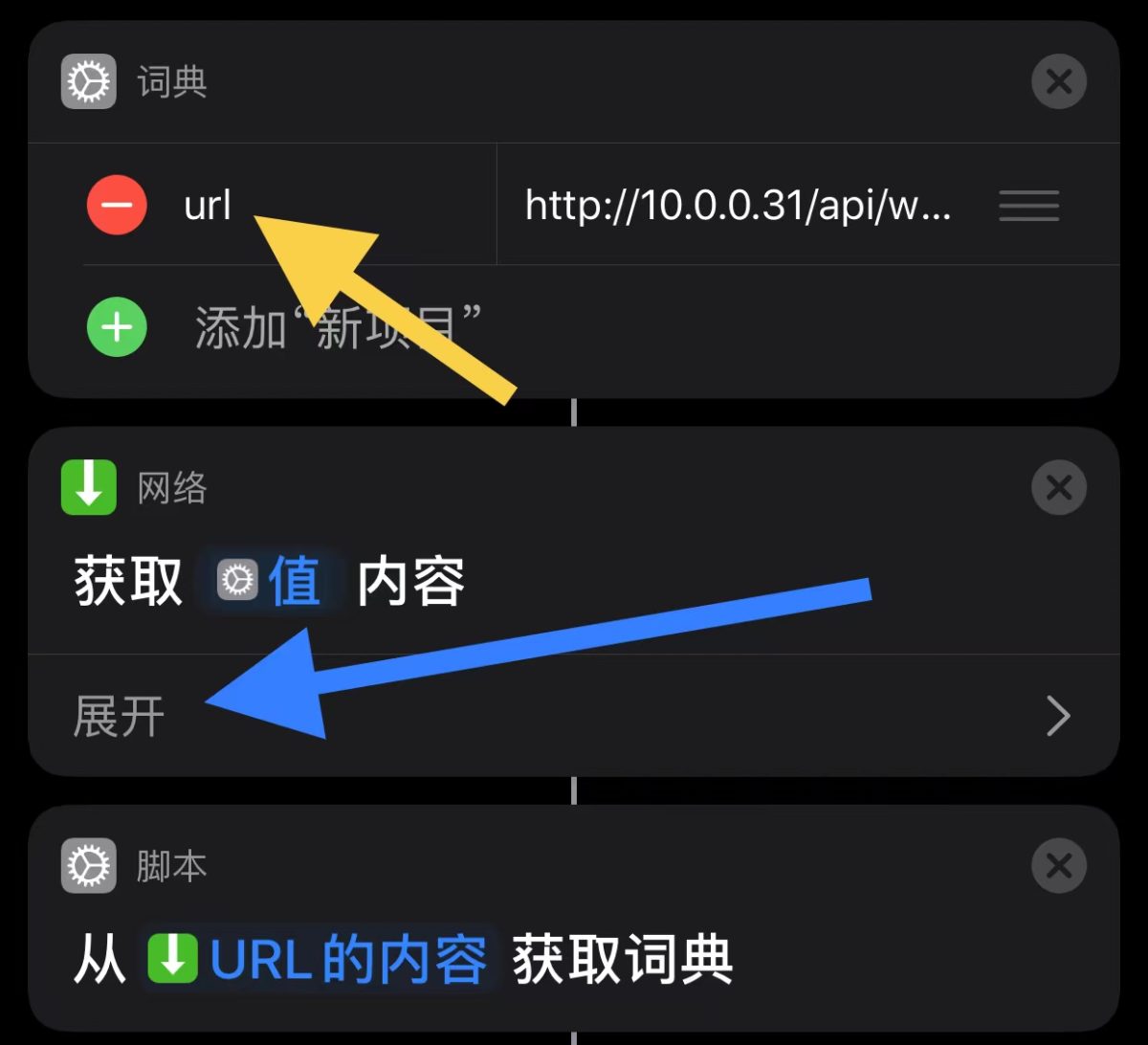
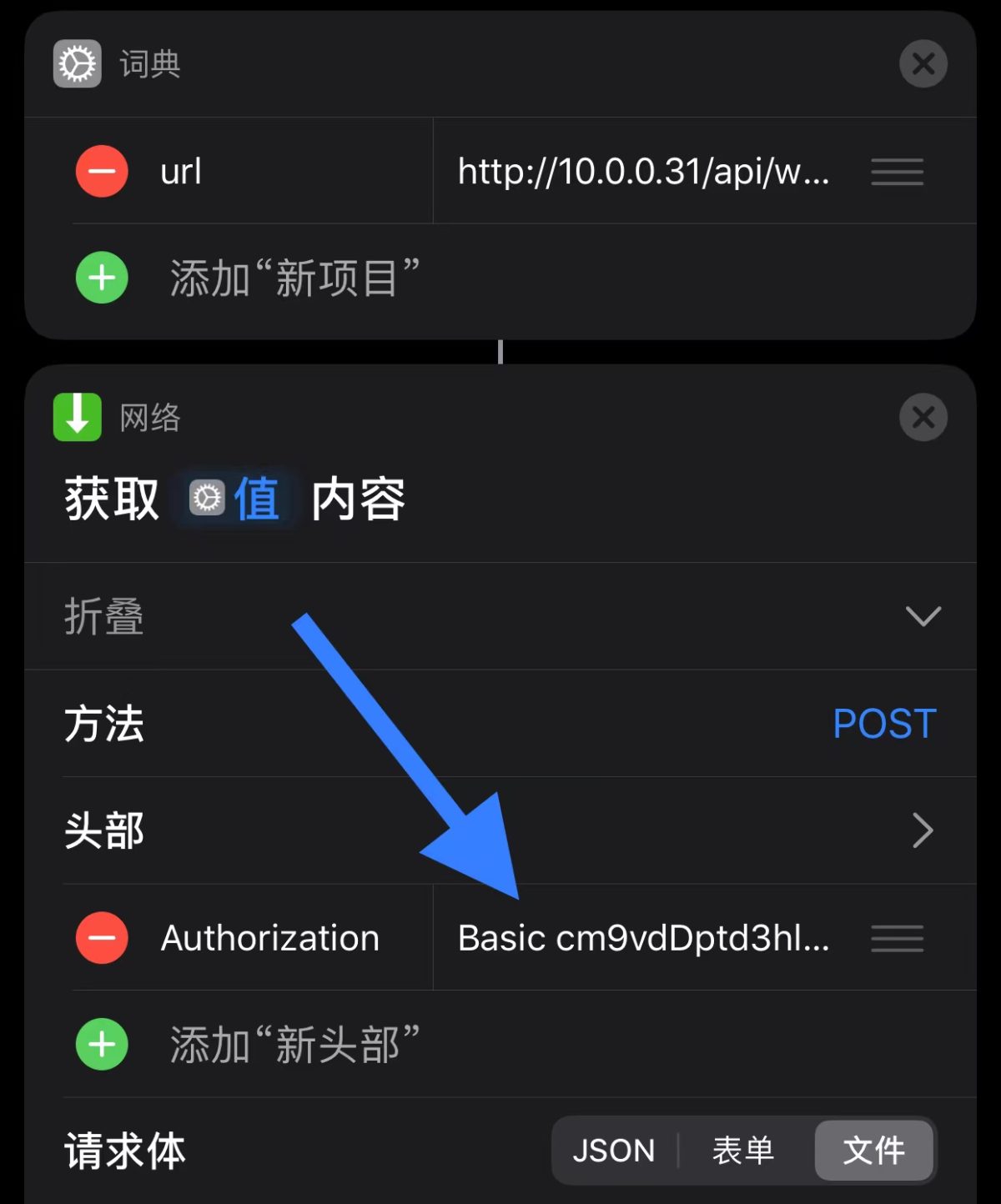
crosstab 是 postgresql 的 tablefunc 扩展模块所提供的函数之一,tablefunc 提供了多个返回多行数据的函数,crosstab 便是其一,crosstab 提供了一种将多行数据转换成一行数据的能力,可以简单地理解为行转列。postgresql 帮助文档上都有对 crosstab 函数的详细介绍,不过使用的例子比较抽象,再加上粗陋的翻译质量可能让人不是很好理解,在此总结一下 crosstab 这个函数,并提供一个手册上没有的实用技巧(见本篇后半部的《双参数的 crosstab 示例2》)。
安装 tablefunc 模块
默认情况下 tablefunc 模块是未安装的,需要手动执行下方命令安装,重复执行会提示该扩展已创建:
CREATE EXTENSION tablefunc;
创建示例表
创建示例表:
CREATE table prod_attr
(
prod_name VARCHAR(20), -- 产品名称
attr_name VARCHAR(40), -- 属性名称
attr_val NUMERIC(15, 2), -- 属性值
attr_val_desc VARCHAR(20) -- 属性单位
);
写入示例数据:
insert into prod_attr(prod_name, attr_name, attr_val, attr_val_desc)
VALUES
('农夫山泉','库存数量', 100, '瓶'),
('农夫山泉','规格', 500, '毫升'),
('农夫山泉','单价', 2.00, '元'),
('雪碧','规格', 200, '毫升'),
('雪碧','单价', 1.80, '元'),
('雪碧','折后价', 1.60, '元'),
('手工面包','库存数量', 10, '盒'),
('手工面包','规格', 300, '克'),
('手工面包','单价', 12.00, '元'),
('手工面包','保质期', 7, '天');
执行查询:
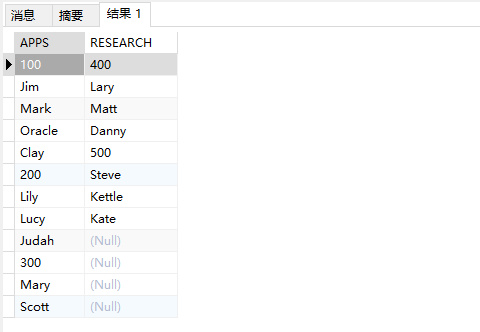
select * from prod_attr;
下图是表里的原始数据:

在进一步介绍上述语句前先介绍下示例表和示例表中的数据:
示例表有四个字段,前三个字段分别是产品名称(prod_name),属性名称(attr_name)和属性值(attr_val),第四个字段(attr_val_desc)在这里并未实际使用,仅出于方便理解的目的作为对第三个字段的解释。
通过插入的实际值能够看出这是一个记录产品常见属性的表,如规格、价格、库存数量、保质期,每一个这样的产品属性占据一行,即同一个产品有几个属性就有几行数据在表里。
这里我们使用 crosstab 的最终目的就是要把分散在每一行的这些产品属性置于同一行来显示,以便用户使用,可以简单地把这种行为理解为行转列。
crosstab 第一个参数的约束限制
上述语句中的 crosstab 只有一个字符串参数,这个字符串参数必须是一个合法的 sql 查询,它的作用是从数据表中找出来需要转换处理的目标数据,这个查询需要满足以下几个条件:
- select 字段:必须具有顺序固定的三个字段列,第一列是名称(示例是产品名称 prod_name),第二列是属性名称(示例是属性名称 atrr_name),第三列是属性值(示例是属性值 attr_val);
- order by 字句:order by 子句的作用是给 select 子句的前两个字段(prod_name、atrr_name)排序,顺序必须是第一个字段在前、第二个字段在后,order by 不能省略且字段顺序一定要处理好,否则执行结果会有问题;
定义 crosstab 的返回字段和数据类型
同时,由于 crosstab 函数定义的返回类型为 record 即多行记录,需要在 crosstab 的 from 子句中为 crosstab 定义返回的字段及数据类型,这里的字段顺序是固定的,第一个字段名及其数据类型同 select 子句的第一个字段(prod_name),后续字段可以根据实际需要(一般是需要显示几个属性就定义几个)自行定义,但是它们的数据类型必备与 select 子句的第三个字段(attr_val)相同。
至此,上述 crosstab 的使用就清楚了,如果你不想看上述繁琐的文字叙述,看一下接下来的图片即明白这个函数的作用了。
一个参数的 crosstab 示例
注意参数中的 sql 里加了 where 条件限制,移除 where 后执行查询你会发现这里有一个问题
select
prod_name,attr_a as "规格",attr_b as "库存数量",attr_c as "单价", attr_d as "保质期"
from crosstab(
'select prod_name, attr_name, attr_val
from prod_attr t1
where t1.prod_name in (''农夫山泉'', ''手工面包'') -- 条件过滤
order by prod_name, attr_name desc'
) as cte(prod_name VARCHAR, attr_a NUMERIC, attr_b NUMERIC, attr_c NUMERIC, attr_d NUMERIC)
这是通过 crosstab 转换后的数据:
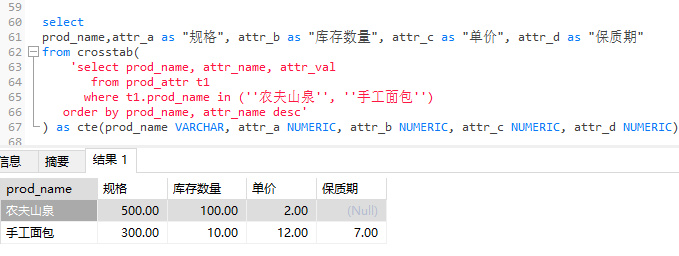
是不是很简单,这里的前提是建立在每个商品属性一致的(即有都有同样的属性,即便其值有所不同值)假设前提下,使用者需要做的是通过第一个参数 sql 中的 order by 保证每个产品名称(prod_name)的属性字段(atrr_name)的顺序一致。当商品的属性不一致时上述语句就会有问题,这也是接下来要描述的双参数的 crosstab 要解决的问题。
两个参数的 crosstab
双参数的 crosstab 与一个参数的 crosstab 作用是相同的,区别是对属性字段的处理上更加灵活。
双参数 crosstab 的第一个参数
双参数 crosstab 的第一个参数与单参数 crosstab 的第一个参数是一样的,也是一个 sql 查询,特别之处是
- 在第一列(商品名称(prod_name))后方可以出现可选的一个或多个额外字段列(extra columns);与单参数一样,属性名称(示例是属性名称 atrr_name)和属性值(示例是属性值 attr_val)这两个字段始终要保证在倒数第二和倒数第一的位置上;
- order by 仍然要做排序,区别是只需要对第一列商品名称(prod_name)进行排序了。
双参数 crosstab 的第二个参数
它的第二个参数也是一个 sql 语句它的作用是指定需要显示的属性名称的列表,即在这里指定那些你希望在最后的结果出现的属性列,且要满足如下条件:
第二个参数的查询结果只能有一个字段,且不能存在重复行,否则会报错,即你要在第二个参数的 select 子句里预防性地加一个 distinct;
注意顺序,与返回字段配合好,关于顺利这里还有另一个技巧可以让你显示地指定这些字段和它们出现的顺序,下面会介绍。
定义 crosstab 的返回字段和数据类型
要求同单参数,不再赘述。
双参数的 crosstab 示例1
还是以上述的示例表中的数据为例,加入第二个参数,通过第二个参数里的 sql 查询指定属性名称(atrr_name)及其排序顺序。
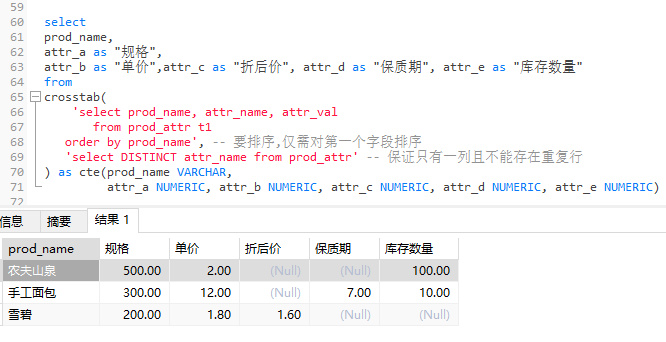
select
prod_name,
attr_a as "规格",
attr_b as "单价",attr_c as "折后价", attr_d as "保质期", attr_e as "库存数量"
from
crosstab(
'select prod_name, attr_name, attr_val
from prod_attr t1
order by prod_name', -- 要排序,仅需对第一个字段排序
'select DISTINCT attr_name from prod_attr' -- 保证只有一列且不能存在重复行
) as cte(prod_name VARCHAR,
attr_a NUMERIC, attr_b NUMERIC, attr_c NUMERIC, attr_d NUMERIC, attr_e NUMERIC)
执行结果如下图:
双参数的 crosstab 示例2(强烈推荐)
通过第二个参数显示指定属性名称字段及其顺序。
select
prod_name, attr_a as "保质期", attr_b as "规格",attr_c as "单价",attr_d as "折后价"
from
crosstab(
'select prod_name, attr_name, attr_val
from prod_attr t1
order by prod_name', -- 排序仍然要, 仅需对第一个字段排序
'VALUES (''保质期''), (''规格''), (''单价''), (''折后价'')' -- 显示指定attr_name值和排序
) as cte(prod_name VARCHAR, attr_a NUMERIC, attr_b NUMERIC, attr_c NUMERIC, attr_d NUMERIC)
执行结果如下图:

参考:http://postgres.cn/docs/12/tablefunc.html