装修了半年多,两个月前正式入住,可以开始好好折腾智能家居了。现在用的一些方案和之前写的智能家居之计划篇差了不少,于是有了这篇博客聊聊现在的设计。这里直入主题,之前的计划篇里有更多的背景介绍。
服务器
我用了一台几年前的联想笔记本做服务器,装了个 Debian。这篇文章提到的大多数应用其实在树莓派上都能跑,Home Assistant 还专门给树莓派优化做了一个集成包叫 Hass.io 。下面主要讲软件部分。
中控系统
一开始用的是 SmartThings,尝试了 Home Assistant 之后就决定改用它了。HA 相对于 ST 有不少优势,首先 ST 的大部分需要联网才能工作,增加了额外的不稳定因素和延迟;同时 HA 是开源的 Python 项目,可定制性比 ST 高很多,例如可以把所有状态变化记录到第三方数据库,支持 FloorPlan 等强大的插件。
HA 本身只是个软件,并不直接支持 Z-Wave 和 Zigbee 等协议。我选了 Aeotec Z-Stick Gen5 用来接收 Z-Wave 的信号,家里 Zigbee 的设备不多,需要的时候也可以用 ST 通过 MQTT 传给 HA。
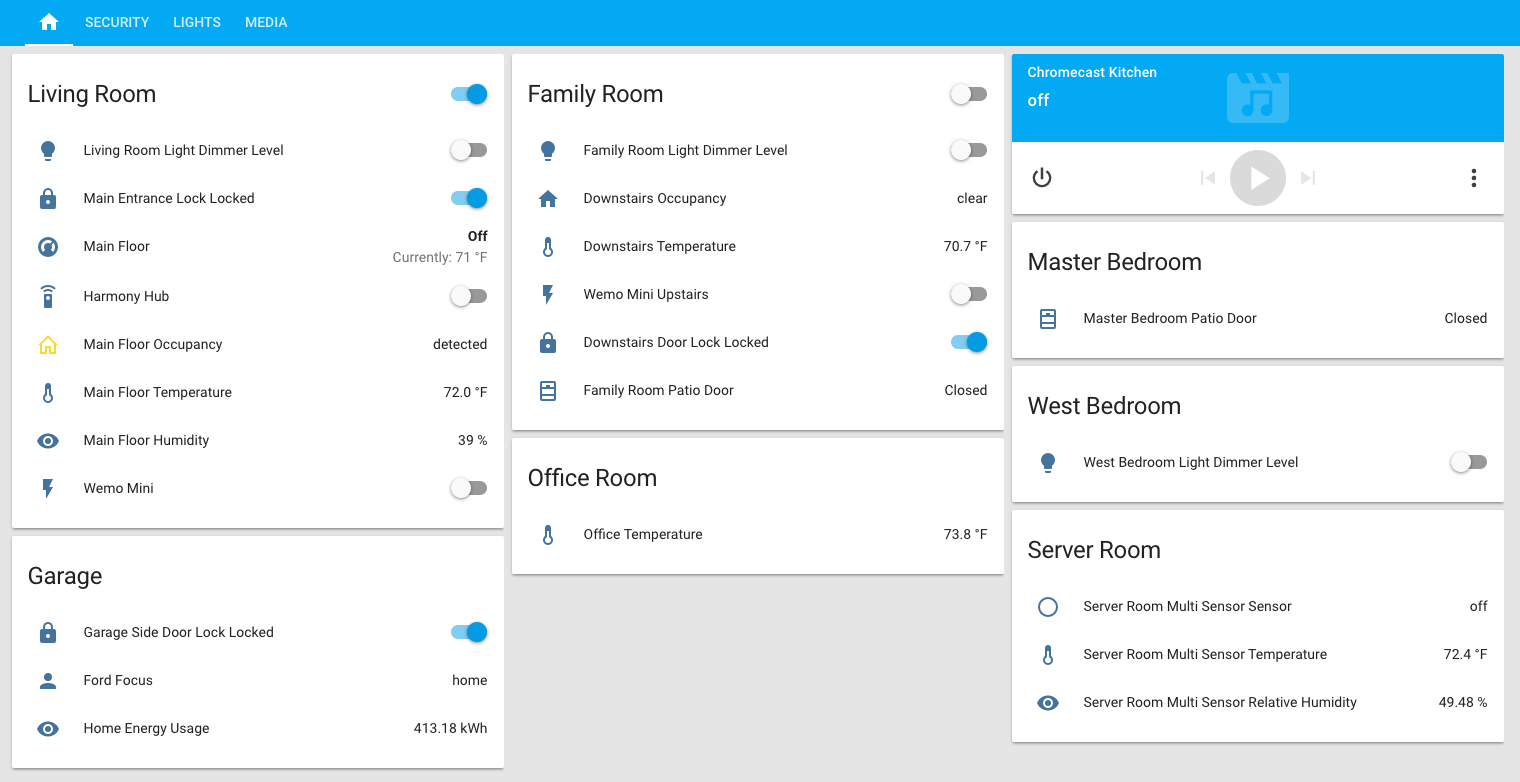
下图就是 Home Assistant 的面板截图,可以设置多个场景方便控制。比如我在睡觉前会看一眼 Security 确保门都锁好,以及其他监控正常。

数据库和监控
Home Assistant 默认会把所有的事件信息保存在 SQLite 数据库里,并不适合长时间保存,而且没法简单的导出给其他应用。我把所有的事件信息都保存到了 InfluxDB 里,在前端搭了一个 Grafana 做监控面板。
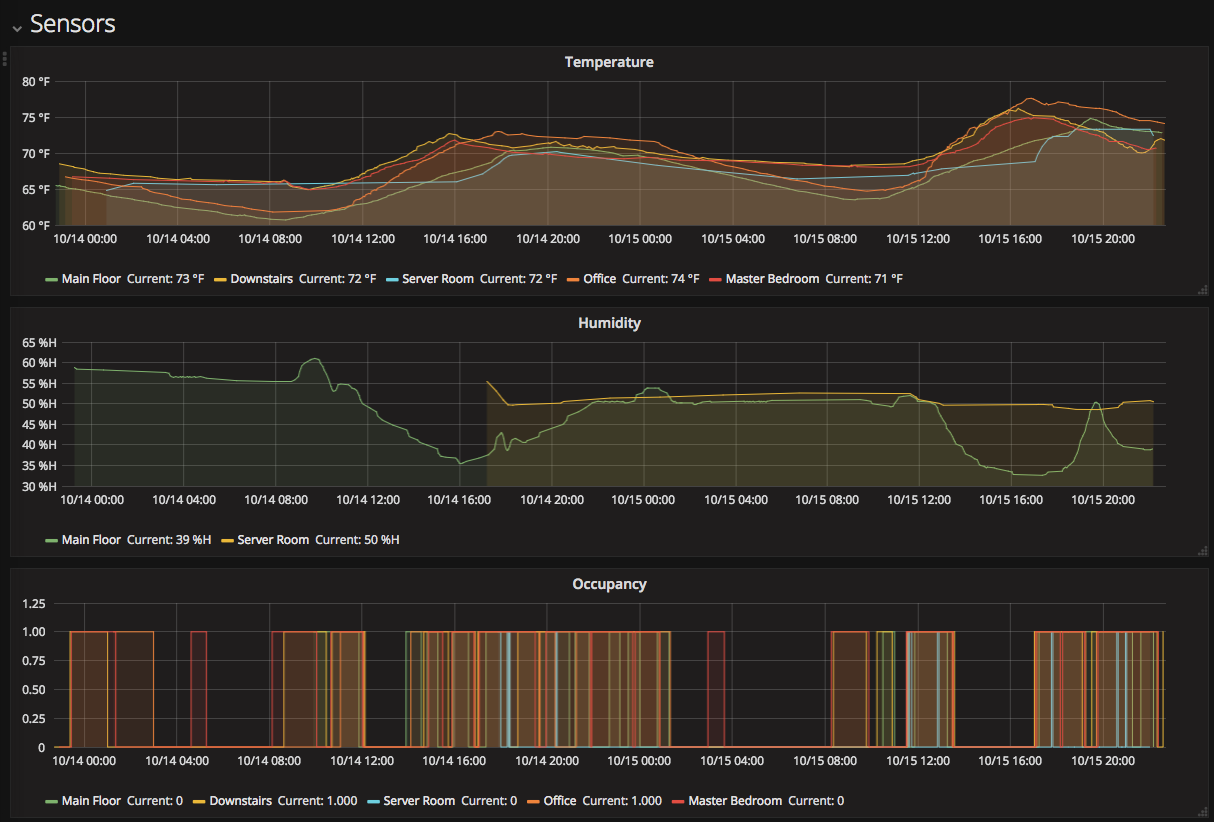
HA 对 InfluxDB 的支持很好,参考官方文档就能搞定,设置好以后所有的传感器更新、开关变化等信号都会保存到 InfluxDB 里。下图就是温度、湿度和占空传感器的一个 Grafana 页面。
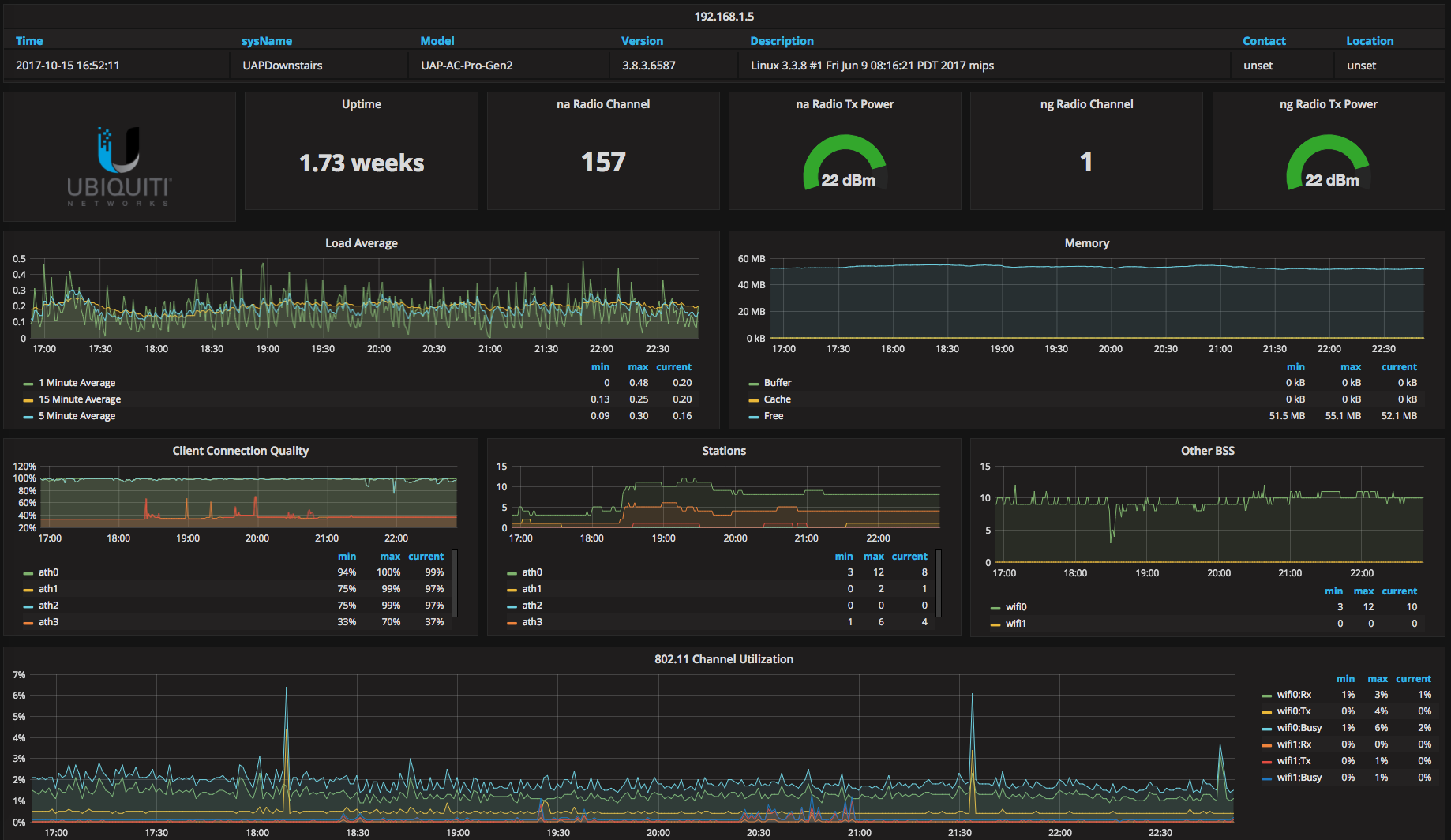
以及 Unifi AP 的信号监控页面,借用了网上的一个 Grafana 模版
传感器
传感器可以用来监控房间的温度、湿度,是否有人,以及门窗是否关好等。接下来介绍一下我研究过的几款传感器。
因为家里是用 Ecobee 控制暖气的,所以多买几个 Room Sensor 可以很方便的集成到网络里。Ecobee 会根据有人的房间的温度控制暖气,同时 Ecobee API 也会输出这些 Sensor 的数据(温度、是否有人)。购买链接
Monoprice Door Sensor
性价比挺高的门窗传感器,外观也比较低调。基于 Z-Wave Plus 协议,会报告剩余电量。购买链接
Monoprice Z-Wave Plus Multi Sensor
可以报告温度、湿度、是否有人和自身电量。默认的报告频率有点低(差 2 度才会发送更新),需要发个指令调节。购买链接
需要先买一个 Tag Manager,可以接入多达 40 个传感器,而且有效范围在 400ft (120m)。这个方案看起来很不错,不过我用 Ecobee sensor 再加几个 Monoprice 的 multi sensor 已经够用了。
小米的温湿度传感器和门窗传感器都只要 ¥49,性价比非常高,而且外观也不错。不过最后我还是没买小米的设备,主要原因是小米用的是私有的 Zigbee 协议,不支持 Smart Things,得买小米自己的中控。然而小米中控的有效范围在 10m 左右,用电池的传感器也不支持信号中继,得在楼上楼下放好几个小米中控才能保证足够的覆盖范围。
Monoprice Z-Wave Plus Door and Window Sensor
Monoprice 的门窗感应器,我在两扇院子门上各装了一个,方便查看院子门有没有关上。购买链接
监控摄像头
一开始我用的是 Arlo Pro,然而用了一阵子后觉得 Arlo 还是有不少问题,比如有录像延迟,检测到物体时经常会错过一开始的几秒,而且不付月租费话不支持 24 小时录像,即使插电源也不可以。
最后决定还是用传统 IP 摄像头 + NVR。视频录制在 NVR 的本地硬盘,出于安全考虑 NVR 不直接暴露给外网,而是通过中控服务器上的 ZoneMinder 间接访问。ZoneMinder 是一个开源的录像监控方案,其实它的功能已经相当强大了,但是同时监控几个摄像头会长时间占用中控的 CPU,所以我还是用了 NVR 专门负责监控录像。
照明
智能开关
研究了几个带亮度控制的开关,主要推荐两款,都是 Z-Wave Plus 协议的:
另外我还试过 Leviton DZMX1-1LZ,不推荐这款,要求有零线,价格不便宜而且还不支持 Z-Wave Plus。Leviton 应该有新款的开关,不过我没研究过。
智能灯泡
这一块没怎么研究,Hue 用过一段时间,还算方便,但就像之前那篇文章里提到的,智能灯泡的问题在于很难和普通开关一起用,得用配套的遥控开关才行,会导致墙上多不少开关。
另外 IKEA 今年出了不少智能灯泡,用了 Zigbee 协议,看评测感觉很有前途。
网络
一开始我在 Eero 和 Orbi 之间纠结,结果有位研究无线网络 4 年的同事给我推荐 Unifi 的无限路由,试了下的确好用。
UniFi Pro AP (UAP‑PRO) 可以通过 PoE 供电。不过 Unifi 设备的 PoE 比较特殊,这款 UAC-PRO 是同时支持 802.3af 和 802.3at 协议的,然而 UAP-AC-LITE 只支持 802.3at。如果你打算用 Unifi 官方的 PoE 网关,不需要担心这个问题。但如果你像我一样用的是其他的(我用了 NETGEAR JGS516PE),买之前得研究下这个供电问题。
Unifi Pro AP 的信号覆盖很好,我家楼上楼下各有 1400 sqft(130 平方米),院子不大。我在楼下入口和楼上靠近院子的房间各放了一个 AP,基本上就做到整个房子包括院子无死角覆盖了。这样算下来成本其实和用 Eero / Orbi 也差不多,但是性能会好很多,因此推荐给房间里布置了网线口的朋友。
Unifi 也出了类似 Eero 的 mesh network 的解决方案,没有研究过所以不做评价。
影音
客厅用了原来的 Harmony 遥控,配合 Amazon Echo 开关电视很方便。
装修的时候在其他房间布置了天花板音响,但是没有现成的价格又不是太贵的多个房间的音响解决方案。研究了一通之后采用了 Echo Dot + T-Amp 的方案,每个房间配一个 Echo Dot 和一个小型功放,用手机控制各个房间的音乐。功放我用的是 Topping TP30,不算音响成本大概在 $130 左右,比起其他动辄两千的解决方案划算多了。
天花板音箱用的是 Polk MC60,天花板音响效果的期望本来就不高,这个 6” 的音箱的音质已经够好了。另外它还防潮,所以厕所也能用。
其他
Homebridge
网上有一个开源的 Homebridge 插件,可以让 Homebridge 支持 Home Assistant,这样在 HomeKit 里面控制 HA 上的设备了。不过我很少用 HomeKit,没有花时间把一个个设备整理好。
门锁
门锁用的是 Schlage Camelot Touchscreen Deadbolt,Z-Wave 协议,很稳定,用到现在没出什么问题。用电量很小,三个月下来我的几个门锁还有 99% 的电(当然也有可能是 Z-Wave 电量报告不准确)。
Automatic
Automatic 是一个车载装置,它可以记录你的车辆行驶状态、当前位置等信息,HA 官方支持 Automatic,可以把车辆信息作为条件放到 HA 的自动化脚本里,比如车在车库里熄火以后关闭内部摄像头。
用电量
试了下 Aeotec 的电量检测工具,需要安装在电箱附近。这套工具价格不贵($15 左右),但是很不好用,有实时更新的问题。Home Assistant 的论坛上有个帖子讨论怎么搞定它的自动更新。
车库门控制
家里车库门的动力引擎用了 LiftMaster,所以我就买了他家的 Chamberlain MYQ-G0201 MyQ-Garage。这个设备不支持 Z-Wave 协议,但是 Home Assistant 有个插件可以以用户名密码的方式登陆后台控制。
如果想要支持 Z-Wave 协议的车库门开关,可以考虑 GoControl GD00Z-4。
电动窗帘
看下来 Bali 的方案还不错,Home Depot 可以试,不过最后因为各种原因还是没装。
Twilio
发短信的平台,配合 HA 的自动脚本很好用。比如我的设置里有一条规则是外门超过 5 分钟以上没锁就发短信提醒自己。正常的推送量用 Twilio 很便宜,价格大概是 $0.0075 一条,所以我都没有设置 HA 的推送平台。
One More Thing: Floorplan
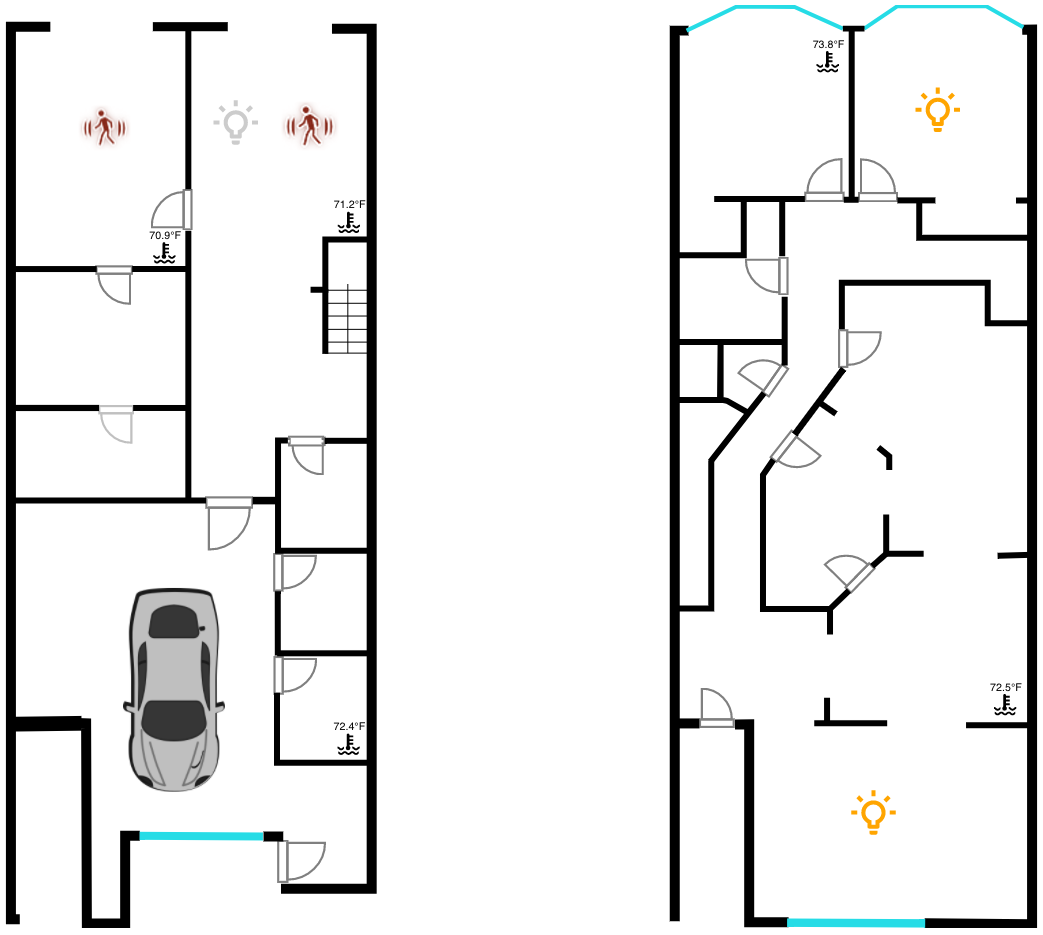
最近在折腾的一个叫 Floorplan 的 HA 插件,顾名思义就是让所有的智能设备显示在一个平面图上方便控制。
这是我目前的效果图,现在只加入了灯光、占空和温度信息,点击对应的房间可以控制这个房间的灯光。接下来打算在左侧放一排全局控制的按键,把弄一个平板挂到墙上,就可以在进家和出门的时候方便的控制全屋设备了。类似下图的效果(图片来源)。